

通信学报 ›› 2016, Vol. 37 ›› Issue (8): 24-33.doi: 10.11959/j.issn.1000-436x.2016152
张宇翔1,2,3,孙菀1,杨家海2,3,周达磊4,孟祥飞5,肖春景1
出版日期:2016-08-25
发布日期:2016-09-01
基金资助:Yu-xiang ZHANG1,2,3,Yu SUN1,Jia-hai YANG2,3,Da-lei ZHOU4,Xiang-fei MENG5,Chun-jing XIAO1
Online:2016-08-25
Published:2016-09-01
Supported by:摘要:
微博中的垃圾用户非常普遍,其异常行为及生产的垃圾信息显著降低了用户体验。为了提高识别准确率,已有研究或是尽可能多地定义特征,或是不断尝试提出新的分类检测方法;那么,微博反垃圾问题的突破点优先置于寻找分类特征还是改进分类检测方法,是否特征越多检测效果越好,新的方法是否可以显著提高检测效果。以新浪微博为例,试图通过不同的特征选择方法与不同的分类器组合实验回答以上问题,实验结果表明特征组的选择较分类器的改进更为重要,需从内容信息、用户行为和社会关系多侧面生成特征,且特征并非越多检测效果越好,这些结论将有助于未来微博反垃圾工作的突破。
张宇翔,孙菀,杨家海,周达磊,孟祥飞,肖春景. 新浪微博反垃圾中特征选择的重要性分析[J]. 通信学报, 2016, 37(8): 24-33.
Yu-xiang ZHANG,Yu SUN,Jia-hai YANG,Da-lei ZHOU,Xiang-fei MENG,Chun-jing XIAO. Feature importance analysis for spammer detection in Sina Weibo[J]. Journal on Communications, 2016, 37(8): 24-33.
表1
特征的统计指标"
| 特征 | 均值 | 变异系数 | ||||||||||||
| 合法用户 | 垃圾用户 | 合法用户 | 垃圾用户 | 内容垃圾 | 僵尸垃圾 | 封号垃圾 | 合法用户 | 垃圾用户 | 内容垃圾 | 僵尸垃圾 | 封号垃圾 | |||
| F1 | 317.00 | 1 107.00 | 492.92 | 1 110.95 | 1 106.02 | 1 396.29 | 1 004.48 | 1.01 | 0.48 | 0.60 | 0.41 | 0.33 | ||
| F2 | 276.00 | 141.50 | 1 137.95 | 428.13 | 772.52 | 239.67 | 241.19 | 28.20 | 7.12 | 6.52 | 5.53 | 1.05 | ||
| F3 | 119.00 | 4.00 | 184.42 | 67.66 | 146.75 | 46.22 | 15.07 | 1.28 | 2.88 | 1.93 | 3.30 | 4.41 | ||
| F4 | 1.11 | 6.33 | 3.00 | 50.31 | 46.11 | 140.50 | 16.95 | 5.23 | 3.21 | 2.41 | 1.99 | 6.24 | ||
| F5 | 2.50 | 249.71 | 18.85 | 419.37 | 316.20 | 560.24 | 443.94 | 5.94 | 1.19 | 1.73 | 1.13 | 0.81 | ||
| F6 | 3.00 | 3.00 | 3.56 | 4.27 | 3.77 | 3.30 | 5.05 | 0.81 | 1.13 | 1.10 | 0.90 | 1.14 | ||
| F7 | 555.00 | 349.00 | 1 271.76 | 541.86 | 818.45 | 372.96 | 397.47 | 1.73 | 2.22 | 2.37 | 1.59 | 0.65 | ||
| F8 | 3.33 | 4.94 | 5.27 | 7.84 | 10.56 | 4.13 | 7.31 | 1.63 | 4.15 | 5.14 | 1.12 | 0.71 | ||
| F9 | 62.00 | 62.00 | 86.51 | 135.35 | 165.86 | 247.50 | 66.56 | 1.00 | 1.09 | 0.96 | 0.81 | 0.55 | ||
| F10 | 0.58 | 1.00 | 0.55 | 0.73 | 0.51 | 0.57 | 0.96 | 0.49 | 0.51 | 0.74 | 0.70 | 0.17 | ||
| F11 | 0.09 | 0.01 | 0.17 | 0.23 | 0.47 | 0.29 | 0.03 | 1.22 | 1.50 | 0.81 | 1.21 | 5.15 | ||
| F12 | 0.82 | 0.38 | 1.70 | 0.36 | 0.35 | 0.16 | 0.42 | 1.56 | 2.09 | 3.22 | 1.87 | 0.33 | ||
| F13 | 1.50 | 0.00 | 2.75 | 0.20 | 0.41 | 0.15 | 0.03 | 1.37 | 4.73 | 3.35 | 3.26 | 6.36 | ||
| F14 | 97.06 | 124.11 | 97.63 | 111.64 | 100.37 | 97.93 | 126.25 | 0.30 | 0.24 | 0.30 | 0.28 | 0.11 | ||
| F15 | 0.04 | 0.04 | 0.07 | 0.09 | 0.16 | 0.07 | 0.04 | 1.18 | 1.51 | 1.15 | 1.54 | 0.89 | ||
| F16 | 5.12 | 7.53 | 6.37 | 8.62 | 10.44 | 7.02 | 7.92 | 1.26 | 0.99 | 1.26 | 0.76 | 0.41 | ||
| F17 | 0.05 | 0.05 | 0.05 | 0.07 | 0.09 | 0.07 | 0.05 | 0.50 | 0.71 | 0.60 | 0.41 | 0.33 |
表2
特征选择算法"
| 编号 | 名称 | 分类 | 评价标准 |
| FS1 | CHI(chi-squared)[ | Filter | CHI-square |
| FS2 | IG(information gain)[ | Filter | 信息熵 |
| FS3 | ReliefF[ | Filter | 欧拉距离 |
| FS4 | SVM-RFE(recursive feature elimination for SVM)[ | Wrapper | 预测分析 |
| FS5 | SU(symmetrical uncertainty)[ | Filter | 不确定分析 |
| FS6 | CR(comprehensive ranking) | — | — |
| FS7 | CFS(correlation-based feature selection)[ | Filter | 相关分析 |
表3
分类器"
编号 | 名称 | 说明 |
| Classfier1 | Naive Bayes (NB)[ | 基于贝叶斯定理与特征之间独立假设基础之上,根据某对象的先验概率利用贝叶斯公式计算出其后验概率,选择具有最大后验概率的类作为该对象所属的类 |
| Classfier2 | logistic regression (LR)[ | 使用逻辑回归sigmod函数来计算后验概率,根据后验概率对所给对象进行分类识别 |
| Classfier3 | support vector machine (SVM)[ | 建立在统计学理论中的结构风险最小化准则基础上,原理是将低维空间的点映射到高维空间,使它们成为线性可分,再使用线性划分的原理来判断分类边界 |
| Classfier4 | radial basis function network (RBFN)[ | 该方法是一种前馈神经网络,采用径向基函数作为激活函数 |
| Classfier5 | k-nearest neighbor (IBk/kNN)[ | 一种基于实例学习的非参数估计的分类方法,计算新样本与训练样本之间的距离,找到距离最近的k个邻居,如果邻居的大多数属于某一个类别,则该样本也属于这个类别 |
| Classfier6 | AdaBoost.M1 (ABM1)[ | 一种提高给定学习算法精度的方法,使用同一个训练集训练不同的弱分类器,然后把这些弱分类器集合起来,构成一个强的最终分类器 |
| Classfier7 | bootstrap aggregating (BA)[ | 与 AdaBoost 一样,也是一种集成学习分类方法,但在训练集的选取和预测函数的生成方面存在明显差异,通常AdaBoost的分类准确度较BA的高,不过BA可以有效避免过拟合 |
| Classfier8 | decision trees (J48/C4.5)[ | 一种简单且快速的非参数树状分类方法,利用信息增益率来选择特征,将信息增益率最大的特征作为决策树的分裂节点,每个分支均重复这一过程 |
| Classfier9 | random forest (RF)[ | 以决策树为基本分类器的一个集成学习分类方法,它包含多个由BA集成学习技术训练得到的决策树,当输入待分类的样本时,最终的分类结果由单个决策树的输出结果投票决定 |
| Classfier10 | logistic model trees (LMT)[ | 在决策树中引入了线性逻辑回归,节点包含逻辑回归函数 |
表4
特征选择实验结果"
| δ | 方法 | Top1 | Top2 | Top3 | Top4 | Top5 | Top6 | Top7 | Top8 | Top9 | Top10 | Top11 | Top12 | Top13 | Top14 | Top15 | Top16 | Top17 |
| ChiSq | F5 | F10 | F1 | F14 | F17 | F11 | F4 | F9 | F3 | F13 | F15 | F6 | F7 | F12 | F16 | F8 | F2 | |
| IG | F5 | F10 | F1 | F14 | F17 | F11 | F4 | F9 | F3 | F13 | F7 | F15 | F12 | F6 | F16 | F8 | F2 | |
| 5.9 | ReliefF | F10 | F1 | F14 | F11 | F17 | F3 | F5 | F13 | F6 | F15 | F7 | F12 | F9 | F4 | F16 | F8 | F2 |
| SVM-RFE(c=0.05) | F5 | F4 | F3 | F1 | F7 | F17 | F10 | F11 | F9 | F6 | F13 | F15 | F12 | F8 | F14 | F16 | F2 | |
| SU | F5 | F1 | F10 | F4 | F17 | F14 | F9 | F11 | F13 | F3 | F7 | F12 | F15 | F16 | F6 | F8 | F2 | |
| CFS | {F5,F10,F13} | |||||||||||||||||
| ChiSq | F10 | F1 | F5 | F17 | F12 | F14 | F11 | F13 | F9 | F3 | F4 | F7 | F15 | F16 | F6 | F8 | F2 | |
| IG | F5 | F10 | F1 | F17 | F12 | F14 | F11 | F13 | F9 | F3 | F4 | F7 | F15 | F6 | F16 | F8 | F2 | |
| ReliefF | F1 | F10 | F5 | F14 | F11 | F17 | F12 | F9 | F3 | F13 | F6 | F16 | F15 | F4 | F7 | F2 | F8 | |
| 1 | ||||||||||||||||||
| SVM-RFE(c=0.01) | F10 | F1 | F5 | F11 | F17 | F12 | F14 | F9 | F3 | F13 | F7 | F15 | F6 | F16 | F4 | F8 | F2 | |
| SU | F5 | F1 | F10 | F12 | F17 | F13 | F11 | F14 | F4 | F9 | F3 | F7 | F15 | F6 | F16 | F8 | F2 | |
| CFS | {F1,F5,F10,F12,F17} | |||||||||||||||||

图1
特征选择方法与分类器组合的检测性能(δ=1)"

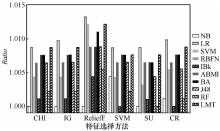
图2
特征选择方法与分类器组合的检测性能(δ=5.9)"
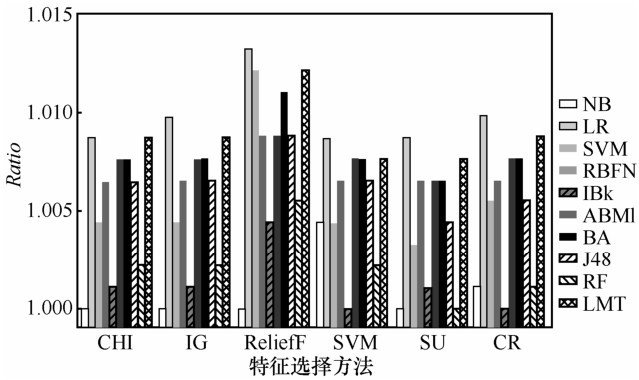
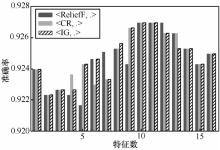
图3
特征数目对准确率的影响(δ=5.9)"


图4
10个分类检测算法的准确率"
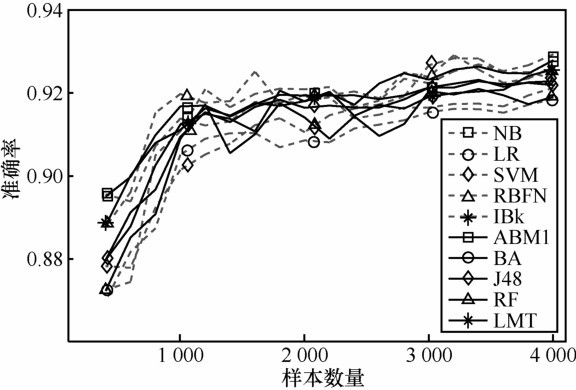
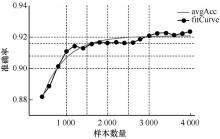
图5
样本数量对准确率的影响"

| [1] | Available online[EB/OL]. |
| [2] | Available online[EB/OL]. |
| [3] | SPIRIN N , HAN J W . Survey on web spam detection:principles and algorithms[J]. ACM SIGKDD Explorations Newsletter, 2012,13(2):50-64. |
| [4] | MUKHERJEE A , LIU B , GLANCE N S . Spotting fake reviewer groups in consumer reviews[C]// The WWW. c2012:191-200. |
| [5] | WANG T Y , WANG G , LI X . Characterizing and detecting malicious crowdsourcing[C]// The ACM SIGCOMM. c2013:537-538. |
| [6] | WANG G , WILSON C , ZHAO X H . Serf and turf:crowdturfing for fun and profit[C]// The WWW. c2012:679-688. |
| [7] | SRIDHARAN V , SHANKAR V , GUPTA M . Twitter games:how successful spammers pick targets[C]// The ACSAC. c2012:389-398. |
| [8] | STRINGHINI G , KRUEGEL C , VIGNA G . Detecting spammers on social networks[C]// The ACSAC. c2012:1-9. |
| [9] | IRANI D , WEBB S , PU C . Study of static classification of social spam profiles in MySpace[C]// The ICWSM. c2010:82-89. |
| [10] | GAO H Y , HU J , WILSON C . Detecting and characterizing social spam campaigns[C]// The CCS. c2010:681-683. |
| [11] | AGGARWAL A , ALMEIDA J M , KUMARAGURU P . Detection of spam tipping behaviour on foursquare[C]// The WWW. c2013:641-648. |
| [12] | GAO Q , ABEL F , HOUBEN G J . A comparative study of user's mi-croblogging behavior on Sina weibo and Twitter[C]// The 20th Interna-tional Conference on User Modeling. c2012:88-101. |
| [13] | YU L , ASUR S , HUBERMAN BA . What trends in Chinese social media[C]// SNA-KDD Workshop. c2011:1-10. |
| [14] | YU LL , ASUR S , HUBERMAN BA . Artificial inflation:the real story of trends and trend-setters in Sina weibo[C]// The International Confernece on Social Computing. c2012:514-519. |
| [15] | 樊鹏翼, 王晖, 姜志宏 , 等. 微博网络测量研究[J]. 计算机研究与发展, 2012,49(4):691-699. FAN P Y , WANG H , JIANG Z H , et al. Measurement of microblog-ging network[J]. Journal of Computer Research Development, 2012,49(4):691-699. |
| [16] | SHARMA P , BISWAS S . Identifying spam in Twitter trending topics.technical report[R]. USC(University of Southern California) Informa-tion Sciences Institute, 2011.1-4. |
| [17] | BENEVENUTO F , MAGNO G , RODRIGUES T . Detecting spammers on Twitter[C]// The 7th Collaboration,Electronic messaging,Anti-Abuse and Spam Conference. c2010:1-9. |
| [18] | HASTIE T , TIBSHIRANI R . DISCRIMINANT adaptive nearest neighbor classification[J]. IEEE Trans.on Pattern Analysis and Ma-chine Intelligence, 1996,18(6):607-616. |
| [19] | FREUND Y , SCHAPIRE RE . A decision-theoretic generalization of on-line learning and an application to boosting[J]. Journal of Com-puter and System Sciences, 1997,55(1):119-139. |
| [20] | ORR M J L . Regularization in the selection of radial basis function centres[J]. Neural Computation, 1995,7(3):606-623. |
| [21] | HO T K . The random subspace method for constructing decision forests[J]. IEEE Trans.on Pattern Analysis and Machine Intelligence, 1998,20(8):832-844. |
| [22] | MILLER Z , DICKINSON B , DEITRICK W , et al. Twitter spammer detection using data stream clustering[J]. Information Sciences, 2014,260(1):64-73. |
| [23] | SHOBEIR F , JAMES F , MADHUSHDANA S , et al. Collective spam-mer detection in evolving multi-relation social networks[C]// The KDD. c2015:1769-1778. |
| [24] | WANG A H . Detecting spam bots in online social networking sites:a machine learning approach[C]// DBSec. c2010:335-342. |
| [25] | LEE K , CAVERLEE J , WEBB S , et al. Uncovering social spammers:social honeypots+machine learning[C]// The SIGIR. c2010:435-442. |
| [26] | MARTINEZ R J , ARAUJO L . Detecting malicious tweets in trending topics using a statistical analysis of language[J]. Expert Systems with Applications, 2013,40(8):2992-3000. |
| [27] | ZHU Y , WANG X , ZHONG E H . Discovering spammers in social networks[C]// The AAAI. c2012:1-7. |
| [28] | HU X , TANG J L , GAO HJ , et al. Social spammer detection with sentiment information[C]// The ICDM. c2014:180-189. |
| [29] | TAN E , GUO L , CHEN S , et al. Unik:unsupervised social network spam detection[C]// The ICDM. c2013:479-488. |
| [30] | ZHANG X , ZHU S , LIANG W . Detecting spam and promoting cam-paigns in the twitter social network[C]// The ICDM. c2012:1194-1199. |
| [31] | SURENDRA S , AIXIN S . HSpam14:a collection of 14 million tweets for hashtag-oriented spam research[C]// The SIGIR. c2015:9-13. |
| [32] | YANG C , HARKREADER R C , ZHANG J . Analyzing spammers' social networks for fun and profit:a case study of cyber criminal eco-system on twitter[C]// The WWW. c2012:71-80. |
| [33] | HU X , TANG J L , LIU H . Online social spammer detection[C]// The AAAI. c2014:1-7. |
| [34] | HU X , TANG J L , ZHANG Y C , et al. Social spammer detection in microblogging[C]// The IJCAI. c2013:177-188. |
| [35] | CASTILLO C , MENDOZA M , POBLETE B . Information credibility on twitter[C]// The WWW. c2011:675-684. |
| [36] | RATKIEWICZ J , CONOVER M , MEISS M . Detecting and tracking political abuse in social media[C]// The ICWSM. c2011:1-8. |
| [37] | 丁兆云, 周斌, 贾焰 , 等. 微博中基于统计特征与双向投票的垃圾用户发现[J]. 计算机研究与发展, 2013,50(11):2336-2348. DING Z Y , ZHOU B , JIA Y , , et al. Detecting spammers with a bidirec-tional vote algorithm based on statistical features in microblogs[J]. Journal of Computer Research and Development, 2013,50(11):2336-2348. |
| [38] | HU X , TANG J L , ZHANG Y C , LIU H . Leveraging knowledge across media for spammer detection in microblogging[C]// The ACM SIGIR. c2014:547-556. |
| [39] | Available online[EB/OL]. |
| [40] | DASH M , LIU H . Feature selection for classifications[J]. Intelligent Data Analysis, 1997,16(21):131-156. |
| [41] | LIU H , SETIONO R . CHI2:feature selection and discretization of numeric attributes[C]// The ICTAI. c1995:338-391. |
| [42] | NOWOZIN S . Estimating attributes:analysis and extensions of RELIEF[C]// The ECML-PKDD. c2012:1-8. |
| [43] | KONONENKO I . Estimating attributes:analysis and extensions of RELIEF[C]// The ECML-PKDD. c1994:171-182. |
| [44] | GUYON I , WESTON J , BARNHILL SMD . Gene selection for cancer classification using support vector machines[J]. Machine Learning, 2002,46(1-3):389-422. |
| [45] | STECK J B . Netpix:a method of feature selection leading to accurate sentiment-based classification models[D]. Central Connecticut State University, 2005. |
| [46] | HALL M A . Correlation-based feature selection for discrete and nu-meric class machine learning[C]// The ICML. c2000:359-366. |
| [47] | JOHN GH , EDU S , LANGLEY P . Estimating continuous distributions in Bayesian classifiers[C]// The UAI. c1995:338-345. |
| [48] | KEERTHI S S , DUAN K , SHEVADE S K . A fast dual algorithm for kernel logistic regression[J]. Machine Learning, 2005,61(1):151-165. |
| [49] | CORTES C , VAPNIK V N . Support-vector networks[J]. Machine Learning, 1995,20(3):273-297. |
| [50] | ORR M J L . Regularization in the selection of radial basis function centres[J]. Neural Computation, 1995,7(3):606-623. |
| [51] | BREIMAN L . Bagging predictors[J]. Machine Learning, 1996,24(2):123-140. |
| [52] | QUINLAN J R . C4.5:programs for machine learning[M]. Morgan Kaufmann Publishers,San Mateo,California, 1993. |
| [53] | LANDWEHR N , HALL M , FRANK E . Logistic model trees[J]. Ma-chine Learning, 2005,59(1):161-205. |
| [54] | KOHAVI R . A study of cross-validation and bootstrap for accuracy estimation and model selection[C]// The IJCAI. c1995:1137-1143. |
| [1] | 仪双燕, 梁永生, 陆晶晶, 柳伟, 胡涛, 何震宇. 联合低秩重构和投影重构的稳健特征选择方法[J]. 通信学报, 2023, 44(3): 209-219. |
| [2] | 李永豪, 胡亮, 张平, 高万夫. 基于动态图拉普拉斯的多标签特征选择[J]. 通信学报, 2020, 41(12): 47-59. |
| [3] | 李占山, 刘兆赓. 基于XGBoost的特征选择算法[J]. 通信学报, 2019, 40(10): 101-108. |
| [4] | 张俐,王枞. 基于最大相关最小冗余联合互信息的多标签特征选择算法[J]. 通信学报, 2018, 39(5): 111-122. |
| [5] | 张震,魏鹏,李玉峰,兰巨龙,徐萍,陈博. 改进粒子群联合禁忌搜索的特征选择算法[J]. 通信学报, 2018, 39(12): 60-68. |
| [6] | 王勇,周慧怡,俸皓,叶苗,柯文龙. 基于深度卷积神经网络的网络流量分类方法[J]. 通信学报, 2018, 39(1): 14-23. |
| [7] | 武小年,彭小金,杨宇洋,方堃. 入侵检测中基于SVM的两级特征选择方法[J]. 通信学报, 2015, 36(4): 19-26. |
| [8] | 刘豫,聂眉宁,苏璞睿,冯登国. 基于可回溯动态污点分析的攻击特征生成方法[J]. 通信学报, 2012, 33(5): 21-28. |
| [9] | 陈亮,龚俭. 基于NetFlow记录的高速应用流量分类方法[J]. 通信学报, 2012, 33(1): 145-152. |
| [10] | 程国振,程东年,俞定玖. 基于多尺度低秩模型的网络异常流量检测方法[J]. 通信学报, 2012, 33(1): 182-190. |
| [11] | 陈铁明,马继霞,宣以广,蔡家楣. 快速特征选择方法及其在入侵检测中的应用[J]. 通信学报, 2010, 31(9A): 233-238. |
| [12] | 卓莹,龚春叶,龚正虎. 网络传输态势感知的研究与实现[J]. 通信学报, 2010, 31(9): 55-64. |
| [13] | 王博,贾焰,杨树强,周斌. 适用于不确定文本分类的特征选择算法[J]. 通信学报, 2009, 30(8): 32-38. |
| [14] | 李洋,郭莉,陆天波,田志宏. TCM-KNN网络异常检测算法优化研究[J]. 通信学报, 2009, 30(7): 13-19. |
| [15] | 张晓惠,林柏钢. 基于特征选择和多分类支持向量机的异常检测[J]. 通信学报, 2009, 30(10A): 68-73. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||
|
||