

Telecommunications Science ›› 2019, Vol. 35 ›› Issue (12): 79-89.doi: 10.11959/j.issn.1000-0801.2019290
• Research and development • Previous Articles Next Articles
Yiming WANG,Ken CHEN,Aihaiti ABUDUSALAMU
Revised:2019-12-10
Online:2019-12-20
Published:2020-01-15
Supported by:CLC Number:
Yiming WANG,Ken CHEN,Aihaiti ABUDUSALAMU. End-to-end audiovisual speech recognition based on attention fusion of SDBN and BLSTM[J]. Telecommunications Science, 2019, 35(12): 79-89.

"
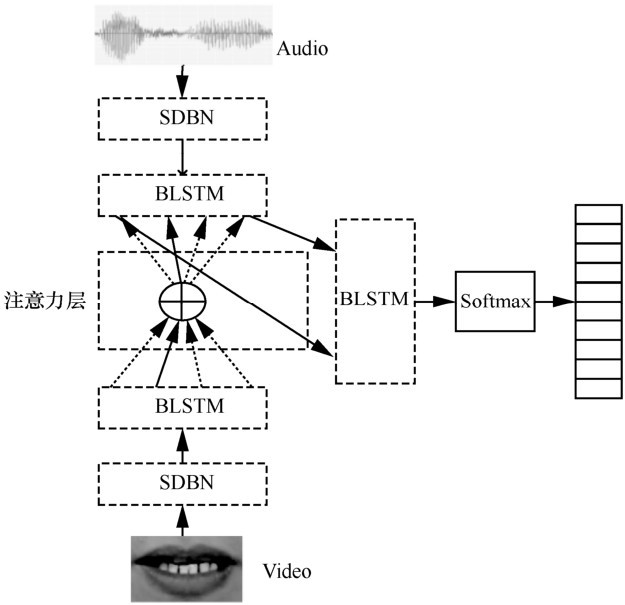
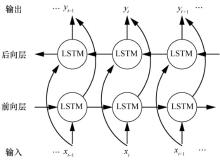
"
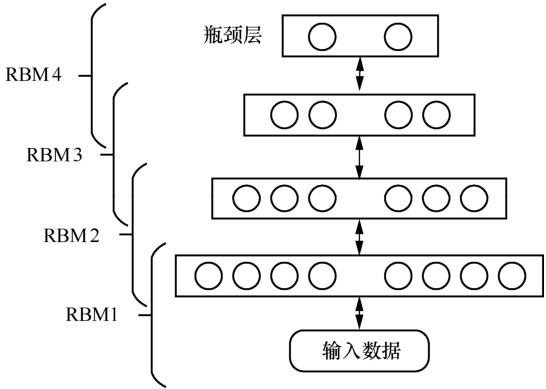
"

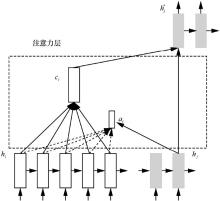
"

"
| 编号 | 短语 |
| 1 | Excuse me |
| 2 | Good bye |
| 3 | Hello |
| 4 | How are you? |
| 5 | Nice to meet you |
| 6 | See you |
| 7 | I am sorry |
| 8 | Thank you |
| 9 | Have a good time |
| 10 | ·ou are welcome |

"

"
| 数据集 | 受试者编号 |
| 训练集 | 1、2、3、5、7、10、11、12、14、16、17、18、19、20、21、23、24、25、27、28、31、32、33、35、36、37、39、40、41、42、45、46、47、48、53 |
| 验证集 | 4、13、22、38、50 |
| 测试集 | 6、8、9、15、26、30、34、43、44、49、51、52 |

"

"
| 算法 | 0° | 30° | 45° | 60° | 90°% | A | A+0° | A+30° | A+45° | A+60° | A+90° |
| 参考文献[ | 94.7% | 89.7% | 90.6% | 87.5% | 93.1% | 98.5% | 98.6% | 98.7% | 98.3% | 98.6% | 98.9% |
| 参考文献[ | 90.0% | 89.2% | 89.7% | 87.2% | 84.2% | 86.39%(-5 dB) | 89.7% | 90.3% | 89.4% | 86.7% | 85.3% |
| 本文算法 | 95.1% | 90.0% | 90.3% | 87.8% | 93.7% | 98.4% | 99.1% | 98.9% | 98.6% | 98.8% | 98.9% |
"
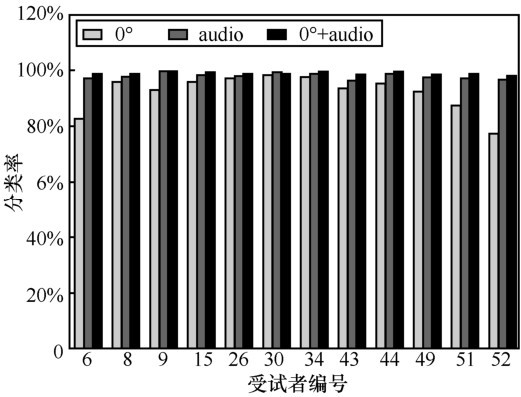
"
| 算法 | 0° | 30° | 45° | 60° | 90° |
| 参考文献[ | 85.6% | 82.5% | 82.5% | 83.3% | 80.3% |
| 参考文献[ | 87.6% | — | — | — | — |
| 参考文献[ | 81.1% | 80.0% | 76.9% | 69.2% | 82.2% |
| 参考文献[ | 94.7% | 89.7% | 90.6% | 87.5% | 93.1% |
| 本文算法 | 95.1% | 90.0% | 90.3% | 87.8% | 93.7% |
| [1] | 王海坤, 潘嘉, 刘聪 . 语音识别技术的研究进展与展望[J]. 电信科学, 2018,34(2): 1-11. |
| WANG H K , PAN J , LIU C . Research development and forecast of automatic speech recognition technologies[J]. Telecommunications Science, 2018,34(2): 1-11. | |
| [2] | CHIU C C , SAINATH T N , WU Y ,et al. State-of-the-art speech recognition with sequence-to-sequence models[C]// ICASSP 2018-2018 IEEE International Conference on Acoustics,Speech and Signal Processing (ICASSP),April 15-20,2018,Calgary,AB,Canada. Piscataway:IEEE Press, 2018. |
| [3] | 王志宏, 杨震 . 人工智能技术研究及未来智能化信息服务体系的思考[J]. 电信科学, 2017,33(5): 1-11. |
| WANG Z H , YANG Z . Research on artificial intelligence technology and the future intelligent information service architecture[J]. Telecommunications Science, 2017,33(5): 1-11. | |
| [4] | NODA K , YAMAGUCHI Y , NAKADAI K ,et al. Audio-visual speech recognition using deep learning[J]. Applied Intelligence, 2015,42(4): 722-737. |
| [5] | HU D , LI X , LU X . Temporal multimodal learning in audiovisual speech recognition[C]// 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR),April 19-24,2016,Brisbane,QLD,Australia. Piscataway:IEEE Press, 2016: 3574-3582. |
| [6] | TAKASHIMA Y , AIHARA R , TAKIGUCHI T ,et al. Audio-visual speech recognition using bimodal-trained bottleneck features for a person with severe hearing loss[J]. 2016: |
| [7] | CHUNG J S , SENIOR A , VINYALS O ,et al. Lip reading sentences in the wild[J]. arXiv:1611.05358, 2016. |
| [8] | PETRIDIS S , STAFYLAKIS T , MA P ,et al. End-to-end audiovisual speech recognition[C]// 2018 IEEE International Conference on Acoustics,Speech and Signal Processing (ICASSP),April 15-20,2018,Calgary,AB,Canada. Piscataway:IEEE Press, 2018: 6548-6552. |
| [9] | WAND M , SCHMIDHUBER J , VU N T . Investigations on End-to-End Audiovisual Fusion[C]// 2018 IEEE International Conference on Acoustics,Speech and Signal Processing (ICASSP),April 15-20,2018,Calgary,AB,Canada. Piscataway:IEEE Press, 2018: 3041-3045. |
| [10] | TAO F , BUSSO C . Gating neural network for large vocabulary audiovisual speech recognition[J]. IEEE/ACM Transactions on Audio,Speech and Language Processing (TASLP), 2018,26(7): 1286-1298. |
| [11] | HINTON G E , SALAKHUTDINOV R R . Reducing the dimensionality of data with neural networks[J]. Science, 2006,313(578): 504-507. |
| [12] | GREZL F , KARAFIAT M , KONTAR S ,et al. Probabilistic and bottle-neck features for LVCSR of meetings[C]// IEEE International Conference on Acoustics,April 15-20,2007,Honolulu,HI,USA. Piscataway:IEEE Press, 2007. |
| [13] | JI N N , ZHANG J S , ZHANG C X . A sparse-response deep belief network based on rate distortion theory[J]. Pattern Recognition, 2014,47(9): 3179-3191. |
| [14] | LEE H , EKANADHAM C , NG A Y . Sparse deep belief net model for visual area V2[C]// Advances in Neural Information Processing Systems,Dec 3-6,2007,Vancouver,British Columbia,Canada.[S.l:s.n. ], 2007: 873-880. |
| [15] | KIAEE F , CHRISTIAN G , ABBASI M . Alternating direction method of multipliers for sparse convolutional neural networks[J]. 2016: |
| [16] | KHALID F , FANANY M I . Combining normal sparse into discriminative deep belief networks[C]// International Conference on Advanced Computer Science & Information Systems,Oct 15-16,2016,Malang,Indonesia. Piscataway:IEEE Press, 2016. |
| [17] | GRAVES A , SCHMIDHUBER J . Framewise phoneme classification with bidirectional LSTM and other neural network architectures[J]. Neural Networks, 2005,18(5-6): 602-610. |
| [18] | LUONG M T , PHAM H , MANNING C D . Effective approaches to attention-based neural machine translation[J].,2015. arXiv preprint arXiv:1508.04025, 2015. |
| [19] | ANINA I , ZHOU Z , ZHAO G ,et al. OuluVS2:a multi-view audiovisual database for non-rigid mouth motion analysis[C]// IEEE International Conference & Workshops on Automatic Face & Gesture Recognition,May 4-8,2015,Ljubljana,Slovenia. Piscataway:IEEE Press, 2015. |
| [20] | HINTON G E . A practical guide to training restricted Boltzmann machines[Z].2012. 2012. |
| [21] | GLOROT X , BENGIO Y . Understanding the difficulty of training deep feedforward neural networks[C]// The Thirteenth International Conference on Artificial Intelligence and Statistics,May 13-15,2010,Chia Laguna Resort,Sardinia,Italy.[S.l.:s.n]. 2010: 249-256. |
| [22] | PETRIDIS S , WANG Y , LI Z ,et al. End-to-end audiovisual fusion with LSTM[J]. arXiv preprint arXiv:1709.04343, 2017. |
| [23] | KOUMPAROULIS A , POTAMIANOS G . Deep View2View mapping for view-invariant lipreading[C]// 2018 IEEE Spoken Language Technology Workshop (SLT),Dec 18-21,2018,Athens,Greece. Piscataway:IEEE Press, 2018: 588-594. |
| [24] | SAITOH T , ZHOU Z , ZHAO G ,et al. Concatenated frame image based CNN for visual speech recognition[C]// Asian Conference on Computer Vision,Nov 20-24,2016,Taipei,China. Berlin:Springer, 2016: 277-289. |
| [25] | FUNG I , MAK B . End-to-end low-resource lip-reading with maxout CNN and LSTM[C]// 2018 IEEE International Conference on Acoustics,Speech and Signal Processing (ICASSP),April 15-20,2018,Calgary,AB,Canada. Piscataway:IEEE Press, 2018: 2511-2515. |
| [26] | LEE D , LEE J , KIM K E . Multi-view automatic lip-reading using neural network[C]// Asian Conference on Computer Vision,Nov 20-24,2016,Taipei,China. Berlin:Springer, 2016: 290-302. |
| [27] | PETRIDIS S , WANG Y , LI Z ,et al. End-to-end multi-view lipreading[J]. arXiv preprint arXiv:1709.00443, 2017. |
| [1] | Yong ZHANG, Jikui LIU, Wenlong KE. EEG emotion recognition based on parallel separable convolution and label smoothing regularization [J]. Telecommunications Science, 2023, 39(5): 116-128. |
| [2] | Yanxia TAN, Guangquan WANG, Zelin WANG, Yanlei ZHENG, He ZHANG, Chenfang ZHANG, Sai HAN, Shikui SHEN. Research on technical scheme of SDN intelligent management and control orchestration system [J]. Telecommunications Science, 2023, 39(3): 143-152. |
| [3] | Jia CHEN, Jianwu ZHANG, Zheliang ZHANG. Spoof speech detection based on context information and attention feature [J]. Telecommunications Science, 2023, 39(2): 92-102. |
| [4] | Jianfeng DAI, Xingyu CHEN, Ligang DONG, Xian JIANG. A triple joint extraction method combining hybrid embedding and relational label embedding [J]. Telecommunications Science, 2023, 39(2): 132-144. |
| [5] | Kai CHEN. Technical solution and application of 5G slicing private network based on cloud-network integration [J]. Telecommunications Science, 2022, 38(7): 166-174. |
| [6] | Yong SONG, Zhiwei YAN, Yukun QIN, Dongming ZHAO, Xiaozhou YE, Yuanyuan CHAI, Ye OUYANG. Customer service complaint work order classification based on matrix factorization and attention multi-task learning [J]. Telecommunications Science, 2022, 38(2): 103-110. |
| [7] | Zhenhua ZHANG, Siyue SUN, Gaosai LIU, Long WANG, Xinglong JIANG, Lin DONG, Guang LIANG. A survey of optical/electric hybrid switching technology for satellite Internet [J]. Telecommunications Science, 2022, 38(11): 1-10. |
| [8] | Guoxin ZHANG. Research and application of 5G cloud-network-edge-end integrated in-depth security protection system [J]. Telecommunications Science, 2022, 38(10): 173-179. |
| [9] | Nan JIN, Ruiqin WANG, Yuecong LU. Ebbinghaus forgetting curve and attention mechanism based recommendation algorithm [J]. Telecommunications Science, 2022, 38(10): 89-97. |
| [10] | Yanxia TAN, Yanlei ZHENG, Guangquan WANG, He ZHANG. Research and practice of OTN controller northbound unified interface model [J]. Telecommunications Science, 2022, 38(10): 163-172. |
| [11] | Peng LIU, Zongpeng DU, Yongjing LI, Lu LU, Xiaodong DUAN. End-to-end deterministic networking architecture and key technologies [J]. Telecommunications Science, 2021, 37(9): 64-73. |
| [12] | Jinyang SUN, Baisong LIU, Hao REN, Jiangbo QIAN. TAGAN: an academic paper adversarial recommendation algorithm incorporating fine-grained semantic features [J]. Telecommunications Science, 2021, 37(8): 57-65. |
| [13] | Yan ZHANG. Networking technology and implementation method based on 5G slice private line [J]. Telecommunications Science, 2021, 37(10): 143-151. |
| [14] | Yiliang LIU,Xin LI,Kaitao BO. End-to-end network collaboration in 5G networks [J]. Telecommunications Science, 2020, 36(3): 144-155. |
| [15] | Tianjie MU,Xiaohui CHEN,Yiyun WANG,Lupeng MA,Dong LIU,Jing ZHOU,Wenyi ZHANG. A survey on deep learning based joint source-channel coding [J]. Telecommunications Science, 2020, 36(10): 56-66. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||
|
||