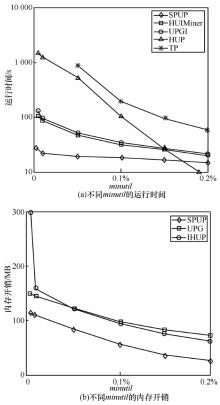
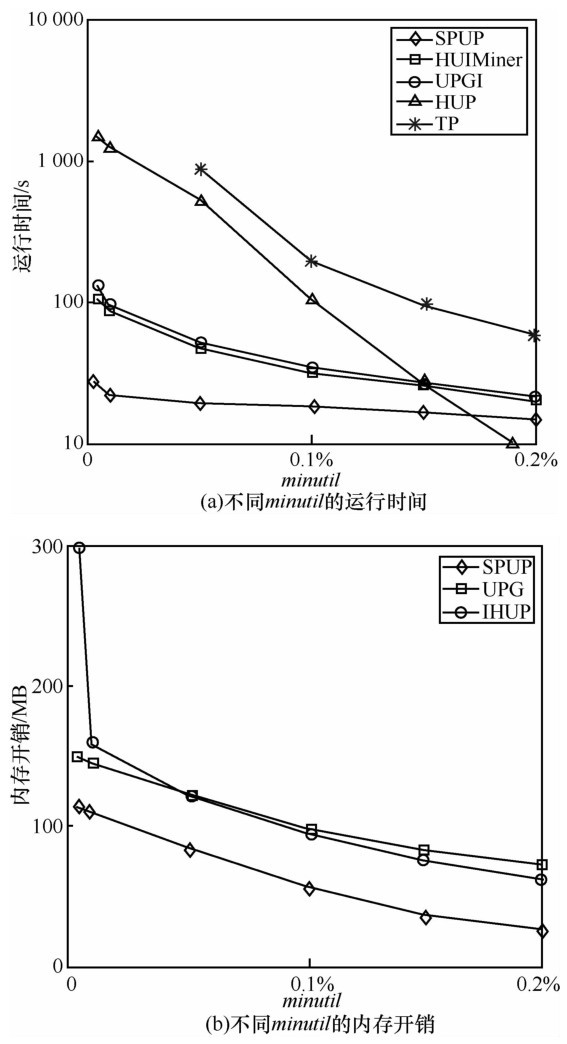
| 1 |
Ahmed C F , Tanbeer S K , Jeong B S , et al. Efficient tree structures for high utility pattern mining in incremental databases. IEEE Transactions on Knowledge and Data Engineering, 2009,21(12): 1708~1721
|
| 2 |
Erwin A , Gopalan R P , Achuthan N R . Efficient mining of high utility itemsets from large datasets. Proceedings of PAKDD, Osaka,Japan, 2008
|
| 3 |
Li Y C , Yeh J S , Chang C C . Isolated items discarding strategy for discovering high utility itemsets. Data & Knowledge Engineering, 2008,64(1): 98~217
|
| 4 |
Liu Y , Liao W , Choudhary A . A fast high utility itemsets mining algorithm. Proceedings of the Utility-Based Data Mining Workshop in Conjunction With the 11th ACM SIGKDD, Chicago,Illinois,USA, 2005
|
| 5 |
Tseng V S , Shie B E , Wu C W , et al. Efficient algorithms for mining high utility itemsets from transactional databases. IEEE Transactions on Knowledge and Data Engineering, 2013,25(8): 1772~1786
|
| 6 |
Yen S J , Lee Y S . Mining high utility quantitative association rules. Proceeding of the 9th International Conference on Data Warehousing and Knowledge Discovery, Regensburg,Germany, 2007
|
| 7 |
Yao H , Hamilton H J , Geng L . A unified framework for utility-based measures for mining itemsets. Proceedings of ACM SIGKDD the 2nd Workshop on Utility-Based Data Mining, Philadelphia,PA,USA, 2006
|
| 8 |
Agrawal R , Srikant R , Geng L . Fast algorithms for mining association rules. Proceedings of the 20th International Conference on Very Large Databases, Santiago,Chile, 1994
|
| 9 |
Han J , Pei J , Yin Y . Mining frequent patterns without candidate generation. Proceedings of ACM SIGMOD conference, Santiago,Chile, 1994
|
| 10 |
Liu J , Pan Y . An efficient algorithm for mining closed itemsets. Journal of Zhejiang University Science, 2004,5(1): 8~15
|
| 11 |
Liu J , Pei Y , Wang K , et al. Mining frequent item sets by opportunistic projection.Proceedings of SIGKDD. Proceedings of SIGKDD, Edmonton,Canada, 2002
|
| 12 |
Shie B E , Cheng J H , Chuang K T , et al. A one-phase method for mining high utility mobile sequential patterns in mobile commerce environments. Proceedings of IEA/AIE12, Dalian,China, 2012
|
| 13 |
Wu C W , Lin Y F , Yu P S , et al. Mining high utility episodes in complex event sequences. Proceedings of the 19th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Chicago Illinois,USA, 2013
|
| 14 |
Wu C W , Shie B E , Tseng V S , et al. Mining top-K high utility itemsets. Proceedings of SIG KDD, Beijing,China, 2012
|
| 15 |
Liu M , Qu J . et al. Mining high utility itemsets without candidate generation. Proceedings of CIKM, Proceedings of CIKM, 2012
|