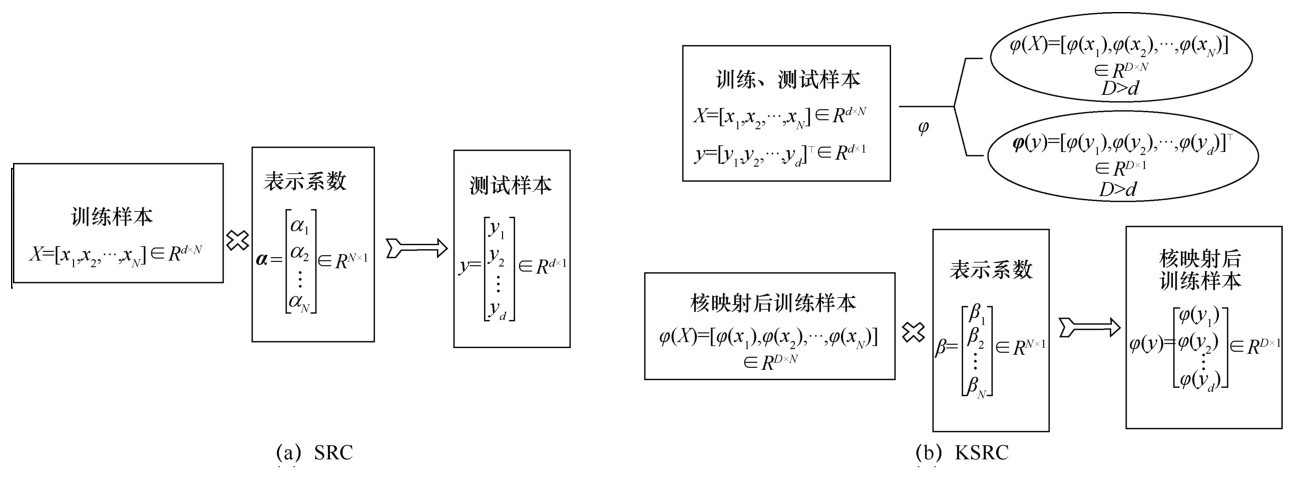
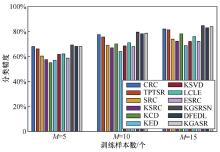
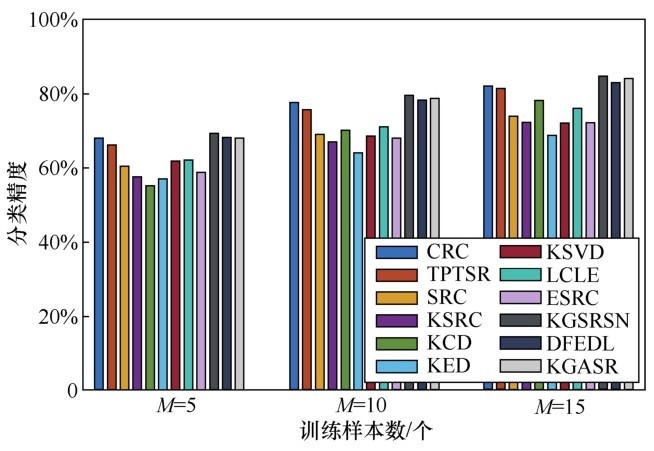
| [1] |
SHEKHAR S , PATEL V M , NASRABADI N M ,et al. Joint sparse representation for robust multimodal biometrics recognition[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2013,36(1): 113-126.
|
| [2] |
YANG M , ZHANG L , FENG X ,et al. Sparse representation based fisher discrimination dictionary learning for image classification[J]. International Journal of Computer Vision, 2014,109(3): 209-232.
|
| [3] |
WANG J , LU C , WANG M ,et al. Robust face recognition via adaptive sparse representation[J]. IEEE Transactions on Cybernetics, 2014,44(12): 2368-2378.
|
| [4] |
YANG J , LUO L , QIAN J ,et al. Nuclear norm based matrix regression with applications to face recognition with occlusion and illumination changes[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2016,39(1): 156-171.
|
| [5] |
WRIGHT J , YANG A Y , GANESH A ,et al. Robust face recognition via sparse representation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2008,31(2): 210-227.
|
| [6] |
ZHANG Z , XU Y , YANG J ,et al. A survey of sparse representation:algorithms and applications[J]. IEEE.Translations and Content Mining, 2015,3: 490-530.
|
| [7] |
SHU T , ZHANG B , TANG Y Y . Sparse supervised representation-based classifier for uncontrolled and imbalanced classification[J]. IEEE Transactions on Neural Networks and Learning Systems, 2018,31(8): 2847-2856.
|
| [8] |
ABAVISANI M , PATEL V M . Deep multimodal sparse representation-based classification[C]// Proceedings of the IEEE International Conference on Image Processing. Piscataway:IEEE Press, 2020: 773-777.
|
| [9] |
YANG J , CHU D , ZHANG L ,et al. Sparse representation classifier steered discriminative projection with applications to face recognition[J]. IEEE Transactions on Neural Networks and Learning Systems, 2013,24(7): 1023-1035.
|
| [10] |
QIAN J , LUO L , YANG J ,et al. Robust nuclear norm regularized regression for face recognition with occlusion[J]. Pattern Recognition, 2015,48(10): 3145-3159.
|
| [11] |
ZHANG J , ZHAO D , GAO W . Group-based sparse representation for image restoration[J]. IEEE Transactions on Image Processing, 2014,23(8): 3336-3351.
|
| [12] |
YANG J , WRIGHT J , HUANG T S ,et al. Image super-resolution via sparse representation[J]. IEEE Transactions on Image Processing, 2010,19(11): 2861-2873.
|
| [13] |
HONG Z , MEI X , PROKHOROV D ,et al. Tracking via robust multi-task multi-view joint sparse representation[C]// Proceedings of the IEEE International Conference on Computer Vision. Piscataway:IEEE Press, 2013: 649-656.
|
| [14] |
WANG S J , YANG J , SUN M F ,et al. Sparse tensor discriminant color space for face verification[J]. IEEE Transactions on Neural Networks and Learning Systems, 2012,23(6): 876-888.
|
| [15] |
BELHUMEUR P N , HESPANHA J P , KRIEGMAN D J.Eigenfaces vs . Fisherfaces:recognition using class specific linear projection[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 1997,19(7): 711-720.
|
| [16] |
ZHANG L , YANG M , FENG X . Sparse representation or collaborative representation:which helps face recognition?[C]// Proceedings of the International Conference on Computer Vision. Piscataway:IEEE Press, 2011: 471-478.
|
| [17] |
DENG W , HU J , GUO J . Extended SRC:undersampled face recognition via intraclass variant dictionary[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2012,34(9): 1864-1870.
|
| [18] |
SHEN C , CHEN L , DONG Y ,et al. Sparse representation classification beyond L1minimization and the subspace assumption[J]. IEEE Transactions on Information Theory, 2020,66(8): 5061-5071.
|
| [19] |
YANG C , WANG W , FENG X ,et al. Classification-friendly sparse encoder and classifier learning[J]. IEEE Access, 2020,8: 54494-54505.
|
| [20] |
ABAVISANI M , PATEL V M . Deep multimodal sparse representation-based classification[C]// Proceedings of the IEEE International Conference on Image Processing (ICIP).[S.l.:s.n.], 2020: 773-777.
|
| [21] |
BENUWA B B , GHANSAH B , ANSAH E K . Kernel based locality–sensitive discriminative sparse representation for face recognition[J]. Scientific African, 2020,7:e00249.
|
| [22] |
ZHANG L , ZHOU W D , CHANG P C ,et al. Kernel sparse representation-based classifier[J]. IEEE Transactions on Signal Processing, 2011,60(4): 1684-1695.
|
| [23] |
CHANG C C , LIN C J . LIBSVM:a library for support vector machines[J]. ACM Transactions on Intelligent Systems and Technology, 2011,2(3): 1-27.
|
| [24] |
ZHANG G , SUN H , XIA G ,et al. Multiple kernel sparse representa tion-based orthogonal discriminative projection and its cost-sensitive extension[J]. IEEE Transactions on Image Processing, 2016,25(9): 4271-4285.
|
| [25] |
JIAN M , JUNG C . Class-discriminative kernel sparse representation-based classification using multi-objective optimization[J]. IEEE Transactions on Signal Processing, 2013,61(18): 4416-4427.
|
| [26] |
GAO S , TSANG I W H , CHIA L T . Sparse representation with kernels[J]. IEEE Transactions on Image Processing, 2012,22(2): 423-434.
|
| [27] |
SONG B , LI P , LI J ,et al. One-class classification of remote sensing images using kernel sparse representation[J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2016,9(4): 1613-1623.
|
| [28] |
ZHOU Y , LIU K , CARRILLO R E ,et al. Kernel-based sparse representation for gesture recognition[J]. Pattern Recognition, 2013,46(12): 3208-3222.
|
| [29] |
HUANG K K , DAI D Q , REN C X ,et al. Learning kernel extended dictionary for face recognition[J]. IEEE Transactions on Neural Networks and Learning Systems, 2016,28(5): 1082-1094.
|
| [30] |
WANG L , YAN H , LV K ,et al. Visual tracking via kernel sparse representation with multikernel fusion[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2014,24(7): 1132-1141.
|
| [31] |
LIU J , WU Z , XIAO L ,et al. Learning multiple parameters for kernel collaborative representation classification[J]. IEEE Transactions on Neural Networks and Learning Systems, 2020,31(12): 5068-5078.
|
| [32] |
FAN Z , NI M , ZHU Q ,et al. L0-norm sparse representation based on modified genetic algorithm for face recognition[J]. Journal of Visual Communication and Image Representation, 2015,28: 15-20.
|
| [33] |
LI Z , ZHANG Z , QIN J ,et al. Discriminative fisher embedding dictionary learning algorithm for object recognition[J]. IEEE Transactions on Neural Networks and Learning Systems, 2019,31(3): 786-800.
|
| [34] |
BOYD S , BOYD S P , VANDENBERGHE L . Convex optimization[M]. Cambridge: Cambridge University Press, 2004.
|
| [35] |
ESTéVEZ P A , TESMER M , PEREZ C A ,et al. Normalized mutual information feature selection[J]. IEEE Transactions on Neural Networks, 2009,20(2): 189-201.
|
| [36] |
杜宏庆, 陈德旺, 黄允浒 ,等. 基于改进遗传算法与支持度的模糊系统优化建模方法[J]. 智能科学与技术学报, 2020,2(2): 179-185.
|
|
DU H X , CHEN D W , HUANG Y H ,et al. A fuzzy system optimization modeling method based on improved genetic algorithm and support degree[J]. Chinese Journal of Intelligent Science and Technology, 2020,2(2): 179-185.
|
| [37] |
辛峻峰, 张永波, 伯佳更 ,等. 基于数据驱动的遗传算法的无人艇路径规划研究[J]. 智能科学与技术学报, 2019,1(2): 171-180.
|
|
XIN J F , ZHANG Y B , BO J G ,et al. Study on path planning of unmanned surface vessel based on data-driven genetic algorithm[J]. Chinese Journal of Intelligent Science and Technology, 2019,1(2): 171-180.
|
| [38] |
SUN Y , ZHANG Z , JIANG W ,et al. Discriminative local sparse representation by robust adaptive dictionary pair learning[J]. IEEE Transactions on Neural Networks and Learning Systems, 2020,31(10): 4303-4317.
|
| [39] |
XU Y , ZHANG D , YANG J ,et al. A two-phase test sample sparse representation method for use with face recognition[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2011,21(9): 1255-1262.
|
| [40] |
HAN N , WU J , FANG X ,et al. Projective double reconstructions based dictionary learning algorithm for cross-domain recognition[J]. IEEE Transactions on Image Processing, 2020,29: 9220-9233.
|
| [41] |
YANG J , ZHANG L , XU Y ,et al. Beyond sparsity:the role of L1-optimizer in pattern classification[J]. Pattern Recognition, 2012,45(3): 1104-1118.
|
| [42] |
CAI D , HE X , HAN J . Speed up kernel discriminant analysis[J]. The VLDB Journal, 2011,20(1): 21-33.
|
| [43] |
XU Y , ZHANG D , JIN Z ,et al. A fast kernel-based nonlinear discriminant analysis for multi-class problems[J]. Pattern Recognition, 2006,39(6): 1026-1033.
|
| [44] |
RUSSELL S J , STUART J . Norvig[J]. Artificial Intelligence:A Modern Approach, 2003: 111-114.
|
| [45] |
ZHENG J , QIU H , SHENG W ,et al. Kernel group sparse representation classifier via structural and non-convex constraints[J]. Neurocomputing, 2018,296: 1-11.
|
| [46] |
LI Z , LAI Z , XU Y ,et al. A locality-constrained and label embedding dictionary learning algorithm for image classification[J]. IEEE Transactions on Neural Networks and Learning Systems, 2015,28(2): 278-293.
|
| [47] |
XU Y , LI Z , YANG J ,et al. A survey of dictionary learning algorithms for face recognition[J]. IEEE Access, 2017,5: 8502-8514.
|
| [48] |
LI Z , ZHANG Z , QIN J ,et al. Discriminative Fisher embedding dictionary learning algorithm for object recognition[J]. IEEE Transactions on Neural Networks and Learning Systems, 2020,31(3): 786-800.
|
| [49] |
BEVERIDGE J R , DRAPER B A , CHANG J M ,et al. Principal angles separate subject illumination spaces in YDB and CMU-PIE[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2008,31(2): 351-363.
|
| [50] |
MARTINEZ A M , KAK A C . PCA versus LDA[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2001,23(2): 228-233.
|
| [51] |
FAN Z , XU Y , ZUO W ,et al. Modified principal component analysis:an integration of multiple similarity subspace models[J]. IEEE Transactions on Neural Networks and Learning Systems, 2014,25(8): 1538-1552.
|
| [52] |
LECUN Y , BOTTOU L , BENGIO Y ,et al. Gradient-based learning applied to document recognition[J]. Proceedings of the IEEE, 1998,86(11): 2278-2324.
|