





1 引言
随着时代的发展,信息量呈指数级增长趋势,为了快速地从庞大的数据中找到所需要的信息,搜索成为了人们共同的选择,搜索技术也从最开始的分类目录时代渐渐进入了以用户为中心的时代。同时,随着数据量的剧增,存储和计算问题也越来越突出,为了解决这一问题,云计算技术应运而生。
如今,云服务越来越便捷。然而,随着云服务的普及,其安全和隐私泄露问题已然成为了人们关注的焦点[1]。因为黑客及云服务器本身的不可信,当数据以明文形式存储在云服务器上时,很可能会导致数据的泄露,鉴于此,数据拥有者倾向于先加密数据,再将密文外包到云服务器中。然而,传统的明文检索技术在密文环境下将毫无用处。与此同时,用户在实时检索时希望以最短的时间获得自己最需要的检索结果,但随着数据量与用户数的激增,云服务器可能会成为云服务的性能瓶颈,增加用户的等待时间,这将严重影响用户的搜索体验。因此,如何在浩瀚的密文中快速地获得自己所需要的检索结果成为密文环境下个性化搜索技术的研究方向。
2 相关工作
但上述方法却只限于明文搜索,如何很好地实现密文环境下的个性化搜索,提升用户的搜索体验,还是一个任重而道远的事情。文献[11]通过用户的搜索历史,并根据语义网(WordNet)构建用户模型,通过关键词优先级将用户兴趣融入用户的查询关键词,然后对存储在云服务器上的密文进行搜索,并返回相关性得分最高的前K个搜索结果给用户,实现在密文环境下个性化搜索的目的,但该方法存在3个不足:1) 索引构建时间太长,不仅加大了数据拥有者构建索引的负担,也不利于索引的更新;2) 云服务器需要计算每个查询与所有文件索引的相关性得分,云服务器的计算负担不容小觑,这可能使云服务器成为性能瓶颈;3) 为了保护用户的隐私信息不被云服务器知晓,引入的假关键词不仅增加了云服务器的开销,还降低了查询的精确度,而高的查询精确度是提高用户搜索体验的保证。
基于以上研究,本文通过引入边缘服务器,提出一种基于多边缘服务器的个性化搜索隐私保护方法,实现了密文环境下的个性化搜索。具体的创新点如下。
1) 文件索引存储在边缘服务器中,而文件的密文存储在云服务器中,从源头上保证了文件索引不被云服务器知晓。
2) 通过索引的切割,边缘服务器只能得到部分索引信息,通过在边缘服务器上加密索引,大大减轻了数据拥有者构建索引的负担。
3) 通过引入随机数后,将用户查询矩阵进行切割、矩阵加密,在优化整个系统查询性能的同时保护了用户的查询隐私。
3 系统模型和相关定义
3.1 系统模型
图1为基于多边缘服务器的隐私保护模型,该模型由用户、数据拥有者、边缘服务器和云服务器这4类实体构成。数据拥有者负责生成密钥sk并通过安全信道将查询加密密钥与密文密钥key传送给用户,同时还负责构建文件的索引并将索引切割后将 pi与相应的索引加密密钥
图1

3.2 相关定义
定义 2 相关性得分。相关性得分的高低反映了加密后的查询矩阵
定义3 安全内积计算[15]。为了达到保护用户的隐私不被泄露及完成相关性得分计算的目标,采用了先对用户查询及索引进行加密,然后通过安全内积计算的方法获得两者的相关性得分。安全内积计算如式(1)所示。
定义5 索引切割。本文采用多个边缘服务器,用于索引的加密及用户查询与其上索引的相关性得分计算。为了实现这一功能,数据拥有者需要根据索引加密密钥的维度对索引进行切割。为了简单起见,假设需要将索引切割成3份,索引加密密钥为3阶方阵,数据拥有者根据索引加密密钥方阵的维数,将索引切割成 3 份。其中,索引中的每一行代表一个文件的索引,行中的每一个元素代表文件中相应关键词的权重。数据拥有者根据索引加密矩阵的维数,以 3 列为一单位对整个索引进行切割。如图2所示,整个索引被切割成了3个15 × 3的矩阵。
图2
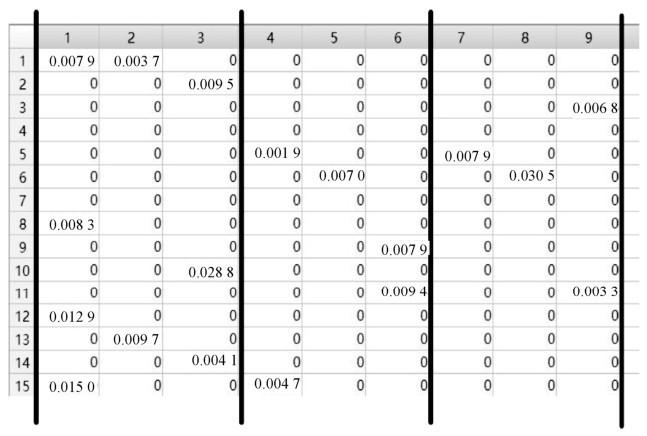
定义 6 查询矩阵切割。查询矩阵为行矩阵,维度等于索引的列数,其切割方法与索引切割方法相同,也是根据相应密钥的维数进行切割,因为查询矩阵的加密密钥与索引的加密密钥一一对应,因此经过切割后的查询矩阵也会和切割后的索引矩阵一一对应。
3.3 攻击模型
4 基于多边缘服务器的隐私保护方法
本文提出了一种基于多边缘服务器的个性化搜索隐私保护方法,该方法的基本思想是引入多个边缘服务器。与文献[11]相比,在保护用户隐私的前提下,引入边缘服务器有如下作用。
1) 在边缘服务器上加密索引,能大幅度地减少数据拥有者的负担,同时提升索引的加密效率。
2) 在边缘服务器上计算用户查询矩阵和索引的相关性得分,在减轻云服务器计算开销的同时能够提升搜索的效率,进而缩短用户获得搜索结果的时间,从而提高用户的搜索体验。
图3
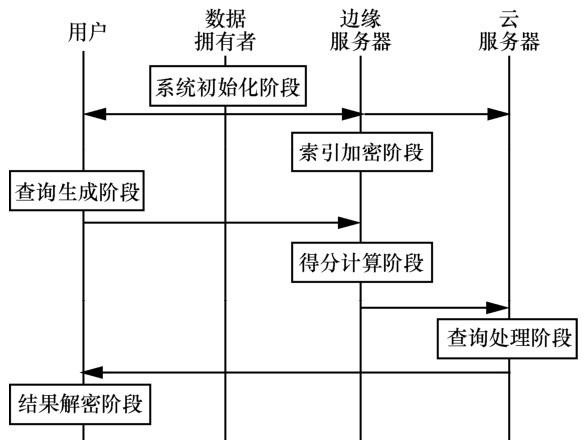
表1 符号描述
| 符号 | 描述 |
| sk | 密钥 |
| K | 用户提交的参数K |
| a | 大于0的随机数 |
| p ,pi | 明文索引 |
| 加密后的索引 | |
| C | 加密后的文件集 |
| 第i个边缘服务器上的第 j行索引的相关性得分 | |
| 第i个边缘服务器计算的相关性得分矩阵 | |
| 用户查询 | |
| n,ni | 关键词数 |
| 用户模型 | |
| m | 文件数量 |
| 加密后的查询矩阵 | |
| S | 云服务器上计算获得的相关性得分矩阵 |
| h | 边缘服务器数量 |
| key | 文件密文解密密钥 |
4.1 系统初始化阶段
在系统初始化阶段,数据拥有者随机切割索引,并设第i部分索引的关键词数为ni(i∈[1,h]),为了尽量减少系统的开销,数据拥有者选取
数据拥有者根据“TF × IDF”模型构建文件集的索引
为了降低加密与解密文件的开销,数据拥有者使用对称密码技术(如3DES、AES)对文件集C中的每个文件进行加密,并将加密后的文件集C发送给云服务器。
4.2 索引加密阶段
大数据时代的到来使数据量呈指数级增长,为了减轻数据拥有者的负担,利用边缘服务器加密索引。由于多边缘服务器能并行加密索引,并且对切割后的索引加密降低了时间复杂度,这大大地缩短了索引加密的时间。边缘服务器利用式(2)对索引进行加密。
4.3 查询生成阶段
步骤1 用户查询的转换
系统会根据用户提交的查询关键词生成查询矩阵,查询矩阵根据用户兴趣模型进行变化,当用户兴趣模型中关键词的权重不为0时,查询矩阵对应的关键词权重作为用户模型中的权重;当用户兴趣模型中关键词权重为0时,查询矩阵中对应的关键词权重不变,为初始值 1。转换后的查询矩阵不仅包含用户的查询信息,还包含用户的兴趣信息,例如用户的查询矩阵
步骤2 查询矩阵的切割与加密
为了迷惑边缘服务器和云服务器,用户首先随机地生成值a(a>0),并让a和转换后的查询矩阵
4.4 得分计算阶段
边缘服务器i在收到用户的查询请求
从式(3)可以看出,边缘服务器计算得到的
4.5 查询处理阶段
当边缘服务器将计算得到的
4.6 结果解密阶段
当用户收到云服务器返回给自己的 top K密文后,用户使用解密密钥key对文件进行解密,从而完成整个搜索的过程。
5 安全性分析
5.1 抵御诚实而好奇的边缘服务器
挑战 1 在本文中,为了充分利用边缘服务器的计算能力,边缘服务器将获得部分索引以及加密该索引的密钥。如果边缘服务器可以知道用户的查询矩阵或用户查询矩阵与文件索引的相关性得分,那么边缘服务器将赢得这个挑战。
定理 1 本文所提方法可以抵御边缘服务器诚实而好奇的窥视。
证明 数据拥有者通过索引切割方法将索引切割成h份子信息
由式(4)~式(6)知,即使用户两次查询的查询向量
经过以上的分析可知,边缘服务器不能确定地猜出用户的查询以及查询矩阵与文件索引的相关性得分。
5.2 抵御诚实而好奇的云服务器
挑战2 云服务器负责密文的存储、查询处理并将最符合用户本次查询请求的前K个密文返回给用户。云服务器希望从中获取用户的隐私信息,进而获得经济效益或满足自己的好奇心,同时也希望获得文件的明文。如果云服务器能够从中获得用户的具体查询信息或者将存储在其上的明文解密,那么云服务器将赢得这个游戏。
定理 2 本文算法可以抵御云服务器诚实而好奇的攻击。
证明 由于云服务器只知道密文以及加密、解密算法,文件采用对称密码技术(如3DES、AES)进行加密,其安全性已被证明,云服务器没有用于文件解密的密钥 key,因此其不可能将密文解密成明文,更不可能获悉返回用户的密文的具体信息。云服务器通过从边缘服务器发送来的
从以上分析可知,云服务器不能猜测出返回给用户的密文信息以及用户的具体查询信息。
5.3 抵御恶意攻击者的窃听攻击
挑战 3 攻击者通过窃听不安全的通信信道,试图从这些数据中挖掘出用户的某些敏感信息,如果攻击者能够恢复用户的查询矩阵或者获知返回用户的文件信息,那么攻击者将赢得这个游戏。
定理 3 本文算法能抵御恶意攻击者的窃听攻击。
证明 假设恶意攻击者拦截到用户发送给所有边缘服务器的查询请求 Ti,由于其不知道加密密钥
从以上分析可知,恶意攻击者既不能获得用户的查询矩阵,也不能猜测出云服务器返回给用户的密文信息。
6 实验及结果分析
实验主要从索引加密、用户查询生成、得分计算及查询处理这4个方面分析本方法的性能,并将其与MRSE[26]以及PRSE[11]方法进行比较,由于边缘服务器数量为1时会造成部分隐私的泄露,因此实验中边缘服务器为1的实验数据仅作性能对比。采用 Yelp 数据集中的“business”与“review”数据作为本文实验的数据集,以一条“business”数据以及与该“business”数据相关的所有“review”数据作为一个文件,进而形成文件集,并采用TF×IDF模型构建这些文件的索引,以期关键词能更好地反映文件。在文件中,每个关键词的重要程度是不一样的,关键词的权重越大,说明该关键词越重要,因此只需要选取权重较大的关键词即能很好地反映文件,同时避免了因关键词字典过于庞大而增加计算开销与存储开销。在构建完关键词字典后,一个文件便可以按照关键词字典中关键词的顺序,形成用关键词的权重表示的文件索引。实验的硬件环境为2.6 GHz Intel (R) Core (TM) i7-6700HQ CPU, 16.00 GB内存,操作系统为Microsoft Windows 10,软件为Matlab R2016b,并使用OriginPro 2017对实验数据进行仿真。
6.1 精确度
如今,数据量呈指数级增长势,在这样的环境下,快速地获得需要的信息变得越来越迫切,因而快速地获得高精度的搜索结果成为了提高用户搜索体验的法宝。本文所提方法能够在保护用户隐私的同时返回用户满意的搜索结果,而用户对返回结果的满意程度在一定程度上反映了精确度的高低。为了评价所提方法的精确度,随机选择10位用户使用本方法进行搜索,结果表明,有 9 人对搜索结果满意,这从一定程度上反映了本方法是可行的。
为了简单明了地说明本方法能够在密文环境下实现个性化搜索的目标,随机选择Yelp数据集中的200 条“business”数据以及与这些“business”数据相关的所有“review”数据,生成了200个文件。然后根据 TF-IDF 模型获得各个文件中的关键词权重,并选择各个文件中关键词权重最大的前10个关键词生成关键词字典,实验中关键词词典共有1 732个关键词。最后,根据关键词字典中关键词的顺序,采用关键词权重表示文件的索引,因此,每个文件可以表示为1×1 732的矩阵。
为了说明本方法中云服务器返回的搜索结果不仅和用户的查询相关,也与用户的历史查询相关,即与用户的兴趣相关。考虑了2种情况下云服务器返回用户的搜索结果列表,具体如下。
1) 只考虑用户提交的查询关键词。本文实验中假设用户选择的关键词数占总关键词数的30%(由于本文实验中总文件数为200个,为了有更多的相关文档,因此假设用户选择的关键词数较多。)。
2) 既考虑用户的查询关键词,也考虑用户的兴趣模型。在实验中,假设用户进行了1 000次的历史查询,并设置这1 000次查询中的用户兴趣偏好如表2所示:即有20%的概率选择前500个关键词, 15%的概率选择第501~1 000个的关键词,10%的概率选择第1 001~1 500个的关键词,1%的概率选择第1 501~1 732个关键词。
设置参数K=10,即云服务器返回得分最高的前10个搜索结果给用户,实验结果如表3所示。
表3 2种情况下搜索结果对比
| 兴趣模型 | 密文按得分降序排序的文件编号 |
| 忽略模型 | 135 85 41 32 34 57 13 69 90 141 |
| 考虑模型 | 90 85 135 32 189 64 41 45 13 199 |
从表3可以看出,云服务器在2种情况下返回给用户的搜索结果列表是不同的,说明了用户兴趣模型真真切切地影响了搜索结果。同时也可以看到,在这2种情况下,云服务器返回给用户的文件有6个是相同的,分别是135、85、41、32、13、90。
从这个实验可以看出,即使对于相同的查询关键词,由于每个人的兴趣偏好、搜索历史不相同,云服务器返回的搜索结果也不会相同,因此本方法适用于个性化搜索,尤其适用于密文环境下的个性化搜索。同时,由于返回的搜索结果不仅与用户的搜索关键词相关,也与用户的搜索历史相关,这无疑能够提高本方法的精确度。
召回率衡量搜索到所有相关文档的能力,但本方法中,云服务器是根据用户提交的参数K返回相关性得分最高的前K个文件给用户。当K越大,召回率显然会相应地提高,比如当用户设置K=10时,而与用户此次查询相关的文档有100个时,召回率会很低。但随着K的增大,召回率也会相应地增加,因而在本文中讨论召回率的大小是没有必要的,也是没有意义的。
6.2 个性化搜索
6.1节的实验表明,在考虑或忽略用户兴趣模型时,2 种情况下返回的搜索结果是不同的。为了更进一步地说明本文所提方法能很好地实现个性化搜索的目标,考虑当用户的搜索关键词相同时,云服务器返回给具有不同兴趣偏好的 3 个用户的搜索结果。
本节采用6.1节中的数据集进行相关实验。
用户兴趣偏好设置如表4所示,既考虑用户的查询关键词,也考虑用户的兴趣模型。在实验中,假设用户进行了 1 000次的历史查询,并设置这1 000次查询中的用户兴趣偏好如表4所示,即用户1、用户2、用户3分别以20%、12%、5%的概率选择前500个关键词,分别以15%、20%、12%的概率选择第501~1 000的关键词;以10%、15%、5%的概率选择第1 001~1 500的关键词,分别以1%、6%、10%的概率选择第1 501~ 1 732个关键词。
表4 用户兴趣偏好设置
| 关键词/个 | 用户1 | 用户2 | 用户3 |
| 1~500 | 20% | 12% | 5% |
| 501~1 000 | 15% | 20% | 12% |
| 1 001~1 500 | 10% | 15% | 5% |
| 1 501~1 732 | 1% | 6% | 10% |
为了进行对比,用户查询和用户 1 的兴趣模型与6.1节中相同,并设置参数K=10,即云服务器返回得分最高的前10个搜索结果给用户,实验结果如表5所示。
表5 不同用户相同查询时返回的搜索结果对比
| 兴趣模型 | 返回用户的top 10 结果 |
| 忽略模型/用户1~用户3 | 135 85 41 32 34 57 13 69 90 141 |
| 考虑模型/用户1 | 90 85 135 32 189 64 41 45 13 199 |
| 考虑模型/用户2 | 135 85 32 41 189 13 69 181 57 34 |
| 考虑模型/用户3 | 135 57 141 181 69 34 146 85 189 32 |
从表5可以看出,当用户的查询相同时,在忽略用户兴趣模型的情况下,返回给用户1至用户3的查询结果是完全相同的;当考虑用户的兴趣模型时,即使用户的查询完全相同,返回给用户的查询结果也是不相同的,因为云服务器返回给用户的查询结果不仅与用户的查询相关,也与用户的搜索历史相关,这无疑会使查询结果更符合用户的需求,进而提升用户的搜索体验。同时,本文算法完全在密文环境下进行,很好地保护了用户的隐私。
6.3 索引加密
图4
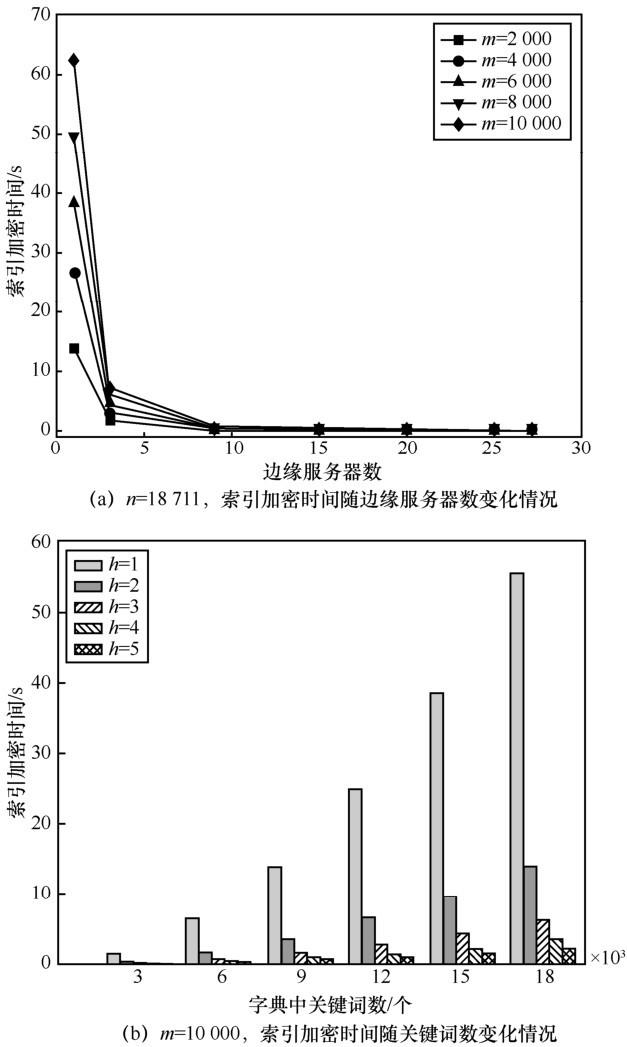
在整个索引的构建开销中,索引加密占了主要的部分,当索引加密时间降得足够低时,有利于采用 TF-IDF 模型更新索引,因而,本方法也为索引的更新提供了新的思路。
表6 3种方案加密时间对比
| 文件数/个 | 本文算法/s | MRSE/s | PRSE/s |
| 2 000 | 1.72 | 6 211.11 | 5 531.48 |
| 4 000 | 3.09 | 13 921.08 | 12 094.42 |
| 6 000 | 4.64 | 20 111.26 | 18 364.29 |
| 8 000 | 6.01 | 27 212.51 | 25 130.54 |
| 10 000 | 7.03 | 32 243.81 | 30 360.43 |
6.4 用户查询生成
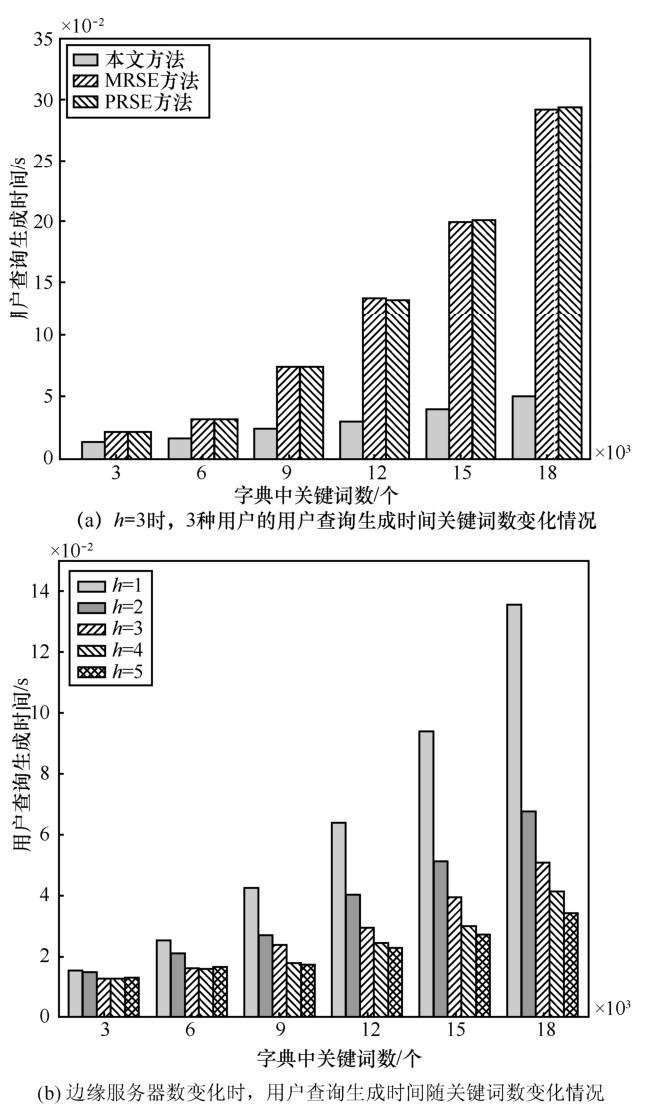
用户查询生成包括用户查询矩阵的转换与用户查询矩阵的切割与加密,为了得到“千人千面”的个性化查询结果,需要根据用户的兴趣模型对用户的查询矩阵进行转换,使转换后的用户查询矩阵不仅带有用户的查询信息,也带有用户的个性化信息,进而使用户得到个性化的搜索结果。以明文形式存在的用户查询矩阵在存储与传输的过程中容易泄露用户的查询隐私,因此需要对转换后的用户查询矩阵进行加密。为了迷惑边缘服务器与第三方攻击者,使用随机生成的迷惑数a乘以转换后的用户查询矩阵q后,采用类似于索引切割的方法,对转换后的用户查询矩阵q进行切割,生成
图5(a)为本文算法取边缘服务器数量h=3时,与MRSE以及PRSE方法在生成用户查询时的性能对比,其表明随着字典中关键词数的增加,3 种方法的用户查询生成时间均增加,并且本文算法性能明显优于MRSE以及PRSE方法,当字典中关键词数越多时,优势越明显,如当字典中关键词数为18 000 时,使用本方法生成用户查询的时间为0.051 s,而MRSE和PRSE方法生成用户查询的时间分别为0.292 s与0.293 s。用户查询的生成为用户整个查询的一部分,用户查询的生成时间越短,用户的搜索体验越好。
图5
6.5 得分计算
得分计算为每个边缘服务器计算出用户部分查询与其上的部分索引的相关性得分
图6

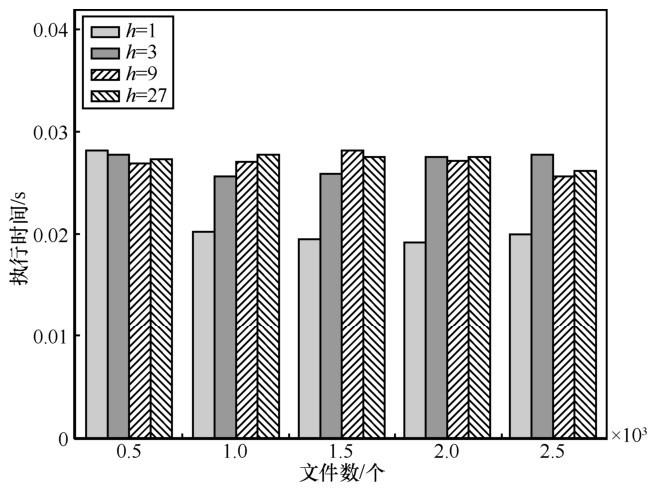
6.6 查询处理
云服务器为了返回与用户此次查询最相关的前K个结果,至少需要知道是哪K个文件与用户的此次查询最相关,即至少需要知道与用户相关性得分最高的前K个文件是哪些。为了实现这一目标,云服务器运行查询处理进程,其将从边缘服务器计算得到的
在云服务器的查询处理阶段,本文将字典中的关键词数n设置为18 711,返回用户的文件数K设置为10。图7表明云服务器上查询处理的执行时间与文件数的多少关系不是很大,这是因为查询处理只需要根据
图7
7 结束语
随着大数据时代的到来,信息过载与隐私保护问题越来越受到人们的关注,基于此,本文提出了一种基于多边缘服务器的个性化搜索方法,该方法同时实现了密文中的个性化搜索与用户隐私保护的统一,并且进行了安全性证明。该方法通过引入多个边缘服务器,并将文件索引存储于边缘服务器中,而将文件密文存储于云服务器中,然后通过切割索引与查询矩阵,成功实现了在边缘服务器上计算部分索引与部分查询之间的相关性得分的目的,有利于保护索引与用户隐私。实验表明,该方法能够实现个性化搜索并大幅地减小用户的搜索等待时间,有利于提高用户的搜索体验,同时该方法减小了云服务的存储开销与计算开销,能更加适用于大量用户的密文搜索环境。
参考文献
Ensuring security and privacy preservation for cloud data services
[J].
Practical techniques for searches on encrypted data
[C]//
Engineering searchable encryption of mobile cloud networks:when QoE meets QoP
[J].
Privacy preserving keyword searches on remote encrypted data
[C]//
Searchable symmetric encryption:improved definitions and efficient constructions
[J].
Public key encryption with keyword search
[C]//
可搜索加密技术研究综述
[J].
Survey on the searchable encryption
[J].
AKSER:attribute-based keyword search with efficient revocation in cloud computing
[J].
Personalized mobile searching approach based on combining content-based filtering and collaborative filtering
[J].
PMSE:a personalized mobile search engine
[J].
Enabling personalized search over encrypted outsourced data with efficiency improvement
[J].
Enabling central keyword-based semantic extension search over encrypted outsourced data
[J].
Fuzzy rule based profiling approach for enterprise information seeking and retrieval
[J].
Enabling cooperative privacy-preserving personalized search in cloud environments
[J].
Secure kNN computation on encrypted databases
[C]//
个性化搜索中一种基于位置服务的隐私保护方法
[J].
Privacy preserving method based on location service in personalized search
[J].
Folksonomy-based personalized search by hybrid user profiles in multiple levels
[J].
WordNet:a lexical database for english
[C]//
A technique to circumvent SSL/TLS validations on iOS devices
[J].
SSL/TLS session-aware user authentication
[J].
Privacy-preserving multi-hop profile-matching protocol for proximity mobile social networks
[J].
PRMS:A personalized mobile search over encrypted outsourced data
[J].
高效可扩展的对称密文检索架构
[J].
Efficient and scalable architecture for searchable symmetric encryption
[J].
Controlling and filtering users data in intelligent transportation system
[J].
Fog-based evaluation approach for trustworthy communication in sensor-cloud system
[J].
Privacy-preserving multi-keyword ranked search over encrypted cloud data
[J].

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}