

电信科学 ›› 2021, Vol. 37 ›› Issue (8): 46-56.doi: 10.11959/j.issn.1000-0801.2021198
康帅1, 章坚武1, 朱尊杰1, 童国锋2
修回日期:2021-08-13
出版日期:2021-08-20
发布日期:2021-08-01
作者简介:康帅(1996− ),女,杭州电子科技大学通信工程学院硕士生,主要研究方向为计算机视觉与人工智能等基金资助:Shuai KANG1, Jianwu ZHANG1, Zunjie ZHU1, Guofeng TONG2
Revised:2021-08-13
Online:2021-08-20
Published:2021-08-01
Supported by:摘要:
复杂视觉场景下存在过暗或者过曝的光照、恶劣的天气、严重遮挡、行人尺寸差别大以及图像模糊等问题,大大增加了行人检测的难度。因此,针对复杂视觉场景下行人检测准确度低、漏检严重的问题,提出了改进的YOLOv4算法以增强复杂视觉场景下的行人检测效果。首先,构建复杂视觉场景下的行人数据集。然后,在主干网中加入混合空洞卷积,提高网络对行人特征的提取能力。最后,提出空间锯齿空洞卷积结构,代替空间金字塔池化结构,获取更多细节特征。实验表明,在本文构建的行人数据集上,改进后的 YOLOv4算法的平均精度(average precision,AP)达到了90.08%,相比原YOLOv4算法提高了7.2%,对数平均漏检率(log-average miss rate,LAMR)降低了13.69%。
中图分类号:
康帅, 章坚武, 朱尊杰, 童国锋. 改进YOLOv4算法的复杂视觉场景行人检测方法[J]. 电信科学, 2021, 37(8): 46-56.
Shuai KANG, Jianwu ZHANG, Zunjie ZHU, Guofeng TONG. An improved YOLOv4 algorithm for pedestrian detection in complex visual scenes[J]. Telecommunications Science, 2021, 37(8): 46-56.
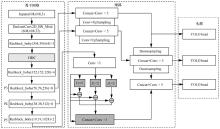
图1
改进后的YOLOv4网络结构"


图2
空洞率为2的空洞卷积"


图3
HDC模块"
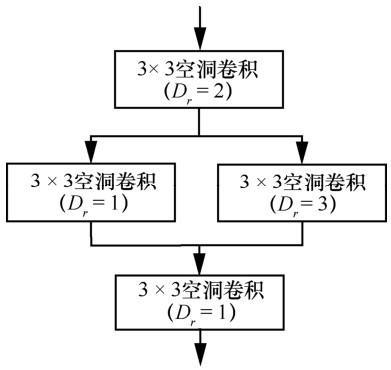
图4
引入HDC后的骨干网结构"
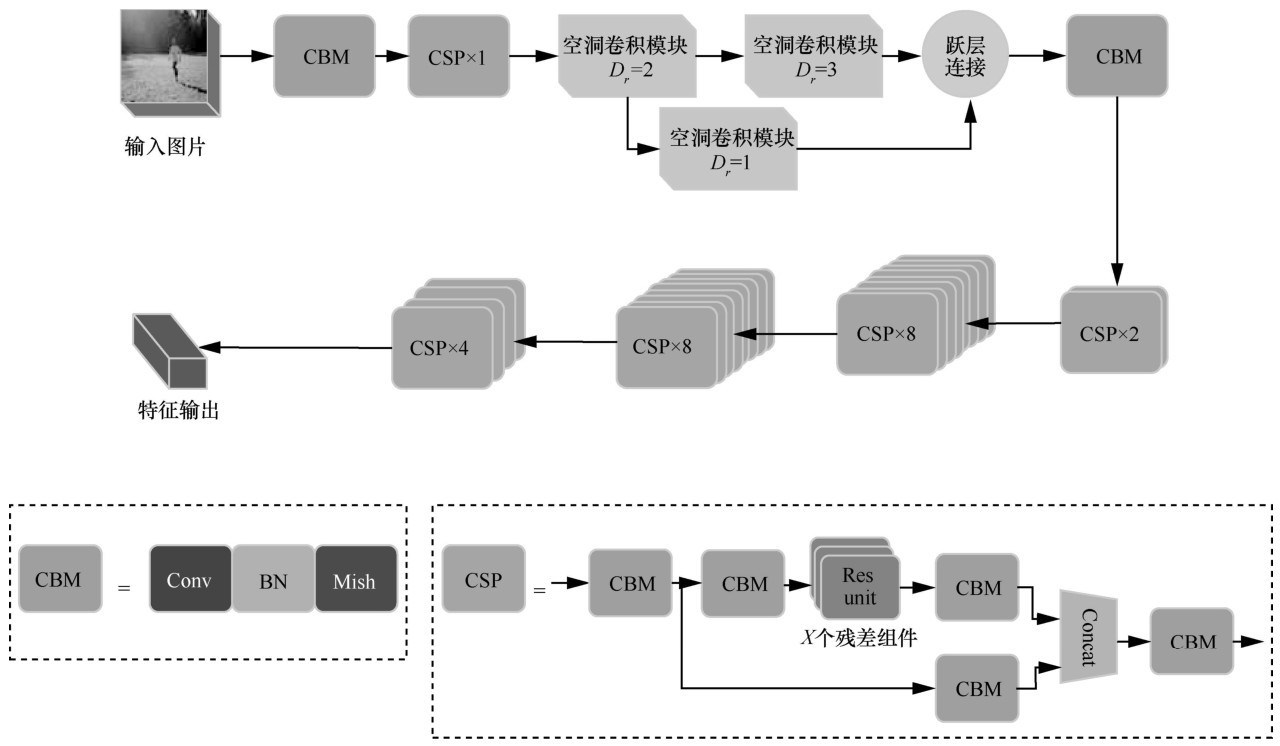
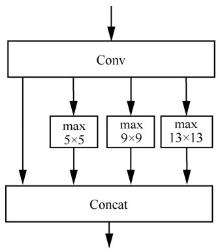
图5
SPP的结构"

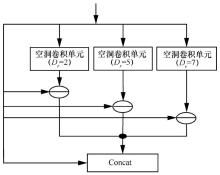
图6
SJDC结构"


图7
聚类结果分布"
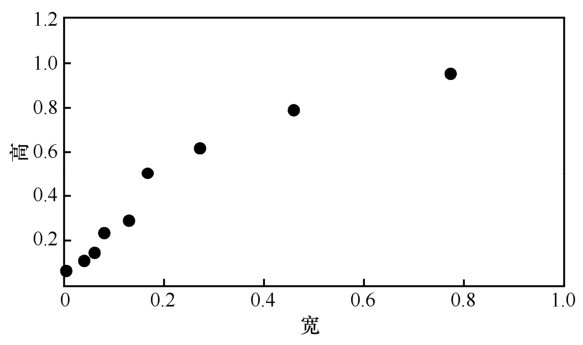

图8
加雾加雨处理图片对比"

图9
自建行人数据集中复杂视觉场景分布情况"
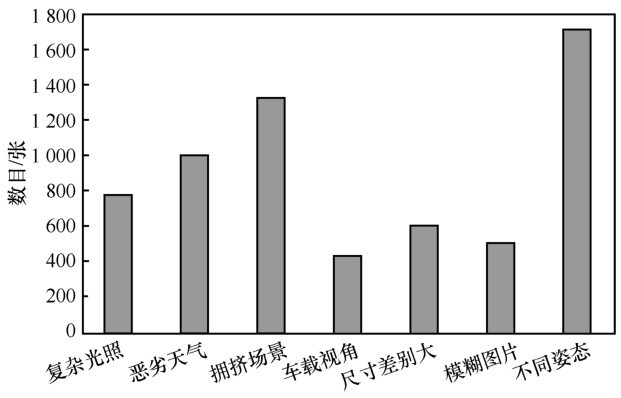
表1
3种网络模型在不同阈值下的APperson对比"
| 阈值 | YOLOv3 | YOLOv4 | YOLOv5 |
| 0.5 | 79.16% | 81.46% | 83.53% |
| 0.6 | 67.89% | 71.55% | 74.05% |
| 0.7 | 44.93% | 49.37% | 52.35% |
| 0.8 | 18.36% | 20.62% | 23.06% |

图10
服装店前的模糊图片检测效果对比"


图11
雨天图片过暗检测效果对比"

表2
3种网络在性能检测漏检情况上的对比"
| 模型 | Epoch | LAMR | APperson |
| YOLOv3 | 150 | 42.42% | 79.16% |
| YOLOv4 | 150 | 40.03% | 82.88% |
| SJDC-YOLOv4 | 150 | 30.33% | 86.90% |

图12
行人重叠遮挡检测效果对比"


图13
光照不足情况检测效果对比"

表3
4种网络在复杂视觉场景下的行人检测效果对比"
| 模型 | LAMR | APperson |
| YOLOv3 | 42.42% | 79.16% |
| YOLOv4 | 40.03% | 82.88% |
| 参考文献[ | 36.80% | 84.00% |
| 本文改进的YOLOv4 | 26.34% | 90.08% |

图14
雾霾天气行人严重重叠检测效果对比"


图15
模糊图片下行人尺寸差距大且存在遮挡情况检测效果对比"

表4
4种网络在非复杂视觉场景下的行人检测效果对比"
| 模型 | LAMR | APperson |
| YOLOv3 | 27.17% | 86.36% |
| YOLOv4 | 8.63% | 95.89% |
| 参考文献[ | 7.07% | 96.22% |
| 本文改进的YOLOv4 | 5.70% | 97.00% |
| [1] | LIN C Z , LU J W , WANG G ,et al. Graininess-aware deep feature learning for robust pedestrian detection[J]. IEEE Transactions on Image Processing, 2020(29): 3820-3834. |
| [2] | 王霞, 张为 . 基于联合学习的多视角室内人员检测网络[J]. 光学学报, 2019,39(2): 78-88. |
| WANG X , ZHANG W . Multi-view indoor human detection neural network based on joint learning[J]. Acta Optica Sinica, 2019,39(2): 78-88. | |
| [3] | VIOLA P , JONES M . Rapid object detection using a boosted cascade of simple features[C]// Proceedings of Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition.CVPR 2001. Piscataway:IEEE Press, 2001. |
| [4] | DALAL N , TRIGGS B . Histograms of oriented gradients for human detection[C]// Proceedings of 2005 IEEE computer society conference on computer vision and pattern recognition (CVPR’05). Piscataway:IEEE Press, 2005. |
| [5] | WANG X Y , HAN T X , YAN S C . An HOG-LBP human detector with partial occlusion handling[C]// Proceedings of 2009 IEEE 12th International Conference on Computer Vision. Piscataway:IEEE Press, 2009: 32-39. |
| [6] | DOLLáR P , APPEL R , BELONGIE S ,et al. Fast feature Pyramids for object detection[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2014,36(8): 1532-1545. |
| [7] | GIRSHICK R , DONAHUE J , DARRELL T ,et al. Rich feature hierarchies for accurate object detection and semantic segmentation[C]// Proceedings of 27th IEEE Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE Press, 2014: 580-587. |
| [8] | GIRSHICK R , . Fast R-CNN[C]// Proceedings of 2015 IEEE International Conference on Computer Vision (ICCV). Piscataway:IEEE Press, 2015: 1440-1448. |
| [9] | REN S Q , HE K M , GIRSHICK R ,et al. Faster R-CNN:towards real-time object detection with region proposal networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017,39(6): 1137-1149. |
| [10] | REDMON J , DIVVALA S , GIRSHICK R ,et al. You only look once:unified,real-time object detection[C]// Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway:IEEE Press, 2016: 779-788. |
| [11] | LIN T Y , GOYAL P , GIRSHICK R ,et al. Focal loss for dense object detection[C]// Proceedings of 2017 IEEE International Conference on Computer Vision (ICCV). Piscataway:IEEE Press, 2017: 2999-3007. |
| [12] | LIU W , ANGUELOV D , ERHAN D ,et al. SSD:single shot MultiBox detector[M]// Computer Vision-ECCV 2016. Cham: Springer International Publishing, 2016: 21-37. |
| [13] | WU D H , LV S C , JIANG M ,et al. Using channel pruning-based YOLOv4 deep learning algorithm for the real-time and accurate detection of apple flowers in natural environments[J]. Computers and Electronics in Agriculture, 2020,178: 105742. |
| [14] | 李彬, 汪诚, 吴静 ,等. 改进 YOLOv4 算法的航空发动机部件表面缺陷检测[J]. 激光与光电子学进展, 2021: 1-17. |
| LI B , WANG C , WU J ,et al. Surface defect detection of aeroengine components based on improved YOLOv4 algorithm[J]. Laser & Optoelectronics Progress, 2021: 1-17. | |
| [15] | LEE C H , LIN C W . A two-phase fashion apparel detection method based on YOLOv4[J]. Applied Sciences, 2021,11(9): 3782. |
| [16] | WU L , MA J , ZHAO Y H ,et al. Apple detection in complex scene using the improved YOLOv4 model[J]. Agronomy, 2021,11(3): 476. |
| [17] | FU H X , SONG G Q , WANG Y C . Improved YOLOv4 marine target detection combined with CBAM[J]. Symmetry, 2021,13(4): 623. |
| [18] | BOCHKOVSKIY A , WANG C Y , LIAO H Y MARK . YOLOv4:optimal speed and accuracy of object detection[EB]. 2020. |
| [19] | 李玉, 甄畅, 石雪 ,等. 基于熵加权K-means全局信息聚类的高光谱图像分类[J]. 中国图象图形学报, 2019,24(4): 630-638. |
| LI Y , ZHEN C , SHI X ,et al. Hyperspectral image classification algorithm based on entropy weighted K-means with global information[J]. Journal of Image and Graphics, 2019,24(4): 630-638. | |
| [20] | WANG P Q , CHEN P F , YUAN Y ,et al. Understanding convolution for semantic segmentation[C]// Proceedings of 2018 IEEE Winter Conference on Applications of Computer Vision (WACV). Piscataway:IEEE Press, 2018: 1451-1460. |
| [21] | HE K M , ZHANG X Y , REN S Q ,et al. Spatial pyramid pooling in deep convolutional networks for visual recognition[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2015,37(9): 1904-1916. |
| [22] | REDMON J , FARHADI A . YOLOv3:an incremental improvement[EB]. 2018. |
| [23] | LIU S , QI L , QIN H F ,et al. Path aggregation network for instance segmentation[C]// Proceedings of 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE Press, 2018: 8759-8768. |
| [24] | YU F , KOLTUN V , FUNKHOUSER T . Dilated residual networks[C]// Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway:IEEE Press, 2017: 636-644. |
| [25] | 赵朵朵, 章坚武, 傅剑峰 . 基于深度学习的实时人流统计方法研究[J]. 传感技术学报, 2020,33(8): 1161-1168. |
| ZHAO D D , ZHANG J W , FU J F . Research on real-time statistics of people flow based on deep learnning[J]. Chinese Journal of Sensors and Actuators, 2020,33(8): 1161-1168. | |
| [26] | EVERINGHAM M , VAN GOOL L , WILLIAMS C K I ,et al. The pascal visual object classes (VOC) challenge[J]. International Journal of Computer Vision, 2010,88(2): 303-338. |
| [27] | DOLLAR P , WOJEK C , SCHIELE B ,et al. Pedestrian detection:an evaluation of the state of the art[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2012,34(4): 743-761. |
| [28] | OUYANG W L , WANG X G . A discriminative deep model for pedestrian detection with occlusion handling[C]// Proceedings of 2012 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE Press, 2012: 3258-3265. |
| [1] | 高凯辉, 李丹. 数据中心网络性能保障研究综述[J]. 电信科学, 2023, 39(6): 1-21. |
| [2] | 李彧, 李召召, 吕平, 刘勤让. 全维可重构的多模态网络交换芯片架构设计[J]. 电信科学, 2023, 39(6): 22-32. |
| [3] | 李炯, 胡宇翔, 崔鹏帅, 田乐, 董永吉. 面向多模态网络环境的网络模态增量式部署机制研究[J]. 电信科学, 2023, 39(6): 33-43. |
| [4] | 郭泽华, 朱昊文, 徐同文. 面向分布式机器学习的网络模态创新[J]. 电信科学, 2023, 39(6): 44-51. |
| [5] | 刘爱华, 骆汉光, 温建中, 占治国. 面向多模态网络的隔离转发技术研究[J]. 电信科学, 2023, 39(6): 52-60. |
| [6] | 邹涛, 张慧峰, 高万鑫, 徐琪, 沈丛麒, 朱俊, 潘仲夏, 国兴昌. 面向智能制造的多模态网络应用技术研究[J]. 电信科学, 2023, 39(6): 61-72. |
| [7] | 何耀宇, 张超. 面向无人机应用的低轨卫星通信技术适航分析[J]. 电信科学, 2023, 39(6): 96-104. |
| [8] | 王甫镔, 孙士渊, 王梦辉, 杨昉, 王小斐, 宋健. 多光源可见光通信关键技术[J]. 电信科学, 2023, 39(5): 3-10. |
| [9] | 马天洋, 陈雄斌, 徐义武. 基于可见光通信的零能耗光标签[J]. 电信科学, 2023, 39(5): 20-27. |
| [10] | 刘思聪, 苏丹萍, 卫天阔, 王先耀. 基于多节点协作的鲁棒可见光智能定位[J]. 电信科学, 2023, 39(5): 28-41. |
| [11] | 胡珈玮, 刘晓谦, 唐昕柯, 董宇涵. 基于DQN的UUV辅助水下无线光通信轨迹规划系统[J]. 电信科学, 2023, 39(5): 42-47. |
| [12] | 刘晓谦, 唐昕柯, 董宇涵. 水下无线光MIMO链路空间信道建模[J]. 电信科学, 2023, 39(5): 48-56. |
| [13] | 张嗣宏, 张健. 以ChatGPT为代表的生成式AI对通信行业的影响和应对思考[J]. 电信科学, 2023, 39(5): 67-75. |
| [14] | 马晓亮, 刘英, 杜德泉, 安玲玲. 运营商智能客服的关键技术和发展趋势[J]. 电信科学, 2023, 39(5): 76-89. |
| [15] | 唐鑫新, 曾学文, 凌致远, 宋磊. 可编程数据平面技术综述[J]. 电信科学, 2023, 39(4): 1-16. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||
|
||