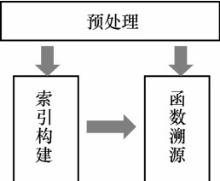
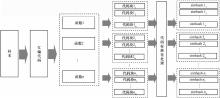
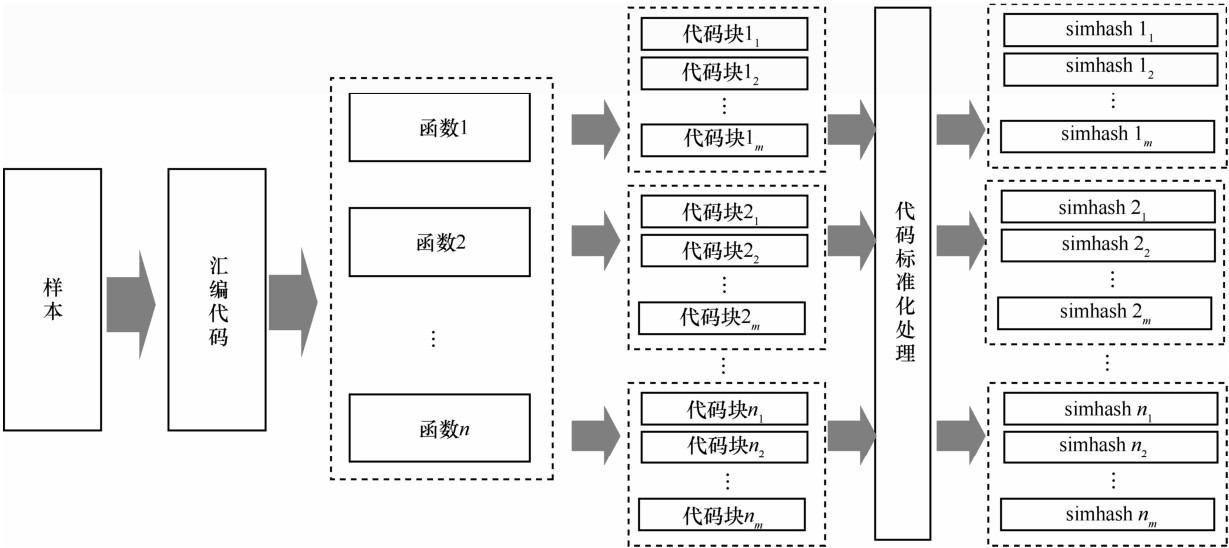
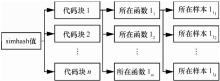
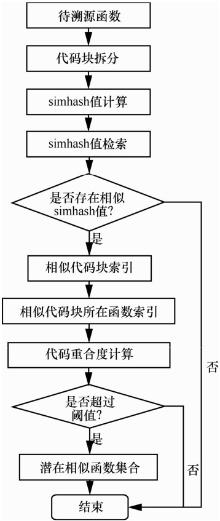
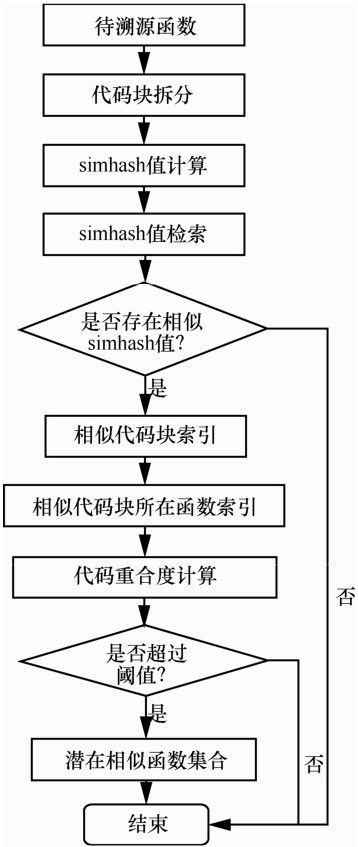
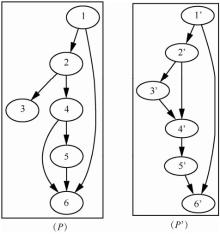
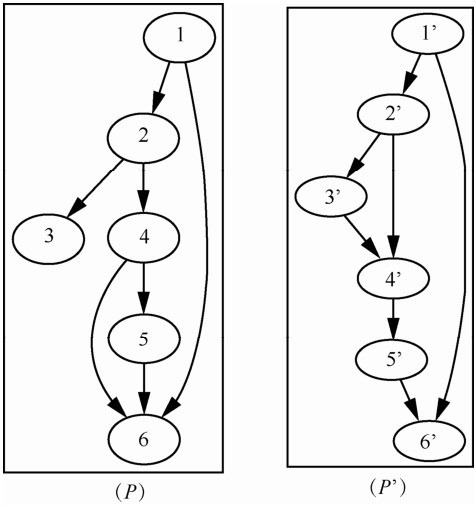
| [1] |
董志强, 肖新光, 张栗伟 . 编码心理学分析病毒同源性[J]. 信息安全与通信保密, 2005(8):55-59. DONG Z Q , XIAO X G , ZHANG S W . Malware homology identifica-tion based on programming psychology[J]. China Information Security, 2005(8):55-59.
|
| [2] |
GReAT . Gauss: abnormal distribution 2012[R/OL].
|
| [3] |
YURY Y , NAMESTNIKOV V K , OLEG K . Chthonic: a new modification of ZeuS 2014[R/OL]. .
|
| [4] |
SKELORU V . Visgean/Zeus[EB/OL]. .
|
| [5] |
GREAT . A fanny equation: “i am your father, stuxnet”2015[EB/OL]. .
|
| [6] |
QIAO Y C , YUN X , ZHANG Y . Fast reused function retrieval method based on simhash and inverted index[C]// 2016 15th IEEE Interna-tional Conference on Trust, Security and Privacy in Computing and Communications. 2016.
|
| [7] |
BENCSATH B , PEK G , BUTTYAN L , et al Duqu: a stuxnet-like malware found in the wild[R]. CrySyS Lab Technical Report. 2011.
|
| [8] |
GREAT . Cloud Atlas: RedOctober APT is back in style 2014[R/OL]. .
|
| [9] |
LABS F S . PITOU: The “silent” resurrection of the notorious Srizbi kernel spambot[R]. . 2014.
|
| [10] |
MYLES G , COLLBERG C , K-gram based software birthmarks[C]// Proceedings of the 2005 ACM Symposium on Applied Computing. 2005:314-318.
|
| [11] |
S?BJ?RNSEN A , WILLCOCK J , PANAS T , et al. Detecting code clones in binary executables[C]// 18th International Symposium on Software Testing and Analysis. 2009:117-128.
|
| [12] |
LAKHOTIA A , PREDA M D , GIACOBAZZI R . Fast location of similar code fragments using semantic'juice'[C]// 2nd ACM SIGPLAN Program Protection and Reverse Engineering Workshop. 2013:1-6.
|
| [13] |
RUTTENBERG B , MILES C , KELLOGG L , et al. Identifying shared software components to support malware forensics[J]. Detection of In-trusions and Malware, and Vulnerability Assessment: Springer, 2014,21-40.
|
| [14] |
OUELLETTE J , PFEFFER A , LAKHOTIA A , et al. Countering malware evolution using cloud-based learning[C]// 2013 8th International Con-ference on Malicious and Unwanted Software, 2013.
|
| [15] |
DAVID Y , YAHAV E , Tracelet-based code search in executables[C]// ACM SIGPLAN Notices. 2014.
|
| [16] |
ALRABAEE S , SHIRANI P , WANG L , et al. SIGMA: a semantic inte-grated graph matching approach for identifying reused functions in binary code[J]. Digital Investigation, 2015,12:S61-S71.
|
| [17] |
CHARIKAR M S . Similarity estimation techniques from rounding algorithms[C]// 34th Annual ACM Symposium on Theory of Comput-ing. 2002.
|
| [18] |
MANKU G S , JAIN A , SARMA A D . Detecting near-duplicates for web crawling[C]// 16th International Conference on World Wide Web. Banff, Alberta, Canada, 2007:141-50.
|
| [19] |
UDDIN M S , ROY C K , SCHNEIDER K A , et al. On the effectiveness of simhash for detecting near-miss clones in large scale software sys-tems[C]// 2011 18th Working Conference on Reverse Engineering(WCRE), 2011.
|
| [20] |
郭颖, 陈峰宏, 周明辉 . 大规模代码克隆的检测方法[J]. 计算机科学与探索, 2014(4):417-426. GUO Y , CHEN F H , ZHOU M H . Code clone detection method for large scale source code[J]. Journal of Frontiers of Computer Science &Technology, 2014(4):417-426.
|
| [21] |
TIMO J , RINNE S L . ssh-3.2.9.1 2003[EB/OL]. .
|
| [22] |
VX Heaven[EB/OL]. .
|
| [23] |
Wikipedia . Agobot 2016[EB/OL]. .
|
| [24] |
KHOO W M , MYCROFT A , ANDERSON R , et al. Rendezvous: a search engine for binary code[C]// Proceedings of the 10th Working Confer-ence on Mining Software Repositories. 2013.
|

 ),张永铮2,3
),张永铮2,3