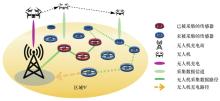
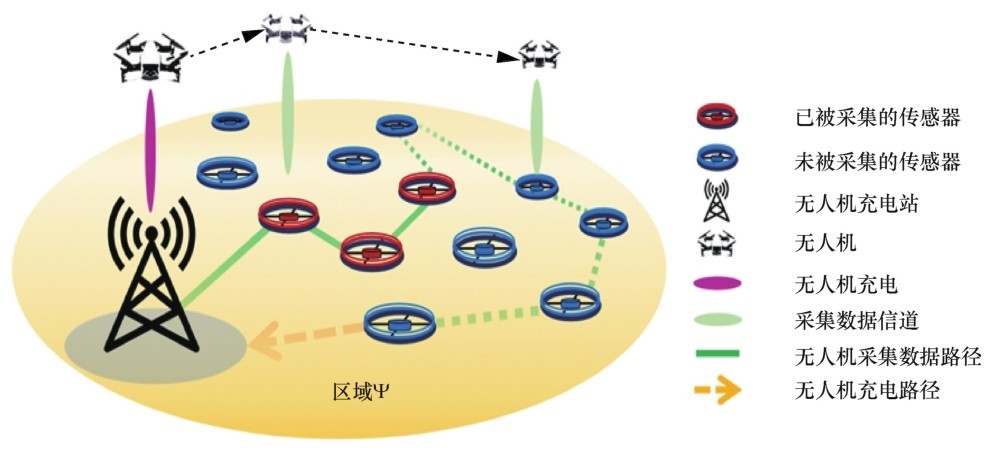
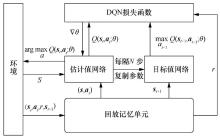
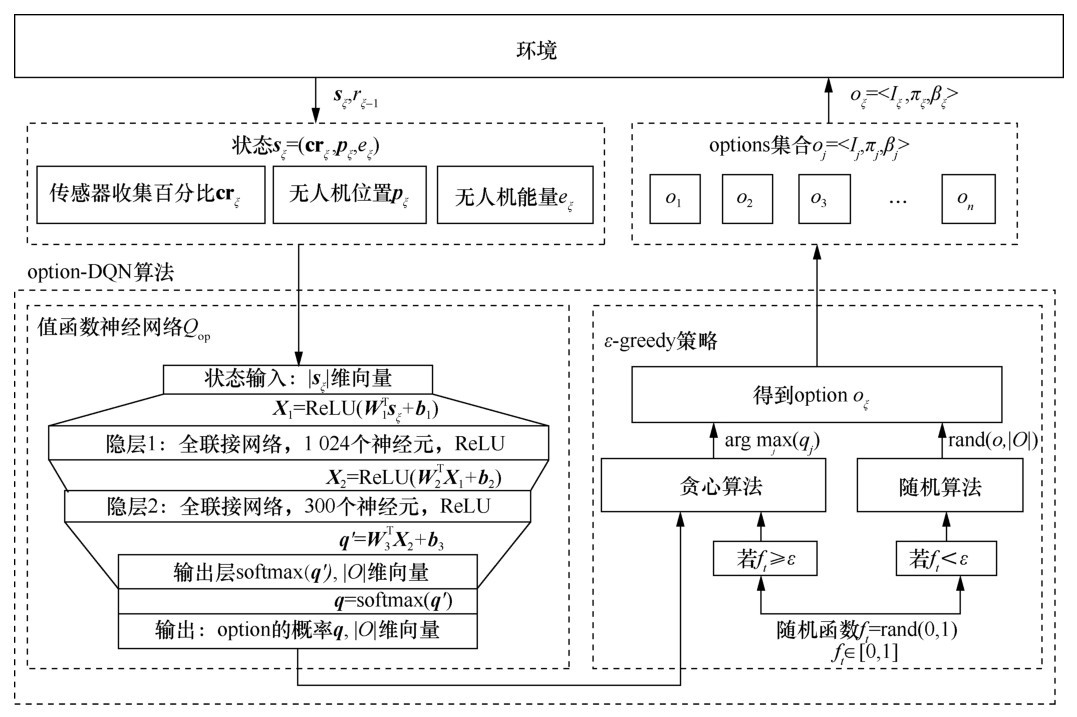
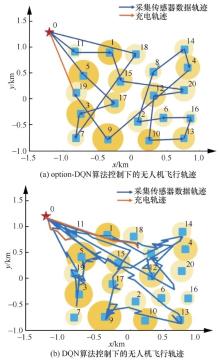
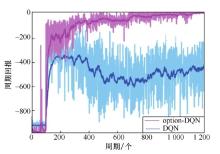
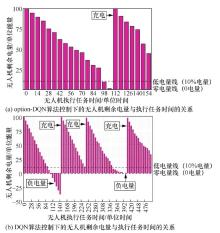
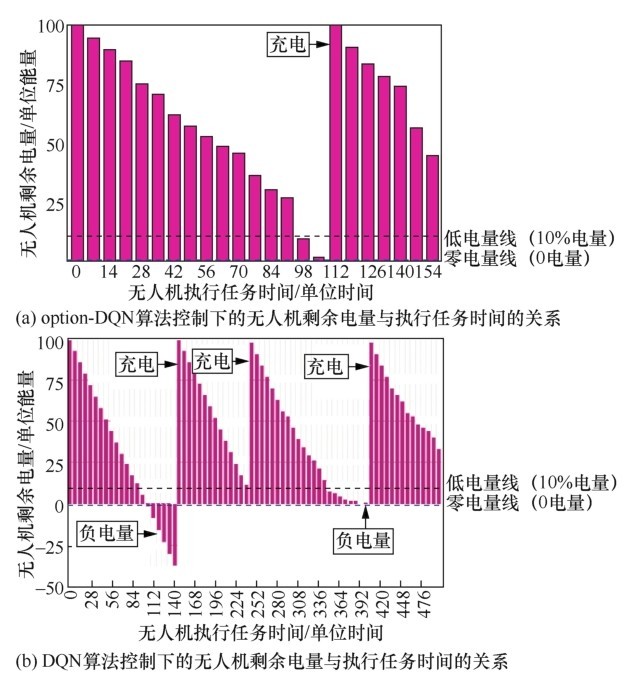
| [1] |
ZHAO N , LU W D , SHENG M ,et al. UAV-assisted emergency networks in disasters[J]. IEEE Wireless Communications, 2019,26(1): 45-51.
|
| [2] |
CHENG F , ZHANG S , LI Z ,et al. UAV trajectory optimization for data offloading at the edge of multiple cells[J]. IEEE Transactions on Vehicular Technology, 2018,67(7): 6732-6736.
|
| [3] |
YOU C S , ZHANG R . 3D trajectory optimization in Rician fading for UAV-enabled data harvesting[J]. IEEE Transactions on Wireless Communications, 2019,18(6): 3192-3207.
|
| [4] |
ZHAN C , ZENG Y , ZHANG R . Energy-efficient data collection in UAV enabled wireless sensor network[J]. IEEE Wireless Communications Letters, 2018,7(3): 328-331.
|
| [5] |
SHAMSOSHOARA A , KHALEDI M , AFGHAH F ,et al. Distributed cooperative spectrum sharing in UAV networks using multi-agent reinforcement learning[C]// 2019 16th IEEE Annual Consumer Communications & Networking Conference (CCNC). IEEE, 2019: 1-6.
|
| [6] |
YANG Q , JANG S J , YOO S J . Q-learning-based fuzzy logic for multi-objective routing algorithm in flying Ad Hoc networks[J]. Wireless Personal Communications, 2020,113(1): 115-138.
|
| [7] |
LIU X , LIU Y X , ZHANG N ,et al. Optimizing trajectory of unmanned aerial vehicles for efficient data acquisition:a matrix completion approach[J]. IEEE Internet of Things Journal, 2019,6(2): 1829-1840.
|
| [8] |
ZHANG J , ZENG Y , ZHANG R . Multi-antenna UAV data harvesting:joint trajectory and communication optimization[J]. Journal of Communications and Information Networks, 2020,5(1): 86-99.
|
| [9] |
ZHAN C , ZENG Y , ZHANG R . Trajectory design for distributed estimation in UAV-enabled wireless sensor network[J]. IEEE Transactions on Vehicular Technology, 2018,67(10): 10155-10159.
|
| [10] |
ALFATTANI S , JAAFAR W , YANIKOMEROGLU H ,et al. Multi-UAV data collection framework for wireless sensor networks[C]// 2019 IEEE Global Communications Conference (GLOBECOM). IEEE, 2019.
|
| [11] |
LI X W , YAO H P , WANG J J ,et al. Joint node assignment and trajectory optimization for rechargeable multi-UAV aided IoT systems[C]// 2019 11th International Conference on Wireless Communications and Signal Processing (WCSP). IEEE, 2019: 1-6.
|
| [12] |
ZHANG Y , LI B , GAO F F ,et al. A robust design for ultra reliable ambient backscatter communication systems[J]. IEEE Internet of Things Journal, 2019,6(5): 8989-8999.
|
| [13] |
CUI M , ZHANG G C , WU Q Q ,et al. Robust trajectory and transmit power design for secure UAV communications[J]. IEEE Transactions on Vehicular Technology, 2018,67(9): 9042-9046.
|
| [14] |
AL-HOURANI A , KANDEEPAN S , LARDNER S . Optimal LAP altitude for maximum coverage[J]. IEEE Wireless Communications Letters, 2014,3(6): 569-572.
|
| [15] |
SCHULMAN J , WOLSKI F , DHARIWAL P ,et al. Proximal policy optimization algorithms[J]. arXiv:1707.06347, 2017
|
| [16] |
SCHAUL T , QUAN J , ANTONOGLOU I ,et al. Prioritized experience replay[J]. arXiv:1511.05952, 2015
|
| [17] |
MNIH V , BADIA A P , MIRZA M ,et al. Asynchronous methods for deep reinforcement learning[C]// International Conference on Machine Learning. 2016: 1928-1937.
|
| [18] |
KULKARNI T D , NARASIMHAN K , SAEEDI A ,et al. Hierarchical deep reinforcement learning:integrating temporal abstraction and intrinsic motivation[C]// Advances in Neural Information Processing Systems. 2016: 3675-3683.
|
| [19] |
丁瑞金, 高飞飞, 邢玲 . 基于深度强化学习的物联网智能路由策略[J]. 物联网学报, 2019,3(2): 56-63.
|
|
DING R J , GAO F F , XING L . Intelligent routing strategy in the Internet of things based on deep reinforcement learning[J]. Chinese Journal on Internet of Things, 2019,3(2): 56-63.
|
| [20] |
MNIH V , KAVUKCUOGLU K , SILVER D ,et al. Human-level control through deep reinforcement learning[J]. Nature, 2015,518(7540): 529-533.
|
| [21] |
SUTTON R S , PRECUP D , SINGH S . Between MDPs and semi-MDPs:a framework for temporal abstraction in reinforcement learning[J]. Artificial Intelligence, 1999,112(1-2): 181-211.
|
| [22] |
蒋昂波, 王维维 . ReLU 激活函数优化研究[J]. 传感器与微系统, 2018,37(2): 50-52.
|
|
JIANG A B , WANG W W . Research on optimization of ReLU activation function[J]. Transducer and Microsystem Technology, 2018,37(2): 50-52.
|
| [23] |
TOKIC M , PALM G . Value-difference based exploration:adaptive control between epsilon-greedy and softmax[C]// Annual Conference on Artificial Intelligence. Springer, 2011: 335-346.
|
| [24] |
BOR-YALINIZ R I , EL-KEYI A , YANIKOMEROGLU H . Efficient 3-D placement of an aerial base station in next generation cellular networks[C]// 2016 IEEE International Conference on Communications (ICC). IEEE, 2016: 1-5.
|