1 引言
随着我国经济、科技水平的不断提高,越来越多的人开始追求更加舒适的居住、工作环境。在影响环境舒适度的众多因素中,温度是非常重要的因素之一。相关研究[1 ] 表明,过高或过低的温度都会使人感到不舒适,降低人的工作效率。暖气设备是常见的室温调节装置。研究如何根据室内人员的需求通过暖气设备自动地调节室温,对于提升室内环境的舒适度具有非常重要的意义。
传统的通过暖气设备控制室温的方法包括比例-积分-微分控制[2 ] 、动态矩阵预测控制[3 ] 以及模糊控制[4 ] 等。在传统的控制方法中,室温的设定值通常是预先设定的固定值,控制器需要调节暖气设备,使得室温尽可能稳定在设定值附近。然而,相关研究[5 ] 表明,稳定的室温无法有效提升人的工作效率,甚至会降低人的工作效率。因此,本文抛弃了常规的固定室温设定值的控制思路,直接以消除人的困倦为控制目标,根据人的状态实时调整室温。本文设计了一种将人的表情作为输入的自学习控制器。这种自学习控制器能够根据人的表情自主学习到合适的控制策略,通过调整暖气设备的阀门开度控制室温,从而尽可能地消除室内人员的疲劳,提升室内人员的工作效率。
户外天气情况的变化和室内人员的自由活动使得房屋的热模型具有很强的不确定性。这导致在实际应用时基于模型的控制方法往往无法取得良好的效果。因此,许多研究者使用无模型的学习算法,尤其是强化学习方法[6 ] 来研究室温控制问题。在参考文献[7 ]中,Barrett E使用贝叶斯学习方法预测室内人员的活动情况,使用Q学习方法学习控制策略。Barrett E使用Bang-Bang控制方法控制加热设备,控制器的输入状态包括室温、时间和天气等。显然,由于传统强化学习算法的限制,控制器的输入状态只能是人们已经提取好的环境信息,无法直接从高维信息中自动学习到控制需要的特征。
近年来,深度学习取得了巨大进展[8 ] ,深度强化学习也得到了越来越多的关注[9 ] 。在参考文献[10 ]中,Wei T S采用深度Q网络方法学习控制策略,控制器的输入状态包括时间、室温以及室外环境的干扰。尽管参考文献[10 ]使用了深度神经网络,但是仍然使用人们已经提取好的环境特征作为控制器的输入,没有发挥深度神经网络自动提取特征的能力。在参考文献[11 ]中,Wei Q L等人使用深度Q网络方法,将人的表情和空调温度设定值作为控制器输入,通过控制空调设备调节室温。然而,参考文献[11 ]中的空调设备并不同于本文所要研究的暖气设备。第一,空调制热会造成室内空气干燥,降低人的舒适度;而暖气设备由下向上加热室内空气,使热空气分布更均匀,人感觉较舒适,因此暖气设备比空调更有利于提升人的舒适度。第二,空调通常具有自动调温功能,只需给定温度设定值,空调即可自动地将房间温度调整到设定值附近,完成闭环控制;而大多暖气设备并不具有自动调温功能,只能通过控制暖气设备的阀门开度控制暖气设备向房间中输入的热量,间接调节室温,进行开环控制。基于这两方面的不同,有必要研究基于深度强化学习的智能暖气控制方案。
本文以消除人的疲劳、提升人的工作效率为直接目标,将人的表情作为控制器的输入状态,使用双深度Q网络方法,通过暖气设备控制室温。接下来,本文将依次介绍总体方案设计、仿真环境与实验结果。
2 总体方案设计
本节将系统阐述以人的表情为输入状态,通过暖气设备自适应调整室温的总体方案。
本文的控制目标是根据人的状态实时调整室温,因此本文采用能够直接反映人的困意的人脸表情图像作为控制器的输入状态 x
控制器通过控制暖气设备的阀门开度调节室温。在本文中,设定暖气设备的阀门开度有9个档位,分别是全闭、1/8开度、1/4开度、3/8开度、半开、5/8开度、3/4开度、7/8开度和全开。控制器的可执行动作共有3种,分别是将阀门开大一个档位、将阀门关小一个档位和保持阀门开度不变。
为了减少控制器的计算负担,需要对控制器的输入状态x
控制器的原始输入状态是一幅图像,它在计算机中的存储形式是Q×P×3维的矩阵,参数Q和P取决于图像的分辨率。在人脸检测步骤中,首先将Q×P×3 维的原始输入图像x x g x g l ,yl )和右下角坐标(xr ,yr )。在截取人眼图像的步骤中,以人脸检测步骤中得到的(xl ,yl )和(xr ,yr )为参考文献[13 ]中的人脸关键点检测器的输入状态,从灰度图像x g re ,yre )和第46个坐标(xle ,yle )分别代表右眼的最右端和左眼的最左端。在(xre ,yre )上减去一个常数 M 得到( x ′ re , y ′ re ) le ,yle )上加上一个常数M得到( x ′ le , y ′ le ) ( x ′ re , y ′ re ) ( x ′ le , y ′ le ) 图1 所示。接下来,根据( x ′ re , y ′ re ) ( x ′ le , y ′ le ) x g x ˜
图1
本文最主要的控制目的是消除人的困意,因此对于困意的检测是至关重要的。研究表明,人的困意与人眼的平稳张开程度有着密切的关系,因此本文使用非眨眼状态下的眼睛张开程度来衡量人的困意。困意检测分为两步:第一步是检测人是否处于眨眼状态,第二步是检测非眨眼状态下眼睛的张开程度。这两个步骤都需要实时检测眼睛的张开程度。
在状态预处理过程的截取人眼图像步骤中,已经检测出了人脸的68个关键点。在这68个关键点中,左右眼各占 6 个。参考文献[14 ]使用眼睛纵横比(eye aspect ratio,EAR)的平均值衡量人眼的张开程度。受参考文献[14 ]启发,本文也使用眼睛纵横比来衡量眼睛的张开程度。但是考虑到眨眼检测的实时性要求以及双眼动作的同步性,本文仅使用右眼的纵横比来衡量眼睛的张开程度。右眼纵横比EARr 如式(1)所示:
EAR r = ‖ d 2 − d 6 ‖ + ‖ d 3 − d 5 ‖ 2 ‖ d 1 − d 4 ‖ ( 1 )
其中,d2 、d3 、d5 、d6 是分布在右眼上下边缘的关键点坐标,d1 、d4 是分布在右眼左右边缘的点坐标。从式(1)可以看出,EARr 等于右眼的纵向距离除以横向距离。当眼睛处于张开状态时,EARr 基本保持不变;当眼睛闭合时,EARr 接近0;当眨眼时, EARr 迅速变化。因此,本文实时检测人眼的EARr 值,通过判断EARr 是否快速变化判断人是否处于眨眼状态,将EARr 平稳时的值作为衡量人困意的依据。
奖励函数的作用是使控制器在与外部环境的交互中逐渐学习到正确的控制策略,告诉控制器哪些动作应当被鼓励。考虑到本文设计的控制器的主要目标是消除人的困意,设计奖励函数如式(2)所示:
r t = { − 1 , EAR t r ≤ EAR t − 1 r 10 , EAR t r = EAR max r 0 , 其 他 ( 2 )
其中,EAR t r EAR t − 1 r x t x t − 1 r 值。在t-1时刻,控制器的输入状态为x t − 1 t-1 后,得到下一个时刻的状态x t x t x t − 1 t 。奖励函数表达了这样的理念:当控制器的动作使人困意增大时,即EAR t r ≤ EAR t − 1 r EAR t r = EAR max r
前文主要介绍了状态预处理算法和奖励函数的设计。有了上面的铺垫后,接下来介绍用于控制暖气设备阀门开度的双深度Q网络算法。
首先,介绍使用近似 Q 函数的深度 Q 网络。为了衡量在状态x Q ( x ˜ , u ; θ ) Q ( x ˜ , u ; θ ) x ˜ x ˜ x ˜ x ˜ v v
其次,介绍双深度Q网络方法的经验回放机制和目标网络机制。在双深度Q网络方法中,笔者使用了经验回放机制打破样本之间的关联性,从而减小神经网络更新时的方差。经验回放机制为:在每一个时间步,控制器接收状态x t t ,得到奖励rt ,获得下一个状态x t + 1 ( x t , u t , r t , x t + 1 ) Q ( x ˜ , u ; θ ) Q ^ ( x ˜ , u ; θ − ) Q ^ ( x ˜ , u ; θ − ) - 周期性地更新,在两次更新的间隔,θ- 保持不变。
接下来,介绍双深度 Q 网络方法中 Q 网络目标值的计算方法。在深度 Q 网络方法中,计算 Q网络的目标值如式(3)所示:
Y t DQN ≡ r t + γ max u t + 1 Q ( x ˜ t + 1 , u t + 1 ; θ − ) ( 3 )
其中,γ是折扣因子。但是,式(3)中的max操作会造成Q函数的过估计,为了避免这种情况,双深度Q网络方法使用式(4)计算Q网络的目标值:
Y t DoubleDQN ≡ r t + γ Q ( x ˜ t + 1 , arg max u Q ( x ˜ t + 1 , u ; θ ) ; θ − ) ( 4 )
最后,介绍双深度Q网络方法的损失函数。在第i个训练回合,Q 网络中的参数为θi ,目标网络中的参数为θ i −
L i ( θ i ) = 1 2 [ r t + γ Q ( x ˜ t + 1 , arg max Q ( x ˜ t + 1 , u ; θ i ) u ; θ i − ) −
Q ( x ˜ t , u t ; θ i ) ] 2 ( 5 )
本文提出的以人的表情为输入状态,通过暖气设备自适应调整室温的方案与参考文献[11 ]中的方案主要有以下几点不同。
第一,被控对象不同。本文使用暖气设备调节室温,而参考文献[11 ]使用空调调节室温。使用空调制热会造成室内空气干燥,使人不舒服,从提升人的舒适度的角度来看,使用暖气制热比使用空调更合适。
第二,控制器施加给被控对象的动作不同。在参考文献[11 ]中,空调大多带有自动调温功能,因此,控制器可直接控制空调的温度设定值,空调与房间之间存在单独的控制回路,空调可以自动调节室温到设定值附近。而在本文中,大多暖气设备只有调节阀,控制器需要通过改变调节阀的开度调节室温,暖气设备与房间之间并不存在控制回路。
第三,状态预处理算法和Q网络的结构不同。在参考文献[11 ]中,空调温度设定值作为图像的一个通道与预处理后的图像合并,由深度神经网络自动提取特征。而在本文中,将阀门开度作为一个已经提取好的特征直接输入最末层的全连接网络,大大减小了计算量。
第四,计算眼睛纵横比的方式不同。在参考文献[11 ]中,分别计算左右眼纵横比,再取平均值得到衡量双眼纵横比的值。而在本文中,考虑到双眼运动的一致性以及眨眼检测的实时性,使用右眼的纵横比代替双眼纵横比,减小了计算量,更便于算法实时运行。
第五,在参考文献[11 ]中,使用深度Q网络方法学习最优策略,而在本文中,为了避免深度Q网络方法造成的动作价值过估计现象,使用双深度Q网络学习控制策略。实验表明,本文中的双深度Q网络方法比参考文献[11 ]中的方法收敛更快,更平稳。
3 仿真环境与实验结果
本节将介绍仿真环境的搭建以及仿真实验的结果。智能体在仿真环境中的工作流程如下:控制器实时检测人眼的运动情况,在t时刻,控制器采集到人非眨眼状态下的表情,并将其作为t时刻的状态x t x t x ˜ t x ˜ t
为了模拟房间中的温度变化,本文建立了一个简化的房屋热模型。由热力学定律可解得室温变化的微分方程:
τ i ( t ) = ρ r σ i + τ o + ( τ r ( 0 ) − ρ r σ i − τ o ) e − 1 ρ r μ r t ( 6 )
其中,τr 和τo 分别代表室内温度和室外温度,μr 和ρr 分别代表房间的热容和热阻,σi 代表房间的输入热量。由式(6)可以看出,稳态室温为τ ∞ = ρ r σ i + τ e ∞ 与暖气设备向房间输入的热量σi 呈线性关系,因此,可以认为房间稳态温度τ∞ 与暖气设备的阀门开度近似为线性关系。
为了模拟人的表情随温度的变化,需要建立一个温度-表情数据库,在这个数据库中,人脸的图片与温度一一对应,输入房间温度,就能得到一张人脸表情的图片。设定房间温度的取值范围是18 ℃到34 ℃之间的6个值。各个温度下的眼睛闭合程度见表1 。从表1 可以看出,当室内温度为26 ℃时, EARr 最大。
在实验中,每个回合开始时的初始温度将从18 ℃、20 ℃、32 ℃和34 ℃中随机选择。控制器将根据人的表情调整暖气设备的阀门开度。当房间温度被调整到最合适的温度时,人的困意最少,此时认为控制器已经达到目的,本回合结束,重新开始新的回合,房间温度将被重新初始化。
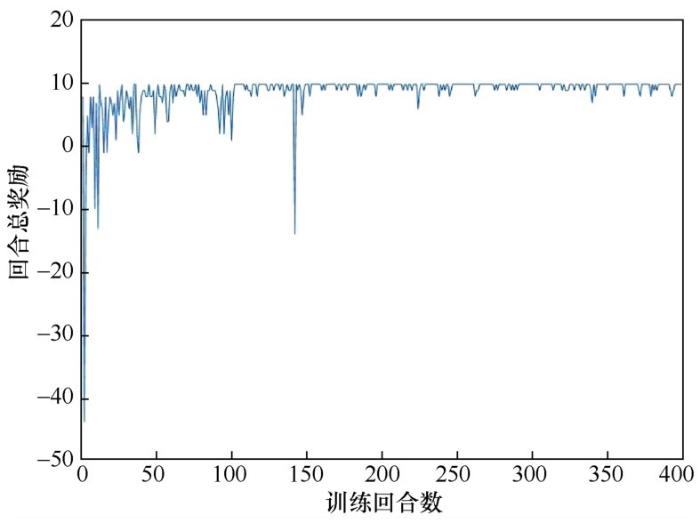
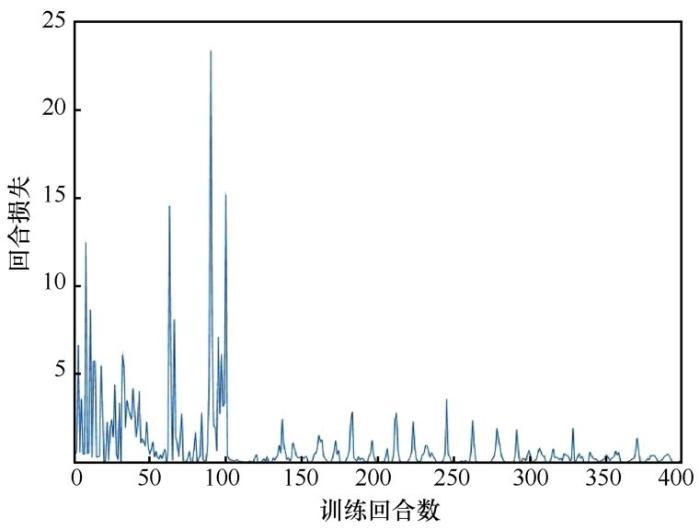
控制器训练过程中的回合总长度、回合总奖励、回合损失的变化分别如图2 、图3 、图4 所示。回合总长度代表调节暖气设备阀门开度的次数。从图2 可以看出,训练初期的回合总长度要明显长于训练末期。在训练末期,回合总长度会稳定在3或4。在训练末期,控制器仍对环境保持着一定的探索性,因此训练末期的回合总长度会在3和4附近有微小的波动。为了展示所提方法的有效性,将双深度Q网络方法与采取随机动作的方法进行对比,通过对比可以看出,双深度Q网络方法的回合总长度明显更小。回合总奖励表示智能体在这一回合中获得的奖励总数。随着训练的进行,智能体能够在每个状态下都做出正确的决定。因此在训练末期,回合总奖励稳定在10 附近。同样地,由于在训练末期,控制器仍保持一定的探索性,曲线在10 附近有轻微的波动。回合损失指损失函数在这一回合结束时的值。从图4 可以看出,随着训练的进行,回合损失逐渐接近于0。
图2
图3
图4
4 结束语
本文提出了一种基于深度强化学习方法,将人的表情作为输入状态,以消除人的困意为直接目标的自适应暖气设备调温系统。通过使用双深度Q网络方法,智能体能够直接从图像中学习到控制策略。仿真结果表明,智能体在充分学习后能够控制暖气设备自适应地将室温调整到最合适的温度。
在未来的工作中,笔者将使用预训练好的卷积神经网络作为Q网络的初值,从而避免从头训练Q网络,减小训练耗时。
The authors have declared that no competing interests exist.
作者已声明无竞争性利益关系。
参考文献
View Option
[1]
HEDGE A , GAYGEN D E . Indoor environment conditions and computer work in an office
[J]. HVAC&R Research , 2010 ,16 (2 ): 123 -138 .
[本文引用: 1]
[2]
施志荣 , 康玉文 . 基于模糊自适应PID的分布式室温监控系统设计
[J]. 齐鲁工业大学学报 , 2017 ,31 (1 ): 78 -80 .
[本文引用: 1]
SHI Z R , KANG Y W . A control system design of distributed room temperature:based on fuzzy adaptive PID
[J]. Journal of Qilu University of Technology , 2017 ,31 (1 ): 78 -80 .
[本文引用: 1]
[3]
高秀娟 . 集中供热系统室温控制策略研究
[D]. 杭州:浙江大学 , 2014 .
[本文引用: 1]
GAO X J . Research on room temperature control strategy for central heating system
[D]. Hangzhou:Zhejiang University , 2014 .
[本文引用: 1]
[4]
李冰皓 . 暖气热量智能控制系统设计及算法研究
[D]. 石家庄:河北科技大学 , 2015 .
[本文引用: 1]
LI B H . Intelligent control system design and algorithm study of heating calories
[D]. Shijiazhuang:Hebei University of Science and Technology , 2015 .
[本文引用: 1]
[5]
TSE W L , SO A T P . The importance of human productivity to air-conditioning control in office environments
[J]. HVAC&R Research , 2007 ,13 (1 ): 3 -21 .
[本文引用: 1]
[6]
王飞跃 , 曹东璞 , 魏庆来 . 强化学习:迈向知行合一的智能机制与算法
[J]. 智能科学与技术学报 , 2020 ,2 (2 ): 101 -106 .
[本文引用: 1]
WANG F Y , CAO D P , WEI Q L . Reinforcement learning:toward action-knowledge merged intelligent mechanisms and algorithms
[J]. Chinese Journal of Intelligent Science and Technology , 2020 ,2 (2 ): 101 -106 .
[本文引用: 1]
[7]
BARRETT E , LINDER S . Autonomous HVAC control,a reinforcement learning approach
[C]// Joint European Conference on Machine Learning and Knowledge Discovery in Databases . Cham:Springer , 2015 : 3 -19 .
[本文引用: 1]
[8]
张钹 . 人工智能进入后深度学习时代
[J]. 智能科学与技术学报 , 2019 ,1 (1 ): 4 -6 .
[本文引用: 1]
ZHANG B . Artificial intelligence is entering the post deep-learning era
[J]. Chinese Journal of Intelligent Science and Technology , 2019 ,1 (1 ): 4 -6 .
[本文引用: 1]
[9]
孙长银 , 穆朝絮 . 多智能体深度强化学习的若干关键科学问题
[J]. 自动化学报 , 2020 ,46 (7 ): 1301 -1312 .
[本文引用: 1]
SUN C Y , MU C X . Important scientific problems of multi-agent deep reinforcement learning
[J]. IEEE/CAA Journal of Automatica Sinica , 2020 ,46 (7 ): 1301 -1312 .
[本文引用: 1]
[10]
WEI T S , WANG Y Z , ZHU Q . Deep reinforcement learning for building HVAC control
[C]// Proceedings of the 54th Annual Design Automation Conference .[S.l.:s.n.], 2017 : 1 -6 .
[本文引用: 2]
[11]
WEI Q L , LI T , LIU D R . Learning control for air conditioning systems via human expressions
[J]. IEEE Transactions on Industrial Electronics , 2020 (99 ): 1 .
[本文引用: 9]
[12]
DALAL N , TRIGGS B . Histograms of oriented gradients for human detection
[C]// 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition . Piscataway:IEEE Press , 2005 ,1 : 886 -893 .
[13]
KAZEMI V , SULLIVAN J . One millisecond face alignment with an ensemble of regression trees
[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Piscataway:IEEE Press , 2014 : 1867 -1874 .
[本文引用: 1]
[14]
SOUKUPOVA T , CECH J . Eye blink detection using facial landmarks
[C]// The 21st Computer Vision Winter Workshop,Rimske Toplice,Slovenia .[S.l.:s.n.], 2016 .
[本文引用: 2]
Indoor environment conditions and computer work in an office
1
2010
... 随着我国经济、科技水平的不断提高,越来越多的人开始追求更加舒适的居住、工作环境.在影响环境舒适度的众多因素中,温度是非常重要的因素之一.相关研究[1 ] 表明,过高或过低的温度都会使人感到不舒适,降低人的工作效率.暖气设备是常见的室温调节装置.研究如何根据室内人员的需求通过暖气设备自动地调节室温,对于提升室内环境的舒适度具有非常重要的意义. ...
基于模糊自适应PID的分布式室温监控系统设计
1
2017
... 传统的通过暖气设备控制室温的方法包括比例-积分-微分控制[2 ] 、动态矩阵预测控制[3 ] 以及模糊控制[4 ] 等.在传统的控制方法中,室温的设定值通常是预先设定的固定值,控制器需要调节暖气设备,使得室温尽可能稳定在设定值附近.然而,相关研究[5 ] 表明,稳定的室温无法有效提升人的工作效率,甚至会降低人的工作效率.因此,本文抛弃了常规的固定室温设定值的控制思路,直接以消除人的困倦为控制目标,根据人的状态实时调整室温.本文设计了一种将人的表情作为输入的自学习控制器.这种自学习控制器能够根据人的表情自主学习到合适的控制策略,通过调整暖气设备的阀门开度控制室温,从而尽可能地消除室内人员的疲劳,提升室内人员的工作效率. ...
基于模糊自适应PID的分布式室温监控系统设计
1
2017
... 传统的通过暖气设备控制室温的方法包括比例-积分-微分控制[2 ] 、动态矩阵预测控制[3 ] 以及模糊控制[4 ] 等.在传统的控制方法中,室温的设定值通常是预先设定的固定值,控制器需要调节暖气设备,使得室温尽可能稳定在设定值附近.然而,相关研究[5 ] 表明,稳定的室温无法有效提升人的工作效率,甚至会降低人的工作效率.因此,本文抛弃了常规的固定室温设定值的控制思路,直接以消除人的困倦为控制目标,根据人的状态实时调整室温.本文设计了一种将人的表情作为输入的自学习控制器.这种自学习控制器能够根据人的表情自主学习到合适的控制策略,通过调整暖气设备的阀门开度控制室温,从而尽可能地消除室内人员的疲劳,提升室内人员的工作效率. ...
集中供热系统室温控制策略研究
1
2014
... 传统的通过暖气设备控制室温的方法包括比例-积分-微分控制[2 ] 、动态矩阵预测控制[3 ] 以及模糊控制[4 ] 等.在传统的控制方法中,室温的设定值通常是预先设定的固定值,控制器需要调节暖气设备,使得室温尽可能稳定在设定值附近.然而,相关研究[5 ] 表明,稳定的室温无法有效提升人的工作效率,甚至会降低人的工作效率.因此,本文抛弃了常规的固定室温设定值的控制思路,直接以消除人的困倦为控制目标,根据人的状态实时调整室温.本文设计了一种将人的表情作为输入的自学习控制器.这种自学习控制器能够根据人的表情自主学习到合适的控制策略,通过调整暖气设备的阀门开度控制室温,从而尽可能地消除室内人员的疲劳,提升室内人员的工作效率. ...
集中供热系统室温控制策略研究
1
2014
... 传统的通过暖气设备控制室温的方法包括比例-积分-微分控制[2 ] 、动态矩阵预测控制[3 ] 以及模糊控制[4 ] 等.在传统的控制方法中,室温的设定值通常是预先设定的固定值,控制器需要调节暖气设备,使得室温尽可能稳定在设定值附近.然而,相关研究[5 ] 表明,稳定的室温无法有效提升人的工作效率,甚至会降低人的工作效率.因此,本文抛弃了常规的固定室温设定值的控制思路,直接以消除人的困倦为控制目标,根据人的状态实时调整室温.本文设计了一种将人的表情作为输入的自学习控制器.这种自学习控制器能够根据人的表情自主学习到合适的控制策略,通过调整暖气设备的阀门开度控制室温,从而尽可能地消除室内人员的疲劳,提升室内人员的工作效率. ...
暖气热量智能控制系统设计及算法研究
1
2015
... 传统的通过暖气设备控制室温的方法包括比例-积分-微分控制[2 ] 、动态矩阵预测控制[3 ] 以及模糊控制[4 ] 等.在传统的控制方法中,室温的设定值通常是预先设定的固定值,控制器需要调节暖气设备,使得室温尽可能稳定在设定值附近.然而,相关研究[5 ] 表明,稳定的室温无法有效提升人的工作效率,甚至会降低人的工作效率.因此,本文抛弃了常规的固定室温设定值的控制思路,直接以消除人的困倦为控制目标,根据人的状态实时调整室温.本文设计了一种将人的表情作为输入的自学习控制器.这种自学习控制器能够根据人的表情自主学习到合适的控制策略,通过调整暖气设备的阀门开度控制室温,从而尽可能地消除室内人员的疲劳,提升室内人员的工作效率. ...
暖气热量智能控制系统设计及算法研究
1
2015
... 传统的通过暖气设备控制室温的方法包括比例-积分-微分控制[2 ] 、动态矩阵预测控制[3 ] 以及模糊控制[4 ] 等.在传统的控制方法中,室温的设定值通常是预先设定的固定值,控制器需要调节暖气设备,使得室温尽可能稳定在设定值附近.然而,相关研究[5 ] 表明,稳定的室温无法有效提升人的工作效率,甚至会降低人的工作效率.因此,本文抛弃了常规的固定室温设定值的控制思路,直接以消除人的困倦为控制目标,根据人的状态实时调整室温.本文设计了一种将人的表情作为输入的自学习控制器.这种自学习控制器能够根据人的表情自主学习到合适的控制策略,通过调整暖气设备的阀门开度控制室温,从而尽可能地消除室内人员的疲劳,提升室内人员的工作效率. ...
The importance of human productivity to air-conditioning control in office environments
1
2007
... 传统的通过暖气设备控制室温的方法包括比例-积分-微分控制[2 ] 、动态矩阵预测控制[3 ] 以及模糊控制[4 ] 等.在传统的控制方法中,室温的设定值通常是预先设定的固定值,控制器需要调节暖气设备,使得室温尽可能稳定在设定值附近.然而,相关研究[5 ] 表明,稳定的室温无法有效提升人的工作效率,甚至会降低人的工作效率.因此,本文抛弃了常规的固定室温设定值的控制思路,直接以消除人的困倦为控制目标,根据人的状态实时调整室温.本文设计了一种将人的表情作为输入的自学习控制器.这种自学习控制器能够根据人的表情自主学习到合适的控制策略,通过调整暖气设备的阀门开度控制室温,从而尽可能地消除室内人员的疲劳,提升室内人员的工作效率. ...
强化学习:迈向知行合一的智能机制与算法
1
2020
... 户外天气情况的变化和室内人员的自由活动使得房屋的热模型具有很强的不确定性.这导致在实际应用时基于模型的控制方法往往无法取得良好的效果.因此,许多研究者使用无模型的学习算法,尤其是强化学习方法[6 ] 来研究室温控制问题.在参考文献[7 ]中,Barrett E使用贝叶斯学习方法预测室内人员的活动情况,使用Q学习方法学习控制策略.Barrett E使用Bang-Bang控制方法控制加热设备,控制器的输入状态包括室温、时间和天气等.显然,由于传统强化学习算法的限制,控制器的输入状态只能是人们已经提取好的环境信息,无法直接从高维信息中自动学习到控制需要的特征. ...
强化学习:迈向知行合一的智能机制与算法
1
2020
... 户外天气情况的变化和室内人员的自由活动使得房屋的热模型具有很强的不确定性.这导致在实际应用时基于模型的控制方法往往无法取得良好的效果.因此,许多研究者使用无模型的学习算法,尤其是强化学习方法[6 ] 来研究室温控制问题.在参考文献[7 ]中,Barrett E使用贝叶斯学习方法预测室内人员的活动情况,使用Q学习方法学习控制策略.Barrett E使用Bang-Bang控制方法控制加热设备,控制器的输入状态包括室温、时间和天气等.显然,由于传统强化学习算法的限制,控制器的输入状态只能是人们已经提取好的环境信息,无法直接从高维信息中自动学习到控制需要的特征. ...
Autonomous HVAC control,a reinforcement learning approach
1
2015
... 户外天气情况的变化和室内人员的自由活动使得房屋的热模型具有很强的不确定性.这导致在实际应用时基于模型的控制方法往往无法取得良好的效果.因此,许多研究者使用无模型的学习算法,尤其是强化学习方法[6 ] 来研究室温控制问题.在参考文献[7 ]中,Barrett E使用贝叶斯学习方法预测室内人员的活动情况,使用Q学习方法学习控制策略.Barrett E使用Bang-Bang控制方法控制加热设备,控制器的输入状态包括室温、时间和天气等.显然,由于传统强化学习算法的限制,控制器的输入状态只能是人们已经提取好的环境信息,无法直接从高维信息中自动学习到控制需要的特征. ...
人工智能进入后深度学习时代
1
2019
... 近年来,深度学习取得了巨大进展[8 ] ,深度强化学习也得到了越来越多的关注[9 ] .在参考文献[10 ]中,Wei T S采用深度Q网络方法学习控制策略,控制器的输入状态包括时间、室温以及室外环境的干扰.尽管参考文献[10 ]使用了深度神经网络,但是仍然使用人们已经提取好的环境特征作为控制器的输入,没有发挥深度神经网络自动提取特征的能力.在参考文献[11 ]中,Wei Q L等人使用深度Q网络方法,将人的表情和空调温度设定值作为控制器输入,通过控制空调设备调节室温.然而,参考文献[11 ]中的空调设备并不同于本文所要研究的暖气设备.第一,空调制热会造成室内空气干燥,降低人的舒适度;而暖气设备由下向上加热室内空气,使热空气分布更均匀,人感觉较舒适,因此暖气设备比空调更有利于提升人的舒适度.第二,空调通常具有自动调温功能,只需给定温度设定值,空调即可自动地将房间温度调整到设定值附近,完成闭环控制;而大多暖气设备并不具有自动调温功能,只能通过控制暖气设备的阀门开度控制暖气设备向房间中输入的热量,间接调节室温,进行开环控制.基于这两方面的不同,有必要研究基于深度强化学习的智能暖气控制方案. ...
人工智能进入后深度学习时代
1
2019
... 近年来,深度学习取得了巨大进展[8 ] ,深度强化学习也得到了越来越多的关注[9 ] .在参考文献[10 ]中,Wei T S采用深度Q网络方法学习控制策略,控制器的输入状态包括时间、室温以及室外环境的干扰.尽管参考文献[10 ]使用了深度神经网络,但是仍然使用人们已经提取好的环境特征作为控制器的输入,没有发挥深度神经网络自动提取特征的能力.在参考文献[11 ]中,Wei Q L等人使用深度Q网络方法,将人的表情和空调温度设定值作为控制器输入,通过控制空调设备调节室温.然而,参考文献[11 ]中的空调设备并不同于本文所要研究的暖气设备.第一,空调制热会造成室内空气干燥,降低人的舒适度;而暖气设备由下向上加热室内空气,使热空气分布更均匀,人感觉较舒适,因此暖气设备比空调更有利于提升人的舒适度.第二,空调通常具有自动调温功能,只需给定温度设定值,空调即可自动地将房间温度调整到设定值附近,完成闭环控制;而大多暖气设备并不具有自动调温功能,只能通过控制暖气设备的阀门开度控制暖气设备向房间中输入的热量,间接调节室温,进行开环控制.基于这两方面的不同,有必要研究基于深度强化学习的智能暖气控制方案. ...
多智能体深度强化学习的若干关键科学问题
1
2020
... 近年来,深度学习取得了巨大进展[8 ] ,深度强化学习也得到了越来越多的关注[9 ] .在参考文献[10 ]中,Wei T S采用深度Q网络方法学习控制策略,控制器的输入状态包括时间、室温以及室外环境的干扰.尽管参考文献[10 ]使用了深度神经网络,但是仍然使用人们已经提取好的环境特征作为控制器的输入,没有发挥深度神经网络自动提取特征的能力.在参考文献[11 ]中,Wei Q L等人使用深度Q网络方法,将人的表情和空调温度设定值作为控制器输入,通过控制空调设备调节室温.然而,参考文献[11 ]中的空调设备并不同于本文所要研究的暖气设备.第一,空调制热会造成室内空气干燥,降低人的舒适度;而暖气设备由下向上加热室内空气,使热空气分布更均匀,人感觉较舒适,因此暖气设备比空调更有利于提升人的舒适度.第二,空调通常具有自动调温功能,只需给定温度设定值,空调即可自动地将房间温度调整到设定值附近,完成闭环控制;而大多暖气设备并不具有自动调温功能,只能通过控制暖气设备的阀门开度控制暖气设备向房间中输入的热量,间接调节室温,进行开环控制.基于这两方面的不同,有必要研究基于深度强化学习的智能暖气控制方案. ...
多智能体深度强化学习的若干关键科学问题
1
2020
... 近年来,深度学习取得了巨大进展[8 ] ,深度强化学习也得到了越来越多的关注[9 ] .在参考文献[10 ]中,Wei T S采用深度Q网络方法学习控制策略,控制器的输入状态包括时间、室温以及室外环境的干扰.尽管参考文献[10 ]使用了深度神经网络,但是仍然使用人们已经提取好的环境特征作为控制器的输入,没有发挥深度神经网络自动提取特征的能力.在参考文献[11 ]中,Wei Q L等人使用深度Q网络方法,将人的表情和空调温度设定值作为控制器输入,通过控制空调设备调节室温.然而,参考文献[11 ]中的空调设备并不同于本文所要研究的暖气设备.第一,空调制热会造成室内空气干燥,降低人的舒适度;而暖气设备由下向上加热室内空气,使热空气分布更均匀,人感觉较舒适,因此暖气设备比空调更有利于提升人的舒适度.第二,空调通常具有自动调温功能,只需给定温度设定值,空调即可自动地将房间温度调整到设定值附近,完成闭环控制;而大多暖气设备并不具有自动调温功能,只能通过控制暖气设备的阀门开度控制暖气设备向房间中输入的热量,间接调节室温,进行开环控制.基于这两方面的不同,有必要研究基于深度强化学习的智能暖气控制方案. ...
Deep reinforcement learning for building HVAC control
2
2017
... 近年来,深度学习取得了巨大进展[8 ] ,深度强化学习也得到了越来越多的关注[9 ] .在参考文献[10 ]中,Wei T S采用深度Q网络方法学习控制策略,控制器的输入状态包括时间、室温以及室外环境的干扰.尽管参考文献[10 ]使用了深度神经网络,但是仍然使用人们已经提取好的环境特征作为控制器的输入,没有发挥深度神经网络自动提取特征的能力.在参考文献[11 ]中,Wei Q L等人使用深度Q网络方法,将人的表情和空调温度设定值作为控制器输入,通过控制空调设备调节室温.然而,参考文献[11 ]中的空调设备并不同于本文所要研究的暖气设备.第一,空调制热会造成室内空气干燥,降低人的舒适度;而暖气设备由下向上加热室内空气,使热空气分布更均匀,人感觉较舒适,因此暖气设备比空调更有利于提升人的舒适度.第二,空调通常具有自动调温功能,只需给定温度设定值,空调即可自动地将房间温度调整到设定值附近,完成闭环控制;而大多暖气设备并不具有自动调温功能,只能通过控制暖气设备的阀门开度控制暖气设备向房间中输入的热量,间接调节室温,进行开环控制.基于这两方面的不同,有必要研究基于深度强化学习的智能暖气控制方案. ...
... ]中,Wei T S采用深度Q网络方法学习控制策略,控制器的输入状态包括时间、室温以及室外环境的干扰.尽管参考文献[10 ]使用了深度神经网络,但是仍然使用人们已经提取好的环境特征作为控制器的输入,没有发挥深度神经网络自动提取特征的能力.在参考文献[11 ]中,Wei Q L等人使用深度Q网络方法,将人的表情和空调温度设定值作为控制器输入,通过控制空调设备调节室温.然而,参考文献[11 ]中的空调设备并不同于本文所要研究的暖气设备.第一,空调制热会造成室内空气干燥,降低人的舒适度;而暖气设备由下向上加热室内空气,使热空气分布更均匀,人感觉较舒适,因此暖气设备比空调更有利于提升人的舒适度.第二,空调通常具有自动调温功能,只需给定温度设定值,空调即可自动地将房间温度调整到设定值附近,完成闭环控制;而大多暖气设备并不具有自动调温功能,只能通过控制暖气设备的阀门开度控制暖气设备向房间中输入的热量,间接调节室温,进行开环控制.基于这两方面的不同,有必要研究基于深度强化学习的智能暖气控制方案. ...
Learning control for air conditioning systems via human expressions
9
2020
... 近年来,深度学习取得了巨大进展[8 ] ,深度强化学习也得到了越来越多的关注[9 ] .在参考文献[10 ]中,Wei T S采用深度Q网络方法学习控制策略,控制器的输入状态包括时间、室温以及室外环境的干扰.尽管参考文献[10 ]使用了深度神经网络,但是仍然使用人们已经提取好的环境特征作为控制器的输入,没有发挥深度神经网络自动提取特征的能力.在参考文献[11 ]中,Wei Q L等人使用深度Q网络方法,将人的表情和空调温度设定值作为控制器输入,通过控制空调设备调节室温.然而,参考文献[11 ]中的空调设备并不同于本文所要研究的暖气设备.第一,空调制热会造成室内空气干燥,降低人的舒适度;而暖气设备由下向上加热室内空气,使热空气分布更均匀,人感觉较舒适,因此暖气设备比空调更有利于提升人的舒适度.第二,空调通常具有自动调温功能,只需给定温度设定值,空调即可自动地将房间温度调整到设定值附近,完成闭环控制;而大多暖气设备并不具有自动调温功能,只能通过控制暖气设备的阀门开度控制暖气设备向房间中输入的热量,间接调节室温,进行开环控制.基于这两方面的不同,有必要研究基于深度强化学习的智能暖气控制方案. ...
... ]中,Wei Q L等人使用深度Q网络方法,将人的表情和空调温度设定值作为控制器输入,通过控制空调设备调节室温.然而,参考文献[11 ]中的空调设备并不同于本文所要研究的暖气设备.第一,空调制热会造成室内空气干燥,降低人的舒适度;而暖气设备由下向上加热室内空气,使热空气分布更均匀,人感觉较舒适,因此暖气设备比空调更有利于提升人的舒适度.第二,空调通常具有自动调温功能,只需给定温度设定值,空调即可自动地将房间温度调整到设定值附近,完成闭环控制;而大多暖气设备并不具有自动调温功能,只能通过控制暖气设备的阀门开度控制暖气设备向房间中输入的热量,间接调节室温,进行开环控制.基于这两方面的不同,有必要研究基于深度强化学习的智能暖气控制方案. ...
... 本文提出的以人的表情为输入状态,通过暖气设备自适应调整室温的方案与参考文献[11 ]中的方案主要有以下几点不同. ...
... 第一,被控对象不同.本文使用暖气设备调节室温,而参考文献[11 ]使用空调调节室温.使用空调制热会造成室内空气干燥,使人不舒服,从提升人的舒适度的角度来看,使用暖气制热比使用空调更合适. ...
... 第二,控制器施加给被控对象的动作不同.在参考文献[11 ]中,空调大多带有自动调温功能,因此,控制器可直接控制空调的温度设定值,空调与房间之间存在单独的控制回路,空调可以自动调节室温到设定值附近.而在本文中,大多暖气设备只有调节阀,控制器需要通过改变调节阀的开度调节室温,暖气设备与房间之间并不存在控制回路. ...
... 第三,状态预处理算法和Q网络的结构不同.在参考文献[11 ]中,空调温度设定值作为图像的一个通道与预处理后的图像合并,由深度神经网络自动提取特征.而在本文中,将阀门开度作为一个已经提取好的特征直接输入最末层的全连接网络,大大减小了计算量. ...
... 第四,计算眼睛纵横比的方式不同.在参考文献[11 ]中,分别计算左右眼纵横比,再取平均值得到衡量双眼纵横比的值.而在本文中,考虑到双眼运动的一致性以及眨眼检测的实时性,使用右眼的纵横比代替双眼纵横比,减小了计算量,更便于算法实时运行. ...
... 第五,在参考文献[11 ]中,使用深度Q网络方法学习最优策略,而在本文中,为了避免深度Q网络方法造成的动作价值过估计现象,使用双深度Q网络学习控制策略.实验表明,本文中的双深度Q网络方法比参考文献[11 ]中的方法收敛更快,更平稳. ...
... ]中,使用深度Q网络方法学习最优策略,而在本文中,为了避免深度Q网络方法造成的动作价值过估计现象,使用双深度Q网络学习控制策略.实验表明,本文中的双深度Q网络方法比参考文献[11 ]中的方法收敛更快,更平稳. ...
Histograms of oriented gradients for human detection
2005
One millisecond face alignment with an ensemble of regression trees
1
2014
... 控制器的原始输入状态是一幅图像,它在计算机中的存储形式是Q×P×3维的矩阵,参数Q和P取决于图像的分辨率.在人脸检测步骤中,首先将Q×P×3 维的原始输入图像 x x g . 然后,使用参考文献[12]中的人脸检测器检测灰度图像 x g l ,yl )和右下角坐标(xr ,yr ).在截取人眼图像的步骤中,以人脸检测步骤中得到的(xl ,yl )和(xr ,yr )为参考文献[13 ]中的人脸关键点检测器的输入状态,从灰度图像 x g re ,yre )和第46个坐标(xle ,yle )分别代表右眼的最右端和左眼的最左端.在(xre ,yre )上减去一个常数 M 得到 ( x ′ re , y ′ re ) le ,yle )上加上一个常数M得到 ( x ′ le , y ′ le ) . ( x ′ re , y ′ re ) ( x ′ le , y ′ le ) 图1 所示.接下来,根据 ( x ′ re , y ′ re ) ( x ′ le , y ′ le ) x g x ˜
Eye blink detection using facial landmarks
2
2016
... 在状态预处理过程的截取人眼图像步骤中,已经检测出了人脸的68个关键点.在这68个关键点中,左右眼各占 6 个.参考文献[14 ]使用眼睛纵横比(eye aspect ratio,EAR)的平均值衡量人眼的张开程度.受参考文献[14 ]启发,本文也使用眼睛纵横比来衡量眼睛的张开程度.但是考虑到眨眼检测的实时性要求以及双眼动作的同步性,本文仅使用右眼的纵横比来衡量眼睛的张开程度.右眼纵横比EARr 如式(1)所示: ...
... ]使用眼睛纵横比(eye aspect ratio,EAR)的平均值衡量人眼的张开程度.受参考文献[14 ]启发,本文也使用眼睛纵横比来衡量眼睛的张开程度.但是考虑到眨眼检测的实时性要求以及双眼动作的同步性,本文仅使用右眼的纵横比来衡量眼睛的张开程度.右眼纵横比EARr 如式(1)所示: ...









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}