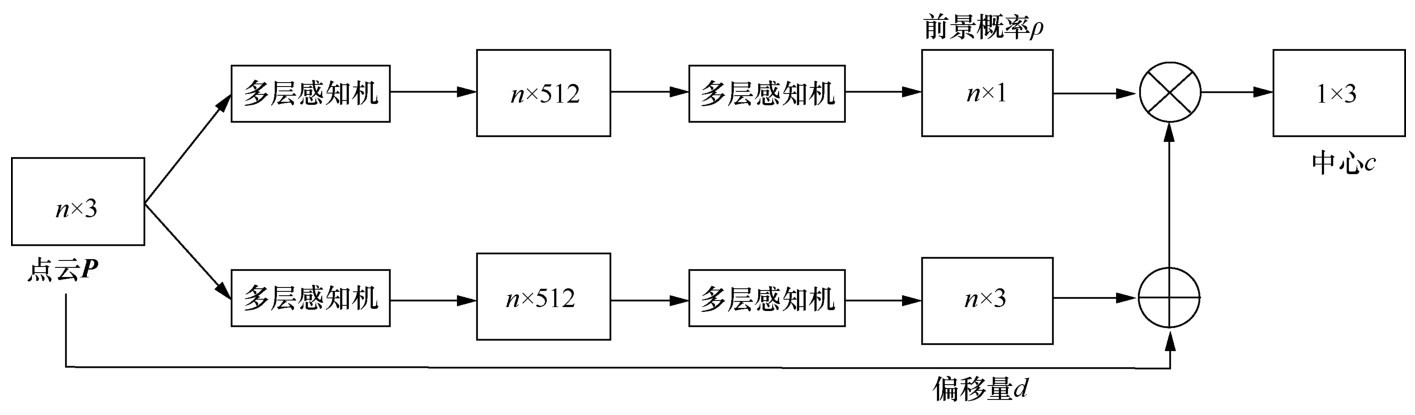
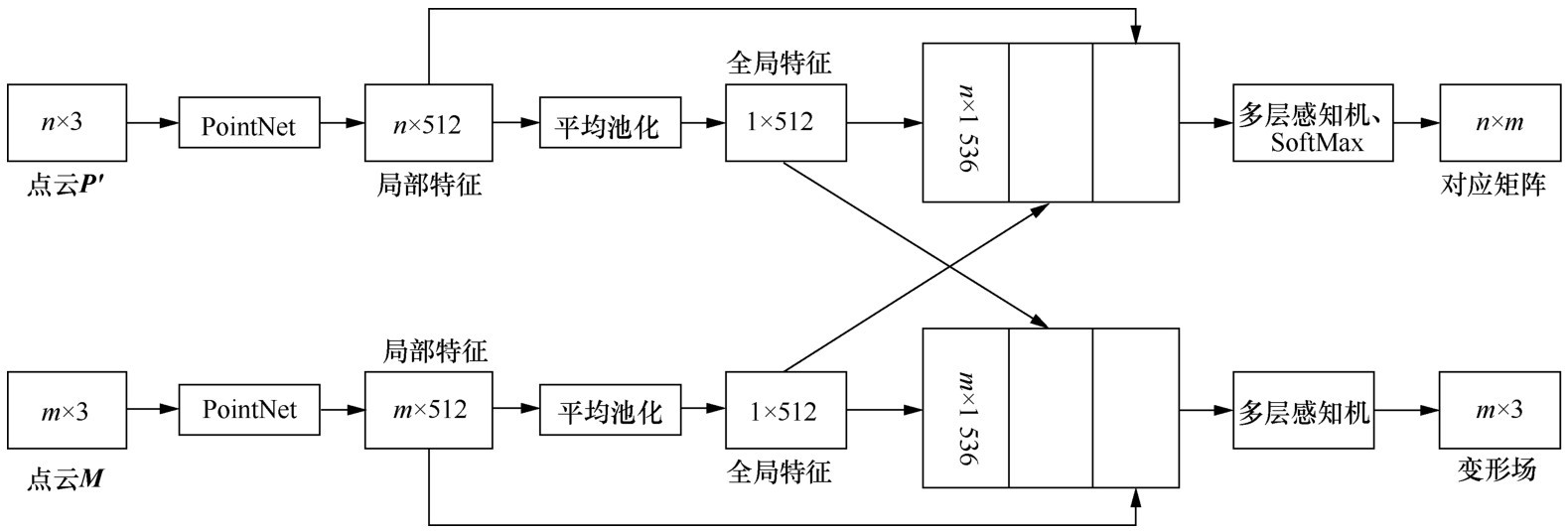
| [1] |
HINTERSTOISSER S , HOLZER S , CAGNIART C ,et al. Multimodal templates for real-time detection of textureless objects in heavily cluttered scenes[C]// Proceedings of 2011 International Conference on Computer Vision.[S.l.:s.n.], 2011.
|
| [2] |
HINTERSTOISSER S , CAGNIART C , ILIC S ,et al. Gradient response maps for real-time detection of textureless objects[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2012,34(5): 876-888.
|
| [3] |
HINTERSTOISSER S , LEPETIT V , ILIC S ,et al. Model based training,detection and pose estimation of texture-less 3D objects in heavily cluttered scenes[C]// Proceedings of the Asian Conference on Computer Vision.[S.l.:s.n.], 2013.
|
| [4] |
DROST B , ULRICH M , NAVAB N ,et al. Model globally,match locally:efficient and robust 3D object recognition[C]// Proceedings of 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE Press, 2010: 998-1005.
|
| [5] |
CHOI C , CHRISTENSEN H I . 3D pose estimation of daily objects using an RGB-D camera[C]// Proceedings of 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems. Piscataway:IEEE Press, 2012: 3342-3349.
|
| [6] |
CHOI C , TREVOR A J B , CHRISTENSEN H I . RGB-D edge detection and edge-based registration[C]// Proceedings of 2013 IEEE/RSJ International Conference on Intelligent Robots and Systems. Piscataway:IEEE Press, 2013: 1568-1575.
|
| [7] |
VIDAL J , LIN C Y , LLADó X , ,et al. A method for 6D pose estimation of free-form rigid objects using point pair features on range data[J]. Sensors, 2018,18(8): 2678.
|
| [8] |
GUO J W , XING X J , QUAN W Z ,et al. Efficient center voting for object detection and 6D pose estimation in 3D point cloud[J]. IEEE Transactions on Image Processing:a Publication of the IEEE Signal Processing Society, 2021,30: 5072-5084.
|
| [9] |
XIANG Y , SCHMIDT T , NARAYANAN V ,et al. PoseCNN:a convolutional neural network for 6D object pose estimation in cluttered scenes[C]// Proceedings of Robotics:Science and Systems XIV. Robotics:Science and Systems Foundation, 2018.
|
| [10] |
LI Y , WANG G , JI X Y ,et al. DeepIM:deep iterative matching for 6D pose estimation[J]. International Journal of Computer Vision, 2020,128(3): 657-678.
|
| [11] |
XU D F , ANGUELOV D , JAIN A . PointFusion:deep sensor fusion for 3D bounding box estimation[C]// Proceedings of 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE Press, 2018: 244-253.
|
| [12] |
WANG C , XU D F , ZHU Y K ,et al. DenseFusion:6D object pose estimation by iterative dense fusion[C]// Proceedings of 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE Press, 2019: 3338-3347.
|
| [13] |
HE Y S , SUN W , HUANG H B ,et al. PVN3D:a deep point-wise 3D keypoints voting network for 6DoF pose estimation[C]// Proceedings of 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE Press, 2020: 11629-11638.
|
| [14] |
HE Y S , HUANG H B , FAN H Q ,et al. FFB6D:a full flow bidirectional fusion network for 6D pose estimation[C]// Proceedings of 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE Press, 2021: 3002-3012.
|
| [15] |
ARUN K S , HUANG T S , BLOSTEIN S D . Least-squares fitting of two 3-D point sets[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 1987,9(5): 698-700.
|
| [16] |
LEPETIT V , MORENO-NOGUER F , FUA P . EPnP:an accurate O(n)solution to the PnP problem[J]. International Journal of Computer Vision, 2008,81(2): 155-166.
|
| [17] |
BESL P J , MCKAY N D . Method for registration of 3-D shapes[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 1992,14(2): 239-256.
|
| [18] |
LABBé Y , CARPENTIER J , AUBRY M ,et al. CosyPose:consistent multi-view multi-object 6D pose estimation[J]. arXiv preprint,2020,arXiv:2008.08465.
|
| [19] |
PARK K , PATTEN T , VINCZE M . Pix2Pose:pixel-wise coordinate regression of objects for 6D pose estimation[C]// Proceedings of 2019 IEEE/CVF International Conference on Computer Vision. Piscataway:IEEE Press, 2019: 7667-7676.
|
| [20] |
LI Z G , WANG G , JI X Y . CDPN:coordinates-based disentangled pose network for real-time RGB-based 6-DoF object pose estimation[C]// Proceedings of 2019 IEEE/CVF International Conference on Computer Vision. Piscataway:IEEE Press, 2019: 7677-7686.
|
| [21] |
K?NIG R , DROST B . A hybrid approach for 6DoF pose estimation[J]. arXiv preprint,2020,arXiv:2011.05669.
|
| [22] |
HODA? T , BARáTH D , MATAS J . EPOS:estimating 6D pose of objects with symmetries[C]// Proceedings of 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE Press, 2020: 11700-11709.
|
| [23] |
HAGELSKJ?R F , BUCH A G . PointVoteNet:accurate object detection and 6 DOF pose estimation in point clouds[C]// Proceedings of 2020 IEEE International Conference on Image Processing. Piscataway:IEEE Press, 2020: 2641-2645.
|
| [24] |
SUNDERMEYER M , DURNER M , PUANG E Y ,et al. Multi-path learning for object pose estimation across domains[C]// Proceedings of 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE Press, 2020: 13913-13922.
|
| [25] |
SAHIN C , KIM T K . Category-level 6D object pose recovery in depth images[C]// Proceedings of the European Conference on Computer Vision. Cham:Springer, 2019.
|
| [26] |
WANG H , SRIDHAR S , HUANG J W ,et al. Normalized object coordinate space for category-level 6D object pose and size estimation[C]// Proceedings of 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE Press, 2019: 2637-2646.
|
| [27] |
UMEYAMA S . Least-squares estimation of transformation parameters between two point patterns[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 1991,13(4): 376-380.
|
| [28] |
FISCHLER M A , BOLLES R C . Random sample consensus:a paradigm for model fitting with applications to image analysis and automated cartography[J]. Communications of the ACM, 1981,24(6): 381-395.
|
| [29] |
CHEN D S , LI J , WANG Z ,et al. Learning canonical shape space for category-level 6D object pose and size estimation[C]// Proceedings of 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE Press, 2020: 11970-11979.
|
| [30] |
AN J , CHO S . Variational autoencoder based anomaly detection using reconstruction probability[J]. Special Lecture on IE, 2015,2(1): 1-18.
|
| [31] |
TIAN M , ANG M H , LEE G H . Shape prior deformation for categorical 6D object pose and size estimation[C]// Proceedings of the European Conference on Computer Vision. Cham:Springer, 2020: 530-546.
|
| [32] |
CHARLES R Q , HAO S , MO K C ,et al. PointNet:deep learning on point sets for 3D classification and segmentation[C]// Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE Press, 2017: 77-85.
|