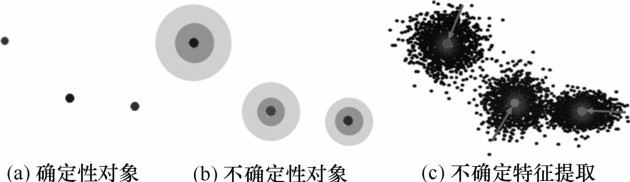
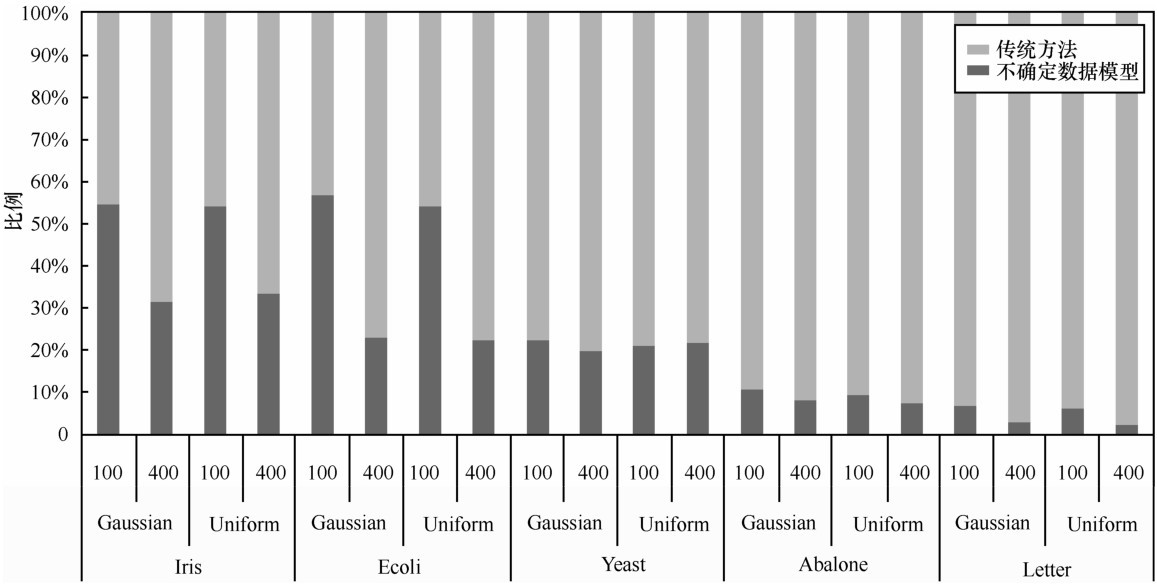
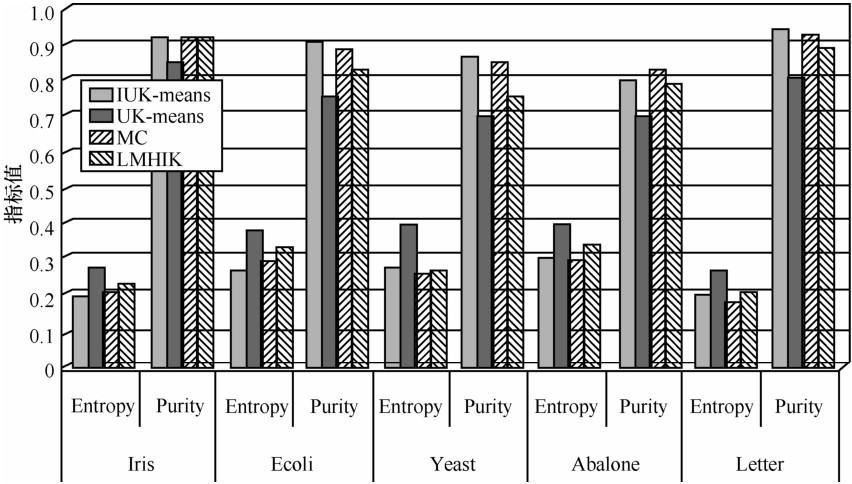
| [1] |
WANG Y , LI X , LI X ,et al. A survey of queries over uncertain data[J]. Knowledge and Information Systems, 2013,37(3): 485-530.
|
| [2] |
SEN P , DESHPANDE A . Representing and querying correlated tuples in probabilistic databases[C]// IEEE 23rd International Conference on Data Engineering. Istanbul,Turkey,IEEE, 2007: 596-605.
|
| [3] |
MUZAMMAL M , RAMAN R . Mining sequential patterns from probabilistic databases[J]. Knowledge and Information Systems, 2015,44(2): 325-358.
|
| [4] |
SOLIMAN M , ILYAS I , CHANG K . Top-k query processing in uncertain databases[C]// IEEE 23rd International Conference on Data Engineering. Istanbul,Turkey,IEEE, 2007: 896-905.
|
| [5] |
AGGARWAL C . Managing and mining uncertain data[M]. USA: SpringerPress, 2009: 1-35.
|
| [6] |
BARBARá D , GARCIA-MOLINA H , PORTER D . The management of probabilistic data[J]. IEEE Transactions on Knowledge and Data Engineering, 1992,4(5): 487-502.
|
| [7] |
ANTOVA L , JANSEN T , KOCH C ,et al. Fast and simple relational processing of uncertain data[C]// IEEE 24th International Conference on Data Engineering. Cancun,Mexico,IEEE, 2008: 983-992.
|
| [8] |
TANG R , CHENG R , WU H ,et al. A framework for conditioning uncertain relational data[J]. Database and Expert Systems Applications, 2012,37(3): 71-87.
|
| [9] |
TASKAR B , SEGAL E , KOLLER D . Probabilistic classification and clustering in relational data[C]// The Seventeenth International Joint Conference on Artificial Intelligence.San Francisco,USA:Morgan Kaufmann Publishers Inc. 2001: 870-878.
|
| [10] |
NGAI W K , KAO B , CHUI C K ,et al. Efficient clustering of uncertain data[C]// The Sixth International Conference on Data Mining. 2006: 436-445.
|
| [11] |
KRIEGEL H , PFEIFLE M . Density-based clustering of uncertain data[C]// The 11st ACM SIGKDD International Conference on Knowledge Discovery in Data Mining. Chicago,USA:ACM, 2005: 672-677.
|
| [12] |
KRIEGEL H , PFEIFLE M . Hierarchical density-based clustering of uncertain data[C]// Fifth IEEE International Conference on Data Mining. Houston,USA,IEEE, 2005: 689-692.
|
| [13] |
李云飞, 王丽珍, 周丽华 . 不确定数据的高效聚类算法[J]. 广西师范大学学报:自然科学版, 2011,29(2): 161-166.
|
|
LI Y F , WANG L Z , ZHOU L H . More efficient clustering algorithm over uncertain data[J]. Journal of Guangxi Normal University (Natural Science Edition), 2011,29(2): 161-166.
|
| [14] |
金萍, 宗瑜, 屈世超 ,等. 面向不确定数据的近似骨架启发式聚类算法[J]. 南京大学学报 (自然科学), 2015,51(1): 197-205.
|
|
JIN P , ZONG Y , QU S C ,et al. Approximate backbone guided heuristic clustering algorithm for uncertain data[J]. Journal of Nanjing University (Natural Sciences), 2015,51(1): 197-205.
|
| [15] |
肖宇鹏, 何云斌, 万静 ,等. 基于模糊 C-均值的空间不确定数据聚类[J]. 计算机工程, 2015,41(10): 47-52.
|
|
XIAO Y P , HE Y B , WAN J ,et al. Clustering of space uncertain data based on fuzzy C-means[J]. Computer Engineering, 2015,41(10): 47-52.
|
| [16] |
CORMODE G , MCGREGOR A . Approximation algorithms for clustering uncertain data[C]// The 27th ACM SIGMOD-SIGACT-SIGART Symposium on Principles of Database Systems. Vancouver,Canada,ACM, 2008: 191-200.
|
| [17] |
ZüFLE A , EMRICH T , SCHMID K A ,et al. Representative clustering of uncertain data[C]// The 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York,USA,ACM, 2014: 243-252.
|
| [18] |
SCHUBERT E , KOOS A , EMRICH T ,et al. A framework for clustering uncertain data[C]// The 41st International Conference on Very Large Data Bases. Hawaii,USA,VLDB Endowment, 2015: 1976-1979.
|
| [19] |
XU L , HU Q , HUNG E ,et al. Large margin clustering on uncertain data by considering probability distribution similarity[J]. Neurocomputing, 2015,158: 81-89.
|
| [20] |
JIANG B , PEI J , TAO Y ,et al. Clustering uncertain data based on probability distribution similarity[J]. IEEE Transactions on Knowledge and Data Engineering, 2013,25(4): 751-763.
|
| [21] |
LóPEZ-RUBIO E , JOSE . Probability densty function estimation with the frequency polygon transform[J]. Information Science, 2015,298: 136-158.
|
| [22] |
ELGAMMAL A , DURAISWAMI R , DAVIS L S . Efficient kernel density estimation using the fast gauss transform with applications to color modeling and tracking[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2003,25(11): 1499-1504.
|
| [23] |
SCOTT D . On optimal and data-based histograms[J]. Biometrika, 1979,66(3): 605-610.
|
| [24] |
GREENGARD L , STRAIN J . The fast Gauss transform[J]. SIAM Journal on Scientific and Statistical Computing, 1991,12(1): 79-94.
|
| [25] |
YANG C , DURAISWAMI R , GUMEROV N ,et al. Improved fast gauss transform and efficient kernel density estimation[C]// Ninth IEEE International Conference on Computer Vision. Nice,France:IEEE, 2003: 664-671.
|
| [26] |
ZHAO Y , KARYPIS G . Criterion functions for document clustering:experiment and analysis[R]. Technical Report TR 01-40,Department of Computer Science,University of Minnesota,USA, 2001.
|
| [27] |
MANNING C D , RAGHAVAN P , SCHUTZE H ,著. 王斌,译 信息检索导论[M]. 北京: 人民邮电出版社, 2010.
|
|
MANNING C D , RAGHAVAN P , SCHUTZE H.WANG B,translate WANG B ,translate. Introduction to information retrieval[M]. Beijing: PTPRESS, 2010.
|
| [28] |
DEMSAR J . Statistical comparisons of classifiers over multiple data sets[J]. Journal of Machine Learning Research, 2006(7): 1-30.
|
| [29] |
ARBELAITZ O , GURRUTXAGA I , MUGUERZA J ,et al. An extensive comparative study of cluster validity indices[J]. Pattern Recognition, 2013,46(1): 243-256.
|