The National Natural Science Foundation of China. 61973070 Liaoning Revitalization Talents Program. XLYC1802010 SAPI Fundamental Research Funds. 2018ZCX22
The output synchronization of heterogeneous multi-agent system was studied by reinforcement learning.According to the topology of multi-agent system, the performance index and value function with neighbor control input were defined.To overcome the disadvantage of existing control methods that require system model, a reinforcement learning algorithm based on system data was proposed.Hence, the output synchronization controller can also be applied when the system model was unknown.In addition, by adjusting the weight matrix in value function, the control cost of each agent can be reduced.Finally, a simulation example was given to illustrate the effectiveness of proposed method and the superiority of defined value function.
Keywords:multi-agent system
;
reinforcement learning
;
output synchronization
;
based on data
LIU Yingying. Output synchronization of heterogeneous multi-agent system:a reinforcement learning approach based on data. Chinese Journal of Intelligent Science and Technology[J], 2020, 2(4): 394-400 doi:10.11959/j.issn.2096-6652.202042
1 引言
多智能体系统(multi-agent system,MAS)可以描述一组系统的集体行为,并且有很多重要的应用[1,2,3]。近些年涌现了大量关于MAS问题的研究[4,5,6,7,8]。其中,输出同步问题是 MAS 的一个基本问题。在很多实际应用中,每个智能体的动态和维度可能是不同的,因此,研究异构 MAS 的输出同步是十分重要的[9]。
目前,已经有许多关于异构 MAS 输出同步问题的分布式控制器设计方法的研究[10,11,12]。大部分控制器设计方法需要求解 MAS 的输出调节方程,并且不可避免地需要系统模型信息。参考文献[11]基于内模原理提出了一种统一的方法来解决异构MAS的输出群同步问题。参考文献[12]通过设计分布式观测器研究了离散MAS的协同输出调节问题。参考文献[11-12]都是基于系统模型得到的结果。然而,在许多实际应用中是无法获取 MAS 的精确模型的。因此,已有的分布式控制方法不能应用于这些系统模型未知的情况。
强化学习起源于“试错学习”,强调使用基于环境的反馈修改行为,它由英国生物和心理学家Conway Morgan正式提出[13]。随后,Werbos P J将强化学习用于求解单系统的最优调节问题[14,15]。由于强化学习可以利用系统数据迭代求解最优控制问题,它也被广泛应用于求解MAS问题[7,16,17]。例如,参考文献[16]利用离策略强化学习算法求解MAS的最优输出同步问题。
对于大多数求解异构 MAS 输出同步问题的强化学习算法,其价值函数由追踪误差和智能体本身的控制输入组成[16,17,19]。这样的价值函数虽然能在一定程度上减少控制成本,但是没有考虑 MAS 拓扑结构对价值函数的影响,即没有考虑邻居智能体对智能体本身的影响。因此需要定义一个包含邻居控制输入信息的性能指标和价值函数,从而减少每个智能体的控制成本。
基于以上讨论,在价值函数中考虑异构 MAS的拓扑信息,并借助系统数据,使用强化学习方法求解异构 MAS 的输出同步问题是十分迫切的。因此,本文定义了一个含有邻居控制输入信息的性能指标,然后基于强化学习中的Q学习提出一个求解MAS控制器的强化学习算法。
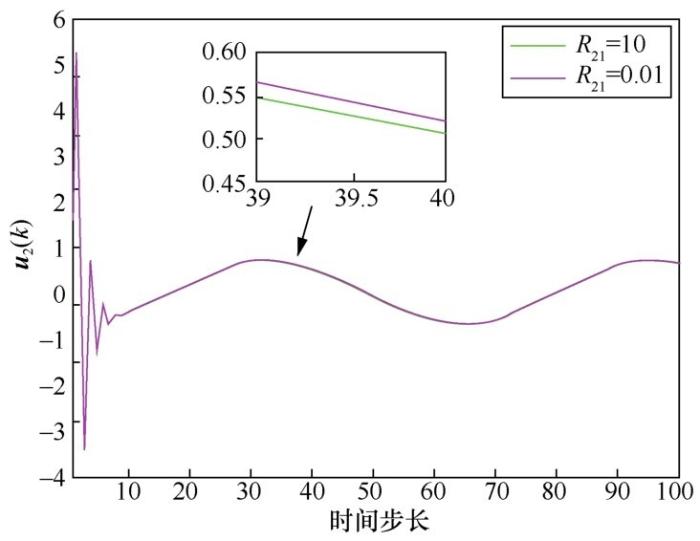
本文研究了异构MAS的输出同步问题。首先,通过定义一个具有邻居控制输入的性能指标和价值函数,得到MAS的Bellman方程;然后,根据最优原则得到基于模型的 MAS 输出同步问题的控制器;为了使控制器也可以应用于模型未知的情况,提出一种基于Q学习的强化学习算法;最后,给出一个仿真示例,并验证了本文方法的有效性。通过调节权重矩阵,体现了本文定义的价值函数的优越性。
The authors have declared that no competing interests exist.
Cooperative output regulation of heterogeneous linear multi-agent networks via H∞performance allocation
1
2019
... 多智能体系统(multi-agent system,MAS)可以描述一组系统的集体行为,并且有很多重要的应用[1,2,3].近些年涌现了大量关于MAS问题的研究[4,5,6,7,8].其中,输出同步问题是 MAS 的一个基本问题.在很多实际应用中,每个智能体的动态和维度可能是不同的,因此,研究异构 MAS 的输出同步是十分重要的[9]. ...
多智能体深度强化学习的若干关键科学问题
1
2020
... 多智能体系统(multi-agent system,MAS)可以描述一组系统的集体行为,并且有很多重要的应用[1,2,3].近些年涌现了大量关于MAS问题的研究[4,5,6,7,8].其中,输出同步问题是 MAS 的一个基本问题.在很多实际应用中,每个智能体的动态和维度可能是不同的,因此,研究异构 MAS 的输出同步是十分重要的[9]. ...
多智能体深度强化学习的若干关键科学问题
1
2020
... 多智能体系统(multi-agent system,MAS)可以描述一组系统的集体行为,并且有很多重要的应用[1,2,3].近些年涌现了大量关于MAS问题的研究[4,5,6,7,8].其中,输出同步问题是 MAS 的一个基本问题.在很多实际应用中,每个智能体的动态和维度可能是不同的,因此,研究异构 MAS 的输出同步是十分重要的[9]. ...
多智能体系统在军事仿真领域的应用现状
1
2017
... 多智能体系统(multi-agent system,MAS)可以描述一组系统的集体行为,并且有很多重要的应用[1,2,3].近些年涌现了大量关于MAS问题的研究[4,5,6,7,8].其中,输出同步问题是 MAS 的一个基本问题.在很多实际应用中,每个智能体的动态和维度可能是不同的,因此,研究异构 MAS 的输出同步是十分重要的[9]. ...
多智能体系统在军事仿真领域的应用现状
1
2017
... 多智能体系统(multi-agent system,MAS)可以描述一组系统的集体行为,并且有很多重要的应用[1,2,3].近些年涌现了大量关于MAS问题的研究[4,5,6,7,8].其中,输出同步问题是 MAS 的一个基本问题.在很多实际应用中,每个智能体的动态和维度可能是不同的,因此,研究异构 MAS 的输出同步是十分重要的[9]. ...
Distributed output regulation of heterogeneous linear multi-agent systems with communication constraints
1
2018
... 多智能体系统(multi-agent system,MAS)可以描述一组系统的集体行为,并且有很多重要的应用[1,2,3].近些年涌现了大量关于MAS问题的研究[4,5,6,7,8].其中,输出同步问题是 MAS 的一个基本问题.在很多实际应用中,每个智能体的动态和维度可能是不同的,因此,研究异构 MAS 的输出同步是十分重要的[9]. ...
基于消息通信的多智能体系统的应用
1
2008
... 多智能体系统(multi-agent system,MAS)可以描述一组系统的集体行为,并且有很多重要的应用[1,2,3].近些年涌现了大量关于MAS问题的研究[4,5,6,7,8].其中,输出同步问题是 MAS 的一个基本问题.在很多实际应用中,每个智能体的动态和维度可能是不同的,因此,研究异构 MAS 的输出同步是十分重要的[9]. ...
基于消息通信的多智能体系统的应用
1
2008
... 多智能体系统(multi-agent system,MAS)可以描述一组系统的集体行为,并且有很多重要的应用[1,2,3].近些年涌现了大量关于MAS问题的研究[4,5,6,7,8].其中,输出同步问题是 MAS 的一个基本问题.在很多实际应用中,每个智能体的动态和维度可能是不同的,因此,研究异构 MAS 的输出同步是十分重要的[9]. ...
Recent advances in consensus of multi-agent systems:a brief survey
1
2017
... 多智能体系统(multi-agent system,MAS)可以描述一组系统的集体行为,并且有很多重要的应用[1,2,3].近些年涌现了大量关于MAS问题的研究[4,5,6,7,8].其中,输出同步问题是 MAS 的一个基本问题.在很多实际应用中,每个智能体的动态和维度可能是不同的,因此,研究异构 MAS 的输出同步是十分重要的[9]. ...
Data-driven optimal consensus control for discrete-time multi-agent systems with unknown dynamics using reinforcement learning method
2
2017
... 多智能体系统(multi-agent system,MAS)可以描述一组系统的集体行为,并且有很多重要的应用[1,2,3].近些年涌现了大量关于MAS问题的研究[4,5,6,7,8].其中,输出同步问题是 MAS 的一个基本问题.在很多实际应用中,每个智能体的动态和维度可能是不同的,因此,研究异构 MAS 的输出同步是十分重要的[9]. ...
... 强化学习起源于“试错学习”,强调使用基于环境的反馈修改行为,它由英国生物和心理学家Conway Morgan正式提出[13].随后,Werbos P J将强化学习用于求解单系统的最优调节问题[14,15].由于强化学习可以利用系统数据迭代求解最优控制问题,它也被广泛应用于求解MAS问题[7,16,17].例如,参考文献[16]利用离策略强化学习算法求解MAS的最优输出同步问题. ...
Fault-tolerant consensus tracking control for linear multi-agent systems under switching directed network
1
2020
... 多智能体系统(multi-agent system,MAS)可以描述一组系统的集体行为,并且有很多重要的应用[1,2,3].近些年涌现了大量关于MAS问题的研究[4,5,6,7,8].其中,输出同步问题是 MAS 的一个基本问题.在很多实际应用中,每个智能体的动态和维度可能是不同的,因此,研究异构 MAS 的输出同步是十分重要的[9]. ...
Observer-based output consensus of a class of heterogeneous multi-agent systems with unmatched disturbances
1
2018
... 多智能体系统(multi-agent system,MAS)可以描述一组系统的集体行为,并且有很多重要的应用[1,2,3].近些年涌现了大量关于MAS问题的研究[4,5,6,7,8].其中,输出同步问题是 MAS 的一个基本问题.在很多实际应用中,每个智能体的动态和维度可能是不同的,因此,研究异构 MAS 的输出同步是十分重要的[9]. ...
Adaptive cooperative output regulation for a class of nonlinear multi-agent systems
1
2015
... 目前,已经有许多关于异构 MAS 输出同步问题的分布式控制器设计方法的研究[10,11,12].大部分控制器设计方法需要求解 MAS 的输出调节方程,并且不可避免地需要系统模型信息.参考文献[11]基于内模原理提出了一种统一的方法来解决异构MAS的输出群同步问题.参考文献[12]通过设计分布式观测器研究了离散MAS的协同输出调节问题.参考文献[11-12]都是基于系统模型得到的结果.然而,在许多实际应用中是无法获取 MAS 的精确模型的.因此,已有的分布式控制方法不能应用于这些系统模型未知的情况. ...
Output group synchronization for networks of heterogeneous linear systems under internal model principle
3
2018
... 目前,已经有许多关于异构 MAS 输出同步问题的分布式控制器设计方法的研究[10,11,12].大部分控制器设计方法需要求解 MAS 的输出调节方程,并且不可避免地需要系统模型信息.参考文献[11]基于内模原理提出了一种统一的方法来解决异构MAS的输出群同步问题.参考文献[12]通过设计分布式观测器研究了离散MAS的协同输出调节问题.参考文献[11-12]都是基于系统模型得到的结果.然而,在许多实际应用中是无法获取 MAS 的精确模型的.因此,已有的分布式控制方法不能应用于这些系统模型未知的情况. ...
... .大部分控制器设计方法需要求解 MAS 的输出调节方程,并且不可避免地需要系统模型信息.参考文献[11]基于内模原理提出了一种统一的方法来解决异构MAS的输出群同步问题.参考文献[12]通过设计分布式观测器研究了离散MAS的协同输出调节问题.参考文献[11-12]都是基于系统模型得到的结果.然而,在许多实际应用中是无法获取 MAS 的精确模型的.因此,已有的分布式控制方法不能应用于这些系统模型未知的情况. ...
... ]通过设计分布式观测器研究了离散MAS的协同输出调节问题.参考文献[11-12]都是基于系统模型得到的结果.然而,在许多实际应用中是无法获取 MAS 的精确模型的.因此,已有的分布式控制方法不能应用于这些系统模型未知的情况. ...
Cooperative output regulation of discrete-time linear time-delay multi-agent systems
4
2016
... 目前,已经有许多关于异构 MAS 输出同步问题的分布式控制器设计方法的研究[10,11,12].大部分控制器设计方法需要求解 MAS 的输出调节方程,并且不可避免地需要系统模型信息.参考文献[11]基于内模原理提出了一种统一的方法来解决异构MAS的输出群同步问题.参考文献[12]通过设计分布式观测器研究了离散MAS的协同输出调节问题.参考文献[11-12]都是基于系统模型得到的结果.然而,在许多实际应用中是无法获取 MAS 的精确模型的.因此,已有的分布式控制方法不能应用于这些系统模型未知的情况. ...
... ]基于内模原理提出了一种统一的方法来解决异构MAS的输出群同步问题.参考文献[12]通过设计分布式观测器研究了离散MAS的协同输出调节问题.参考文献[11-12]都是基于系统模型得到的结果.然而,在许多实际应用中是无法获取 MAS 的精确模型的.因此,已有的分布式控制方法不能应用于这些系统模型未知的情况. ...
... -12]都是基于系统模型得到的结果.然而,在许多实际应用中是无法获取 MAS 的精确模型的.因此,已有的分布式控制方法不能应用于这些系统模型未知的情况. ...
... 注释2:从算法1可以看出,式(30)基于系统数据求解异构 MAS 的输出同步问题.因此,本文通过强化学习中的 Q 学习克服了已有研究需要系统模型的弊端[12,13]. ...
强化学习:迈向知行合一的智能机制与算法
2
2020
... 强化学习起源于“试错学习”,强调使用基于环境的反馈修改行为,它由英国生物和心理学家Conway Morgan正式提出[13].随后,Werbos P J将强化学习用于求解单系统的最优调节问题[14,15].由于强化学习可以利用系统数据迭代求解最优控制问题,它也被广泛应用于求解MAS问题[7,16,17].例如,参考文献[16]利用离策略强化学习算法求解MAS的最优输出同步问题. ...
... 注释2:从算法1可以看出,式(30)基于系统数据求解异构 MAS 的输出同步问题.因此,本文通过强化学习中的 Q 学习克服了已有研究需要系统模型的弊端[12,13]. ...
强化学习:迈向知行合一的智能机制与算法
2
2020
... 强化学习起源于“试错学习”,强调使用基于环境的反馈修改行为,它由英国生物和心理学家Conway Morgan正式提出[13].随后,Werbos P J将强化学习用于求解单系统的最优调节问题[14,15].由于强化学习可以利用系统数据迭代求解最优控制问题,它也被广泛应用于求解MAS问题[7,16,17].例如,参考文献[16]利用离策略强化学习算法求解MAS的最优输出同步问题. ...
... 注释2:从算法1可以看出,式(30)基于系统数据求解异构 MAS 的输出同步问题.因此,本文通过强化学习中的 Q 学习克服了已有研究需要系统模型的弊端[12,13]. ...
Reinforcement learning and adaptive dynamic programming for feedback control
1
2009
... 强化学习起源于“试错学习”,强调使用基于环境的反馈修改行为,它由英国生物和心理学家Conway Morgan正式提出[13].随后,Werbos P J将强化学习用于求解单系统的最优调节问题[14,15].由于强化学习可以利用系统数据迭代求解最优控制问题,它也被广泛应用于求解MAS问题[7,16,17].例如,参考文献[16]利用离策略强化学习算法求解MAS的最优输出同步问题. ...
H∞ tracking control for linear discrete-time systems via reinforcement learning
1
2020
... 强化学习起源于“试错学习”,强调使用基于环境的反馈修改行为,它由英国生物和心理学家Conway Morgan正式提出[13].随后,Werbos P J将强化学习用于求解单系统的最优调节问题[14,15].由于强化学习可以利用系统数据迭代求解最优控制问题,它也被广泛应用于求解MAS问题[7,16,17].例如,参考文献[16]利用离策略强化学习算法求解MAS的最优输出同步问题. ...
Optimal model-free output synchronization of heterogeneous systems using off-policy reinforcement learning
4
2016
... 强化学习起源于“试错学习”,强调使用基于环境的反馈修改行为,它由英国生物和心理学家Conway Morgan正式提出[13].随后,Werbos P J将强化学习用于求解单系统的最优调节问题[14,15].由于强化学习可以利用系统数据迭代求解最优控制问题,它也被广泛应用于求解MAS问题[7,16,17].例如,参考文献[16]利用离策略强化学习算法求解MAS的最优输出同步问题. ...
... .例如,参考文献[16]利用离策略强化学习算法求解MAS的最优输出同步问题. ...
... 对于大多数求解异构 MAS 输出同步问题的强化学习算法,其价值函数由追踪误差和智能体本身的控制输入组成[16,17,19].这样的价值函数虽然能在一定程度上减少控制成本,但是没有考虑 MAS 拓扑结构对价值函数的影响,即没有考虑邻居智能体对智能体本身的影响.因此需要定义一个包含邻居控制输入信息的性能指标和价值函数,从而减少每个智能体的控制成本. ...
Optimal synchronization of heterogeneous nonlinear systems with unknown dynamics
3
2018
... 强化学习起源于“试错学习”,强调使用基于环境的反馈修改行为,它由英国生物和心理学家Conway Morgan正式提出[13].随后,Werbos P J将强化学习用于求解单系统的最优调节问题[14,15].由于强化学习可以利用系统数据迭代求解最优控制问题,它也被广泛应用于求解MAS问题[7,16,17].例如,参考文献[16]利用离策略强化学习算法求解MAS的最优输出同步问题. ...
... 对于大多数求解异构 MAS 输出同步问题的强化学习算法,其价值函数由追踪误差和智能体本身的控制输入组成[16,17,19].这样的价值函数虽然能在一定程度上减少控制成本,但是没有考虑 MAS 拓扑结构对价值函数的影响,即没有考虑邻居智能体对智能体本身的影响.因此需要定义一个包含邻居控制输入信息的性能指标和价值函数,从而减少每个智能体的控制成本. ...
... 对于大多数求解异构 MAS 输出同步问题的强化学习算法,其价值函数由追踪误差和智能体本身的控制输入组成[16,17,19].这样的价值函数虽然能在一定程度上减少控制成本,但是没有考虑 MAS 拓扑结构对价值函数的影响,即没有考虑邻居智能体对智能体本身的影响.因此需要定义一个包含邻居控制输入信息的性能指标和价值函数,从而减少每个智能体的控制成本. ...












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}