

电信科学 ›› 2019, Vol. 35 ›› Issue (12): 99-111.doi: 10.11959/j.issn.1000-0801.2019286
赵朵朵1,章坚武1( ),郭春生1,周迪2,穆罕默德·阿卜杜·沙拉夫·哈基米1
),郭春生1,周迪2,穆罕默德·阿卜杜·沙拉夫·哈基米1
修回日期:2019-12-10
出版日期:2019-12-20
发布日期:2020-01-15
作者简介:赵朵朵(1995- ),女,杭州电子科技大学通信工程学院硕士生,主要研究方向为图像处理与人工智能等|章坚武(1961- ),男 ,博士,杭州电子科技大学通信工程学院教授、博士生导师,中国电子学会、中国通信学会高级会员,浙江省通信学会常务理事,主要研究方向为移动通信、多媒体信号处理与人工智能、通信网络与信息安全。|郭春生(1971- ),男,博士,杭州电子科技大学通信工程学院副教授、硕士生导师,主要研究方向为视频分析与模式识别。|周迪(1975- ),男 ,浙江宇视科技有限公司高级工程师、宇视研究院院长,主要研究方向为视频安全、人工智能等。|穆罕默德·阿卜杜·沙拉夫·哈基米(1991- ),男,杭州电子科技大学博士生,主要研究方向为图像处理与人工智能。
基金资助:
Duoduo ZHAO1,Jianwu ZHANG1(),Chunsheng GUO1,Di ZHOU2,ABDUSHARAFALHAKIMI MOHAMMED1
Revised:2019-12-10
Online:2019-12-20
Published:2020-01-15
Supported by:摘要:
近年来,自动学习特征的深度学习方法在视频行为识别领域中不断被挖掘探索。在总结了常用的行为识别数据集的基础上,对传统的行为识别方法以及深度学习的相关基础原理进行了概述,着重对基于不同输入内容与不同深度网络的行为识别方法进行了较为全面、系统性的总结、对比与分析。最后,对深度学习在行为识别领域的发展做了总结并展望了未来的发展趋势。
中图分类号:
赵朵朵,章坚武,郭春生,周迪,穆罕默德·阿卜杜·沙拉夫·哈基米. 基于深度学习的视频行为识别方法综述[J]. 电信科学, 2019, 35(12): 99-111.
Duoduo ZHAO,Jianwu ZHANG,Chunsheng GUO,Di ZHOU,ABDUSHARAFALHAKIMI MOHAMMED. A survey of video behavior recognition based on deep learning[J]. Telecommunications Science, 2019, 35(12): 99-111.
表1
数据集汇总"
| 名称(年份) | 简介 | 视频样本数 | 目前最高识别率 |
| KTH[ | 由25人完成的6类动作:挥手、步行、慢跑、跑步、拍手和拳击。有4个不同场景 | 2 391 | 98.83%[ |
| Weizmann[ | 包含9人完成的10个动作:走、跑、跳、挥手和弯腰等 | 93 | 100%[ |
| Hollywood 2[ | 含10类场景下的12种行为类别:打架、开车、握手、拥抱、亲吻等。样本均来自69部Hollywood电影 | 3 669 | 78.6%[ |
| Olympic sports[ | 含16种运动动作,有跳高、跳远等 | 783 | 96.6%[ |
| HMDB51[ | 含51个类别,一个类别至少含101段视频样本。样本来源于公共数据库、电影和YouTube等 | 6 849 | 82.1%[ |
| UCF Datasets (2007年- ) | (1)UCF-11(2008)[ | 1 600 | 94.5%[ |
| (2)UCF-50[ | 6 676 | 99.98%[ | |
| (3)UCF-101[ | 13 320 | 98.0%[ | |
| (4)UCF Sports[ | 150 | 96.2%[ | |
| Sports-1M[ | 包含 487 种体育运动项目,分为六大类:水上、团队、冬季、球类、对抗、与动物等运动覆盖700种人类动作,每个动作至少包含600个视频,每一段都来自一个独特的YouTube视频。动作包括演奏乐、握手、拥抱等涉及人物、动物、物体或自然现象,捕捉了动态场景中标记了的3秒视频 | 1 133 158650 0001 000 000 | 75.9%[ |

图1
传统行为识别流程"

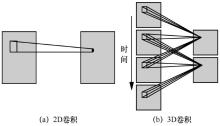
图2
2D与3D卷积对比"

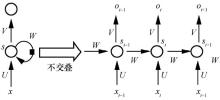
图3
循环神经网络结构"
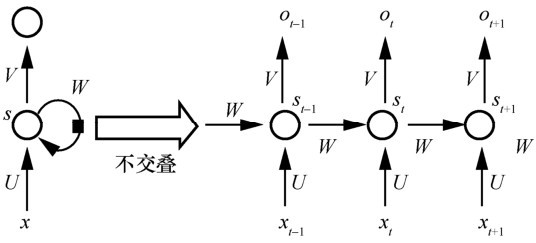

图4
基于深度学习的视频行为识别流程"
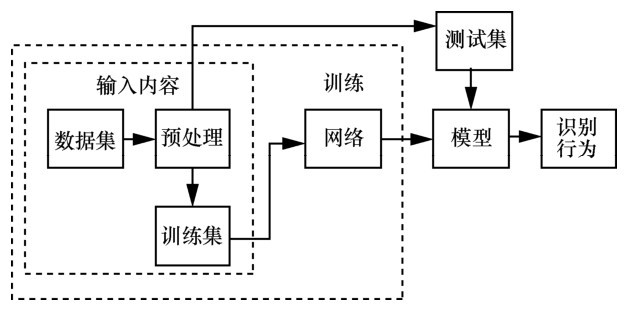

图5
结合LSTM的双流改进网络"
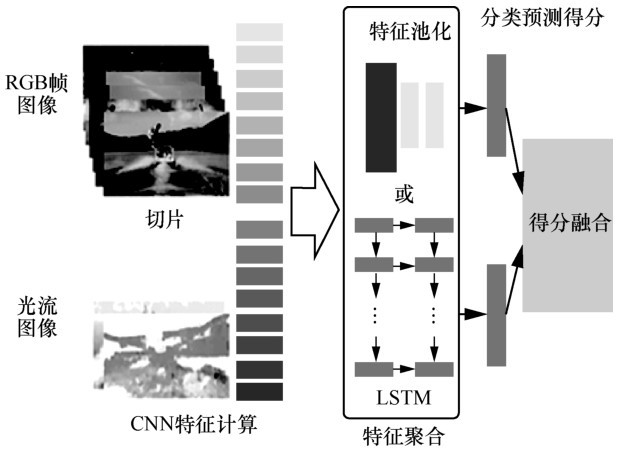
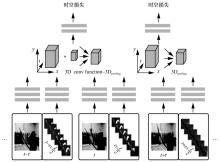
图6
双流融合网络结构"
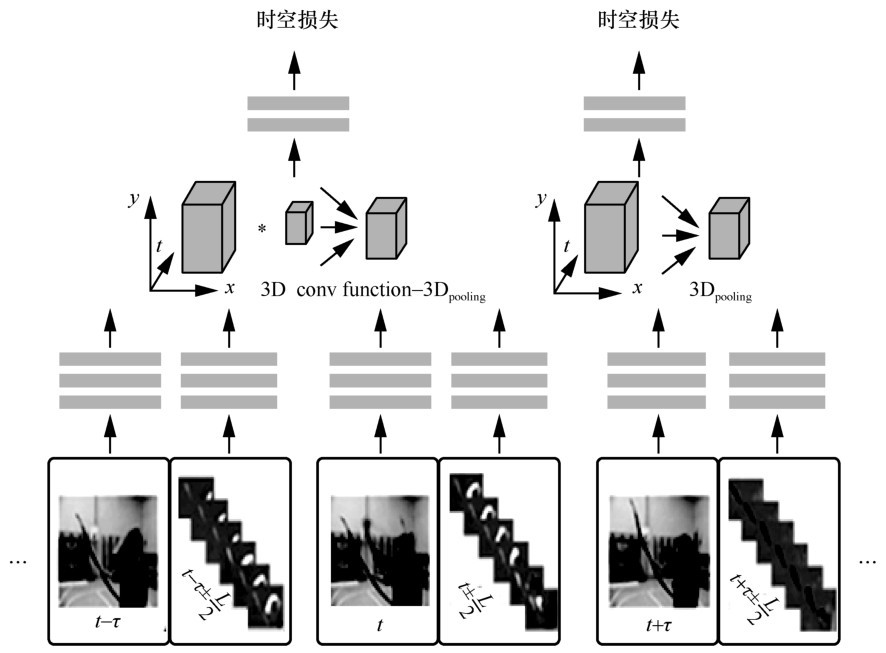
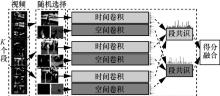
图7
TSN结构"
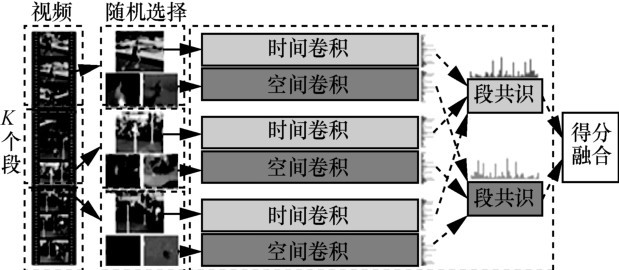
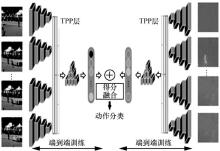
图8
DTPP网络结构"
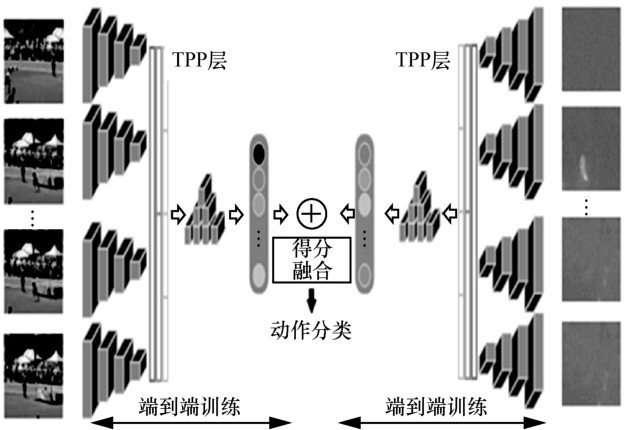
表2
双流网络及其衍生行为识别方法在UCF-101和HMDB51数据集上的性能比较"
| 参考文献 | 方法 | 预训练数据集 | UCF-101 | HMDB51 |
| Two-Stream(VGG-M) | ImageNet | 88.0 | 59.4 | |
| Two-Stream+LSTM | ImageNet | 88.6 | — | |
| Very deep Two-Stream(GoogLeNet)Very deep Two-Stream(VGG-16) | ImageNet | 89.391.4 | —58.5 | |
| Two -Stream fusion(VGG-16)Two-Stream fusion(VGG-16)+ IDT | ImageNet | 92.593.5 | 65.469.2 | |
| ST-ResNet*ST-ResNet*+IDT | ImageNet | 93.494.6 | 66.470.3 | |
| ST-Pyramid Network(VGG-16) | 93.2 | 66.1 | ||
| ST-Pyramid Network(ResNet-50) | ImageNet | 93.8 | 66.5 | |
| ST-Pyramid Network( BN-Inception) | 94.6 | 68.9 | ||
| ST-MultiplierST-Multiplier+IDT | ImageNet | 94.294.9 | 68.972.2 | |
| TLE:FC-Pooling | 92.2 | 68.8 | ||
| TLE:Bilinear+TS | ImageNet | 95.1 | 70.6 | |
| TLE:Bilinear | 95.6 | 71.1 | ||
| TSNTSN(Inception v3) | ImageNet | 94.296.2 | 69.475.3 | |
| Hidden Two-Stream (TSN)Hidden Two-Stream ( I3D) | Kinetics | 93.297.1 | 66.878.7 |
表3
C3D卷积网络及其衍生行为识别方法在UCF-101和HMDB51数据集上的性能比较"
| 参考文献 | 方法 | 预训练数据集 | UCF-101 | HMDB51 |
| FstCN | ImageNet | 88.1 | 59.1 | |
| C3D one network | Sports-1M | 82.3 | — | |
| C3D ensemble | 85.2 | — | ||
| C3D ensemble + IDT | 90.1 | — | ||
| C3D+LSTM | — | 92.9 | 70.1 | |
| T3D | ImageNet | 90.3 | 59.2 | |
| T3D-Transfer | 91.7 | 61.1 | ||
| T3D+TSN | 93.2 | 63.5 | ||
| STRN | ImageNet | 93.2 | 64.9 | |
| P3D ResNet | ImageNet+Sports-1M | 88.6 | ||
| P3D ResNet+IDT | 93.7 | |||
| Multi-task C3D+LSTM | Sports-1M | 93.4 | 68.9 | |
| R(2+1)D-RGB | Sports-1M | 93.6 | 66.6 | |
| R(2+1)D-Flow | 93.3 | 70.1 | ||
| R(2+1)D-Two-Stream | 95.0 | 72.7 | ||
| R(2+1)D-RGB | Kinetics | 96.8 | 74.5 | |
| R(2+1)D-Flo w | 95.5 | 76.4 | ||
| R(2+1)D-Two-Stream | 97.3 | 78.7 | ||
| RGB-I3D | ImageNet+Kinetics | 95.6 | 74.8 | |
| Flow-I3D | 96.7 | 77.1 | ||
| Two-Stream I3D | 98.0 | 80.7 | ||
| RGB-I3D | Kinetics | 95.1 | 74.3 | |
| Flow-I3D | 96.5 | 77.3 | ||
| Two-Stream I3D | 97.8 | 80.9 |
表4
其他优秀网络行为识别方法在UCF-101和HMDB51数据集上的性能比较"
| 参考文献 | 方法 | 预训练数据集 | UCF-101 | HMDB51 |
| TDD | ImageNet | 90.3 | 63.2 | |
| TDD+IDT | 91.5 | 65.9 | ||
| LTC | Sports-1M | 91.7 | 64.8 | |
| LTC+IDT | 92.7 | 67.2 | ||
| Key -volume mining deep framework | ImageNet | 93.1 | 63.3 | |
| AdaScan | ImageNet | 89.4 | 54.9 | |
| AdaScan+iDT | 91.3 | 61.0 | ||
| AdaScan+ iDT+C3D | 93.2 | 66.9 | ||
| RNN-FV(C3D+VGG-CCA) | — | 54.33 | 88.01 | |
| RNN-FV(C3D+VGG-CCA) +IDT | — | 94.08 | 67.71 | |
| DOVF | ImageNet | 94.9 | 71.7 | |
| DOVF + MIFS | 95.3 | 75.0 | ||
| TVNet | — | 94.35 | 71.0 | |
| TVNet+IDT | 95.4 | 72.6 | ||
| Four-Stream | ImageNet | 95.5 | 72.5 | |
| Four-Stream + IDT | 96.0 | 74.9 | ||
| DTPP | ImageNet | 95.8 | 74.8 | |
| DTPP + MIFS | 96.1 | 76.3 | ||
| DTPP + IDT | 96.2 | 75.3 | ||
| DTPP | Kinetics | 98.0 | 82.1 |
| [1] | SCHULDT C , LAPTEV I , CAPUTO B . Recognizing human actions:a local SVM approach[C]// 17th International Conference on Pattern Recognition(ICPR),Aug 23-26,2004,Cambridge,UK. Piscataway:IEEE Press, 2004: 32-36. |
| [2] | BLANK M , GORELICK L , SHECHTMAN E ,et al. Actions as space-time shapes[C]// 10th IEEE International Conference on Computer Vision(ICCV),Oct 17-21,2005,Beijing,China. Piscataway:IEEE Press, 2005: 1395-1402. |
| [3] | GORELICK L , BLANK M , SHECHTMAN E ,et al. Actions as space-time shapes[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2007,29(12): 2247-2253. |
| [4] | MARSZALEK M , LAPTEV I , SCHMID C . Actions in context[C]// 22nd IEEE Conference on Computer Vision and Pattern Recognition(CVPR),Jun 20-25,2009,Florida,USA. Piscataway:IEEE Press, 2009: 2929-2936. |
| [5] | NIEBLES J C , CHEN C W , LI F F . Modeling temporal structure of decomposable motion segments for activity classification[C]// 11th European Conference on Computer Vision (ECCV),Sep 5-11,2010,Heraklion,Crete,Greece. Berlin:Springer Verlag, 2010: 392-405. |
| [6] | KUEHNE H , JHUANG H , GARROTE E ,et al. HMDB:a large video database for human motion recognition[C]// 16th IEEE International Conference on Computer Vision(ICCV),Nov 6-13,2011,Barcelona,Spain. Piscataway:IEEE Press, 2011: 2556-2563. |
| [7] | LIU J G , LUO J B , SHAH M . Recognizing realistic actions from videos[C]// 22nd IEEE Conference on Computer Vision and Pattern Recognition(CVPR),Jun 20-25,2009,Florida,USA. Piscataway:IEEE Press, 2009: 1996-2003. |
| [8] | REDDY K K , SHAH M . Recognizing 50 human action categories of Web videos[J]. Machine Vision and Applications, 2013,24(5): 971-981. |
| [9] | SOOMRO K , ZAMIR A R , SHAH M . UCF101:a dataset of 101 human actions classes from videos in the wild[J]. Computer Science, 2012: 1-7. |
| [10] | RODRIGUEZ M D , AHMED J , SHAH M . Action match a spatio-temporal maximum average correlation height filter for action recognition[C]// 21st IEEE Conference on Computer Vision and Pattern Recognition(CVPR),Jun 24-26,2008,Anchorage,Alaska,USA. Piscataway:IEEE Press, 2008: 1-8. |
| [11] | KARPATHY A , TODERICI G , SHETTY S ,et al. Large-scale video classification with convolutional neural networks[C]// 27th IEEE Conference on Computer Vision and Pattern Recognition(CVPR),Jun 23-28,2014,Columbus,USA. Piscataway:IEEE Press, 2014: 1725-1732. |
| [12] | KAY W , CARREIRA J , SIMONYAN K ,et al. The kinetics human action video dataset[J]. arXiv:1705.06950, 2017: |
| [13] | MONFORT M , ANDONIAN A , ZHOU B ,et al. Moments in time dataset:one million videos for event understanding[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2019(3): 1-9. |
| [14] | XU W R , MIAO Z J , TIAN Y . A novel mid-level distinctive feature learning for action recognition via diffusion map[J]. Neurocomputing, 2016(218): 185-196. |
| [15] | TONG M , WANG H Y , TIAN W J ,et al. Action recognition new framework with robust 3D-TCCHOGAC and 3D-HOOFGAC[J]. Multimedia Tools and Applications, 2017,76(2): 3011-3030. |
| [16] | VISHWAKARMA D K , KAPOOR R , DHIMAN A . Unified framework for human activity recognition:an approach using spatial edge distribution and transform[J]. AEU-International Journal of Electronics and Communications, 2016,70(3): 341-353. |
| [17] | WANG Y , TRAN V , HOAI M . Evolution-preserving dense trajectory descriptors[J]. arXiv:1702.04037, 2017: |
| [18] | LI Y W , LI W X , MAHADEVAN V ,et al. VLAD3:encoding dynamics of deep features for action recognition[C]// 29th IEEE Conference on Computer Vision and Pattern Recognition(CVPR),Jun 27-30,2016,Las Vegas,USA. Piscataway:IEEE Press, 2016: 1951-1960. |
| [19] | ZHU J , ZOU W , ZHU Z . End-to-end video-level representation learning for action recognition[C]// 24th International Conference on Pattern Recognition(ICPR),Aug 20-24,2018,Beijing,China. Piscataway:IEEE Press, 2018: 645-650. |
| [20] | SUN Q , LIU H , MA L ,et al. A novel hierarchical bag-of-words model for compact action representation[J]. Neurocomputing, 2016(174): 722-732. |
| [21] | IJJINA E P , MOHAN C K . Human action recognition using genetic algorithms and convolutional neural networks[J]. Pattern Recognition, 2016(59): 199-212. |
| [22] | MAHASSENI B , TODOROVIC S . Regularizing long short term memory with 3D human-skeleton sequences for action recognition[C]// 29th IEEE Conference on Computer Vision and Pattern Recognition(CVPR),Jun 27-30,2016,Las Vegas,USA. Piscataway:IEEE Press, 2016: 3054-3062. |
| [23] | ALHARBI N , GOTOH Y . A unified spatio-temporal human body region tracking approach to action recognition[J]. Neurocomputing, 2015(161): 56-64. |
| [24] | MAHASSENI B , TODOROVIC S . Regularizing long short term memory with 3D human-skeleton sequences for action recognition[C]// 29th IEEE Conference on Computer Vision and Pattern Recognition(CVPR),Jun 27-30,2016,Las Vegas,USA. Piscataway:IEEE Press, 2016: 3054-3062. |
| [25] | ZHANG X , BAO Y , ZHANG F ,et al. Qiniu submission to Activity Net challenge 2018[J].,2018. 2018 Computer Vision and Pattern Recognition Challenge,arXiv:1806.04391, 2018. |
| [26] | LI Y , XU Z , WU Q ,et al. Submission to moments in time challenge 2018[J]. 2018 Computer Vision and Pattern Recognition Challenge,a rXiv:1808.03766, 2018. |
| [28] | WANG H,KLāSER A , SCHMID C ,et al. Dense trajectories and motion boundary descriptors for action recognition[J]. International Journal of Computer Vision, 2013,103(1): 60-79. |
| [29] | WANG H , SCHMID C . Action recognition with improved trajectories[C]// 18th IEEE International Conference on Computer Vision(ICCV),Dec 1-8,2013,Sydeny,Australia. Piscataway:IEEE Press, 2013: 3551-3558. |
| [30] | LECUN Y , BOTTOU L , BENGIO Y ,et al. Gradient-based learning applied to document recognition[J]. Proceedings of the IEEE, 1998,86(11): 2278-2324. |
| [31] | KRIZHEVSKY A , SUTSKEVER I , HINTON G E . ImageNet classification with deep convolutional neural networks[C]// 25th Annual Conference on Neural Information Processing Systems,Dec 3-6,2012,Lake Tahoe,USA. Massachusetts:MIT Press, 2012: 1106-1114. |
| [32] | SIMONYAN K , ZISSERMAN A . Very deep convolutional networks for large-scale image recognition[C]// 3rd International Conference on Learning Representations(ICLR),May 7-9,2015,San Diego,USA. New York:AMC Press, 2015: 1-14. |
| [33] | HE K , ZHANG X , REN S ,et al. Deep residual learning for image recognition[C]// 29th IEEE Conference on Computer Vision and Pattern Recognition(CVPR),Jun 26-Jul 1,2016,Las Vegas,USA. Piscataway:IEEE Press, 2016: 770-778. |
| [34] | SZEGEDY C , LIU W , JIA Y ,et al. Going deeper with convolutions[C]// 28th IEEE Conference on Computer Vision and Pattern Recognition(CVPR),Jun 7-12,2015,Boston,USA. Piscataway:IEEE Press, 2015: 7-12. |
| [35] | ARIF S , WANG J , HASSAN U T ,et al. 3D-CNN-based fused feature maps with LSTM applied to action recognition[J]. Future Internet, 2019,11(2):42. |
| [36] | JI S , XU W , YANG M ,et al. 3D convolutional neural networks for human action recognition[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2013,35(1): 221-231. |
| [37] | NG Y H , HAUSKNECHT M , VIJAYANARASIMHAN S ,et al. Beyond short snippets:deep networks for video classification[C]// 28th IEEE Conference on Computer Vision and Pattern Recognition(CVPR),Jun 7-12,2015,Boston,USA. Piscataway:IEEE Press, 2015: 4694-4702. |
| [38] | LIU Z , HU H F . Spatiotemporal relation networks for video action recognition[J]. IEEE Access, 2019(7): 14969-14976. |
| [39] | BACCOUCHE M , MAMALET F , WOLF C ,et al. Sequential deep learning for human action recognition[C]// 2nd International Conference on Human Behavior Unterstanding(HBU),Nov 16-16,2011,Amsterdam,Netherlands. Berlin:Springer Verlag, 2011: 29-39. |
| [40] | DONAHUE J , HENDRICKS L A , ROHRBACH M ,et al. Long-term recurrent convolutional networks for visual recognition and description[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2014,39(4): 677-691. |
| [41] | ILG E , MAYER N , SAIKIA T ,et al. FlowNet 2.0:evolution of optical flow estimation with deep networks[C]// 30th IEEE Conference on Computer Vision and Pattern Recognition(CVPR),Jul 21-26,2017,Honolulu,USA. Piscataway:IEEE Press, 2017: 1467-1655. |
| [42] | FISCHER P , DOSOVITSKIY A , ILG E ,et al. FlowNet:learning optical flow with convolutional networks[C]// 20th IEEE International Conference on Computer Vision(ICCV),Dec 11-18,2015,Santiago,Chile. Piscataway:IEEE Press, 2015: 2758-2766. |
| [43] | YE H , WU Z , ZHAO R W ,et al. Evaluating Two-Stream CNN for Video Classification[C]// 5th ACM on International Conference on Multimedia Retrieval(ICMR),Jun 23-26,2015,Shanghai,China. New York:ACM, 2015: 435-442. |
| [44] | WU Z , WANG X , JIANG Y G ,et al. Modeling spatial-temporal clues in a hybrid deep learning framework for video classification[C]// 23rd ACM Multimedia Conference,Oct 26-30,2015,Brisbane,Australia. New York:ACM Press, 2015: 461-470. |
| [45] | WU Z , JIANG Y G , WANG X ,et al. Multi-stream multi-class fusion of deep networks for video classification[C]// 24th ACM Multimedia Conference,Oct 15-19,2016,Amsterdam,UK. New York:ACM Press, 2016: 791-800. |
| [46] | LONG X , GAN C , MELO G D ,et al. Attention clusters:Purely attention based local feature integration for video classification[C]// 31st IEEE Conference on Computer Vision and Pattern Recognition (CVPR),Jun 18-22,2018,Salt Lake,USA. Piscataway:IEEE Press, 2018: 7834-7843. |
| [47] | JIANG Y G , WU Z , TANG J ,et al. Modeling multimodal clues in a hybrid deep learning framework for video classification[J]. IEEE Transactions on Multimedia, 2018,20(11): 3137-3147. |
| [48] | SIMONYAN K , ZISSERMAN A . Two-stream convolutional networks for action recognition in videos[C]// 28th Annual Conference on Neural Information Processing Systems(NIPS),Dec 8-13,2014,Montreal,Canda. Massachusetts:MIT Press, 2014: 568-576. |
| [49] | FEICHTENHOFER , PINZ A , ZISSERMAN A . Convolutional two-stream network fusion for video action recognition[C]// 29th IEEE Conference on Computer Vision and Pattern Recognition(CVPR),Jun 27-30,2016,Las Vegas,USA. Piscataway:IEEE Press, 2016: 1933-1941. |
| [50] | WANG L , XIONG Y , WANG Z ,et al. Temporal segment networks:towards good practices for deep action recognition[C]// 14th European Conference on Computer Vision(ECCV),Oct 8-16,2016,Amsterdam,Netherlands. Berlin:Springer Verlag, 2016: 20-36. |
| [51] | LAN Z , ZHU Y , HAUPTMANN A G . Deep local video feature for action recognition[C]// 30th IEEE Conference on Computer Vision and Pattern Recognition(CVPR),Jul 21-26,2017,Honolulu,USA. Piscataway:IEEE Press, 2017: 1219-1225. |
| [52] | ZHOU B , ANDONIAN A , TORRALBA A . Temporal relational reasoning in videos[C]// 15th European Conference on Computer Vision(ECCV),Sep 8-14,2018,Munich,Germany. Berlin:Springer Verlag, 2018: 831-846. |
| [53] | DIBA A , SHARMA V , VAN GOOL L . Deep temporal linear encoding networks[C]// 30th IEEE Conference on Computer Vision and Pattern Recognition(CVPR),July 21-26,2017,Honolulu,USA. Piscataway:IEEE Press, 2017: 1541-1550. |
| [54] | TRAN D , BOURDEV L , FERGUS R ,et al. Learning spatiotemporal features with 3D convolutional networks[C]// 20th IEEE International Conference on Computer Vision(ICCV),Dec 11-18,2015,Santiago,Chile. Piscataway:IEEE Press, 2015: 4489-4497. |
| [55] | SUN L , JIA K , YEUNG D Y ,et al. Human action recognition using factorized spatio-temporal convolutional networks[C]// 20th IEEE International Conference on Computer Vision(ICCV),Dec 11-18,2015,Santiago,Chile. Piscataway:IEEE Press, 2015: 4597-4605. |
| [56] | QIU Z , YAO T , MEI T . Learning Spatio-temporal representation with pseudo-3D residual networks[C]// 22nd IEEE International Conference on Computer Vision(ICCV),Oct 22-29,2017,Venice,Italy. Piscataway:IEEE Press, 2017: 5534-5542. |
| [57] | DIBA A , FAYYAZ M , SHARMA V ,et al. Temporal 3D ConvNets:new architecture and transfer learning for video classification[J].,2017. arXiv:1711.08200, 2017. |
| [58] | CARREIRA J , ZISSERMAN A . Quo Vadis,action recognition? A new model and the kinetics dataset[C]// 30th IEEE Conference on Computer Vision and Pattern Recognition(CVPR),Jul 21-26,2017,Honolulu,USA. Piscataway:IEEE Press, 2017: 6299-6308. |
| [59] | TRAN D , WANG H , TORRESANI L ,et al. A closer look at spatiotemporal convolutions for action recognition[C]// 31st IEEE Conference on Computer Vision and Pattern Recognition(CVPR),Jun 18-22,2018,Salt Lake,USA. Piscataway:IEEE Press, 2018: 6450-6459. |
| [60] | FAN L , HUANG W , GAN C ,et al. End-to-end learning of motion representation for video understanding[C]// 31st IEEE Conference on Computer Vision and Pattern Recognition (CVPR),Jun 18-22,2018,Salt Lake,USA. Piscataway:IEEE Press, 2018: 6016-6025. |
| [61] | ZHU W , HU J , SUN G ,et al. A key volume mining deep framework for action recognition[C]// 29th IEEE Conference on Computer Vision and Pattern Recognition(CVPR),Jun 27-30,2016,Las Vegas,USA. Piscataway:IEEE Press, 2016: 1991-1999. |
| [62] | KAR A , RAI N , SIKKA K ,et al. AdaScan:adaptive scan pooling in deep convolutional neural networks for human action recognition in Videos[C]// 30th IEEE Conference on Computer Vision and Pattern Recognition(CVPR),Jul 21-26,2017,Honolulu,USA. Piscataway:IEEE Press, 2017: 5699-5708. |
| [63] | ZHU Y , LAN Z , NEWSAM S ,et al. Hidden two-stream convolutional networks for action recognition[C]// 14th Asian Conference on Computer Vision(ACCV),Dec 2-6,2018,Perth,Australia. Berlin:Springer Verlag, 2018: 363-378. |
| [64] | WANG L , XIONG Y , WANG Z ,et al. Towards good practices for very deep two-stream ConvNets[J]. Computer Science,arXiv:1507.02159, 2015. |
| [65] | FEICHTENHOFER C , PINZ A , WILDES R P . Spatiotemporal residual networks for video action recognition[C]// 30th Conference and Workshop on Neural Information Processing Systems (NIPS),Dec 5-10,2016,Barcelona,Spain.[S.l.:s.n]. 2016: 3476-3484. |
| [66] | WANG Y , LONG M , WANG J ,et al. Spatiotemporal pyramid network for video action recognition[C]// 30th IEEE Conference on Computer Vision and Pattern Recognition(CVPR),Jul 21-26,2017,Honolulu,USA. Piscataway:IEEE Press, 2017: 2097-2106. |
| [67] | FEICHTENHOFER C , PINZ A , WILDES R P . Spatiotemporal multiplier networks for video action recognition[C]// 30th IEEE Conference on Computer Vision and Pattern Recognition (CVPR),Jul 21-26,2017,Honolulu,USA. Piscataway:IEEE Press, 2017: 7445-7454. |
| [68] | OUYANG X , XU S J , ZHANG C Y ,et al. A 3D-CNN and LSTM based multi-task learning architecture for action recognition[J]. IEEE Access, 2019(7): 40757-40770. |
| [69] | WANG L , QIAO Y , TANG X . Action recognition with trajectory-pooled deep-convolutional descriptors[C]// 28th IEEE Conference on Computer Vision and Pattern Recognition(CVPR),Jun 7-12,2015,Boston,USA. Piscataway:IEEE Press, 2015: 4305-4314. |
| [70] | VAROL G , LAPTEV I , SCHMID C . Long-term temporal convolutions for action recognition[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018: 1510-1517. |
| [71] | LEV G , SADEH G , KLEIN B ,et al. RNN fisher vectors for action recognition and image annotation[C]// 14th European Conference on Computer Vision(ECCV),Oct 8-16,2016,Amsterdam,Netherlands. Berlin:Springer Verlag, 2016: 833-850. |
| [72] | BILEN H , FERNANDO B , GAVVES E ,et al. Action recognition with dynamic image networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018,40(12): 2799-2813. |
| [1] | 朱应钊, 李嫚. 元学习研究综述[J]. 电信科学, 2021, 37(1): 22-31. |
| [2] | 张旭,刘洋,胡磊,赵晓东,张海滨. 电信行业基于种子用户群扩展技术的定向营销研究与应用[J]. 电信科学, 2018, 34(1): 166-173. |
| [3] | 张德刚,吴毅,张少泉,彭庆军. 电力企业异构数据集成研究[J]. 电信科学, 2015, 31(6): 128-131. |
| [4] | 王桂玲,张峰,韩燕波. 一种基于数据服务超链进行情景数据集成的方法[J]. 电信科学, 2014, 30(2): 51-59. |
| [5] | 张瑜,潘红芳. 基于一体化平台数据中心的数据质量管理在内蒙古电力公司的应用[J]. 电信科学, 2014, 30(1): 142-147. |
| [6] | 潘俊,程建和. 电信企业通用数据服务平台的设计与实现[J]. 电信科学, 2013, 29(2): 124-128. |
| [7] | 吴舜,苏丹,吴佳,李坤,许大卫,刘昀,魏征. 基于TiIera平台的网络细粒度应用行为识别[J]. 电信科学, 2013, 29(11): 94-98. |
| [8] | 陆慧娟,张金伟,马小平,杨小兵. 基于特征选择的过抽样算法的研究[J]. 电信科学, 2012, 28(1): 87-91. |
| [9] | 陆慧娟,张金伟,张金伟,张金伟,马小平,杨小兵. 基于特征选择的过抽样算法的研究[J]. 电信科学, 2012, 28(1): 91-95. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||
|
||