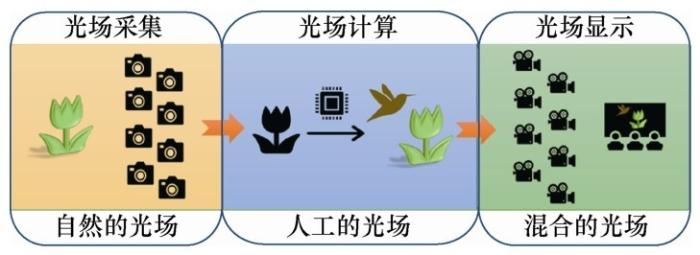
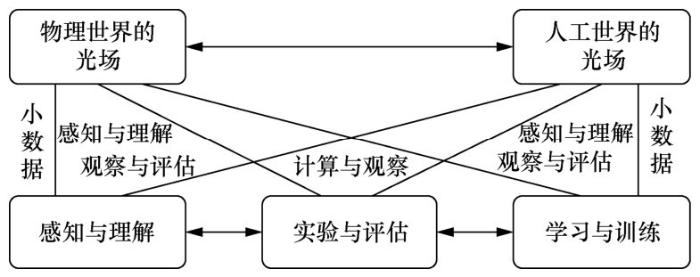
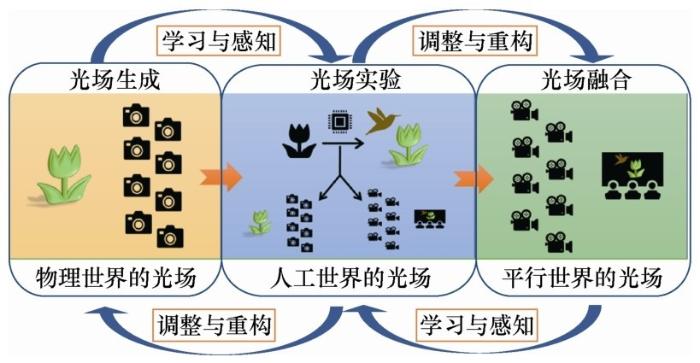
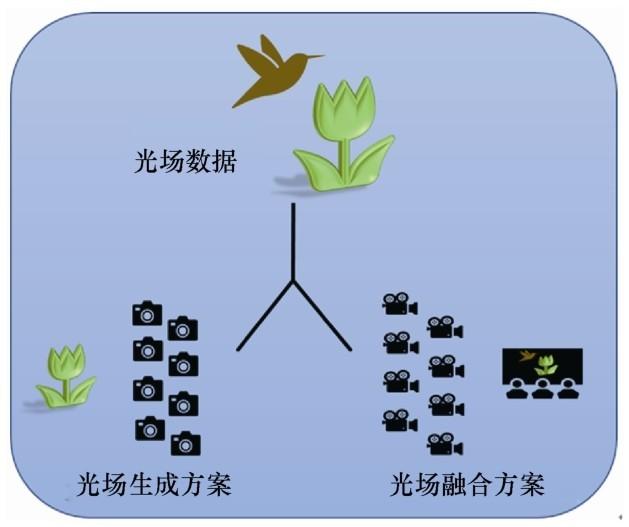
The light field is the collection of lights in the environment, and the acquisition, calculation and display of light field information are extremely challenging and complex issues.The ACP-based theory of parallel light field provides a new and effective way to solve this problem.It used the acquired light field information from the actual physical world to construct an enhanced light field of artificial world.And guided by the light field and other information from the actual physical world, light field experiments were conducted in the enhanced light field in all artificial world to obtain the optimal light field acquisition or display schemes.Finally, the parallel optimization of the physical and artificial light fields was established through the process of parallel execution, so that the entire system become a closed-loop system.In this way, intelligent light field acquisition and display were achieved, and a real-virtual theoretical framework for light field information processing and utilization was established.
Keywords:parallel
;
ACP
;
light field
;
light field display
;
light field acquisition
WANG Fei-Yue. Parallel light field: the framework and processes. Chinese Journal of Intelligent Science and Technology[J], 2021, 3(1): 110-122 doi:10.11959/j.issn.2096-6652.202112
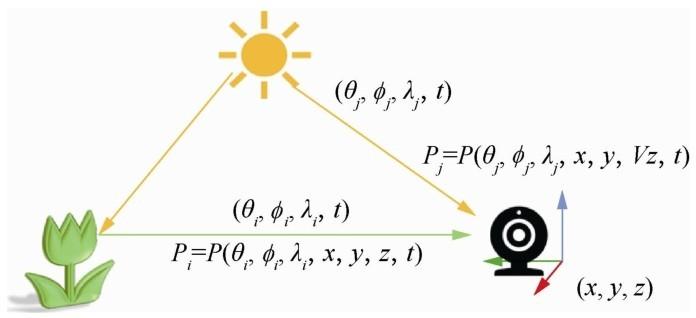
光场采集的目的是获取实际物理世界场景中的光场信息。分析式(1)可以得出,与光场采集相关的变量有7个:相机的位置(x, y, z)、光线的入射角度(θ,φ)、光线波长λ以及采集时间t。因此,单目相机获取的二维图像是一种简单的降维采样后的光场,其仅包含场景中固定位置、单一角度、固定时间的光场。为了尽可能从更多位置、更多角度、更长时间内获取光场信息,目前广泛研究的光场采集方案有3种。图3(a)为美国Adobe系统公司研发的基于微透镜阵列的光场采集[17,18,19],其在成像传感器与主镜头之间加入由多透镜组成的微透镜阵列,使得来自物体一点上的光线经过主镜头汇聚后,在微透镜阵列处散开,然后被相机记录,这种方案的优点是体积小,但是分辨率较低,并且采集的范围有限。图3(b)为Bennett W等人[20]在斯坦福大学研发的基于相机阵列的光场采集系统,该系统将多个标定后的相机分布在不同位置、不同角度,同时对场景的光场进行采集。该方案采集分辨率高,但是所需相机数量多,硬件成本非常高,因此曹煊等人[21]在此基础上提出利用压缩感知和稀疏编码的方案对采集信息进行处理,可以在一定程度上减少相机数量。图3(c)为Kshitij M等人[22]在麻省理工学院设计的基于编码掩模的光场采集相机,其在镜头和成像传感器间加入一片半透明的编码掩模,通过掩模的调制获取环境的信息,进而根据与掩模相关的提前训练好的光场字典恢复场景的光场信息,此采集方案的优点是体积小,缺点是采用半透明掩模会使采集到的光场信噪比较低。
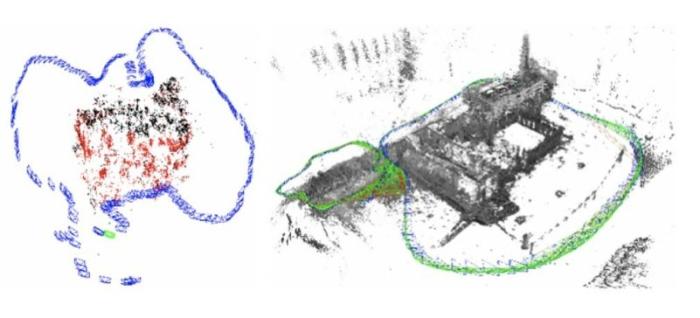
以上技术可以被总结为静态光场采集技术,即通过硬件上改造相机来获取多位置、多角度的光场,除此之外,还可以通过相机的移动来获取多角度、多位置的光场信息,然后再利用相机间的相对位姿信息,将光场信息融合起来,获取环境的全光场信息,因此,此方案的关键在于获取相机移动过程中的位姿信息以及相机合理的移动轨迹。从此角度考虑,同时定位和重建(simultaneous localization and mapping,SLAM)技术[23,24]可以被看作一种动态光场采集技术,其在相机移动的同时实时计算相机的位姿,如果不考虑场景中光线随时间的变化(局部时间内不变),SLAM 采集方案可以被等效为相机阵列光场采集方案。视觉 SLAM 光场采集技术示意图如图4所示。
根据使用传感器的不同,视觉SLAM可以被划分为单目视觉SLAM、双目视觉SLAM以及RGB-D SLAM[24]。传统的SLAM系统由前端和后端两部分组成。前端又称视觉里程计,它根据帧间的匹配关系增量式地恢复相机位姿。根据优化目标的不同,前端使用的方法可被分为直接法和间接法两类[25]。其中直接法以光度误差为优化目标,对相机位姿和路标点进行优化,而间接法的优化目标为重投影误差。因为系统长时间运行会累积噪声,所以在SLAM后端引入了减小误差的策略,具体来说有两种实现方案:滤波和非线性优化。其中非线性优化按照贝叶斯法则求解相机在每个位置的最大似然估计,准确率较高,现已在SLAM系统中得到了广泛应用。除此之外,为了使结果具有全局一致性,SLAM系统还具有含基于外观方法的闭环检测功能。在没有先验信息的场景中,SLAM技术将相机位姿信息和地图数据作为反馈形成闭环,同步迭代,保证了系统的高效稳定运行。此外,随着深度学习技术在计算机视觉领域的发展,业界已逐步开始将深度学习的方法融入视觉SLAM 系统,从而为SLAM系统提供更丰富的环境语义信息[26]。传统的SLAM系统受环境影响较大,在此基础上,孟祥冰等人[27]提出了平行感知理论框架,为解决视觉 SLAM 系统在复杂场景下的精度低、泛化能力差等问题指明了方向。
例如,基于视觉SLAM的动态光场采集通过视觉 SLAM 获取当前场景的相机的位姿以及采集到的光场,并将其反馈给人工世界,光场实验根据此光场信息在人工光场数据库中寻找与之最匹配的信息,以此为优化初值,然后结合物理世界和人工世界的光场搜索得到最优的采集路径以及最优的视觉SLAM方案,通过物理世界中的执行端进行采集,进而形成由人工世界引导的动态采集过程。此方案充分考虑了环境对采集算法的影响,并且充分利用了人工世界的先验知识,既保证了采集的稳定性,又提升了采集精度。
传统的光场采集方案包括微透镜阵列、阵列相机、掩模光场相机等。场景中的光场是稠密的,若要采集到场景中所有位置的光场,需要在场景中所有位置都布置相机,因此实际光场采集需要在采集的稠密性和相机的数量间进行权衡。而移动采集方案(例如视觉SLAM[23]、运动恢复结构(structure from motion,SFM)[46]等)则通过相机的移动在一定程度上解决了静态场景下的光场采集的稠密性问题。SFM 和 SLAM 的区别在于SLAM 需要实时在线地计算相机位姿和场景结构,而SFM则可以在前期完成数据的采集,在后期根据数据完成场景的重建和相机位姿的计算。因此,阵列相机方案结合移动采集方案是获取稠密光场的有效途径。在这个方案中,阵列相机布置方案以及相机的移动方案是稠密采集的关键,因此,需要人工光场的指引,从而构成光场生成的平行执行过程。
当前已有很多成熟的游戏引擎和仿真工具能够完成光场生成的任务,例如Unity、Half-Life 2、Delta3D、OpenGL、Panda3D、Google 3D Warehouse、3DS MAX、OVVV、VDrift等。然而,人工世界的光场中生成的光场需要满足实际物理光场的规律,这些工具均无法直接获取实际物理光场的规律。GAN[47]由 Goodfellow 提出,其通过生成器和判别器的对抗博弈来获得能够生成足够逼真的数据的生成器,并且已经在图像生成、风格迁移、图像转换、场景合成领域被广泛应用。在平行光场中,笔者采用GAN,以实际的物理光场为风格(真)信息,以人工生成的光场为内容信息,利用不断获取的数据对网络进行优化更新,以获取符合实际物理光场规律的光场信息。
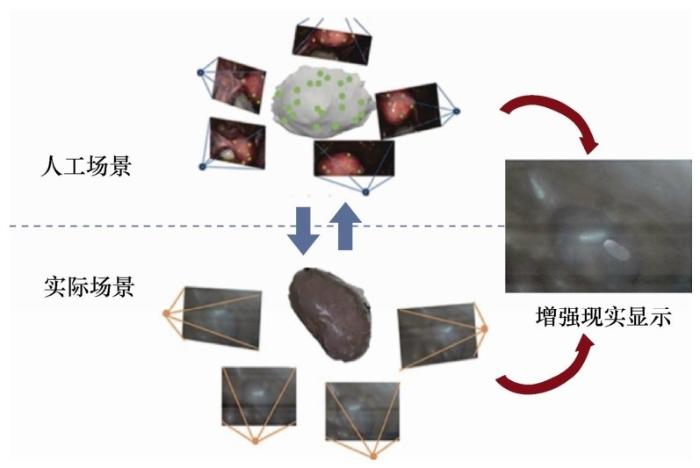
图18 所示是由中国科学院自动化研究所王飞跃团队开发的增强现实系统[27]在肾脏手术中的应用。该系统通过多目相机实时地采集腹腔中的光场信息,通过SLAM技术对该场景信息进行重建,进而获得实时的腹腔场景的三维结构信息。利用该三维结构信息和人工场景中的肾脏模型进行匹配定位,建立起人工场景和实际场景在空间上的关联,进而通过对人工场景进行增强(渲染手术所需的肿瘤等信息),获取融合后的光场信息,最终通过 AR 或真三维显示技术投射到真实的物理世界中,形成平行世界的光场,然后根据物理世界的光场信息的变化,实时调整光场的采集和增强策略。因此该应用几乎涵盖了平行光场从光场采集到光场显示的每个步骤,是平行光场在医疗手术中的典型应用。然而,该应用并没有建立一套完备的人工世界的光场,单纯将采集后的局部光场信息融合到术前采集的信息中。因此,该应用仅可以进行简单的光场实验,是平行光场理论在医学领域的初步探索。
Spatio-angular resolution tradeoffs in integral photography
1
2006
... 光场采集的目的是获取实际物理世界场景中的光场信息.分析式(1)可以得出,与光场采集相关的变量有7个:相机的位置(x, y, z)、光线的入射角度(θ,φ)、光线波长λ以及采集时间t.因此,单目相机获取的二维图像是一种简单的降维采样后的光场,其仅包含场景中固定位置、单一角度、固定时间的光场.为了尽可能从更多位置、更多角度、更长时间内获取光场信息,目前广泛研究的光场采集方案有3种.图3(a)为美国Adobe系统公司研发的基于微透镜阵列的光场采集[17,18,19],其在成像传感器与主镜头之间加入由多透镜组成的微透镜阵列,使得来自物体一点上的光线经过主镜头汇聚后,在微透镜阵列处散开,然后被相机记录,这种方案的优点是体积小,但是分辨率较低,并且采集的范围有限.图3(b)为Bennett W等人[20]在斯坦福大学研发的基于相机阵列的光场采集系统,该系统将多个标定后的相机分布在不同位置、不同角度,同时对场景的光场进行采集.该方案采集分辨率高,但是所需相机数量多,硬件成本非常高,因此曹煊等人[21]在此基础上提出利用压缩感知和稀疏编码的方案对采集信息进行处理,可以在一定程度上减少相机数量.图3(c)为Kshitij M等人[22]在麻省理工学院设计的基于编码掩模的光场采集相机,其在镜头和成像传感器间加入一片半透明的编码掩模,通过掩模的调制获取环境的信息,进而根据与掩模相关的提前训练好的光场字典恢复场景的光场信息,此采集方案的优点是体积小,缺点是采用半透明掩模会使采集到的光场信噪比较低. ...
Light field camera design for integral view photography
1
2008
... 光场采集的目的是获取实际物理世界场景中的光场信息.分析式(1)可以得出,与光场采集相关的变量有7个:相机的位置(x, y, z)、光线的入射角度(θ,φ)、光线波长λ以及采集时间t.因此,单目相机获取的二维图像是一种简单的降维采样后的光场,其仅包含场景中固定位置、单一角度、固定时间的光场.为了尽可能从更多位置、更多角度、更长时间内获取光场信息,目前广泛研究的光场采集方案有3种.图3(a)为美国Adobe系统公司研发的基于微透镜阵列的光场采集[17,18,19],其在成像传感器与主镜头之间加入由多透镜组成的微透镜阵列,使得来自物体一点上的光线经过主镜头汇聚后,在微透镜阵列处散开,然后被相机记录,这种方案的优点是体积小,但是分辨率较低,并且采集的范围有限.图3(b)为Bennett W等人[20]在斯坦福大学研发的基于相机阵列的光场采集系统,该系统将多个标定后的相机分布在不同位置、不同角度,同时对场景的光场进行采集.该方案采集分辨率高,但是所需相机数量多,硬件成本非常高,因此曹煊等人[21]在此基础上提出利用压缩感知和稀疏编码的方案对采集信息进行处理,可以在一定程度上减少相机数量.图3(c)为Kshitij M等人[22]在麻省理工学院设计的基于编码掩模的光场采集相机,其在镜头和成像传感器间加入一片半透明的编码掩模,通过掩模的调制获取环境的信息,进而根据与掩模相关的提前训练好的光场字典恢复场景的光场信息,此采集方案的优点是体积小,缺点是采用半透明掩模会使采集到的光场信噪比较低. ...
Full resolution lightfield rendering
1
2008
... 光场采集的目的是获取实际物理世界场景中的光场信息.分析式(1)可以得出,与光场采集相关的变量有7个:相机的位置(x, y, z)、光线的入射角度(θ,φ)、光线波长λ以及采集时间t.因此,单目相机获取的二维图像是一种简单的降维采样后的光场,其仅包含场景中固定位置、单一角度、固定时间的光场.为了尽可能从更多位置、更多角度、更长时间内获取光场信息,目前广泛研究的光场采集方案有3种.图3(a)为美国Adobe系统公司研发的基于微透镜阵列的光场采集[17,18,19],其在成像传感器与主镜头之间加入由多透镜组成的微透镜阵列,使得来自物体一点上的光线经过主镜头汇聚后,在微透镜阵列处散开,然后被相机记录,这种方案的优点是体积小,但是分辨率较低,并且采集的范围有限.图3(b)为Bennett W等人[20]在斯坦福大学研发的基于相机阵列的光场采集系统,该系统将多个标定后的相机分布在不同位置、不同角度,同时对场景的光场进行采集.该方案采集分辨率高,但是所需相机数量多,硬件成本非常高,因此曹煊等人[21]在此基础上提出利用压缩感知和稀疏编码的方案对采集信息进行处理,可以在一定程度上减少相机数量.图3(c)为Kshitij M等人[22]在麻省理工学院设计的基于编码掩模的光场采集相机,其在镜头和成像传感器间加入一片半透明的编码掩模,通过掩模的调制获取环境的信息,进而根据与掩模相关的提前训练好的光场字典恢复场景的光场信息,此采集方案的优点是体积小,缺点是采用半透明掩模会使采集到的光场信噪比较低. ...
High performance imaging using large camera arrays
1
2005
... 光场采集的目的是获取实际物理世界场景中的光场信息.分析式(1)可以得出,与光场采集相关的变量有7个:相机的位置(x, y, z)、光线的入射角度(θ,φ)、光线波长λ以及采集时间t.因此,单目相机获取的二维图像是一种简单的降维采样后的光场,其仅包含场景中固定位置、单一角度、固定时间的光场.为了尽可能从更多位置、更多角度、更长时间内获取光场信息,目前广泛研究的光场采集方案有3种.图3(a)为美国Adobe系统公司研发的基于微透镜阵列的光场采集[17,18,19],其在成像传感器与主镜头之间加入由多透镜组成的微透镜阵列,使得来自物体一点上的光线经过主镜头汇聚后,在微透镜阵列处散开,然后被相机记录,这种方案的优点是体积小,但是分辨率较低,并且采集的范围有限.图3(b)为Bennett W等人[20]在斯坦福大学研发的基于相机阵列的光场采集系统,该系统将多个标定后的相机分布在不同位置、不同角度,同时对场景的光场进行采集.该方案采集分辨率高,但是所需相机数量多,硬件成本非常高,因此曹煊等人[21]在此基础上提出利用压缩感知和稀疏编码的方案对采集信息进行处理,可以在一定程度上减少相机数量.图3(c)为Kshitij M等人[22]在麻省理工学院设计的基于编码掩模的光场采集相机,其在镜头和成像传感器间加入一片半透明的编码掩模,通过掩模的调制获取环境的信息,进而根据与掩模相关的提前训练好的光场字典恢复场景的光场信息,此采集方案的优点是体积小,缺点是采用半透明掩模会使采集到的光场信噪比较低. ...
Dictionary-based light field acquisition using sparse camera array
1
2014
... 光场采集的目的是获取实际物理世界场景中的光场信息.分析式(1)可以得出,与光场采集相关的变量有7个:相机的位置(x, y, z)、光线的入射角度(θ,φ)、光线波长λ以及采集时间t.因此,单目相机获取的二维图像是一种简单的降维采样后的光场,其仅包含场景中固定位置、单一角度、固定时间的光场.为了尽可能从更多位置、更多角度、更长时间内获取光场信息,目前广泛研究的光场采集方案有3种.图3(a)为美国Adobe系统公司研发的基于微透镜阵列的光场采集[17,18,19],其在成像传感器与主镜头之间加入由多透镜组成的微透镜阵列,使得来自物体一点上的光线经过主镜头汇聚后,在微透镜阵列处散开,然后被相机记录,这种方案的优点是体积小,但是分辨率较低,并且采集的范围有限.图3(b)为Bennett W等人[20]在斯坦福大学研发的基于相机阵列的光场采集系统,该系统将多个标定后的相机分布在不同位置、不同角度,同时对场景的光场进行采集.该方案采集分辨率高,但是所需相机数量多,硬件成本非常高,因此曹煊等人[21]在此基础上提出利用压缩感知和稀疏编码的方案对采集信息进行处理,可以在一定程度上减少相机数量.图3(c)为Kshitij M等人[22]在麻省理工学院设计的基于编码掩模的光场采集相机,其在镜头和成像传感器间加入一片半透明的编码掩模,通过掩模的调制获取环境的信息,进而根据与掩模相关的提前训练好的光场字典恢复场景的光场信息,此采集方案的优点是体积小,缺点是采用半透明掩模会使采集到的光场信噪比较低. ...
Compressive light field photography using over complete dictionaries and optimized projections
1
2013
... 光场采集的目的是获取实际物理世界场景中的光场信息.分析式(1)可以得出,与光场采集相关的变量有7个:相机的位置(x, y, z)、光线的入射角度(θ,φ)、光线波长λ以及采集时间t.因此,单目相机获取的二维图像是一种简单的降维采样后的光场,其仅包含场景中固定位置、单一角度、固定时间的光场.为了尽可能从更多位置、更多角度、更长时间内获取光场信息,目前广泛研究的光场采集方案有3种.图3(a)为美国Adobe系统公司研发的基于微透镜阵列的光场采集[17,18,19],其在成像传感器与主镜头之间加入由多透镜组成的微透镜阵列,使得来自物体一点上的光线经过主镜头汇聚后,在微透镜阵列处散开,然后被相机记录,这种方案的优点是体积小,但是分辨率较低,并且采集的范围有限.图3(b)为Bennett W等人[20]在斯坦福大学研发的基于相机阵列的光场采集系统,该系统将多个标定后的相机分布在不同位置、不同角度,同时对场景的光场进行采集.该方案采集分辨率高,但是所需相机数量多,硬件成本非常高,因此曹煊等人[21]在此基础上提出利用压缩感知和稀疏编码的方案对采集信息进行处理,可以在一定程度上减少相机数量.图3(c)为Kshitij M等人[22]在麻省理工学院设计的基于编码掩模的光场采集相机,其在镜头和成像传感器间加入一片半透明的编码掩模,通过掩模的调制获取环境的信息,进而根据与掩模相关的提前训练好的光场字典恢复场景的光场信息,此采集方案的优点是体积小,缺点是采用半透明掩模会使采集到的光场信噪比较低. ...
基于单目视觉的同时定位与地图构建方法综述
3
2016
... 以上技术可以被总结为静态光场采集技术,即通过硬件上改造相机来获取多位置、多角度的光场,除此之外,还可以通过相机的移动来获取多角度、多位置的光场信息,然后再利用相机间的相对位姿信息,将光场信息融合起来,获取环境的全光场信息,因此,此方案的关键在于获取相机移动过程中的位姿信息以及相机合理的移动轨迹.从此角度考虑,同时定位和重建(simultaneous localization and mapping,SLAM)技术[23,24]可以被看作一种动态光场采集技术,其在相机移动的同时实时计算相机的位姿,如果不考虑场景中光线随时间的变化(局部时间内不变),SLAM 采集方案可以被等效为相机阵列光场采集方案.视觉 SLAM 光场采集技术示意图如图4所示. ...
... 根据使用传感器的不同,视觉SLAM可以被划分为单目视觉SLAM、双目视觉SLAM以及RGB-D SLAM[24].传统的SLAM系统由前端和后端两部分组成.前端又称视觉里程计,它根据帧间的匹配关系增量式地恢复相机位姿.根据优化目标的不同,前端使用的方法可被分为直接法和间接法两类[25].其中直接法以光度误差为优化目标,对相机位姿和路标点进行优化,而间接法的优化目标为重投影误差.因为系统长时间运行会累积噪声,所以在SLAM后端引入了减小误差的策略,具体来说有两种实现方案:滤波和非线性优化.其中非线性优化按照贝叶斯法则求解相机在每个位置的最大似然估计,准确率较高,现已在SLAM系统中得到了广泛应用.除此之外,为了使结果具有全局一致性,SLAM系统还具有含基于外观方法的闭环检测功能.在没有先验信息的场景中,SLAM技术将相机位姿信息和地图数据作为反馈形成闭环,同步迭代,保证了系统的高效稳定运行.此外,随着深度学习技术在计算机视觉领域的发展,业界已逐步开始将深度学习的方法融入视觉SLAM 系统,从而为SLAM系统提供更丰富的环境语义信息[26].传统的SLAM系统受环境影响较大,在此基础上,孟祥冰等人[27]提出了平行感知理论框架,为解决视觉 SLAM 系统在复杂场景下的精度低、泛化能力差等问题指明了方向. 10.11959/j.issn.2096-6652.202112.F003
... 传统的光场采集方案包括微透镜阵列、阵列相机、掩模光场相机等.场景中的光场是稠密的,若要采集到场景中所有位置的光场,需要在场景中所有位置都布置相机,因此实际光场采集需要在采集的稠密性和相机的数量间进行权衡.而移动采集方案(例如视觉SLAM[23]、运动恢复结构(structure from motion,SFM)[46]等)则通过相机的移动在一定程度上解决了静态场景下的光场采集的稠密性问题.SFM 和 SLAM 的区别在于SLAM 需要实时在线地计算相机位姿和场景结构,而SFM则可以在前期完成数据的采集,在后期根据数据完成场景的重建和相机位姿的计算.因此,阵列相机方案结合移动采集方案是获取稠密光场的有效途径.在这个方案中,阵列相机布置方案以及相机的移动方案是稠密采集的关键,因此,需要人工光场的指引,从而构成光场生成的平行执行过程. ...
基于单目视觉的同时定位与地图构建方法综述
3
2016
... 以上技术可以被总结为静态光场采集技术,即通过硬件上改造相机来获取多位置、多角度的光场,除此之外,还可以通过相机的移动来获取多角度、多位置的光场信息,然后再利用相机间的相对位姿信息,将光场信息融合起来,获取环境的全光场信息,因此,此方案的关键在于获取相机移动过程中的位姿信息以及相机合理的移动轨迹.从此角度考虑,同时定位和重建(simultaneous localization and mapping,SLAM)技术[23,24]可以被看作一种动态光场采集技术,其在相机移动的同时实时计算相机的位姿,如果不考虑场景中光线随时间的变化(局部时间内不变),SLAM 采集方案可以被等效为相机阵列光场采集方案.视觉 SLAM 光场采集技术示意图如图4所示. ...
... 根据使用传感器的不同,视觉SLAM可以被划分为单目视觉SLAM、双目视觉SLAM以及RGB-D SLAM[24].传统的SLAM系统由前端和后端两部分组成.前端又称视觉里程计,它根据帧间的匹配关系增量式地恢复相机位姿.根据优化目标的不同,前端使用的方法可被分为直接法和间接法两类[25].其中直接法以光度误差为优化目标,对相机位姿和路标点进行优化,而间接法的优化目标为重投影误差.因为系统长时间运行会累积噪声,所以在SLAM后端引入了减小误差的策略,具体来说有两种实现方案:滤波和非线性优化.其中非线性优化按照贝叶斯法则求解相机在每个位置的最大似然估计,准确率较高,现已在SLAM系统中得到了广泛应用.除此之外,为了使结果具有全局一致性,SLAM系统还具有含基于外观方法的闭环检测功能.在没有先验信息的场景中,SLAM技术将相机位姿信息和地图数据作为反馈形成闭环,同步迭代,保证了系统的高效稳定运行.此外,随着深度学习技术在计算机视觉领域的发展,业界已逐步开始将深度学习的方法融入视觉SLAM 系统,从而为SLAM系统提供更丰富的环境语义信息[26].传统的SLAM系统受环境影响较大,在此基础上,孟祥冰等人[27]提出了平行感知理论框架,为解决视觉 SLAM 系统在复杂场景下的精度低、泛化能力差等问题指明了方向. 10.11959/j.issn.2096-6652.202112.F003
... 传统的光场采集方案包括微透镜阵列、阵列相机、掩模光场相机等.场景中的光场是稠密的,若要采集到场景中所有位置的光场,需要在场景中所有位置都布置相机,因此实际光场采集需要在采集的稠密性和相机的数量间进行权衡.而移动采集方案(例如视觉SLAM[23]、运动恢复结构(structure from motion,SFM)[46]等)则通过相机的移动在一定程度上解决了静态场景下的光场采集的稠密性问题.SFM 和 SLAM 的区别在于SLAM 需要实时在线地计算相机位姿和场景结构,而SFM则可以在前期完成数据的采集,在后期根据数据完成场景的重建和相机位姿的计算.因此,阵列相机方案结合移动采集方案是获取稠密光场的有效途径.在这个方案中,阵列相机布置方案以及相机的移动方案是稠密采集的关键,因此,需要人工光场的指引,从而构成光场生成的平行执行过程. ...
Past,present,and future of simultaneous localization and mapping:toward the robust-perception age
2
2016
... 以上技术可以被总结为静态光场采集技术,即通过硬件上改造相机来获取多位置、多角度的光场,除此之外,还可以通过相机的移动来获取多角度、多位置的光场信息,然后再利用相机间的相对位姿信息,将光场信息融合起来,获取环境的全光场信息,因此,此方案的关键在于获取相机移动过程中的位姿信息以及相机合理的移动轨迹.从此角度考虑,同时定位和重建(simultaneous localization and mapping,SLAM)技术[23,24]可以被看作一种动态光场采集技术,其在相机移动的同时实时计算相机的位姿,如果不考虑场景中光线随时间的变化(局部时间内不变),SLAM 采集方案可以被等效为相机阵列光场采集方案.视觉 SLAM 光场采集技术示意图如图4所示. ...
... 根据使用传感器的不同,视觉SLAM可以被划分为单目视觉SLAM、双目视觉SLAM以及RGB-D SLAM[24].传统的SLAM系统由前端和后端两部分组成.前端又称视觉里程计,它根据帧间的匹配关系增量式地恢复相机位姿.根据优化目标的不同,前端使用的方法可被分为直接法和间接法两类[25].其中直接法以光度误差为优化目标,对相机位姿和路标点进行优化,而间接法的优化目标为重投影误差.因为系统长时间运行会累积噪声,所以在SLAM后端引入了减小误差的策略,具体来说有两种实现方案:滤波和非线性优化.其中非线性优化按照贝叶斯法则求解相机在每个位置的最大似然估计,准确率较高,现已在SLAM系统中得到了广泛应用.除此之外,为了使结果具有全局一致性,SLAM系统还具有含基于外观方法的闭环检测功能.在没有先验信息的场景中,SLAM技术将相机位姿信息和地图数据作为反馈形成闭环,同步迭代,保证了系统的高效稳定运行.此外,随着深度学习技术在计算机视觉领域的发展,业界已逐步开始将深度学习的方法融入视觉SLAM 系统,从而为SLAM系统提供更丰富的环境语义信息[26].传统的SLAM系统受环境影响较大,在此基础上,孟祥冰等人[27]提出了平行感知理论框架,为解决视觉 SLAM 系统在复杂场景下的精度低、泛化能力差等问题指明了方向. ...
Simultaneous localization and mapping:a survey of current trends in autonomous driving
1
2017
... 根据使用传感器的不同,视觉SLAM可以被划分为单目视觉SLAM、双目视觉SLAM以及RGB-D SLAM[24].传统的SLAM系统由前端和后端两部分组成.前端又称视觉里程计,它根据帧间的匹配关系增量式地恢复相机位姿.根据优化目标的不同,前端使用的方法可被分为直接法和间接法两类[25].其中直接法以光度误差为优化目标,对相机位姿和路标点进行优化,而间接法的优化目标为重投影误差.因为系统长时间运行会累积噪声,所以在SLAM后端引入了减小误差的策略,具体来说有两种实现方案:滤波和非线性优化.其中非线性优化按照贝叶斯法则求解相机在每个位置的最大似然估计,准确率较高,现已在SLAM系统中得到了广泛应用.除此之外,为了使结果具有全局一致性,SLAM系统还具有含基于外观方法的闭环检测功能.在没有先验信息的场景中,SLAM技术将相机位姿信息和地图数据作为反馈形成闭环,同步迭代,保证了系统的高效稳定运行.此外,随着深度学习技术在计算机视觉领域的发展,业界已逐步开始将深度学习的方法融入视觉SLAM 系统,从而为SLAM系统提供更丰富的环境语义信息[26].传统的SLAM系统受环境影响较大,在此基础上,孟祥冰等人[27]提出了平行感知理论框架,为解决视觉 SLAM 系统在复杂场景下的精度低、泛化能力差等问题指明了方向. ...
... 传统的光场采集方案包括微透镜阵列、阵列相机、掩模光场相机等.场景中的光场是稠密的,若要采集到场景中所有位置的光场,需要在场景中所有位置都布置相机,因此实际光场采集需要在采集的稠密性和相机的数量间进行权衡.而移动采集方案(例如视觉SLAM[23]、运动恢复结构(structure from motion,SFM)[46]等)则通过相机的移动在一定程度上解决了静态场景下的光场采集的稠密性问题.SFM 和 SLAM 的区别在于SLAM 需要实时在线地计算相机位姿和场景结构,而SFM则可以在前期完成数据的采集,在后期根据数据完成场景的重建和相机位姿的计算.因此,阵列相机方案结合移动采集方案是获取稠密光场的有效途径.在这个方案中,阵列相机布置方案以及相机的移动方案是稠密采集的关键,因此,需要人工光场的指引,从而构成光场生成的平行执行过程. ...
Generative adversarial networks
2
2014
... 当前已有很多成熟的游戏引擎和仿真工具能够完成光场生成的任务,例如Unity、Half-Life 2、Delta3D、OpenGL、Panda3D、Google 3D Warehouse、3DS MAX、OVVV、VDrift等.然而,人工世界的光场中生成的光场需要满足实际物理光场的规律,这些工具均无法直接获取实际物理光场的规律.GAN[47]由 Goodfellow 提出,其通过生成器和判别器的对抗博弈来获得能够生成足够逼真的数据的生成器,并且已经在图像生成、风格迁移、图像转换、场景合成领域被广泛应用.在平行光场中,笔者采用GAN,以实际的物理光场为风格(真)信息,以人工生成的光场为内容信息,利用不断获取的数据对网络进行优化更新,以获取符合实际物理光场规律的光场信息. ...
图18 所示是由中国科学院自动化研究所王飞跃团队开发的增强现实系统[27]在肾脏手术中的应用.该系统通过多目相机实时地采集腹腔中的光场信息,通过SLAM技术对该场景信息进行重建,进而获得实时的腹腔场景的三维结构信息.利用该三维结构信息和人工场景中的肾脏模型进行匹配定位,建立起人工场景和实际场景在空间上的关联,进而通过对人工场景进行增强(渲染手术所需的肿瘤等信息),获取融合后的光场信息,最终通过 AR 或真三维显示技术投射到真实的物理世界中,形成平行世界的光场,然后根据物理世界的光场信息的变化,实时调整光场的采集和增强策略.因此该应用几乎涵盖了平行光场从光场采集到光场显示的每个步骤,是平行光场在医疗手术中的典型应用.然而,该应用并没有建立一套完备的人工世界的光场,单纯将采集后的局部光场信息融合到术前采集的信息中.因此,该应用仅可以进行简单的光场实验,是平行光场理论在医学领域的初步探索. ...



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}