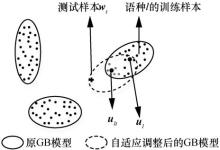
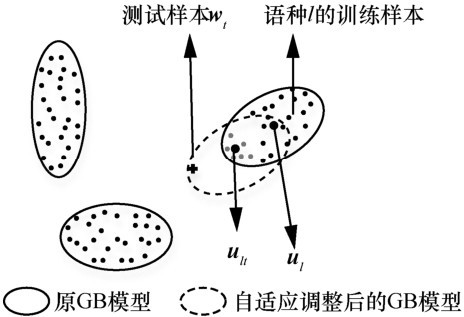
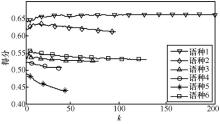
| [1] |
蒋兵 . 语种识别深度学习方法研究[D]. 合肥:中国科学技术大学, 2015.
|
|
JIAN B . Deep learning based spoken language identification[D]. Hefei:University of Science and Technology of China, 2015.
|
| [2] |
DEHAK N , KENNY P , DEHAK R ,et al. Front-end factor analysis for speaker verification[J]. IEEE Transactions on Audio,Speech,and Language Processing, 2011,19(4): 788-798.
|
| [3] |
DEHAK N , TORRES-CARRASQUILLO P A , REYNOLDS D A , et al ,et al. Language recognition via i-vectors and dimensionality reduction[C]// The 12th Annual Conference of the International Speech Communication Association (Interspeech). 2011: 857-860.
|
| [4] |
MARTINEZ D , PLCHOT O , BURGET L ,et al. Language recognition in iVectors space[C]// The Interspeech 2011,Conference of the International Speech Communication Association. 2011: 861-864.
|
| [5] |
PENAGARIKANO M , VARONA A , DIEZ M ,et al. Study of different backends in a state-of-the-art language recognition system[C]// Interspeech. 2012: 2049-2052.
|
| [6] |
杨绪魁, 屈丹, 张文林 . 正交拉普拉斯语种识别方法[J]. 自动化学报, 2014,40(8): 1812-1818.
|
|
YANG X K , QU D , ZHANG W L . An orthogonal laplacian language recognition approach[J]. Acta Automatica Sinica, 2014,40(8): 1812-1818.
|
| [7] |
LIU G , HASAN T , BORIL H ,et al. An investigation on back-end for speaker recognition in multi-session enrollment[C]// 2013 IEEE International Conference on Acoustics,Speech and Signal Processing (ICASSP),IEEE, 2013: 7755-7759.
|
| [8] |
VAN L D A , BRUMMER N . Channel-dependent GMM and multi-class logistic regression models for language recognition[C]// 2006 IEEE Odyssey-The Speaker and Language Recognition Workshop.IEEE. 2006: 1-8.
|
| [9] |
BENZ M F , GAUVAIN J L , LAMEL L . Language score calibration using adapted Gaussian back-end[C]// Interspeech 2009. 2009: 2191-2194.
|
| [10] |
SENOUSSAOUI M , KENNY P,BRüMMER N , et al . Mixture of PLDA models in i-vector space for gender-independent speaker recognition[C]// Interspeech. 2011: 25-28.
|
| [11] |
KANAGASUNDARAM A , VOGT R J , DEAN D B ,et al. PLDA based speaker recognition on short utterances[C]// The Speaker and Language Recognition Workshop (Odyssey 2012). ISCA, 2012.
|
| [12] |
SARKAR A K , MATROUF D , BOUSQUET P M ,et al. Study of the effect of i-vector modeling on short and mismatch utterance duration for speaker verification[C]// Interspeech. 2012: 2662-2665.
|
| [13] |
WANG M G , SONG Y , JIANG B ,et al. Exemplar based language recognition method for short-duration speech segments[C]// 2013 IEEE International Conference on Acoustics,Speech and Signal Processing. IEEE, 2013: 7354-7358.
|
| [14] |
SONG Y , HONG X , JIANG B ,et al. Deep bottleneck network based i-vector representation for language identification[C]. Interspeech 2015. 2015: 398-402.
|
| [15] |
洪新海, 宋彦, 蒋兵 ,等. 采用 DBN 的 TV 改进方法在语种识别中的应用[J]. 信号处理, 2015,31(9): 1152-1158.
|
|
HONG X H , SONG Y , JIANG B ,et al. Improved total variability modeling method using deep bottleneck network for language identification[J]. Journal of Signal Processing, 2015,31(9): 1152-1158.
|
| [16] |
王梦鸽 . 短时语种识别若干问题研究[D]. 合肥:中国科学技术大学, 2014.
|
|
WANG M G . Research on problems in spoken language identification with short-duration segments[D]. Hefei:University of Science and Technology of China, 2014.
|
| [17] |
ZHANG K , HUTTER M , JIN H . A new local distance-based outlier detection approach for scattered real-world data[M]// Advances in Knowledge Discovery and Data Mining. Springer Berlin Heidelberg, 2009: 813-822.
|
| [18] |
BISWAS S , ROHDIN J , SHINODA K . I-vector selection for effective PLDA modeling in speaker recognition[C]// Proceedings Odyssey 2014-The Speaker and Language Recognition Workshop. 2014: 100-105.
|
| [19] |
VAN DER M L , HINTON G . Visualizing data using t-SNE[J]. Journal of Machine Learning Research, 2008,9(2605): 2579-2605.
|
| [20] |
MARTIN A F , PRZYBOCKI M A . NIST 2003 language recognition evaluation[C]// Interspeech. 2003.
|
| [21] |
MARTIN A F , GREENBERG C S . The 2009 NIST language recognition evaluation[C]// Odyssey. 2010:30.
|