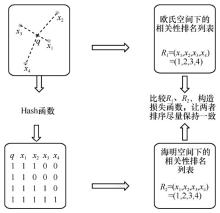
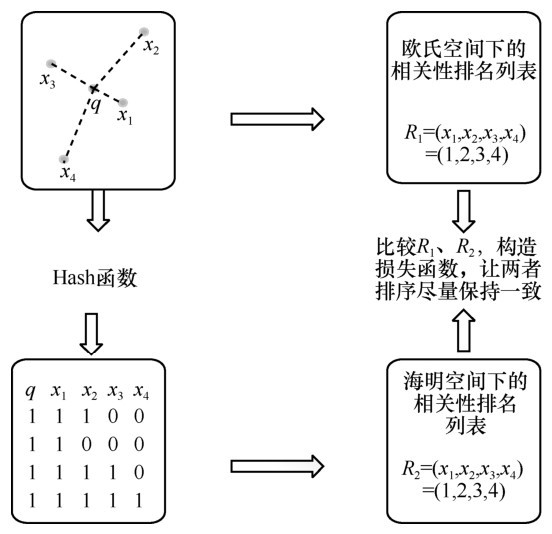
| [1] |
GUTTMAN A . R-trees:adynamic index structure for spatial searching[J]. ACM Sigmod Record, 1984,14(2): 47-57.
|
| [2] |
SONGD , LIU W , JI R . Top rank supervised binary coding for visual search[C]// 2015 IEEE International Conference on Computer Vision,Dec 13-16,2015,Sontiago,Chile. Piscataway:IEEE Press, 2015.
|
| [3] |
PARK Y , CAFARELLA M , MOZAFARI B . Neighbor-sensitive Hashing[M]. New York: ACM PressPress, 2016.
|
| [4] |
WANG J , ZHANG T , SONG J ,et al. A survey on learning to hash[J]. IEEE Transaction on Pattern Analysis and Machine Intelligence, 2016(99):1.
|
| [5] |
DATAR M , IMMORLICA N , INDYK P ,et al. Locality-sensitive hashing scheme based on p-stable distributions[C]// Twentieth Symposium on Computational Gemetry,Jun 8-11,2004,New York,USA. New York:ACM Press, 2004:253.
|
| [6] |
WEISS Y , TORRALBA A , FERGUS R . Spectral Hashing[C]// Neural Information Processing System,Dec 8-11,2008,British Columbia,Canada. New York:ACM Press, 2008.
|
| [7] |
ZHANGD , WANG J , CAI D ,et al. Self-taught hashing for fast similarity search[C]// 33rd International ACM SIGIR Conference on Research and Development in Information Retrieval,July 19-23,2010,IGO,Geneva Switzerland. New York:ACM Press, 2010.
|
| [8] |
GONG Y , LAZEBINK S , GORDO A ,et al. Iterative quantization:a procrustean approach to learning binary codes for large-scale image retrieval[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2013,135(12): 2916-2919.
|
| [9] |
LIN R S , ROSS D A , YAGNIK J . Spec hashing:similarity preserving algorithm for entropy-based coding[C]// Computer Vision and Pattern Recognition,Jun 13-18,2010,San Francisco,CA,USA.[S.l.:sn]. 2010.
|
| [10] |
NOROUZI M E , FLEETD J . Minimal loss hashing for compact binary codes[C]// The 28th International Conference on Machine Learning,June 28-July 2,2011,Washington,USA. Piscataway:IEEE Press, 2011.
|
| [11] |
CHANG S F , JIANG Y G , JI R ,et al. Supervised hashing with kernels[C]// Computer Vision and Pattern Recognition,June 16-21,2012,Providence,RI,USA. Piscataway:IEEE Press, 2012.
|
| [12] |
SHEN F , SHEN C , LIU W . Supervised discrete hashing[C]// Computer Vision and Pattern Recognition,June 8-10,2015,Boston,USA. Piscataway:IEEE Press, 2015.
|
| [13] |
STRECHA C , BRONSTEIN A , BRONSTEIN M ,et al. LDAHash:improved matching with smaller descriptors[J]. IEEE Transactions actions on Pattern Analysis and Machine Intelligence, 2011,34(1): 66-78.
|
| [14] |
WANG J , KUMA R S , CHANG S F . Semi-supervised hashing for large-scale search[J]. IEEE Transactions on Pattern Analysis Machine Intelligence, 2012,34(12): 2393-2406.
|
| [15] |
LIN G , SHEN C , WU J . Optimizing ranking measures for compact binary code learning[Z]. 2014.
|
| [16] |
SONG D , LIU W , MEYER D ,et al. Rank preserving hashing for rapid image search[C]// 2015 Data Compression Conference,April 7-9,2015,Snowbird,UT,USA. Piscataway:IEEE Press, 2015.
|
| [17] |
JIANG Y , WANG J , XUE X . Query-adaptive image search with hash codes[J]. IEEE Transactions on Multimedia, 2013,15(2): 442-453.
|
| [18] |
SHUM H Y , . QsRank:query-sensitive hash code ranking for efficient ε-nighbor search[C]// IEEE Conference on and Pattern Recognition,June 16-21,2012,Providence,RI,USA. Piscataway:IEEE Press, 2012.
|
| [19] |
JI T , LIU X , DENG C ,et al. Query-adaptive hash code ranking for fast nearest neighbor search[C]// ACM International Conference on Multimedia,Dec 3-7,2014,Orlando,FL,USA. New York:ACM Press, 2014.
|
| [20] |
LI X , LIN G , SHEN C ,et al. Learning hash functions using column generation[J]. Computer Science, 2013: 142-150.
|
| [21] |
NOROUZI M , FLEET D J , SALAKHUTDINOV R . Hamming distance metric learning[C]// International Conference on Neural Information Processing System,Dec 3-6,2012,Lake Tahoe,Nevada. New York:ACM Press, 2012: 1061-1069.
|
| [22] |
WANG J , LIU W , SUN A X ,et al. Learning hash codes with listwise supervision[C]// The 2013 IEEE International Conference on Computer Vision,Dec 1-8,2013,Sydney,Australia. Piscataway:IEEE Press, 2013: 3032-3039.
|
| [23] |
WANG Q , ZHANG Z , SI L . Ranking preserving hashing for fast similiarity search[C]// IJCAI,July 25-31,2015,Buenos Aires,Argentina.[S.l.:s. n], 2015.
|
| [24] |
YAO T , LONG F , MEI T ,et al. Deep semantic preserving and ranking-based hashing for image retrieval[C]// IJCAI,July 9-15,2016,New York,USA.[S.l.:sn]. 2016.
|
| [25] |
LIU L , SHAO L , SHEN F ,et al. Discretely coding semantic rank orders for supervised image hashing[C]// 2017 IEEE Conference on Computer Vision and Pattern Recognition,July 21-26,2017,Honolulu,HI,USA. Piscataway:IEEE Press, 2017.
|

 ),董一鸿,陈华辉
),董一鸿,陈华辉