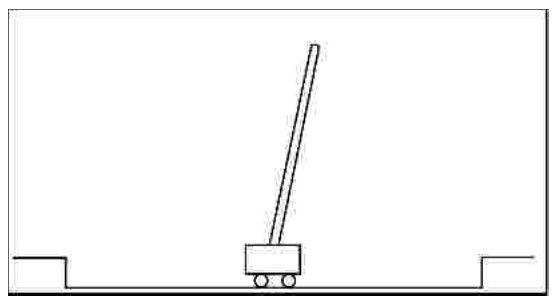
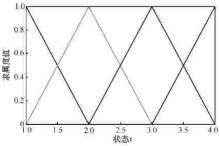
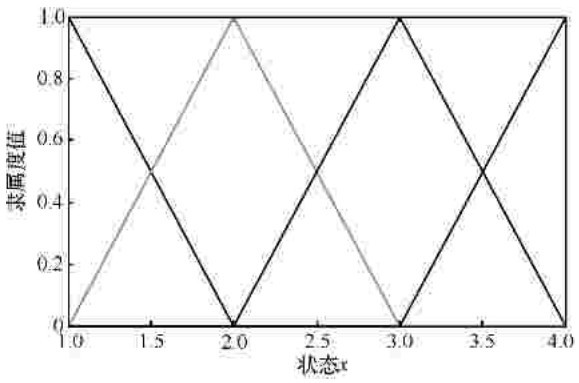
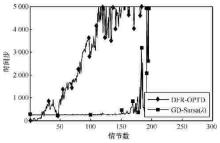
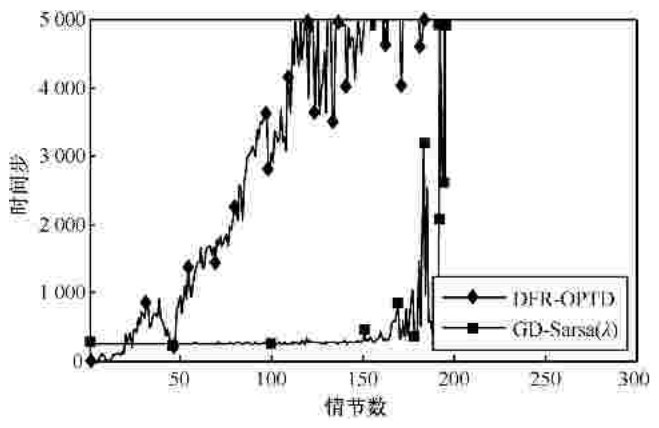
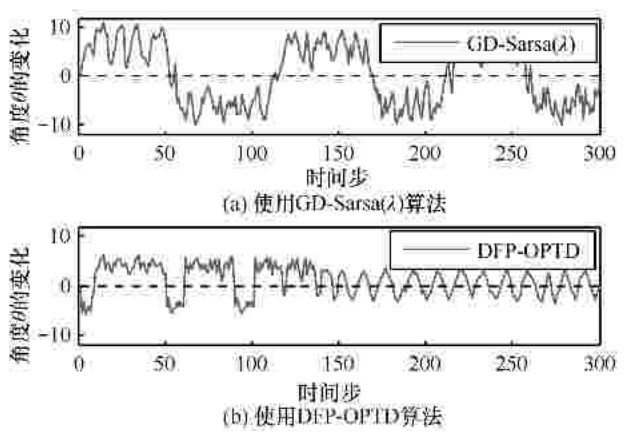
| [1] |
SUTTON R S , BARTO A G . Reinforcement Learning:An Introduc-tion[M]. Cambridge: MIT Press, 1998.
|
| [2] |
刘全, 闫其粹, 伏玉琛 ,等. 一种基于启发式奖赏函数的分层强化学习方法[J]. 计算机研究与发展, 2011,48(12): 2352-2358. LIU Q , YAN Q C , FU Y C ,et al. A hierarchical reinforcement learning method based on heuristic reward function[J]. Journal of Computer Research and Development, 2011,48(12): 2352-2358.
|
| [3] |
SUTTON R S , MCALLESTER D , SINGH S ,et al. Policy gradient methods for reinforcement learning with function approximation[A]. Proc of the 16th Annual Conference on Neural Information Processing Systems[C]. Denver, 1999. 1057-1063.
|
| [4] |
MAEI H R , SUTTON R S . GQ(?):a general gradient algorithm for? temporal difference prediction learning with eligibili y traces[A]. International Conference on Artificial General Intelligence[C]. Lugano, 2010. 91-96.
|
| [5] |
SUTTON R S,SZEPESV′ARI CS , MAEI H R . A convergent O(n)algorithm for off-policy temporal-difference learning with linear func-tion approximation[A]. Proc of the 22nd Annual Conference Neural Infor mation Processing Systems[C]. Vancouver, 2009. 1609-1616.
|
| [6] |
SHERSTOV A A , STONE P . Function approximation via tile coding:automating parameter choice[A]. Proc of the 5th Sympos um on Ab-straction,Reformulation and Approximation[C]. New York,USA, 2005. 194-205.
|
| [7] |
HEINEN M R , ENGEL P M . An incremental probabilistic neural network for regression and reinforcement learning tasks[A]. Proc of the 20th International Conference on Artificial Neural Networks[C]. Berlin, 2010. 170-179.
|
| [8] |
PAZIS J , LAGOUDAKIS M G . Learning continuous-action control policies[A]. Proc of the IEEE Symposium on Adaptive Dynamic Pro-gramming and Reinforcement Learning[C]. Washington, 2009. 169-176.
|
| [9] |
BONARINI A , LAZARIC A , MONTRONE F ,et al. Reinforcement distribution in fuzzy Q-learning[J]. Fuzzy Sets and Systems, 2009,160(10): 1420-1443.
|
| [10] |
HSU C H , JUANG C F . Self-organizing interval type-2 fuzzy Q-learning for reinforcement fuzzy control[A]. Proc of the 2011 IEEE International Conference on Systems,Man,and Cybernetics[C]. New Jersey, 2011. 2033-2038.
|
| [11] |
TADASHI H , AKINORI F , OSAMU ,et al. Fuzzy interpolation-based Q-learning with continuous states and actions[A]. Proc of the Fifth IEEE International Conference on Fuzzy Systems[C]. New York,USA, 2011. 594-600.
|
| [12] |
GLORENNEC P Y , JOUFFE L . Fuzzy Q-learning[A]. Proc of the Sixth IEEE International Conference on Fuzzy Systems[C]. Cam-bridge, 1997. 659-662.
|
| [13] |
CHANG H S , FU M C , HU J ,et al. Simulation-based Algorithms for Markov Decision Processes[M]. New York: Springer, 2007.
|
| [14] |
LUCIAN B , ROBERT B , BART D S ,et al. Reinforcement Learning and Dynamic Programming Using Function Approximation[M]. Flor-ida: CRC Press, 2010.
|
| [15] |
CASTILLO O , MELIN P . Type-2 Fuzzy Logic:Theory and Applica-tions[M]. New York: Springer, 2008.
|
| [16] |
TSITSIKLIS J N , ROY V B . An analysis of temporal-difference learning with function approximation[J]. IEEE Transactions Auto-matic Control, 1997,42(5): 674-690.
|
| [17] |
DAYAN P D . The convergence of TD(?)for general?[J]. Machine Learning, 1992,8(3-4): 341-362.
|
| [18] |
刘次华 . 随机过程[M]. 武汉: 华中科技大学出版社, 2008. LIU C H . Stochastic Process[M]. Wuhan: Huazhong University o Science and Technology PressPress, 2008.
|