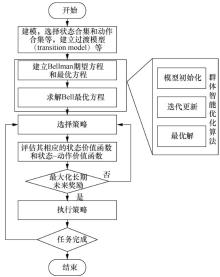
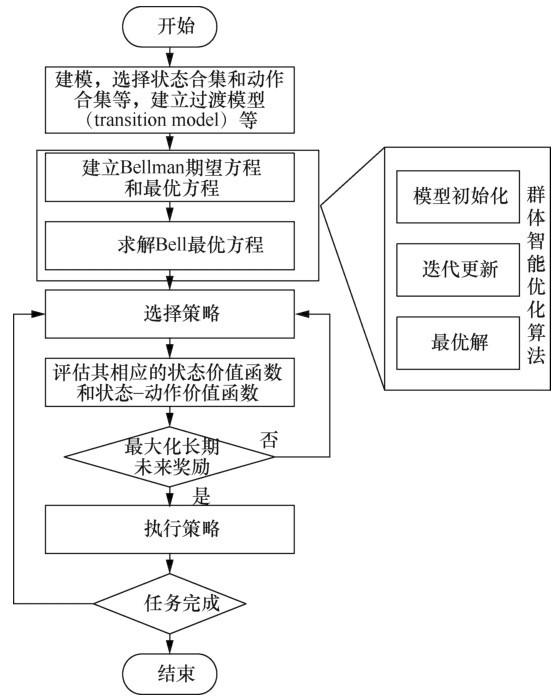
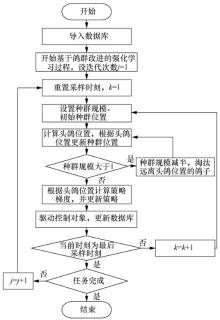
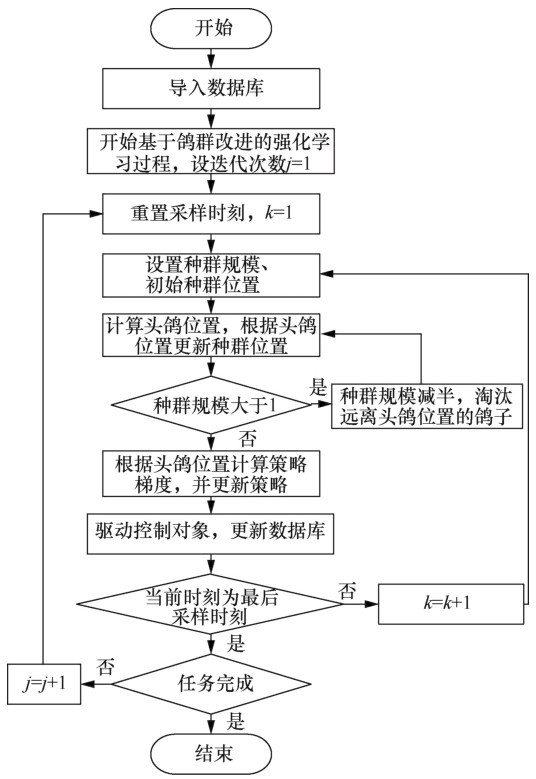
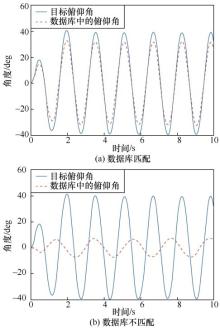
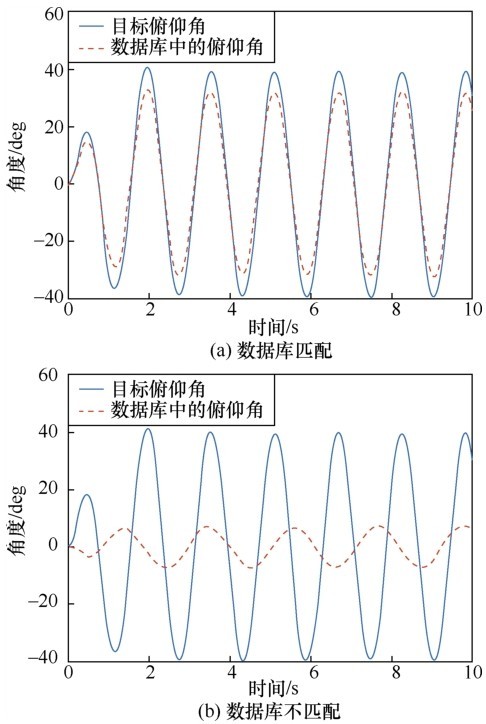
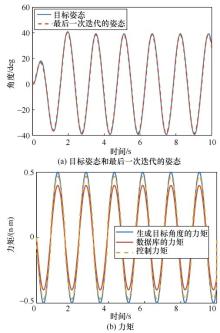
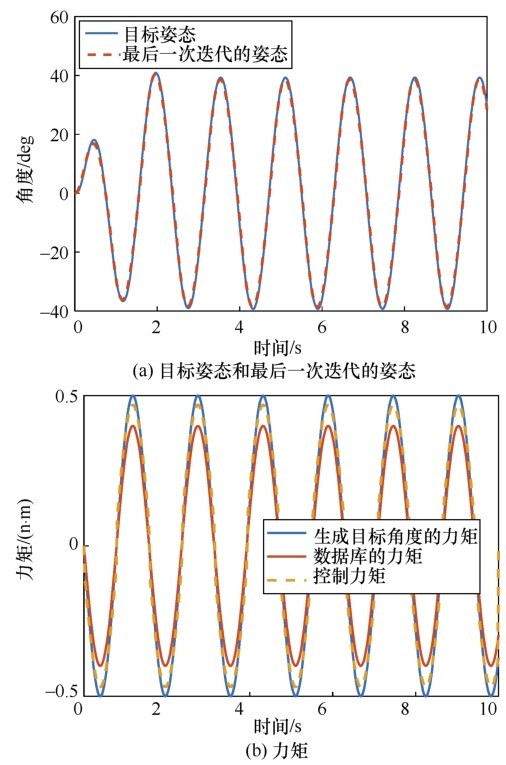
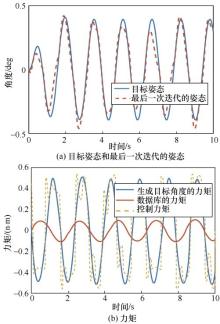
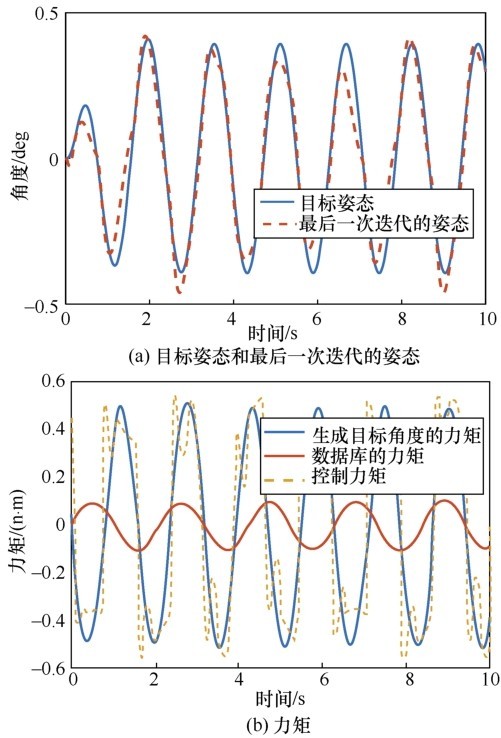
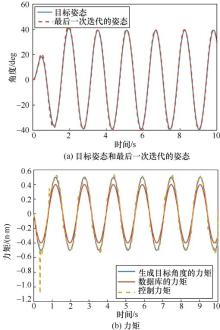
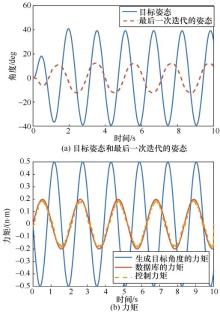
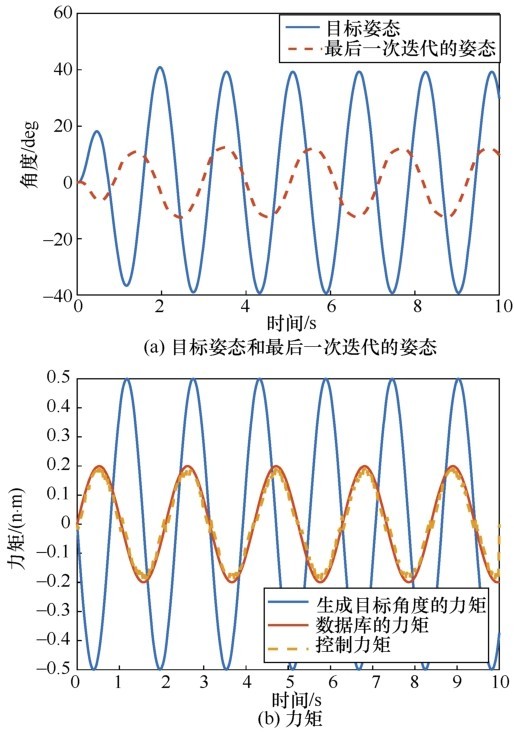
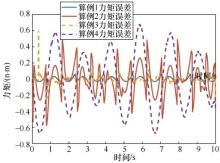
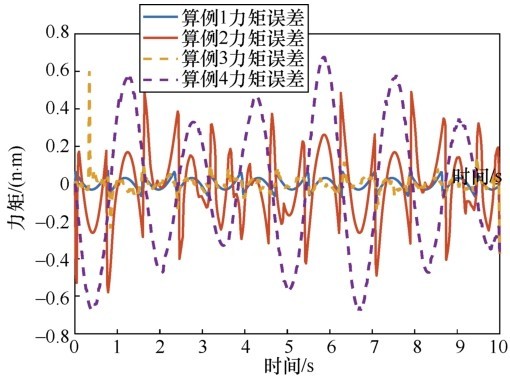
| [1] |
PETERS J , SCHAAL S . Policy gradient methods for robotics[C]// 2006 IEEE/RSJ International Conference on Intelligent Robots and Systems. 2006: 2219-2225.
|
| [2] |
BAUM Y , AMICO M , HOWELL S ,et al. Experimental deep reinforcement learning for error-robust gate-set design on a superconducting quantum computer[J]. PRX Quantum, 2021,2(4): 040324.
|
| [3] |
HUA J , ZENG L , LI G ,et al. Learning for a robot:deep reinforcement learning,imitation learning,transfer learning[J]. Sensors, 2021,21(4): 1278.
|
| [4] |
SIVAK V V , EICKBUSCH A , LIU H ,et al. Model-free quantum control with reinforcement learning[J]. Physical Review X, 2022,12(1): 011059.
|
| [5] |
AGARWAL N , HAZAN E , MAJUMDAR A ,et al. A regret minimization approach to iterative learning control[C]// International Conference on Machine Learning (PMLR). 2021: 100-109.
|
| [6] |
KRIZHEVSKY A , SUTSKEVER I , HINTON G E . Imagenet classification with deep convolutional neural networks[J]. Advances in Neural Information Processing Systems. 2012: 1097-1105.
|
| [7] |
YARATS D , FERGUS R , LAZARIC A ,et al. Reinforcement learning with prototypical representations[C]// International Conference on Machine Learning (PMLR). 2021: 11920-11931.
|
| [8] |
DAHL G E , YU D , DENG L ,et al. Context-dependent pre-trained deep neural networks for large-vocabulary speech recognition[J]. IEEE Transactions on Audio,Speech,and Language Processing, 2011: 30-42.
|
| [9] |
HAOXIANG W , SMYS S . Overview of configuring adaptive activation functions for deep neural networks—a comparative study[J]. Journal of Ubiquitous Computing and Communication Technologies (UCCT), 2021,3(1): 10-22.
|
| [10] |
MISHRA A , LATORRE J A , Pool J ,et al. Accelerating sparse deep neural networks[J]. arXiv preprint arXiv:2104.08378, 2021.
|
| [11] |
SILVER D , HUANG A , MADDISON C J ,et al. Mastering the game of go with deep neural networks and tree search[J]. Nature, 2016,529:484.
|
| [12] |
VINYALS O , BABUSCHKIN I , CZARNECKI W M ,et al. Grandmaster level in StarCraft II using multi-agent reinforcement learning[J]. Nature, 2019,575: 350-354.
|
| [13] |
HEESS N , WAYNE G , SILVER D ,et al. Learning continuous control policies by stochastic value gradients[C]// Advances in Neural Information Processing Systems. 2015:28.
|
| [14] |
CHEN Z , CHEN B , XIE S ,et al. Efficiently training on-policy actor-critic networks in robotic deep reinforcement learning with demonstration-like sampled exploration[C]// 2021 3rd International Symposium on Robotics & Intelligent Manufacturing Technology (ISRIMT). 2021: 292-298.
|
| [15] |
WANG C , LING Y . Actor-critic tracking with precise scale estimation and advantage function[J]. Journal of Physics Conference Series, 2021,1827(1): 012064.
|
| [16] |
ZHANG S , DUAN H . Gaussian pigeon-inspired optimization approach to orbital spacecraft formation reconfiguration[J]. Chinese Journal of Aeronautics, 2015,28(1): 200-205.
|
| [17] |
ZHANG B , DUAN H . Three-dimensional path planning for uninhabited combat aerial vehicle based on predator-prey pigeon-inspired optimization in dynamic environment[J]. IEEE/ACM Transactions on Computational Biology & Bioinformatics, 2017,14(1): 97-107.
|
| [18] |
周雨鹏 . 基于鸽群算法的函数优化问题求解[D]. 长春:东北师范大学, 2016.
|
|
ZHOU Y P . Function optimization problem solving based on pigeon swarm algorithm[D]. Changchun:Northeast Normal University, 2016.
|
| [19] |
顾清华, 孟倩倩 . 优化复杂函数的粒子群-鸽群混合优化算法[J]. 计算机工程与应用, 2019,55(22): 46-52.
|
|
GU Q H , MENG Q Q . Hybrid particle swarm optimization and pigeon—inspired optimization algorithm for solving complex functions[J]. Computer Engineering and Applications, 2019,55(22): 46-52.
|
| [20] |
胡耀龙, 冯强, 海星朔 ,等. 基于自适应学习策略的改进鸽群优化算法[J]. 北京航空航天大学学报, 2020,46(12): 2348-2356.
|
|
HU Y L , FENG Q , HAI X S ,et al. Improved pigeon-inspired optimization algorithm based on adaptive learning strategy[J]. Journal of Beijing University of Aeronautics and Astronautics, 2020,46(12): 2348-2356.
|