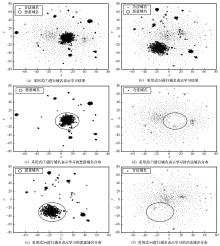
| [1] |
ZHAUNIAROVICH Y , KHALIL I , YU T ,et al. A survey on malicious domains detection through DNS data analysis[J]. ACM Computing Surveys, 2018,51(4): 1-36.
|
| [2] |
GAO H Y , YEGNESWARAN V , JIANG J ,et al. Reexamining DNS from a global recursive resolver perspective[J]. IEEE/ACM Transactions on Networking, 2016,24(1): 43-57.
|
| [3] |
WANG X , ZHENG K F , NIU X X ,et al. Detection of command and control in advanced persistent threat based on independent access[C]// Proceedings of 2016 IEEE International Conference on Communications (ICC). Piscataway:IEEE Press, 2016: 1-6.
|
| [4] |
彭成维, 云晓春, 张永铮 ,等. 一种基于域名请求伴随关系的恶意域名检测方法[J]. 计算机研究与发展, 2019,56(6): 1263-1274.
|
|
PENG C W , YUN X C , ZHANG Y Z ,et al. Detecting malicious do-mains using co-occurrence relation between DNS query[J]. Journal of Computer Research and Development, 2019,56(6): 1263-1274.
|
| [5] |
YEDIDIA J S , FREEMAN W T , WEISS Y . Understanding belief propagation and its generalizations[J]. Exploring Artificial Intelligence in the New Millennium, 2003,8: 236-239.
|
| [6] |
MANADHATA P K , YADAV S , RAO P ,et al. Detecting malicious domains via graph inference[M]. Cham: Springer International Publishing, 2014.
|
| [7] |
KHALIL I , YU T , GUAN B . Discovering malicious domains through passive DNS data graph analysis[C]// Proceedings of the 11th ACM on Asia Conference on Computer and Communications Security. New York:ACM Press, 2016: 663-674.
|
| [8] |
LEE J , LEE H . GMAD:graph-based malware activity detection by DNS traffic analysis[J]. Computer Communications, 2014,49: 33-47.
|
| [9] |
臧小东, 龚俭, 胡晓艳 . 基于 AGD 的恶意域名检测[J]. 通信学报, 2018,39(7): 15-25.
|
|
ZANG X D , GONG J , HU X Y . Detecting malicious domain names based on AGD[J]. Journal on Communications, 2018,39(7): 15-25.
|
| [10] |
PENG C W , YUN X C , ZHANG Y Z ,et al. Discovering malicious domains through alias-canonical graph[C]// Proceedings of 2017 IEEE Trustcom/BigDataSE/ICESS. Piscataway:IEEE Press, 2017: 225-232.
|
| [11] |
ZOU F T , ZHANG S Y , RAO W X ,et al. Detecting malware based on DNS graph mining[J]. International Journal of Distributed Sensor Networks, 2015,2015: 1-12.
|
| [12] |
SUN Y Z , HAN J W . Mining heterogeneous information networks:principles and methodologies[J]. Synthesis Lectures on Data Mining and Knowledge Discovery, 2012,3(2): 1-159.
|
| [13] |
TANG J , QU M , WANG M Z ,et al. LINE:large-scale information network embedding[C]// Proceedings of the 24th International Conference on World Wide Web. New York:ACM Press, 2015: 1067-1077.
|
| [14] |
LEI K , FU Q A , NI J K ,et al. Detecting malicious domains with behavioral modeling and graph embedding[C]// Proceedings of 2019 IEEE 39th International Conference on Distributed Computing Systems (ICDCS). Piscataway:IEEE Press, 2019: 601-611.
|
| [15] |
PENG C W , YUN X C , ZHANG Y Z ,et al. MalShoot:shooting malicious domains through graph embedding on passive DNS data[M]. Cham: Springer International Publishing, 2019.
|
| [16] |
SUN X Q , TONG M K , YANG J H . HinDom:a robust malicious domain detection system based on heterogeneous information network with transductive classification[C]// Proceeding of the 22nd International Symposium on Research in Attacks,Intrusions and Defenses. Berkley:USENIX Association, 2019: 399-412.
|
| [17] |
KIPF T N , WELLING M . Semi-supervised classification with graph convolutional networks[J]. arXiv Preprint,arXiv:1609.02907, 2016.
|
| [18] |
LIU Z , LI S , ZHANG Y ,et al. Ringer:systematic mining of malicious domains by dynamic graph convolutional network[C]// Proceeding of the International Conference on Computational Science. Berlin:Springer, 2020: 379-398.
|
| [19] |
SUN X Q , YANG J H , WANG Z L ,et al. HGDom:heterogeneous graph convolutional networks for malicious domain detection[C]// Proceedings of 2020 IEEE/IFIP Network Operations and Management Symposium. Piscataway:IEEE Press, 2020: 1-9.
|
| [20] |
HE W X , GOU G P , KANG C C ,et al. Malicious domain detection via domain relationship and graph models[C]// Proceedings of 2019 IEEE 38th International Performance Computing and Communications Conference (IPCCC). Piscataway:IEEE Press, 2019: 1-8.
|
| [21] |
NSFOCUS. 2019 Botnet trend report[R]. NSFOCUS Security Labs, 2020.
|
| [22] |
MIKOLOV T , SUTSKEVER I , CHEN K ,et al. Distributed representations of words and phrases and their compositionality[C]// Proceeding of the Advances in Neural Information Processing Systems. Massachusetts:MIT Press, 2013: 3111-3119.
|
| [23] |
SCHüPPEN S , TEUBERT D , HERRMANN P ,et al. FANCI:feature-based automated NXDomain classification and intelligence[C]// Proceeding of the 27th USENIX Security Symposium. Berkley:USENIX Association, 2018: 1165-1181.
|
| [24] |
VAN D M L , HINTON G . Visualizing data using t-SNE[J]. Journal of machine learning research, 2008,9(11): 2579-2605.
|