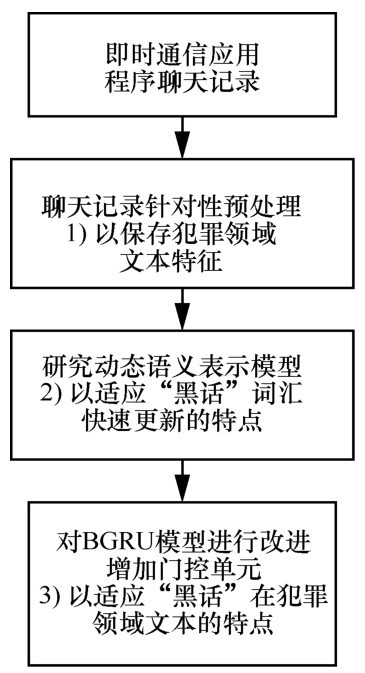
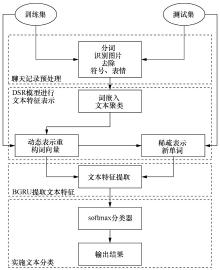
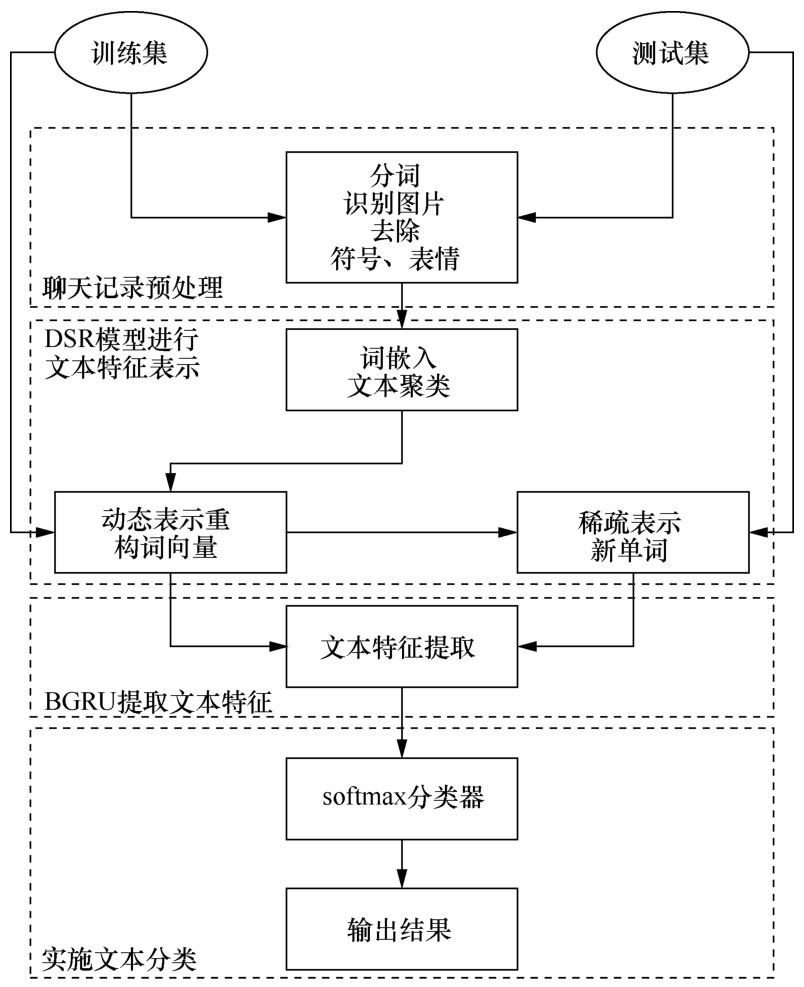
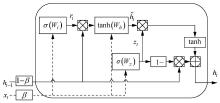
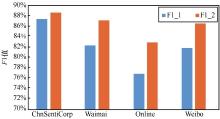
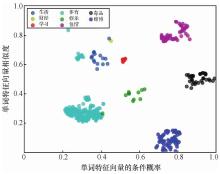
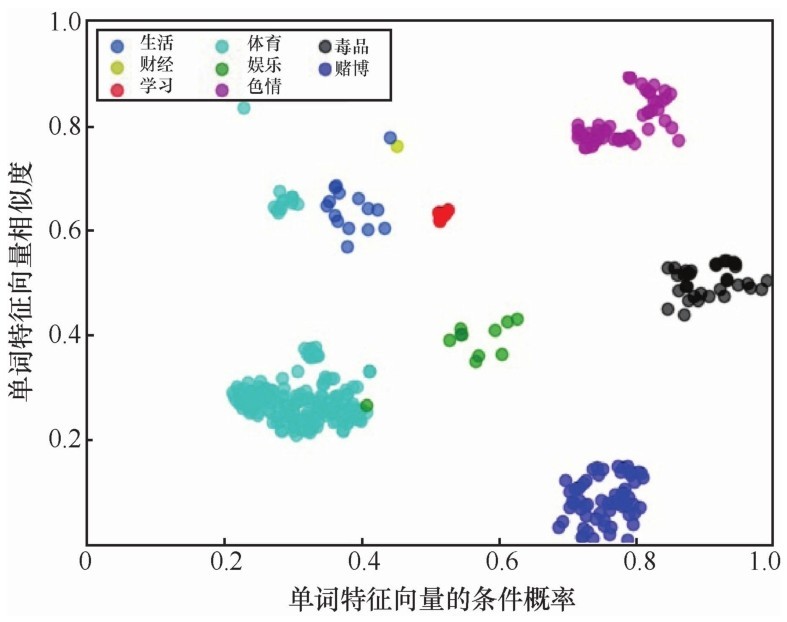
| [1] |
中国互联网络中心. 中国互联网络发展状况统计报告[EB].
|
|
China Internet Network Center. Statistical report on Internet development in China[EB].
|
| [2] |
刘昊, 徐鹏 . 基于关系网络的PageRank算法在禁毒情报上的应用研究[J]. 中国人民公安大学学报(自然科学版), 2019,25(1): 65-73.
|
|
LIU H , XU P . Research on application of PageRank algorithm based on relational network in anti-drug intelligence[J]. Journal of People's Public Security University of China (Science and Technology), 2019,25(1): 65-73.
|
| [3] |
杜思佳, 于海宁, 张宏莉 . 基于深度学习的文本分类研究进展[J]. 网络与信息安全学报, 2020,6(4): 1-13.
|
|
DU S J , YU H N , ZHANG H L . Survey of text classification methods based on deep learning[J]. Chinese Journal of Network and Information Security, 2020,6(4): 1-13.
|
| [4] |
于游, 付钰, 吴晓平 . 中文文本分类方法综述[J]. 网络与信息安全学报, 2019,5(5): 1-8.
|
|
YU Y , FU Y , WU X P . Summary of text classification methods[J]. Chinese Journal of Network and Information Security, 2019,5(5): 1-8.
|
| [5] |
LAI S , XU L , LIU K ,et al. Recurrent convolutional neural networks for text classification[C]// Proceedings of Twenty-ninth AAAI Conference on Artificial intelligence. 2015.
|
| [6] |
TRAN K , BISAZZA A , MONZ C . Recurrent memory networks for language modeling[J]. 2016:arXiv:1601.01272.
|
| [7] |
TANG D Y , QIN B , FENG X C ,et al. Effective LSTMs for target-dependent sentiment classification[J]. 2015:arXiv:1512.01100.
|
| [8] |
LIU G , GUO J B . Bidirectional LSTM with attention mechanism and convolutional layer for text classification[J]. Neurocomputing, 2019,337: 325-338.
|
| [9] |
赵宏, 王乐, 王伟杰 . 基于 BiLSTM-CNN 串行混合模型的文本情感分析[J]. 计算机应用, 2020,40(1): 16-22.
|
|
ZHAO H , WANG L , WANG W J . Text sentiment analysis based on serial hybrid model of bi-directional long short-term memory and convolutional neural network[J]. Journal of Computer Applications, 2020,40(1): 16-22.
|
| [10] |
陈榕, 任崇广, 王智远 ,等. 基于注意力机制的CRNN文本分类算法[J]. 计算机工程与设计, 2019,40(11): 3151-3157.
|
|
CHEN R , REN C G , WANG Z Y ,et al. Attention based CRNN for text classification[J]. Computer Engineering and Design, 2019,40(11): 3151-3157.
|
| [11] |
张洋, 胡燕 . 基于多通道深度学习网络的混合语言短文本情感分类方法[J]. 计算机应用研究, 2021,38(1): 69-74.
|
|
ZHANG Y , HU Y . Code-switching short-text sentiment classification method based on multi-channel deep learning network[J]. Application Research of Computers, 2021,38(1): 69-74.
|
| [12] |
丁建立, 苏现帅 . 基于组合式深度学习网络的混合文本情感分类[J]. 计算机工程与设计, 2019,40(11): 3254-3258,3264.
|
|
DING J L , SU X S . Mixed text classification method based on combined deep learning network[J]. Computer Engineering and Design, 2019,40(11): 3254-3258,3264.
|
| [13] |
曹宇, 李天瑞, 贾真 ,等. BGRU:中文文本情感分析的新方法[J]. 计算机科学与探索, 2019,13(6): 973-981.
|
|
CAO Y , LI T R , JIA Z ,et al. BGRU:new method of Chinese text sentiment analysis[J]. Journal of Frontiers of Computer Science and Technology, 2019,13(6): 973-981.
|
| [14] |
MOREO A , ESULI A , SEBASTIANI F . Word-class embeddings for multiclass text classification[J]. Data Mining and Knowledge Discovery, 2021,35(3): 911-963.
|
| [15] |
DU J , VONG C M , CHEN C L P . Novel efficient RNN and LSTM-like architectures:recurrent and gated broad learning systems and their applications for text classification[J]. IEEE Transactions on Cybernetics, 2021,51(3): 1586-1597.
|
| [16] |
XU J Y , CAI Y , WU X ,et al. Incorporating context-relevant concepts into convolutional neural networks for short text classification[J]. Neurocomputing, 2020,386: 42-53.
|
| [17] |
段丹丹, 唐加山, 温勇 ,等. 基于 BERT 模型的中文短文本分类算法[J]. 计算机工程, 2021,47(1): 79-86.
|
|
DUAN D D , TANG J S , WEN Y ,et al. Chinese short text classification algorithm based on BERT model[J]. Computer Engineering, 2021,47(1): 79-86.
|