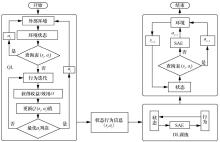
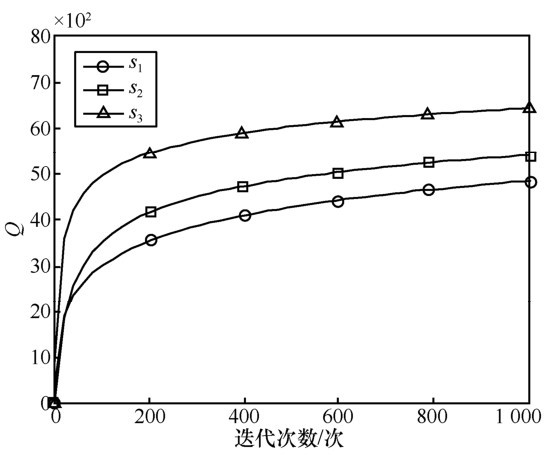
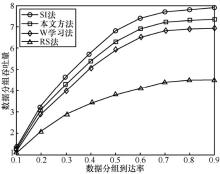
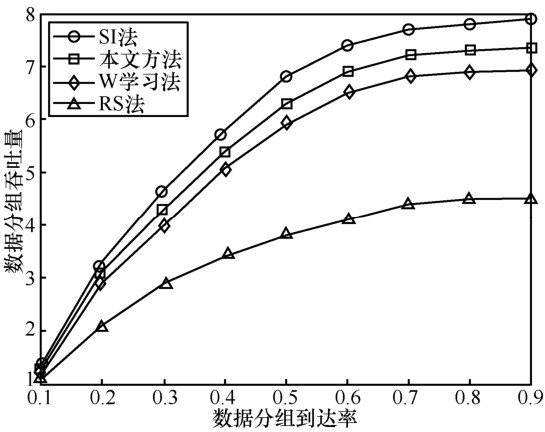
| [17] |
KOBAYASHI T , SHIBUYA T , TANAKA F ,et al. Q-learning in continuous state-action space by using a selective desensitization neural network[J]. IEICE Technical Report Neurocomputing, 2011,111: 119-123.
|
| [18] |
周文云 . 强化学习维数灾问题解决方法研究[D]. 苏州:苏州大学, 2009.
|
| [1] |
朱江, 徐斌阳, 李少谦 . 一种基于马尔可夫决策过程的认知无线电网络传输调度方案[J]. 电子与信息学报, 2009,31(8): 2019-2023.
|
|
ZHU J , XU B Y , LI S Q . A transmission and scheduling scheme based on Markov decision process in cognitive radio networks[J]. Journal of Electronics & Information Technology, 2009,31(8): 2019-2023.
|
| [18] |
ZHOU W Y . Research on the curse of dimensionality in reinforcement learning[D]. Suzhou:Soochow University, 2009.
|
| [19] |
LIU W , LIU N , SUN H ,et al. Dispatching algorithm design for elevator group control system with Q-learning based on a recurrent neural network[C]// Control and Decision Conference. 2013: 3397-3402.
|
| [2] |
ZHU J , PENG Z Z , LI F . A transmission and scheduling scheme based on W-learning algorithm in wireless networks[C]// 8th International ICST Conference on Communications and Networking in China (CHINACOM). 2013: 85-90.
|
| [3] |
LI H , HAN Z . Competitive spectrum access in cognitive radio networks:graphical game and learning[C]// Wireless Communications and Networking Conference (WCNC). 2010: 1-6.
|
| [20] |
WEI Q , LEWISF L , SUN Q ,et al. Discrete-time deterministic Q-learning:a novel convergence analysis[J]. IEEE transactions on cybernetics, 2016: 1-14.
|
| [21] |
李军, 徐玖平 . 运筹学:非线性系统优化[M]. 北京: 科学出版社, 2003.
|
| [4] |
林晓辉, 谭宇, 张俊玲 ,等. 无线传输中基于马尔可夫决策的高能效策略[J]. 系统工程与电子技术, 2014,36(7): 1433-1438.
|
|
LIN X H , TAN Y , ZHANG J L ,et al. MDP-based energy efficient policy for wireless transmission[J]. Systems Engineering and Electronics, 2014,36(7): 1433-1438.
|
| [5] |
WANG H S , MOAYERI N . Finite-state Markov channel-a useful model for radio communication channels[J]. IEEE Transactions on Vehicular Technology, 1995,44(1): 163-171.
|
| [6] |
GAO Q , ZHU G , LIN S ,et al. Robust QoS-aware cross-layer design of adaptive modulation transmission on OFDM systems in high-speed railway[J]. IEEE Access, 2016,PP(99):1.
|
| [7] |
CHEN X , CHEN W . Delay-optimal probabilistic scheduling for low-complexity wireless links with fixed modulation and coding:a cross-layer design[J]. IEEE Transactions on Vehicular Technology, 2016:1.
|
| [8] |
LAU V K N , . Performance of variable rate bit interleaved coding for high bandwidth efficiency[C]// The Vehicular Technology Conference. 2000: 2054-2058.
|
| [9] |
CHUNG S T , GOLDSMITH A J . Degrees of freedom in adaptive modulation:a unified view[C]// IEEE Transactions on Communications. 2001: 1561-1571.
|
| [10] |
WEI Q , LIU D , SHI G . A novel dual iterative Q-learning method for optimal battery management in smart residential environments[J]. IEEE Transactions on Industrial Electronics, 2015,62(4): 2509-2518.
|
| [11] |
NI J , LIU M , REN L ,et al. A multiagent Q-learning-based optimal allocation approach for urban water resource management system[J]. IEEE Transactions on Automation Science & Engineering, 2014,11(1): 204-214.
|
| [12] |
SILVER D , HUANG A , MADDISON C J ,et al. Mastering the game of Go with deep neural networks and tree search[J]. Nature, 2016,529(7587): 484-489.
|
| [13] |
WEI C , ZHANG Z , QIAO W ,et al. An adaptive network-based reinforcement learning method for MPPT control of PMSG wind energy conversion systems[J]. IEEE Transactions on Power Electronics, 2016:1.
|
| [14] |
KIM T , SUN Z , COOK C ,et al. Invited-cross-layer modeling and optimization for electromigration induced reliability[C]// Design Automation Conference. 2016: 1-6.
|
| [15] |
COMSA I S , ZHANG S , AYDIN M . A novel dynamic Q-learning-based scheduler technique for LTE-advanced technologies using neural networks[C]// Conference on Local Computer Networks. 2012: 332-335.
|
| [16] |
TENG T H , TAN A H . Fast reinforcement learning under uncertainties with self-organizing neural networks[C]// IEEE / WIC / ACM International Conference on Web Intelligence and Intelligent Agent Technology. 2015: 51-58.
|
| [21] |
LI J , XU J P . Operations research:nonlinear system optimization[M]. Beijing: Science PressPress, 2003.
|

 ),宋永辉,刘亚利
),宋永辉,刘亚利