












1 引言
传统的负荷预测只考虑历史负荷数据、气温、降雨量等结构化数据,具有一定的局限性。事实上,电力负荷除了与历史负荷有关,还受到政策宏观调控、经济等多方面因素的影响,这些因素随机多变,并能显著影响智能电网的电力负荷[1]。因此,对智能电网进行负荷预测会涉及社会学与经济学等理论。
目前,国内外学者对如何将政策措施加入负荷预测中的研究较少。Li X L等人[2]分析了环保政策对区域短期电力负荷的影响,将空气质量指数作为环保措施的政策影响变量加入基于樽海鞘群算法(salp swarm algorithm,SSA)和最小二乘支持向量机(least squares support vector machine,LSSVM)的短期负荷预测模型,取得了良好的效果。Zhao L N等人[3]深入分析了新经济常态的特点,提炼出能够正确表征新常态变化的因素,并将其应用于中长期负荷预测模型中。Chen X等人[4]分析了温度、湿度、气压等8个气象因素对负荷的影响,并采用支持向量机(support vector machine,SVM)和反向传播(back propagation,BP)神经网络进行组合预测。上述方法在一定程度上弥补了只考虑单一历史负荷影响因素的缺陷,但必须指出的是,这些方法对政策因素的处理方式过于简单,没有考虑电力负荷与政策因素之间复杂的非线性关系,无法很好地量化政策宏观调控对区域负荷的影响。
政策评价理论在经济、社会、科技等领域的发展为学者将电力政策应用到负荷预测中提供了新思路。政策评价是一种具有判断、衡量政策方案的复杂系统工程,国内外学者对政策的量化处理采用定性与定量相结合的方法,包括文献计量、内容分析法、图论、网络分析、知识图谱等[5]。例如,范梓腾等人[6]从政策“目标-工具”匹配的角度对大数据发展政策开展文献量化研究,认为我国地方政府应该给予需求面政策工具更多的关注,解决大数据发展政策中的“目标-工具”的错配现象。Dantas G A等人[7]通过德尔菲法评估巴西电网代表性创新政策的有效性,分析不同专家之间的共识和分歧所在,最终确定哪些政策是有前景的,为政策制定者提供决策依据。李樵[8]为了探究我国大数据发展政策工具选择体系结构的有效性,运用内容分析法对63项大数据发展政策文本包含的政策工具进行编码,认为我国大数据政策工具缺乏长期规划,政策及政策工具协同不足,应加强战略规划和发展理念指引,重视政策及政策工具协同。汪晓梦[9]基于相关性和灰色关联分析的视角对区域性技术创新政策绩效评价予以实证研究,并选取合肥市作为案例进行分析。Stolbova V等人[10]将金融因素加入气候政策评估模型,提出了金融宏观网络方法,并将其应用到欧元区经济体中,实证分析了金融部门与实体经济之间的反馈循环,为全面评估气候政策对经济的影响提供了一个新的视角。
上述评价方法在特定领域都取得了不错的效果,但仍存在一些缺陷。例如灰色关联模型受主观因素影响较大;层次分析法在进行多指标政策评价时效果不佳;BP 神经网络模型运行速度较慢,存在过拟合、局部极小化等问题,对超参数设置能力有一定要求。针对上述问题,本文采用政策建模一致性(policy modeling consistency,PMC)指数模型对电力政策进行量化评价,该模型主要通过文本挖掘方式获取原始数据,能够在很大程度上避免主观性,并提高评价准确度。为了验证 PMC 指数模型的有效性,本文将 PMC 政策量化结果与其他电力负荷影响因素一同输入长短期记忆(long short term memory,LSTM)负荷预测模型中,与不考虑政策因素的负荷预测模型进行对比,模型整体结构如图1所示。总体而言,本文的主要贡献如下。
(1)针对传统负荷预测没有考虑到电力负荷与政策因素之间复杂的非线性关系这一问题,本文重点研究如何对政策措施进行客观评价,首次将PMC指数模型应用到电力政策领域,通过文本挖掘技术和 PMC 指数模型将难以刻画的政策因素转换为能够计算分析的指标变量。
图1

(2)针对传统负荷预测只考虑单一历史负荷影响因素的问题,本文在考虑政策因素的同时,选取日期、气温、天气、降雨量等电力负荷影响指标作为负荷预测模型的输入,使用灰色关联分析(grey relational analysis,GRA)相似日算法对训练集进行扩充,提高了负荷预测模型精度。
(3)将PMC指数模型与LSTM负荷预测模型结合,建立考虑政策因素的短期负荷预测模型,对中国中部地区的日前电力负荷进行预测,使用相关指标对模型结果进行评价,验证了 PMC 政策量化模型的有效性。
本文的其余部分组织如下。第 2 节介绍 PMC政策量化评价模型;第3节介绍所构建的LSTM负荷预测模型,包括建模思想和变量选择、训练样本集设置和负荷预测技术;第 4~5 节以我国中部地区日前电力负荷预测为例,给出实证结果;第6节对全文进行总结。
2 PMC政策量化评价模型
本文将Estrada M A R [11]提出的PMC指数模型作为评估政策建模的工具。该模型以Estrada M A R于 2008 年提出的 Omnia Mobilis 假说为指导思想,认为世间万物皆因存在关联而十分重要,变量选取应该尽量详尽。该模型可以分析某一具体政策模型的一致性水平,并且能够直观了解待评价政策的优势和缺陷,以及这些变量的具体含义和所代表的水平。
为了适应电力政策量化,本文对 PMC 指数模型建立过程进行了改进,具体来说,PMC指数模型建立有如下步骤:
● 设定政策变量与参数;
● 建立多输入-多输出表;
● 计算两级变量值及PMC指数。
得到 PMC 指数后,将其作为电力政策量化结果加入LSTM负荷预测网络,整体模型框架如图1所示。
2.1 变量分类与参数设置
电力政策的出台会对经济、社会、技术、环境等产生重要影响。通常来说,电力政策在相关部门的引导、激励、监管、约束下,会对电力市场产生一系列新的影响,这些影响通过一定的渠道以负荷变化的形式表现出来,负荷变化又对电力政策产生影响,从而形成一个完整的循环链,如图2所示。
本文参照上述电力政策作用机理,结合我国电力政策的具体特点确立了 8 个一级变量和 29 个二级变量,具体变量设计见表1。
为了体现变量选取的全面性和代表性,本文在选取一级变量和二级变量的过程中,对电力政策文献进行概念化和范畴化分析。首先,通过对政策文本原始内容的研读和判别,抽取能够反映政策文本核心内容的开放性编码概念结果。其次,在反复比较和循环论证后,将具有相近或相似含义的概念进一步提炼为范畴。最终,本文提取出 8 个一级变量,其中X1表征政策目标维度;X2、X3、X4、X6表征政策力度维度;X5、X7、X8表征政策措施维度。
2.2 建立多输入-多输出表
多输入-多输出表是一种可存储大量数据、对单个变量采用多维度测量的数据分析框架,具体见表2。多输入-输出表由一级变量和二级变量组成,其中一级变量没有固定的排列顺序且相互独立,每个一级变量可以包含任意数量的二级变量,这是因为在 PMC 指数建模过程中,研究者关心的是一个政策在某个特定领域有无影响,并不需要对变量重要性进行排序。每个一级变量下的所有二级变量都拥有相同的权重,并且取值始终为0或者1。
图2
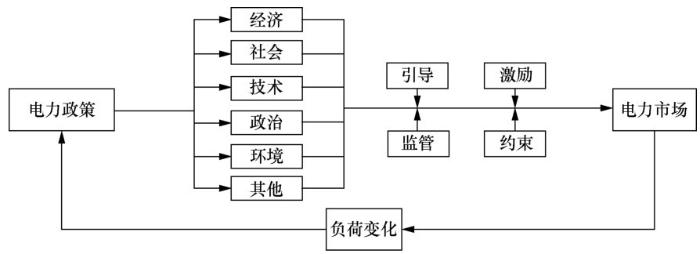
表1 电力政策评价变量
| 一级变量 | 二级变量 | 二级变量含义 | 二级变量评价标准 |
| 政策性质X1 | X1:1 | 预测 | 体现预测性,有则为1,没有为0 |
| X1:2 | 建议 | 提出建议,有则为1,没有为0 | |
| X1:3 | 监管 | 体现监管性,有则为1,没有为0 | |
| X1:4 | 支持 | 体现支持特征,有则为1,没有为0 | |
| X1:5 | 引导 | 包含引导性,有则为1,没有为0 | |
| 政策效力X2 | X2:1 | 长期 | 涉及多于10年的内容,有为1,没有为0 |
| X2:2 | 中期 | 涉及5~10年内容,有则为1,没有为0 | |
| X2:3 | 短期 | 涉及1~5年内容,有则为1,没有为0 | |
| 政策级别X3 | X3:1 | 全国 | 政策范围涉及全国,是为1,否则为0 |
| X3:2 | 全省 | 政策范围涉及全省,是为1,否则为0 | |
| X3:3 | 全市 | 政策范围涉及全市,是为1,否则为0 | |
| X3:4 | 区县 | 政策范围涉及区县,是为1,否则为0 | |
| 政策领域X4 | X4:1 | 经济 | 政策领域涉及经济,是为1,否则为0 |
| X4:2 | 社会服务 | 政策领域涉及社会服务,是为1,否则为0 | |
| X4:3 | 环境 | 政策领域涉及环境,是为1,否则为0 | |
| X4:4 | 制度 | 政策领域涉及制度,是为1,否则为0 | |
| X4:5 | 技术 | 政策领域涉及技术,是为1,否则为0 | |
| 激励约束X5 | X5:1 | 政府补贴 | 涉及政府补贴内容,有则为1,没有为0 |
| X5:2 | 专项基金 | 涉及专项基金内容,有则为1,没有为0 | |
| X5:3 | 法律法规 | 涉及法律法规内容,有则为1,没有为0 | |
| 政策受体X6 | X6:1 | 各部委 | 涉及国家各部委,有则为1,没有为0 |
| X6:2 | 省、自治区、直辖市 | 涉及省、自治区、直辖市,有则为1,没有为0 | |
| X6:3 | 国家电网 | 涉及国家电网,有则为1,没有为0 | |
| 政策重点X7 | X7:1 | 能源价格 | 涉及能源价格内容,有则为1,没有为0 |
| X7:2 | 能源投资 | 涉及能源投资内容,有则为1,没有为0 | |
| X7:3 | 环境保护 | 涉及环境保护内容,有则为1,没有为0 | |
| X7:4 | 安全防护 | 涉及安全防护内容,有则为1,没有为0 | |
| X7:5 | 电力改革 | 涉及电力改革内容,有则为1,没有为0 | |
| X7:6 | 节能减排 | 涉及节能减排内容,有则为1,没有为0 | |
| 政策公开X8 | — | — | 政策公开发布,是为1,否则为0 |
表2 多输入-多输出表
| 一级变量 | 二级变量 |
| X1 | X1:1 X1:2 X1:3 X1:4 X1:5 |
| X2 | X2:1 X2:2 X2:3 |
| X3 | X3:1 X3:2 X3:3 X3:4 |
| X4 | X4:1 X4:2 X4:3 X4:4 X4:5 |
| X5 | X5:1 X5:2 X5:3 |
| X6 | X6:1 X6:2 X6:3 |
| X7 | X7:1 X7:2 X7:3 X7:4 X7:5 X7:6 |
| X8 | — |
2.3 计算PMC指数
PMC指数的测量包括4个步骤。第一步是将8 个一级变量和 29 个二级变量放入多输入-多输出表(见表2);第二步是根据各二级变量评价标准逐个评估二级变量,见计算式(1);第三步是计算每个一级变量的值,它等于所有二级变量的总和除以二级变量的总数,见计算式(2);第四步是对 PMC指数的实际测量,PMC指数等于所有主要变量的总和,见计算式(3)。
其中,Xt为一级变量;Xtj为二级变量;m为一级变量数;n为二级变量数,函数 T( )表示计算所有二次变量的个数。
3 考虑政策措施影响的短期负荷预测模型
3.1 GRA相似日算法
在考虑多种负荷影响因素的情况下,发现预测日的特征与以周或年为周期的历史日的特征具有一定差异。为了更好地训练模型学习影响因素与预测目标间的关系,有必要从历史样本集中选取与预测日特征相似的一天作为训练样本,这就需要用到GRA相似日算法。
本文采用 GRA[12]从历史样本数据集中选择与待预测日气象特征相似的相似日变量作为输入模型的强相关变量。GRA的基本思想是通过计算两个时间序列变量之间的关联度值来判断两者的相似度,具体计算步骤如下。
(1)构建序列矩阵
本文将待预测日的气象因素特征作为参考序列
(2)数据归一化处理
数据归一化是为了消除数据的量纲,并将其映射到0到1的范围内。若m=1代表温度,则待预测日的温度时间序列为
其中,
(3)计算关联系数
基于数据归一化后的各个时间序列,分别计算参考序列中各气象因素特征与比较序列中对应的气象因素特征之间的关联系数,如计算式(5)所示:
其中,σit为待预测日之前第i天第t时刻的关联系数;
(4)计算关联度
待预测日之前第i天的气象特征与待预测日气象特征的灰色关联度Ri表示为:
(5)选择相似日特征变量
依据式(1)~式(4)计算出第i天的关联度,并取关联度Ri> 0.8的变量作为相似日特征变量。最后,若待预测日是工作日,则只保留是工作日的相似日特征变量;若待预测日是节假日,则只保留节假日的相似日特征变量。
3.2 LSTM负荷预测模型
LSTM网络结构可以对长时间以来的历史负荷变化规律进行学习,又不至于引发梯度消失问题进而对模型训练造成影响,能够在有效地学习历史负荷的变化规律同时,建立各负荷影响因素与电力需求间的映射关系。
图3 给出了一个简单的 LSTM 网络神经元结构,其中引入3种“门”来进行神经单元的状态更新与传递,分别是输入门、输出门和遗忘门。“门”结构实际上是一个取值在[0,1]的系数,“门”结构将代替之前的环状信息流完成隐藏层间各单元状态的传递。LSTM网络神经元的运作机制如下。
图3
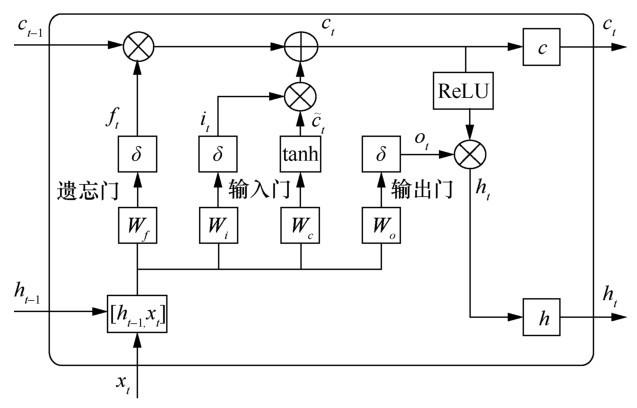
首先按如下计算式计算3个“门”的系数:
然后根据当前时刻的输入和上一个时刻的输出来更新神经元的状态值:
最后计算输出值:
其中,xt为输入值,it、ft和ot分别表示时刻t下的3个“门”的系数值,ct表示t时刻的神经元状态, ht表示t时刻的输出值,σ是 sigmoid 函数,
4 实验设置
本节将介绍模型建立的细节,包括模型的构建思想、变量选择方式、实验数据集建立方式以及模型设置节。
4.1 模型构建思想与变量选择
本文构建考虑电力政策措施影响的LSTM负荷预测模型的基本思路是:在传统负荷预测模型的基础上,引入PMC指数作为政策影响变量,构建PMC指数与区域短期负荷之间的映射关系,从而预测电力负荷。
图4

4.2 实验数据集
本实验所用的电力政策数据集来自国家电网有限公司官网、中国电力企业官网,主要通过网络爬虫技术获取,整个数据集包括2013年12月至2018年12月的11 350篇电力政策新闻。为了进行负荷预测实验,本文还选取华中地区4个省份2013年12月至2018年12月每日的电力负荷、日期类型、气候数据,构建了负荷预测数据集。
为了将天气状态、星期和节假日数据加入预测模型,本文对其进行了编码。天气状态主要以晴、阴、雨和雪为代表,考虑到雨和雪的差异主要是由气温的不同造成的,一概可以认为是降水过程,因此本文将天气状态编码为3类:1代表晴,2代表阴,3代表降雨或降雪。对于星期的量化编码,采用与人们经验一致的方式,即1代表星期一,2代表星期二,依此类推。根据每年国务院颁发的法定节假日安排,对节假日进行编码,1 代表当日为工作日,2 代表当日为节假日,涉及的节假日包括元旦、春节、清明节、劳动节、端午节、中秋节以及国庆节。本文选取的电力负荷影响因素包括温度、降雨量、日期类型、天气类型等,各变量及取值规则见表3。
表3 电力负荷影响因素及取值
| 变量名称 | 单位 | 取值规则 |
| 日平均负荷 | MW | 每日负荷实际值 |
| 日平均气温 | ℃ | 每日气温实际值 |
| 降雨量 | mm | 每日降雨量实际值 |
| 日期类型 | — | 1代表工作日,2代表节假日 |
| 天气类型 | — | 1代表晴,2代表阴,3代表降雨或降雪 |
最终获得了4 740条负荷预测样本数据,其中3 017条数据为训练集,948条数据为验证集,775条数据为测试集。上述数据在输入模型前均应完成归一化处理,将数据映射到[-1,1],以避免模型不收敛的问题。计算式如下:
其中,xmax、xmin分别为变量的极大值与极小值,X∗为归一化结果。
4.3 负荷预测模型设置细节
为了确定LSTM参数的最优值,本文采用网格搜索的方法,在训练集上进行了5次交叉验证。使用Keras平台搭建LSTM负荷预测模型,模型训练中的超参数设置如下:模型包含 3 个 LSTM 层, LSTM 隐藏向量维度分别为 200、150、100;批大小(batch size)为128;迭代次数(epoch)为300;随机失活(dropout)设置为0.2;训练算法为Adam。
5 实验结果
5.1 PMC指数计算结果
根据第2.3节提出的PMC指数计算步骤,通过文本挖掘法量化得到多输入-多输出表,并计算得出各项政策的PMC指数。同时根据Estrada M A R文章中提出的评价标准进行修改,将所得到的PMC指数划分成4个等级:如果PMC指数在8和9之间,那么这个政策文本就是“优秀”;如果PMC指数在6和7.9之间,那么这个政策文本就是“良好”;PMC指数在4和5.9之间,那么这个政策文本就是“可接受”;如果PMC指数在0和3.9之间,那么该政策文本就是“不良”,具体规则见表4。
PMC指数模型对评价对象无特殊要求,可以对任何一项电力政策进行全面分析和评估。表5展示了3个政策文本的PMC指数计算结果,并且根据政策评分标准,对9项电力政策进行等级划分。
表5 政策文本的PMC指数计算结果
| 政策一级指标 | 政策文本1的PMC指数 | 政策文本2的PMC指数 | 政策文本3的PMC指数 |
| 政策性质X1 | 0.3 | 0.3 | 0.4 |
| 政策效力X2 | 0.67 | 0.23 | 0.33 |
| 政策级别X3 | 0.5 | 0.5 | 0.5 |
| 政策领域X4 | 0.2 | 0.4 | 0.4 |
| 激励约束X5 | 0.67 | 0.77 | 0.33 |
| 政策受体X6 | 0.4 | 0.75 | 1 |
| 政策重点X7 | 0.23 | 0.83 | 0.4 |
| 政策公开X8 | 1 | 1 | 1 |
| PMC指数 | |||
| 等级 | 不良 | 可接受 | 可接受 |
从表5可以看出,政策文本1的PMC指数为3.97,等级为“不良”,其一级变量中政策领域 X4和政策重点 X7 得分较低,这表明该政策重点不明确,整体不具备科学性;政策文本2的PMC指数为4.78,等级为“可接受”,并且激励约束X5和政策重点 X7 得分较高,而政策性质 X1 和政策效力X2 得分较低,这表明该政策整体重点突出,制定合理,但是政策效力较差;政策文本3的PMC指数为4.36,等级为“可接受”,并且政策效力X2和激励约束 X5 较低,其他一级变量得分适中,这表明该政策级别较低,效力也较差。
5.2 负荷预测结果
为了进一步评估PMC政策量化模型的有效性,本文将政策量化结果输入LSTM负荷预测网络,并与其他先进的方法进行对比,主要包括支持向量机和人工神经网络两个负荷预测模型。本文先将不包含政策量化结果的数据集输入实验模型,观察负荷预测结果;然后将包含政策量化结果的数据集输入实验模型,与不考虑政策因素的实验结果进行对比,衡量政策因素对负荷预测的影响,进而判断PMC政策量化模型是否有效。
为了衡量模型训练结果、评价负荷预测的准确度,本文采用平均绝对百分比误差(mean absolute percentage error,MAPE)和平均绝对误差(mean absolute error,MSE)对负荷预测结果进行评价。式(13)和式(14)如下:
其中,n为样本的数量,yi为第i条训练样本的实际值,
为了进行无偏比较,本文采用网格搜索法和5次交叉验证的方法来选择支持向量机参数的最优值。采用径向基函数,将径向基核的γ参数设为 32.12,误差代价C设为2。神经网络采用3层反向传播(back propagation,BP)网络作为基准模型。输出层具有1 个节点,并且使用线性传递函数,而隐藏层具有10个节点,并且使用sigmoid作为激活函数。为了优化神经网络的参数,本文构建了一个基于动量梯度下降和自适应学习速率的反向传播的多层感知器。将验证检查设置为 100,以防止模型欠拟合,并选择200个epoch作为训练的收敛准则,以防止过拟合。在训练过程中测试了 0.5%、0.2%、0.05%、0.01%和0.005%的学习率,最终将0.01%作为初始学习率。
图5

对上述3个模型分别计算MAPE和MAE,对比结果见表6。通过比较发现,LSTM 负荷预测模型在加入政策因素后,负荷预测准确度提升最高,网络模型结果指标均优于其他两组。这表明基于人工智能技术的负荷预测模型能更好地反映政策因素与电力负荷之间的变化关系,具有更好的政策理解能力。
表6 负荷预测结果误差对比
| 模型 | MAPE(包含政策) | MAPE(不包含政策) | MAE(包含政策) | MAE(不包含政策) |
| LSTM | 0.98 | 1.67 | 19.68 | 28.97 |
| BP神经网络 | 1.24 | 1.78 | 24.22 | 34.87 |
| SVM | 1.73 | 2.24 | 37.56 | 44.63 |
6 结束语
本文展示了如何利用PMC模型对电力政策进行评价量化,并将结果应用到电力负荷预测中。首先构建了一个适用于电力领域的PMC评价体系;然后获取电力政策文本,并对其进行量化;最后建立LSTM负荷预测模型,将政策量化结果输入预测模型。在构建负荷预测模型输入数据集时采用了GRA相似日算法,并综合考虑了日期、天气等因素,有效扩充了数据集。实验结果表明,PMC 指数模型能有效地实现电力政策量化,并且量化结果对提升负荷预测模型精度有一定作用。未来,笔者希望利用变压器的双向编码器表示(bidirectional encoder representation from transformers,BERT)模型实现生成式文本摘要,挖掘更多政策要素,提升摘要结果和量化精度。
参考文献
Load profiles analysis for electricity market
[J].
Forecasting the short-term electric load considering the influence of air pollution prevention and control policy via a hybrid model
[J].
Study of applicability of the methods of medium and long term load forecasting in new economy normal state
[C]//
An improved load forecast model using factor analysis:an australian case study
[C]//
政策文献量化研究:公共政策研究的新方向
[J].
Policy documents quantitative research:a new direction for public policy study
[J].
地方政府大数据发展政策的文献量化研究——基于政策“目标-工具”匹配的视角
[J].
Big data development strategies of Chinese local governments based on documents quantitative methods- compatibility of policy goals and policy tools
[J].
Public policies for smart grids in Brazil
[J].
我国促进大数据发展政策工具选择体系结构及其优化策略研究
[J].
Research on the architecture and optimization strategy of policy instrument selection for the development of big data in China
[J].
区域性技术创新政策绩效评价的实证研究——基于相关性和灰色关联分析的视角
[J].
An empirical study on performance evaluation of regional technology innovation policy-based on perspective analysis of correlation and grey correlation
[J].
A financial macro-network approach to climate policy evaluation
[J].
Policy modeling:definition,classification and evaluation
[J].
Short-term load forecasting based on improved grey relational analysis and neural network optimized by bat algorithm
[J].
Short-term load forecasting
[J].

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}