




1 引言
CNN 规模大和计算量大的特点导致移动端上部署变得很困难,规模太大可以压缩[4,5],计算量太大就须进行加速。如今,CNN嵌入式端加速主要集中于 FPGA[6]。例如,文献[7]结合卷积计算特点用多个二维卷积器实现三维卷积操作,充分利用FPGA上资源实现高速计算。文献[8]首先考虑FPGA资源限制(如片上存储、寄存器、计算资源和外部存储带宽),之后为给定的CNN模型探索出基于 OpenCL 的最大化吞吐量的 FPGA加速器。文献[9]在FPGA上部署Winograd算法进行卷积加速。但以上利用FPGA的加速方法都未能利用卷积计算中的稀疏性。利用卷积计算中稀疏性的加速方法有文献[10],采用行固定的处理数据方式来利用稀疏性,当数据通道的输入为 0 值时直接不做处理。文献[11]利用并行矩阵乘法器完成卷积计算并充分利用了参数稀疏性。文献[12]把 Winograd算法和稀疏性进行结合减少卷积操作,改变 Winograd 作用域来利用稀疏性,Winograd算法计算快但对数据输入输出要求高,运用到FPGA上时存取速度成了限制因素。
2 问题描述
2.1 CNN稀疏性特点
CNN卷积层的卷积计算有一个激活函数,常用的激活函数Relu示意如图1所示。
图1

图2
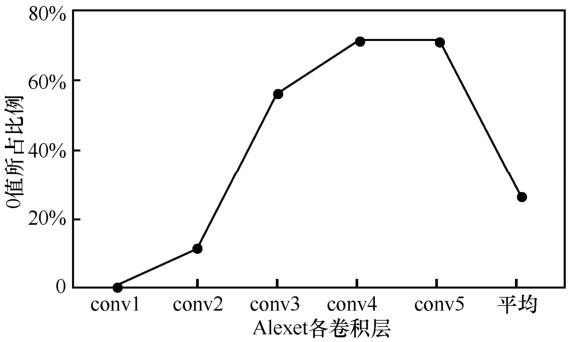
图3
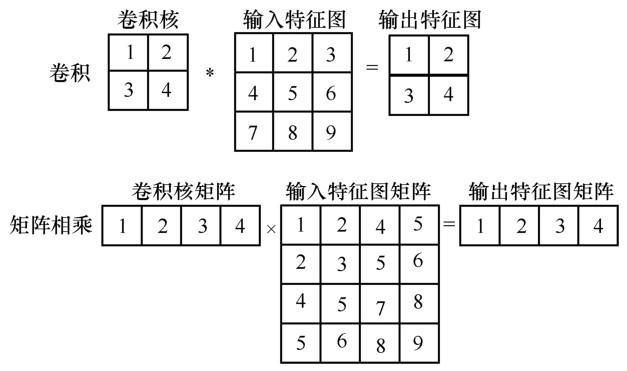
2.2 并行矩阵乘法器用于CNN加速
图4
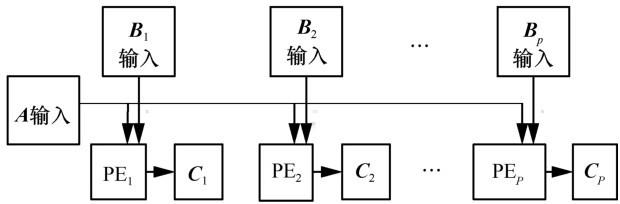
表1 45 nm CMOS 相关操作能量消耗
| 操作类型 | 能量消耗/pJ | 能量消耗比例 |
| 32 bit int ADD | 0.1 | 1 |
| 32 bit float ADD | 0.9 | 9 |
| 32 bit Register File | 1 | 10 |
| 32 bit int MULT | 3.1 | 31 |
| 32 bit float MULT | 3.7 | 37 |
| 32 bit SRAM Cache | 5 | 50 |
| 32 bit DRAM Memory | 640 | 6 400 |
3 改进的线性脉动阵列
图5

图6
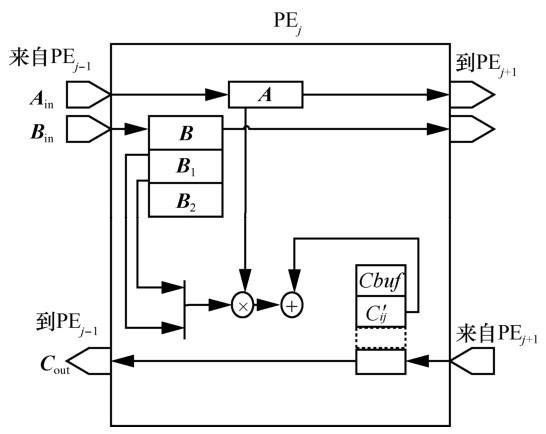
图7

图8
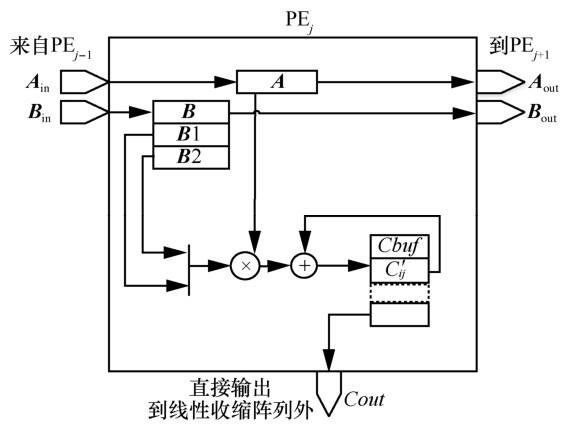
单输出线性脉动阵列和多输出线性脉动阵列仅在输出时有差别,本文以单输出线性脉动阵列为例说明具体计算方式。对于n×n的矩阵,改进线性脉动阵列需要n个处理单元(PE)。矩阵乘法时,矩阵
PEj在计算
1) 对于有很多0值的输入特征图
2) 卷积核矩阵
图9以3×3的矩阵乘法进行示例说明。“√”代表得出最后的计算结果且下一个周期进行传输,“←”代表传送方向,“有”代表该位置有值继而下一个周期往前传,“空”代表该位置已经把值传送出去。例如,第1周期内完成了
4 单输出线性脉动阵列性能分析
本文所用的单输出线性脉动阵列和文献[11]的并行矩阵乘法器的对比从3个方面进行:计算循环周期、存取操作类别和存取操作次数以及资源耗费情况。下面依次进行说明(接下来分析针对没有0值的情况,为0值时对应线性脉动阵列的第一个方面改进)。
4.1 计算循环周期
对于由n个PE完成的n × n的矩阵乘法,单输出线性脉动阵列共需要2n2+1个周期完成所有操作(从开始输入到输出所有数据)。
本文把所有操作分为2个阶段,2个阶段以
对于并行矩阵乘法器,当有n个处理单元时,由于每个周期从
4.2 存取操作类别和存取操作次数
单输出线性脉动阵列和并行矩阵乘法器在完成n×n的矩阵乘法时,要从片外内存取数据到片内缓存以及反向的存操作,这部分操作是一致的,另外,每个PE内部深度为n的SRAM Cache存取中间结果也是一致的。
对于单输出线性脉动阵列,从 PE 外 Cache输入数据时,每个数据只输入一次,即2n2次Cache到寄存器操作,之后在线性脉动阵列PE的内部寄存器之间传输,
图9

图10

对于并行矩阵乘法器,n×n的
表2 单输出线性脉动阵列和并行矩阵乘法器存取操作类别和存取操作次数对比
| 操作类别 | 存取操作次数 | |
| 单输出线性脉动阵列 | 并行矩阵乘法器 | |
| 片外→片内及片内→片外 | 一致 | 一致 |
| PE外Cache→PE内寄存器 | 2n2 | 2n3 |
| PE内部寄存器→寄存器 | ― | |
| 存取中间结果Cache操作 | 一致 | 一致 |
| 输出时Cache操作 | n2 | |
从上述对比可以看出,二者的数据搬移量相等。从能量方面看, PE外Cache到PE内寄存器传输操作以及输出时的 Cache 操作可以视为从SRAM读取数据的能量消耗,可以进行合并。差别如下:单输出线性脉动阵列独有
4.3 资源耗费情况
改进的线性脉动阵列
表3 并行矩阵乘法器用于Alexnet卷积加速时的FPGA内部资源使用情况
| 资源类别 | 总使用量 | 可利用总量 | 利用率 |
| BRAM_18K | 1 458 | 2 060 | 70.78% |
| DSP48E | 1 792 | 2 800 | 64.00% |
| FF | 1 792 | 607 200 | 28.12% |
| LUT | 142 304 | 303 600 | 46.87% |
从 I/O 端口来看,单输出线性脉动阵列只需3 个端口,而并行矩阵乘法器需要n+n+n=3n个端口,对于n较大的情况,端口消耗以及带宽要求差异非常明显。从资源消耗来看,单输出线性脉动阵列虽然使用较多的 FF 资源,但却很大程度上减少了I/O端口量及带宽要求。
4.4 与并行矩阵乘法器对比
表4 单输出线性脉动阵列和并行矩阵乘法器对比
| 单输出线性脉动阵列 | 并行矩阵乘法器 | |
| 周期 | 2n2+1 | n2 |
| 存取操作差异次数 | ||
| (寄存器读) | (SRAM读) | |
| 寄存器消耗 | 多2n | — |
| I/O端口及带宽 | 3 | 3n |
5 多输出线性脉动阵列性能分析
表5 Alexnet各卷积层矩阵分块
| 卷积层 | 原始大小 | 分块 |
| 卷积层1 | (3 025×363)×(363×96) | (95×12)×(12×3) |
| 卷积层2 | (729×1200)×(1200×256) | (23×38)×(38×8) |
| 卷积层3 | (169×2 304)×(2 304×384) | (6×72)×(72×12) |
| 卷积层4 | (169×1 728)×(1 728×384) | (6×54)×(54×12) |
| 卷积层5 | (169×1 728)×(1 728×256) | (6×54)×(54×8) |
分块后一个很重要的想法是进一步复用和并行流水线。14个并行的线性脉动阵列可以同时进行矩阵乘法计算,分块矩阵乘法有以下2种(如图11所示):第一种是为了在乘法完成后方便进行相加;第二种是为了实现对分块矩阵的复用,设置多级缓存可以进一步减少数据搬移量。
图11

线性脉动阵列计算只是占了整个过程的一部分,如图10中前3后5个周期都没有计算操作,单纯的传输时间占用不少。除了复用,还可以采用流水线设计。
表6 多输出线性脉动阵列和并行矩阵乘法器存取操作类别和存取操作次数对比
| 多输出线性脉动阵列 | 并行矩阵乘法器 | |
| 周期 | n2 | |
| 存取操作差异次数 | 2n 2(n−1) (SRAM读) | |
| (寄存器读) | ||
| 寄存器消耗 | 多2n | ― |
| I/O端口及带宽 | 2+n | 3n |
表7 改进的线性脉动阵列和并行矩阵乘法器特点
| 改进方案 | 特点 |
| 文献[11]并行矩阵乘法器 | 带宽要求最大但周期最少,耗能最多 |
| 单输出线性脉动阵列 | 带宽要求最小但周期最多,耗能次之 |
| 多输出线性脉动阵列 | 带宽、周期处于前两者之间,耗能最少 |
相比单输出线性脉动阵列,多输出线性脉动阵列的最大优点是周期数大幅减少。相比并行矩阵乘法器,该方式仍然具有带宽的优势。具体应用场景方面,由于线性脉动阵列能利用输入中全部稀疏性(
6 结束语
本文针对CNN计算稀疏性的特点以及文献[11]所述的传统并行矩阵乘法器用于 CNN 加速的局限性,对文献[13-14]的线性脉动阵列提出了2种改进——单输出以及多输出线性脉动阵列,用于CNN嵌入式端的加速。文献[11]提出的并行矩阵乘法器直接作用于 CNN 加速时所需带宽太大,而线性脉动阵列正好能弥补该缺陷。单输出线性脉动阵列和并行矩阵乘法器对比有耗能以及 I/O端口少的优势,但计算周期却是2倍的关系,所以本文进一步改进线性脉动阵列,提出了多输出线性脉动阵列。对比来看,多输出方式的周期及I/O 需求介于两者之间,很好地解决了前两者的突出缺陷问题,可行性最高。本文所进行的对比分析只是理论上说明,如何最佳组合以及最充分利用资源并实现是下一步的工作。
参考文献
Eyeriss:an energy-efficient reconfigurable accelerator for deep convolutional neural networks
[J].
利用参数稀疏性的卷积神经网络计算优化及其FPGA加速器设计
[J].
Calculation optimization for convolutional neural networks and FPGA-based accelerator design using the parameters sparsity
[J].
Efficient sparse-winograd convolutional neural networks
[C]//
Energy-and time-efficient matrix multiplication on FPGAs
[J].
Energy efficient architecture for matrix multiplication on FPGAs
[C]//
Caffe:convolutional architecture for fast feature embedding
[C]//
Energy-efficient convnets through approximate computing
[C]//
基于 FPGA 的实时双精度浮点矩阵乘法器设计
[J].
Design of field programmable gate array based real-time double-precision floating-point matrix multiplier
[J].
Learning both weights and connections for efficient neural network
[C]//
Deep compression:compressing deep neural networks with pruning,trained quantization and huffman coding
[J].
Going deeper with embedded FPGA platform for convolutional neural network
[C]//
Dynamic routing between capsules
[C]//
EIE:efficient inference engine on compressed deep neural network
[J].
Compressing neural networks with the hashing trick
[C]//
Optimizing loop operation and dataflow in FPGA acceleration of deep convolutional neural networks
[C]//
A multistage dataflow implementation of a deep convolutional neural network based on FPGA for high-speed object recognition
[C]//
Throughput-optimized openCL-based FPGA accelerator for large-scale convolutional neural networks
[C]//
Exploring heterogeneous algorithms for accelerating deep convolutional neural networks on FPGAs
[C]//
Efficient designs of multi-ported memory on FPGA
[J].
The research of peer-to-peer network security
[C]//

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}