The National Natural Science Foundation of China. 61876112 The National Natural Science Foundation of China. 61976170 The Natural Science Foundation of Beijing. L201022
A method based on visual saliency for ego-motion estimation and scale estimation of the vehicle in front was proposed.Firstly, for the ego-motion estimation of vehicle-mounted camera, the visual saliency calculation method was used to detect and remove moving objects in the monocular image sequence containing noise.While considering the image texture and smooth region, the weighted saliency map was used to retain useful feature points, to improve the robustness of ego-motion estimation.Secondly, the distance of the vehicle in front was converted into a vehicle scale estimation, by integrating descriptor match and the strength of regularization match of the lie algebra to minimize loss function.The visual attention mechanism was used to get texture image block without shade, and the pixel in the image block weight to mitigate the effects of destroyed by noise pixel, so as to realize the robust and accurate scale estimation.Finally, several challenging datasets were used to analyze and verify the proposed method.The results show that the monocular camera ego-motion estimation method reaches the level of the stereo camera-based method, and the vehicle scale estimation method ensures the prediction accuracy while giving full play to the advantages of strong robustness.
AI Mingxin. A method based on visual saliency for vehicle-mounted monocular camera ego-motion estimation and vehicle scale estimation. Chinese Journal of Intelligent Science and Technology[J], 2021, 3(3): 280-293 doi:10.11959/j.issn.2096-6652.202129
基于以上分析,本文的主要创新点概括如下:(1)提出一种用显著性计算方法去除异常区域的自运动估计方法,并且考虑图像的纹理区域和平滑区域,增强了方法的鲁棒性;(2)将描述子匹配的鲁棒性和强度匹配的精确性结合,弥补了两者的不足,两阶段注意力机制使方法适用于有遮挡且环境多变的复杂情况;(3)将单目自运动估计方法和前车尺度估计方法结合,有助于碰撞时间的精准计算。本文分别在KITTI数据集、纹理区域图像(texture area image,TAI)数据集和视频数据集上对几种方法进行测试比较,证明了本文方法的优势。
2 相关工作
自运动估计通过相机运动前后拍摄的连续图像序列分析估算相机和景物之间的相对运动参数。运动估计分为基于特征的方法(使用稀疏的匹配特征点集来估计相机运动)和直接法(直接使用图像序列中的强度梯度估计相机运动)。基于特征的相机运动估计方法需要检测和提取特征点。常用的特征点提取方法有斑点检测法、角点检测法等。其中,斑点检测法用于检测灰度值大于或小于周围像素的区域。经典的斑点检测法包括尺度不变特征变换(scale invariant feature transform,SIFT)[16]算法和加速鲁棒特征(speeded up robust features,SURF)[17]算法。SIFT算法对旋转、尺度缩放和亮度变化保持不变性,对视角变化、仿射变换和噪声具有鲁棒性。SURF算法是SIFT算法的加速版本,具有很好的实时性。查冰等人[18]比较并分析了 SIFT、SURF 和ORB(oriented FAST and rotated BRIEF)这3种特征提取算法。他们发现,在不考虑速度的情况下, SIFT 算法在估计各种图像的相对位置关系时具有更高的精度。ORB算法在时间开销上有较大优势,特征点检测和匹配数量最多。SURF 算法的时间成本和准确度适中。经典的角点检测法包括Harris角点检测法、Shi-Tomas 角点检测法[19]和加速分割测试的特征(features from accelerated segment test, FAST)算法。Lucas B D等人[20]在1981年提出了计算稀疏光流(由两帧之间的运动引起)的 Lucas-Kanade(LK)光流方法。该方法创建了一个光流对象来估计运动对象的方向和速度。基于LK光流,Chang H C等人[16]将连续帧的光流场应用于简化的仿射运动模型,从而进行相机运动估计。Cai J H等人[21]利用LK特征跟踪器的金字塔和局部运动直方图来估计光流。Jaegle A 等人[1]利用流场残差的似然分布,提出了噪声光流数据的期望残差(expected residual,ERL)。该方法的实验结果表明,在具有挑战性的KITTI数据集上,ERL优于单目相机自运动估计方法,同时与其他相机自运动估计方法相比,ERL几乎没有增加运行成本。
在图像内容分析方面,Chen Q X等人[22]提出了结合人眼视觉注意力机制的显著性目标检测(salient object detection,SOD)方法。面对复杂的环境时,人们会通过视觉注意力机制在潜意识中快速、准确地识别出感兴趣区域(region of interest, RoI)。该方法利用计算机模拟人类视觉注意力机制,计算图像各部分的重要性,然后快速找到感兴趣的显著性区域。这对结合人眼视觉注意力机制的显著性目标检测研究具有重要意义。直接法是基于前后帧图像的灰度信息变化直接计算相机运动参数的方法,采用光流在其灰度梯度方向上的投影-法向流进行相机自运动参数的计算。但是法向流中包含相机的运动信息(平移、旋转)、图像纹理信息以及景物深度信息和噪声,这些信息混杂在一起,导致无法直接将相机运动信息从中剥离。
基于描述子的跟踪方法使用特征跟踪目标对象,具有很强的鲁棒性[14-15]。Danelljan M等人[14]引入了判别式尺度空间跟踪器(discriminative scale space tracker,DSST),利用相关滤波器估计目标的尺度。然而,DSST提供的尺度估计是粗糙和离散的。大多数基于描述子的方法不能准确估计目标对象的位置和尺度[23-24]。因此,相关滤波器提供的基于描述子的位置估计仅被当作基于强度的精确跟踪的粗先验信息。
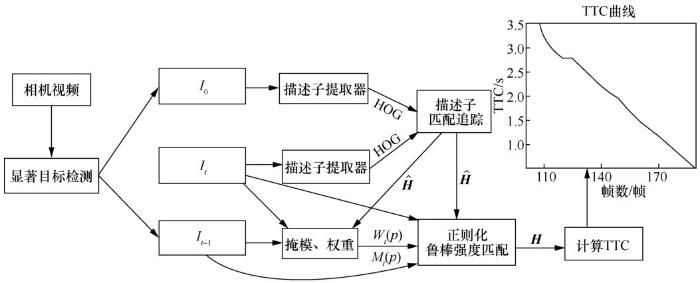
使用参考文献[14]的方法计算,使用参考图像I0的方向梯度直方图(histogram of oriented gradient,HOG)特征来训练二维平移滤波器和一维尺度滤波器。对于当前图像It,使用平移滤波器得到参数、,使用尺度滤波器得到尺度参数和代数结构Lie Group SL(3)下的单应性矩阵:
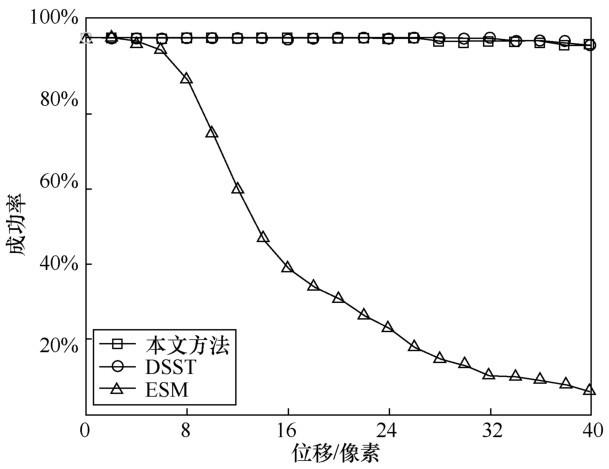
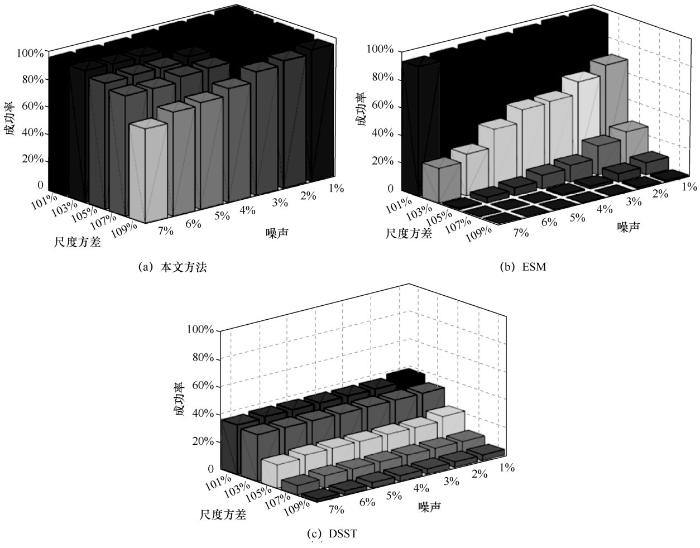
对图像进行不同的操作,从而比较3种方法在噪声破坏和尺度方差方面的性能,如用椒盐噪声破坏图像改变被损坏像素所占比例,从而控制噪声的影响或扭曲图像。图9分别展示了本文方法、ESM、DSST这3种方法在不同尺度方差和噪声下的成功率,实验结果表明在噪声和尺度方差较大的情况下,本文方法的性能明显优于DSST和ESM,噪声等级的增加和尺度方差的增加对本文方法的 SR 影响不大。在最坏的情况下,本文方法仍然具有大于65%的SR。然而,随着噪声等级和尺度方差的增加, ESM的SR从97%急剧下降到1%。由于DSST的尺度空间是离散的,其处理大尺度差分问题的性能较差。
... 自运动估计通过相机运动前后拍摄的连续图像序列分析估算相机和景物之间的相对运动参数.运动估计分为基于特征的方法(使用稀疏的匹配特征点集来估计相机运动)和直接法(直接使用图像序列中的强度梯度估计相机运动).基于特征的相机运动估计方法需要检测和提取特征点.常用的特征点提取方法有斑点检测法、角点检测法等.其中,斑点检测法用于检测灰度值大于或小于周围像素的区域.经典的斑点检测法包括尺度不变特征变换(scale invariant feature transform,SIFT)[16]算法和加速鲁棒特征(speeded up robust features,SURF)[17]算法.SIFT算法对旋转、尺度缩放和亮度变化保持不变性,对视角变化、仿射变换和噪声具有鲁棒性.SURF算法是SIFT算法的加速版本,具有很好的实时性.查冰等人[18]比较并分析了 SIFT、SURF 和ORB(oriented FAST and rotated BRIEF)这3种特征提取算法.他们发现,在不考虑速度的情况下, SIFT 算法在估计各种图像的相对位置关系时具有更高的精度.ORB算法在时间开销上有较大优势,特征点检测和匹配数量最多.SURF 算法的时间成本和准确度适中.经典的角点检测法包括Harris角点检测法、Shi-Tomas 角点检测法[19]和加速分割测试的特征(features from accelerated segment test, FAST)算法.Lucas B D等人[20]在1981年提出了计算稀疏光流(由两帧之间的运动引起)的 Lucas-Kanade(LK)光流方法.该方法创建了一个光流对象来估计运动对象的方向和速度.基于LK光流,Chang H C等人[16]将连续帧的光流场应用于简化的仿射运动模型,从而进行相机运动估计.Cai J H等人[21]利用LK特征跟踪器的金字塔和局部运动直方图来估计光流.Jaegle A 等人[1]利用流场残差的似然分布,提出了噪声光流数据的期望残差(expected residual,ERL).该方法的实验结果表明,在具有挑战性的KITTI数据集上,ERL优于单目相机自运动估计方法,同时与其他相机自运动估计方法相比,ERL几乎没有增加运行成本. ...
... 基于描述子的跟踪方法使用特征跟踪目标对象,具有很强的鲁棒性[14-15].Danelljan M等人[14]引入了判别式尺度空间跟踪器(discriminative scale space tracker,DSST),利用相关滤波器估计目标的尺度.然而,DSST提供的尺度估计是粗糙和离散的.大多数基于描述子的方法不能准确估计目标对象的位置和尺度[23-24].因此,相关滤波器提供的基于描述子的位置估计仅被当作基于强度的精确跟踪的粗先验信息. ...
... [14]引入了判别式尺度空间跟踪器(discriminative scale space tracker,DSST),利用相关滤波器估计目标的尺度.然而,DSST提供的尺度估计是粗糙和离散的.大多数基于描述子的方法不能准确估计目标对象的位置和尺度[23-24].因此,相关滤波器提供的基于描述子的位置估计仅被当作基于强度的精确跟踪的粗先验信息. ...
... 其中,,tx、ty分别表示在x、y方向上的平移;s表示尺度;表示匹配得分[14]. ...
... 使用参考文献[14]的方法计算,使用参考图像I0的方向梯度直方图(histogram of oriented gradient,HOG)特征来训练二维平移滤波器和一维尺度滤波器.对于当前图像It,使用平移滤波器得到参数、,使用尺度滤波器得到尺度参数和代数结构Lie Group SL(3)下的单应性矩阵: ...
... 基于描述子的跟踪方法使用特征跟踪目标对象,具有很强的鲁棒性[14-15].Danelljan M等人[14]引入了判别式尺度空间跟踪器(discriminative scale space tracker,DSST),利用相关滤波器估计目标的尺度.然而,DSST提供的尺度估计是粗糙和离散的.大多数基于描述子的方法不能准确估计目标对象的位置和尺度[23-24].因此,相关滤波器提供的基于描述子的位置估计仅被当作基于强度的精确跟踪的粗先验信息. ...
A robust and efficient video stabilization algorithm
2
2004
... 自运动估计通过相机运动前后拍摄的连续图像序列分析估算相机和景物之间的相对运动参数.运动估计分为基于特征的方法(使用稀疏的匹配特征点集来估计相机运动)和直接法(直接使用图像序列中的强度梯度估计相机运动).基于特征的相机运动估计方法需要检测和提取特征点.常用的特征点提取方法有斑点检测法、角点检测法等.其中,斑点检测法用于检测灰度值大于或小于周围像素的区域.经典的斑点检测法包括尺度不变特征变换(scale invariant feature transform,SIFT)[16]算法和加速鲁棒特征(speeded up robust features,SURF)[17]算法.SIFT算法对旋转、尺度缩放和亮度变化保持不变性,对视角变化、仿射变换和噪声具有鲁棒性.SURF算法是SIFT算法的加速版本,具有很好的实时性.查冰等人[18]比较并分析了 SIFT、SURF 和ORB(oriented FAST and rotated BRIEF)这3种特征提取算法.他们发现,在不考虑速度的情况下, SIFT 算法在估计各种图像的相对位置关系时具有更高的精度.ORB算法在时间开销上有较大优势,特征点检测和匹配数量最多.SURF 算法的时间成本和准确度适中.经典的角点检测法包括Harris角点检测法、Shi-Tomas 角点检测法[19]和加速分割测试的特征(features from accelerated segment test, FAST)算法.Lucas B D等人[20]在1981年提出了计算稀疏光流(由两帧之间的运动引起)的 Lucas-Kanade(LK)光流方法.该方法创建了一个光流对象来估计运动对象的方向和速度.基于LK光流,Chang H C等人[16]将连续帧的光流场应用于简化的仿射运动模型,从而进行相机运动估计.Cai J H等人[21]利用LK特征跟踪器的金字塔和局部运动直方图来估计光流.Jaegle A 等人[1]利用流场残差的似然分布,提出了噪声光流数据的期望残差(expected residual,ERL).该方法的实验结果表明,在具有挑战性的KITTI数据集上,ERL优于单目相机自运动估计方法,同时与其他相机自运动估计方法相比,ERL几乎没有增加运行成本. ...
... [16]将连续帧的光流场应用于简化的仿射运动模型,从而进行相机运动估计.Cai J H等人[21]利用LK特征跟踪器的金字塔和局部运动直方图来估计光流.Jaegle A 等人[1]利用流场残差的似然分布,提出了噪声光流数据的期望残差(expected residual,ERL).该方法的实验结果表明,在具有挑战性的KITTI数据集上,ERL优于单目相机自运动估计方法,同时与其他相机自运动估计方法相比,ERL几乎没有增加运行成本. ...
Speeded-up robust features (SURF)
1
2008
... 自运动估计通过相机运动前后拍摄的连续图像序列分析估算相机和景物之间的相对运动参数.运动估计分为基于特征的方法(使用稀疏的匹配特征点集来估计相机运动)和直接法(直接使用图像序列中的强度梯度估计相机运动).基于特征的相机运动估计方法需要检测和提取特征点.常用的特征点提取方法有斑点检测法、角点检测法等.其中,斑点检测法用于检测灰度值大于或小于周围像素的区域.经典的斑点检测法包括尺度不变特征变换(scale invariant feature transform,SIFT)[16]算法和加速鲁棒特征(speeded up robust features,SURF)[17]算法.SIFT算法对旋转、尺度缩放和亮度变化保持不变性,对视角变化、仿射变换和噪声具有鲁棒性.SURF算法是SIFT算法的加速版本,具有很好的实时性.查冰等人[18]比较并分析了 SIFT、SURF 和ORB(oriented FAST and rotated BRIEF)这3种特征提取算法.他们发现,在不考虑速度的情况下, SIFT 算法在估计各种图像的相对位置关系时具有更高的精度.ORB算法在时间开销上有较大优势,特征点检测和匹配数量最多.SURF 算法的时间成本和准确度适中.经典的角点检测法包括Harris角点检测法、Shi-Tomas 角点检测法[19]和加速分割测试的特征(features from accelerated segment test, FAST)算法.Lucas B D等人[20]在1981年提出了计算稀疏光流(由两帧之间的运动引起)的 Lucas-Kanade(LK)光流方法.该方法创建了一个光流对象来估计运动对象的方向和速度.基于LK光流,Chang H C等人[16]将连续帧的光流场应用于简化的仿射运动模型,从而进行相机运动估计.Cai J H等人[21]利用LK特征跟踪器的金字塔和局部运动直方图来估计光流.Jaegle A 等人[1]利用流场残差的似然分布,提出了噪声光流数据的期望残差(expected residual,ERL).该方法的实验结果表明,在具有挑战性的KITTI数据集上,ERL优于单目相机自运动估计方法,同时与其他相机自运动估计方法相比,ERL几乎没有增加运行成本. ...
不同特征提取算法对相机运动估计的适用性研究
1
2018
... 自运动估计通过相机运动前后拍摄的连续图像序列分析估算相机和景物之间的相对运动参数.运动估计分为基于特征的方法(使用稀疏的匹配特征点集来估计相机运动)和直接法(直接使用图像序列中的强度梯度估计相机运动).基于特征的相机运动估计方法需要检测和提取特征点.常用的特征点提取方法有斑点检测法、角点检测法等.其中,斑点检测法用于检测灰度值大于或小于周围像素的区域.经典的斑点检测法包括尺度不变特征变换(scale invariant feature transform,SIFT)[16]算法和加速鲁棒特征(speeded up robust features,SURF)[17]算法.SIFT算法对旋转、尺度缩放和亮度变化保持不变性,对视角变化、仿射变换和噪声具有鲁棒性.SURF算法是SIFT算法的加速版本,具有很好的实时性.查冰等人[18]比较并分析了 SIFT、SURF 和ORB(oriented FAST and rotated BRIEF)这3种特征提取算法.他们发现,在不考虑速度的情况下, SIFT 算法在估计各种图像的相对位置关系时具有更高的精度.ORB算法在时间开销上有较大优势,特征点检测和匹配数量最多.SURF 算法的时间成本和准确度适中.经典的角点检测法包括Harris角点检测法、Shi-Tomas 角点检测法[19]和加速分割测试的特征(features from accelerated segment test, FAST)算法.Lucas B D等人[20]在1981年提出了计算稀疏光流(由两帧之间的运动引起)的 Lucas-Kanade(LK)光流方法.该方法创建了一个光流对象来估计运动对象的方向和速度.基于LK光流,Chang H C等人[16]将连续帧的光流场应用于简化的仿射运动模型,从而进行相机运动估计.Cai J H等人[21]利用LK特征跟踪器的金字塔和局部运动直方图来估计光流.Jaegle A 等人[1]利用流场残差的似然分布,提出了噪声光流数据的期望残差(expected residual,ERL).该方法的实验结果表明,在具有挑战性的KITTI数据集上,ERL优于单目相机自运动估计方法,同时与其他相机自运动估计方法相比,ERL几乎没有增加运行成本. ...
不同特征提取算法对相机运动估计的适用性研究
1
2018
... 自运动估计通过相机运动前后拍摄的连续图像序列分析估算相机和景物之间的相对运动参数.运动估计分为基于特征的方法(使用稀疏的匹配特征点集来估计相机运动)和直接法(直接使用图像序列中的强度梯度估计相机运动).基于特征的相机运动估计方法需要检测和提取特征点.常用的特征点提取方法有斑点检测法、角点检测法等.其中,斑点检测法用于检测灰度值大于或小于周围像素的区域.经典的斑点检测法包括尺度不变特征变换(scale invariant feature transform,SIFT)[16]算法和加速鲁棒特征(speeded up robust features,SURF)[17]算法.SIFT算法对旋转、尺度缩放和亮度变化保持不变性,对视角变化、仿射变换和噪声具有鲁棒性.SURF算法是SIFT算法的加速版本,具有很好的实时性.查冰等人[18]比较并分析了 SIFT、SURF 和ORB(oriented FAST and rotated BRIEF)这3种特征提取算法.他们发现,在不考虑速度的情况下, SIFT 算法在估计各种图像的相对位置关系时具有更高的精度.ORB算法在时间开销上有较大优势,特征点检测和匹配数量最多.SURF 算法的时间成本和准确度适中.经典的角点检测法包括Harris角点检测法、Shi-Tomas 角点检测法[19]和加速分割测试的特征(features from accelerated segment test, FAST)算法.Lucas B D等人[20]在1981年提出了计算稀疏光流(由两帧之间的运动引起)的 Lucas-Kanade(LK)光流方法.该方法创建了一个光流对象来估计运动对象的方向和速度.基于LK光流,Chang H C等人[16]将连续帧的光流场应用于简化的仿射运动模型,从而进行相机运动估计.Cai J H等人[21]利用LK特征跟踪器的金字塔和局部运动直方图来估计光流.Jaegle A 等人[1]利用流场残差的似然分布,提出了噪声光流数据的期望残差(expected residual,ERL).该方法的实验结果表明,在具有挑战性的KITTI数据集上,ERL优于单目相机自运动估计方法,同时与其他相机自运动估计方法相比,ERL几乎没有增加运行成本. ...
Good features to track
1
1994
... 自运动估计通过相机运动前后拍摄的连续图像序列分析估算相机和景物之间的相对运动参数.运动估计分为基于特征的方法(使用稀疏的匹配特征点集来估计相机运动)和直接法(直接使用图像序列中的强度梯度估计相机运动).基于特征的相机运动估计方法需要检测和提取特征点.常用的特征点提取方法有斑点检测法、角点检测法等.其中,斑点检测法用于检测灰度值大于或小于周围像素的区域.经典的斑点检测法包括尺度不变特征变换(scale invariant feature transform,SIFT)[16]算法和加速鲁棒特征(speeded up robust features,SURF)[17]算法.SIFT算法对旋转、尺度缩放和亮度变化保持不变性,对视角变化、仿射变换和噪声具有鲁棒性.SURF算法是SIFT算法的加速版本,具有很好的实时性.查冰等人[18]比较并分析了 SIFT、SURF 和ORB(oriented FAST and rotated BRIEF)这3种特征提取算法.他们发现,在不考虑速度的情况下, SIFT 算法在估计各种图像的相对位置关系时具有更高的精度.ORB算法在时间开销上有较大优势,特征点检测和匹配数量最多.SURF 算法的时间成本和准确度适中.经典的角点检测法包括Harris角点检测法、Shi-Tomas 角点检测法[19]和加速分割测试的特征(features from accelerated segment test, FAST)算法.Lucas B D等人[20]在1981年提出了计算稀疏光流(由两帧之间的运动引起)的 Lucas-Kanade(LK)光流方法.该方法创建了一个光流对象来估计运动对象的方向和速度.基于LK光流,Chang H C等人[16]将连续帧的光流场应用于简化的仿射运动模型,从而进行相机运动估计.Cai J H等人[21]利用LK特征跟踪器的金字塔和局部运动直方图来估计光流.Jaegle A 等人[1]利用流场残差的似然分布,提出了噪声光流数据的期望残差(expected residual,ERL).该方法的实验结果表明,在具有挑战性的KITTI数据集上,ERL优于单目相机自运动估计方法,同时与其他相机自运动估计方法相比,ERL几乎没有增加运行成本. ...
An iterative image registration technique with an application to stereo vision
1
1981
... 自运动估计通过相机运动前后拍摄的连续图像序列分析估算相机和景物之间的相对运动参数.运动估计分为基于特征的方法(使用稀疏的匹配特征点集来估计相机运动)和直接法(直接使用图像序列中的强度梯度估计相机运动).基于特征的相机运动估计方法需要检测和提取特征点.常用的特征点提取方法有斑点检测法、角点检测法等.其中,斑点检测法用于检测灰度值大于或小于周围像素的区域.经典的斑点检测法包括尺度不变特征变换(scale invariant feature transform,SIFT)[16]算法和加速鲁棒特征(speeded up robust features,SURF)[17]算法.SIFT算法对旋转、尺度缩放和亮度变化保持不变性,对视角变化、仿射变换和噪声具有鲁棒性.SURF算法是SIFT算法的加速版本,具有很好的实时性.查冰等人[18]比较并分析了 SIFT、SURF 和ORB(oriented FAST and rotated BRIEF)这3种特征提取算法.他们发现,在不考虑速度的情况下, SIFT 算法在估计各种图像的相对位置关系时具有更高的精度.ORB算法在时间开销上有较大优势,特征点检测和匹配数量最多.SURF 算法的时间成本和准确度适中.经典的角点检测法包括Harris角点检测法、Shi-Tomas 角点检测法[19]和加速分割测试的特征(features from accelerated segment test, FAST)算法.Lucas B D等人[20]在1981年提出了计算稀疏光流(由两帧之间的运动引起)的 Lucas-Kanade(LK)光流方法.该方法创建了一个光流对象来估计运动对象的方向和速度.基于LK光流,Chang H C等人[16]将连续帧的光流场应用于简化的仿射运动模型,从而进行相机运动估计.Cai J H等人[21]利用LK特征跟踪器的金字塔和局部运动直方图来估计光流.Jaegle A 等人[1]利用流场残差的似然分布,提出了噪声光流数据的期望残差(expected residual,ERL).该方法的实验结果表明,在具有挑战性的KITTI数据集上,ERL优于单目相机自运动估计方法,同时与其他相机自运动估计方法相比,ERL几乎没有增加运行成本. ...
Robust motion estimation for camcorders mounted in mobile platforms
1
2008
... 自运动估计通过相机运动前后拍摄的连续图像序列分析估算相机和景物之间的相对运动参数.运动估计分为基于特征的方法(使用稀疏的匹配特征点集来估计相机运动)和直接法(直接使用图像序列中的强度梯度估计相机运动).基于特征的相机运动估计方法需要检测和提取特征点.常用的特征点提取方法有斑点检测法、角点检测法等.其中,斑点检测法用于检测灰度值大于或小于周围像素的区域.经典的斑点检测法包括尺度不变特征变换(scale invariant feature transform,SIFT)[16]算法和加速鲁棒特征(speeded up robust features,SURF)[17]算法.SIFT算法对旋转、尺度缩放和亮度变化保持不变性,对视角变化、仿射变换和噪声具有鲁棒性.SURF算法是SIFT算法的加速版本,具有很好的实时性.查冰等人[18]比较并分析了 SIFT、SURF 和ORB(oriented FAST and rotated BRIEF)这3种特征提取算法.他们发现,在不考虑速度的情况下, SIFT 算法在估计各种图像的相对位置关系时具有更高的精度.ORB算法在时间开销上有较大优势,特征点检测和匹配数量最多.SURF 算法的时间成本和准确度适中.经典的角点检测法包括Harris角点检测法、Shi-Tomas 角点检测法[19]和加速分割测试的特征(features from accelerated segment test, FAST)算法.Lucas B D等人[20]在1981年提出了计算稀疏光流(由两帧之间的运动引起)的 Lucas-Kanade(LK)光流方法.该方法创建了一个光流对象来估计运动对象的方向和速度.基于LK光流,Chang H C等人[16]将连续帧的光流场应用于简化的仿射运动模型,从而进行相机运动估计.Cai J H等人[21]利用LK特征跟踪器的金字塔和局部运动直方图来估计光流.Jaegle A 等人[1]利用流场残差的似然分布,提出了噪声光流数据的期望残差(expected residual,ERL).该方法的实验结果表明,在具有挑战性的KITTI数据集上,ERL优于单目相机自运动估计方法,同时与其他相机自运动估计方法相比,ERL几乎没有增加运行成本. ...
Salient object detection:integrate salient features in the deep learning framework
1
2019
... 在图像内容分析方面,Chen Q X等人[22]提出了结合人眼视觉注意力机制的显著性目标检测(salient object detection,SOD)方法.面对复杂的环境时,人们会通过视觉注意力机制在潜意识中快速、准确地识别出感兴趣区域(region of interest, RoI).该方法利用计算机模拟人类视觉注意力机制,计算图像各部分的重要性,然后快速找到感兴趣的显著性区域.这对结合人眼视觉注意力机制的显著性目标检测研究具有重要意义.直接法是基于前后帧图像的灰度信息变化直接计算相机运动参数的方法,采用光流在其灰度梯度方向上的投影-法向流进行相机自运动参数的计算.但是法向流中包含相机的运动信息(平移、旋转)、图像纹理信息以及景物深度信息和噪声,这些信息混杂在一起,导致无法直接将相机运动信息从中剥离. ...
Visual object tracking using adaptive correlation filters
1
2010
... 基于描述子的跟踪方法使用特征跟踪目标对象,具有很强的鲁棒性[14-15].Danelljan M等人[14]引入了判别式尺度空间跟踪器(discriminative scale space tracker,DSST),利用相关滤波器估计目标的尺度.然而,DSST提供的尺度估计是粗糙和离散的.大多数基于描述子的方法不能准确估计目标对象的位置和尺度[23-24].因此,相关滤波器提供的基于描述子的位置估计仅被当作基于强度的精确跟踪的粗先验信息. ...
Struck:structured output tracking with kernels
2
2016
... 基于描述子的跟踪方法使用特征跟踪目标对象,具有很强的鲁棒性[14-15].Danelljan M等人[14]引入了判别式尺度空间跟踪器(discriminative scale space tracker,DSST),利用相关滤波器估计目标的尺度.然而,DSST提供的尺度估计是粗糙和离散的.大多数基于描述子的方法不能准确估计目标对象的位置和尺度[23-24].因此,相关滤波器提供的基于描述子的位置估计仅被当作基于强度的精确跟踪的粗先验信息. ...
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}