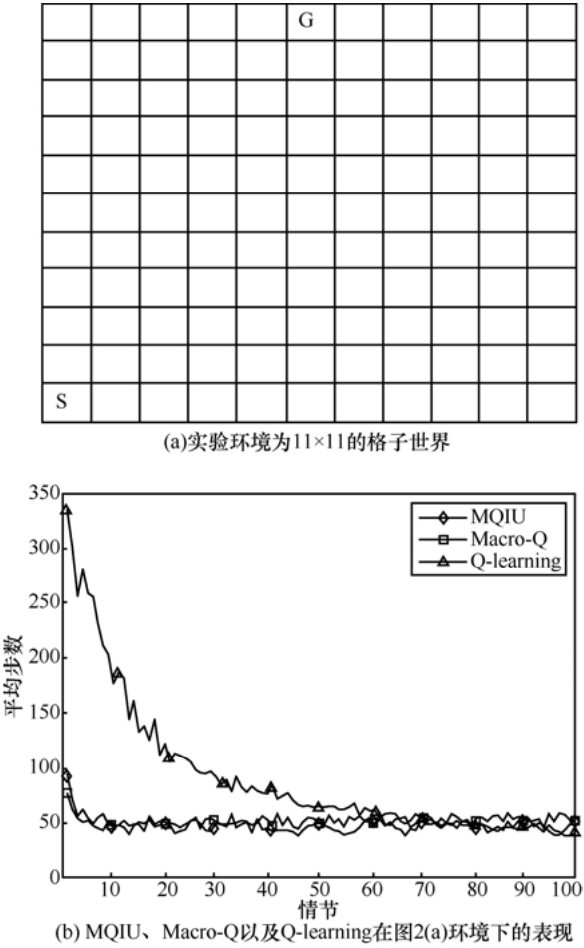
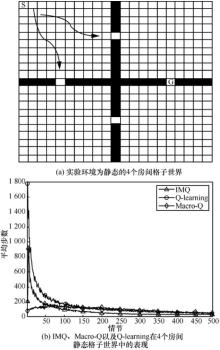
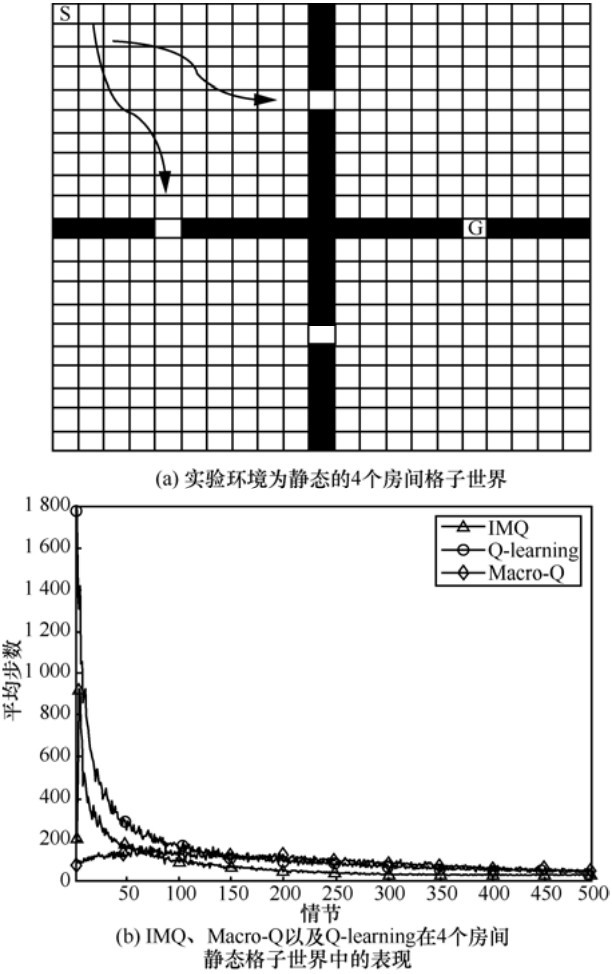
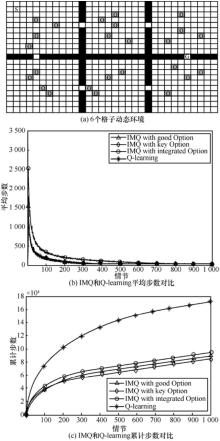
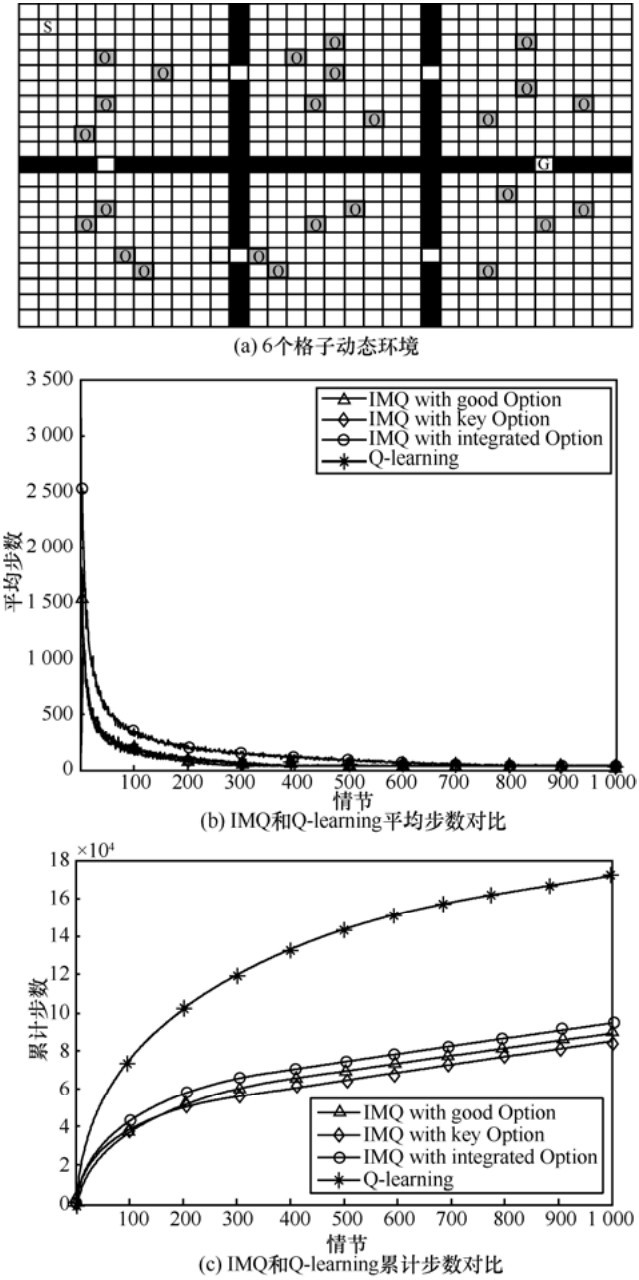
| [1] |
OTTERLO M V , WIERING M . Reinforcement learning and Markov decision processes[J]. Adaptation Learning &Optimization, 2012,206(4): 3-42.
|
| [2] |
VAN H H . Reinforcement learning:state of the art[M]. Berlin: SpringerPress, 2007.
|
| [3] |
沈晶, 顾国昌, 刘海波 . 未知动态环境中基于分层强化学习的移动机器人路径规划[J]. 机器人, 2006,28(5): 544-547. SHEN J , GU G C , LIU H B . Mobile robot path planning based on hierarchical reinforcement learning in unknown dynamic environment[J]. ROBOT, 2006,28(5): 544-547.
|
| [4] |
刘全, 闫其粹, 伏玉琛 ,等. 一种基于启发式奖赏函数的分层强化学习方法[J]. 计算机研究与发展, 2011,48(12): 2352-2358. LIU Q , YAN Q C , FU Y C ,et al. A hierarchical reinforcement learning method based on heuristic reward function[J]. Journal of Computer Research and Development, 2011,48(12): 2352-2358.
|
| [5] |
陈兴国, 高阳, 范顺国 ,等. 基于核方法的连续动作Actor-Critic学习[J]. 模式识别与人工智能, 2014(2): 103-110. CHEN X G , GAO Y , FAN S G ,et al. Kernel-based continuous-action actor-critic learning[J]. Pattern Recognition and Artificial Intelligence, 2014(2): 103-110.
|
| [6] |
朱斐, 刘全, 傅启明 ,等. 一种用于连续动作空间的最小二乘行动者-评论家方法[J]. 计算机研究与发展, 2014,51(3): 548-558. ZHU F , LIU Q , FU Q M ,et al. A least square actor-critic approach for continuous action space[J]. Journal of Computer Research and Development, 2014,51(3): 548-558.
|
| [7] |
唐昊, 张晓艳, 韩江洪 ,等. 基于连续时间半马尔可夫决策过程的Option算法[J]. 计算机学报, 2014(9): 2027-2037. TANG H , ZHANG X Y , HAN J H ,et al. Option algorithm based on continuous-time semi-Markov decision process[J]. Chinese Journal of Computers, 2014(9): 2027-2037.
|
| [8] |
SUTTON R S , PRECUP D , SINGH S . Between MDPs and semi-MDPs:a framework for temporal abstraction in reinforcement learning[J]. Artificial Intelligence, 1999,112(1): 181-211.
|
| [9] |
MCGOVERN A , BARTO A G . Automatic discovery of subgoals in reinforcement learning using diverse density[J]. Computer Science Department Faculty Publication Series, 2001(8): 361-368.
|
| [10] |
?IM?EK ? , WOLFE A P , BARTO A G . Identifying useful subgoals in reinforcement learning by local graph partitioning[C]// The 22nd International Conference on Machine Learning. ACM, 2005: 816-823.
|
| [11] |
?IM?EK ? , BARTO A G , . Using relative novelty to identify useful temporal abstractions in reinforcement learning[C]// The Twenty-first International Conference on Machine Learning. ACM, 2004: 751-758.
|
| [12] |
CHAGANTY A T , GAUR P , RAVINDRAN B . Learning in a small world[C]// The 11th International Conference on Autonomous Agents and Multiagent Systems-Volume 1.International Foundation for Autonomous Agents and Multiagent Systems. 2012: 391-397.
|
| [13] |
SUTTON R S , SINGH S , PRECUP D ,et al. Improved switching among temporally abstract actions[J]. Advances in Neural Information Processing Systems, 1999: 1066-1072.
|
| [14] |
CASTRO P S , PRECUP D . Automatic construction of temporally extended actions for mdps using bisimulation metrics[C]// European Conference on Recent Advances in Reinforcement Learning. Springer-Verlag, 2011: 140-152.
|
| [15] |
何清, 李宁, 罗文娟 ,等. 大数据下的机器学习算法综述[J]. 模式识别与人工智能, 2014,27(4): 327-336. HE Q , LI N , LUO W J ,et al. A survey of machine learning algorithms for big data[J]. Pattern Recognition and Artificial Intelligence, 2014,27(4): 327-336.
|
| [16] |
SUTTON R S , PRECUP D , SINGH S P . Intra-option learning about temporally abstract actions[C]// ICML. 1998,98: 556-564.
|
| [17] |
石川, 史忠植, 王茂光 . 基于路径匹配的在线分层强化学习方法[J]. 计算机研究与发展, 2008,45(9): 1470-1476. SHI C , SHI Z Z , WANG M G . Online hierarchical reinforcement learning based on path-matching[J]. Journal of Computer Research and Development, 2008,45(9): 1470-1476.
|
| [18] |
BOTVINICK M M . Hierarchical reinforcement learning and decision making[J]. Current Opinion in Neurobiology, 2012,22(6): 956-962.
|
| [19] |
王爱平, 万国伟, 程志全 ,等. 支持在线学习的增量式极端随机森林分类器[J]. 软件学报, 2011,22(9): 2059-2074. WANG A P , WAN G W , CHENG Z Q ,et al. Incremental learning extremely random forest classifier for online learning[J]. Journal of Software, 2011,22(9): 2059-2074.
|