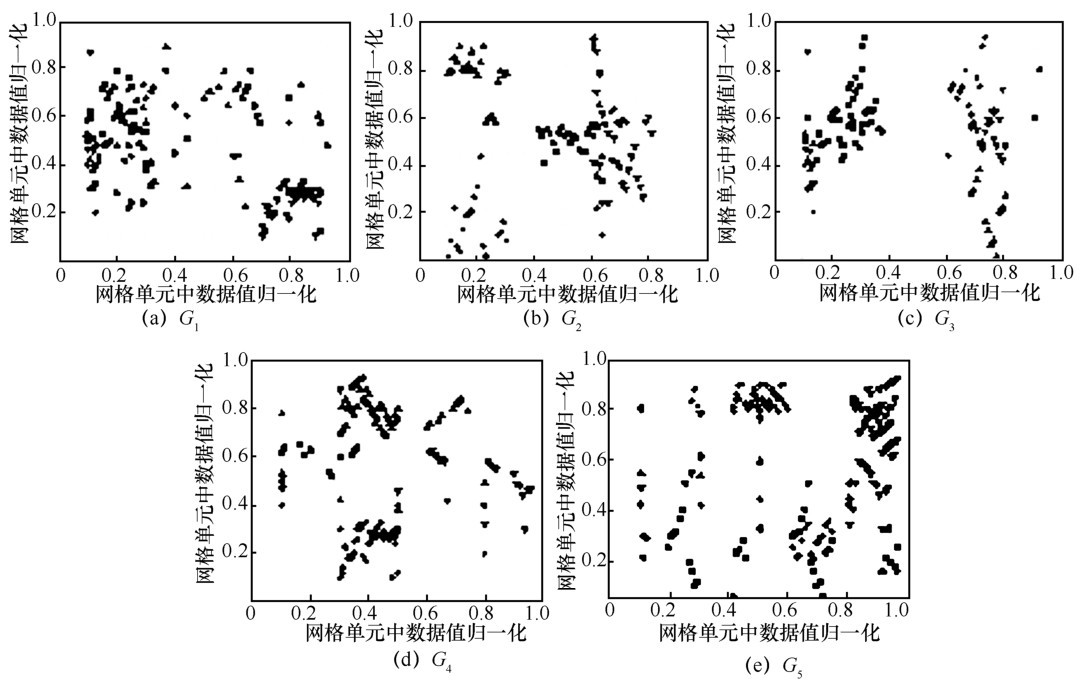
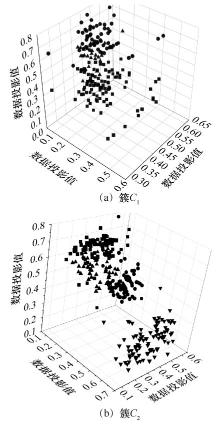
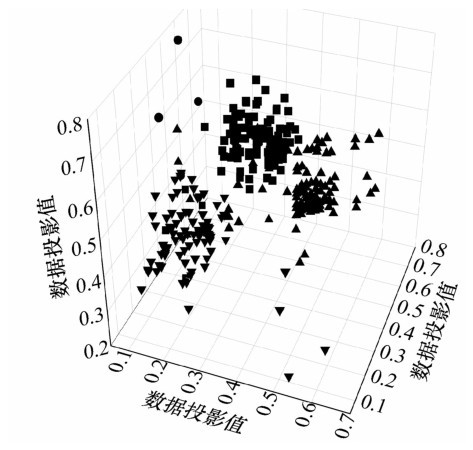
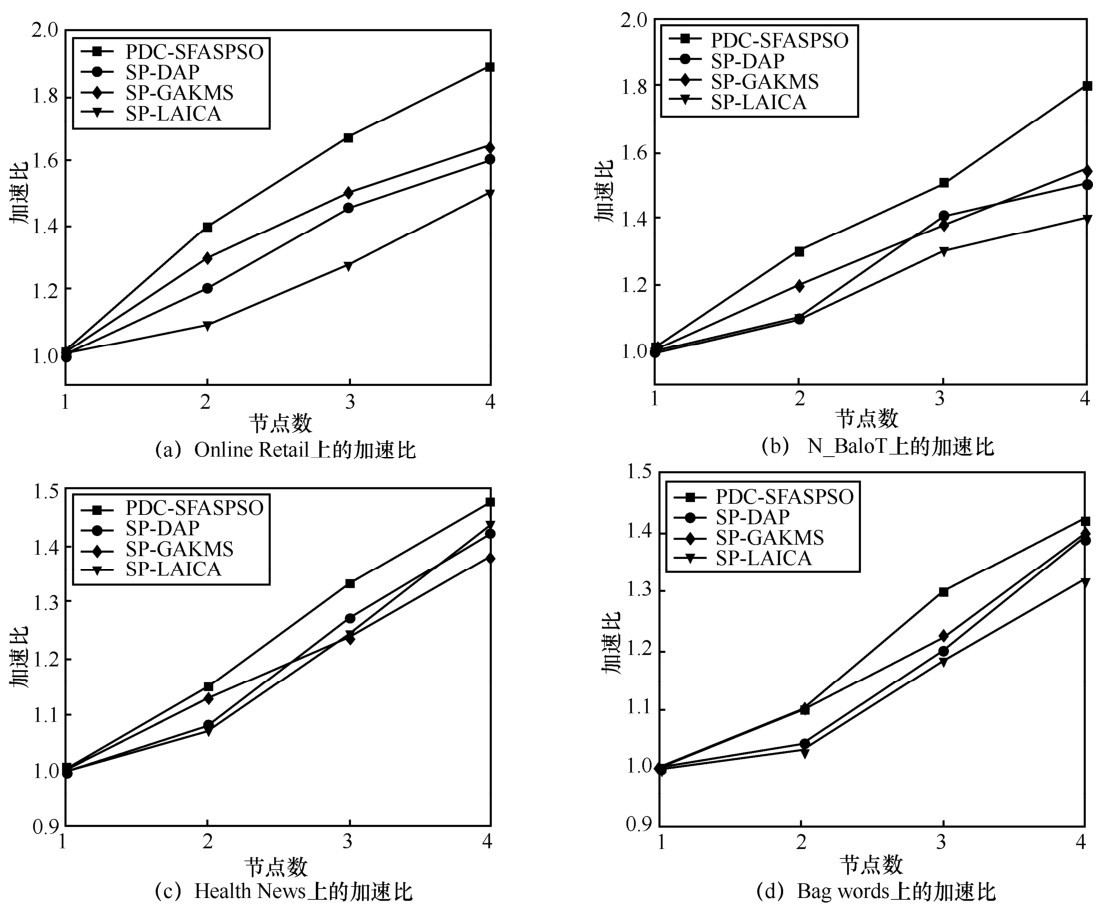
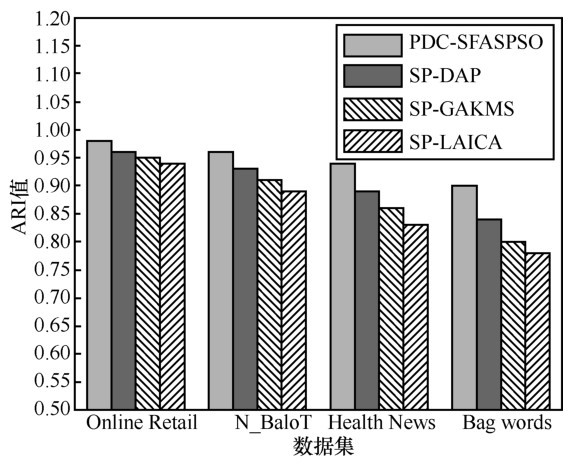
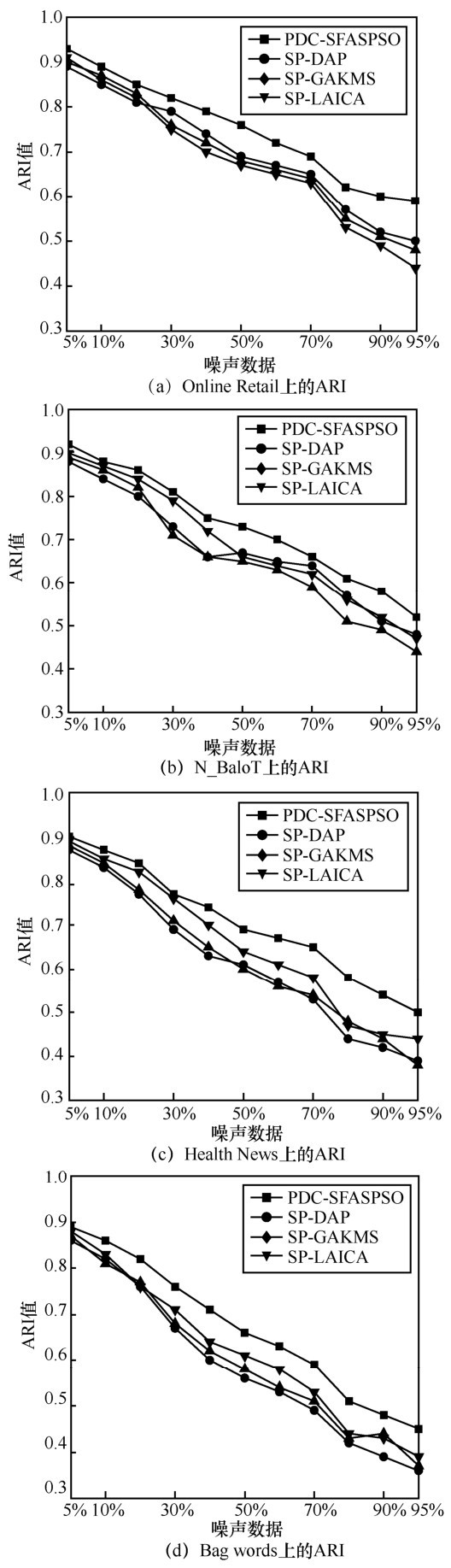
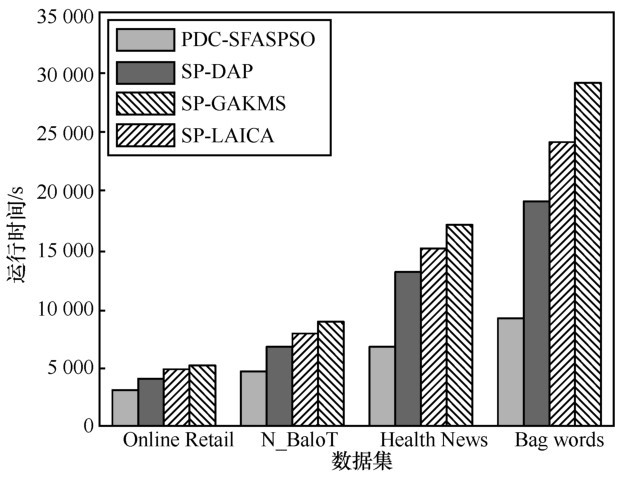
| [1] |
WANG P K , CHEN C H , PUN S H ,et al. Parallel architecture to accelerate super paramagnetic clustering algorithm[J]. Electronics Letters, 2020,56(14): 701-704.
|
| [2] |
KHAN A , ZUBAIR S . Expansion of regularized kmeans discretization machine learning approach in prognosis of dementia progression[C]// Proceedings of 2020 11th International Conference on Computing,Communication and Networking Technologies. Piscataway:IEEE Press, 2020: 1-6.
|
| [3] |
MARTANTO , ANWAR S , ROHMAT C L ,et al. Clustering of Internet network usage using the K-medoid method[J]. IOP Conference Series:Materials Science and Engineering, 2021,1088(1): 012036.
|
| [4] |
SCHUBERT E , ROUSSEEUW P J . Fast and eager k-medoids clustering:O(k) runtime improvement of the PAM,CLARA,and CLARANS algorithms[J]. Information Systems, 2021,101: 101804.
|
| [5] |
LEKHWAR S , YADAV S , SINGH A . Big data analytics in retail[R]. 2019.
|
| [6] |
WEISSMAN B , VAN D L E . Working with spark in big data clusters[R]. 2020.
|
| [7] |
MUGDHA S , CHIRAG P , AKASH A . Design and implementation of university network[J]. International Journal of Recent Technology and Engineering, 2019,8(26): 1199-1214.
|
| [8] |
王海艳, 肖亦康 . 基于密度峰值聚类的动态群组发现方法[J]. 计算机研究与发展, 2018,55(2): 391-399.
|
|
WANG H Y , XIAO Y K . Dynamic group discovery based on density peaks clustering[J]. Journal of Computer Research and Development, 2018,55(2): 391-399.
|
| [9] |
WANG B W , YIN J , HUA Q ,et al. Parallelizing K-means-based clustering on spark[C]// Proceedings of 2016 International Conference on Advanced Cloud and Big Data. Piscataway:IEEE Press, 2016: 31-36.
|
| [10] |
徐鹏程, 王诚 . K-means算法改进及基于Spark计算模型的实现[J]. 南京邮电大学学报(自然科学版), 2017,37(4): 113-118.
|
|
XU P C , WANG C . Improvement of K-means algorithm and implementation based on Spark computing model[J]. Journal of Nanjing University of Posts and Telecommunications (Natural Science Edition), 2017,37(4): 113-118.
|
| [11] |
MULTAZAM M T , DIJAYA R , DEVI N S . Index group optimization based on automatic clustering using K-means genetic algorithm[J]. Journal of Physics:Conference Series, 2019,1402(6): 066028.
|
| [12] |
许明杰, 蔚承建, 沈航 . 基于 Spark 的并行 K-means 算法研究[J]. 微电子学与计算机, 2018,35(5): 95-99.
|
|
XU M J , WEI C J , SHEN H . Research on K-means algorithm of Spark parallelization[J]. Microelectronics & Computer, 2018,35(5): 95-99.
|
| [13] |
GAO H J , LI Y T , KABALYANTS P ,et al. A novel hybrid PSO-K-means clustering algorithm using Gaussian estimation of distribution method and Lévy flight[J]. IEEE Access, 2020,8: 122848-122863.
|
| [14] |
AGRAWAL S , PATEL A . SAG cluster:an unsupervised graph clustering based on collaborative similarity for community detection in complex networks[J]. Physica A:Statistical Mechanics and Its Applications, 2021,563: 125459.
|
| [15] |
LAI M J , MCKENZIE D . Compressive sensing for cut improvement and local clustering[J]. SIAM Journal on Mathematics of Data Science, 2020,2(2): 368-395.
|
| [16] |
裴继红, 谢维信 . 势函数聚类自适应多阈值图像分割[J]. 计算机学报, 1999,22(7): 758-762.
|
|
PEI J H , XIE W X . Adaptive multi thresholds image segmentation based on potential function clustering[J]. Chinese Journal of Computers, 1999,22(7): 758-762.
|
| [17] |
ZHANG Y L , HAN J . Differential privacy fuzzy C-means clustering algorithm based on Gaussian kernel function[J]. PLoS One, 2021,16(3): e0248737.
|
| [18] |
赵姝, 许显胜, 华波 ,等. 收缩邻居节点集方法求解有向网络的最大流问题[J]. 模式识别与人工智能, 2013,26(5): 425-431.
|
|
ZHAO S , XU X S , HUA B ,et al. Contracting neighbor-node-set approach for solving maximum flow problem in directed network[J]. Pattern Recognition and Artificial Intelligence, 2013,26(5): 425-431.
|
| [19] |
PAULCHAMY B , CHIDAMBARAM S , JAYA J . An energy efficient neighbor node based clustering (EENNC) algorithm for wireless sensor networks[J]. Journal of Xidian University, 2020,14(6): 2483-2493.
|
| [20] |
SUN C , YUE S H , LI Q . Clustering characteristics of UCI dataset[C]// Proceedings of 2020 39th Chinese Control Conference (CCC). Piscataway:IEEE Press, 2020,13(5): 428-439.
|
| [21] |
DASH D R , DASH P K , BISOI R . Short term solar power forecasting using hybrid minimum variance expanded RVFLN and sine-cosine Levy flight PSO algorithm[J]. Renewable Energy, 2021,174: 513-537.
|