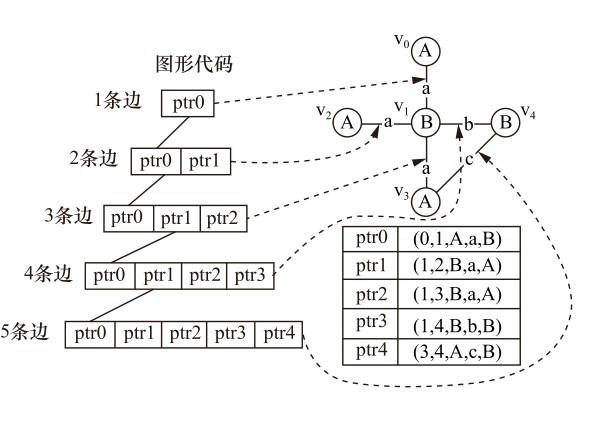
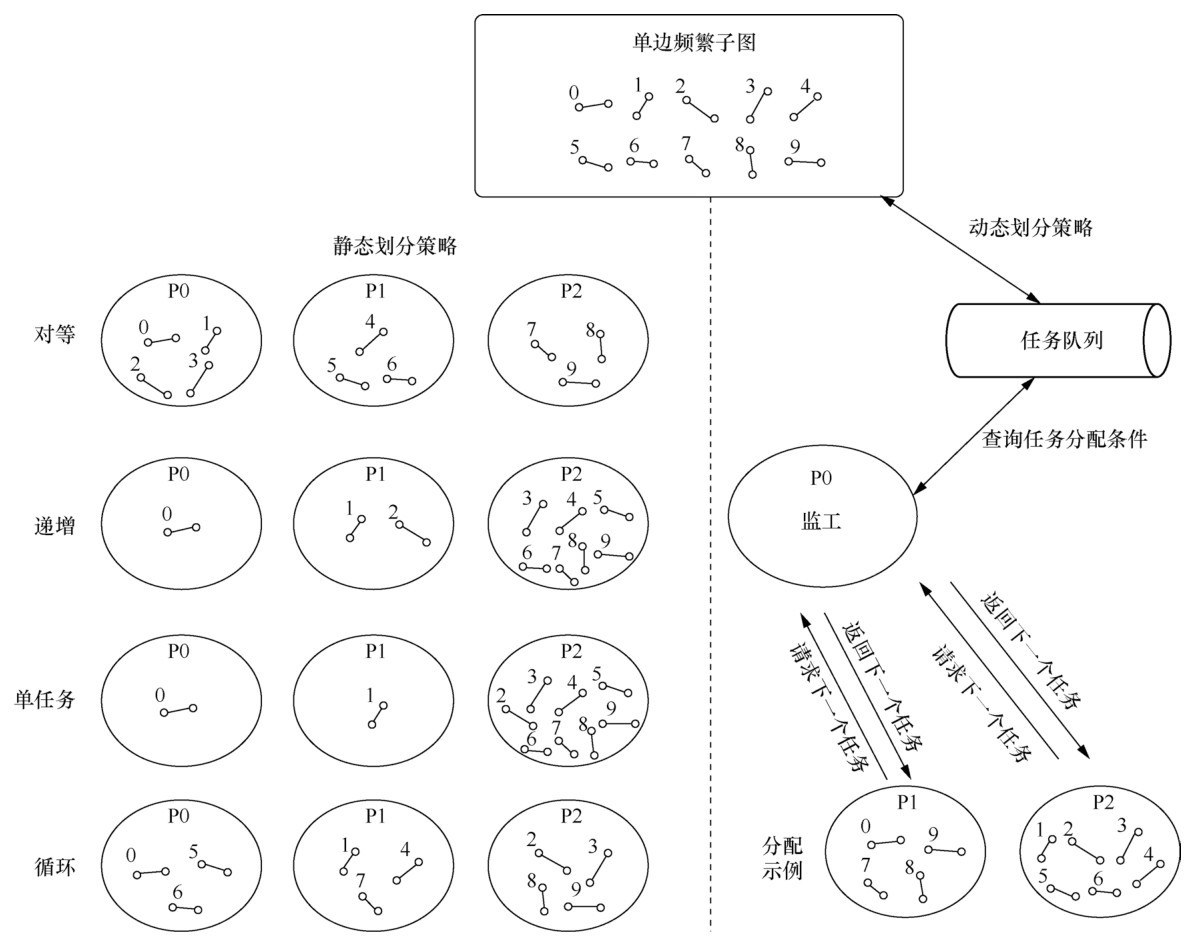
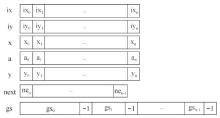
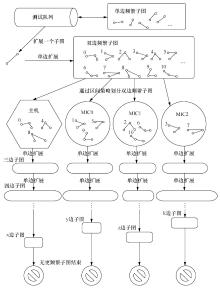
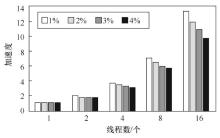
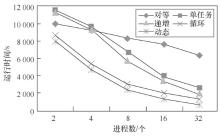
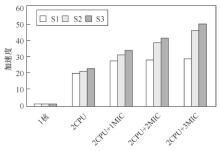
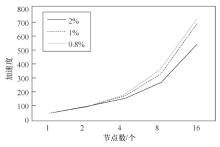
| [1] |
LIN W . Efficient techniques for subgraph mining and query processing[D]. Singapore:Nanyang Technological University, 2015.
|
| [2] |
HUAN J , WANG W , PRINS J ,et al. SPIN:mining maximal frequent subgraphs from graph databases[C]// The 10th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining,August 22-25,2004,Seattle,USA. New York:ACM Press, 2004: 581-586.
|
| [3] |
JIANG X , XIONG H , WANG C ,et al. Mining globally distributed frequent subgraphs in a single labeled graph[J]. Data and Knowledge Engineering, 2009,68(10): 1034-1058.
|
| [4] |
KURAMOCHI M , KARYPIS G . Finding frequent patterns in a large sparse graph[J]. Data Mining & Knowledge Discovery, 2005,11(3): 243-271.
|
| [5] |
KANG U , TSOURAKAKIS CE , FALOUTSOS C . PEGASUS:mining peta-scale graphs[J]. Knowledge & Information Systems, 2011,27(2): 303-325.
|
| [6] |
REINHARDT S , KARYPIS G . A multi-level parallel implementation of a program for finding frequent patterns in a large sparse graph[C]// 2007 IEEE International Parallel and Distributed Processing Symposium,March 26-30,2007,Rome,Italy. Piscataway:IEEE Press, 2007: 1-8.
|
| [7] |
WU B , BAI Y L . An efficient distributed subgraph mining algorithm in extreme largegraphs[C]// The 2010 International Conference on Artificial Intelligence and Computational Intelligence,October 23-24,2010,Sanya,China. Heidelberg:Springer, 2010: 107-115.
|
| [8] |
YAN Y , DONG Y , HE X ,et al. FSMBUS:a frequent subgraph mining algorithm in single large-scale graph using spark[J]. Journal of Computer Research and Development, 2015,52(8): 1768-1783.
|
| [9] |
LIN W , XIAO X , XIE X ,et al. Network motif discovery:a GPU approach[C]// IEEE 31st International Conference on Data Engineering,April 13-17,2015,Seoul,Korea. Piscataway:IEEE Press, 2015: 831-842.
|
| [10] |
HILL S , SRICHANDAN B , SUNDERRAMAN R . An iterative MapReduce approach to frequent subgraph mining in biological datasets[C]// The ACM Conference on Bioinformatics,Computational Biology and Biomedicine,October 7-10,2012,Orlando,USA. New York:ACM Press, 2012: 661-666.
|
| [11] |
INOKUCHI A , WASHIO T , MOTODA H . An apriori-based algorithm for mining frequent substructures from graph data[C]// The 4th European Conference on Principles of Data Mining and Knowledge Discovery,September 13-16,2000,London,UK. London:SpringerVerlag, 2000: 13-23.
|
| [12] |
KURAMOCHI M , KARYPIS G . Frequent subgraph discovery[C]// IEEE International Conference on Data Mining,November 29-December 2,2001,San Jose,USA. Piscataway:IEEE Press, 2001: 313-320.
|
| [13] |
MEINL T , FISCHER I , PHILIPPSEN M . A quantitative comparison of the subgraph miners mofa,gspan,FFSM,and gaston[C]// European Conference on Principles and Practice of Knowledge Discovery in Databases,October 3-7,2005,Porto,Portugal. Heidelberg:Springer, 2005: 392-403.
|
| [14] |
BORGELT C , BERTHOLD M R . Mining molecular fragments:finding relevant substructures of molecules[C]// 2002 IEEE International Conference on Data Mining,December 9-12,2002,Maebashi City,Japan. Piscataway:IEEE Press, 2002: 51-58.
|
| [15] |
HUAN J , WANG W , PRINS J . Efficient mining of frequent subgraphs in the presence of isomorphism[C]// The 3rd IEEE International Conference on Data Mining,November 19-22,2003,Melbourne,USA. Washington,DC:IEEE Computer Society, 2003: 549-552.
|
| [16] |
YAN X , HAN J . gSpan:graph-based substructure pattern mining[C]// 2002 IEEE International Conference on Data Mining,December 9-12,2002,Maebashi City,Japan. Piscataway:IEEE Press, 2002: 721-724.
|
| [17] |
NIJSSEN S , . A quickstart in frequent structure mining can make a difference[C]// The 10th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining,August 2225,2004,Seattle,USA. New York:ACM Press, 2004: 647-652.
|
| [18] |
BUEHRER G , PARTHASARATHY S , CHEN Y K . Adaptive parallel graph mining for CMP architectures[C]// The 6th International Conference on Data Mining,December 18-22,2006,Hong Kong,China. Piscataway:IEEE Press, 2006: 97-106.
|
| [19] |
WANG C , WANG W , PEI J ,et al. Scalable mining of large disk-based graph databases[C]// The 10th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining,August 22-25,2004,Seattle,USA. New York:ACM Press, 2004: 316-325.
|
| [20] |
NGUYEN S N , ORLOWSKA M E , LI X . Graph mining based on a data partitioning approach[C]// The 19th Conference on Australasian Database,December 3-4,2007,Gold Coast,Australia.Darlinghurst:Australian Computer Society,Inc. , 2008: 31-37.
|
| [21] |
DEAN J , GHEMAWAT S . MapReduce:simplified data processing on large clusters[C]// The 6th Conference on Symposium on Opearting Systems Design & Implementation,December 6-8,2004,San Francisco,USA. Berkeley:USENIX Association, 2004: 107-113.
|
| [22] |
BHUIYAN M A , AL H M . An iterative MapReduce based frequent subgraph mining algorithm[J]. IEEE Transactions on Knowledge& Data Engineering, 2013,27(3): 608-620.
|
| [23] |
LU W , CHEN G , TUNG A K H ,et al. Efficiently extracting frequent subgraphs using MapReduce[C]// 2013 IEEE International Conference on Big Data,October 6-9,2013,Silicon Valley,USA. Piscataway:IEEE Press, 2013: 639-647.
|
| [24] |
LIN W , XIAO X , GHINITA G . Largescale frequent subgraph mining in MapReduce[C]// 2014 IEEE 30th International Conference on Data Engineering,March 31-April l4,2014,Chicago,USA. Piscataway:IEEE Press, 2014: 844-855.
|