1 引言
随着机器人技术和传感器、控制、导航等相关技术的迅速发展,自主式水下航行器(autonomous underwater vehicle,AUV)在水下探测、搜救、检测等领域得到了广泛的应用。传统的 AUV 运动控制需要建立一个精确的 AUV 模型,控制质量与模型精度密切相关。而 AUV 是一个典型的多变量、强耦合的非线性系统,其参数和模型具有不确定性。这些不确定性给水下机器人的运动控制带来了巨大挑战。针对这种复杂环境下 AUV 的决策与控制问题,机器学习(machine learning,ML)提供了一种有效的解决方案。作为一种最基本的ML方法,监督学习的方法可以通过 AUV 运动数据训练神经网络,从而对模型误差和不确定性进行自适应补偿,实现AUV的高精度运动控制[1 ] 。
强化学习是更有效的ML方法[2 ] 。强化学习算法不需要系统模型信息以及人为设计控制律,而是通过设置奖励函数让机器人自己探索、学习有用的控制策略。对于一个不断与环境进行交互的机器人来说,强化学习将系统实时状态和动作映射为奖励函数,机器人依靠现有数据寻找可以产生最大回报的动作,从而提高机器人在不确定场景中的智能性。例如,在西洋双陆棋比赛中,使用强化学习算法训练的机器人击败了世界冠军[3 ] ,而且,强化学习算法训练的智能体在雅达利游戏公司出品的多种游戏中的表现超过了人类的水平[4 ] 。
2013年,DeepMind公司提出了深度Q学习网络(deep Q-learning network,DQN)算法,这种将强化学习与深度神经网络结合的算法叫作深度强化学习(deep reinforcement learning,DRL)算法[4 ] 。在系统模型未知的情况下,智能体通过设置的奖励函数来学习探索更好的控制策略,并利用深度神经网络估计强化学习评价指标和拟合当前的控制策略。当控制器训练好时,因为神经网络前向传播的计算速度极快,能很快地实现输入状态和控制输入之间端到端的解算,控制的实时性能得到保障。在2016年和2017年,AlphaGo使用DRL算法连续两年击败围棋世界冠军,引起了社会轰动[5 ] 。目前, DRL算法发展迅速,对于提高机器人的自主性和智能性具有十分重要的意义。本文旨在研究一种DRL算法来解决AUV的深度控制问题。
由于 AUV 是一个连续时间系统,其控制行为有无限种选择,而经典的强化学习(reinforcement learning,RL)算法主要针对状态或控制空间有限的离散情况,因此,无法直接控制 AUV 运动。为了解决这个问题,Silver D等人[6 ] 提出确定性策略梯度(deterministic policy gradient,DPG)算法,解决了在随机策略梯度下具有大动作空间的智能体采样数多的问题,使得通过RL算法控制连续时间系统成为可能。在2016年国际学习表征会议(ICLR)上,Lillicrap T P等人[7 ] 将深度神经网络与DPG结合,提出了深度确定性策略梯度(deep deterministic policy gradient,DDPG),并将其应用于简单的连续系统控制。而苏黎世 ETH 机器人实验室成功地将DRL算法应用于腿部机器人的运动控制[8 ] 。
AUV在执行任务时,一般要求在固定的深度保持稳定的运动,因此深度控制是 AUV 的基本控制目标。本文的目的是探索一种更加先进的 AUV 深度控制方法,解决 AUV 模型的不确定性和非线性给控制带来的难题,并提高 AUV 的控制性能;仅依靠训练得到的与周围环境的交互数据,设计DRL算法,从而实现AUV的深度控制。
2 AUV的运动模型
由于AUV的深度控制主要是在垂直面实现的,因此本文仅考虑其在铅垂平面内的运动方程。地面坐标系与体坐标系下的 AUV 如图1 所示,oxy与o b x ′ y ′ o b x b y b e 为控制输入;[ x , y , θ ] ⊤ [ x , y ] ⊤
图1
x ˙ = v x cos θ − v y sin θ
y ˙ = v x sin θ − v y cos θ
θ ˙ = w z
v ˙ x = ( T − C x S 1 2 ρ v 2 S − Δ G sin θ ) / m 11
v ˙ y = ( η ( J z z + λ 66 ) − μ m 26 ) / ( m 22 ( J z z + λ 66 ) − m 26 2 )
w ˙ z = ( μ m 26 − μ ( J z z + λ 66 ) ) / ( m 26 2 − m 22 ( J z z + λ 66 ) ) ( 1 )
其中η = − m v x ω z + 1 2 ρ v 2 S C y − Δ G cos θ C y = C y α α + C y δ e δ e + C y ϖ z ϖ z v = v x 2 + v y 2 μ = ( − m x c v x ω z + G ( y c sin θ − x c cos θ ) + 1 2 ρ v 2 S L m z ) m 11 = m + λ 11 m 22 = m + λ 22 m 26 = m x c + λ 26 m z = m y α α + m y δ e δ e + m y ϖ z ϖ z 11 、λ22 、λ26 、λ66 是与流体动力学有关的附加质量;xc 、yc 是AUV重心到浮力中心的距离在x轴和y轴上的分量;T是由螺旋桨提供的推力;CxS 是AUV的阻力系数,该数值与 AUV 的最大横截面积S、速度v和水的密度ρ有关;ΔG是AUV的负浮力,即重力与浮力之差;J zz 是AUV绕z轴旋转的转动惯量;vx 与vy 分别是AUV在x轴与y轴上的速度分量,wz 是 AUV 的俯仰角速度。此外,攻角α = − arctan ( v y / v x ) ϖ z = w z L / v C y α C y δ e e 的位置导数;C y ϖ z ϖ z m y α m y δ e m y ϖ z e 以及ϖ z
对于给定的控制输入δe ,通过式(1)中的运动模型即可求得AUV的状态s = [ x , y , z , v x , v y , w z ] ⊤
3 基础知识
3.1 强化学习
强化学习是一种机器学习方法,主要解决序列决策的问题。强化学习的基本框架如图2 所示,当智能体给出一个具体动作at 时,环境更新智能体的状态s t t 。这里,当t→∞时,定义智能体的累积奖励为:
G = ∑ t = 0 ∞ γ t r t ( 2 )
图2
强化学习理论推导是在马尔可夫决策模型下进行的,如果一个系统满足马尔可夫性,则系统将来时刻状态只与当前时刻状态有关,与过去时刻状态无关。
p ( s t + 1 | s t ) = p ( s t + 1 | s 1 , s 2 , ⋯ , s t ) ( 3 )
马尔可夫决策过程是在马尔可夫过程中加入了决策部分,假设有智能体与环境从1到T时刻的交互序列:
τ = s 1 , a 1 , s 2 , a 2 , ⋯ , s T , a T ( 4 )
定义随机策略函数π θ ( a t | s t ) = P [ a t | s t ] s t t 的概率。设系统模型为p ( s t + 1 | s t , a t ) t 到下一个状态的概率。其整个马尔可夫决策过程链为:
p θ ( τ ) = p ( s 1 ) ∏ t = 1 T π θ ( a t | s t ) p ( s t + 1 | s t , a t ) ( 5 )
在该交互序列下,强化学习的目标是找到使回报最大的策略参数:
θ * = arg max θ E τ ~ p θ ( τ ) [ ∑ t = 1 T γ t r ( s t , a t ) ] ( 6 )
其优化目标为J ( θ ) = E τ ~ p θ ( τ ) [ ∑ t = 1 T γ t r ( s t , a t ) ]
θ i + 1 = θ i − α ∇ θ J ( θ i ) ( 7 )
∇ θ J ( θ ) = E τ ~ p θ ( τ ) [ ∇ θ log p θ ( τ ) ( ∑ t = 1 T γ t r ( s t , a t ) ) ] d τ ( 8 )
∇ θ J ( θ ) = E τ ~ π θ ( τ ) [ ( ∑ t = 1 T ∇ θ log π θ ( a t | s t ) ) ( ∑ t = 1 T γ t r ( s t , a t ) ) ] ( 9 )
从式(9)可知,对策略进行优化是对策略进行梯度求解。其中,将式(9)后的半部分定义为强化学习状态值函数:
Q π ( s t , a t ) = E τ ~ π θ ( τ ) [ ∑ t = 1 T γ t r ( s t , a t ) ] ( 10 )
3.2 深度前馈神经网络
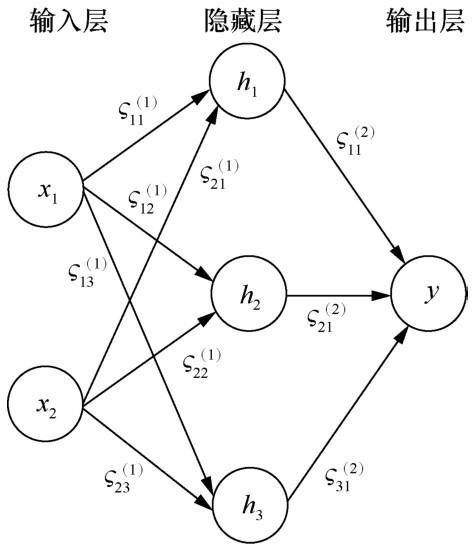
深度前馈神经网络是典型的深度学习模型。前馈神经网络定义了一个映射y=g(x;ς),通过学习的方法选择最佳参数ς,使得函数g(⋅)可以拟合函数y= f(x)。
深度前馈神经网络的结构如图3 所示。第一部分是神经网络的输入层,中间的隐藏层通常有多层结构,最后一部分是输出层,用于输出函数值。ς i j ( 1 ) ς i j ( 2 )
图3
深度前馈神经网络得到的近似函数g(⋅)的精确度可用损失函数L(g(x;ς),y)表示,其中,g(x;ς)为神经网络的估计值,y为真实值。损失函数表示估计值和真实值之间的差异。深度学习中损失函数通常为交叉熵或其他特定函数。选定损失函数后,需要通过最小化损失函数来优化参数ς[10 ] :
ς * = arg max ς L ( g ( x ; ς ) , y ) ( 11 )
求解优化问题时常用的一种深度学习算法是ADAM(adaptive moment estimation)算法[11 ] ,如下所示。
步骤12:If ‖ ε s ^ / ( r ^ + l ) ‖ ≤ 10 − 8
3.3 深度强化学习算法
在本文中,笔者利用actor-critic深度神经网络来实现强化学习算法[2 ] ,其中状态值函数Q π ( s t , a t ) π ( a t | s t ) Q π ( s t , a t )
Q π ( s t , a t ) ≈ Q ( s t , a t ; ω ) ( 12 )
其中,ω为 critic 神经网络参数。通过式(12)可以得到:
Q π ( s t , a t ) = r t + γ Q π ( s t + 1 , a t + 1 ) ( 13 )
为了求得状态值函数Q π ( s t , a t ) [7 ] :
L = ( Q q − Q ( s t , a t ; ω ) ) 2 ( 14 )
Q q = r t + γ Q ′ ( s t + 1 , π ′ ( s t + 1 ; θ ′ ) ; ω ′ ) ( 15 )
其中,Q′和π′为目标神经网络,其作用为稳定学习过程。目标神经网络参数θ′与ω′更新方式如下[12 ] :
θ ′ ← τ θ + ( 1 − τ ) θ ′
ω ′ ← τ ω + ( 1 − τ ) ω ′ ( 16 )
其中,τ的取值远小于 1,以保证目标神经网络的稳定性。
利用一组N个数据对 critic 神经网络进行训练,求得其平均损失函数为:
L ¯ = 1 N ∑ t = 1 N ( Q q − Q ( s t , a t ; ω ) ) 2 ( 17 )
∇ L ¯ ω = ∇ ω ( 1 N ∑ t = 1 N ( Q q − Q ( s t , a t ; ω ) ) 2 ) ( 18 )
通过ADAM算法对式(18)的梯度进行计算,利用学习到的参数ω* 对状态值函数Q π ( s t , a t ) Q ( s t , a t ; ω * )
与随机策略梯度不同,在确定性策略梯度中,动作at 在状态s t π θ ( s t ) π ( s t ) [13 ] ,将最优策略求解转化为对actor神经网络参数θ的优化,以达到奖励函数最大化的目的,即
θ * = arg min θ E τ ~ p θ ( τ ) [ ∑ t = 1 T γ t r ( s t , a t ) ] ( 19 )
p θ ( τ ) = p ( s 1 ) ∏ t = 1 T π θ ( s t ) p ( s t +1 | s t , a t ) ( 20 )
J ( θ ) = E τ ~ ρ ( τ ) [ Q ( s t , a t ) | a t = π θ ( s t ) ] ( 21 )
ρ ( τ ) = p ( s 1 ) ∏ t = 1 T p ( s t +1 | s t , a t ) ( 22 )
∇ θ J ( θ ) = E τ ~ ρ ( τ ) [ ∇ Q a ( s t , a t ) | a t = π θ ( s t ) · ∇ θ π θ ( s t ) ] ( 23 )
该算法为离线迭代算法,通过 AUV 运动数据对其进行训练。利用一组N个数据对actor神经网络进行训练,利用蒙特卡洛方法对期望进行估计可以得到梯度:
∇ θ J ( θ ) = 1 N ∑ t = 1 N [ ∇ Q a ( s t , a t ) | a t = π θ ( s t ) · ∇ θ π θ ( s t ) ] ( 24 )
最后,利用 ADAM 算法对梯度进行计算,得到最优参数θ* 。
当对critic和actor神经网络进行训练时,一般假设训练数据是独立不相关的。但是机器人探索得到的数据是有相关性的,这会导致神经网络的训练效果不佳。可以通过建立一个回放记忆单元解决这一问题,将机器人探索得到的数据存入回放记忆单元中,在训练时随机从回放记忆单元中提取一组数据,以打破数据的相关性[12 ] 。DDPG算法如下[7 ] 。
步骤 1:初始化 critic 神经网络Q ( s t , a t ; ω ) π θ ( s t )
步骤2:初始化目标神经网络参数θ′与ω′,令t=0,i=0;
步骤8:Q q = r t + γ Q ′ ( s t + 1 , π ′ ( s t + 1 ; θ ′ ) ; ω ′ )
步骤12:J ( θ ) = E τ ~ ρ ( τ ) [ Q ( s t , a t ; ω ) | a t = π θ ( s t ) ]
4 基于DRL算法的AUV定深控制
利用 DRL 算法对 AUV 进行定深控制需要AUV 对环境进行探索学习。考虑到在真实环境中AUV获取大量数据的费用是昂贵的,因此利用式(1)中的AUV模型来获取训练数据。
定义s t = [ x ( t ) , y ( t ) , z ( t ) , v x ( t ) , v y ( t ) , w z ( t ) ] ⊤ δ e ( t ) = K ( s t ) a t = δ e ( t )
定深控制的定义是通过控制输入将 AUV 保持在预定深度yd 运动。为了解决强化学习中的稀疏奖励和奖励延迟问题,根据 AUV 定深控制的运动特性设计了一个分段式的奖励函数。
R ( s t ) = − c y ‖ y ( t ) − y d ‖ − c θ ‖ θ ( t ) ‖ − c ω ‖ ω z ( t ) ‖ ( 25 )
其中,cy >0、cθ >0、cω >0,均为常数。其目的是鼓励 AUV 下潜到预定深度,并防止其俯仰角过大。
当AUV到达预定深度yd 的一定范围内时,将奖励函数切换为:
R ( s t ) = c r ( 26 )
其中,cr 是一个常数。其目的是鼓励 AUV 保持在该深度运行。综合上述分析,奖励函数为:
R ( s t ) = { − c y ‖ y ( t ) − y d ‖ − c θ ‖ θ ( t ) ‖ − c ω ‖ ω z ( t ) ‖ ( y ( t ) − y d > 0.1 ) c r ( y ( t ) − y d ≤ 0.1 ) ( 27 )
将设计的奖励函数代入算法 2 中,利用 critic神经网络估计状态值函数:
Q π ( s t , a t ) ≈ Q ( s t , a t ; ω ) ( 28 )
通过训练actor神经网络得到最优策略π θ * ( s t )
a ′ t = π θ ( s t ) + υ ( 29 )
其中,υ是Ornstein-Uhlenbeck随机噪声[14 ] 。
为了训练神经网络,将下一时刻系统状态s t + 1 s t t 和奖励rt 组成一个元组〈 s t + 1 , s t , a t , r t 〉
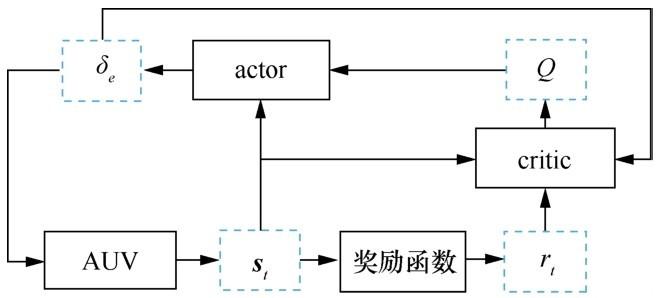
基于深度强化学习的 AUV 定深控制系统如图4 所示。其中,用于估计状态值函数的critic神经网络的输入为 〈 s t , a t , r t 〉 Q ( s t , a t ; ω ) t ,输出为定深控制动作。
图4
5 仿真实验
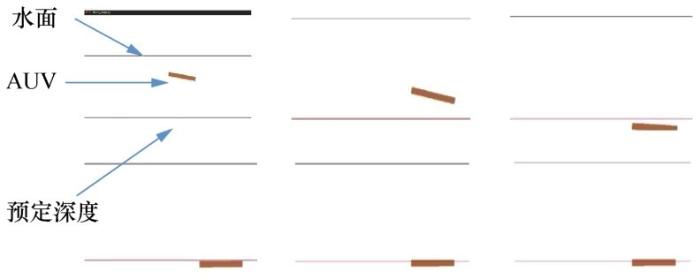
在本节中,笔者用仿真实验验证算法的有效性。仿真平台为OpenAI Gym平台,利用第2节的AUV运动模型建立仿真模型,如图5 所示。
图5
图5
OpenAI Gym仿真平台中的AUV深度控制模型
初始化奖励函数参数cy =1、cθ =4、cω =2、cr =5。通过 TensorFlow 搭建深度神经网络[15 ] ,其中critic神经网络由5个全连接层组成,隐藏层每层节点数为 32 个,除输出层外,在其他 4 层加入ReLU激活函数[16 ] 。actor神经网络由4个全连接层组成,隐藏层每层节点数为16个,除了输出层外,在其他3层加入ReLU激活函数,输出层使用tanh激活函数对输出进行[-1,1]的归一化。
在训练初期,AUV先进行自由探索,将数据存入回放记忆单元中。当回放记忆单元存满后,通过随机采样的方式抽取一组 64 个数据对神经网络进行训练。critic神经网络训练的学习率为0.001,actor神经网络的学习率为0.000 1。在对两个神经网络进行更新后,通过式(16)对目标神经网络进行更新,其中更新参数 t=0.001。最后,利用训练后的 actor神经网络与环境进行交互,将得到的数据用于更新数据集。在整个学习过程中重复上述步骤,直到奖励函数收敛。平均奖励值随训练幕数的变化如图6 所示,由图6 可知,在经过1 000幕的训练后,每一幕的平均奖励函数得到了收敛。AUV定深运动的轨迹如图7 所示。
图6
图7
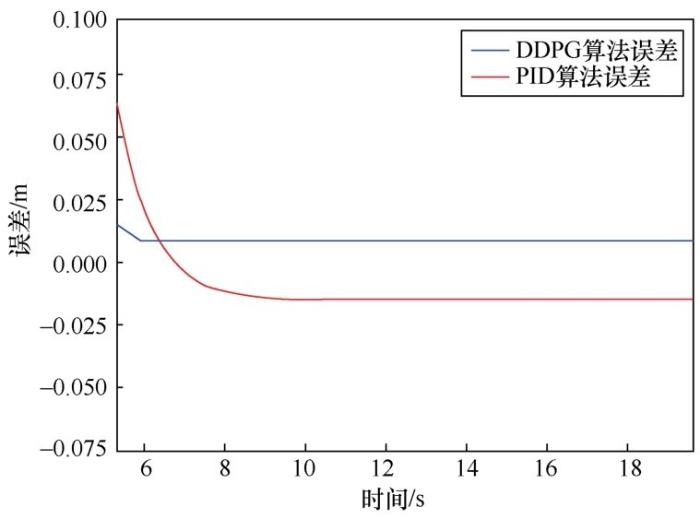
假设AUV的预定深度yd = -5 m,图6 和图7 显示,经过2 000幕的训练后,由actor神经网络控制AUV定深运动的轨迹。这表示经过训练的actor神经网络可以控制 AUV 高精度下潜到预定深度,并保持在预定深度运动。如图8 所示,与另一种不需要模型信息的PID控制算法相比,DDPG算法有更高的控制精度。
图8
6 结束语
本文将DRL算法应用于AUV的定深控制,不依赖于 AUV 的系统建模和控制律设计。通过设计合理的奖励函数引导 AUV 探索学习定深控制律。仿真实验证明了该方法的可行性,比起传统无模型PID控制算法,其具有更高的精度。在未来的研究中可以着重研究提高算法学习速率和学习效率的方法和向实际系统迁移的可能性。
The authors have declared that no competing interests exist.
作者已声明无竞争性利益关系。
参考文献
View Option
[1]
ZHANG L J , QI X , PANG Y J . Adaptive output feedback control based on DRFNN for AUV
[J]. Ocean Engineering , 2009 ,36 (9-10 ): 716 -722 .
[本文引用: 1]
[2]
SUTTON R , BARTO A . Reinforcement learning:an introduction
[M]. Cambridge : MIT Press , 1998 .
[本文引用: 2]
[3]
TESAURO G . TD-Gammon,a self-teaching backgammon program,achieves master-level play
[J]. Neural Computation , 1944 ,6 (2 ): 215 -219 .
[本文引用: 1]
[4]
MNIH V , KAVUKCUOGLU K , SILVER D ,et al . Playing atari with deep reinforcement learning
[J]. Computer Science , 2013 .
[本文引用: 2]
[5]
SILVER D , HUANG A , MADDISON C J ,et al . Mastering the game of go with deep neural networks and tree search
[J]. Nature , 2016 ,529 (7587 ): 484 -489 .
[本文引用: 1]
[6]
SILVER D , TECHNOLOGIES D , LEVER G ,et al . Deterministic policy gradient algorithms
[C]// International Conference on Machine Learning . New York:ACM Press , 2014 .
[本文引用: 1]
[7]
LILLICRAP T P , HUNT J J , PRITZEL A ,et al . Continuous control with deep reinforcement learning
[J]. Computer Science , 2015 ,6 (6 ): A187 .
[本文引用: 3]
[8]
HWANGBO J , LEE J , DOSOVITSKIY A ,et al . Learning agile and dynamic motor skills for legged robots
[J]. Science Robotics , 2019 ,4 (26 ).
[本文引用: 1]
[9]
严卫生 . 鱼雷航行力学
[M]. 西安 : 西北工业大学出版社 , 2005 .
[本文引用: 1]
YAN W S . Torpedo navigation mechanics
[M]. Xi’an : Northwestern Polytechnical University Press , 2005 .
[本文引用: 1]
[10]
GOODFELLOW I , BENGIO Y , COURVILLE A . Deep learning
[M]. Cambridge : MIT Press , 2016 .
[本文引用: 1]
[11]
KINGMA D , BA J . ADAM:a method for stochastic optimization
[J]. Computer Science , 2014 .
[本文引用: 1]
[12]
MNIH V , KAVUKCUOGLU K , SILVER D ,et al . Human-level control through deep reinforcement learning
[J]. Nature , 2015 , 518 -529 .
[本文引用: 2]
[13]
KONDA V , TSITSIKLIS J . Actor-critic algorithms
[J]. In Advances in Neural Information Processing Systems , 2003 : 1008 -1014 .
[本文引用: 1]
[14]
UHLENBECK G E , ORNSTEIN L S . On the theory of the Brownian motion
[J]. Revista Latinoamericana De Microbiología , 1973 ,15 (1 ): 29 .
[本文引用: 1]
[15]
ABADI M , BARHAM P , CHEN P ,et al . TensorFlow:a system for large-scale machine learning
[J]. Google Brain , 2016 .
[本文引用: 1]
[16]
NAIR V , HINTON G . Rectified linear units improve restricted Boltzmann machines
[C]// International Conference on Machine Learning .[S.l.:s.n.], 2010 .
[本文引用: 1]
Adaptive output feedback control based on DRFNN for AUV
1
2009
... 随着机器人技术和传感器、控制、导航等相关技术的迅速发展,自主式水下航行器(autonomous underwater vehicle,AUV)在水下探测、搜救、检测等领域得到了广泛的应用.传统的 AUV 运动控制需要建立一个精确的 AUV 模型,控制质量与模型精度密切相关.而 AUV 是一个典型的多变量、强耦合的非线性系统,其参数和模型具有不确定性.这些不确定性给水下机器人的运动控制带来了巨大挑战.针对这种复杂环境下 AUV 的决策与控制问题,机器学习(machine learning,ML)提供了一种有效的解决方案.作为一种最基本的ML方法,监督学习的方法可以通过 AUV 运动数据训练神经网络,从而对模型误差和不确定性进行自适应补偿,实现AUV的高精度运动控制[1 ] . ...
Reinforcement learning:an introduction
2
1998
... 强化学习是更有效的ML方法[2 ] .强化学习算法不需要系统模型信息以及人为设计控制律,而是通过设置奖励函数让机器人自己探索、学习有用的控制策略.对于一个不断与环境进行交互的机器人来说,强化学习将系统实时状态和动作映射为奖励函数,机器人依靠现有数据寻找可以产生最大回报的动作,从而提高机器人在不确定场景中的智能性.例如,在西洋双陆棋比赛中,使用强化学习算法训练的机器人击败了世界冠军[3 ] ,而且,强化学习算法训练的智能体在雅达利游戏公司出品的多种游戏中的表现超过了人类的水平[4 ] . ...
... 在本文中,笔者利用actor-critic深度神经网络来实现强化学习算法[2 ] ,其中状态值函数 Q π ( s t , a t ) π ( a t | s t ) Q π ( s t , a t )
TD-Gammon,a self-teaching backgammon program,achieves master-level play
1
1944
... 强化学习是更有效的ML方法[2 ] .强化学习算法不需要系统模型信息以及人为设计控制律,而是通过设置奖励函数让机器人自己探索、学习有用的控制策略.对于一个不断与环境进行交互的机器人来说,强化学习将系统实时状态和动作映射为奖励函数,机器人依靠现有数据寻找可以产生最大回报的动作,从而提高机器人在不确定场景中的智能性.例如,在西洋双陆棋比赛中,使用强化学习算法训练的机器人击败了世界冠军[3 ] ,而且,强化学习算法训练的智能体在雅达利游戏公司出品的多种游戏中的表现超过了人类的水平[4 ] . ...
Playing atari with deep reinforcement learning
2
2013
... 强化学习是更有效的ML方法[2 ] .强化学习算法不需要系统模型信息以及人为设计控制律,而是通过设置奖励函数让机器人自己探索、学习有用的控制策略.对于一个不断与环境进行交互的机器人来说,强化学习将系统实时状态和动作映射为奖励函数,机器人依靠现有数据寻找可以产生最大回报的动作,从而提高机器人在不确定场景中的智能性.例如,在西洋双陆棋比赛中,使用强化学习算法训练的机器人击败了世界冠军[3 ] ,而且,强化学习算法训练的智能体在雅达利游戏公司出品的多种游戏中的表现超过了人类的水平[4 ] . ...
... 2013年,DeepMind公司提出了深度Q学习网络(deep Q-learning network,DQN)算法,这种将强化学习与深度神经网络结合的算法叫作深度强化学习(deep reinforcement learning,DRL)算法[4 ] .在系统模型未知的情况下,智能体通过设置的奖励函数来学习探索更好的控制策略,并利用深度神经网络估计强化学习评价指标和拟合当前的控制策略.当控制器训练好时,因为神经网络前向传播的计算速度极快,能很快地实现输入状态和控制输入之间端到端的解算,控制的实时性能得到保障.在2016年和2017年,AlphaGo使用DRL算法连续两年击败围棋世界冠军,引起了社会轰动[5 ] .目前, DRL算法发展迅速,对于提高机器人的自主性和智能性具有十分重要的意义.本文旨在研究一种DRL算法来解决AUV的深度控制问题. ...
Mastering the game of go with deep neural networks and tree search
1
2016
... 2013年,DeepMind公司提出了深度Q学习网络(deep Q-learning network,DQN)算法,这种将强化学习与深度神经网络结合的算法叫作深度强化学习(deep reinforcement learning,DRL)算法[4 ] .在系统模型未知的情况下,智能体通过设置的奖励函数来学习探索更好的控制策略,并利用深度神经网络估计强化学习评价指标和拟合当前的控制策略.当控制器训练好时,因为神经网络前向传播的计算速度极快,能很快地实现输入状态和控制输入之间端到端的解算,控制的实时性能得到保障.在2016年和2017年,AlphaGo使用DRL算法连续两年击败围棋世界冠军,引起了社会轰动[5 ] .目前, DRL算法发展迅速,对于提高机器人的自主性和智能性具有十分重要的意义.本文旨在研究一种DRL算法来解决AUV的深度控制问题. ...
Deterministic policy gradient algorithms
1
2014
... 由于 AUV 是一个连续时间系统,其控制行为有无限种选择,而经典的强化学习(reinforcement learning,RL)算法主要针对状态或控制空间有限的离散情况,因此,无法直接控制 AUV 运动.为了解决这个问题,Silver D等人[6 ] 提出确定性策略梯度(deterministic policy gradient,DPG)算法,解决了在随机策略梯度下具有大动作空间的智能体采样数多的问题,使得通过RL算法控制连续时间系统成为可能.在2016年国际学习表征会议(ICLR)上,Lillicrap T P等人[7 ] 将深度神经网络与DPG结合,提出了深度确定性策略梯度(deep deterministic policy gradient,DDPG),并将其应用于简单的连续系统控制.而苏黎世 ETH 机器人实验室成功地将DRL算法应用于腿部机器人的运动控制[8 ] . ...
Continuous control with deep reinforcement learning
3
2015
... 由于 AUV 是一个连续时间系统,其控制行为有无限种选择,而经典的强化学习(reinforcement learning,RL)算法主要针对状态或控制空间有限的离散情况,因此,无法直接控制 AUV 运动.为了解决这个问题,Silver D等人[6 ] 提出确定性策略梯度(deterministic policy gradient,DPG)算法,解决了在随机策略梯度下具有大动作空间的智能体采样数多的问题,使得通过RL算法控制连续时间系统成为可能.在2016年国际学习表征会议(ICLR)上,Lillicrap T P等人[7 ] 将深度神经网络与DPG结合,提出了深度确定性策略梯度(deep deterministic policy gradient,DDPG),并将其应用于简单的连续系统控制.而苏黎世 ETH 机器人实验室成功地将DRL算法应用于腿部机器人的运动控制[8 ] . ...
... 为了求得状态值函数 Q π ( s t , a t ) [7 ] : ...
... 当对critic和actor神经网络进行训练时,一般假设训练数据是独立不相关的.但是机器人探索得到的数据是有相关性的,这会导致神经网络的训练效果不佳.可以通过建立一个回放记忆单元解决这一问题,将机器人探索得到的数据存入回放记忆单元中,在训练时随机从回放记忆单元中提取一组数据,以打破数据的相关性[12 ] .DDPG算法如下[7 ] . ...
Learning agile and dynamic motor skills for legged robots
1
2019
... 由于 AUV 是一个连续时间系统,其控制行为有无限种选择,而经典的强化学习(reinforcement learning,RL)算法主要针对状态或控制空间有限的离散情况,因此,无法直接控制 AUV 运动.为了解决这个问题,Silver D等人[6 ] 提出确定性策略梯度(deterministic policy gradient,DPG)算法,解决了在随机策略梯度下具有大动作空间的智能体采样数多的问题,使得通过RL算法控制连续时间系统成为可能.在2016年国际学习表征会议(ICLR)上,Lillicrap T P等人[7 ] 将深度神经网络与DPG结合,提出了深度确定性策略梯度(deep deterministic policy gradient,DDPG),并将其应用于简单的连续系统控制.而苏黎世 ETH 机器人实验室成功地将DRL算法应用于腿部机器人的运动控制[8 ] . ...
鱼雷航行力学
1
2005
... AUV在垂直面的二维运动模型如下[9 ] : ...
鱼雷航行力学
1
2005
... AUV在垂直面的二维运动模型如下[9 ] : ...
Deep learning
1
2016
... 深度前馈神经网络得到的近似函数g(⋅)的精确度可用损失函数L(g(x;ς),y)表示,其中,g(x;ς)为神经网络的估计值,y为真实值.损失函数表示估计值和真实值之间的差异.深度学习中损失函数通常为交叉熵或其他特定函数.选定损失函数后,需要通过最小化损失函数来优化参数ς[10 ] : ...
ADAM:a method for stochastic optimization
1
2014
... 求解优化问题时常用的一种深度学习算法是ADAM(adaptive moment estimation)算法[11 ] ,如下所示. ...
Human-level control through deep reinforcement learning
2
2015
... 其中,Q′和π′为目标神经网络,其作用为稳定学习过程.目标神经网络参数θ′与ω′更新方式如下[12 ] : ...
... 当对critic和actor神经网络进行训练时,一般假设训练数据是独立不相关的.但是机器人探索得到的数据是有相关性的,这会导致神经网络的训练效果不佳.可以通过建立一个回放记忆单元解决这一问题,将机器人探索得到的数据存入回放记忆单元中,在训练时随机从回放记忆单元中提取一组数据,以打破数据的相关性[12 ] .DDPG算法如下[7 ] . ...
Actor-critic algorithms
1
2003
... 与随机策略梯度不同,在确定性策略梯度中,动作at 在状态 s t π θ ( s t ) π ( s t ) [13 ] ,将最优策略求解转化为对actor神经网络参数θ的优化,以达到奖励函数最大化的目的,即 ...
On the theory of the Brownian motion
1
1973
... 其中,υ是Ornstein-Uhlenbeck随机噪声[14 ] . ...
TensorFlow:a system for large-scale machine learning
1
2016
... 初始化奖励函数参数cy =1、cθ =4、cω =2、cr =5.通过 TensorFlow 搭建深度神经网络[15 ] ,其中critic神经网络由5个全连接层组成,隐藏层每层节点数为 32 个,除输出层外,在其他 4 层加入ReLU激活函数[16 ] .actor神经网络由4个全连接层组成,隐藏层每层节点数为16个,除了输出层外,在其他3层加入ReLU激活函数,输出层使用tanh激活函数对输出进行[-1,1]的归一化. ...
Rectified linear units improve restricted Boltzmann machines
1
2010
... 初始化奖励函数参数cy =1、cθ =4、cω =2、cr =5.通过 TensorFlow 搭建深度神经网络[15 ] ,其中critic神经网络由5个全连接层组成,隐藏层每层节点数为 32 个,除输出层外,在其他 4 层加入ReLU激活函数[16 ] .actor神经网络由4个全连接层组成,隐藏层每层节点数为16个,除了输出层外,在其他3层加入ReLU激活函数,输出层使用tanh激活函数对输出进行[-1,1]的归一化. ...













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}