| [1] |
DAVIS K H , BIDDULPH R , BALASHEK S . Automatic recognition of spoken digits[J]. Journal of the Acoustical Society of America, 1952,24(6): 637.
|
| [2] |
FERGUSON J D . Application of hidden Markov models to text and speech[EB]. 1980.
|
| [3] |
RABINER L R . A tutorial on hidden Markov models and selected applications in speech recognition[J]. Readings in Speech Recognition, 1990,77(2): 267-296.
|
| [4] |
LEEE K F L M . An overview of the SPHINX speech recognition system[J]. IEEE Transactions on Acoustics Speech & Signal Processing Speech, 1990,38(1): 35-45.
|
| [5] |
WAIBEL A , HANAZAWA T , HINTON G . Phoneme recognition using time-delay neural networks[J]. IEEE Transactions on Acoustics,Speech,and Signal Processing, 1990,1(2): 393-404.
|
| [6] |
YOUNG S , EVERMANN G , GALES M ,et al. The HTK book[EB]. 2005.
|
| [7] |
HINTON G E , OSINDERO S , TEH Y W . A fast learning algorithm for deep belief nets[J]. Neural Computation, 2006,18(7): 1527-1554.
|
| [8] |
MOHAMED A R , DAHL G , HINTON G . Deep belief networks for phone recognition[EB]. 2009.
|
| [9] |
YU D , DENG L . Deep learning and its applications to signal and information processing[J]. IEEE Signal Processing Magazine, 2011,28(1): 145-154.
|
| [10] |
DENG L , . An overview of deep-structured learning for information processing[C]// Asian-Pacific Signal and Information Processing-Annual Summit and Conference (APSIPA-ASC),October 18,2011, Xi’an,China.[S.l.:s.n] 2011.
|
| [11] |
BENGIO Y . Learning deep architectures for AI[J]. Foundations and Trends? in Machine Learning, 2009,2(1): 1-127.
|
| [12] |
HINTON G E . Training products of experts by minimizing contrastive divergence[J]. Neural Computation, 2002,14(8): 1771-1800.
|
| [13] |
BAKER J , DENG L , GLASS J ,et al. Developments and directions in speech recognition and understanding[J]. IEEE Signal Processing Magazine, 2009,26(3): 75-80.
|
| [14] |
MOHAMED A R , DAHL G , HINTON G . Deep belief networks for phone recognition[EB]. 2009.
|
| [15] |
SAINATH T N , KINGSBURY B , RAMABHADRAN B ,et al. Making deep belief networks effective for large vocabulary continuous speech recognition[EB]. 2011.
|
| [16] |
MOHAMED A , DAHL G E , HINTON G . Acoustic modeling using deep belief networks[J]. IEEE Transactions on Audio,Speech,and Language Processing, 2012,20(1): 14-22.
|
| [17] |
DAHL G E , YU D , DENG L ,et al. Context-dependent pre-trained deep neural networks for large vocabulary speech recognition[J]. IEEE Transactions on Audio,Speech,and Language Processing, 2012,20(1): 30-42.
|
| [18] |
HINTON G , DENG L , YU D ,et al. Deep neural networks for acoustic modeling in speech recognition:the shared views of four research groups[J]. IEEE Signal Processing Magazine, 2012,29(6): 82-97.
|
| [19] |
HOCHREITER S , SCHMIDHUBER J . Long short-term memory[J]. Neural Computation, 1997,9(8): 1735-1780.
|
| [20] |
ZHANG Y , CHEN G G , YU D ,et al. Highway long short-term memory RNNS for distant speech recognition[C]// 2016 IEEE International Conference on Acoustics,Speech and Signal Processing,March 20-25,2016,Shanghai,China. Piscataway:IEEE Press, 2016.
|
| [21] |
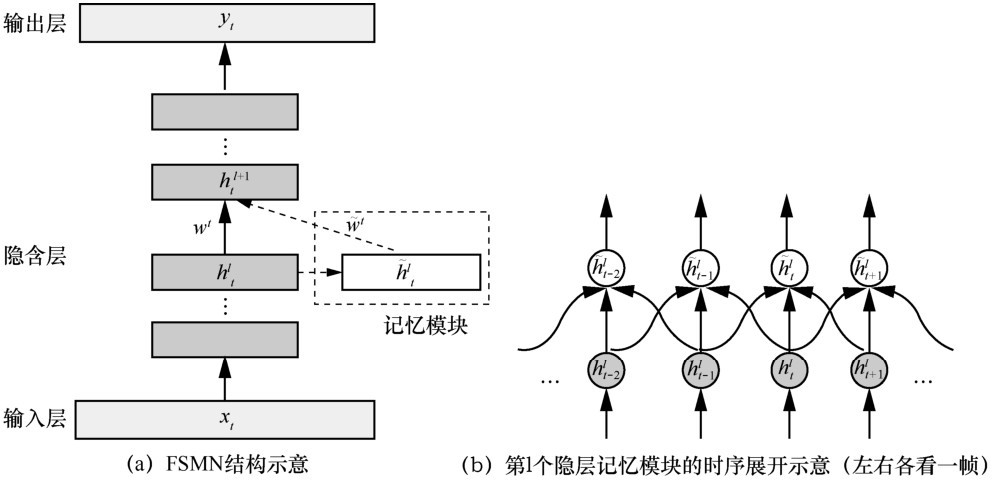
ZHANG S L , LIU C , JIANG H ,et al. Feedforward sequential memory networks:a new structure to learn long-term dependency[J]. arXiv:1512.08301, 2015.
|
| [22] |
LECUN Y , BENGIO Y . Convolutional networks for images,speech and time-series[M]. Cambridge: MIT Press, 1995.
|
| [23] |
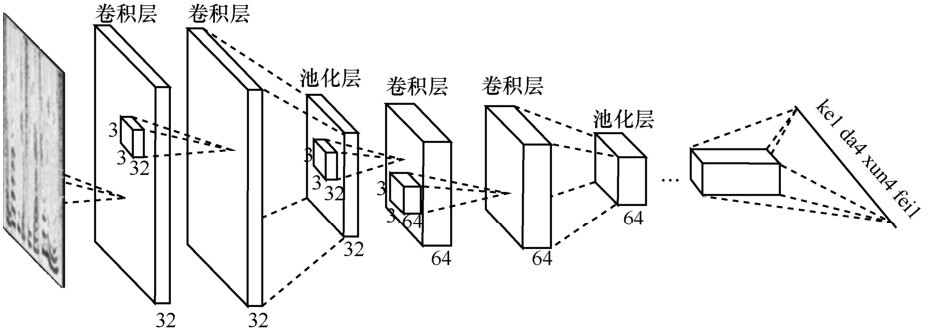
ABDEL-HAMID O , MOHAMED A R , JIANG H ,et al. Applying convolutional neural networks concepts to hybrid NN-HMM model for speech recognition[C]// 2012 IEEE International Conference on Acoustics,Speech and Signal Processing,March 20,2012,Kyoto,Japan. Piscataway:IEEE Press, 2012: 4277-4280.
|
| [24] |
ABDEL-HAMID O , MOHAMED A R , JIANG H ,et al. Convolutional neural networks for speech recognition[J]. IEEE/ACM Transactions on Audio Speech & Language Processing, 2014,22(10): 1533-1545.
|
| [25] |
ABDEL-HAMID O , DENG L , YU D . Exploring convolutional neural network structures and optimization techniques for speech recognition[EB]. 2013.
|
| [26] |
SAINATH T N , MOHAMED A R , KINGSBURY B ,et al. Deep convolutional neural networks for LVCSR[C]// 2013 IEEE International Conference on Acoustics,Speech and Signal Processing,May 26-30,2013,Vancouver,BC,Canada. Piscataway:IEEE Press, 2013: 8614-8618.
|
| [27] |
SAINATH T N , VINYALS O , SENIOR A ,et al. Convolutional,long short-term memory,fully connected deep neural networks[C]// 2015 IEEE International Conference on Acoustics,Speech and Signal Processing,April 19-24,Brisbane,QLD,Australia. Piscataway:IEEE Press, 2015: 4580-4584.
|
| [28] |
SEIDE F , LI G , YU D . Conversational speech transcription using context- dependent deep neural networks[C]// International Conference on Machine Learning,June 28-July 2,2011,Bellevue, Washington,USA.[S.l.:s.n] 2011: 437-440.
|
| [29] |
DAHL G E , YU D , DENG L ,et al. Large vocabulary continuous speech recognition with context-dependent DBNHMMs[C]// ICASSP,May 22-27,2011,Prague, Czech Republic.[S.l.:s.n] 2011: 4688-4691.
|
| [30] |
YU D , SEIDE F , LI G ,et al. Exploiting sparseness in deep neural networks for large vocabulary speech recognition[C]// ICASSP,March 25-30,2012, Kyoto,Japan.[S.l.:s.n] 2012: 4409-4412.
|
| [31] |
SAINATH T N , KINGSBURY B , SINDHWANI V ,et al. Low-rank matrix factorization for deep neural network training with high-dimensional output targets[C]// ICASSP,May 26-31,2013,Vancouver, BC,Canada,.[S.l.:s.n] 2013: 6655-6659.
|
| [32] |
KONTáR S , . Parallel training of neural networks for speech recognition[C]// 13th International Conference on Text,Speech and Dialogue,September 6-10,2010,Brno,Czech Republic. New York:ACM Press, 2006: 6-10.
|
| [33] |
VESELY K , BURGET L , GRéZL F . Parallel training of neural networks for speech recognition[C]// 13th International Conference on Text,Speech and Dialogue,September 6-10,2010,Brno,Czech Republic. New York:ACM Press, 2006: 439-446.
|
| [34] |
PARK J , DIEHL F , GALES M J F ,et al. Efficient generation and use of MLP features for Arabic speech recognition[C]// Interspeech,Conference of the International Speech Communication Association,September 6-10,2009, Brighton,UK.[S.l.:s.n] 2009: 236-239.
|
| [35] |
LE Q V , RANZATO M A , MONGA R ,et al. Building high-level features using large scale unsupervised learning[J]. arXiv preprint arXiv:1112.6209, 2011.
|
| [36] |
ZHANG S , ZHANG C , YOU Z ,et al. Asynchronous stochastic gradient descent for DNN training[C]// IEEE International Conference on Acoustics,June 27-July 2,2013,Santa Clara Marriott,CA,USA. Piscataway:IEEE Press, 2013: 6660-6663.
|
| [37] |
CHEN X , EVERSOLE A , LI G ,et al. Pipelined back-propagation for context-dependent deep neural networks[C]// 13th Annual Conference of the International Speech Communication Association,September 9-13,2012,Portland, OR,USA.[S.l:s.n] 2012: 429-433.
|
| [38] |
ZHOU P , LIU C , LIU Q ,et al. A cluster-based multiple deep neural networks method for large vocabulary continuous speech recognition[C]// ICASSP,May 26-31,2013,Vancouver, BC,Canada.[S.l.:s.n] 2013: 6650-6654.
|
| [39] |
JELINEK F . The development of an experimental discrete dictation recognizer[J]. Readings in Speech Recognition, 1990,73(11): 1616-1624.
|
| [40] |
BENGIO Y , DUCHARME R , VINCENT P . A neural probabilistic language model[J]. Journal of Machine Learning Research, 2003(3): 1137-1155.
|
| [41] |
SCHWENK H , GAUVAIN J L . Training neural network language models on very large corpora[C]// Conference on Human Language Technology & Empirical Methods in Natural Language Processing,October 6-8,2005,Vancouver,BC,Canada. New York:ACM Press, 2005: 201-208.
|
| [42] |
AR?SOY E , SAINATH T N , KINGSBURY B ,et al. Deep neural network language models[C]// NAACL-HLT 2012 Workshop,June 8,2012,Montreal,Canada. New York:ACM Press, 2012: 20-28.
|
| [43] |
MIKOLOV T , KARAFIAT M , BURGET L ,et al. Recurrent neural network based language model[C]// 11th Annual Conference of the International Speech Communication Association,September 26-30,2010,Makuhari, Chiba,Japan.[S.l.:s.n] 2010: 1045-1048.
|
| [44] |
CHEN X , WANG Y , LIU X ,et al. Efficient GPU-based training of recurrent neural network language models using spliced sentence bunch[EB]. 2014.
|
| [45] |
MIKOLOV T , KOMBRINK S , BURGET L ,et al. Extensions of recurrent neural network language model[C]// IEEE International Conference on Acoustics,May 22-27,2011,Prague,Czech Republic. Piscataway:IEEE Press, 2011: 5528-5531.
|
| [46] |
SUNDERMEYER M , SCHLUTER R , NEY H . LSTM neural networks for language modeling[EB]. 2012.
|
| [47] |
BENGIO Y , SIMARD P , FRASCONI P . Learning long term dependencies with gradient descent is difficult[J]. IEEE Transactions on Neural Networks, 1994,5(2): 157.
|
| [48] |
SAK H , SENIOR A , RAO K . Learning acoustic frame labeling for speech recognition with recurrent neural networks[C]// 2015 ICASSP,April 19-24,2015,Brisbane, QLD,Australia.[S.l.:s.n] 2015: 4280-4284.
|
| [49] |
SAK H , SENIOR A , RAO K ,et al. Fast and accurate recurrent neural network acoustic models for speech recognition[J]. arXiv:1507.06947, 2015.
|
| [50] |
SENIOR A , SAK H , QUITRY F D C ,et al. Acoustic modelling with CD-CTC-SMBR LSTM RNNS[C]// 2015 IEEE Workshop on Automatic Speech Recognition and Understanding (ASRU),December 13-17,2015,Scottsdale,AZ,USA. Piscataway:IEEE Press, 2015: 604-609.
|
| [51] |
BAHDANAU D , CHO K , BENGIO Y . Neural machine translation by jointly learning to align and translate[J]. arXiv:1409.0473, 2014.
|
| [52] |
MNIH V , HEESS N , GRAVES A ,et al. Recurrent models of visual attention[C]// 28th Annual Conference on Neural Information Processing Systems,December 8-13,2014. Montreal,Canada.[S.l.:s.n] 2014: 2204-2212.
|
| [53] |
TUSKE Z , GOLIK P , SCHLUTER R ,et al. Acoustic modeling with deep neural networks using raw time signal for LVCSR[EB]. 2014.
|
| [54] |
SAINATH T N , WEISS R J , SENIOR A W ,et al. Learning the speech front-end with raw waveform[EB]. 2015.
|