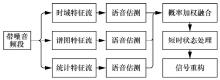
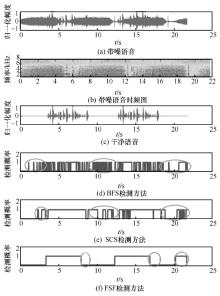
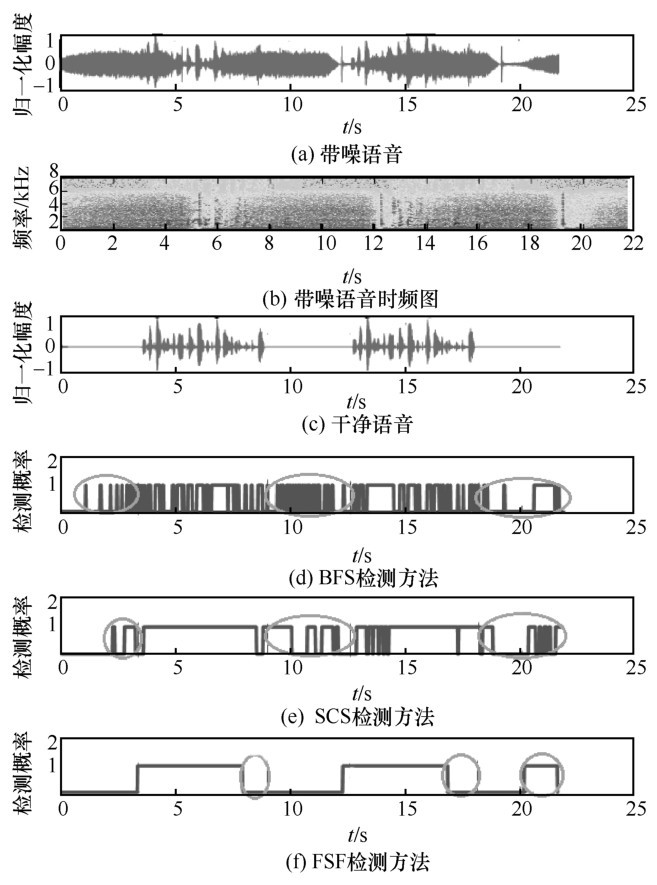
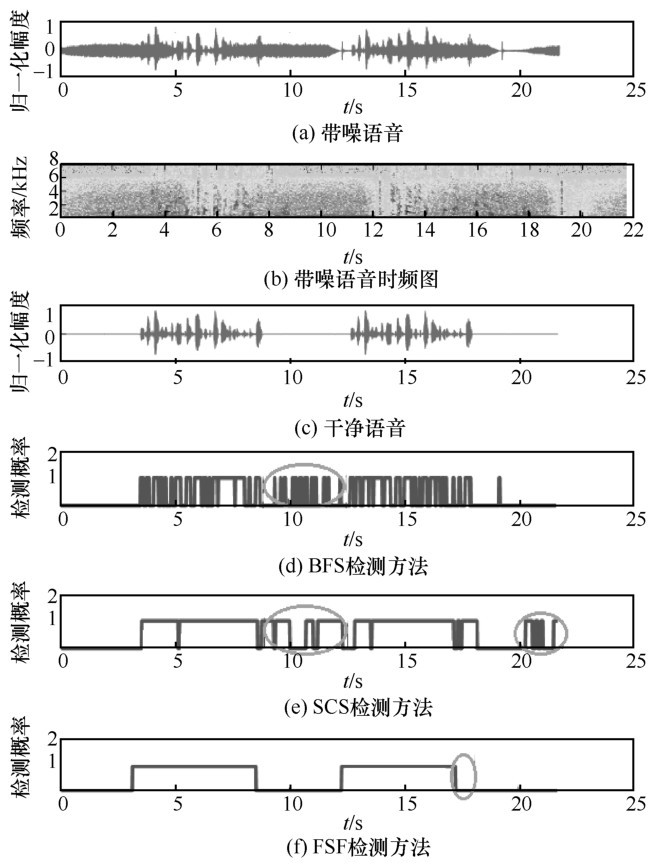
| [1] |
WEI J , SUN X . Research on speech endpoint detection algorithm with low SNR[J]. Open Access Library Journal, 2017,4(3): 1-8.
|
| [2] |
LI Q , XIE H E , ZHENG Q J ,et al. The voice activity detection algorithm based on spectral entropy and high-order statistics[J]. Applied Mechanics and Materials, 2014(624): 495-499.
|
| [3] |
PALIWAL K K , WOJCICKI K , SCHWERIN B ,et al. Single-channe speech enhancement using spectral subtraction in the short-time modulation domain[J]. Speech Communication, 2010,52(5): 450-475.
|
| [4] |
MENDELEV V , PRISYACH T , PRUDNIKOV A ,et al. Robust voice activity detection with deep maxout neural networks[J]. Mathematical Models and Methods in Applied Sciences, 2015,9(8): 153-159.
|
| [5] |
LENGERICH C , HANNUN A . An end-to-end architecture for keyword spotting and voice activity detection[J]. arXiv Preprint,arXiv:1611.09405, 2016
|
| [6] |
IVRY A , BERDUGO B , COHEN I ,et al. Voice activity detection for transient noisy environment based on diffusion nets[J]. IEEE Journal of Selected Topics in Signal Processing, 2019,13(2): 254-264.
|
| [7] |
SOHN J , KIM N S , SUNG W ,et al. A statistical model-based voice activity detection[J]. IEEE Signal Processing Letters, 1999,6(1): 1-3.
|
| [8] |
FISHER E , TABRIKIAN J , DUBNOV S ,et al. Generalized likelihood ratio test for voiced-unvoiced decision in noisy speech using the harmonic model[J]. IEEE Transactions on Audio,Speech,and Language Processing, 2006,14(2): 502-510.
|
| [9] |
KIM J T , JUNG S H , CHO K H ,et al. Efficient harmonic peak detection of vowel sounds for enhanced voice activity detection[J]. Let Signal Processing, 2018,12(8): 975-982.
|
| [10] |
SHAMMA S A , ELHILALI M , MICHEYL C ,et al. Temporal coherence and attention in auditory scene analysis[J]. Trends in Neurosciences, 2011,34(3): 114-123.
|
| [11] |
HWANG S , JIN Y G , SHIN J W ,et al. Dual microphone voice activity detection based on reliable spatial cues[J]. Sensors, 2019,19(14): 3056-3064.
|
| [12] |
TEKI S , BARASCUD N , PICARD S ,et al. Neural correlates of auditory figure-ground segregation based on temporal coherence[J]. Cerebral Cortex, 2016,26(9): 3669-3680.
|
| [13] |
KLEINSCHMIDT M , . Spectro-temporal Gabor features as a front end for automatic speech recognition[C]// In 3rd European Congress on Acoustics.[S.n.:s.l]. 2002: 1-6.
|
| [14] |
罗智勇, 杨旭, 孙广路 ,等. 基于马尔可夫的有限自动机入侵容忍系统模型[J]. 通信学报, 2019,40(10): 79-89.
|
|
LUO Z Y , YANG X , SUN G L ,et al. Finite automaton intrusion tolerance system model based on Markov[J]. Journal on Communications, 2019,40(10): 79-89.
|
| [15] |
NIELSEN J K , JENSEN T L , JENSEN J R ,et al. Fast fundamental frequency estimation:making a statistically efficient estimator computationally efficient[J]. Signal Process, 2017(135): 188-197.
|
| [16] |
SHE L M , NIELSEN J K , JENSEN J R ,et al. Bayesian pitch tracking based on the harmonic model[J]. IEEE/ACM Transactions on Audio,Speech,and Language Processing, 2019,27(11): 1737-1751.
|
| [17] |
SCHLUTER R , BEZRUKOV L , WANGNER H ,et al. Gammatone features and feature combination for large vocabulary speech recognition[C]// International Conference on Acoustics,Speech and Signal Processing. Piscataway:IEEE Press, 2007: 649-652.
|
| [18] |
SHAO Y , JIN Z , WANG D L ,et al. An auditory-based feature for robust speech recognition[C]// Proceedings of International Conference on Acoustics,Speech and Signal Processing. Piscataway:IEEE Press, 2009: 4625-4628.
|
| [19] |
MAARTEN V S , ANDREAS T , NARAYANAN S . A robust front end for VAD:exploiting contextual,discriminative and spectral cues of human voice[C]// Proceedings of the Annual Conference of the International Speech Communication Association. Piscataway:IEEE Press, 2013: 704-708.
|
| [20] |
MAARTEN V S , ANDREAS T , NARAYANAN . A robust front end for VAD:exploiting contextual,discriminative and spectral cues of human voice[C]// Proceedings of the Annual Conference of the International Speech Communication Association. Piscataway:IEEE Press, 2013: 704-708.
|
| [21] |
LU L , JIANG H , ZHANG H ,et al. A robust audio classification and segmentation method[C]// ACM Multimedia. New York:ACM Press, 2001: 203-211.
|
| [22] |
ZHAO J H , GAO H B , LIU Y C ,et al. Speech recognition algorithm based on neural network and hidden Markov model[J]. The Journal of China Universities of Posts and Telecommunications, 2018,25(4): 28-37.
|

 ),邵玉斌
),邵玉斌