1 引言
与其他人工智能方法(如神经网络(Neural Network,NN)、进化算法等)相比,模糊系统理论的突出优点是整个系统是基于规则构建的,在可解释性上具有显著的优越性[1 ] ,主要体现在结构与参数具有清晰的物理意义、每一条规则都可以被直观地解释,这为人们理解与接受其中蕴涵的知识提供了思路。模糊系统由一系列IF-THEN规则构成,系统的结构和参数可以用IF-THEN规则解释,且具备快速、灵活性强的优势。而神经网络在这方面却表现很差,即使是专家也难以解释和理解参数的意义。目前,基于全局优化的模糊神经网络系统以及神经网络、模糊系统和遗传算法三者相结合的方法能够优化从数据中提取出的模糊规则。尽管该方法已经较好地解决了上述问题,但系统的可解释性仍得不到保证。其原因在于这些算法的目标是获得最优系统响应性能,而对模糊集合划分个数、隶属函数参数的选取缺乏有效的指导[1 ,2 ] 。因此,如何在提高模糊系统精度与收敛速度的同时,得到最优的响应系统,克服算法效率下降的问题,增强系统的可解释性已成为研究的热点。
模糊建模的关键是模糊规则的获取,Wang 等人[3 ] 于1992年证明了一类模糊系统是万能逼近器,开辟了模糊逼近领域,并与 Mendel 共同提出一种与先验知识无关的、从样本数据中获得模糊规则的方法[4 ] ,该方法可以从完备的、规模较小且不含坏数据的样本集中获得完备的、具有较好逼近性能的模糊规则库,取得了较好的成果,但 Wang-Mendel (WM)方法存在以下几个问题:一是其产生的模糊规则库缺乏良好的完备性和鲁棒性,进而导致模糊系统精度不高;二是算法效率下降很快,对高维大数据问题无能为力;三是规则数目随着输入维度的增加而呈指数式增加,难以摆脱高维的魔咒。针对此问题,众多学者提出了改进算法。参考文献[5 ]提出的一种模糊c均值聚类(fuzzy c-means,FCM)算法可以在一定程度上减小样本的规模,消除噪声数据,提高WM方法的完备性和鲁棒性,提高模糊系统的预测精度。参考文献[6 ]提出了一种基于粒子群优化的改进WM方法,采用改进的粒子群优化算法对数据覆盖区域的模糊规则质心进行优化,通过外推得到完整的模糊规则集,在一定程度上提高了WM方法的预测精度。参考文献[7 ]提出一种改进的WM方法来优化样本,利用样本间的加权距离提取完整的模糊规则库,具有良好的性能,缺点为只能处理低维小数据。参考文献[8 ]提出了一种简化的加权WM方法,通过平衡算法的完备性和计算时间来解决模糊规则的数量和数据规模导致的 WM 方法效率不高的问题。参考文献[9 ]提出了一种基于改进的WM方法的语义描述方法,该方法得到的语言规则库在准确度和可解释性方面具有较强的竞争力。然而,在测试过程中,如何在避免算法效率下降以及兼顾完备性、鲁棒性的同时,提高模糊系统的可解释性,仍然是亟待解决的问题。
基于以上分析,本文提出了一种基于改进遗传算法与支持度的模糊系统优化建模方法。模糊建模实验表明,本文所提的方法在回归预测问题上比其他方法效果更佳,在充分发挥模糊系统强鲁棒性的优势的同时保障了预测精度,且有效降低了模糊规则数目,提高了模糊系统的可解释性。
2 模糊系统初始化
假设U = { ( x i ; y i ) } i = 1 N x i = [ x 1 i , x 2 i , ⋯ , x j i , ⋯ , x m i ] i 为对应的输出值。本文模糊系统初始化的步骤如下。
第一步,将输入、输出空间划分为对应的模糊区间。在每个输入变量以及输出变量的论域上,划分若干个模糊子集,每个子集对应一个隶属函数。各变量的模糊子集数量及对应的隶属函数类型可按实际情况调整。
第二步,从训练样本中提取模糊规则,一条输入输出样本数据产生一条模糊规则。例如,对于某条训练样本(xi ;yi ),计算每一维度的所有隶属函数值,选取具有最大隶属函数值的模糊子集,并由每一维度上选中的模糊子集Ar 、Br 组合得到该训练样本对应的模糊规则:
if x 1 i is A 1 and x 2 i is A 2 ⋯ and
x m i is A m then y i is B l ( 1 )
第三步,赋予每条规则一个强度[4 ] 。规则的强度D()i 定义如下:
D ( i ) = ( ∏ j = 1 m F j s ( i , j ) ( x j i ) ) ⋅ F s ( i ) ( y i ) ( 2 )
其中,Fk (⋅)为论域上的模糊子集Fk 的隶属函数, S(,i j)、S ( i ) x j i i 被选中的模糊子集所在位置索引。
第四步,创建模糊规则库。当样本量大时,容易产生冲突规则与冗余规则。为解决上述问题,当向规则库添加一条规则时,先检查该条规则的前件是否已存在于规则库中,若不存在,则加入规则库;否则,保留该条规则与规则库中具有最大强度的规则。
第五步,基于模糊规则库构建模糊系统,并进行模糊推理预测。采用中心反模糊化推理机,可得到第i条规则输出模糊子集的中心值为y ¯ i
y ( x ) = ∑ i = 1 R ∏ j = 1 m F j s ( i , j ) ( x j ) ⋅ y ¯ i ∑ i = 1 R ∏ j = 1 m F j s ( i , j ) ( x j ) ( 3 )
至此,初始化模型构建完成。该模型的不足之处在于其产生的模糊规则库缺乏良好的完备性和鲁棒性[10 ] ,进而导致模型精度不高。因此,为了提高模型精度,需要采取某种全局优化方法来提高模糊系统性能,从而提取更可靠、更优的规则,避免从“坏数据”提取出“坏规则”[11 ] 而导致模型精度下降现象的产生。另外,减少模糊系统规则数、提升其可解释性也是优化目的之一。
3 改进遗传算法适应度函数
遗传算法(genetic algorithm,GA)是模拟生物进化论的自然选择和群体遗传机理的计算模型,通过模拟自然选择和自然遗传过程中的繁殖、杂交和突变现象来求解问题,体现了“优胜劣汰,适者生存”的思想。其通过概率的状态转移规则自适应地调整搜索方向,本质上是一种随机化搜索全局最优解的方法,适用于模糊系统的优化[12 ] 。
适应度函数的质量在一定程度上决定了遗传算法搜索的范围与全局寻优能力。传统的遗传算法将单一目标函数作为适应度函数,考虑问题不够全面,有时无法寻得最优解。为综合评估模糊系统参数所有可行解的适应度并提升遗传算法找到最优解的效率,本文从传统的遗传算法出发,对适应度函数的确定方法进行改进:对于n个目标函数f i ( x ) ( i = 1 , 2 , ⋯ , n ) [13 ] 与评价函数法,赋予每个目标函数权重w i ( i = 1 , 2 , ⋯ , n )
μ ( x ) = ∑ i = 1 n w i ⋅ f i ( x ) ( 4 )
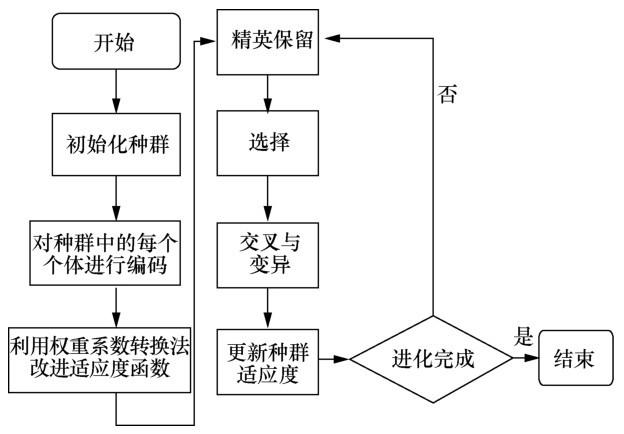
将多目标函数 μ ( x ) = ∑ i = 1 n w i ⋅ f i ( x ) ( 4 ) 图1 所示。
图1
4 遗传模糊系统
4.1 问题描述
作为一种全局优化方法,遗传算法适用于模糊系统的结构和隶属函数参数集的优化。当前,利用遗传算法优化模糊系统的一般方法存在一定缺陷。例如,在优化完成后,不同的模糊规则中同一语言变量具有相同语义的模糊子集的参数往往不同[14 ] ,这在一定程度上降低了模糊系统的可解释性;再者,若维持模糊子集的语义一致性,而对不同的模糊子集进行编码[15 ] ,只能优化隶属函数参数,无法优化模糊系统的结构。
针对上述问题,本文以改进遗传算法机理和初始化模型的不足为出发点,利用随机化技术以及选择、交叉和变异操作[16 ] 对一个经过编码的隶属函数的参数空间进行高效搜索,优化模糊系统的结构和参数;提出一种基于改进遗传算法的模糊系统,即遗传模糊系统(genetic fuzzy system,GFS)的优化建模方法,对模糊系统结构及隶属函数参数进行优化,以提高模糊系统输入隶属函数的适应性和模糊规则的质量,从而提升模糊系统的可解释性及其模型的精度。
4.2 GFS建模
结合改进遗传算法机理和初始化模糊系统,给出如下GFS建模流程。
第一步,初始化种群。为确保种群基因的多样性,在式(3)中待优化的n维隶属函数参数解向量S = [ k 1 , k 2 , ⋯ , k j , ⋯ , k n ]
第二步,染色体编码。采用二进制编码方式将每个个体编码为基因型,并通过进制转换将基因型转换成表现型(十进制)。
第三步,评估种群。选择目标函数作为个体的适应度函数,通过适应度函数值来评估种群。本文综合考虑模糊系统精度评价指标,分别将平均绝对误差(mean absolute error,MAE)、均方误差(mean square error,MSE)以及决定系数R2 作为目标函数,计算式如下:
MAE ( y ^ i , y i ) = 1 n ∑ i = 1 n | y ^ i − y i | ( 5 )
MSE ( y ^ i , y i ) = 1 n ∑ i = 1 n ( y ^ i − y i ) 2 ( 6 )
R 2 ( y ^ i , y i ) = 1 − ∑ i = 1 n ( y ^ i − y i ) 2 ∑ i = 1 n ( y ¯ i − y i ) 2 ( 7 )
其中,y ^ i i 为实际值,y ¯ i i 的中心值。为综合评估种群,引入式(5)~式(7)作为多目标函数,并采用权重系数转换法,给每个目标函数fi (x)(i=1,2,3)赋予权重wi (i=1,2,3),通过式(4)得到评估该种群的适应度函数。
第四步,选择。选择操作的原则是个体适应度越大,被选择到下一代的机会越大。本文采用轮盘赌方式,即利用个体适应度计算其被选择的概率[17 ] ,根据概率决定该个体是否遗传到下一代。设个体i的适应度为上述某个目标函数值 fi ,种群规模为PS,则个体i被选择的概率为:
P i = f i ∑ i = 1 PS f i ( 8 )
第五步,交叉与变异。对第四步选中的个体采用交叉算子、变异算子产生下一代个体。其中,交叉操作的目的是保留具有优良性状的基因,而变异操作的目的是增加基因的多样性,提高在解空间中找到全局最优解的概率。本文采用的变异概率范围为0.001~0.1。
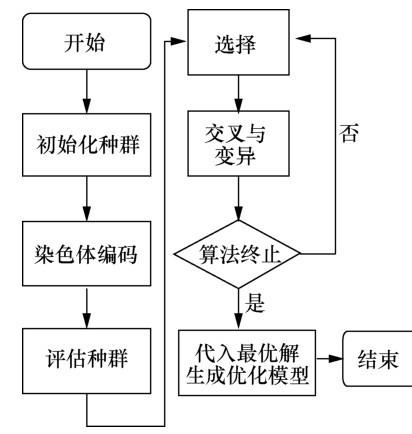
第六步,算法终止判断。根据设定的最优解的阈值或迭代次数来判断算法是否终止,并将子代中具有最高适应度的个体对应的解向量作为全局最优解,输出该解。
第七步,代入最优解生成优化模型。将第六步搜索到的 n 维全局最优解向量 S * = [ k 1 * , k 2 * , ⋯ , k j * , ⋯ , k n * ] F k ( ⋅ ) F * k ( ⋅ )
SD ( i ) = ( ∑ j = 1 m F j s ( i , j ) ( x j i ) ) ⋅ F s ( i ) ( y i ) ( 9 )
通过设置SD的阈值来限制“坏规则”加入规则库,从而使模糊系统规则数由R减少为R* ,故优化后的模糊系统如下:
y ( x ) = ∑ i = 1 R * ∏ j = 1 m F j * s ( i , j ) ( x j ) ⋅ y ¯ i ∑ i = 1 R * ∏ j = 1 m F j * s ( i , j ) ( x j ) ( 10 )
图2
5 实验结果与分析
本文采用的CCPP数据集是收集于某联合循环发电厂的9 568个数据点,共包含5个特征:每小时平均环境变量温度(AT)、环境压力(AP)、相对湿度(RH)、排气真空(V)和净每小时电能输出(PE),其中电能输出PE为待预测变量。
为了在回归预测问题上对提出的 GFS 进行评估,比较分析了其与径向基函数(radial basis function,RBF)神经网络[18 ] 、反向传播(back propagation,BP)神经网络[19 ] 、经典Wang-Mendel这3种方法的性能指标。根据上述3个目标函数的不同线性组合生成的GFS模型的优化效果不同,本文枚举出所有可能的线性组合,并介绍其中性能较佳的 3 种模型(GFS1、GFS2 与 GFS3)。以模型精度为设定依据,给出式(4)中的权重系数分配,见表1 。
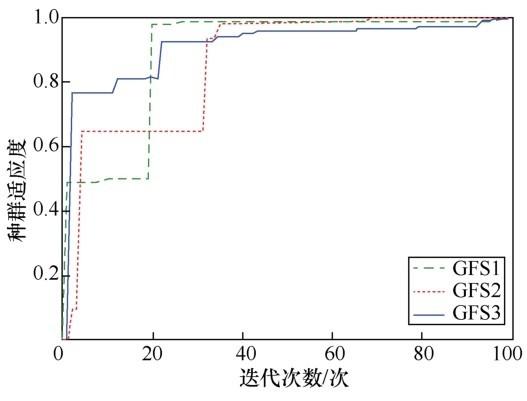
实验结果表明,GFS3 收敛速度最快,优化时间最短。由上述权重系数分配生成适应度函数,并将种群初始化为 10 个个体,经过 100 次遗传迭代后,GFS1、GFS2与GFS3这3个模型的适应度变化曲线如图3 所示。
图3
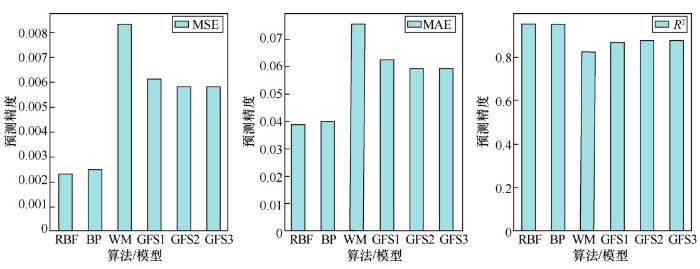
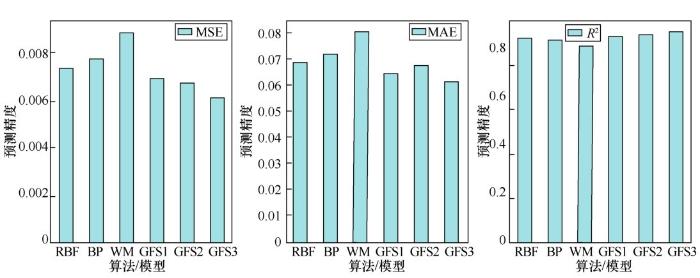
从图3 可以看出,约在第80次迭代时,3种模型均收敛至最优值,这表示已找到全局最优解。收敛完成后的模型GFS1、GFS2与GFS3在标准数据集、加噪(高斯噪声,均值为0,标准偏差为0.12)数据集上进行测试。结果显示,WM方法的规则数为140,而GFSi的规则数仅为65。GFSi的预测精度与其他方法对比结果见表2 、表3 。
由表2 可以看出,GFSi在标准数据集上的预测精度均优于经典WM方法,但在精度方面仍与神经网络算法存在一定差距,这也是目前的模糊系统普遍存在的问题之一[20 ] 。而从表3 可以看出,GFSi的预测精度均优于RBF神经网络、BP神经网络,体现出了模糊系统抗噪能力强的优点。图4 展示了GFSi和WM方法在标准数据集上的预测值与实际值的对比。
图4
图5
以GFS3为例,图5 展示了GFS3和RBF神经网络、BP 神经网络在加噪数据集上的预测值与实际值的对比。
由图4 、图5 可以看出,GFSi的预测精度明显优于经典WM方法,其中GFS3在加噪数据集上的拟合效果最佳,展现出了模糊系统强鲁棒性的优势。
6 结束语
本文针对传统模糊系统建模方法的弊端,提出一种基于改进遗传算法的模糊系统建模方法——GFS,并给出基于规则支持度的规则约简方法,减少了规则数,降低了模糊计算模型的复杂性。模糊建模实验表明,本文提出的方法在回归预测问题上的精度明显高于经典WM方法,并且抗噪能力优于RBF神经网络、BP神经网络算法,在充分发挥模糊系统可解释性、强鲁棒性的优势的同时保障了预测精度。
The authors have declared that no competing interests exist.
作者已声明无竞争性利益关系。
参考文献
View Option
[1]
阎岭 , 郑洪涛 , 蒋静坪 . 基于进化策略生成可解释性模糊系统
[J]. 电子学报 , 2005 ,33 (1 ): 70 -73 .
[本文引用: 2]
YAN L , ZHENG H T , JIANG J P . Generation of interpretable fuzzy system based on evolution strategy
[J]. Acta Electronica Sinica , 2005 ,33 (1 ): 70 -73 .
[本文引用: 2]
[2]
YANG L , ENTCHEV E . Performance prediction of a hybrid microgeneration system using adaptive neuro-fuzzy inference system (ANFIS) technique
[J]. Applied Energy , 2014 ,134 : 197 -203 .
[本文引用: 1]
[3]
WANG L X , MENDEL J M . Fuzzy basis functions,universal approximation,and orthogonal least-squares learning
[J]. IEEE Transactions on Neural Networks , 1992 ,3 (5 ): 807 -814 .
[本文引用: 1]
[4]
WANG L X , MENDEL J M . Generating fuzzy rules by learning from examples
[J]. IEEE Transactions on Systems,Man,and Cybernetics , 1992 ,22 (6 ): 1414 -1427 .
[本文引用: 2]
[5]
GOU J , HOU F , CHEN W Y ,et al . Improving wang-mendel method performance in fuzzy rules generation using the fuzzy c-means clustering algorithm
[J]. Neurocomputing , 2015 ,151 : 1293 -1304 .
[本文引用: 1]
[6]
YANG X M , YUAN J Y , YUAN J S ,et al . An improved WM method based on PSO for electric load forecasting
[J]. Expert Systems with Applications , 2010 ,37 (12 ): 8036 -8041 .
[本文引用: 1]
[7]
GOU J , FAN Z W , WANG C ,et al . An improved wang-mendel method based on the FSFDP clustering algorithm and sample correlation
[J]. Journal of Intelligent & Fuzzy Systems , 2016 ,31 (6 ): 2839 -2850 .
[本文引用: 1]
[8]
FAN Z W , GOU J , WANG C ,et al . A reduced weighted wang-mendel algorithm using the clustering algorithm to build fuzzy system
[C]// The 2016 International Conference on Progress in Informatics and Computing . Piscataway:IEEE Press , 2016 : 8 -12 .
[本文引用: 1]
[9]
WANG Y G , DUAN X D , LIU X D ,et al . Semantic description method for face features of larger Chinese ethnic groups based on improved WM method
[J]. Neurocomputing , 2016 ,175 : 515 -528 .
[本文引用: 1]
[10]
王永富 , 王殿辉 , 柴天佑 . 一个具有完备性和鲁棒性的模糊规则提取算法
[J]. 自动化学报 , 2010 ,36 (9 ): 127 -132 .
[本文引用: 1]
WANG Y F , WANG D H , CHAI T Y . Extraction of fuzzy rules with completeness and robustness
[J]. Acta Automatica Sinica , 2010 ,36 (9 ): 127 -132 .
[本文引用: 1]
[11]
王永富 , 柴天佑 . 从数据中挖掘模糊规则及其系统实现
[J]. 系统工程学报 , 2005 ,20 (5 ): 497 -503 .
[本文引用: 1]
WANG Y F , CHAI T Y . Mining fuzzy rules from data and its system implementation
[J]. Journal of Systems Engineering , 2005 ,20 (5 ): 497 -503 .
[本文引用: 1]
[12]
王晶 , 李玉兰 , 蔡自兴 ,等 . 基于遗传算法的模糊系统优化设计方法
[J]. 控制理论与应用 , 1999 (5 ): 699 -704 .
[本文引用: 1]
WANG J , LI Y L , CAI Z X ,et al . An optimal design approach for fuzzy system based on genetic algorithm
[J]. Control Theory & Applications , 1999 (5 ): 699 -704 .
[本文引用: 1]
[13]
任宇佳 . 基于自适应遗传算法的自动化立体仓库入库货位分配优化研究
[J]. 中国储运 , 2019 (11 ): 130 -132 .
[本文引用: 1]
REN Y J . Research on the allocation optimization of storage space in automated three-dimensional warehouse based on adaptive genetic algorithm
[J]. China Storage & Transport , 2019 (11 ): 130 -132 .
[本文引用: 1]
[14]
DANIELA S , MELIN P , CASTILLO O . Fuzzy system optimization using a hierarchical genetic algorithm applied to pattern recognition
[J]. Advances in Intelligent Systems & Computing , 2015 ,323 : 713 -720 .
[本文引用: 1]
[15]
王锋 , 张国煊 , 张怀相 . 模糊隶属度函数的遗传优化
[J]. 杭州电子科技大学学报 , 2009 ,29 (4 ): 34 -37 .
[本文引用: 1]
WANG F , ZHANG G X , ZHANG H X . Genetic optimization of fuzzy membership functions
[J]. Journal of Hangzhou Dianzi University , 2009 ,29 (4 ): 34 -37 .
[本文引用: 1]
[16]
辛峻峰 , 张永波 , 伯佳更 ,等 . 基于数据驱动的遗传算法的无人艇路径规划研究
[J]. 智能科学与技术学报 , 2019 ,1 (2 ): 171 -180 .
[本文引用: 1]
XIN J F , ZHANG Y B , BO J G ,et al . Study on path planning of unmanned surface vessel based on data-driven genetic algorithm
[J]. Chinese Journal of Intelligent Science and Technology , 2019 ,1 (2 ): 171 -180 .
[本文引用: 1]
[17]
刘睿 , 王锋 . 一种基于改进遗传算法的摄像机自标定方法
[J]. 光盘技术 , 2008 (5 ): 42 -44 .
[本文引用: 1]
LIU R , WANG F . Self-calibration of the camera based on genetic algorithm
[J]. CD Tecnnology , 2008 (5 ): 42 -44 .
[本文引用: 1]
[18]
彭显刚 , 胡松峰 , 吕大勇 ,等 . 基于RBF神经网络的短期负荷预测方法综述
[J]. 电力系统保护与控制 , 2011 ,39 (17 ): 144 -148 .
[本文引用: 1]
PENG X G , HU S F , LYU D Y ,et al . Review on grid short-term load forecasting methods based on RBF neural network
[J]. Power System Protection and Control , 2011 ,39 (17 ): 144 -148 .
[本文引用: 1]
[19]
王林 , 彭璐 , 夏德 ,等 . 自适应差分进化算法优化BP神经网络的时间序列预测
[J]. 计算机工程与科学 , 2015 ,37 (12 ): 2270 -2275 .
[本文引用: 1]
WANG L , PENG L , XIA D ,et al . BP neural network incorporating self-adaptive differential evolution algorithm for time series forecasting
[J]. Computer Engineering and Science , 2015 ,37 (12 ): 2270 -2275 .
[本文引用: 1]
[20]
陈德旺 , 蔡际杰 , 黄允浒 . 面向可解释性人工智能与大数据的模糊系统发展展望
[J]. 智能科学与技术学报 , 2019 ,1 (4 ): 327 -334 .
[本文引用: 1]
CHEN D W , CAI J J , HUANG Y H . Development prospect of fuzzy system oriented to interpretable artificial intelligence and big data
[J]. Chinese Journal of Intelligent Science and Technology , 2019 ,1 (4 ): 327 -334 .
[本文引用: 1]
基于进化策略生成可解释性模糊系统
2
2005
... 与其他人工智能方法(如神经网络(Neural Network,NN)、进化算法等)相比,模糊系统理论的突出优点是整个系统是基于规则构建的,在可解释性上具有显著的优越性[1 ] ,主要体现在结构与参数具有清晰的物理意义、每一条规则都可以被直观地解释,这为人们理解与接受其中蕴涵的知识提供了思路.模糊系统由一系列IF-THEN规则构成,系统的结构和参数可以用IF-THEN规则解释,且具备快速、灵活性强的优势.而神经网络在这方面却表现很差,即使是专家也难以解释和理解参数的意义.目前,基于全局优化的模糊神经网络系统以及神经网络、模糊系统和遗传算法三者相结合的方法能够优化从数据中提取出的模糊规则.尽管该方法已经较好地解决了上述问题,但系统的可解释性仍得不到保证.其原因在于这些算法的目标是获得最优系统响应性能,而对模糊集合划分个数、隶属函数参数的选取缺乏有效的指导[1 ,2 ] .因此,如何在提高模糊系统精度与收敛速度的同时,得到最优的响应系统,克服算法效率下降的问题,增强系统的可解释性已成为研究的热点. ...
... [1 ,2 ].因此,如何在提高模糊系统精度与收敛速度的同时,得到最优的响应系统,克服算法效率下降的问题,增强系统的可解释性已成为研究的热点. ...
基于进化策略生成可解释性模糊系统
2
2005
... 与其他人工智能方法(如神经网络(Neural Network,NN)、进化算法等)相比,模糊系统理论的突出优点是整个系统是基于规则构建的,在可解释性上具有显著的优越性[1 ] ,主要体现在结构与参数具有清晰的物理意义、每一条规则都可以被直观地解释,这为人们理解与接受其中蕴涵的知识提供了思路.模糊系统由一系列IF-THEN规则构成,系统的结构和参数可以用IF-THEN规则解释,且具备快速、灵活性强的优势.而神经网络在这方面却表现很差,即使是专家也难以解释和理解参数的意义.目前,基于全局优化的模糊神经网络系统以及神经网络、模糊系统和遗传算法三者相结合的方法能够优化从数据中提取出的模糊规则.尽管该方法已经较好地解决了上述问题,但系统的可解释性仍得不到保证.其原因在于这些算法的目标是获得最优系统响应性能,而对模糊集合划分个数、隶属函数参数的选取缺乏有效的指导[1 ,2 ] .因此,如何在提高模糊系统精度与收敛速度的同时,得到最优的响应系统,克服算法效率下降的问题,增强系统的可解释性已成为研究的热点. ...
... [1 ,2 ].因此,如何在提高模糊系统精度与收敛速度的同时,得到最优的响应系统,克服算法效率下降的问题,增强系统的可解释性已成为研究的热点. ...
Performance prediction of a hybrid microgeneration system using adaptive neuro-fuzzy inference system (ANFIS) technique
1
2014
... 与其他人工智能方法(如神经网络(Neural Network,NN)、进化算法等)相比,模糊系统理论的突出优点是整个系统是基于规则构建的,在可解释性上具有显著的优越性[1 ] ,主要体现在结构与参数具有清晰的物理意义、每一条规则都可以被直观地解释,这为人们理解与接受其中蕴涵的知识提供了思路.模糊系统由一系列IF-THEN规则构成,系统的结构和参数可以用IF-THEN规则解释,且具备快速、灵活性强的优势.而神经网络在这方面却表现很差,即使是专家也难以解释和理解参数的意义.目前,基于全局优化的模糊神经网络系统以及神经网络、模糊系统和遗传算法三者相结合的方法能够优化从数据中提取出的模糊规则.尽管该方法已经较好地解决了上述问题,但系统的可解释性仍得不到保证.其原因在于这些算法的目标是获得最优系统响应性能,而对模糊集合划分个数、隶属函数参数的选取缺乏有效的指导[1 ,2 ] .因此,如何在提高模糊系统精度与收敛速度的同时,得到最优的响应系统,克服算法效率下降的问题,增强系统的可解释性已成为研究的热点. ...
Fuzzy basis functions,universal approximation,and orthogonal least-squares learning
1
1992
... 模糊建模的关键是模糊规则的获取,Wang 等人[3 ] 于1992年证明了一类模糊系统是万能逼近器,开辟了模糊逼近领域,并与 Mendel 共同提出一种与先验知识无关的、从样本数据中获得模糊规则的方法[4 ] ,该方法可以从完备的、规模较小且不含坏数据的样本集中获得完备的、具有较好逼近性能的模糊规则库,取得了较好的成果,但 Wang-Mendel (WM)方法存在以下几个问题:一是其产生的模糊规则库缺乏良好的完备性和鲁棒性,进而导致模糊系统精度不高;二是算法效率下降很快,对高维大数据问题无能为力;三是规则数目随着输入维度的增加而呈指数式增加,难以摆脱高维的魔咒.针对此问题,众多学者提出了改进算法.参考文献[5 ]提出的一种模糊c均值聚类(fuzzy c-means,FCM)算法可以在一定程度上减小样本的规模,消除噪声数据,提高WM方法的完备性和鲁棒性,提高模糊系统的预测精度.参考文献[6 ]提出了一种基于粒子群优化的改进WM方法,采用改进的粒子群优化算法对数据覆盖区域的模糊规则质心进行优化,通过外推得到完整的模糊规则集,在一定程度上提高了WM方法的预测精度.参考文献[7 ]提出一种改进的WM方法来优化样本,利用样本间的加权距离提取完整的模糊规则库,具有良好的性能,缺点为只能处理低维小数据.参考文献[8 ]提出了一种简化的加权WM方法,通过平衡算法的完备性和计算时间来解决模糊规则的数量和数据规模导致的 WM 方法效率不高的问题.参考文献[9 ]提出了一种基于改进的WM方法的语义描述方法,该方法得到的语言规则库在准确度和可解释性方面具有较强的竞争力.然而,在测试过程中,如何在避免算法效率下降以及兼顾完备性、鲁棒性的同时,提高模糊系统的可解释性,仍然是亟待解决的问题. ...
Generating fuzzy rules by learning from examples
2
1992
... 模糊建模的关键是模糊规则的获取,Wang 等人[3 ] 于1992年证明了一类模糊系统是万能逼近器,开辟了模糊逼近领域,并与 Mendel 共同提出一种与先验知识无关的、从样本数据中获得模糊规则的方法[4 ] ,该方法可以从完备的、规模较小且不含坏数据的样本集中获得完备的、具有较好逼近性能的模糊规则库,取得了较好的成果,但 Wang-Mendel (WM)方法存在以下几个问题:一是其产生的模糊规则库缺乏良好的完备性和鲁棒性,进而导致模糊系统精度不高;二是算法效率下降很快,对高维大数据问题无能为力;三是规则数目随着输入维度的增加而呈指数式增加,难以摆脱高维的魔咒.针对此问题,众多学者提出了改进算法.参考文献[5 ]提出的一种模糊c均值聚类(fuzzy c-means,FCM)算法可以在一定程度上减小样本的规模,消除噪声数据,提高WM方法的完备性和鲁棒性,提高模糊系统的预测精度.参考文献[6 ]提出了一种基于粒子群优化的改进WM方法,采用改进的粒子群优化算法对数据覆盖区域的模糊规则质心进行优化,通过外推得到完整的模糊规则集,在一定程度上提高了WM方法的预测精度.参考文献[7 ]提出一种改进的WM方法来优化样本,利用样本间的加权距离提取完整的模糊规则库,具有良好的性能,缺点为只能处理低维小数据.参考文献[8 ]提出了一种简化的加权WM方法,通过平衡算法的完备性和计算时间来解决模糊规则的数量和数据规模导致的 WM 方法效率不高的问题.参考文献[9 ]提出了一种基于改进的WM方法的语义描述方法,该方法得到的语言规则库在准确度和可解释性方面具有较强的竞争力.然而,在测试过程中,如何在避免算法效率下降以及兼顾完备性、鲁棒性的同时,提高模糊系统的可解释性,仍然是亟待解决的问题. ...
... 第三步,赋予每条规则一个强度[4 ] .规则的强度D()i 定义如下: ...
Improving wang-mendel method performance in fuzzy rules generation using the fuzzy c-means clustering algorithm
1
2015
... 模糊建模的关键是模糊规则的获取,Wang 等人[3 ] 于1992年证明了一类模糊系统是万能逼近器,开辟了模糊逼近领域,并与 Mendel 共同提出一种与先验知识无关的、从样本数据中获得模糊规则的方法[4 ] ,该方法可以从完备的、规模较小且不含坏数据的样本集中获得完备的、具有较好逼近性能的模糊规则库,取得了较好的成果,但 Wang-Mendel (WM)方法存在以下几个问题:一是其产生的模糊规则库缺乏良好的完备性和鲁棒性,进而导致模糊系统精度不高;二是算法效率下降很快,对高维大数据问题无能为力;三是规则数目随着输入维度的增加而呈指数式增加,难以摆脱高维的魔咒.针对此问题,众多学者提出了改进算法.参考文献[5 ]提出的一种模糊c均值聚类(fuzzy c-means,FCM)算法可以在一定程度上减小样本的规模,消除噪声数据,提高WM方法的完备性和鲁棒性,提高模糊系统的预测精度.参考文献[6 ]提出了一种基于粒子群优化的改进WM方法,采用改进的粒子群优化算法对数据覆盖区域的模糊规则质心进行优化,通过外推得到完整的模糊规则集,在一定程度上提高了WM方法的预测精度.参考文献[7 ]提出一种改进的WM方法来优化样本,利用样本间的加权距离提取完整的模糊规则库,具有良好的性能,缺点为只能处理低维小数据.参考文献[8 ]提出了一种简化的加权WM方法,通过平衡算法的完备性和计算时间来解决模糊规则的数量和数据规模导致的 WM 方法效率不高的问题.参考文献[9 ]提出了一种基于改进的WM方法的语义描述方法,该方法得到的语言规则库在准确度和可解释性方面具有较强的竞争力.然而,在测试过程中,如何在避免算法效率下降以及兼顾完备性、鲁棒性的同时,提高模糊系统的可解释性,仍然是亟待解决的问题. ...
An improved WM method based on PSO for electric load forecasting
1
2010
... 模糊建模的关键是模糊规则的获取,Wang 等人[3 ] 于1992年证明了一类模糊系统是万能逼近器,开辟了模糊逼近领域,并与 Mendel 共同提出一种与先验知识无关的、从样本数据中获得模糊规则的方法[4 ] ,该方法可以从完备的、规模较小且不含坏数据的样本集中获得完备的、具有较好逼近性能的模糊规则库,取得了较好的成果,但 Wang-Mendel (WM)方法存在以下几个问题:一是其产生的模糊规则库缺乏良好的完备性和鲁棒性,进而导致模糊系统精度不高;二是算法效率下降很快,对高维大数据问题无能为力;三是规则数目随着输入维度的增加而呈指数式增加,难以摆脱高维的魔咒.针对此问题,众多学者提出了改进算法.参考文献[5 ]提出的一种模糊c均值聚类(fuzzy c-means,FCM)算法可以在一定程度上减小样本的规模,消除噪声数据,提高WM方法的完备性和鲁棒性,提高模糊系统的预测精度.参考文献[6 ]提出了一种基于粒子群优化的改进WM方法,采用改进的粒子群优化算法对数据覆盖区域的模糊规则质心进行优化,通过外推得到完整的模糊规则集,在一定程度上提高了WM方法的预测精度.参考文献[7 ]提出一种改进的WM方法来优化样本,利用样本间的加权距离提取完整的模糊规则库,具有良好的性能,缺点为只能处理低维小数据.参考文献[8 ]提出了一种简化的加权WM方法,通过平衡算法的完备性和计算时间来解决模糊规则的数量和数据规模导致的 WM 方法效率不高的问题.参考文献[9 ]提出了一种基于改进的WM方法的语义描述方法,该方法得到的语言规则库在准确度和可解释性方面具有较强的竞争力.然而,在测试过程中,如何在避免算法效率下降以及兼顾完备性、鲁棒性的同时,提高模糊系统的可解释性,仍然是亟待解决的问题. ...
An improved wang-mendel method based on the FSFDP clustering algorithm and sample correlation
1
2016
... 模糊建模的关键是模糊规则的获取,Wang 等人[3 ] 于1992年证明了一类模糊系统是万能逼近器,开辟了模糊逼近领域,并与 Mendel 共同提出一种与先验知识无关的、从样本数据中获得模糊规则的方法[4 ] ,该方法可以从完备的、规模较小且不含坏数据的样本集中获得完备的、具有较好逼近性能的模糊规则库,取得了较好的成果,但 Wang-Mendel (WM)方法存在以下几个问题:一是其产生的模糊规则库缺乏良好的完备性和鲁棒性,进而导致模糊系统精度不高;二是算法效率下降很快,对高维大数据问题无能为力;三是规则数目随着输入维度的增加而呈指数式增加,难以摆脱高维的魔咒.针对此问题,众多学者提出了改进算法.参考文献[5 ]提出的一种模糊c均值聚类(fuzzy c-means,FCM)算法可以在一定程度上减小样本的规模,消除噪声数据,提高WM方法的完备性和鲁棒性,提高模糊系统的预测精度.参考文献[6 ]提出了一种基于粒子群优化的改进WM方法,采用改进的粒子群优化算法对数据覆盖区域的模糊规则质心进行优化,通过外推得到完整的模糊规则集,在一定程度上提高了WM方法的预测精度.参考文献[7 ]提出一种改进的WM方法来优化样本,利用样本间的加权距离提取完整的模糊规则库,具有良好的性能,缺点为只能处理低维小数据.参考文献[8 ]提出了一种简化的加权WM方法,通过平衡算法的完备性和计算时间来解决模糊规则的数量和数据规模导致的 WM 方法效率不高的问题.参考文献[9 ]提出了一种基于改进的WM方法的语义描述方法,该方法得到的语言规则库在准确度和可解释性方面具有较强的竞争力.然而,在测试过程中,如何在避免算法效率下降以及兼顾完备性、鲁棒性的同时,提高模糊系统的可解释性,仍然是亟待解决的问题. ...
A reduced weighted wang-mendel algorithm using the clustering algorithm to build fuzzy system
1
2016
... 模糊建模的关键是模糊规则的获取,Wang 等人[3 ] 于1992年证明了一类模糊系统是万能逼近器,开辟了模糊逼近领域,并与 Mendel 共同提出一种与先验知识无关的、从样本数据中获得模糊规则的方法[4 ] ,该方法可以从完备的、规模较小且不含坏数据的样本集中获得完备的、具有较好逼近性能的模糊规则库,取得了较好的成果,但 Wang-Mendel (WM)方法存在以下几个问题:一是其产生的模糊规则库缺乏良好的完备性和鲁棒性,进而导致模糊系统精度不高;二是算法效率下降很快,对高维大数据问题无能为力;三是规则数目随着输入维度的增加而呈指数式增加,难以摆脱高维的魔咒.针对此问题,众多学者提出了改进算法.参考文献[5 ]提出的一种模糊c均值聚类(fuzzy c-means,FCM)算法可以在一定程度上减小样本的规模,消除噪声数据,提高WM方法的完备性和鲁棒性,提高模糊系统的预测精度.参考文献[6 ]提出了一种基于粒子群优化的改进WM方法,采用改进的粒子群优化算法对数据覆盖区域的模糊规则质心进行优化,通过外推得到完整的模糊规则集,在一定程度上提高了WM方法的预测精度.参考文献[7 ]提出一种改进的WM方法来优化样本,利用样本间的加权距离提取完整的模糊规则库,具有良好的性能,缺点为只能处理低维小数据.参考文献[8 ]提出了一种简化的加权WM方法,通过平衡算法的完备性和计算时间来解决模糊规则的数量和数据规模导致的 WM 方法效率不高的问题.参考文献[9 ]提出了一种基于改进的WM方法的语义描述方法,该方法得到的语言规则库在准确度和可解释性方面具有较强的竞争力.然而,在测试过程中,如何在避免算法效率下降以及兼顾完备性、鲁棒性的同时,提高模糊系统的可解释性,仍然是亟待解决的问题. ...
Semantic description method for face features of larger Chinese ethnic groups based on improved WM method
1
2016
... 模糊建模的关键是模糊规则的获取,Wang 等人[3 ] 于1992年证明了一类模糊系统是万能逼近器,开辟了模糊逼近领域,并与 Mendel 共同提出一种与先验知识无关的、从样本数据中获得模糊规则的方法[4 ] ,该方法可以从完备的、规模较小且不含坏数据的样本集中获得完备的、具有较好逼近性能的模糊规则库,取得了较好的成果,但 Wang-Mendel (WM)方法存在以下几个问题:一是其产生的模糊规则库缺乏良好的完备性和鲁棒性,进而导致模糊系统精度不高;二是算法效率下降很快,对高维大数据问题无能为力;三是规则数目随着输入维度的增加而呈指数式增加,难以摆脱高维的魔咒.针对此问题,众多学者提出了改进算法.参考文献[5 ]提出的一种模糊c均值聚类(fuzzy c-means,FCM)算法可以在一定程度上减小样本的规模,消除噪声数据,提高WM方法的完备性和鲁棒性,提高模糊系统的预测精度.参考文献[6 ]提出了一种基于粒子群优化的改进WM方法,采用改进的粒子群优化算法对数据覆盖区域的模糊规则质心进行优化,通过外推得到完整的模糊规则集,在一定程度上提高了WM方法的预测精度.参考文献[7 ]提出一种改进的WM方法来优化样本,利用样本间的加权距离提取完整的模糊规则库,具有良好的性能,缺点为只能处理低维小数据.参考文献[8 ]提出了一种简化的加权WM方法,通过平衡算法的完备性和计算时间来解决模糊规则的数量和数据规模导致的 WM 方法效率不高的问题.参考文献[9 ]提出了一种基于改进的WM方法的语义描述方法,该方法得到的语言规则库在准确度和可解释性方面具有较强的竞争力.然而,在测试过程中,如何在避免算法效率下降以及兼顾完备性、鲁棒性的同时,提高模糊系统的可解释性,仍然是亟待解决的问题. ...
一个具有完备性和鲁棒性的模糊规则提取算法
1
2010
... 至此,初始化模型构建完成.该模型的不足之处在于其产生的模糊规则库缺乏良好的完备性和鲁棒性[10 ] ,进而导致模型精度不高.因此,为了提高模型精度,需要采取某种全局优化方法来提高模糊系统性能,从而提取更可靠、更优的规则,避免从“坏数据”提取出“坏规则”[11 ] 而导致模型精度下降现象的产生.另外,减少模糊系统规则数、提升其可解释性也是优化目的之一. ...
一个具有完备性和鲁棒性的模糊规则提取算法
1
2010
... 至此,初始化模型构建完成.该模型的不足之处在于其产生的模糊规则库缺乏良好的完备性和鲁棒性[10 ] ,进而导致模型精度不高.因此,为了提高模型精度,需要采取某种全局优化方法来提高模糊系统性能,从而提取更可靠、更优的规则,避免从“坏数据”提取出“坏规则”[11 ] 而导致模型精度下降现象的产生.另外,减少模糊系统规则数、提升其可解释性也是优化目的之一. ...
从数据中挖掘模糊规则及其系统实现
1
2005
... 至此,初始化模型构建完成.该模型的不足之处在于其产生的模糊规则库缺乏良好的完备性和鲁棒性[10 ] ,进而导致模型精度不高.因此,为了提高模型精度,需要采取某种全局优化方法来提高模糊系统性能,从而提取更可靠、更优的规则,避免从“坏数据”提取出“坏规则”[11 ] 而导致模型精度下降现象的产生.另外,减少模糊系统规则数、提升其可解释性也是优化目的之一. ...
从数据中挖掘模糊规则及其系统实现
1
2005
... 至此,初始化模型构建完成.该模型的不足之处在于其产生的模糊规则库缺乏良好的完备性和鲁棒性[10 ] ,进而导致模型精度不高.因此,为了提高模型精度,需要采取某种全局优化方法来提高模糊系统性能,从而提取更可靠、更优的规则,避免从“坏数据”提取出“坏规则”[11 ] 而导致模型精度下降现象的产生.另外,减少模糊系统规则数、提升其可解释性也是优化目的之一. ...
基于遗传算法的模糊系统优化设计方法
1
1999
... 遗传算法(genetic algorithm,GA)是模拟生物进化论的自然选择和群体遗传机理的计算模型,通过模拟自然选择和自然遗传过程中的繁殖、杂交和突变现象来求解问题,体现了“优胜劣汰,适者生存”的思想.其通过概率的状态转移规则自适应地调整搜索方向,本质上是一种随机化搜索全局最优解的方法,适用于模糊系统的优化[12 ] . ...
基于遗传算法的模糊系统优化设计方法
1
1999
... 遗传算法(genetic algorithm,GA)是模拟生物进化论的自然选择和群体遗传机理的计算模型,通过模拟自然选择和自然遗传过程中的繁殖、杂交和突变现象来求解问题,体现了“优胜劣汰,适者生存”的思想.其通过概率的状态转移规则自适应地调整搜索方向,本质上是一种随机化搜索全局最优解的方法,适用于模糊系统的优化[12 ] . ...
基于自适应遗传算法的自动化立体仓库入库货位分配优化研究
1
2019
... 适应度函数的质量在一定程度上决定了遗传算法搜索的范围与全局寻优能力.传统的遗传算法将单一目标函数作为适应度函数,考虑问题不够全面,有时无法寻得最优解.为综合评估模糊系统参数所有可行解的适应度并提升遗传算法找到最优解的效率,本文从传统的遗传算法出发,对适应度函数的确定方法进行改进:对于n个目标函数 f i ( x ) ( i = 1 , 2 , ⋯ , n ) [13 ] 与评价函数法,赋予每个目标函数权重 w i ( i = 1 , 2 , ⋯ , n )
基于自适应遗传算法的自动化立体仓库入库货位分配优化研究
1
2019
... 适应度函数的质量在一定程度上决定了遗传算法搜索的范围与全局寻优能力.传统的遗传算法将单一目标函数作为适应度函数,考虑问题不够全面,有时无法寻得最优解.为综合评估模糊系统参数所有可行解的适应度并提升遗传算法找到最优解的效率,本文从传统的遗传算法出发,对适应度函数的确定方法进行改进:对于n个目标函数 f i ( x ) ( i = 1 , 2 , ⋯ , n ) [13 ] 与评价函数法,赋予每个目标函数权重 w i ( i = 1 , 2 , ⋯ , n )
Fuzzy system optimization using a hierarchical genetic algorithm applied to pattern recognition
1
2015
... 作为一种全局优化方法,遗传算法适用于模糊系统的结构和隶属函数参数集的优化.当前,利用遗传算法优化模糊系统的一般方法存在一定缺陷.例如,在优化完成后,不同的模糊规则中同一语言变量具有相同语义的模糊子集的参数往往不同[14 ] ,这在一定程度上降低了模糊系统的可解释性;再者,若维持模糊子集的语义一致性,而对不同的模糊子集进行编码[15 ] ,只能优化隶属函数参数,无法优化模糊系统的结构. ...
模糊隶属度函数的遗传优化
1
2009
... 作为一种全局优化方法,遗传算法适用于模糊系统的结构和隶属函数参数集的优化.当前,利用遗传算法优化模糊系统的一般方法存在一定缺陷.例如,在优化完成后,不同的模糊规则中同一语言变量具有相同语义的模糊子集的参数往往不同[14 ] ,这在一定程度上降低了模糊系统的可解释性;再者,若维持模糊子集的语义一致性,而对不同的模糊子集进行编码[15 ] ,只能优化隶属函数参数,无法优化模糊系统的结构. ...
模糊隶属度函数的遗传优化
1
2009
... 作为一种全局优化方法,遗传算法适用于模糊系统的结构和隶属函数参数集的优化.当前,利用遗传算法优化模糊系统的一般方法存在一定缺陷.例如,在优化完成后,不同的模糊规则中同一语言变量具有相同语义的模糊子集的参数往往不同[14 ] ,这在一定程度上降低了模糊系统的可解释性;再者,若维持模糊子集的语义一致性,而对不同的模糊子集进行编码[15 ] ,只能优化隶属函数参数,无法优化模糊系统的结构. ...
基于数据驱动的遗传算法的无人艇路径规划研究
1
2019
... 针对上述问题,本文以改进遗传算法机理和初始化模型的不足为出发点,利用随机化技术以及选择、交叉和变异操作[16 ] 对一个经过编码的隶属函数的参数空间进行高效搜索,优化模糊系统的结构和参数;提出一种基于改进遗传算法的模糊系统,即遗传模糊系统(genetic fuzzy system,GFS)的优化建模方法,对模糊系统结构及隶属函数参数进行优化,以提高模糊系统输入隶属函数的适应性和模糊规则的质量,从而提升模糊系统的可解释性及其模型的精度. ...
基于数据驱动的遗传算法的无人艇路径规划研究
1
2019
... 针对上述问题,本文以改进遗传算法机理和初始化模型的不足为出发点,利用随机化技术以及选择、交叉和变异操作[16 ] 对一个经过编码的隶属函数的参数空间进行高效搜索,优化模糊系统的结构和参数;提出一种基于改进遗传算法的模糊系统,即遗传模糊系统(genetic fuzzy system,GFS)的优化建模方法,对模糊系统结构及隶属函数参数进行优化,以提高模糊系统输入隶属函数的适应性和模糊规则的质量,从而提升模糊系统的可解释性及其模型的精度. ...
一种基于改进遗传算法的摄像机自标定方法
1
2008
... 第四步,选择.选择操作的原则是个体适应度越大,被选择到下一代的机会越大.本文采用轮盘赌方式,即利用个体适应度计算其被选择的概率[17 ] ,根据概率决定该个体是否遗传到下一代.设个体i的适应度为上述某个目标函数值 fi ,种群规模为PS,则个体i被选择的概率为: ...
一种基于改进遗传算法的摄像机自标定方法
1
2008
... 第四步,选择.选择操作的原则是个体适应度越大,被选择到下一代的机会越大.本文采用轮盘赌方式,即利用个体适应度计算其被选择的概率[17 ] ,根据概率决定该个体是否遗传到下一代.设个体i的适应度为上述某个目标函数值 fi ,种群规模为PS,则个体i被选择的概率为: ...
基于RBF神经网络的短期负荷预测方法综述
1
2011
... 为了在回归预测问题上对提出的 GFS 进行评估,比较分析了其与径向基函数(radial basis function,RBF)神经网络[18 ] 、反向传播(back propagation,BP)神经网络[19 ] 、经典Wang-Mendel这3种方法的性能指标.根据上述3个目标函数的不同线性组合生成的GFS模型的优化效果不同,本文枚举出所有可能的线性组合,并介绍其中性能较佳的 3 种模型(GFS1、GFS2 与 GFS3).以模型精度为设定依据,给出式(4)中的权重系数分配,见表1 . ...
基于RBF神经网络的短期负荷预测方法综述
1
2011
... 为了在回归预测问题上对提出的 GFS 进行评估,比较分析了其与径向基函数(radial basis function,RBF)神经网络[18 ] 、反向传播(back propagation,BP)神经网络[19 ] 、经典Wang-Mendel这3种方法的性能指标.根据上述3个目标函数的不同线性组合生成的GFS模型的优化效果不同,本文枚举出所有可能的线性组合,并介绍其中性能较佳的 3 种模型(GFS1、GFS2 与 GFS3).以模型精度为设定依据,给出式(4)中的权重系数分配,见表1 . ...
自适应差分进化算法优化BP神经网络的时间序列预测
1
2015
... 为了在回归预测问题上对提出的 GFS 进行评估,比较分析了其与径向基函数(radial basis function,RBF)神经网络[18 ] 、反向传播(back propagation,BP)神经网络[19 ] 、经典Wang-Mendel这3种方法的性能指标.根据上述3个目标函数的不同线性组合生成的GFS模型的优化效果不同,本文枚举出所有可能的线性组合,并介绍其中性能较佳的 3 种模型(GFS1、GFS2 与 GFS3).以模型精度为设定依据,给出式(4)中的权重系数分配,见表1 . ...
自适应差分进化算法优化BP神经网络的时间序列预测
1
2015
... 为了在回归预测问题上对提出的 GFS 进行评估,比较分析了其与径向基函数(radial basis function,RBF)神经网络[18 ] 、反向传播(back propagation,BP)神经网络[19 ] 、经典Wang-Mendel这3种方法的性能指标.根据上述3个目标函数的不同线性组合生成的GFS模型的优化效果不同,本文枚举出所有可能的线性组合,并介绍其中性能较佳的 3 种模型(GFS1、GFS2 与 GFS3).以模型精度为设定依据,给出式(4)中的权重系数分配,见表1 . ...
面向可解释性人工智能与大数据的模糊系统发展展望
1
2019
... 由表2 可以看出,GFSi在标准数据集上的预测精度均优于经典WM方法,但在精度方面仍与神经网络算法存在一定差距,这也是目前的模糊系统普遍存在的问题之一[20 ] .而从表3 可以看出,GFSi的预测精度均优于RBF神经网络、BP神经网络,体现出了模糊系统抗噪能力强的优点.图4 展示了GFSi和WM方法在标准数据集上的预测值与实际值的对比. ...
面向可解释性人工智能与大数据的模糊系统发展展望
1
2019
... 由表2 可以看出,GFSi在标准数据集上的预测精度均优于经典WM方法,但在精度方面仍与神经网络算法存在一定差距,这也是目前的模糊系统普遍存在的问题之一[20 ] .而从表3 可以看出,GFSi的预测精度均优于RBF神经网络、BP神经网络,体现出了模糊系统抗噪能力强的优点.图4 展示了GFSi和WM方法在标准数据集上的预测值与实际值的对比. ...










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}