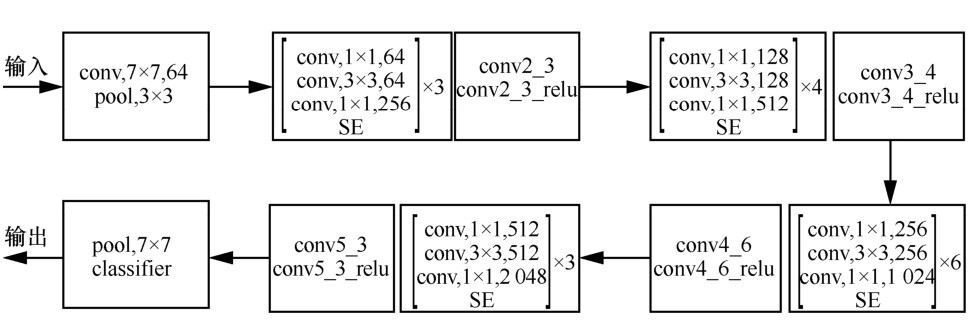
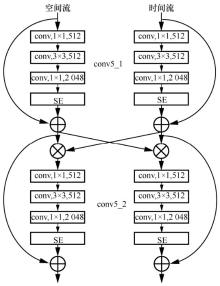
| [1] |
HERATH S , HARANDI M , PORIKLI F . Going deeper into action recognition:a survey[J]. Image and Vision Computing, 2017(60): 4-21.
|
| [2] |
胡琼, 秦磊, 黄庆 . 基于视觉的人体动作识别综述[J]. 计算机学报, 2013,36(12): 2512-2524.
|
|
HU Q , QIN L , HUANG Q . Overview of human action recognition based on vision[J]. Chinese Journal of Computers, 2013,36(12): 2512-2524.
|
| [3] |
朱煜, 赵江坤, 王逸宁 . 基于深度学习的人体行为识别算法综述[J]. 自动化学报, 2016,42(6): 848-857.
|
|
ZHU Y , ZHAO J K , WANG Y N . A review of human action recognition based on deep learning[J]. ACTA Automatica Sinica, 2016,42(6): 848-857.
|
| [4] |
罗会兰, 王婵娟, 卢飞 . 视频行为识别综述[J]. 通信学报, 2018,39(6): 173-184.
|
|
LUO H L , WANG C J , LU F . Survey of video behavior recognition[J]. Journal on Communications, 2018,39(6): 173-184.
|
| [5] |
BOBICK A F , DAVIS J W . An appearance-based representation of action[C]// International Conference on Pattern Recognition. IEEE, 1996: 307-312.
|
| [6] |
WEINLAND D , RONFARD R , BOYER E . Free viewpoint action recognition using motion history volumes[J]. Computer Vision and Image Understanding, 2006,104(2-3): 249-257.
|
| [7] |
YILMAZ A , SHAH M . Actions sketch:a novel action representation[C]// Computer Vision and Pattern Recognition. IEEE, 2005: 984-989.
|
| [8] |
WANG H , ULLAH M M , KLASER A ,et al. Evaluation of local spatio-temporal features for action recognition[C]// British Machine Vision Conference. BMVA, 2009: 1-11.
|
| [9] |
KLASER A , SCHMID C . Action recognition by dense trajectories[C]// Computer Vision and Pattern Recognition. IEEE, 2011: 3169-3176.
|
| [10] |
WANG H , SCHMID C . Action recognition with improved trajectories[C]// International Conference on Computer Vision. IEEE, 2013: 3551-3558.
|
| [11] |
JI S , XU W , YANG M ,et al. 3D convolutional neural networks for human action recognition[J]. IEEE Transactions on Pattern Analysis &Machine Intelligence, 2013,35(1): 221-231.
|
| [12] |
DU T , BOURDEV L , FERGUS R ,et al. Learning spatiotemporal features with 3D convolutional networks[C]// International Conference on Computer Vision. IEEE, 2015: 4489-4497.
|
| [13] |
TRAN D , RAY J , SHOU Z ,et al. ConvNet architecture search for spatiotemporal feature learning[J]. Computing Research Repository, 2017,16(8): 178-190.
|
| [14] |
KARPATHY A , TODERICI G , SHETTY S ,et al. Large-scale video classification with convolutional neural networks[C]// Computer Vision and Pattern Recognition. IEEE, 2014: 1725-1732.
|
| [15] |
SIMONYAN K , ZISSERMAN A . Two-stream convolutional networks for action recognition in videos[C]// Neural Information Processing Systems. NeurlPS, 2014: 568-576.
|
| [16] |
WANG L , XIONG Y , WANG Z ,et al. Temporal segment networks:towards good practices for deep action recognition[J]. ACM Transactions on Information Systems, 2016,22(1): 20-36.
|
| [17] |
FEICHTENHOFER C , PINZ A , WILDES R P . Spatiotemporal residual networks for video action recognition[C]// Neural Information Processing Systems. NeurlPS, 2016: 3468-3476.
|
| [18] |
WANG X , FARHADI A , GUPTA A . Actions~transformations[C]// Computer Vision and Pattern Recognition. IEEE, 2016: 2658-2667.
|
| [19] |
WANG Y , LONG M , WANG J ,et al. Spatiotemporal pyramid network for video action recognition[C]// Computer Vision and Pattern Recognition. IEEE, 2017: 2097-2106.
|
| [20] |
FEICHTENHOFER C , PINZ A , ZISSERMAN A . Convolutional two-stream network fusion for video action recognition[C]// Computer Vision and Pattern Recognition. IEEE, 2016: 1933-1941.
|
| [21] |
FEICHTENHOFER C , PINZ A , WILDES R P . Spatiotemporal multiplier networks for video action recognition[C]// Computer Vision and Pattern Recognition. IEEE, 2017: 7445-7454.
|
| [22] |
WANG L , GE L , LI R ,et al. Three-stream CNNs for action recognition[J]. Pattern Recognition Letters, 2017,92(C): 33-40.
|
| [23] |
BILEN H , FERNANDO B , GAVVES E ,et al. Action recognition with dynamic image networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018,40(12): 2799-2813.
|
| [24] |
HE K , ZHANG X , REN S ,et al. Deep residual learning for image recognition[C]// Computer Vision and Pattern Recognition. IEEE, 2016: 770-778.
|
| [25] |
HU J , SHEN L , SUN G . Squeeze-and-excitation networks[C]// Computer Vision and Pattern Recognition. IEEE, 2018: 7132-7141.
|
| [26] |
SOOMRO K , ZAMIR A R , SHAH M . UCF101:a dataset of 101 human actions classes from videos in the wild[J]. Computer Science, 2012,3(12): 1-9.
|
| [27] |
KUEHNE H , JHUANG H , GARROTE E ,et al. HMDB:a large video database for human motion recognition[C]// International Conference on Computer Vision. IEEE, 2011: 2556-2563.
|
| [28] |
ZHANG C L , ZHANG H , WEI X S ,et al. Deep bimodal regression for apparent personality analysis[C]// European Conference on Computer Vision Workshops. Springer, 2016: 311-324.
|
| [29] |
KHOWAJA S A , LEE S-L . Semantic image networks for human action recognition[J]. The Computing Research Repository, 2019,21(1): 1-30.
|