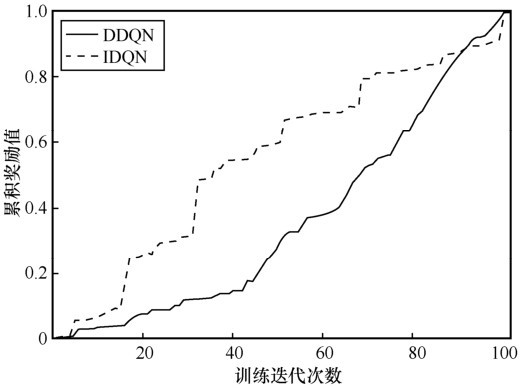
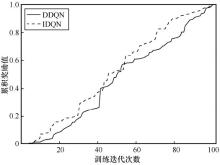
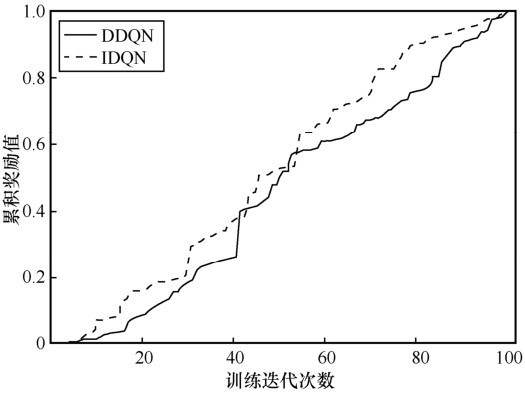
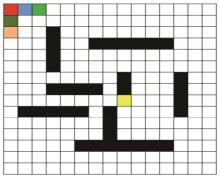
| [1] |
史进, 董瑶, 白振东 ,等. 移动机器人动态路径规划方法的研究与实现[J]. 计算机应用, 2017,37(11): 3119-3123.
|
|
SHI J , DONG Y , BAI Z D ,et al. Research and implementation of mobile robot path planning method[J]. Journal of Computer Applications, 2017,37(11): 3119-3123.
|
| [2] |
魏彤, 龙琛 . 基于改进遗传算法的移动机器人路径规划[J]. 北京航空航天大学学报, 2020,46(4): 703-711.
|
|
WEI T , LONG C . Path planning for mobile robot based on improved genetic algorithm[J]. Journal of Beijing University of Aeronautics and Astronautics, 2020,46(4): 703-711.
|
| [3] |
YOU X M , LIU S , LYU J Q . Ant colony algorithm based on dynamic search strategy and its application on path planning of robot[J]. Control and Decision, 2017,32(3): 552-556.
|
| [4] |
默凡凡 . 基于 Q 学习算法的移动机器人路径规划方法研究[D]. 北京:北京工业大学, 2016.
|
|
MO F F . Research on path planning of mobile robot based on Q learning algorithm[D]. Beijing:Beijing University of Technology, 2016.
|
| [5] |
姜涛, 王建中, 施家栋 . 小型移动机器人自主返航路径规划方法[J]. 计算机工程, 2015,41(1): 164-168.
|
|
JIANG T , WANG J Z , SHI J D . Path planning method in autonomous returning for mini-mobile robot[J]. Computer Engineering, 2015,41(1): 164-168.
|
| [6] |
刘洁, 赵海芳, 周德廉 . 一种改进量子行为粒子群优化算法的移动机器人路径规划[J]. 计算机科学, 2017,44(S2): 123-128.
|
|
LIU J , ZHAO H F , ZHOU D L . Improved quantum behaved particle swarm optimization algorithm for mobile robot path planning[J]. Computer Science, 2017,44(S2): 123-128.
|
| [7] |
孙炜, 吕云峰, 唐宏伟 ,等. 基于一种改进A*算法的移动机器人路径规划[J]. 湖南大学学报(自然科学版), 2017,44(4): 94-101.
|
|
SUN W , LYU Y F , TANG H W ,et al. Mobile robot path planning based on an improved A* algorithm[J]. Journal of Hunan University (Natural Sciences), 2017,44(4): 94-101.
|
| [8] |
胡俊, 朱庆保 . 未知环境下基于有先验知识的滚动Q学习机器人路径规划[J]. 控制与决策, 2010,25(9): 1364-1368.
|
|
HU J , ZHU Q B . Path planning of robot for unknown environment based on prior knowledge rolling Q-learning[J]. Control and Decision, 2010,25(9): 1364-1368.
|
| [9] |
XIN J , ZHAO H , LIU D ,et al. Application of deep reinforcement learning in mobile robot path planning[C]// Proceedings of 2017 Chinese Automation Congress. Piscataway:IEEE Press, 2017: 7112-7116.
|
| [10] |
TAI L , LIU M . Towards cognitive exploration through deep reinforcement learning for mobile robots[J]. arXiv preprint,2016,arXiv:1610.01733.
|
| [11] |
江其洲, 曾碧 . 基于深度强化学习的移动机器人导航策略研究[J]. 计算机测量与控制, 2019,27(8): 217-221,226.
|
|
JIANG Q Z , ZENG B . Research on navigation strategy of mobile robot based on deep reinforcement learning[J]. Computer Measurement& Control, 2019,27(8): 217-221,226.
|
| [12] |
张荣霞, 武长旭, 孙同超 ,等. 深度强化学习及在路径规划中的研究进展[J]. 计算机工程与应用, 2021,57(19): 44-56.
|
|
ZHANG R X , WU C X , SUN T C ,et al. Progress on deep reinforcement learning in path planning[J]. Computer Engineering and Applications, 2021,57(19): 44-56.
|
| [13] |
刘朝阳, 穆朝絮, 孙长银 . 深度强化学习算法与应用研究现状综述[J]. 智能科学与技术学报, 2020,2(4): 314-326.
|
|
LIU Z Y , MU C X , SUN C Y . An overview on algorithms and applications of deep reinforcement learning[J]. Chinese Journal of Intelligent Science and Technology, 2020,2(4): 314-326.
|
| [14] |
韩向敏, 鲍泓, 梁军 ,等. 一种基于深度强化学习的自适应巡航控制算法[J]. 计算机工程, 2018,44(7): 32-35,41.
|
|
HAN X M , BAO H , LIANG J ,et al. An adaptive cruise control algorithm based on deep reinforcement learning[J]. Computer Engineering, 2018,44(7): 32-35,41.
|
| [15] |
刘婵, 朱永川, 白园 ,等. 基于 flocking 的多智能体群集与避障算法研究与仿真[J]. 通信技术, 2019,52(7): 1632-1638.
|
|
LIU C , ZHU Y C , BAI Y ,et al. Flocking for multi-agent clustering and obstacle avoidance:algorithm and simulation[J]. Communications Technology, 2019,52(7): 1632-1638.
|
| [16] |
刘辉, 肖克, 王京擘 . 基于多智能体强化学习的多 AGV 路径规划方法[J]. 自动化与仪表, 2020,35(2): 84-89.
|
|
LIU H , XIAO K , WANG J B . Multi-AGV path planning method based on multi-agent reinforcement learning[J]. Automation & Instrumentation, 2020,35(2): 84-89.
|
| [17] |
黄子蓉, 甯彦淞, 王莉 . 基于优先经验回放的多智能体协同算法[J]. 太原理工大学学报, 2021,52(5): 747-753.
|
|
HUANG Z R , NING Y S , WANG L . Prioritized experience replay for multi-agent cooperation[J]. Journal of Taiyuan University of Technology, 2021,52(5): 747-753.
|
| [18] |
高振洋, 秦斌 . 深度强化学习研究进展[J]. 电脑知识与技术, 2019,15(4): 157-159,173.
|
|
GAO Z Y , QIN B . Progress in deep reinforcement learning research[J]. Computer Knowledge and Technology, 2019,15(4): 157-159,173.
|
| [19] |
杨思明, 单征, 丁煜 ,等. 深度强化学习研究综述[J]. 计算机工程, 2021,47(12): 19-29.
|
|
YANG S M , SHAN Z , DING Y ,et al. Survey of research on deep reinforcement learning[J]. Computer Engineering, 2021,47(12): 19-29.
|
| [20] |
刘全, 翟建伟, 章宗长 ,等. 深度强化学习综述[J]. 计算机学报, 2018,41(1): 1-27.
|
|
LIU Q , ZHAI J W , ZHANG Z C ,et al. A survey on deep reinforcement learning[J]. Chinese Journal of Computers, 2018,41(1): 1-27.
|