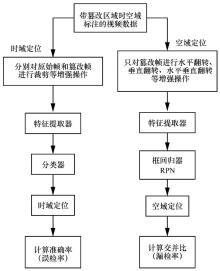
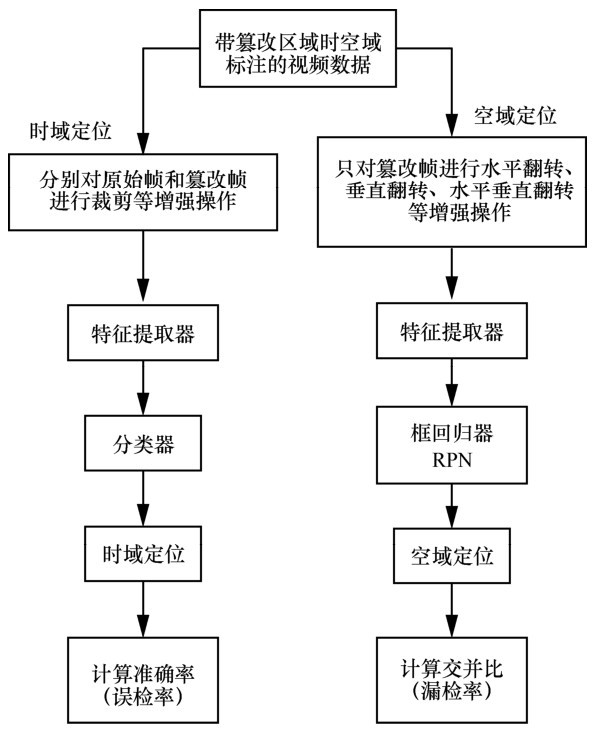
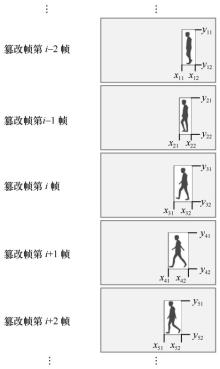
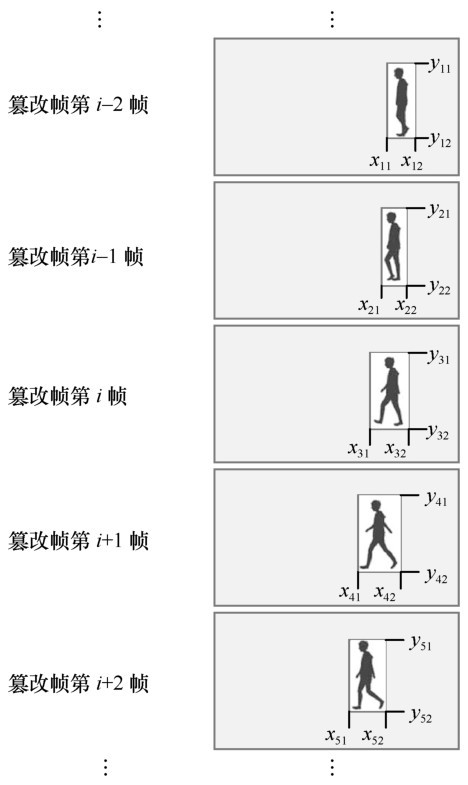
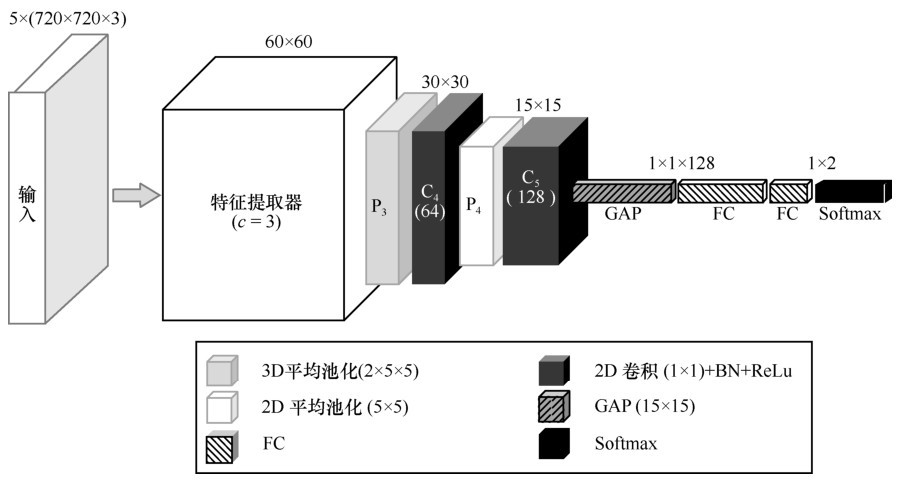
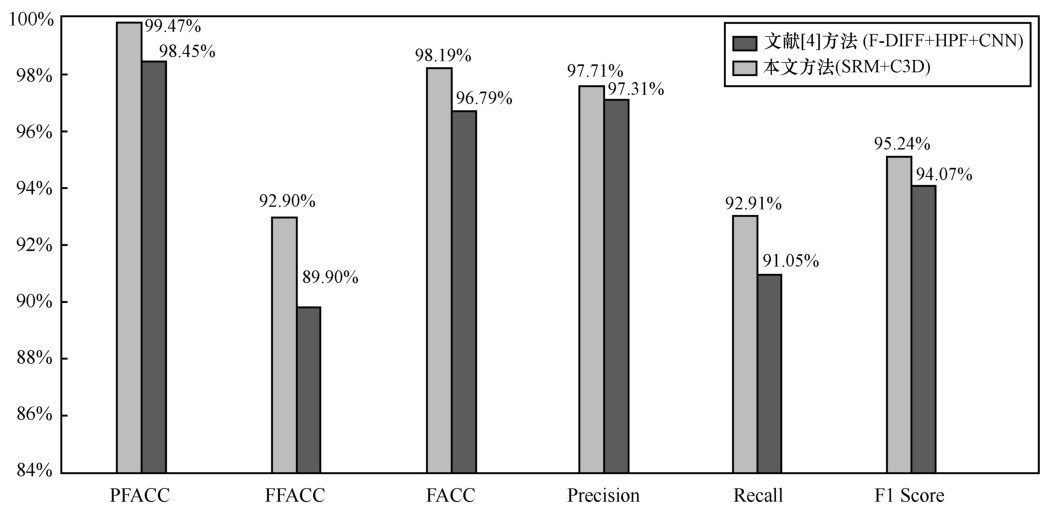
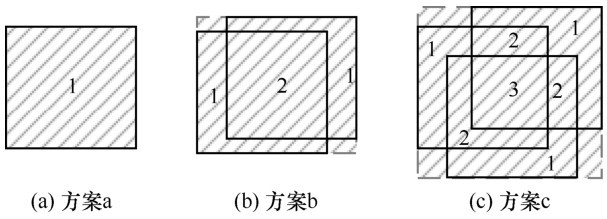
| [19] |
SONG W , REN D , YU J ,et al. A new special video detection algorithm based on 3D convolutional co-occurrence gradient histogram and multi-instance learning[J]. Chinese Journal of Computers, 2019,42(1): 151-165.
|
| [20] |
HUANG S Y , RAMANAN D . Expecting the unexpected:training detectors for unusual pedestrians with adversarial imposters[C]// Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE Press, 2017: 4664-4673.
|
| [21] |
王青, 张荣 . 基于DCT系数双量化映射关系的图像盲取证算法[J]. 电子与信息学报, 2014,36(9): 2068-2074.
|
|
WANG Q , ZHANG R . A blind Image forensic algorithm based on double quantization mapping relationship of DCT coefficients[J]. Journal of Electronics & Information Technology, 2014,36(9): 2068-2074.
|
| [22] |
武伟, 詹玲超 . 利用颜色滤波阵列特性和模糊估计检测篡改[J]. 计算机工程与设计, 2007,28(21): 5179-5180.
|
|
WU W , ZHAN L C . Detection of tampering using color filter array characteristics and fuzzy estimation[J]. Computer Engineering and Design, 2007,28(21): 5179-5180.
|
| [23] |
张静, 陈静, 苏育挺 . 基于滤波检测的视频区域篡改检测算法[J]. 电子测量技术, 2011,34(11): 66-69.
|
|
ZHANG J , CHEN J , SU Y T . Detection of region-duplication forgery in the video streams[J]. Electronic Measurement Technology, 2011,34(11): 66-69.
|
| [24] |
杨弘, 周治平, 周翠娟 ,等. 基于模式噪声的手机图像篡改检测[J]. 计算机系统应用, 2013,22(9): 210-213.
|
|
YANG H , ZHOU Z P , ZHOU C J ,et al. Mobile image tampering detection based on pattern noise[J]. Journal of Computer System Applications, 2013,22(9): 210-213.
|
| [25] |
王鑫, 鲁志波 . 基于JPEG块效应差异的图像篡改区域自动定位[J]. 计算机科学, 2010,37(2): 269-273.
|
|
WANG X , LU Z B . Automatic localization of image tampering area based on JPEG block effect difference[J]. Computer Science, 2010,37(2): 269-273.
|
| [1] |
骆伟祺, 黄继武, 丘国平 . 鲁棒的区域复制图像篡改检测技术[J]. 计算机学报, 2007,30(11): 112-121.
|
|
LUO W Q , HUANG J W , QIU G P . Robust tamper detection technology of regional reproduction image[J]. Chinese Journal of Computers, 2007,30(11): 112-121.
|
| [26] |
王传旭, 张祥光, 原春锋 ,等. 基于邻域相关性和帧间连续性的前景目标分割[J]. 数据采集与处理, 2007,22(3): 288-291.
|
|
WANG C X , ZHANG X G , YUAN C F ,et al. Foreground target segmentation based on neighborhood correlation and frame continuity[J]. Data Collection and Processing, 2007,22(3): 288-291.
|
| [2] |
胡永健, AL-HAMIDI S, 王宇飞, ,等. 视频篡改检测数据库的构建及测试[J]. 华南理工大学学报(自然科学版), 2017,45(12): 57-64.
|
|
HU Y J , AL-HAMIDI S , WANG Y F ,et al. Construction and testing of video tamper detection database[J]. Journal of South China University of Technology (Natural Science Edition), 2017,45(12): 57-64.
|
| [27] |
阳婷, 官洪运 . 基于帧间高频能量和相关性的烟雾检测算法研究[J]. 微型机与应用, 2015(17): 36-39.
|
|
YANG T , GUAN H Y . Research on smoke detection algorithm based on high frequency energy and correlation between frames[J]. Microcomputer and Application, 2015(17): 36-39.
|
| [3] |
陈威兵, 杨高波, 陈日超 ,等. 数字视频真实性和来源的被动取证[J]. 通信学报, 2011,32(6): 177-183.
|
|
CHEN W B , YANG G B , CHEN R C ,et al. Digital video passive forensics for its authenticity and source[J]. Journal on Communications, 2011,32(6): 177-183.
|
| [4] |
YAO Y , SHI Y Q , WENG S W ,et al. Deep learning for detection of object-based forgery in advanced video[J]. Symmetry, 2017,10(1):3.
|
| [5] |
姚晔, 胡伟通, 任一支 ,等. 数字视频区域篡改的检测与定位[J]. 中国图象图形学报, 2018(6): 779-791.
|
| [28] |
DU T , LUBOMIR B , ROB F ,et al. Learning Spatiotemporal Features with 3D Convolutional Networks[C]// Proceedings of 2015 IEEE International Conference on Computer Vision. Piscataway:IEEE Press, 2015: 4489-4497.
|
| [29] |
CHEN S D , TAN S Q , LI B ,et al. Automatic detection of object-based forgery in advanced video[J]. IEEE Transactions on Circuits & Systems for Video Technology, 2016,26(11): 2138-2151.
|
| [5] |
YAO Y , HU W T , REN Y Z ,et al. Detection and location of digital video region tampering[J]. Journal of Image and Graphics, 2018(6): 779-791.
|
| [6] |
李岩, 刘念, 张斌 ,等. 图像镜像复制粘贴篡改检测中的 FI-SURF算法[J]. 通信学报, 2015,36(5): 54-65.
|
|
LI Y , LIU N , ZHANG B ,et al. FI-SURF algorithm in image mirror copy and paste tamper detection[J]. Journal on Communications, 2015,36(5): 54-65.
|
| [7] |
黄维隽, 王士林 . 一种基于优化马尔可夫特征的图像篡改盲检测算法[J]. 信息安全与通信保密, 2014(3): 93-98,103.
|
|
HUANG W J , WANG S L . An image tampering blind detection algorithm based on optimized Markov features[J]. Information Security and Communication Security, 2014(3): 93-98,103.
|
| [8] |
文伟, 肖志云, 彭思龙 . 边缘指导的BDCT压缩图像的后处理算法[J]. 计算机辅助设计与图形学学报, 2005(9): 2022-2028.
|
|
WEN W , XIAO Z Y , PENG S L . Post processing algorithm of BDCT compressed image guided by edge[J]. Journal of Computer Aided Design and Graphics, 2005(9): 2022-2028.
|
| [9] |
耿庆田, 赵宏伟 . 基于分形维数和隐马尔可夫特征的车牌识别[J]. 光学精密工程, 2013(12): 216-222.
|
|
GENG Q T , ZHAO H W . License plate recognition based on fractal dimension and hidden Markov features[J]. Optical Precision Engineering, 2013(12): 216-222.
|
| [10] |
ZHOU P , HAN X T , MORARIU V I ,et al. Learning rich features for image manipulation detection[C]// Proceedings of 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE Press, 2018: 1053-1061.
|
| [11] |
REN S Q , HE K M , GIRSHICK R ,et al. Faster R-CNN:towards real-time object detection with region proposal networks[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2015,39(6): 1137-1149.
|
| [12] |
桑军, 郭沛, 项志立 ,等. Faster-RCNN的车型识别分析[J]. 重庆大学学报, 2017,40(7): 32-36.
|
|
SANG J , GUO P , XIANG Z L ,et al. Vehicle detection based on fast er-RCNN[J]. Journal of Chongqing University, 2017,40(7): 32-36.
|
| [13] |
FAN Q F , BROWN L , SMITH J . A closer look at Faster R-CNN for vehicle detection[C]// Proceedings of 2016 IEEE Intelligent Vehicles Symposium (IV). Piscataway:IEEE Press, 2016: 124-129.
|
| [14] |
刘雨青, 黄添强 . 基于时空域能量可疑度的视频篡改检测与篡改区域定位[J]. 南京大学学报(自然科学), 2014(1): 61-71.
|
|
LIU Y Q , HUANG T Q . Video tamper detection and tamper location based on energy suspicious degree in space-time domain[J]. Journal of Nanjing University (Natural Science), 2014(1): 61-71.
|
| [15] |
李倩, 王让定, 徐达文 . 基于视频修复的运动目标删除篡改行为的检测算法[J]. 光电子·激光, 2016,27(2): 182-190.
|
|
LI Q , WANG R D , XU D W . Detection to video moving object deletion based on video inpainting[J]. Optoelectronics · Laser, 2016,27(2): 182-190.
|
| [16] |
何沛松 . 基于重编码痕迹的数字视频被动取证算法研究[D]. 上海:上海交通大学, 2018.
|
|
HE P S . Research on digital video passive forensics algorithm based on recoded traces[D]. Shanghai:Shanghai Jiaotong University, 2018.
|
| [17] |
MOLCHANOV P , GUPTA S , KIM K ,et al. Hand gesture recognition with 3D convolutional neural networks[C]// Proceedings of 2015 IEEE Conference on Computer Vision and Pattern Recognition Workshops. Piscataway:IEEE Press, 2015: 1-7.
|
| [18] |
MOLCHANOV P , YANG X D , GUPTA S ,et al. Online detection and classification of dynamic hand gestures with recurrent 3D convolutional neural networks[C]// Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE Press, 2016: 4207-4215.
|
| [30] |
JIANG B R , LUO R X , MAO J Y ,et al. Acquisition of localization confidence for accurate object detection[C]// European Conference on Computer Vision. Berlin:Springer, 2018: 816-832.
|
| [19] |
宋伟, 任栋, 于京 ,等. 一种新的基于三维卷积共生梯度直方图和多示例学习的特殊视频检测算法[J]. 计算机学报, 2019,42(1): 151-165.
|

 ),张祯1,吴国华1
),张祯1,吴国华1