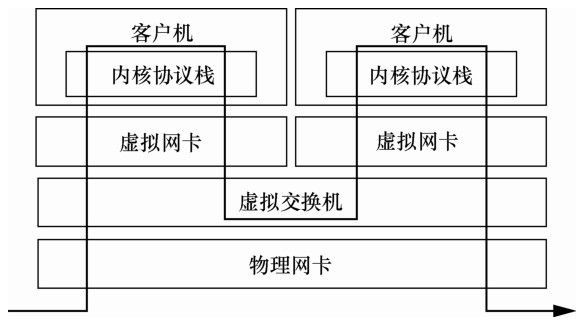
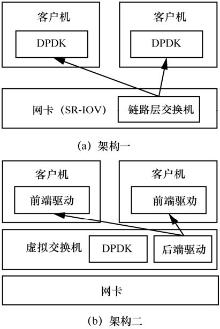
| [12] |
KAZEMPOUR V , KAMALI A , FEDOROVA A . AASH:an asymmetry-aware scheduler for hypervisors[J]. ACM SIGPLAN Notices, 2010,45(7): 85-96.
|
| [13] |
VAHDAT A , YOCUM K , WALSH K , et al. Scalability and accuracy in a large-scale network emulator[J]. ACM SIGOPS Operating Systems Review, 2002,36(SI): 271-284.
|
| [14] |
EMMERICH P , RAUMER D , WOHLFART F , et al. erformance characteristics of virtual switching[C]// 2014 IEEE 3rd International Conference on Cloud Networking (CloudNet), October 8-10,2014, Luxembourg. New Jersey: IEEE Press, 2014:120-125.
|
| [15] |
LIN X , CHEN Y , LI X , et al. Scalable kernel TCP design and implementation for short-lived connections[C]// International Conference on Architectural Support for Programming Languages & Operating Systems, April 2-6,2016, Atlanta,Georgia,USA. New York: ACM Press, 2016:339-352.
|
| [1] |
李晨, 段晓东, 陈炜 , 等. SDN和NFV的思考与实践[J]. 电信科学, 2014,30(8):23-27.
|
|
LI C , DUAN X D , CHEN W , et al. Thoughts and practices about SDN and NFV[J]. Telecommunications Science, 2014,30(8):23-27.
|
| [2] |
赵慧玲, 史凡 . SDN/NFV的发展与挑战[J]. 电信科学, 2014,30(8):13-18.
|
|
ZHAO H L , SHI F . Development and challenge of SDN/NFV[J]. Telecommunications Science, 2014,30(8):13-18.
|
| [3] |
HWANG J , RAMAKRISHNAN K K , WOOD T . NetVM:high performance and flexible networking using virtualization on commodity platforms[J]. IEEE Transactions on Network and Service Management, 2015,12(1): 34-47.
|
| [4] |
FIGURE E . Eliminating receive livelock in an interrupt-driven kernel[J]. ACM Transactions on Computer Systems, 1997,15(3): 217-252.
|
| [5] |
YANG J , MINTURN D B , HADY F . When poll is better than interrupt[C]// FAST, February 14-17,2012, San Jose,CA,USA. New York: ACM Press, 2012:3.
|
| [6] |
WU W , CRAWFORD M , BOWDEN M . The performance analysis of Linux networking-packet receiving[J]. Computer Communications, 2007,30(5): 1044-1057.
|
| [7] |
KOH Y , PU C , BHATIA S , et al. Efficient packet processing in user-level Oses:a study of UML[C]// The 31th IEEE Conference on Local Computer Networks, November 14-16,2006, Sydney,Australia. New Jersey: IEEE Press, 2006:63-70.
|
| [8] |
DEAN J , . Designs,lessons and advice from building large distributed systems[J]. Keynote from LADIS, 2009(1).
|
| [9] |
DINIZ P C , RINARD M C . Lock coarsening:eliminating lock overhead in automatically parallelized object-based programs[J]. Journal of Parallel and Distributed Computing, 1998,49(2): 218-244.
|
| [10] |
BOYD-WICKIZER S , CLEMENTS A T , MAO Y , et al. An analysis of Linux scalability to many cores[C]// Usenix Symposium on Operating Systems Design & Implementation, October 4-6,2010, Vancouver,BC,Canada. New York: ACM Press, 2010:86-93.
|
| [11] |
KAMRUZZAMAN M , SWANSON S , TULLSEN D M . Inter-core prefetching for multicore processors using migrating helper threads[J]. ACM SIGPLAN Notices, 2011,46(3): 393-404.
|
| [16] |
LEVINTHAL D . Performance analysis guide for intel core i7 processor and intel XEON 5500 processors[J]. Intel Performance Analysis Guide, 2009(30):18.
|