Reinforcement learning:an introduction
1
2018
... 近年来,强化学习[1]方法受到了广泛的关注,其主要被用于解决序列决策问题.强化学习受到动物学习中试错法的启发,将智能体与环境交互得到的奖励值作为反馈信号对智能体进行训练.强化学习一般可以用马尔可夫决策过程(Markov decision process,MDP)表示,主要元素包含(S, A, R, T,γ),其中,S表示所处的环境状态,A表示智能体采取的动作,R表示得到的奖励值,T表示状态转移概率,γ表示折扣因子.智能体的策略π表示状态空间到动作空间的一个映射.当智能体状态st∈S时,根据策略π采取动作at∈A,进而根据状态转移概率T转移到下一个状态st+1,同时接收环境反馈的奖励值rt∈R.强化学习的目标是不断地优化智能体的策略,从而得到最大的奖励值.智能体的值函数和动作值函数分别为和 ,用来评估智能体在状态st下所能得到的长期奖励的期望.智能体的最优策略可以通过优化值函数得到. ...
Deep learning
1
2015
... 深度学习拥有强大的感知能力,在一些应用场景下甚至已经超越了人类的感知水平[2].它采用深度神经网络提取原始输入的特征,在图像识别、语音识别、机器翻译等多个领域取得了成功.深度强化学习(deep reinforcement learning,DRL)基于深度学习强大的感知能力来处理复杂的、高维的环境特征,并结合强化学习的思想与环境进行交互,完成决策过程[3,4].2015 年 DeepMind 团队在 Nature上发表了深度Q网络(deep Q-network,DQN)的文章[5],认为DRL可以实现类人水平的控制.2017年, DeepMind 团队根据深度学习和策略搜索的方法推出了 AlphaGo[6],击败了围棋世界冠军李世石.此后,基于DRL的AlphaGo Zero在不需要人类经验的帮助下,经过短时间的训练就击败了AlphaGo[7].2018 年,OpenAI 团队基于多智能体 DRL (multi-agent DRL,MADRL)推出了OpenAI Five,在Dota2游戏5v5模式下击败了人类玩家[8],并且在经过一段时间的训练后,击败了Dota2世界冠军OG 战队.2019 年,DeepMind 团队基于 MADRL推出的AlphaStar在StarCraftII游戏中达到了人类大师级的水平,并且在StarCraftII的官方排名中超越了99.8%的人类玩家[9].可以看到,DRL在封闭、静态和确定性的环境(如围棋、游戏等)下,可以达到甚至超越人类的决策水平. ...
深度强化学习综述:兼论计算机围棋的发展
1
2016
... 深度学习拥有强大的感知能力,在一些应用场景下甚至已经超越了人类的感知水平[2].它采用深度神经网络提取原始输入的特征,在图像识别、语音识别、机器翻译等多个领域取得了成功.深度强化学习(deep reinforcement learning,DRL)基于深度学习强大的感知能力来处理复杂的、高维的环境特征,并结合强化学习的思想与环境进行交互,完成决策过程[3,4].2015 年 DeepMind 团队在 Nature上发表了深度Q网络(deep Q-network,DQN)的文章[5],认为DRL可以实现类人水平的控制.2017年, DeepMind 团队根据深度学习和策略搜索的方法推出了 AlphaGo[6],击败了围棋世界冠军李世石.此后,基于DRL的AlphaGo Zero在不需要人类经验的帮助下,经过短时间的训练就击败了AlphaGo[7].2018 年,OpenAI 团队基于多智能体 DRL (multi-agent DRL,MADRL)推出了OpenAI Five,在Dota2游戏5v5模式下击败了人类玩家[8],并且在经过一段时间的训练后,击败了Dota2世界冠军OG 战队.2019 年,DeepMind 团队基于 MADRL推出的AlphaStar在StarCraftII游戏中达到了人类大师级的水平,并且在StarCraftII的官方排名中超越了99.8%的人类玩家[9].可以看到,DRL在封闭、静态和确定性的环境(如围棋、游戏等)下,可以达到甚至超越人类的决策水平. ...
深度强化学习综述:兼论计算机围棋的发展
1
2016
... 深度学习拥有强大的感知能力,在一些应用场景下甚至已经超越了人类的感知水平[2].它采用深度神经网络提取原始输入的特征,在图像识别、语音识别、机器翻译等多个领域取得了成功.深度强化学习(deep reinforcement learning,DRL)基于深度学习强大的感知能力来处理复杂的、高维的环境特征,并结合强化学习的思想与环境进行交互,完成决策过程[3,4].2015 年 DeepMind 团队在 Nature上发表了深度Q网络(deep Q-network,DQN)的文章[5],认为DRL可以实现类人水平的控制.2017年, DeepMind 团队根据深度学习和策略搜索的方法推出了 AlphaGo[6],击败了围棋世界冠军李世石.此后,基于DRL的AlphaGo Zero在不需要人类经验的帮助下,经过短时间的训练就击败了AlphaGo[7].2018 年,OpenAI 团队基于多智能体 DRL (multi-agent DRL,MADRL)推出了OpenAI Five,在Dota2游戏5v5模式下击败了人类玩家[8],并且在经过一段时间的训练后,击败了Dota2世界冠军OG 战队.2019 年,DeepMind 团队基于 MADRL推出的AlphaStar在StarCraftII游戏中达到了人类大师级的水平,并且在StarCraftII的官方排名中超越了99.8%的人类玩家[9].可以看到,DRL在封闭、静态和确定性的环境(如围棋、游戏等)下,可以达到甚至超越人类的决策水平. ...
深度强化学习理论及其应用综述
1
2019
... 深度学习拥有强大的感知能力,在一些应用场景下甚至已经超越了人类的感知水平[2].它采用深度神经网络提取原始输入的特征,在图像识别、语音识别、机器翻译等多个领域取得了成功.深度强化学习(deep reinforcement learning,DRL)基于深度学习强大的感知能力来处理复杂的、高维的环境特征,并结合强化学习的思想与环境进行交互,完成决策过程[3,4].2015 年 DeepMind 团队在 Nature上发表了深度Q网络(deep Q-network,DQN)的文章[5],认为DRL可以实现类人水平的控制.2017年, DeepMind 团队根据深度学习和策略搜索的方法推出了 AlphaGo[6],击败了围棋世界冠军李世石.此后,基于DRL的AlphaGo Zero在不需要人类经验的帮助下,经过短时间的训练就击败了AlphaGo[7].2018 年,OpenAI 团队基于多智能体 DRL (multi-agent DRL,MADRL)推出了OpenAI Five,在Dota2游戏5v5模式下击败了人类玩家[8],并且在经过一段时间的训练后,击败了Dota2世界冠军OG 战队.2019 年,DeepMind 团队基于 MADRL推出的AlphaStar在StarCraftII游戏中达到了人类大师级的水平,并且在StarCraftII的官方排名中超越了99.8%的人类玩家[9].可以看到,DRL在封闭、静态和确定性的环境(如围棋、游戏等)下,可以达到甚至超越人类的决策水平. ...
深度强化学习理论及其应用综述
1
2019
... 深度学习拥有强大的感知能力,在一些应用场景下甚至已经超越了人类的感知水平[2].它采用深度神经网络提取原始输入的特征,在图像识别、语音识别、机器翻译等多个领域取得了成功.深度强化学习(deep reinforcement learning,DRL)基于深度学习强大的感知能力来处理复杂的、高维的环境特征,并结合强化学习的思想与环境进行交互,完成决策过程[3,4].2015 年 DeepMind 团队在 Nature上发表了深度Q网络(deep Q-network,DQN)的文章[5],认为DRL可以实现类人水平的控制.2017年, DeepMind 团队根据深度学习和策略搜索的方法推出了 AlphaGo[6],击败了围棋世界冠军李世石.此后,基于DRL的AlphaGo Zero在不需要人类经验的帮助下,经过短时间的训练就击败了AlphaGo[7].2018 年,OpenAI 团队基于多智能体 DRL (multi-agent DRL,MADRL)推出了OpenAI Five,在Dota2游戏5v5模式下击败了人类玩家[8],并且在经过一段时间的训练后,击败了Dota2世界冠军OG 战队.2019 年,DeepMind 团队基于 MADRL推出的AlphaStar在StarCraftII游戏中达到了人类大师级的水平,并且在StarCraftII的官方排名中超越了99.8%的人类玩家[9].可以看到,DRL在封闭、静态和确定性的环境(如围棋、游戏等)下,可以达到甚至超越人类的决策水平. ...
Human-level control through deep reinforcement learning
2
2015
... 深度学习拥有强大的感知能力,在一些应用场景下甚至已经超越了人类的感知水平[2].它采用深度神经网络提取原始输入的特征,在图像识别、语音识别、机器翻译等多个领域取得了成功.深度强化学习(deep reinforcement learning,DRL)基于深度学习强大的感知能力来处理复杂的、高维的环境特征,并结合强化学习的思想与环境进行交互,完成决策过程[3,4].2015 年 DeepMind 团队在 Nature上发表了深度Q网络(deep Q-network,DQN)的文章[5],认为DRL可以实现类人水平的控制.2017年, DeepMind 团队根据深度学习和策略搜索的方法推出了 AlphaGo[6],击败了围棋世界冠军李世石.此后,基于DRL的AlphaGo Zero在不需要人类经验的帮助下,经过短时间的训练就击败了AlphaGo[7].2018 年,OpenAI 团队基于多智能体 DRL (multi-agent DRL,MADRL)推出了OpenAI Five,在Dota2游戏5v5模式下击败了人类玩家[8],并且在经过一段时间的训练后,击败了Dota2世界冠军OG 战队.2019 年,DeepMind 团队基于 MADRL推出的AlphaStar在StarCraftII游戏中达到了人类大师级的水平,并且在StarCraftII的官方排名中超越了99.8%的人类玩家[9].可以看到,DRL在封闭、静态和确定性的环境(如围棋、游戏等)下,可以达到甚至超越人类的决策水平. ...
... 图5展示了几个典型的Atari 2600游戏环境,它们是很多DRL算法的测试环境.Atari 2600包含57款游戏,可以用来模拟真实环境中遇到的情况,且游戏环境具有多样性.DQN较早应用于Atari 2600的算法[5],它在22款游戏中取得了人类玩家的平均水平.之后,DQN 的各种改进版本(如 DDQN[14]、优先经验回放的DQN[15]、Dueling DQN[16],以及分布式DQN[17])分别在Atari 2600游戏中取得了不同程度的提升.然而,很难有一种算法能够在所有Atari 2600 游戏中都达到人类的水平,这主要有两个原因:一个是长期的信度分配,另一个是探索困境.信度分配在DRL中用来解决动作-奖励值分配的问题,DRL中存在奖励延时,因此很难将奖励值分配到具体的行动中,而且游戏运行时间越长,信度分配问题就越难解决.探索困境是指当环境状态的维数很大并且奖励值的设置比较稀疏时,智能体需要很多探索行为才能得到积极的反馈,导致算法很难收敛.为了解决这些问题,Badia A P等人[24]提出了Agent57算法,并成功地在所有Atari 2600游戏中超越了人类平均水平.针对长期的信度分配问题,Agent57 算法动态地对折扣因子进行调整,权衡未来奖励对当前状态-动作的重要性.同时Agent57 算法加入内部奖励值来解决探索困境,内部奖励值的大小由未探索过状态的新奇程度来决定.Agent57 算法采用两种内部的奖励值:一种是在一个学习周期(episode)内根据新奇的状态得到的奖励值;另一种是长期的,在学习周期之间根据状态的新奇程度得到的奖励值.最后的内部奖励值由这两部分组成.通过这些方法,Agent57算法成功地在所有Atari 2600游戏中超越人类玩家的平均水平,提高了DRL算法的通用性. ...
Mastering the game of Go with deep neural networks and tree search
1
2016
... 深度学习拥有强大的感知能力,在一些应用场景下甚至已经超越了人类的感知水平[2].它采用深度神经网络提取原始输入的特征,在图像识别、语音识别、机器翻译等多个领域取得了成功.深度强化学习(deep reinforcement learning,DRL)基于深度学习强大的感知能力来处理复杂的、高维的环境特征,并结合强化学习的思想与环境进行交互,完成决策过程[3,4].2015 年 DeepMind 团队在 Nature上发表了深度Q网络(deep Q-network,DQN)的文章[5],认为DRL可以实现类人水平的控制.2017年, DeepMind 团队根据深度学习和策略搜索的方法推出了 AlphaGo[6],击败了围棋世界冠军李世石.此后,基于DRL的AlphaGo Zero在不需要人类经验的帮助下,经过短时间的训练就击败了AlphaGo[7].2018 年,OpenAI 团队基于多智能体 DRL (multi-agent DRL,MADRL)推出了OpenAI Five,在Dota2游戏5v5模式下击败了人类玩家[8],并且在经过一段时间的训练后,击败了Dota2世界冠军OG 战队.2019 年,DeepMind 团队基于 MADRL推出的AlphaStar在StarCraftII游戏中达到了人类大师级的水平,并且在StarCraftII的官方排名中超越了99.8%的人类玩家[9].可以看到,DRL在封闭、静态和确定性的环境(如围棋、游戏等)下,可以达到甚至超越人类的决策水平. ...
Mastering the game of go without human knowledge
1
2017
... 深度学习拥有强大的感知能力,在一些应用场景下甚至已经超越了人类的感知水平[2].它采用深度神经网络提取原始输入的特征,在图像识别、语音识别、机器翻译等多个领域取得了成功.深度强化学习(deep reinforcement learning,DRL)基于深度学习强大的感知能力来处理复杂的、高维的环境特征,并结合强化学习的思想与环境进行交互,完成决策过程[3,4].2015 年 DeepMind 团队在 Nature上发表了深度Q网络(deep Q-network,DQN)的文章[5],认为DRL可以实现类人水平的控制.2017年, DeepMind 团队根据深度学习和策略搜索的方法推出了 AlphaGo[6],击败了围棋世界冠军李世石.此后,基于DRL的AlphaGo Zero在不需要人类经验的帮助下,经过短时间的训练就击败了AlphaGo[7].2018 年,OpenAI 团队基于多智能体 DRL (multi-agent DRL,MADRL)推出了OpenAI Five,在Dota2游戏5v5模式下击败了人类玩家[8],并且在经过一段时间的训练后,击败了Dota2世界冠军OG 战队.2019 年,DeepMind 团队基于 MADRL推出的AlphaStar在StarCraftII游戏中达到了人类大师级的水平,并且在StarCraftII的官方排名中超越了99.8%的人类玩家[9].可以看到,DRL在封闭、静态和确定性的环境(如围棋、游戏等)下,可以达到甚至超越人类的决策水平. ...
Dota2 with large scale deep reinforcement learning
1
2019
... 深度学习拥有强大的感知能力,在一些应用场景下甚至已经超越了人类的感知水平[2].它采用深度神经网络提取原始输入的特征,在图像识别、语音识别、机器翻译等多个领域取得了成功.深度强化学习(deep reinforcement learning,DRL)基于深度学习强大的感知能力来处理复杂的、高维的环境特征,并结合强化学习的思想与环境进行交互,完成决策过程[3,4].2015 年 DeepMind 团队在 Nature上发表了深度Q网络(deep Q-network,DQN)的文章[5],认为DRL可以实现类人水平的控制.2017年, DeepMind 团队根据深度学习和策略搜索的方法推出了 AlphaGo[6],击败了围棋世界冠军李世石.此后,基于DRL的AlphaGo Zero在不需要人类经验的帮助下,经过短时间的训练就击败了AlphaGo[7].2018 年,OpenAI 团队基于多智能体 DRL (multi-agent DRL,MADRL)推出了OpenAI Five,在Dota2游戏5v5模式下击败了人类玩家[8],并且在经过一段时间的训练后,击败了Dota2世界冠军OG 战队.2019 年,DeepMind 团队基于 MADRL推出的AlphaStar在StarCraftII游戏中达到了人类大师级的水平,并且在StarCraftII的官方排名中超越了99.8%的人类玩家[9].可以看到,DRL在封闭、静态和确定性的环境(如围棋、游戏等)下,可以达到甚至超越人类的决策水平. ...
Grandmaster level in StarCraftII using multi-agent reinforcement learning
1
2019
... 深度学习拥有强大的感知能力,在一些应用场景下甚至已经超越了人类的感知水平[2].它采用深度神经网络提取原始输入的特征,在图像识别、语音识别、机器翻译等多个领域取得了成功.深度强化学习(deep reinforcement learning,DRL)基于深度学习强大的感知能力来处理复杂的、高维的环境特征,并结合强化学习的思想与环境进行交互,完成决策过程[3,4].2015 年 DeepMind 团队在 Nature上发表了深度Q网络(deep Q-network,DQN)的文章[5],认为DRL可以实现类人水平的控制.2017年, DeepMind 团队根据深度学习和策略搜索的方法推出了 AlphaGo[6],击败了围棋世界冠军李世石.此后,基于DRL的AlphaGo Zero在不需要人类经验的帮助下,经过短时间的训练就击败了AlphaGo[7].2018 年,OpenAI 团队基于多智能体 DRL (multi-agent DRL,MADRL)推出了OpenAI Five,在Dota2游戏5v5模式下击败了人类玩家[8],并且在经过一段时间的训练后,击败了Dota2世界冠军OG 战队.2019 年,DeepMind 团队基于 MADRL推出的AlphaStar在StarCraftII游戏中达到了人类大师级的水平,并且在StarCraftII的官方排名中超越了99.8%的人类玩家[9].可以看到,DRL在封闭、静态和确定性的环境(如围棋、游戏等)下,可以达到甚至超越人类的决策水平. ...
深度强化学习综述
1
2018
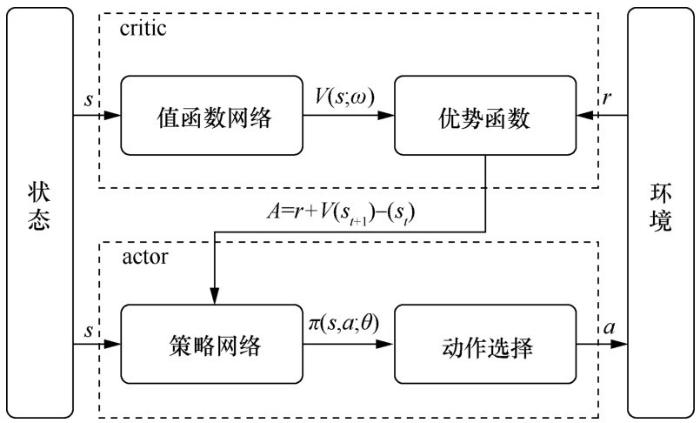
... DRL算法主要分为两类:值函数算法和策略梯度算法[10,11].值函数算法通过迭代更新值函数来间接得到智能体的策略,当值函数迭代达到最优时,智能体的最优策略通过最优值函数得到.策略梯度算法直接采用函数近似的方法建立策略网络,通过策略网络选取动作得到奖励值,并沿梯度方向对策略网络参数进行优化,得到优化的策略最大化奖励值.在算法应用的场景上,值函数算法需要对动作进行采样,因此只能处理离散动作的情况,而策略梯度算法直接利用策略网络对动作进行搜索,可以被用来处理连续动作的情况.近年来,将值函数算法和策略梯度算法结合得到的执行器ԟ评价器(actor-critic,AC)结构也受到了广泛的关注.在 AC 结构中,执行器使用策略梯度法选取动作,通过值函数对执行器采取的动作进行评价,并且在训练时,执行器和评价器的参数交替更新. ...
深度强化学习综述
1
2018
... DRL算法主要分为两类:值函数算法和策略梯度算法[10,11].值函数算法通过迭代更新值函数来间接得到智能体的策略,当值函数迭代达到最优时,智能体的最优策略通过最优值函数得到.策略梯度算法直接采用函数近似的方法建立策略网络,通过策略网络选取动作得到奖励值,并沿梯度方向对策略网络参数进行优化,得到优化的策略最大化奖励值.在算法应用的场景上,值函数算法需要对动作进行采样,因此只能处理离散动作的情况,而策略梯度算法直接利用策略网络对动作进行搜索,可以被用来处理连续动作的情况.近年来,将值函数算法和策略梯度算法结合得到的执行器ԟ评价器(actor-critic,AC)结构也受到了广泛的关注.在 AC 结构中,执行器使用策略梯度法选取动作,通过值函数对执行器采取的动作进行评价,并且在训练时,执行器和评价器的参数交替更新. ...
基于值函数和策略梯度的深度强化学习综述
1
2019
... DRL算法主要分为两类:值函数算法和策略梯度算法[10,11].值函数算法通过迭代更新值函数来间接得到智能体的策略,当值函数迭代达到最优时,智能体的最优策略通过最优值函数得到.策略梯度算法直接采用函数近似的方法建立策略网络,通过策略网络选取动作得到奖励值,并沿梯度方向对策略网络参数进行优化,得到优化的策略最大化奖励值.在算法应用的场景上,值函数算法需要对动作进行采样,因此只能处理离散动作的情况,而策略梯度算法直接利用策略网络对动作进行搜索,可以被用来处理连续动作的情况.近年来,将值函数算法和策略梯度算法结合得到的执行器ԟ评价器(actor-critic,AC)结构也受到了广泛的关注.在 AC 结构中,执行器使用策略梯度法选取动作,通过值函数对执行器采取的动作进行评价,并且在训练时,执行器和评价器的参数交替更新. ...
基于值函数和策略梯度的深度强化学习综述
1
2019
... DRL算法主要分为两类:值函数算法和策略梯度算法[10,11].值函数算法通过迭代更新值函数来间接得到智能体的策略,当值函数迭代达到最优时,智能体的最优策略通过最优值函数得到.策略梯度算法直接采用函数近似的方法建立策略网络,通过策略网络选取动作得到奖励值,并沿梯度方向对策略网络参数进行优化,得到优化的策略最大化奖励值.在算法应用的场景上,值函数算法需要对动作进行采样,因此只能处理离散动作的情况,而策略梯度算法直接利用策略网络对动作进行搜索,可以被用来处理连续动作的情况.近年来,将值函数算法和策略梯度算法结合得到的执行器ԟ评价器(actor-critic,AC)结构也受到了广泛的关注.在 AC 结构中,执行器使用策略梯度法选取动作,通过值函数对执行器采取的动作进行评价,并且在训练时,执行器和评价器的参数交替更新. ...
Learning to predict by the methods of temporal differences
1
1988
... 基于值函数的 DRL 算法采用深度神经网络对值函数或者动作值函数进行近似,通过时间差分(temporal difference,TD)学习[12]或者 Q 学习[13]的方式分别对值函数或者动作值函数进行更新. ...
Q-learning
1
1992
... 基于值函数的 DRL 算法采用深度神经网络对值函数或者动作值函数进行近似,通过时间差分(temporal difference,TD)学习[12]或者 Q 学习[13]的方式分别对值函数或者动作值函数进行更新. ...
Deep reinforcement learning with double Q-learning
2
2016
... DQN的出现促进了DRL的兴起.然而,DQN还存在一些不足之处,例如对动作值函数的过估计.DQN的优化目标为 ,每一次更新时它都会对目标Q网络采取最大化操作,这样会导致对 Q 值的过高估计.深度双 Q 网络(double DQN,DDQN)[14]在目标Q函数中采用双网络结构,根据当前Q网络选取最优动作,并使用目标Q网络对选取的最优动作进行评估,两套参数将动作选择和策略评估分开,降低了过估计的风险.DDQN的目标函数表示为: ...
... 图5展示了几个典型的Atari 2600游戏环境,它们是很多DRL算法的测试环境.Atari 2600包含57款游戏,可以用来模拟真实环境中遇到的情况,且游戏环境具有多样性.DQN较早应用于Atari 2600的算法[5],它在22款游戏中取得了人类玩家的平均水平.之后,DQN 的各种改进版本(如 DDQN[14]、优先经验回放的DQN[15]、Dueling DQN[16],以及分布式DQN[17])分别在Atari 2600游戏中取得了不同程度的提升.然而,很难有一种算法能够在所有Atari 2600 游戏中都达到人类的水平,这主要有两个原因:一个是长期的信度分配,另一个是探索困境.信度分配在DRL中用来解决动作-奖励值分配的问题,DRL中存在奖励延时,因此很难将奖励值分配到具体的行动中,而且游戏运行时间越长,信度分配问题就越难解决.探索困境是指当环境状态的维数很大并且奖励值的设置比较稀疏时,智能体需要很多探索行为才能得到积极的反馈,导致算法很难收敛.为了解决这些问题,Badia A P等人[24]提出了Agent57算法,并成功地在所有Atari 2600游戏中超越了人类平均水平.针对长期的信度分配问题,Agent57 算法动态地对折扣因子进行调整,权衡未来奖励对当前状态-动作的重要性.同时Agent57 算法加入内部奖励值来解决探索困境,内部奖励值的大小由未探索过状态的新奇程度来决定.Agent57 算法采用两种内部的奖励值:一种是在一个学习周期(episode)内根据新奇的状态得到的奖励值;另一种是长期的,在学习周期之间根据状态的新奇程度得到的奖励值.最后的内部奖励值由这两部分组成.通过这些方法,Agent57算法成功地在所有Atari 2600游戏中超越人类玩家的平均水平,提高了DRL算法的通用性. ...
Prioritized experience replay
2
2016
... 经验回放技术打破了数据样本之间的相关性,保证了DQN训练的稳定性.但DQN中的经验数据是均匀随机采样的,有些关键的经验数据可能无法被采样到,这降低了算法的更新效率.为此,Schaul T等人[15]采用优先经验回放(prioritized experience replay)的方式来代替均匀随机采样,从而使策略更新速度加快.具体实施方法是:在提取经验数据时,根据 TD 误差的大小来判断优先级.TD 误差表示为 ,并且TD误差的绝对值越大,该经验样本被选取的概率越高.同时,优先经验回放在采样过程中使用随机比例化(stochastic prioritization)和重要性采样权重(importancesampling weight)两种技术.随机比例化使智能体以TD误差的大小进行概率采样,从而扩展了采样的多样性,保证了各个样本都有概率被采样到.重要性采样权重的使用放缓了参数更新的速度,保证了学习的稳定性.在Atari 2600游戏中,使用优先经验回放的 DQN 不仅可以提升算法收敛的速度,同时也能够取得更好的性能表现. ...
... 图5展示了几个典型的Atari 2600游戏环境,它们是很多DRL算法的测试环境.Atari 2600包含57款游戏,可以用来模拟真实环境中遇到的情况,且游戏环境具有多样性.DQN较早应用于Atari 2600的算法[5],它在22款游戏中取得了人类玩家的平均水平.之后,DQN 的各种改进版本(如 DDQN[14]、优先经验回放的DQN[15]、Dueling DQN[16],以及分布式DQN[17])分别在Atari 2600游戏中取得了不同程度的提升.然而,很难有一种算法能够在所有Atari 2600 游戏中都达到人类的水平,这主要有两个原因:一个是长期的信度分配,另一个是探索困境.信度分配在DRL中用来解决动作-奖励值分配的问题,DRL中存在奖励延时,因此很难将奖励值分配到具体的行动中,而且游戏运行时间越长,信度分配问题就越难解决.探索困境是指当环境状态的维数很大并且奖励值的设置比较稀疏时,智能体需要很多探索行为才能得到积极的反馈,导致算法很难收敛.为了解决这些问题,Badia A P等人[24]提出了Agent57算法,并成功地在所有Atari 2600游戏中超越了人类平均水平.针对长期的信度分配问题,Agent57 算法动态地对折扣因子进行调整,权衡未来奖励对当前状态-动作的重要性.同时Agent57 算法加入内部奖励值来解决探索困境,内部奖励值的大小由未探索过状态的新奇程度来决定.Agent57 算法采用两种内部的奖励值:一种是在一个学习周期(episode)内根据新奇的状态得到的奖励值;另一种是长期的,在学习周期之间根据状态的新奇程度得到的奖励值.最后的内部奖励值由这两部分组成.通过这些方法,Agent57算法成功地在所有Atari 2600游戏中超越人类玩家的平均水平,提高了DRL算法的通用性. ...
Dueling network architectures for deep reinforcement learning
2
2016
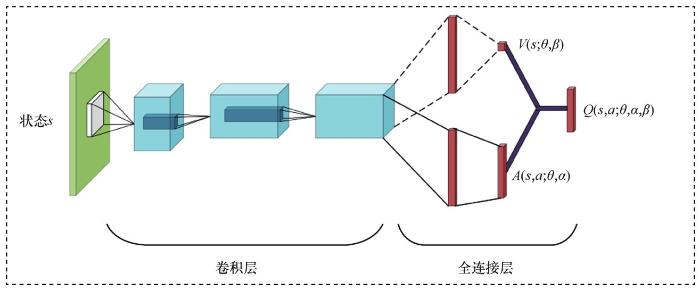
... 基于竞争架构的深度Q网络(Dueling DQN)[16]从网络结构上对 DQN 进行改进.与 DQN 相同, Dueling DQN采用卷积神经网络处理原始输入,但经过卷积神经网络处理的特征被分流到两个全连接网络中,一个是值函数网络V(s;θ,β),另一个是优势函数网络A(s,a;θ,α),其中θ是卷积神经网络的权重,β是值函数网络全连接层的权重参数,α是优势函数网络全连接层的权重参数.Dueling DQN的网络结构如图3所示,它的值函数网络被用来评估当前状态的价值,优势函数网络被用来处理与当前状态有关的动作.最后,将这两个网络进行合并,得到: ...
... 图5展示了几个典型的Atari 2600游戏环境,它们是很多DRL算法的测试环境.Atari 2600包含57款游戏,可以用来模拟真实环境中遇到的情况,且游戏环境具有多样性.DQN较早应用于Atari 2600的算法[5],它在22款游戏中取得了人类玩家的平均水平.之后,DQN 的各种改进版本(如 DDQN[14]、优先经验回放的DQN[15]、Dueling DQN[16],以及分布式DQN[17])分别在Atari 2600游戏中取得了不同程度的提升.然而,很难有一种算法能够在所有Atari 2600 游戏中都达到人类的水平,这主要有两个原因:一个是长期的信度分配,另一个是探索困境.信度分配在DRL中用来解决动作-奖励值分配的问题,DRL中存在奖励延时,因此很难将奖励值分配到具体的行动中,而且游戏运行时间越长,信度分配问题就越难解决.探索困境是指当环境状态的维数很大并且奖励值的设置比较稀疏时,智能体需要很多探索行为才能得到积极的反馈,导致算法很难收敛.为了解决这些问题,Badia A P等人[24]提出了Agent57算法,并成功地在所有Atari 2600游戏中超越了人类平均水平.针对长期的信度分配问题,Agent57 算法动态地对折扣因子进行调整,权衡未来奖励对当前状态-动作的重要性.同时Agent57 算法加入内部奖励值来解决探索困境,内部奖励值的大小由未探索过状态的新奇程度来决定.Agent57 算法采用两种内部的奖励值:一种是在一个学习周期(episode)内根据新奇的状态得到的奖励值;另一种是长期的,在学习周期之间根据状态的新奇程度得到的奖励值.最后的内部奖励值由这两部分组成.通过这些方法,Agent57算法成功地在所有Atari 2600游戏中超越人类玩家的平均水平,提高了DRL算法的通用性. ...
Massively parallel methods for deep reinforcement learning
2
2015
... 在训练过程中,DQN使用单个机器进行训练,这导致在实际中训练时间较长.为了充分利用计算资源,Nair A等人[17]提出一种分布式架构来加快算法的训练速度.它主要包括4个部分:①并行的行动者,算法采用N个不同的行动者,每个行动者复制一份 Q 网络,并在同一个环境中执行不同的动作,从而得到不同的经验;②经验回放存储机制,它将N个行动者与环境交互的经验存储到经验池中;③并行的学习者,算法采用N个学习者使用经验池存储的经验数据来计算损失函数的梯度,并发送到参数服务器中,从而对 Q 网络的参数进行更新;④参数服务器,用来接收学习者发送的梯度,并通过梯度下降的方式对Q网络参数进行更新.在49个Atari 2600游戏中,有41个游戏的基于分布式DQN算法的性能超过了DQN,并且在多种Atari 2600游戏中,分布式DQN算法的训练时间大大减少. ...
... 图5展示了几个典型的Atari 2600游戏环境,它们是很多DRL算法的测试环境.Atari 2600包含57款游戏,可以用来模拟真实环境中遇到的情况,且游戏环境具有多样性.DQN较早应用于Atari 2600的算法[5],它在22款游戏中取得了人类玩家的平均水平.之后,DQN 的各种改进版本(如 DDQN[14]、优先经验回放的DQN[15]、Dueling DQN[16],以及分布式DQN[17])分别在Atari 2600游戏中取得了不同程度的提升.然而,很难有一种算法能够在所有Atari 2600 游戏中都达到人类的水平,这主要有两个原因:一个是长期的信度分配,另一个是探索困境.信度分配在DRL中用来解决动作-奖励值分配的问题,DRL中存在奖励延时,因此很难将奖励值分配到具体的行动中,而且游戏运行时间越长,信度分配问题就越难解决.探索困境是指当环境状态的维数很大并且奖励值的设置比较稀疏时,智能体需要很多探索行为才能得到积极的反馈,导致算法很难收敛.为了解决这些问题,Badia A P等人[24]提出了Agent57算法,并成功地在所有Atari 2600游戏中超越了人类平均水平.针对长期的信度分配问题,Agent57 算法动态地对折扣因子进行调整,权衡未来奖励对当前状态-动作的重要性.同时Agent57 算法加入内部奖励值来解决探索困境,内部奖励值的大小由未探索过状态的新奇程度来决定.Agent57 算法采用两种内部的奖励值:一种是在一个学习周期(episode)内根据新奇的状态得到的奖励值;另一种是长期的,在学习周期之间根据状态的新奇程度得到的奖励值.最后的内部奖励值由这两部分组成.通过这些方法,Agent57算法成功地在所有Atari 2600游戏中超越人类玩家的平均水平,提高了DRL算法的通用性. ...
Deterministic policy gradient algorithms
1
2014
... 策略梯度算法一般采用随机性策略进行表示,表示为.然而随机性策略梯度算法需要对动作进行采样,当动作空间较大时,采样的计算量也会随之增加.为此,Silver D等人[18]提出确定性策略梯度(deterministic policy gradient,DPG)算法,采用确定性的方式对动作进行采样.确定性策略表示为μθ(s)=a,即在当前状态下采取确定的动作.为进一步提升算法的通用性, Lillicrap P T等人[19]将DQN和DPG算法进行结合,提出了DDPG算法.DDPG分别将θμ和θQ作为神经网络的参数来表示确定性策略和值函数.其中,策略网络被用来更新策略,相当于AC结构中的执行器;值函数网络被用来对动作进行评价,并提供梯度信息,相当于AC结构中的评价器.策略网络的更新过程表示为: ...
Continuous control with deep reinforcement learning
1
2016
... 策略梯度算法一般采用随机性策略进行表示,表示为.然而随机性策略梯度算法需要对动作进行采样,当动作空间较大时,采样的计算量也会随之增加.为此,Silver D等人[18]提出确定性策略梯度(deterministic policy gradient,DPG)算法,采用确定性的方式对动作进行采样.确定性策略表示为μθ(s)=a,即在当前状态下采取确定的动作.为进一步提升算法的通用性, Lillicrap P T等人[19]将DQN和DPG算法进行结合,提出了DDPG算法.DDPG分别将θμ和θQ作为神经网络的参数来表示确定性策略和值函数.其中,策略网络被用来更新策略,相当于AC结构中的执行器;值函数网络被用来对动作进行评价,并提供梯度信息,相当于AC结构中的评价器.策略网络的更新过程表示为: ...
Asynchronous methods for deep reinforcement learning
1
2016
... A3C 基于异步强化学习(asynchronous reinforcement learning)的思想[20],采用多线程操作,每一个线程异步执行智能体的动作.在每一时刻,各个执行器都经历不同的状态,并采取不同的动作,去除了训练过程中样本之间的相关性,因此这种异步的方式能够很好地代替经验回放,并且可以使用同策略(on-policy)的方式对参数进行更新.A3C算法显著地降低了对硬件的要求.以往的策略梯度算法需要计算能力很强的处理器GPU,而A3C算法在训练过程中只需要一个多核的 CPU.在 Atari 2600的游戏仿真中,A3C算法不仅大大降低了训练时间,而且平均性能也有明显提升.此外,A3C算法可以广泛地应用于各种2D、3D离散和连续动作的情况,具有很强的通用性. ...
Proximal policy optimization algorithms
1
2017
... 对于近年来的DRL算法来说,DQN由于不能处理连续动作,导致它的应用范围有限,A3C算法面临着超参数调整以及较低的采样效率.为此, Schulman J等人[21]提出了PPO算法.PPO算法采用一种“替代”目标: ...
Soft actor-critic:off-policy maximum entropy deep reinforcement learning with a stochastic actor
1
2018
... 策略梯度算法面临的一个很大的挑战是收敛性问题,即需要对学习率、探索因子等超参数进行精细的调整.为此,Haarnoja T等人[22]提出了一种基于最大熵的AC(soft AC,SAC)算法.SAC算法将熵的思想加入目标函数中,通过最大化目标函数得到最优奖励,同时也最大化熵,即智能体在完成任务的同时尽可能采取随机动作.SAC算法的目标函数的计算式为: ...
游戏智能中的 AI——从多角色博弈到平行博弈
1
2020
... DRL首先应用于视频游戏领域[23],主要的原因是 DRL 需要大量的采样和试错训练,而游戏环境能够提供充足的样本,并且避免了试错的成本.从目前的文献来看,研究 DRL 所采用的游戏环境可以分为两类:一类用来提升算法的通用性,如Atari 2600;另一类用来处理复杂的游戏场景,如ViZDoom、StarCraftII等. ...
游戏智能中的 AI——从多角色博弈到平行博弈
1
2020
... DRL首先应用于视频游戏领域[23],主要的原因是 DRL 需要大量的采样和试错训练,而游戏环境能够提供充足的样本,并且避免了试错的成本.从目前的文献来看,研究 DRL 所采用的游戏环境可以分为两类:一类用来提升算法的通用性,如Atari 2600;另一类用来处理复杂的游戏场景,如ViZDoom、StarCraftII等. ...
Agent57:outperforming the atari human benchmark
1
2020
... 图5展示了几个典型的Atari 2600游戏环境,它们是很多DRL算法的测试环境.Atari 2600包含57款游戏,可以用来模拟真实环境中遇到的情况,且游戏环境具有多样性.DQN较早应用于Atari 2600的算法[5],它在22款游戏中取得了人类玩家的平均水平.之后,DQN 的各种改进版本(如 DDQN[14]、优先经验回放的DQN[15]、Dueling DQN[16],以及分布式DQN[17])分别在Atari 2600游戏中取得了不同程度的提升.然而,很难有一种算法能够在所有Atari 2600 游戏中都达到人类的水平,这主要有两个原因:一个是长期的信度分配,另一个是探索困境.信度分配在DRL中用来解决动作-奖励值分配的问题,DRL中存在奖励延时,因此很难将奖励值分配到具体的行动中,而且游戏运行时间越长,信度分配问题就越难解决.探索困境是指当环境状态的维数很大并且奖励值的设置比较稀疏时,智能体需要很多探索行为才能得到积极的反馈,导致算法很难收敛.为了解决这些问题,Badia A P等人[24]提出了Agent57算法,并成功地在所有Atari 2600游戏中超越了人类平均水平.针对长期的信度分配问题,Agent57 算法动态地对折扣因子进行调整,权衡未来奖励对当前状态-动作的重要性.同时Agent57 算法加入内部奖励值来解决探索困境,内部奖励值的大小由未探索过状态的新奇程度来决定.Agent57 算法采用两种内部的奖励值:一种是在一个学习周期(episode)内根据新奇的状态得到的奖励值;另一种是长期的,在学习周期之间根据状态的新奇程度得到的奖励值.最后的内部奖励值由这两部分组成.通过这些方法,Agent57算法成功地在所有Atari 2600游戏中超越人类玩家的平均水平,提高了DRL算法的通用性. ...
Vizdoom:a doom-based AI research platform for visual reinforcement learning
1
2016
... 复杂游戏环境的状态和动作空间显著增大,更多地考虑 3D 环境的情况,并且涉及单智能体的多任务学习,或者多智能体之间的交互.Kempka M等人[25]提出将 ViZDoom 作为 DRL 的测试平台.ViZDoom采用第一视角的3D游戏环境,且游戏环境可以自由设计,以测试算法在不同任务上的性能.Lample G等人[26]提出了一种改进的DQN算法并将其应用于ViZDoom,该算法主要解决游戏中的两个任务,一个是在地图中导航搜寻敌人或者弹药,另一个是在发现敌人时采取射击行动,并且对每个任务分别采用一个网络,两个网络交替训练能够取得很好的效果.Dosovitskiy A等人[27]将一种有监督学习的方法应用于ViZDoom,使用高维感知流和低维测量流分别处理高维的原始图像以及与智能体当前状态有关的信息,并且训练好的模型可以被用于动态的指定目标.Pathak D等人[28]引入好奇心机制来解决 ViZDoom 游戏环境中奖励的稀疏性问题,将当前状态特征和动作输入前向模型中,对下一时刻的状态特征进行预测,并将预测误差作为内部奖励,鼓励智能体探索新奇的环境状态,同时还使用逆模型来提取只与当前动作有关的环境特征.针对 ViZDoom 游戏的复杂性,Wu Y 等人[29]提出了一种主从式课程 DRL 的方法,该方法引入了主从智能体的概念,其中一个主智能体被用来处理目标任务,多个从智能体被用来处理子任务,并且主从智能体可以使用不同的动作空间,同时引入课程学习,大大提高了算法的训练速度,显著地提高了智能体在游戏中的表现性能. ...
Playing FPS games with deep reinforcement learning
1
2017
... 复杂游戏环境的状态和动作空间显著增大,更多地考虑 3D 环境的情况,并且涉及单智能体的多任务学习,或者多智能体之间的交互.Kempka M等人[25]提出将 ViZDoom 作为 DRL 的测试平台.ViZDoom采用第一视角的3D游戏环境,且游戏环境可以自由设计,以测试算法在不同任务上的性能.Lample G等人[26]提出了一种改进的DQN算法并将其应用于ViZDoom,该算法主要解决游戏中的两个任务,一个是在地图中导航搜寻敌人或者弹药,另一个是在发现敌人时采取射击行动,并且对每个任务分别采用一个网络,两个网络交替训练能够取得很好的效果.Dosovitskiy A等人[27]将一种有监督学习的方法应用于ViZDoom,使用高维感知流和低维测量流分别处理高维的原始图像以及与智能体当前状态有关的信息,并且训练好的模型可以被用于动态的指定目标.Pathak D等人[28]引入好奇心机制来解决 ViZDoom 游戏环境中奖励的稀疏性问题,将当前状态特征和动作输入前向模型中,对下一时刻的状态特征进行预测,并将预测误差作为内部奖励,鼓励智能体探索新奇的环境状态,同时还使用逆模型来提取只与当前动作有关的环境特征.针对 ViZDoom 游戏的复杂性,Wu Y 等人[29]提出了一种主从式课程 DRL 的方法,该方法引入了主从智能体的概念,其中一个主智能体被用来处理目标任务,多个从智能体被用来处理子任务,并且主从智能体可以使用不同的动作空间,同时引入课程学习,大大提高了算法的训练速度,显著地提高了智能体在游戏中的表现性能. ...
Learning to act by predicting the future
1
2016
... 复杂游戏环境的状态和动作空间显著增大,更多地考虑 3D 环境的情况,并且涉及单智能体的多任务学习,或者多智能体之间的交互.Kempka M等人[25]提出将 ViZDoom 作为 DRL 的测试平台.ViZDoom采用第一视角的3D游戏环境,且游戏环境可以自由设计,以测试算法在不同任务上的性能.Lample G等人[26]提出了一种改进的DQN算法并将其应用于ViZDoom,该算法主要解决游戏中的两个任务,一个是在地图中导航搜寻敌人或者弹药,另一个是在发现敌人时采取射击行动,并且对每个任务分别采用一个网络,两个网络交替训练能够取得很好的效果.Dosovitskiy A等人[27]将一种有监督学习的方法应用于ViZDoom,使用高维感知流和低维测量流分别处理高维的原始图像以及与智能体当前状态有关的信息,并且训练好的模型可以被用于动态的指定目标.Pathak D等人[28]引入好奇心机制来解决 ViZDoom 游戏环境中奖励的稀疏性问题,将当前状态特征和动作输入前向模型中,对下一时刻的状态特征进行预测,并将预测误差作为内部奖励,鼓励智能体探索新奇的环境状态,同时还使用逆模型来提取只与当前动作有关的环境特征.针对 ViZDoom 游戏的复杂性,Wu Y 等人[29]提出了一种主从式课程 DRL 的方法,该方法引入了主从智能体的概念,其中一个主智能体被用来处理目标任务,多个从智能体被用来处理子任务,并且主从智能体可以使用不同的动作空间,同时引入课程学习,大大提高了算法的训练速度,显著地提高了智能体在游戏中的表现性能. ...
Curiosity-driven exploration by self-supervised prediction
1
2017
... 复杂游戏环境的状态和动作空间显著增大,更多地考虑 3D 环境的情况,并且涉及单智能体的多任务学习,或者多智能体之间的交互.Kempka M等人[25]提出将 ViZDoom 作为 DRL 的测试平台.ViZDoom采用第一视角的3D游戏环境,且游戏环境可以自由设计,以测试算法在不同任务上的性能.Lample G等人[26]提出了一种改进的DQN算法并将其应用于ViZDoom,该算法主要解决游戏中的两个任务,一个是在地图中导航搜寻敌人或者弹药,另一个是在发现敌人时采取射击行动,并且对每个任务分别采用一个网络,两个网络交替训练能够取得很好的效果.Dosovitskiy A等人[27]将一种有监督学习的方法应用于ViZDoom,使用高维感知流和低维测量流分别处理高维的原始图像以及与智能体当前状态有关的信息,并且训练好的模型可以被用于动态的指定目标.Pathak D等人[28]引入好奇心机制来解决 ViZDoom 游戏环境中奖励的稀疏性问题,将当前状态特征和动作输入前向模型中,对下一时刻的状态特征进行预测,并将预测误差作为内部奖励,鼓励智能体探索新奇的环境状态,同时还使用逆模型来提取只与当前动作有关的环境特征.针对 ViZDoom 游戏的复杂性,Wu Y 等人[29]提出了一种主从式课程 DRL 的方法,该方法引入了主从智能体的概念,其中一个主智能体被用来处理目标任务,多个从智能体被用来处理子任务,并且主从智能体可以使用不同的动作空间,同时引入课程学习,大大提高了算法的训练速度,显著地提高了智能体在游戏中的表现性能. ...
Master-slave curriculum design for reinforcement learning
1
2018
... 复杂游戏环境的状态和动作空间显著增大,更多地考虑 3D 环境的情况,并且涉及单智能体的多任务学习,或者多智能体之间的交互.Kempka M等人[25]提出将 ViZDoom 作为 DRL 的测试平台.ViZDoom采用第一视角的3D游戏环境,且游戏环境可以自由设计,以测试算法在不同任务上的性能.Lample G等人[26]提出了一种改进的DQN算法并将其应用于ViZDoom,该算法主要解决游戏中的两个任务,一个是在地图中导航搜寻敌人或者弹药,另一个是在发现敌人时采取射击行动,并且对每个任务分别采用一个网络,两个网络交替训练能够取得很好的效果.Dosovitskiy A等人[27]将一种有监督学习的方法应用于ViZDoom,使用高维感知流和低维测量流分别处理高维的原始图像以及与智能体当前状态有关的信息,并且训练好的模型可以被用于动态的指定目标.Pathak D等人[28]引入好奇心机制来解决 ViZDoom 游戏环境中奖励的稀疏性问题,将当前状态特征和动作输入前向模型中,对下一时刻的状态特征进行预测,并将预测误差作为内部奖励,鼓励智能体探索新奇的环境状态,同时还使用逆模型来提取只与当前动作有关的环境特征.针对 ViZDoom 游戏的复杂性,Wu Y 等人[29]提出了一种主从式课程 DRL 的方法,该方法引入了主从智能体的概念,其中一个主智能体被用来处理目标任务,多个从智能体被用来处理子任务,并且主从智能体可以使用不同的动作空间,同时引入课程学习,大大提高了算法的训练速度,显著地提高了智能体在游戏中的表现性能. ...
StarcraftII:a new challenge for reinforcement learning
1
2017
... Vinyals O 等人[30]提出了一种基于实时策略(real-time strategy,RTS)的 DRL 游戏环境StarCraftII.游戏环境中存在多智能体模式,由多个智能体通过协作或者竞争来取得游戏的胜利.在游戏环境中智能体接收有限的观测范围,通过高维、多变的动作空间选取动作,并且智能体还需要处理长期的信度分配问题以及探索困境.为了方便对DRL算法的研究,将StarCraftII简化为7个微型游戏,每个微型游戏分别代表不同的子任务.针对这个游戏环境,Zambaldi V等人[31]提出了一种关系型DRL(relational DRL)算法,该算法将关系型学习引入 DRL 中,将环境编码成二维输入,其中每个区域代表一个“实体”,并采用自我注意力机制[32]来计算各个“实体”之间的关系.实验表明,提出的算法在6个StarCraftII的微型游戏中取得了较好的结果,并且在4个微型游戏中超越了人类大师水平的玩家.Rashid T等人[33]采用一种MADRL算法来处理StarCraftII,提出QMIX算法将每个智能体的Q函数进行单调非线性的结合,形成一个联合Q函数,并使用联合Q函数进行学习.这种集中式训练、分布式执行的方式在StarCraftII上有很好的表现. ...
Relational deep reinforcement learning
1
2018
... Vinyals O 等人[30]提出了一种基于实时策略(real-time strategy,RTS)的 DRL 游戏环境StarCraftII.游戏环境中存在多智能体模式,由多个智能体通过协作或者竞争来取得游戏的胜利.在游戏环境中智能体接收有限的观测范围,通过高维、多变的动作空间选取动作,并且智能体还需要处理长期的信度分配问题以及探索困境.为了方便对DRL算法的研究,将StarCraftII简化为7个微型游戏,每个微型游戏分别代表不同的子任务.针对这个游戏环境,Zambaldi V等人[31]提出了一种关系型DRL(relational DRL)算法,该算法将关系型学习引入 DRL 中,将环境编码成二维输入,其中每个区域代表一个“实体”,并采用自我注意力机制[32]来计算各个“实体”之间的关系.实验表明,提出的算法在6个StarCraftII的微型游戏中取得了较好的结果,并且在4个微型游戏中超越了人类大师水平的玩家.Rashid T等人[33]采用一种MADRL算法来处理StarCraftII,提出QMIX算法将每个智能体的Q函数进行单调非线性的结合,形成一个联合Q函数,并使用联合Q函数进行学习.这种集中式训练、分布式执行的方式在StarCraftII上有很好的表现. ...
Attention is all you need
1
2017
... Vinyals O 等人[30]提出了一种基于实时策略(real-time strategy,RTS)的 DRL 游戏环境StarCraftII.游戏环境中存在多智能体模式,由多个智能体通过协作或者竞争来取得游戏的胜利.在游戏环境中智能体接收有限的观测范围,通过高维、多变的动作空间选取动作,并且智能体还需要处理长期的信度分配问题以及探索困境.为了方便对DRL算法的研究,将StarCraftII简化为7个微型游戏,每个微型游戏分别代表不同的子任务.针对这个游戏环境,Zambaldi V等人[31]提出了一种关系型DRL(relational DRL)算法,该算法将关系型学习引入 DRL 中,将环境编码成二维输入,其中每个区域代表一个“实体”,并采用自我注意力机制[32]来计算各个“实体”之间的关系.实验表明,提出的算法在6个StarCraftII的微型游戏中取得了较好的结果,并且在4个微型游戏中超越了人类大师水平的玩家.Rashid T等人[33]采用一种MADRL算法来处理StarCraftII,提出QMIX算法将每个智能体的Q函数进行单调非线性的结合,形成一个联合Q函数,并使用联合Q函数进行学习.这种集中式训练、分布式执行的方式在StarCraftII上有很好的表现. ...
QMIX:monotonic value function factorisation for deep multi-agent reinforcement learning
1
2018
... Vinyals O 等人[30]提出了一种基于实时策略(real-time strategy,RTS)的 DRL 游戏环境StarCraftII.游戏环境中存在多智能体模式,由多个智能体通过协作或者竞争来取得游戏的胜利.在游戏环境中智能体接收有限的观测范围,通过高维、多变的动作空间选取动作,并且智能体还需要处理长期的信度分配问题以及探索困境.为了方便对DRL算法的研究,将StarCraftII简化为7个微型游戏,每个微型游戏分别代表不同的子任务.针对这个游戏环境,Zambaldi V等人[31]提出了一种关系型DRL(relational DRL)算法,该算法将关系型学习引入 DRL 中,将环境编码成二维输入,其中每个区域代表一个“实体”,并采用自我注意力机制[32]来计算各个“实体”之间的关系.实验表明,提出的算法在6个StarCraftII的微型游戏中取得了较好的结果,并且在4个微型游戏中超越了人类大师水平的玩家.Rashid T等人[33]采用一种MADRL算法来处理StarCraftII,提出QMIX算法将每个智能体的Q函数进行单调非线性的结合,形成一个联合Q函数,并使用联合Q函数进行学习.这种集中式训练、分布式执行的方式在StarCraftII上有很好的表现. ...
Mastering complex control in MOBA games with deep reinforcement learning
1
2020
... 腾讯的AI Lab利用DRL研究了多人在线战术竞技(multi-player online battle arena,MOBA)游戏的1v1模式,该游戏具有很复杂的环境,并且需要很多的控制量.以MOBA中的王者荣耀(Honor of Kings)为例,它具有比围棋更大的状态和动作空间,给策略搜索带来了巨大的挑战.Ye D等人[34]提出了一种包含人工智能服务器、调度模块、记忆池以及强化学习学习者的 DRL 架构来处理该游戏环境,其中人工智能服务器负责与环境进行交互来产生经验数据;调度模块负责将人工智能服务器产生的经验数据进行压缩、打包,送到记忆池中;记忆池用于存储数据,并支持各种长度的样本数据,以及基于生成时间的数据采样;强化学习学习者采用分布式训练,并行地从记忆池中采样数据得到梯度,在同步梯度取均值后,对策略参数进行更新,并且将更新的策略参数传到人工智能服务器中.经过训练后,提出的算法在2 100场Honor of Kings的1v1竞赛中的获胜率为99.81%. ...
Control of memory,active perception,and action in minecraft
1
2016
... 对迷宫导航的研究首先根据应用场景设计迷宫环境,然后根据导航环境中要解决的问题采用相应的DRL算法.Oh J等人[35]针对多变的3D导航环境 Minecraft,提出了一种基于记忆的DRL架构.智能体提前对导航环境信息进行记忆,然后根据记忆的信息到达指定的目标点并获得奖励.Jaderberg M等人[36]提出采用无监督的辅助任务来增强 A3C 算法在迷宫导航中的性能.该辅助任务一方面将输入的迷宫图像分为多个不重叠的小区域,根据区域像素的变化生成伪奖励,鼓励智能体探索未知环境;另一方面使用先前的经验数据对下一时刻状态的即时奖励进行预测,解决环境奖励的稀疏性问题.经过辅助任务的加速训练,提出的算法在收敛速度、鲁棒性、成功率上都取得了较大的提升.Mirowski P等人[37]提出了一种基于A3C的DRL算法,使用其在复杂的迷宫环境中进行导航,迷宫环境如图6(a)所示.除了A3C算法的训练任务外,该算法还加入了两个辅助任务.第一个辅助任务是重建一个低维的深度图进行避障及短期路径规划,第二个辅助任务是直接从同步定位与建模(simultaneous localization and mapping,SLAM)中调用循环闭包来防止环路的形成.经过算法的训练,智能体能够在目标不断变化的 3D 迷宫环境中达到人类水平.Wang Y等人[38]提出了一种模块化的 DRL 算法来处理复杂的动态迷宫环境,并将导航任务分为避障模块和导航模块.避障模块采用时间和空间两个网络来处理动态障碍物信息.导航模块分为离线部分和在线部分,离线部分要进行预训练,用于快速地在无障碍的迷宫环境中找到终点,在线部分实时地在迷宫中探索、寻找路径.最后将两个模块采取的动作发送到动作调度器中选取智能体的动作.Shi H 等人[39]提出了一种端对端的DRL导航策略,用于迷宫导航.该导航策略采用好奇心机制解决导航环境中奖励稀疏的问题,同时将低维、稀疏的传感器用于智能体的观测输入,确保训练好的智能体可以直接应用于现实的导航环境中.Savinov N等人[40]将已经访问过的状态放入记忆模块中,并训练一个神经网络近似器来判断当前状态跟记忆中的状态的距离,并根据这个距离来判断这个状态是否为新奇的状态.经过该算法的训练,智能体能够在多种导航任务中取得好的表现,并且能够被用在无奖励的导航任务中. ...
Reinforcement learning with unsupervised auxiliary tasks
1
2016
... 对迷宫导航的研究首先根据应用场景设计迷宫环境,然后根据导航环境中要解决的问题采用相应的DRL算法.Oh J等人[35]针对多变的3D导航环境 Minecraft,提出了一种基于记忆的DRL架构.智能体提前对导航环境信息进行记忆,然后根据记忆的信息到达指定的目标点并获得奖励.Jaderberg M等人[36]提出采用无监督的辅助任务来增强 A3C 算法在迷宫导航中的性能.该辅助任务一方面将输入的迷宫图像分为多个不重叠的小区域,根据区域像素的变化生成伪奖励,鼓励智能体探索未知环境;另一方面使用先前的经验数据对下一时刻状态的即时奖励进行预测,解决环境奖励的稀疏性问题.经过辅助任务的加速训练,提出的算法在收敛速度、鲁棒性、成功率上都取得了较大的提升.Mirowski P等人[37]提出了一种基于A3C的DRL算法,使用其在复杂的迷宫环境中进行导航,迷宫环境如图6(a)所示.除了A3C算法的训练任务外,该算法还加入了两个辅助任务.第一个辅助任务是重建一个低维的深度图进行避障及短期路径规划,第二个辅助任务是直接从同步定位与建模(simultaneous localization and mapping,SLAM)中调用循环闭包来防止环路的形成.经过算法的训练,智能体能够在目标不断变化的 3D 迷宫环境中达到人类水平.Wang Y等人[38]提出了一种模块化的 DRL 算法来处理复杂的动态迷宫环境,并将导航任务分为避障模块和导航模块.避障模块采用时间和空间两个网络来处理动态障碍物信息.导航模块分为离线部分和在线部分,离线部分要进行预训练,用于快速地在无障碍的迷宫环境中找到终点,在线部分实时地在迷宫中探索、寻找路径.最后将两个模块采取的动作发送到动作调度器中选取智能体的动作.Shi H 等人[39]提出了一种端对端的DRL导航策略,用于迷宫导航.该导航策略采用好奇心机制解决导航环境中奖励稀疏的问题,同时将低维、稀疏的传感器用于智能体的观测输入,确保训练好的智能体可以直接应用于现实的导航环境中.Savinov N等人[40]将已经访问过的状态放入记忆模块中,并训练一个神经网络近似器来判断当前状态跟记忆中的状态的距离,并根据这个距离来判断这个状态是否为新奇的状态.经过该算法的训练,智能体能够在多种导航任务中取得好的表现,并且能够被用在无奖励的导航任务中. ...
Learning to navigate in complex environments
1
2016
... 对迷宫导航的研究首先根据应用场景设计迷宫环境,然后根据导航环境中要解决的问题采用相应的DRL算法.Oh J等人[35]针对多变的3D导航环境 Minecraft,提出了一种基于记忆的DRL架构.智能体提前对导航环境信息进行记忆,然后根据记忆的信息到达指定的目标点并获得奖励.Jaderberg M等人[36]提出采用无监督的辅助任务来增强 A3C 算法在迷宫导航中的性能.该辅助任务一方面将输入的迷宫图像分为多个不重叠的小区域,根据区域像素的变化生成伪奖励,鼓励智能体探索未知环境;另一方面使用先前的经验数据对下一时刻状态的即时奖励进行预测,解决环境奖励的稀疏性问题.经过辅助任务的加速训练,提出的算法在收敛速度、鲁棒性、成功率上都取得了较大的提升.Mirowski P等人[37]提出了一种基于A3C的DRL算法,使用其在复杂的迷宫环境中进行导航,迷宫环境如图6(a)所示.除了A3C算法的训练任务外,该算法还加入了两个辅助任务.第一个辅助任务是重建一个低维的深度图进行避障及短期路径规划,第二个辅助任务是直接从同步定位与建模(simultaneous localization and mapping,SLAM)中调用循环闭包来防止环路的形成.经过算法的训练,智能体能够在目标不断变化的 3D 迷宫环境中达到人类水平.Wang Y等人[38]提出了一种模块化的 DRL 算法来处理复杂的动态迷宫环境,并将导航任务分为避障模块和导航模块.避障模块采用时间和空间两个网络来处理动态障碍物信息.导航模块分为离线部分和在线部分,离线部分要进行预训练,用于快速地在无障碍的迷宫环境中找到终点,在线部分实时地在迷宫中探索、寻找路径.最后将两个模块采取的动作发送到动作调度器中选取智能体的动作.Shi H 等人[39]提出了一种端对端的DRL导航策略,用于迷宫导航.该导航策略采用好奇心机制解决导航环境中奖励稀疏的问题,同时将低维、稀疏的传感器用于智能体的观测输入,确保训练好的智能体可以直接应用于现实的导航环境中.Savinov N等人[40]将已经访问过的状态放入记忆模块中,并训练一个神经网络近似器来判断当前状态跟记忆中的状态的距离,并根据这个距离来判断这个状态是否为新奇的状态.经过该算法的训练,智能体能够在多种导航任务中取得好的表现,并且能够被用在无奖励的导航任务中. ...
Learning to navigate through complex dynamic environment with modular deep reinforcement learning
1
2018
... 对迷宫导航的研究首先根据应用场景设计迷宫环境,然后根据导航环境中要解决的问题采用相应的DRL算法.Oh J等人[35]针对多变的3D导航环境 Minecraft,提出了一种基于记忆的DRL架构.智能体提前对导航环境信息进行记忆,然后根据记忆的信息到达指定的目标点并获得奖励.Jaderberg M等人[36]提出采用无监督的辅助任务来增强 A3C 算法在迷宫导航中的性能.该辅助任务一方面将输入的迷宫图像分为多个不重叠的小区域,根据区域像素的变化生成伪奖励,鼓励智能体探索未知环境;另一方面使用先前的经验数据对下一时刻状态的即时奖励进行预测,解决环境奖励的稀疏性问题.经过辅助任务的加速训练,提出的算法在收敛速度、鲁棒性、成功率上都取得了较大的提升.Mirowski P等人[37]提出了一种基于A3C的DRL算法,使用其在复杂的迷宫环境中进行导航,迷宫环境如图6(a)所示.除了A3C算法的训练任务外,该算法还加入了两个辅助任务.第一个辅助任务是重建一个低维的深度图进行避障及短期路径规划,第二个辅助任务是直接从同步定位与建模(simultaneous localization and mapping,SLAM)中调用循环闭包来防止环路的形成.经过算法的训练,智能体能够在目标不断变化的 3D 迷宫环境中达到人类水平.Wang Y等人[38]提出了一种模块化的 DRL 算法来处理复杂的动态迷宫环境,并将导航任务分为避障模块和导航模块.避障模块采用时间和空间两个网络来处理动态障碍物信息.导航模块分为离线部分和在线部分,离线部分要进行预训练,用于快速地在无障碍的迷宫环境中找到终点,在线部分实时地在迷宫中探索、寻找路径.最后将两个模块采取的动作发送到动作调度器中选取智能体的动作.Shi H 等人[39]提出了一种端对端的DRL导航策略,用于迷宫导航.该导航策略采用好奇心机制解决导航环境中奖励稀疏的问题,同时将低维、稀疏的传感器用于智能体的观测输入,确保训练好的智能体可以直接应用于现实的导航环境中.Savinov N等人[40]将已经访问过的状态放入记忆模块中,并训练一个神经网络近似器来判断当前状态跟记忆中的状态的距离,并根据这个距离来判断这个状态是否为新奇的状态.经过该算法的训练,智能体能够在多种导航任务中取得好的表现,并且能够被用在无奖励的导航任务中. ...
End-to-end navigation strategy with deep reinforcement learning for mobile robots
1
2020
... 对迷宫导航的研究首先根据应用场景设计迷宫环境,然后根据导航环境中要解决的问题采用相应的DRL算法.Oh J等人[35]针对多变的3D导航环境 Minecraft,提出了一种基于记忆的DRL架构.智能体提前对导航环境信息进行记忆,然后根据记忆的信息到达指定的目标点并获得奖励.Jaderberg M等人[36]提出采用无监督的辅助任务来增强 A3C 算法在迷宫导航中的性能.该辅助任务一方面将输入的迷宫图像分为多个不重叠的小区域,根据区域像素的变化生成伪奖励,鼓励智能体探索未知环境;另一方面使用先前的经验数据对下一时刻状态的即时奖励进行预测,解决环境奖励的稀疏性问题.经过辅助任务的加速训练,提出的算法在收敛速度、鲁棒性、成功率上都取得了较大的提升.Mirowski P等人[37]提出了一种基于A3C的DRL算法,使用其在复杂的迷宫环境中进行导航,迷宫环境如图6(a)所示.除了A3C算法的训练任务外,该算法还加入了两个辅助任务.第一个辅助任务是重建一个低维的深度图进行避障及短期路径规划,第二个辅助任务是直接从同步定位与建模(simultaneous localization and mapping,SLAM)中调用循环闭包来防止环路的形成.经过算法的训练,智能体能够在目标不断变化的 3D 迷宫环境中达到人类水平.Wang Y等人[38]提出了一种模块化的 DRL 算法来处理复杂的动态迷宫环境,并将导航任务分为避障模块和导航模块.避障模块采用时间和空间两个网络来处理动态障碍物信息.导航模块分为离线部分和在线部分,离线部分要进行预训练,用于快速地在无障碍的迷宫环境中找到终点,在线部分实时地在迷宫中探索、寻找路径.最后将两个模块采取的动作发送到动作调度器中选取智能体的动作.Shi H 等人[39]提出了一种端对端的DRL导航策略,用于迷宫导航.该导航策略采用好奇心机制解决导航环境中奖励稀疏的问题,同时将低维、稀疏的传感器用于智能体的观测输入,确保训练好的智能体可以直接应用于现实的导航环境中.Savinov N等人[40]将已经访问过的状态放入记忆模块中,并训练一个神经网络近似器来判断当前状态跟记忆中的状态的距离,并根据这个距离来判断这个状态是否为新奇的状态.经过该算法的训练,智能体能够在多种导航任务中取得好的表现,并且能够被用在无奖励的导航任务中. ...
Episodic curiosity through reachability
1
2019
... 对迷宫导航的研究首先根据应用场景设计迷宫环境,然后根据导航环境中要解决的问题采用相应的DRL算法.Oh J等人[35]针对多变的3D导航环境 Minecraft,提出了一种基于记忆的DRL架构.智能体提前对导航环境信息进行记忆,然后根据记忆的信息到达指定的目标点并获得奖励.Jaderberg M等人[36]提出采用无监督的辅助任务来增强 A3C 算法在迷宫导航中的性能.该辅助任务一方面将输入的迷宫图像分为多个不重叠的小区域,根据区域像素的变化生成伪奖励,鼓励智能体探索未知环境;另一方面使用先前的经验数据对下一时刻状态的即时奖励进行预测,解决环境奖励的稀疏性问题.经过辅助任务的加速训练,提出的算法在收敛速度、鲁棒性、成功率上都取得了较大的提升.Mirowski P等人[37]提出了一种基于A3C的DRL算法,使用其在复杂的迷宫环境中进行导航,迷宫环境如图6(a)所示.除了A3C算法的训练任务外,该算法还加入了两个辅助任务.第一个辅助任务是重建一个低维的深度图进行避障及短期路径规划,第二个辅助任务是直接从同步定位与建模(simultaneous localization and mapping,SLAM)中调用循环闭包来防止环路的形成.经过算法的训练,智能体能够在目标不断变化的 3D 迷宫环境中达到人类水平.Wang Y等人[38]提出了一种模块化的 DRL 算法来处理复杂的动态迷宫环境,并将导航任务分为避障模块和导航模块.避障模块采用时间和空间两个网络来处理动态障碍物信息.导航模块分为离线部分和在线部分,离线部分要进行预训练,用于快速地在无障碍的迷宫环境中找到终点,在线部分实时地在迷宫中探索、寻找路径.最后将两个模块采取的动作发送到动作调度器中选取智能体的动作.Shi H 等人[39]提出了一种端对端的DRL导航策略,用于迷宫导航.该导航策略采用好奇心机制解决导航环境中奖励稀疏的问题,同时将低维、稀疏的传感器用于智能体的观测输入,确保训练好的智能体可以直接应用于现实的导航环境中.Savinov N等人[40]将已经访问过的状态放入记忆模块中,并训练一个神经网络近似器来判断当前状态跟记忆中的状态的距离,并根据这个距离来判断这个状态是否为新奇的状态.经过该算法的训练,智能体能够在多种导航任务中取得好的表现,并且能够被用在无奖励的导航任务中. ...
Target-driven visual navigation in indoor scenes using deep reinforcement learning
1
2017
... 室内导航采用 DRL 算法在室内环境中找到指定的目标点,主要的研究包括多目标导航以及将在仿真环境中训练好的智能体直接用到现实环境中.Zhu Y 等人[41]提出了一种多目标室内导航的 DRL算法,为了保证训练好的智能体能够被直接应用到新的导航目标,将导航的目标点和智能体的观测合并,作为输入,得到策略及值函数,采用A3C算法进行训练.同时,将算法应用于图6(b)所示的3D 室内导航环境中,训练后的智能体经过参数微调可以被直接应用到现实环境中.Tai L 等人[42]采用DRL算法训练智能体在迷宫中避开各种障碍物,将原始的 RGB 图像作为输入,使用深度学习在导航环境中进行预训练,并把预训练的权重复制到DRL 的卷积层上,然后端对端地对智能体进行训练.此后 Tai L 等人[43]又提出了一种连续控制的DRL导航方法,将虚拟导航环境中训练好的智能体直接应用到现实环境中.为了减少虚拟环境和现实环境的偏差,其采用低维的激光传感器作为视觉输入,并且输出智能体的线速度和角速度,以达到连续控制的效果.Wu Y等人[44]提出了两个设计来提升 DRL 方法室内多目标导航的表现性能:一是将逆动态模型(inverse dynamics model,InvDM)引入AC结构中,该InvDM被训练为一个辅助任务,用于预测给定了当前状态和最后一个状态的情况下智能体所采取的最后一个动作;二是提出了一种多目标共同学习的方法,智能体导航到一个目标的路径中可能包含其他的目标,因此这条路径可以为导航到其他目标点提供帮助.Zhang W等人[45]提出了一种适用于不同大小智能体的 DRL 算法,先利用 SAC 算法在虚拟导航环境中进行训练,然后将训练好的智能体直接应用到现实的导航环境中,进一步采用元学习方法将现实环境中训练好的导航技巧扩展到其他不同大小的智能体上. ...
Towards cognitive exploration through deep reinforcement learning for mobile robots
1
2016
... 室内导航采用 DRL 算法在室内环境中找到指定的目标点,主要的研究包括多目标导航以及将在仿真环境中训练好的智能体直接用到现实环境中.Zhu Y 等人[41]提出了一种多目标室内导航的 DRL算法,为了保证训练好的智能体能够被直接应用到新的导航目标,将导航的目标点和智能体的观测合并,作为输入,得到策略及值函数,采用A3C算法进行训练.同时,将算法应用于图6(b)所示的3D 室内导航环境中,训练后的智能体经过参数微调可以被直接应用到现实环境中.Tai L 等人[42]采用DRL算法训练智能体在迷宫中避开各种障碍物,将原始的 RGB 图像作为输入,使用深度学习在导航环境中进行预训练,并把预训练的权重复制到DRL 的卷积层上,然后端对端地对智能体进行训练.此后 Tai L 等人[43]又提出了一种连续控制的DRL导航方法,将虚拟导航环境中训练好的智能体直接应用到现实环境中.为了减少虚拟环境和现实环境的偏差,其采用低维的激光传感器作为视觉输入,并且输出智能体的线速度和角速度,以达到连续控制的效果.Wu Y等人[44]提出了两个设计来提升 DRL 方法室内多目标导航的表现性能:一是将逆动态模型(inverse dynamics model,InvDM)引入AC结构中,该InvDM被训练为一个辅助任务,用于预测给定了当前状态和最后一个状态的情况下智能体所采取的最后一个动作;二是提出了一种多目标共同学习的方法,智能体导航到一个目标的路径中可能包含其他的目标,因此这条路径可以为导航到其他目标点提供帮助.Zhang W等人[45]提出了一种适用于不同大小智能体的 DRL 算法,先利用 SAC 算法在虚拟导航环境中进行训练,然后将训练好的智能体直接应用到现实的导航环境中,进一步采用元学习方法将现实环境中训练好的导航技巧扩展到其他不同大小的智能体上. ...
Virtual-to-real deep reinforcement learning:continuous control of mobile robots for mapless navigation
1
2017
... 室内导航采用 DRL 算法在室内环境中找到指定的目标点,主要的研究包括多目标导航以及将在仿真环境中训练好的智能体直接用到现实环境中.Zhu Y 等人[41]提出了一种多目标室内导航的 DRL算法,为了保证训练好的智能体能够被直接应用到新的导航目标,将导航的目标点和智能体的观测合并,作为输入,得到策略及值函数,采用A3C算法进行训练.同时,将算法应用于图6(b)所示的3D 室内导航环境中,训练后的智能体经过参数微调可以被直接应用到现实环境中.Tai L 等人[42]采用DRL算法训练智能体在迷宫中避开各种障碍物,将原始的 RGB 图像作为输入,使用深度学习在导航环境中进行预训练,并把预训练的权重复制到DRL 的卷积层上,然后端对端地对智能体进行训练.此后 Tai L 等人[43]又提出了一种连续控制的DRL导航方法,将虚拟导航环境中训练好的智能体直接应用到现实环境中.为了减少虚拟环境和现实环境的偏差,其采用低维的激光传感器作为视觉输入,并且输出智能体的线速度和角速度,以达到连续控制的效果.Wu Y等人[44]提出了两个设计来提升 DRL 方法室内多目标导航的表现性能:一是将逆动态模型(inverse dynamics model,InvDM)引入AC结构中,该InvDM被训练为一个辅助任务,用于预测给定了当前状态和最后一个状态的情况下智能体所采取的最后一个动作;二是提出了一种多目标共同学习的方法,智能体导航到一个目标的路径中可能包含其他的目标,因此这条路径可以为导航到其他目标点提供帮助.Zhang W等人[45]提出了一种适用于不同大小智能体的 DRL 算法,先利用 SAC 算法在虚拟导航环境中进行训练,然后将训练好的智能体直接应用到现实的导航环境中,进一步采用元学习方法将现实环境中训练好的导航技巧扩展到其他不同大小的智能体上. ...
Exploring the task cooperation in multi-goal visual navigation
1
2019
... 室内导航采用 DRL 算法在室内环境中找到指定的目标点,主要的研究包括多目标导航以及将在仿真环境中训练好的智能体直接用到现实环境中.Zhu Y 等人[41]提出了一种多目标室内导航的 DRL算法,为了保证训练好的智能体能够被直接应用到新的导航目标,将导航的目标点和智能体的观测合并,作为输入,得到策略及值函数,采用A3C算法进行训练.同时,将算法应用于图6(b)所示的3D 室内导航环境中,训练后的智能体经过参数微调可以被直接应用到现实环境中.Tai L 等人[42]采用DRL算法训练智能体在迷宫中避开各种障碍物,将原始的 RGB 图像作为输入,使用深度学习在导航环境中进行预训练,并把预训练的权重复制到DRL 的卷积层上,然后端对端地对智能体进行训练.此后 Tai L 等人[43]又提出了一种连续控制的DRL导航方法,将虚拟导航环境中训练好的智能体直接应用到现实环境中.为了减少虚拟环境和现实环境的偏差,其采用低维的激光传感器作为视觉输入,并且输出智能体的线速度和角速度,以达到连续控制的效果.Wu Y等人[44]提出了两个设计来提升 DRL 方法室内多目标导航的表现性能:一是将逆动态模型(inverse dynamics model,InvDM)引入AC结构中,该InvDM被训练为一个辅助任务,用于预测给定了当前状态和最后一个状态的情况下智能体所采取的最后一个动作;二是提出了一种多目标共同学习的方法,智能体导航到一个目标的路径中可能包含其他的目标,因此这条路径可以为导航到其他目标点提供帮助.Zhang W等人[45]提出了一种适用于不同大小智能体的 DRL 算法,先利用 SAC 算法在虚拟导航环境中进行训练,然后将训练好的智能体直接应用到现实的导航环境中,进一步采用元学习方法将现实环境中训练好的导航技巧扩展到其他不同大小的智能体上. ...
Map-less navigation:a single DRL-based controller for robots with varied dimensions
1
2020
... 室内导航采用 DRL 算法在室内环境中找到指定的目标点,主要的研究包括多目标导航以及将在仿真环境中训练好的智能体直接用到现实环境中.Zhu Y 等人[41]提出了一种多目标室内导航的 DRL算法,为了保证训练好的智能体能够被直接应用到新的导航目标,将导航的目标点和智能体的观测合并,作为输入,得到策略及值函数,采用A3C算法进行训练.同时,将算法应用于图6(b)所示的3D 室内导航环境中,训练后的智能体经过参数微调可以被直接应用到现实环境中.Tai L 等人[42]采用DRL算法训练智能体在迷宫中避开各种障碍物,将原始的 RGB 图像作为输入,使用深度学习在导航环境中进行预训练,并把预训练的权重复制到DRL 的卷积层上,然后端对端地对智能体进行训练.此后 Tai L 等人[43]又提出了一种连续控制的DRL导航方法,将虚拟导航环境中训练好的智能体直接应用到现实环境中.为了减少虚拟环境和现实环境的偏差,其采用低维的激光传感器作为视觉输入,并且输出智能体的线速度和角速度,以达到连续控制的效果.Wu Y等人[44]提出了两个设计来提升 DRL 方法室内多目标导航的表现性能:一是将逆动态模型(inverse dynamics model,InvDM)引入AC结构中,该InvDM被训练为一个辅助任务,用于预测给定了当前状态和最后一个状态的情况下智能体所采取的最后一个动作;二是提出了一种多目标共同学习的方法,智能体导航到一个目标的路径中可能包含其他的目标,因此这条路径可以为导航到其他目标点提供帮助.Zhang W等人[45]提出了一种适用于不同大小智能体的 DRL 算法,先利用 SAC 算法在虚拟导航环境中进行训练,然后将训练好的智能体直接应用到现实的导航环境中,进一步采用元学习方法将现实环境中训练好的导航技巧扩展到其他不同大小的智能体上. ...
Learning to navigate in cities without a map
1
2018
... 街景导航的研究涉及长距离导航,主要通过DRL 算法来解决城市之间的路径规划问题.Mirowski P等人[46]提出了一种无地图城市之间导航的 DRL 算法,主要使用谷歌街景地图的内容构建了一个覆盖全球的交互导航环境StreetLearn,并提出了一种模块化、以目标为导向的 DRL 算法来处理这个导航场景.Li A等人[47]提出了利用鸟瞰以及地面两种视图来完成导航任务的 DRL 方法,先使用街景环境的地面和鸟瞰视图对智能体进行训练,通过新的导航环境的鸟瞰视图对智能体的训练结果进行调整,然后将调整的结果迁移到新的地面视图街景导航环境中.Hermann K M 等人[48]在StreetLearn的基础上,加入了谷歌地图中的驾驶说明,用于指导从起点到终点的路径,使智能体像人类一样按照指示在城市之间导航,构建了一种新的街景导航环境StreetNav.针对DRL算法在现实导航任务中采样效率不足的问题,Chancán M等人[49]提出了一种交互式街景导航架构CityLearn,采用视觉位置识别和深度学习模型对传感器的输入图像进行编码,将目标位置生成状态作为智能体的输入状态,再使用PPO算法对智能体进行训练,得到导航策略,训练好的智能体在极度变化的视觉环境中(如从白天到黑夜)也能应用. ...
Cross-view policy learning for street navigation
1
2019
... 街景导航的研究涉及长距离导航,主要通过DRL 算法来解决城市之间的路径规划问题.Mirowski P等人[46]提出了一种无地图城市之间导航的 DRL 算法,主要使用谷歌街景地图的内容构建了一个覆盖全球的交互导航环境StreetLearn,并提出了一种模块化、以目标为导向的 DRL 算法来处理这个导航场景.Li A等人[47]提出了利用鸟瞰以及地面两种视图来完成导航任务的 DRL 方法,先使用街景环境的地面和鸟瞰视图对智能体进行训练,通过新的导航环境的鸟瞰视图对智能体的训练结果进行调整,然后将调整的结果迁移到新的地面视图街景导航环境中.Hermann K M 等人[48]在StreetLearn的基础上,加入了谷歌地图中的驾驶说明,用于指导从起点到终点的路径,使智能体像人类一样按照指示在城市之间导航,构建了一种新的街景导航环境StreetNav.针对DRL算法在现实导航任务中采样效率不足的问题,Chancán M等人[49]提出了一种交互式街景导航架构CityLearn,采用视觉位置识别和深度学习模型对传感器的输入图像进行编码,将目标位置生成状态作为智能体的输入状态,再使用PPO算法对智能体进行训练,得到导航策略,训练好的智能体在极度变化的视觉环境中(如从白天到黑夜)也能应用. ...
Learning to follow directions in street view
1
2020
... 街景导航的研究涉及长距离导航,主要通过DRL 算法来解决城市之间的路径规划问题.Mirowski P等人[46]提出了一种无地图城市之间导航的 DRL 算法,主要使用谷歌街景地图的内容构建了一个覆盖全球的交互导航环境StreetLearn,并提出了一种模块化、以目标为导向的 DRL 算法来处理这个导航场景.Li A等人[47]提出了利用鸟瞰以及地面两种视图来完成导航任务的 DRL 方法,先使用街景环境的地面和鸟瞰视图对智能体进行训练,通过新的导航环境的鸟瞰视图对智能体的训练结果进行调整,然后将调整的结果迁移到新的地面视图街景导航环境中.Hermann K M 等人[48]在StreetLearn的基础上,加入了谷歌地图中的驾驶说明,用于指导从起点到终点的路径,使智能体像人类一样按照指示在城市之间导航,构建了一种新的街景导航环境StreetNav.针对DRL算法在现实导航任务中采样效率不足的问题,Chancán M等人[49]提出了一种交互式街景导航架构CityLearn,采用视觉位置识别和深度学习模型对传感器的输入图像进行编码,将目标位置生成状态作为智能体的输入状态,再使用PPO算法对智能体进行训练,得到导航策略,训练好的智能体在极度变化的视觉环境中(如从白天到黑夜)也能应用. ...
CityLearn:diverse real-world environments for sample-efficient navigation policy learning
1
2020
... 街景导航的研究涉及长距离导航,主要通过DRL 算法来解决城市之间的路径规划问题.Mirowski P等人[46]提出了一种无地图城市之间导航的 DRL 算法,主要使用谷歌街景地图的内容构建了一个覆盖全球的交互导航环境StreetLearn,并提出了一种模块化、以目标为导向的 DRL 算法来处理这个导航场景.Li A等人[47]提出了利用鸟瞰以及地面两种视图来完成导航任务的 DRL 方法,先使用街景环境的地面和鸟瞰视图对智能体进行训练,通过新的导航环境的鸟瞰视图对智能体的训练结果进行调整,然后将调整的结果迁移到新的地面视图街景导航环境中.Hermann K M 等人[48]在StreetLearn的基础上,加入了谷歌地图中的驾驶说明,用于指导从起点到终点的路径,使智能体像人类一样按照指示在城市之间导航,构建了一种新的街景导航环境StreetNav.针对DRL算法在现实导航任务中采样效率不足的问题,Chancán M等人[49]提出了一种交互式街景导航架构CityLearn,采用视觉位置识别和深度学习模型对传感器的输入图像进行编码,将目标位置生成状态作为智能体的输入状态,再使用PPO算法对智能体进行训练,得到导航策略,训练好的智能体在极度变化的视觉环境中(如从白天到黑夜)也能应用. ...
多智能体深度强化学习的若干关键科学问题
1
2020
... 近年来,DRL在多智能体协作方面也得到了广泛的应用.采用 DRL 解决多智能体协作问题涉及智能体之间的交互,需要考虑状态-动作维数过大、环境非静态、部分可观测等问题[50],因此相对于单智能体来说,对多智能体的研究更具有挑战性.多智能体协作是指多个智能体通过相互合作达到共同的目标,从而得到联合的奖励值.DRL在多智能体协作方面的研究主要包括独立学习者协作、集中式评价器协作以及通信协作等[51]. ...
多智能体深度强化学习的若干关键科学问题
1
2020
... 近年来,DRL在多智能体协作方面也得到了广泛的应用.采用 DRL 解决多智能体协作问题涉及智能体之间的交互,需要考虑状态-动作维数过大、环境非静态、部分可观测等问题[50],因此相对于单智能体来说,对多智能体的研究更具有挑战性.多智能体协作是指多个智能体通过相互合作达到共同的目标,从而得到联合的奖励值.DRL在多智能体协作方面的研究主要包括独立学习者协作、集中式评价器协作以及通信协作等[51]. ...
A review of cooperative multi-agent deep reinforcement learning
1
2019
... 近年来,DRL在多智能体协作方面也得到了广泛的应用.采用 DRL 解决多智能体协作问题涉及智能体之间的交互,需要考虑状态-动作维数过大、环境非静态、部分可观测等问题[50],因此相对于单智能体来说,对多智能体的研究更具有挑战性.多智能体协作是指多个智能体通过相互合作达到共同的目标,从而得到联合的奖励值.DRL在多智能体协作方面的研究主要包括独立学习者协作、集中式评价器协作以及通信协作等[51]. ...
Deep decentralized multi-task multi-agent reinforcement learning under partial observability
1
2017
... 独立学习者是指智能体在更新自身的策略时,把其他智能体作为环境的一部分,每个智能体采用独立更新的方式,不考虑其他智能体的状态和动作.若采用这种更新方式,每个智能体在训练时比较简单,方便智能体进行数量上的扩展.但其他智能体的策略在不断更新,因此智能体所处的环境是不断变化的,这导致智能体不满足 MDP 条件,即MADRL面临环境非静态问题.Omidshafiei S等人[52]提出使用滞回强化学习[53]的方法来解决环境非静态问题,通过对不同的TD误差采用不同大小的学习率,减弱环境变化对Q值的影响,并采用一种并行经验回放的方式,保证多个智能体在使用经验回放时能够得到最优的联合动作.对于多智能体来说,当智能体的策略不断变化时,经验回放技术也不再适用,这给MADRL带来了很大的挑战.Palmer G等人[55]提出了宽松DQN(lenient DQN)算法来解决环境非静态问题,以宽松条件来决定经验池中的采样数据,不满足条件的经验数据将被忽略.Jin Y等人[57]提出了对其他智能体的动作进行估计的方法来解决环境非稳态问题,在评估Q函数时加入对其他智能体动作的估计,减弱环境非静态带来的影响.Liu X等人[58]对邻近智能体的关系进行建模,提出了注意力关系型编码器来聚合任意数量邻近智能体的特征,并采用参数共享[59]的方式来减少参数的更新量,使算法可扩展到大规模智能体的训练. ...
Hysteretic Q-learning:an algorithm for decentralized reinforcement learning in cooperative multi-agent teams
1
2007
... 独立学习者是指智能体在更新自身的策略时,把其他智能体作为环境的一部分,每个智能体采用独立更新的方式,不考虑其他智能体的状态和动作.若采用这种更新方式,每个智能体在训练时比较简单,方便智能体进行数量上的扩展.但其他智能体的策略在不断更新,因此智能体所处的环境是不断变化的,这导致智能体不满足 MDP 条件,即MADRL面临环境非静态问题.Omidshafiei S等人[52]提出使用滞回强化学习[53]的方法来解决环境非静态问题,通过对不同的TD误差采用不同大小的学习率,减弱环境变化对Q值的影响,并采用一种并行经验回放的方式,保证多个智能体在使用经验回放时能够得到最优的联合动作.对于多智能体来说,当智能体的策略不断变化时,经验回放技术也不再适用,这给MADRL带来了很大的挑战.Palmer G等人[55]提出了宽松DQN(lenient DQN)算法来解决环境非静态问题,以宽松条件来决定经验池中的采样数据,不满足条件的经验数据将被忽略.Jin Y等人[57]提出了对其他智能体的动作进行估计的方法来解决环境非稳态问题,在评估Q函数时加入对其他智能体动作的估计,减弱环境非静态带来的影响.Liu X等人[58]对邻近智能体的关系进行建模,提出了注意力关系型编码器来聚合任意数量邻近智能体的特征,并采用参数共享[59]的方式来减少参数的更新量,使算法可扩展到大规模智能体的训练. ...
Stabilising experience replay for deep multi-agent reinforcement learning
1
2017
... 几类DRL的应用领域及研究意义
| 应用领域 | 分类方式 | 参考文献 | 研究意义 |
| 视频游戏 | Atari 2600 | [5,14-17,24] | 将DRL应用在多种游戏环境中,提升DRL算法的通用性 |
| ViZDoom、StarCraftII等 | [25-34] | 将DRL应用到复杂的游戏场景中,提升智能体的决策能力 |
| 导航 | 迷宫导航 | [35-40] | 根据应用场景设计迷宫环境,采用DRL处理特定的导航问题 |
| 室内导航 | [41-45] | 采用 DRL 算法训练智能体在室内环境进行导航,并尝试将虚拟环境中训练好的智能体应用到现实环境中 |
| 街景导航 | [46-49] | 采用DRL处理城市与城市之间的长距离导航,并提升DRL算法的泛化能力 |
| 多智能体协作 | 独立学习者协作 | [50-53,54,55,56,57-59] | 协作智能体在训练时使用独立DRL的方式,方便进行数量上的扩展 |
| 集中式评价器协作 | [60-64] | 协作智能体在训练时通过集中式的评价器获取其他智能体的信息,解决环境非静态问题 |
| 通信协作 | [65-69] | 利用 DRL 处理多智能体之间可以通信的情况,并采用通信促进智能体之间的协作 |
| 推荐系统 | 推荐算法 | [70-73] | 利用 DRL 进行推荐可以实时地对推荐策略进行调整,从而满足用户的动态偏好,并且推荐算法能够得到长期的回报 |
图5展示了几个典型的Atari 2600游戏环境,它们是很多DRL算法的测试环境.Atari 2600包含57款游戏,可以用来模拟真实环境中遇到的情况,且游戏环境具有多样性.DQN较早应用于Atari 2600的算法[5],它在22款游戏中取得了人类玩家的平均水平.之后,DQN 的各种改进版本(如 DDQN[14]、优先经验回放的DQN[15]、Dueling DQN[16],以及分布式DQN[17])分别在Atari 2600游戏中取得了不同程度的提升.然而,很难有一种算法能够在所有Atari 2600 游戏中都达到人类的水平,这主要有两个原因:一个是长期的信度分配,另一个是探索困境.信度分配在DRL中用来解决动作-奖励值分配的问题,DRL中存在奖励延时,因此很难将奖励值分配到具体的行动中,而且游戏运行时间越长,信度分配问题就越难解决.探索困境是指当环境状态的维数很大并且奖励值的设置比较稀疏时,智能体需要很多探索行为才能得到积极的反馈,导致算法很难收敛.为了解决这些问题,Badia A P等人[24]提出了Agent57算法,并成功地在所有Atari 2600游戏中超越了人类平均水平.针对长期的信度分配问题,Agent57 算法动态地对折扣因子进行调整,权衡未来奖励对当前状态-动作的重要性.同时Agent57 算法加入内部奖励值来解决探索困境,内部奖励值的大小由未探索过状态的新奇程度来决定.Agent57 算法采用两种内部的奖励值:一种是在一个学习周期(episode)内根据新奇的状态得到的奖励值;另一种是长期的,在学习周期之间根据状态的新奇程度得到的奖励值.最后的内部奖励值由这两部分组成.通过这些方法,Agent57算法成功地在所有Atari 2600游戏中超越人类玩家的平均水平,提高了DRL算法的通用性. ...
Lenient multi-agent deep reinforcement learning
1
2018
... 独立学习者是指智能体在更新自身的策略时,把其他智能体作为环境的一部分,每个智能体采用独立更新的方式,不考虑其他智能体的状态和动作.若采用这种更新方式,每个智能体在训练时比较简单,方便智能体进行数量上的扩展.但其他智能体的策略在不断更新,因此智能体所处的环境是不断变化的,这导致智能体不满足 MDP 条件,即MADRL面临环境非静态问题.Omidshafiei S等人[52]提出使用滞回强化学习[53]的方法来解决环境非静态问题,通过对不同的TD误差采用不同大小的学习率,减弱环境变化对Q值的影响,并采用一种并行经验回放的方式,保证多个智能体在使用经验回放时能够得到最优的联合动作.对于多智能体来说,当智能体的策略不断变化时,经验回放技术也不再适用,这给MADRL带来了很大的挑战.Palmer G等人[55]提出了宽松DQN(lenient DQN)算法来解决环境非静态问题,以宽松条件来决定经验池中的采样数据,不满足条件的经验数据将被忽略.Jin Y等人[57]提出了对其他智能体的动作进行估计的方法来解决环境非稳态问题,在评估Q函数时加入对其他智能体动作的估计,减弱环境非静态带来的影响.Liu X等人[58]对邻近智能体的关系进行建模,提出了注意力关系型编码器来聚合任意数量邻近智能体的特征,并采用参数共享[59]的方式来减少参数的更新量,使算法可扩展到大规模智能体的训练. ...
Learning against non-stationary agents with opponent modelling and deep reinforcement learning
1
2018
... 几类DRL的应用领域及研究意义
| 应用领域 | 分类方式 | 参考文献 | 研究意义 |
| 视频游戏 | Atari 2600 | [5,14-17,24] | 将DRL应用在多种游戏环境中,提升DRL算法的通用性 |
| ViZDoom、StarCraftII等 | [25-34] | 将DRL应用到复杂的游戏场景中,提升智能体的决策能力 |
| 导航 | 迷宫导航 | [35-40] | 根据应用场景设计迷宫环境,采用DRL处理特定的导航问题 |
| 室内导航 | [41-45] | 采用 DRL 算法训练智能体在室内环境进行导航,并尝试将虚拟环境中训练好的智能体应用到现实环境中 |
| 街景导航 | [46-49] | 采用DRL处理城市与城市之间的长距离导航,并提升DRL算法的泛化能力 |
| 多智能体协作 | 独立学习者协作 | [50-53,54,55,56,57-59] | 协作智能体在训练时使用独立DRL的方式,方便进行数量上的扩展 |
| 集中式评价器协作 | [60-64] | 协作智能体在训练时通过集中式的评价器获取其他智能体的信息,解决环境非静态问题 |
| 通信协作 | [65-69] | 利用 DRL 处理多智能体之间可以通信的情况,并采用通信促进智能体之间的协作 |
| 推荐系统 | 推荐算法 | [70-73] | 利用 DRL 进行推荐可以实时地对推荐策略进行调整,从而满足用户的动态偏好,并且推荐算法能够得到长期的回报 |
图5展示了几个典型的Atari 2600游戏环境,它们是很多DRL算法的测试环境.Atari 2600包含57款游戏,可以用来模拟真实环境中遇到的情况,且游戏环境具有多样性.DQN较早应用于Atari 2600的算法[5],它在22款游戏中取得了人类玩家的平均水平.之后,DQN 的各种改进版本(如 DDQN[14]、优先经验回放的DQN[15]、Dueling DQN[16],以及分布式DQN[17])分别在Atari 2600游戏中取得了不同程度的提升.然而,很难有一种算法能够在所有Atari 2600 游戏中都达到人类的水平,这主要有两个原因:一个是长期的信度分配,另一个是探索困境.信度分配在DRL中用来解决动作-奖励值分配的问题,DRL中存在奖励延时,因此很难将奖励值分配到具体的行动中,而且游戏运行时间越长,信度分配问题就越难解决.探索困境是指当环境状态的维数很大并且奖励值的设置比较稀疏时,智能体需要很多探索行为才能得到积极的反馈,导致算法很难收敛.为了解决这些问题,Badia A P等人[24]提出了Agent57算法,并成功地在所有Atari 2600游戏中超越了人类平均水平.针对长期的信度分配问题,Agent57 算法动态地对折扣因子进行调整,权衡未来奖励对当前状态-动作的重要性.同时Agent57 算法加入内部奖励值来解决探索困境,内部奖励值的大小由未探索过状态的新奇程度来决定.Agent57 算法采用两种内部的奖励值:一种是在一个学习周期(episode)内根据新奇的状态得到的奖励值;另一种是长期的,在学习周期之间根据状态的新奇程度得到的奖励值.最后的内部奖励值由这两部分组成.通过这些方法,Agent57算法成功地在所有Atari 2600游戏中超越人类玩家的平均水平,提高了DRL算法的通用性. ...
Stabilizing multi-agent deep reinforcement learning by implicitly estimating other agents’ behaviors
1
2020
... 独立学习者是指智能体在更新自身的策略时,把其他智能体作为环境的一部分,每个智能体采用独立更新的方式,不考虑其他智能体的状态和动作.若采用这种更新方式,每个智能体在训练时比较简单,方便智能体进行数量上的扩展.但其他智能体的策略在不断更新,因此智能体所处的环境是不断变化的,这导致智能体不满足 MDP 条件,即MADRL面临环境非静态问题.Omidshafiei S等人[52]提出使用滞回强化学习[53]的方法来解决环境非静态问题,通过对不同的TD误差采用不同大小的学习率,减弱环境变化对Q值的影响,并采用一种并行经验回放的方式,保证多个智能体在使用经验回放时能够得到最优的联合动作.对于多智能体来说,当智能体的策略不断变化时,经验回放技术也不再适用,这给MADRL带来了很大的挑战.Palmer G等人[55]提出了宽松DQN(lenient DQN)算法来解决环境非静态问题,以宽松条件来决定经验池中的采样数据,不满足条件的经验数据将被忽略.Jin Y等人[57]提出了对其他智能体的动作进行估计的方法来解决环境非稳态问题,在评估Q函数时加入对其他智能体动作的估计,减弱环境非静态带来的影响.Liu X等人[58]对邻近智能体的关系进行建模,提出了注意力关系型编码器来聚合任意数量邻近智能体的特征,并采用参数共享[59]的方式来减少参数的更新量,使算法可扩展到大规模智能体的训练. ...
Attentive relational state representation in decentralized multiagent reinforcement learning
1
2020
... 独立学习者是指智能体在更新自身的策略时,把其他智能体作为环境的一部分,每个智能体采用独立更新的方式,不考虑其他智能体的状态和动作.若采用这种更新方式,每个智能体在训练时比较简单,方便智能体进行数量上的扩展.但其他智能体的策略在不断更新,因此智能体所处的环境是不断变化的,这导致智能体不满足 MDP 条件,即MADRL面临环境非静态问题.Omidshafiei S等人[52]提出使用滞回强化学习[53]的方法来解决环境非静态问题,通过对不同的TD误差采用不同大小的学习率,减弱环境变化对Q值的影响,并采用一种并行经验回放的方式,保证多个智能体在使用经验回放时能够得到最优的联合动作.对于多智能体来说,当智能体的策略不断变化时,经验回放技术也不再适用,这给MADRL带来了很大的挑战.Palmer G等人[55]提出了宽松DQN(lenient DQN)算法来解决环境非静态问题,以宽松条件来决定经验池中的采样数据,不满足条件的经验数据将被忽略.Jin Y等人[57]提出了对其他智能体的动作进行估计的方法来解决环境非稳态问题,在评估Q函数时加入对其他智能体动作的估计,减弱环境非静态带来的影响.Liu X等人[58]对邻近智能体的关系进行建模,提出了注意力关系型编码器来聚合任意数量邻近智能体的特征,并采用参数共享[59]的方式来减少参数的更新量,使算法可扩展到大规模智能体的训练. ...
Cooperative multi-agent control using deep reinforcement learning
1
2017
... 独立学习者是指智能体在更新自身的策略时,把其他智能体作为环境的一部分,每个智能体采用独立更新的方式,不考虑其他智能体的状态和动作.若采用这种更新方式,每个智能体在训练时比较简单,方便智能体进行数量上的扩展.但其他智能体的策略在不断更新,因此智能体所处的环境是不断变化的,这导致智能体不满足 MDP 条件,即MADRL面临环境非静态问题.Omidshafiei S等人[52]提出使用滞回强化学习[53]的方法来解决环境非静态问题,通过对不同的TD误差采用不同大小的学习率,减弱环境变化对Q值的影响,并采用一种并行经验回放的方式,保证多个智能体在使用经验回放时能够得到最优的联合动作.对于多智能体来说,当智能体的策略不断变化时,经验回放技术也不再适用,这给MADRL带来了很大的挑战.Palmer G等人[55]提出了宽松DQN(lenient DQN)算法来解决环境非静态问题,以宽松条件来决定经验池中的采样数据,不满足条件的经验数据将被忽略.Jin Y等人[57]提出了对其他智能体的动作进行估计的方法来解决环境非稳态问题,在评估Q函数时加入对其他智能体动作的估计,减弱环境非静态带来的影响.Liu X等人[58]对邻近智能体的关系进行建模,提出了注意力关系型编码器来聚合任意数量邻近智能体的特征,并采用参数共享[59]的方式来减少参数的更新量,使算法可扩展到大规模智能体的训练. ...
Multi-agent actor-critic for mixed cooperative-competitive environments
1
2017
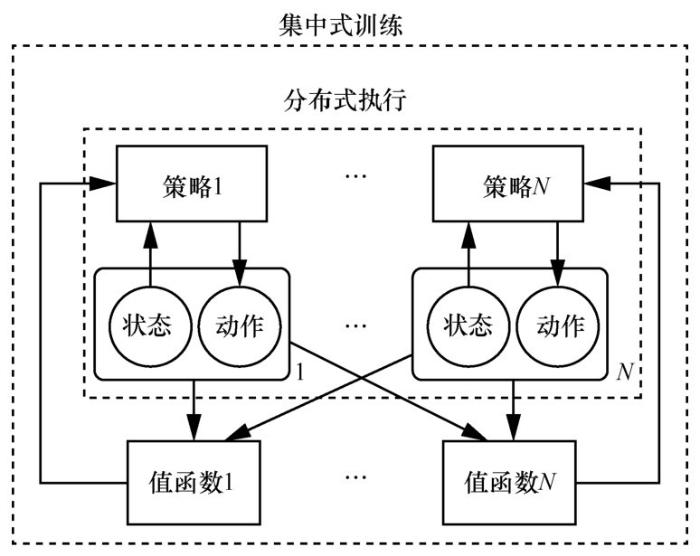
... Lowe R 等人[60]采用集中式训练、分布式执行的训练机制,提出了多智能体深度确定性策略梯度(multi-agent deep deterministic policy gradient, MADDPG)算法,结构如图7所示.该机制采用集中式评价器,假设智能体的评价器在训练时能够得到其他所有智能体的状态和动作信息,这样即使其他智能体的策略发生变化,环境也是稳定的.而执行器只能得到环境的局部信息来执行动作,训练结束后,算法只采用独立的执行器进行分布式执行.这种机制能够很好地解决环境非静态问题,利用了AC 结构的优势,方便智能体的训练和执行.Foerster J等人[61]提出了COMA策略梯度算法,采用集中式训练、分散式执行的机制,使得每个智能体在协作过程中都能收到对应于自身行动的奖励值,同时提高所有智能体共同的奖励值.Sunehag P等人[62]将所有智能体的联合Q网络分解为每个智能体单独的Q网络,提出VDN算法.Mao H等人[63]提出了基于注意力机制的MADDPG算法,对其他智能体的策略进行自适应建模,以促进多智能体之间的协作,同时引入注意力机制来提升智能体建模的效率.Iqbal S等人[64]在集中式评判器中采用自我注意力机制,使每个智能体都对其他智能体的观测和动作信息进行不同程度的关注,有效提升了算法的效率,并且可以扩展到大规模智能体的情况,同时引入了 SAC 算法来避免收敛到次优的策略,采用 COMA 算法思想解决多智能体信度分配的问题. ...
Counterfactual multi-agent policy gradients
1
2018
... Lowe R 等人[60]采用集中式训练、分布式执行的训练机制,提出了多智能体深度确定性策略梯度(multi-agent deep deterministic policy gradient, MADDPG)算法,结构如图7所示.该机制采用集中式评价器,假设智能体的评价器在训练时能够得到其他所有智能体的状态和动作信息,这样即使其他智能体的策略发生变化,环境也是稳定的.而执行器只能得到环境的局部信息来执行动作,训练结束后,算法只采用独立的执行器进行分布式执行.这种机制能够很好地解决环境非静态问题,利用了AC 结构的优势,方便智能体的训练和执行.Foerster J等人[61]提出了COMA策略梯度算法,采用集中式训练、分散式执行的机制,使得每个智能体在协作过程中都能收到对应于自身行动的奖励值,同时提高所有智能体共同的奖励值.Sunehag P等人[62]将所有智能体的联合Q网络分解为每个智能体单独的Q网络,提出VDN算法.Mao H等人[63]提出了基于注意力机制的MADDPG算法,对其他智能体的策略进行自适应建模,以促进多智能体之间的协作,同时引入注意力机制来提升智能体建模的效率.Iqbal S等人[64]在集中式评判器中采用自我注意力机制,使每个智能体都对其他智能体的观测和动作信息进行不同程度的关注,有效提升了算法的效率,并且可以扩展到大规模智能体的情况,同时引入了 SAC 算法来避免收敛到次优的策略,采用 COMA 算法思想解决多智能体信度分配的问题. ...
Value-decomposition networks for cooperative multi-agent learning
1
2011
... Lowe R 等人[60]采用集中式训练、分布式执行的训练机制,提出了多智能体深度确定性策略梯度(multi-agent deep deterministic policy gradient, MADDPG)算法,结构如图7所示.该机制采用集中式评价器,假设智能体的评价器在训练时能够得到其他所有智能体的状态和动作信息,这样即使其他智能体的策略发生变化,环境也是稳定的.而执行器只能得到环境的局部信息来执行动作,训练结束后,算法只采用独立的执行器进行分布式执行.这种机制能够很好地解决环境非静态问题,利用了AC 结构的优势,方便智能体的训练和执行.Foerster J等人[61]提出了COMA策略梯度算法,采用集中式训练、分散式执行的机制,使得每个智能体在协作过程中都能收到对应于自身行动的奖励值,同时提高所有智能体共同的奖励值.Sunehag P等人[62]将所有智能体的联合Q网络分解为每个智能体单独的Q网络,提出VDN算法.Mao H等人[63]提出了基于注意力机制的MADDPG算法,对其他智能体的策略进行自适应建模,以促进多智能体之间的协作,同时引入注意力机制来提升智能体建模的效率.Iqbal S等人[64]在集中式评判器中采用自我注意力机制,使每个智能体都对其他智能体的观测和动作信息进行不同程度的关注,有效提升了算法的效率,并且可以扩展到大规模智能体的情况,同时引入了 SAC 算法来避免收敛到次优的策略,采用 COMA 算法思想解决多智能体信度分配的问题. ...
Modelling the dynamic joint policy of teammates with attention multi-agent DDPG
1
2019
... Lowe R 等人[60]采用集中式训练、分布式执行的训练机制,提出了多智能体深度确定性策略梯度(multi-agent deep deterministic policy gradient, MADDPG)算法,结构如图7所示.该机制采用集中式评价器,假设智能体的评价器在训练时能够得到其他所有智能体的状态和动作信息,这样即使其他智能体的策略发生变化,环境也是稳定的.而执行器只能得到环境的局部信息来执行动作,训练结束后,算法只采用独立的执行器进行分布式执行.这种机制能够很好地解决环境非静态问题,利用了AC 结构的优势,方便智能体的训练和执行.Foerster J等人[61]提出了COMA策略梯度算法,采用集中式训练、分散式执行的机制,使得每个智能体在协作过程中都能收到对应于自身行动的奖励值,同时提高所有智能体共同的奖励值.Sunehag P等人[62]将所有智能体的联合Q网络分解为每个智能体单独的Q网络,提出VDN算法.Mao H等人[63]提出了基于注意力机制的MADDPG算法,对其他智能体的策略进行自适应建模,以促进多智能体之间的协作,同时引入注意力机制来提升智能体建模的效率.Iqbal S等人[64]在集中式评判器中采用自我注意力机制,使每个智能体都对其他智能体的观测和动作信息进行不同程度的关注,有效提升了算法的效率,并且可以扩展到大规模智能体的情况,同时引入了 SAC 算法来避免收敛到次优的策略,采用 COMA 算法思想解决多智能体信度分配的问题. ...
Actor-attention-critic for multi-agent reinforcement learning
1
2019
... Lowe R 等人[60]采用集中式训练、分布式执行的训练机制,提出了多智能体深度确定性策略梯度(multi-agent deep deterministic policy gradient, MADDPG)算法,结构如图7所示.该机制采用集中式评价器,假设智能体的评价器在训练时能够得到其他所有智能体的状态和动作信息,这样即使其他智能体的策略发生变化,环境也是稳定的.而执行器只能得到环境的局部信息来执行动作,训练结束后,算法只采用独立的执行器进行分布式执行.这种机制能够很好地解决环境非静态问题,利用了AC 结构的优势,方便智能体的训练和执行.Foerster J等人[61]提出了COMA策略梯度算法,采用集中式训练、分散式执行的机制,使得每个智能体在协作过程中都能收到对应于自身行动的奖励值,同时提高所有智能体共同的奖励值.Sunehag P等人[62]将所有智能体的联合Q网络分解为每个智能体单独的Q网络,提出VDN算法.Mao H等人[63]提出了基于注意力机制的MADDPG算法,对其他智能体的策略进行自适应建模,以促进多智能体之间的协作,同时引入注意力机制来提升智能体建模的效率.Iqbal S等人[64]在集中式评判器中采用自我注意力机制,使每个智能体都对其他智能体的观测和动作信息进行不同程度的关注,有效提升了算法的效率,并且可以扩展到大规模智能体的情况,同时引入了 SAC 算法来避免收敛到次优的策略,采用 COMA 算法思想解决多智能体信度分配的问题. ...
Learning to communicate with deep multi-agent reinforcement learning
1
2016
... 多智能体通信一方面可以促进智能体之间的协作,另一方面,训练时智能体能够得到其他智能体的信息,从而缓解环境非静态问题.Foerster J N等人[65]使用通信来促进智能体之间的协作,并提出了RIAL和DIAL两种通信方法.RIAL的Q网络中不仅要输出环境动作,还要输出通信动作到其他智能体的Q网络中.DIAL利用集中式学习的优势,直接在两个智能体的 Q 网络之间建立一个可微信道,促进智能体之间的双向交流.Sukhbaatar S 等人[66]提出了一种通信神经网络模型 CommNet,使得多智能体在协作的过程中能够连续通信.Jiang J等人[67]提出了注意力通信模型ATOC,通过注意力单元来选取智能体的通信对象,采用双向长短期记忆(long short term memory,LSTM)单元来收集通信智能体的信息,进而选取动作.Kim D 等人[68]考虑更实际的多智能体通信,即带宽有限以及智能体共享通信介质的情况,提出了SchedNet结构,采用基于权重调度的方法和调度向量来确定需要通信的智能体,解决通信资源有限以及智能体竞争通信的问题.Das A等人[69]提出了一种目标通信结构TarMAC,采用自注意力机制来计算智能体与其他智能体的通信权重,并根据权重来整合其他智能体的通信信息. ...
Learning multiagent communication with back propagation
1
2016
... 多智能体通信一方面可以促进智能体之间的协作,另一方面,训练时智能体能够得到其他智能体的信息,从而缓解环境非静态问题.Foerster J N等人[65]使用通信来促进智能体之间的协作,并提出了RIAL和DIAL两种通信方法.RIAL的Q网络中不仅要输出环境动作,还要输出通信动作到其他智能体的Q网络中.DIAL利用集中式学习的优势,直接在两个智能体的 Q 网络之间建立一个可微信道,促进智能体之间的双向交流.Sukhbaatar S 等人[66]提出了一种通信神经网络模型 CommNet,使得多智能体在协作的过程中能够连续通信.Jiang J等人[67]提出了注意力通信模型ATOC,通过注意力单元来选取智能体的通信对象,采用双向长短期记忆(long short term memory,LSTM)单元来收集通信智能体的信息,进而选取动作.Kim D 等人[68]考虑更实际的多智能体通信,即带宽有限以及智能体共享通信介质的情况,提出了SchedNet结构,采用基于权重调度的方法和调度向量来确定需要通信的智能体,解决通信资源有限以及智能体竞争通信的问题.Das A等人[69]提出了一种目标通信结构TarMAC,采用自注意力机制来计算智能体与其他智能体的通信权重,并根据权重来整合其他智能体的通信信息. ...
Learning attentional communication for multi-agent cooperation
1
2018
... 多智能体通信一方面可以促进智能体之间的协作,另一方面,训练时智能体能够得到其他智能体的信息,从而缓解环境非静态问题.Foerster J N等人[65]使用通信来促进智能体之间的协作,并提出了RIAL和DIAL两种通信方法.RIAL的Q网络中不仅要输出环境动作,还要输出通信动作到其他智能体的Q网络中.DIAL利用集中式学习的优势,直接在两个智能体的 Q 网络之间建立一个可微信道,促进智能体之间的双向交流.Sukhbaatar S 等人[66]提出了一种通信神经网络模型 CommNet,使得多智能体在协作的过程中能够连续通信.Jiang J等人[67]提出了注意力通信模型ATOC,通过注意力单元来选取智能体的通信对象,采用双向长短期记忆(long short term memory,LSTM)单元来收集通信智能体的信息,进而选取动作.Kim D 等人[68]考虑更实际的多智能体通信,即带宽有限以及智能体共享通信介质的情况,提出了SchedNet结构,采用基于权重调度的方法和调度向量来确定需要通信的智能体,解决通信资源有限以及智能体竞争通信的问题.Das A等人[69]提出了一种目标通信结构TarMAC,采用自注意力机制来计算智能体与其他智能体的通信权重,并根据权重来整合其他智能体的通信信息. ...
Learning to schedule communication in multi-agent reinforcement learning
1
2019
... 多智能体通信一方面可以促进智能体之间的协作,另一方面,训练时智能体能够得到其他智能体的信息,从而缓解环境非静态问题.Foerster J N等人[65]使用通信来促进智能体之间的协作,并提出了RIAL和DIAL两种通信方法.RIAL的Q网络中不仅要输出环境动作,还要输出通信动作到其他智能体的Q网络中.DIAL利用集中式学习的优势,直接在两个智能体的 Q 网络之间建立一个可微信道,促进智能体之间的双向交流.Sukhbaatar S 等人[66]提出了一种通信神经网络模型 CommNet,使得多智能体在协作的过程中能够连续通信.Jiang J等人[67]提出了注意力通信模型ATOC,通过注意力单元来选取智能体的通信对象,采用双向长短期记忆(long short term memory,LSTM)单元来收集通信智能体的信息,进而选取动作.Kim D 等人[68]考虑更实际的多智能体通信,即带宽有限以及智能体共享通信介质的情况,提出了SchedNet结构,采用基于权重调度的方法和调度向量来确定需要通信的智能体,解决通信资源有限以及智能体竞争通信的问题.Das A等人[69]提出了一种目标通信结构TarMAC,采用自注意力机制来计算智能体与其他智能体的通信权重,并根据权重来整合其他智能体的通信信息. ...
TarMAC:targeted multi-agent communication
1
2019
... 多智能体通信一方面可以促进智能体之间的协作,另一方面,训练时智能体能够得到其他智能体的信息,从而缓解环境非静态问题.Foerster J N等人[65]使用通信来促进智能体之间的协作,并提出了RIAL和DIAL两种通信方法.RIAL的Q网络中不仅要输出环境动作,还要输出通信动作到其他智能体的Q网络中.DIAL利用集中式学习的优势,直接在两个智能体的 Q 网络之间建立一个可微信道,促进智能体之间的双向交流.Sukhbaatar S 等人[66]提出了一种通信神经网络模型 CommNet,使得多智能体在协作的过程中能够连续通信.Jiang J等人[67]提出了注意力通信模型ATOC,通过注意力单元来选取智能体的通信对象,采用双向长短期记忆(long short term memory,LSTM)单元来收集通信智能体的信息,进而选取动作.Kim D 等人[68]考虑更实际的多智能体通信,即带宽有限以及智能体共享通信介质的情况,提出了SchedNet结构,采用基于权重调度的方法和调度向量来确定需要通信的智能体,解决通信资源有限以及智能体竞争通信的问题.Das A等人[69]提出了一种目标通信结构TarMAC,采用自注意力机制来计算智能体与其他智能体的通信权重,并根据权重来整合其他智能体的通信信息. ...
An MDP-based recommender system
1
2005
... 现有的大多数方法把推荐过程考虑为一个静态过程,按照贪婪策略进行推荐,这些方法无法捕捉到用户的动态偏好;另外,传统方法主要考虑最大化短期贡献,忽略了推荐对象在长期回报中的贡献[70].DRL可以很好地应对这些挑战,首先,DRL可以使用推荐系统与用户实时交互的反馈对推荐策略进行调整,直到最后收敛到一个满足用户动态偏好的最优策略;其次,DRL的目标是最大化累积的长期奖励,因此利用 DRL 训练出的推荐系统可以在用户推荐中得到长期的回报[71].例如,Zhao X等人[72]采用一种基于 AC 结构的 DRL 方法,执行器根据用户的偏好生成推荐页面,评价器对生成的推荐页面进行评估,并且执行器根据评估的结果对推荐策略进行改进.Zheng G 等人[73]提出了一种DRL算法,用于新闻推荐,不仅考虑了新闻推荐中存在的适应性和长期性问题,而且在用户反馈中加入了用户的积极性,即用户多久会返回到推荐服务中,此外还提出了一种改进的探索方式来解决现有推荐方法中存在的推荐相似新闻倾向的问题. ...
Deep reinforcement learning for search,recommendation,and online advertising:a survey
1
2019
... 现有的大多数方法把推荐过程考虑为一个静态过程,按照贪婪策略进行推荐,这些方法无法捕捉到用户的动态偏好;另外,传统方法主要考虑最大化短期贡献,忽略了推荐对象在长期回报中的贡献[70].DRL可以很好地应对这些挑战,首先,DRL可以使用推荐系统与用户实时交互的反馈对推荐策略进行调整,直到最后收敛到一个满足用户动态偏好的最优策略;其次,DRL的目标是最大化累积的长期奖励,因此利用 DRL 训练出的推荐系统可以在用户推荐中得到长期的回报[71].例如,Zhao X等人[72]采用一种基于 AC 结构的 DRL 方法,执行器根据用户的偏好生成推荐页面,评价器对生成的推荐页面进行评估,并且执行器根据评估的结果对推荐策略进行改进.Zheng G 等人[73]提出了一种DRL算法,用于新闻推荐,不仅考虑了新闻推荐中存在的适应性和长期性问题,而且在用户反馈中加入了用户的积极性,即用户多久会返回到推荐服务中,此外还提出了一种改进的探索方式来解决现有推荐方法中存在的推荐相似新闻倾向的问题. ...
Deep reinforcement learning for page-wise recommendations
1
2018
... 现有的大多数方法把推荐过程考虑为一个静态过程,按照贪婪策略进行推荐,这些方法无法捕捉到用户的动态偏好;另外,传统方法主要考虑最大化短期贡献,忽略了推荐对象在长期回报中的贡献[70].DRL可以很好地应对这些挑战,首先,DRL可以使用推荐系统与用户实时交互的反馈对推荐策略进行调整,直到最后收敛到一个满足用户动态偏好的最优策略;其次,DRL的目标是最大化累积的长期奖励,因此利用 DRL 训练出的推荐系统可以在用户推荐中得到长期的回报[71].例如,Zhao X等人[72]采用一种基于 AC 结构的 DRL 方法,执行器根据用户的偏好生成推荐页面,评价器对生成的推荐页面进行评估,并且执行器根据评估的结果对推荐策略进行改进.Zheng G 等人[73]提出了一种DRL算法,用于新闻推荐,不仅考虑了新闻推荐中存在的适应性和长期性问题,而且在用户反馈中加入了用户的积极性,即用户多久会返回到推荐服务中,此外还提出了一种改进的探索方式来解决现有推荐方法中存在的推荐相似新闻倾向的问题. ...
DRN:a deep reinforcement learning framework for news recommendation
1
2018
... 现有的大多数方法把推荐过程考虑为一个静态过程,按照贪婪策略进行推荐,这些方法无法捕捉到用户的动态偏好;另外,传统方法主要考虑最大化短期贡献,忽略了推荐对象在长期回报中的贡献[70].DRL可以很好地应对这些挑战,首先,DRL可以使用推荐系统与用户实时交互的反馈对推荐策略进行调整,直到最后收敛到一个满足用户动态偏好的最优策略;其次,DRL的目标是最大化累积的长期奖励,因此利用 DRL 训练出的推荐系统可以在用户推荐中得到长期的回报[71].例如,Zhao X等人[72]采用一种基于 AC 结构的 DRL 方法,执行器根据用户的偏好生成推荐页面,评价器对生成的推荐页面进行评估,并且执行器根据评估的结果对推荐策略进行改进.Zheng G 等人[73]提出了一种DRL算法,用于新闻推荐,不仅考虑了新闻推荐中存在的适应性和长期性问题,而且在用户反馈中加入了用户的积极性,即用户多久会返回到推荐服务中,此外还提出了一种改进的探索方式来解决现有推荐方法中存在的推荐相似新闻倾向的问题. ...











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}