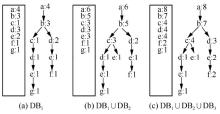
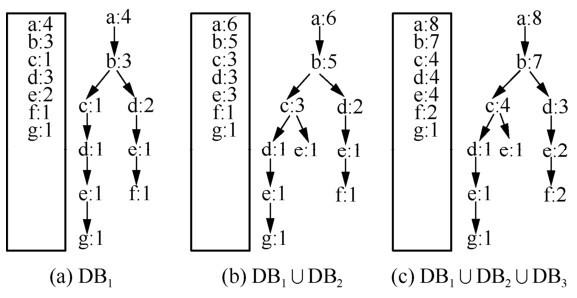
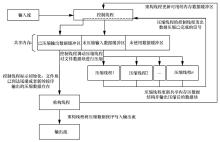
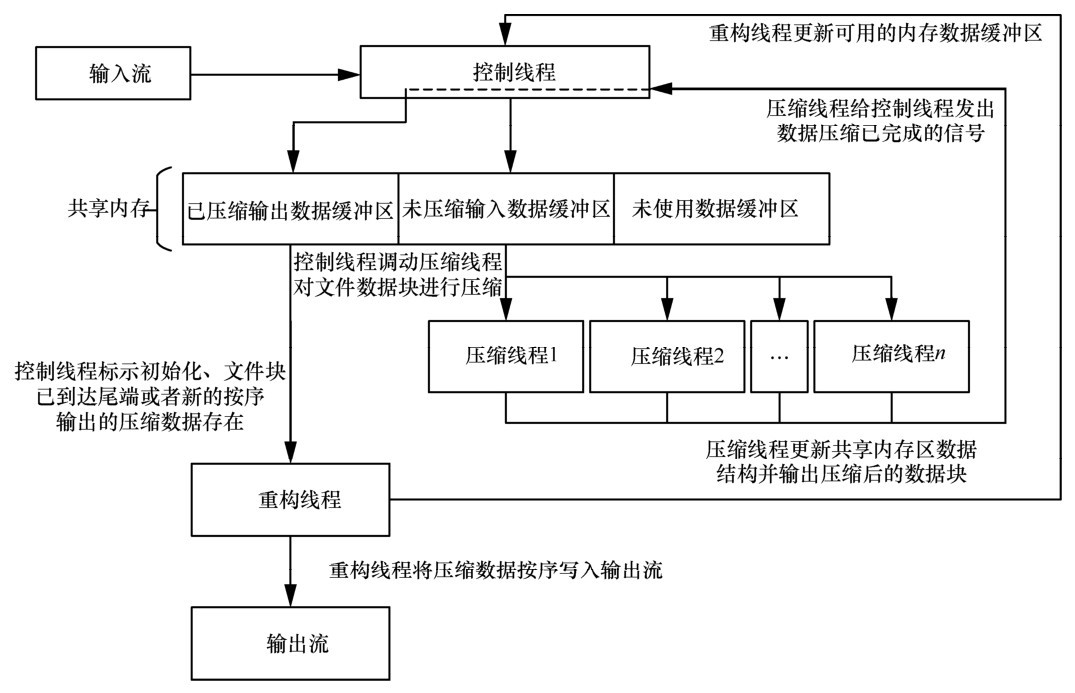
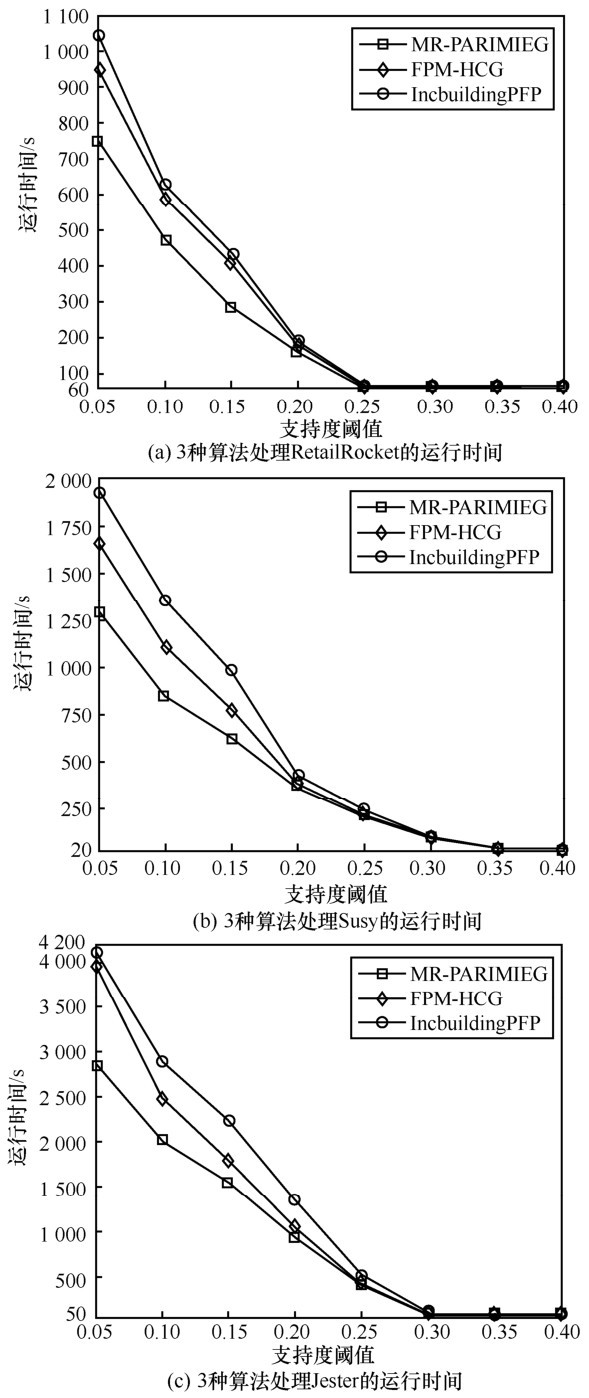
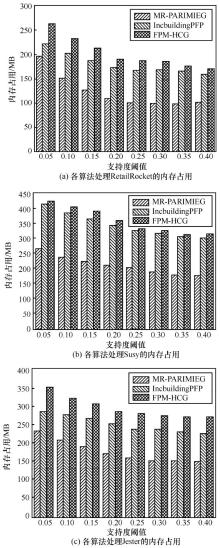
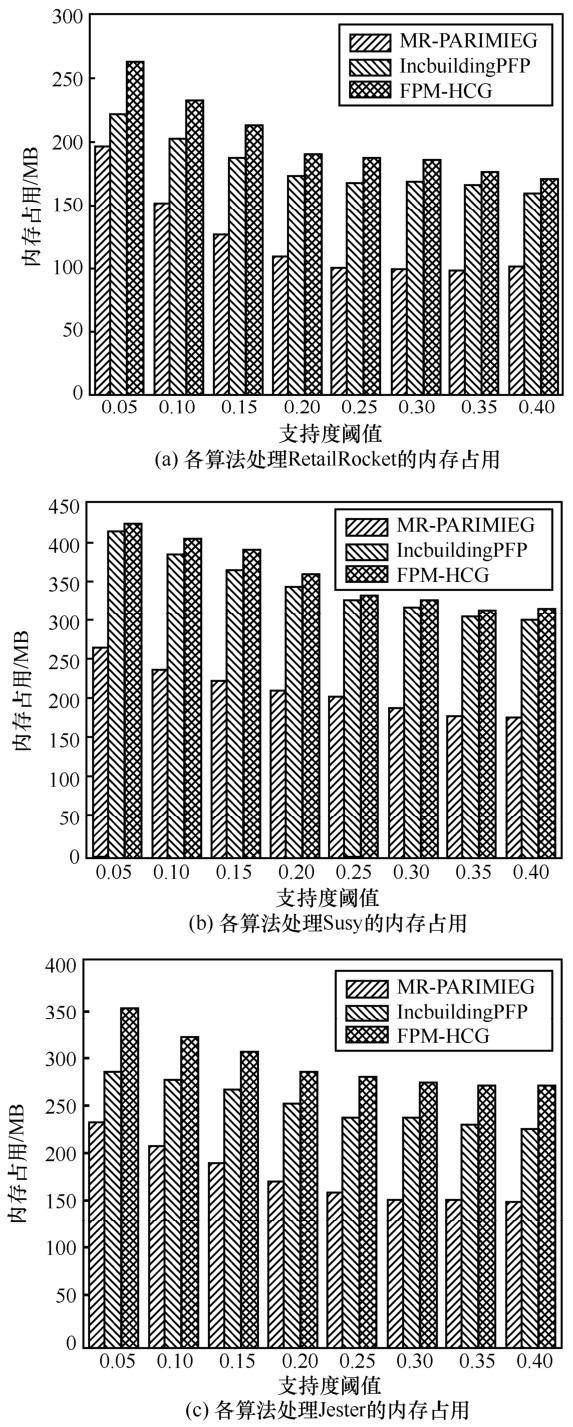
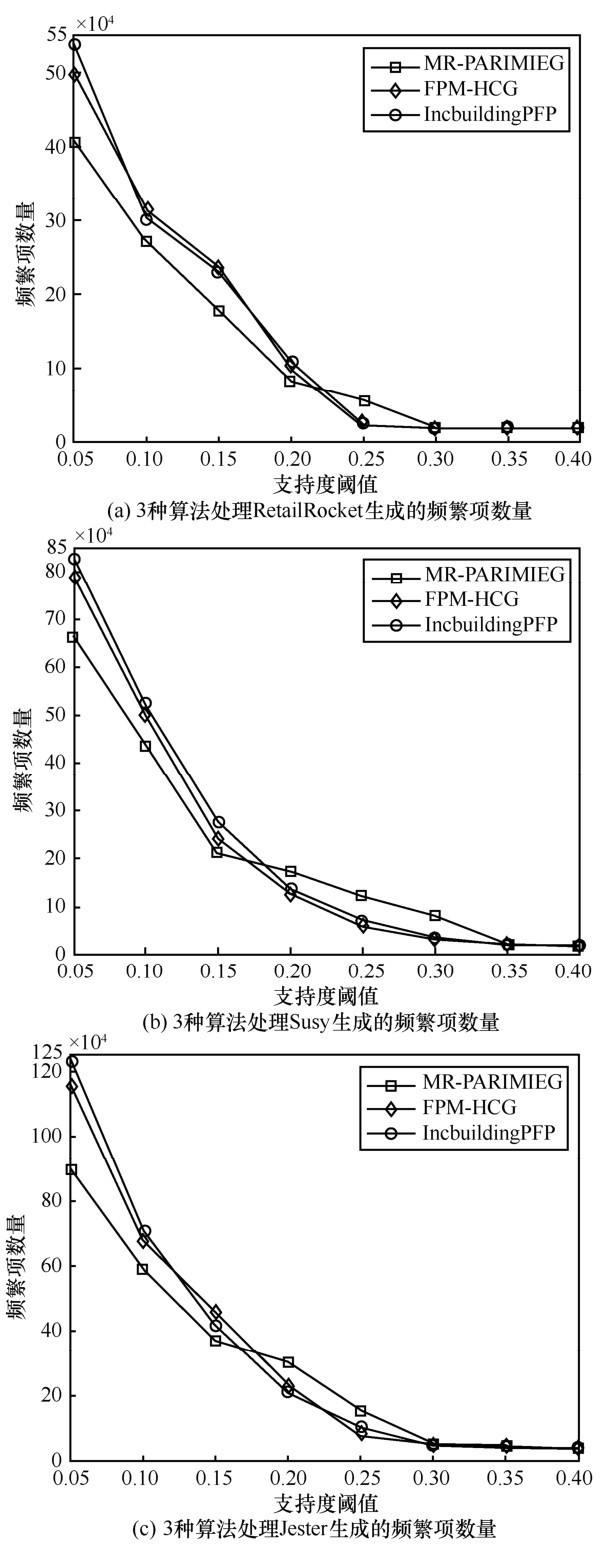
| [1] |
HAND D J , ADAMS N M . Data mining[EB].(2015-06-22)[2020-11-13].
|
| [2] |
KAMSU-FOGUEM B , RIGAL F , MAUGET F . Mining association rules for the quality improvement of the production process[J]. Expert Systems WithApplications, 2013,40(4): 1034-1045.
|
| [3] |
SáNCHEZ D , VILA M A , CERDA L ,et al. Association rules applied to credit card fraud detection[J]. Expert Systems WithApplications, 2009,36(2): 3630-3640.
|
| [4] |
BHANDARI A , GUPTA A , DAS D . Improvised apriori algorithm using frequent pattern tree for real time applications in data mining[J]. Procedia Computer Science, 2015,46: 644-651.
|
| [5] |
ZHANG W , LIAO H Z , ZHAO N . Research on the FP growth algorithm about association rule mining[C]// 2008 International Seminar on Business and Information Management. Piscataway:IEEE Press, 2008: 315-318.
|
| [6] |
LI Z F , LIU X F , CAO X . A study on improved eclat data mining algorithm[J]. Advanced Materials Research, 2011,328: 1896-1899.
|
| [7] |
LEUNG C K S , KHAN Q I , HOQUE T . CanTree:a tree structure for efficient incremental mining of frequent patterns[C]// Fifth IEEE International Conference on Data Mining. Piscataway:IEEE Press, 2005: 1-8.
|
| [8] |
KUSUMAKUMARI V , SHERIGAR D , CHANDRAN R ,et al. Frequent pattern mining on stream data using Hadoop CanTree-GTree[J]. Procedia Computer Science, 2017,115: 266-273.
|
| [9] |
DEAN J , GHEMAWAT S . MapReduce:simplified data processing on large clusters[J]. Communications of the ACM, 2008,51(1): 107-113.
|
| [10] |
SONG Y G , CUI H M , FENG X B . Parallel incremental frequent itemset mining for large data[J]. Journal of Computer Science and Technology, 2017,32(2): 368-385.
|
| [11] |
胡军, 潘皓安 . 基于Can树的关联规则增量更新算法改进[J]. 重庆邮电大学学报(自然科学版), 2018,30(4): 558-563.
|
|
HU J , PAN H A . Improved incremental updating algorithm of association rules based on Can-tree[J]. Journal of Chongqing University of Posts and Telecommunications (Natural Science Edition), 2018,30(4): 558-563.
|
| [12] |
RAGAVENTHIRAN J , KAVITHADEVI M K . Map-optimize-reduce:CAN tree assisted FP-growth algorithm for clusters based FP mining on Hadoop[J]. Future Generation Computer Systems, 2020,103: 111-122.
|
| [13] |
申玲艳 . MapReduce计算模式的性能优化设计及其应用[J]. 信息与电脑(理论版), 2016(14): 49-50.
|
|
SHEN L Y . MapReduce computing model designed to performance optimization and applications[J]. China Computer & Communication, 2016(14): 49-50.
|
| [14] |
CAO Y , WANG H . Communication optimisation for intermediate data of MapReduce computing model[J]. International Journal of Computational Science and Engineering, 2020,21(2): 226-233.
|
| [15] |
KIM J , HWANG B . Real-time stream data mining based on CanTree and Gtree[J]. Information Sciences, 2016,367: 512-528.
|
| [16] |
LIANG J , SHI Z , LI D ,et al. Information entropy,rough entropy and knowledge granulation in incomplete information systems[J]. International Journal of General Systems, 2006,35(6): 641-654.
|
| [17] |
KOHLAS J , MONNEY P A . A mathematical theory of hints:an approach to the Dempster-Shafer theory of evidence[M]. Berlin: Springer Science & Business Media, 2013.
|
| [18] |
KANE J , YANG Q . Compression speed enhancements to LZO for multi-core systems[C]// 2012 IEEE 24th International Symposium on Computer Architecture and High Performance Computing. Piscataway:IEEE Press, 2012: 108-115.
|
| [19] |
METAWA N , HASSAN M K , ELHOSENY M . Genetic algorithm based model for optimizing bank lending decisions[J]. Expert Systems With Applications, 2017,80: 75-82.
|
| [20] |
BART G . Frequent itemset mining dataset repository[EB].(2020-03-01)[2020-11-13].
|