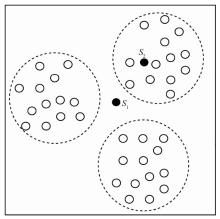
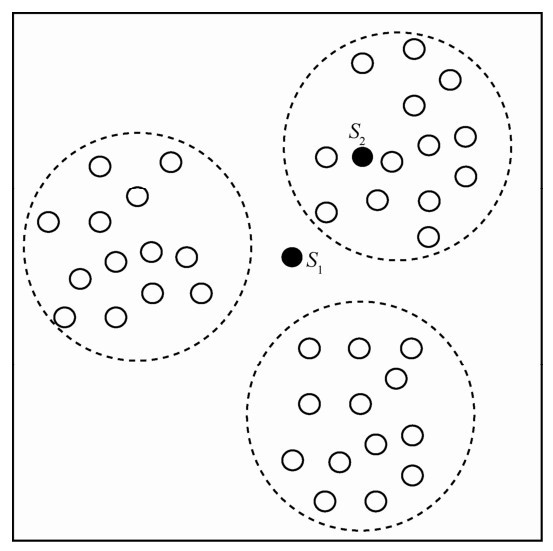
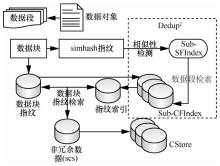
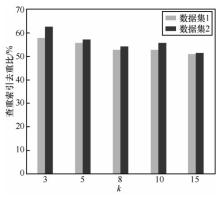
| [1] |
ZHU B , LI K , PATTERSON H . Avoiding the disk bottleneck in the data domain deduplication file system[A]. Proceedings of the 6th USENIX Conference on File and Storage Technologies,USENIX Association[C]. 2008. 1-14.
|
| [2] |
LILLIBRIDGE M , ESHGHI K , BHAGWAT D ,et al. Sparse indexing:large scale,inline deduplication using sampling and locality[A]. Proccedings of the 7th Conference on File and Storage Technologies,USENIX Association[C]. 2009. 111-123.
|
| [3] |
BHAGWAT D , ESHGHI K , LONG D ,et al. Extreme binning:scalable,parallel deduplication for chunk-based file backup[A]. In Modeling,Analysis & Simulation of Computer and Telecommunication Systems,IEEE International Symposium[C]. IEEE, 2009. 1-9.
|
| [4] |
XIA W , JIANG H , FENG D ,et al. SiLo:a similarity-locality based near-exact deduplication scheme with low RAM overhead and high throughput[A]. Proceedings of the 2011 USENIX Annual Technical Conference(ATC),USENIX Association[C]. 2011. 26-28.
|
| [5] |
ARONOVICH L , ASHER R , BACHMAT E ,et al. The design of a similarity based deduplication system[A]. Proceedings of SYSTOR 2009,The Israeli Experimental Systems Conference[C]. ACM, 2009. 1-14.
|
| [6] |
ROMA?SKI B , HELDT ? ? , KILIAN W ,et al. Anchor-driven subchunk deduplication[A]. Proceedings of the 4th Annual International Conference on Systems and Storage[C]. 2011. 16-28.
|
| [7] |
ZHANG Z , BHAGWAT D , LITWIN W ,et al. Improved deduplication through parallel binning[A]. Performance Computing and Communications Conference(IPCCC),2012 IEEE 31st International[C]. 2012. 130-141.
|
| [8] |
DOUGLIS F , IYENGAR A . Application-specific deltaencoding via resemblance detection[A]. Proceedings of the 2003 USENIX Annual Technical Conference[C]. San Antonio,Texas, 2003. 113-126.
|
| [9] |
BRODER A Z , MITZENMACHER M . Network applications of Bloom filters:a survey[J]. Internet Mathematics, 2004,1(4): 485-509.
|
| [10] |
TAN L J , YAO W B , LIU Z Y.et al . CDFS:a cloud-based deduplication filesystem[J]. Advanced Science Letters,American Scientific Publishers, 2012,9(1): 855-860.
|
| [11] |
TEODOSIU D , BJORNER N , GUREVICH Y ,et al. Optimizing file replication over limited-bandwidth networks using remote differential compression[R]. Technical Report MSR-TR-2006-157,Microsoft Research, 2006.
|
| [12] |
YAO W B , YE P D . Simdedup:a new deduplication scheme based on simhash[A]. In Web-Age Information Management[C]. Springer Berlin Heidelberg, 2013. 79-88.
|
| [13] |
CHARIKAR M . Similarity estimation techniques from rounding algorithms[A]. Proc 34th Annual Symposium on Theory of Computing(STOC2002)[C]. 2002. 380-388.
|
| [14] |
MEISTER D , BRINKMANN A . Multi-level comparison of data deduplication in a backup scenario[A]. Proceedings of SYSTOR 2009,The Israeli Experimental Systems Conference[C].ACM, 2009.
|
| [15] |
MEYER D T , BOLOSKY W J . A study of practical deduplication[J]. ACM Transactions on Storage(TOS), 2012,7(4): 14.
|
| [16] |
WALLACE G , DOUGLIS F , QIAN H ,et al. Characteristics of backup workloads in production systems[A]. Proceedings of the Tenth USENIX Conference on File and Storage Technologies(FAST’12)[C]. 2012.
|
| [17] |
WEI J , JIANG H , ZHOU K ,et al. MAD2:a scalable high-throughput exact deduplication approach for network backup services[A]. Mass Storage Systems and Technologies(MSST),2010 IEEE 26th Symposium[C].IEEE, 2010. 1-14.
|
| [18] |
KAISER J , MEISTER D , BRINKMANN A ,et al. Design of an exact data deduplication cluster[A]. Mass Storage Systems and Technologies(MSST),2012 IEEE 28th Symposium[C].IEEE, 2012. 1-12.
|
| [19] |
BALACHANDRAN S , CONSTANTINESCU C . Sequence of hashes compression in data de-duplication[A]. Data Compression Conference,DCC 2008[C].IEEE, 2008.505.
|
| [20] |
CONSTANTINESCU C , PIEPER J , LI T . Block size optimization in deduplication systems[A]. Data Compression Conference,DCC'09[C].IEEE, 2009. 442-442.
|
| [21] |
ESHGHI K , LILLIBRIDGE M , WILCOCK L ,et al. Jumbo store:providing efficient incremental upload and versioning for a utility rendering service[A]. FAST[C]. 2007. 123-138.
|
| [22] |
MEISTER D , BRINKMANN A,Sü? T . File recipe compression in data deduplication systems[A]. Proceedings of 11th USENIX Conference on File and Storage Technologies(FAST)[C]. 2013. 175-182.
|
| [23] |
HART P E . The condensed nearest neighbor rule[J]. IEEE Transactions on Information Theory IT-14, 1968: 515-516.
|