1 引言
特征提取是人脸识别中比较重要的步骤,在研究特征提取的过程中产生了许多降维的方法[1 ,2 ,3 ] ,如主成分分析(principal component analysis,PCA)[4 ] 和线性判别分析(liner discriminant analysis,LDA)[5 ] 等,这些方法都能在一定程度上较好地对特征进行提取。与 PCA 和 LDA 不同的是,非负矩阵分解(non-negative matrix factorization,NMF)要求非负矩阵中的所有元素都大于或等于零,在这种约束下,原始数据中的噪声信息被充分过滤,从而使新的数据具有更好的表示能力。
作为一种基于局部的提取方法,NMF在特征提取领域已得到广泛使用,同时也产生了许多 NMF的扩展方法,包括稀疏NMF、鉴别NMF、正交NMF以及流形 NMF 等。有学者通过对非负矩阵施加稀疏编码,提出了一种新的非负稀疏编码(non-negative sparse coding,NNSC)方法[6 ] ,很大程度上增强了NMF的稀疏表示能力。Cai D等人[7 ] 将 NMF 与流形结构结合,提出了图正则化 NMF (graph regularized NMF,GNMF)算法,从而保持了数据的内在几何结构。类似的算法还有流形正则化判别 NMF(manifold regularized discriminative NMF,MD-NMF)[8 ] 、图嵌入正则化投影NMF(graph embedding regularized projection NMF,GEPNMF)[9 ] 等。这些扩展算法都使 NMF 方法的能力得到了很大的提高。
尽管许多 NMF 方法结合了不同的性质,如稀疏性、判别能力或流形结构,但这些基于 NMF 的方法都将欧氏距离作为度量,该度量对数据噪声非常敏感。为了增强 NMF 的鲁棒性,人们也提出了一些鲁棒的NMF方法,如鲁棒NMF(robust NMF, RNMF)[10 ] 、基于L2.1 范数的NMF [11 ] 等。这些鲁棒的 NMF 方法都是基于局部学习的,忽略了数据的全局信息。然而在实际应用中,数据中的噪声的全局分布大多是不规律的。因此,现有的鲁棒的NMF方法的鲁棒性是有限的。事实上,在对损坏数据进行分类时,数据的全局信息比局部信息具有更强的鲁棒性。
低秩表示(low-rank representation,LRR)可以捕获数据的全局结构,揭示样本的隶属度。在图像分类中,局部信息和全局信息在特征提取和分类中都起着重要作用。NMF 方法在局部特征学习上具有较强的能力,但忽略了数据的全局信息,为了保持局部特征学习和全局学习能力,在 LRR 的激励下,本文提出了一种利用低秩、非负监督约束和稀疏性[12 ,13 ,14 ] 的算法——非负监督低秩鉴别嵌入(non-negative supervised low-rank discriminant embedding,NSLRE)来分类被破坏的数据。笔者假设数据被严重损坏,并将L1 范数作为假定的噪声矩阵的稀疏约束。NSLRE先学习低秩矩阵、恢复干净矩阵并去除数据中的噪声;然后,对学习到的低秩矩阵进行非负因子分解,保持数据的局部表示能力,在此基础上结合流形正则化保持数据的局部几何结构,进一步增强 NMF的局部属性。NSLRE能够同时进行低秩学习和非负性学习,能够很好地获得基于局部和全局的数据表示。这保证了 NMF 中两个非负矩阵的构造不受噪声的影响。该算法既能保留数据的局部几何信息,又能进行去噪处理,对有噪声的图像分类任务有较好的处理效果。该算法的主要优点如下。
(1)NSLRE结合了NMF和LRR的一些优点。该算法学习到的低秩矩阵具有类似于 LRR 的全局表示,基础矩阵具有类似于 NMF 的局部表示。将局部表示和全局表示结合进行非负学习,实现鲁棒图像分类。
(2)在没有数据噪声干扰的情况下,在学习到的投影子空间中,同一类的数据点可以尽可能接近,这可以提高基于NMF的鲁棒方法的判别能力。
2 相关工作
2.1 非负矩阵分解
给定一个训练集 X = [ x 1 , x 2 , ⋯ , x i , ⋯ , x n ] ∈ R m × n X U ∈ R m × k V ∈ R k × n
O = ‖ X − U V ‖ F 2 , s .t . U ≥ 0 , V ≥ 0 ( 1 )
u j k t + 1 ← u j k t ( X V ⊤ ) j k ( U V V ⊤ ) j k , v k i t + 1 ← v k i t ( U ⊤ X ) k i ( U ⊤ U V ) k i ( 2 )
其中,u j k v k i U V
2.2 低秩表示
为了解决子空间分解问题,有学者提出了LRR[15 ,16 ,17 ] 方法,LRR的数据向量是其他样本的线性组合。与稀疏表示不同,LRR联合搜索所有数据的最低秩表示,捕获数据的全局结构。
给定一个训练集X = [ x 1 , x 2 , ⋯ , x i , ⋯ , x n ] ∈ R m × n X D
X = D Z ( 3 )
其中,Z Z
min Z ‖ Z ‖ * , s .t . X = D Z ( 4 )
对于被损坏的数据,将噪声矩阵E
min Z ‖ Z ‖ * + λ ‖ E ‖ 2 , 1 , s .t . X = D Z + E ( 5 )
3 目标函数及迭代方法
3.1 目标函数
给定一个训练集X = [ x 1 , x 2 , ⋯ , x i , ⋯ , x n ] ∈ R m × n E
min U ≥ 0 , V ≥ 0 = ‖ X − E − U V ‖ F 2 ( 6 )
min A , E , U , V ≥ 0 = ‖ A − U V ‖ F 2 , s .t . X = A + E ( 7 )
其中,A
min A , E , p , U , V ≥ 0 = ∑ i , j ‖ y i − y j ‖ 2 2 S i j w − ‖ y i − y j ‖ 2 2 S i j b +
α rank ( A ) + ‖ A − U V ‖ F 2 ,
s .t . X = A + E ( 8 )
其中,S i j w S i j b p A A
但是由于式(8)是一个NP问题,笔者将该问题用凸优化问题代替:
min A , E , p , U , V ≥ 0 = ∑ i , j ‖ y i − y j ‖ 2 2 S i j w − ‖ y i − y j ‖ 2 2 S i j b +
α ‖ A ‖ * + ‖ A − U V ‖ F 2
s . t . X = A + E ( 9 )
假设噪声是稀疏的,笔者使用L1 范数对噪声矩阵E
min A , E , p , U , V ≥ 0 = ∑ i , j ‖ y i − y j ‖ 2 2 S i j w − ‖ y i − y j ‖ 2 2 S i j b +
α ‖ A ‖ * + β ‖ E ‖ 1 + ‖ A − U V ‖ F 2 ,
s .t . X = A + E ( 10 )
该模型考虑了样本的全局信息与局部信息,同时对样本添加低秩特性,确保误差是稀疏的。
3.2 优化方法
笔者用交替方向乘子法(alternating direction method of multiplier,ADMM)或增广拉格朗日乘子法(augmented Lagrangian multiplier,ALM)来解决式(4)~式(10)。具体利用核范数[18 ] 的下列性质来解决。
定理 1 对于任意矩阵A ∈ R m × n ‖ A ‖ * = min R , H 1 2 ( ‖ R ‖ F 2 + ‖ H ‖ F 2 ) A = R H
min A , E , p , R , H , U , V ≥ 0 = ∑ i , j ‖ y i − y j ‖ 2 2 S i j w − ‖ y i − y j ‖ 2 2 S i j b +
α 2 ( ‖ R ‖ F 2 + ‖ H ‖ F 2 ) + β ‖ E ‖ 1 + ‖ A − U V ‖ F 2 ,
s .t . X = A + E , A = R H ( 11 )
L ( A , E , U , V , R , H , p , Y 1 , Y 2 , μ ) = ∑ i , j ‖ y i − y j ‖ 2 2 S i j w −
‖ y i − y j ‖ 2 2 S i j b + α 2 ( ‖ R ‖ F 2 + ‖ H ‖ F 2 ) + β ‖ E ‖ 1 + ‖ A − U V ‖ F 2 +
〈 Y 1 , X − A − E 〉 + 〈 Y 2 , A − R H 〉 +
μ 2 ( ‖ X − A − E ‖ F 2 + ‖ A − R H ‖ F 2 ) =
∑ i , j ‖ y i − y j ‖ 2 2 S i j w − ‖ y i − y j ‖ 2 2 S i j b +
α 2 ( ‖ R ‖ F 2 + ‖ H ‖ F 2 ) + β ‖ E ‖ 1 + ‖ A − U V ‖ F 2 +
μ 2 ‖ X − A − E + Y 1 μ ‖ F 2 + μ 2 ‖ A − R H + Y 2 μ ‖ F 2 −
1 2 μ ( ‖ Y 1 ‖ F 2 + ‖ Y 2 ‖ F 2 ) ( 12 )
min A ‖ A − U V ‖ F 2 +
μ 2 ‖ X − A − E + Y 1 μ ‖ F 2 + μ 2 ‖ A − R H + Y 2 μ ‖ F 2 ( 13 )
A = 2 K 1 + μ ( K 2 + K 3 ) 2 + 2 μ ( 14 )
其中, K 1 = U V K 2 = X − E + Y 1 μ K 3 = R H − Y 2 μ
min E β ‖ E ‖ 1 + μ 2 ‖ X − A − E + Y 1 μ ‖ F 2 ( 15 )
这是一个软阈值问题,可以通过收缩因子来求解该问题:
e k + 1 = arg min j β μ k ‖ e ‖ 1 +
1 2 ‖ e − ( A − X + Y 1 k μ k ) ‖ 2 2 = ζ β μ k ( A − X + Y 1 k μ k ) ( 16 )
ζ ξ ( π ) = { π − ξ , π > ξ π + ξ , π < ξ 0, 其 他 ( 17 )
min U ≥ 0 ‖ A − U V ‖ F 2 ( 18 )
‖ A − U V ‖ F 2 = tr ( A − U V ) ( A − U V ) ⊤ =
tr ( A A ⊤ − A V ⊤ U ⊤ − U V A ⊤ + U V V ⊤ U ⊤ ) ( 19 )
假设拉格朗日乘子为ψ i j u i j ≥ 0
L ( U ) = tr ( A A ⊤ − A V ⊤ U ⊤ −
U V A ⊤ + U V V ⊤ U ⊤ ) + tr ( Ψ U ⊤ ) ( 20 )
∂ L ( U ) ∂ U = − 2 A V ⊤ + 2 U V V ⊤ + Ψ ( 21 )
通过KKT条件可知,需要 ψ i j u i j = 0
( − A V ⊤ ) i j u i j + ( U V V ⊤ ) i j u i j = 0 ( 22 )
u i j ← u i j ( A V ⊤ ) i j ( U V V ⊤ ) i j ( 23 )
求解V U
min V ≥ 0 ‖ A − U V ‖ F 2 ( 24 )
L ( V ) = tr ( A A ⊤ − A V ⊤ U ⊤ −
U V A ⊤ + U V V ⊤ U ⊤ ) + tr ( Φ V ⊤ ) ( 25 )
∂ L ( V ) ∂ V = − 2 U ⊤ A + 2 U ⊤ U V + Φ ( 26 )
( − U ⊤ A ) i j v i j + ( U U ⊤ V ) i j v i j = 0 ( 27 )
v i j ← v i j ( U ⊤ A ) i j ( U ⊤ U V ) i j ( 28 )
min R α 2 ‖ R ‖ F 2 + μ 2 ‖ A − R H + Y 2 μ ‖ F 2 ( 29 )
α R + μ R H H ⊤ − ( μ A + Y 2 ) H ⊤ = 0
⇒ R = ( Y 2 + μ A ) H ⊤ ( μ H H ⊤ + α I ) − 1 ( 30 )
min H α 2 ‖ H ‖ F 2 + μ 2 ‖ A − R H + Y 2 μ ‖ F 2 ( 31 )
H = ( μ R ⊤ R + α I ) − 1 R ⊤ ( Y 2 + μ A ) ( 32 )
min p ∑ i , j ‖ y i − y j ‖ 2 2 S i j w − ∑ i , j ‖ y i − y j ‖ 2 2 S i j b ( 33 )
∑ i , j ‖ y i − y j ‖ 2 2 S i j w − ∑ i , j ‖ y i − y j ‖ 2 2 S i j b =
∑ i , j ‖ p ⊤ x i − p ⊤ x j ‖ 2 2 S i j w − ∑ i , j ‖ p ⊤ x i − p ⊤ x j ‖ 2 2 S i j b =
p ⊤ X ( D − S w ) X ⊤ p − p ⊤ X ( H − S b ) X ⊤ p =
p ⊤ X ( L − J ) X ⊤ p ( 34 )
步骤1:初始化E = 0 V = 0 U = 0 Y 1 = Y 2 = 0
Y 1 = Y 1 + μ ( X − A − E )
Y 2 = Y 2 + μ ( X − R H )
4 实验
4.1 数据集
ORL人脸数据库包含400张图像,共40个人,每个人10张图像。每张图像的大小为56×46像素,包含了每个人不同的姿势和面部表情。
Yale人脸数据库的图像数量较少,共165张图像,包含15个人,每个人有11张图像。每张图像的大小为80×100像素,表情、手势和灯光都不一样。
AR人脸数据库包含120个人的2 400张图像,每一张都被裁剪成50×40像素。
FERET人脸数据库包含200个人,每个人都有7张受不同照明影响的图像,共1 400张图像。每张图像都被调整为40×40像素。
PolyU掌纹数据库有100个人的600张图像。每个人的6个样本被采集了两次,采集间隔两个月。
4.2 实验参数
笔者从不同的数据集中选取不同的样本来测试本文提出的方法的性能。选择不同数据集中的t张图像作为训练样本,图像分别来自 ORL、Yale 和AR(t= 3,4,5,6)以及 FERET 人脸数据库(t= 2,3,4,5)。为了证明该方法的准确性,笔者将其与经典的线性方法LDA和低秩方法LRR、流形学习的方法LPP及其监督扩展SLPP、基于非负矩阵分解的方法NMF和鲁棒扩展方法RNMF以及基于相同低秩思想的LRNF方法进行比较。参数α和β的选择范围为{10-4 ,10-2 ,…,102 ,103 }。最后使用最近邻分类器对提取的样本进行分类。
4.3 连续像素遮挡的鲁棒性检验
为了进一步测试 NSLRE 在面对不同层次的连续遮挡数据时的鲁棒性,笔者在图像的不同位置随机添加一些遮挡块,将块大小分别设置为 5×5 和10×10。ORL、Yale、AR 和 FERET 人脸数据库的原始图像及其不同级别连续遮挡的损坏图像见表1 。
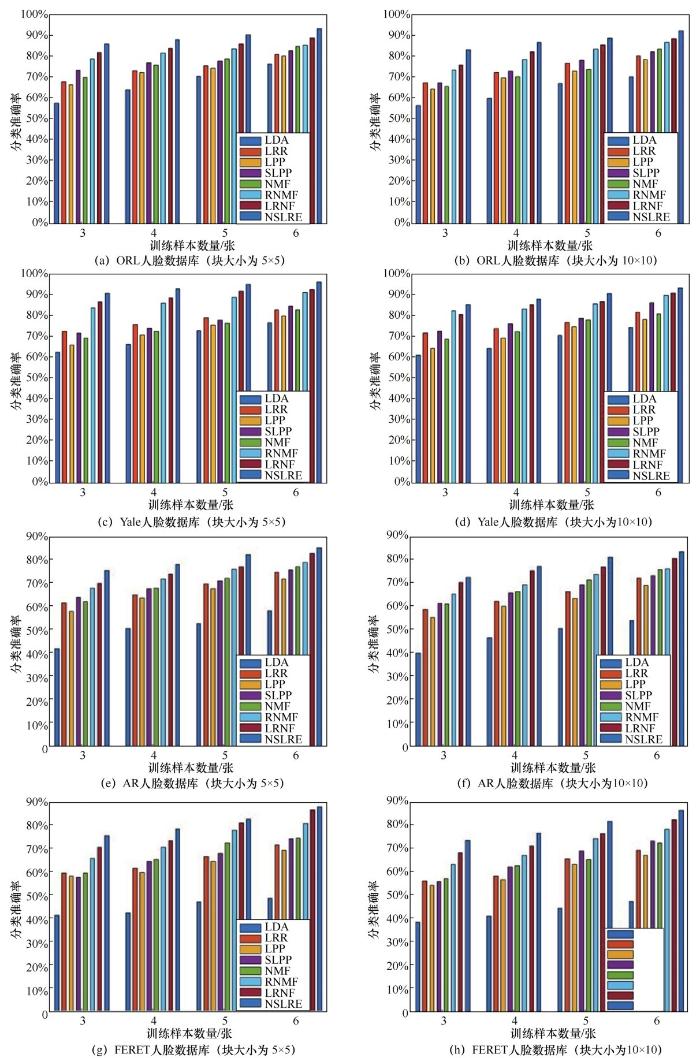
图1 展示了LDA、LRR、LPP、SLPP、NMF、RNMF、LRNF和NSLRE在不同遮挡水平下,在不同数量的训练样本中的最高分类准确率,表2 ,表3 ,表4 ,表5 展示了块遮挡下不同人脸数据库上各算法的最高识别率。
4.4 PolyU掌纹数据库的实验
图1
图1
LDA、LRR、LPP、SLPP、NMF、RNMF、LRNF和NSLRE在ORL、Yale、AR和FERET人脸数据库上的最高分类准确率
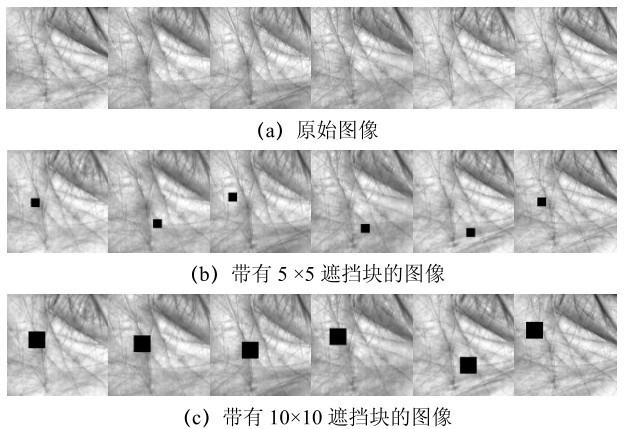
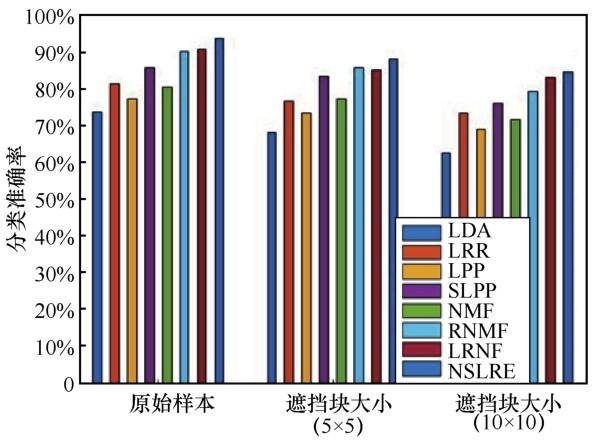
PolyU掌纹数据库包含100个人的600张图像。每张图像的大小都是128×128像素。为了进一步测试NSLRE在掌纹数据库上的鲁棒性,笔者在样本图像上分别添加了大小为 5×5 和 10×10 的遮挡块。PolyU 掌纹数据库的原始图像与分别带有 5×5 和10×10遮挡块的损坏图像如图2 所示。笔者为每个掌纹选取3张图像作为训练样本。实验结果如图3 所示。PolyU掌纹数据库上各算法的最高识别率见表6 。
图2
图2
PolyU掌纹数据库的原始图像与分别带有5×5和10×10遮挡块的损坏图像
图3
图3
LDA、LRR、LPP、SLPP、NMF、RNMF、LRNF和NSLRE在PolyU掌纹数据库上的最高分类准确率
4.5 实验结果与分析
对于人脸数据库,图1 显示了不同方法在ORL、Yale、AR和FERET人脸数据库上的最高识别率随训练样本数量的变化,表2 至表5 显示了不同算法随不同训练样本在不同人脸数据库上的最高识别率。上述结果表明,LPP和SLPP方法作为流形学习方法,识别率较LDA有所提升,因为LPP和SLPP都采用了图嵌入的思想,通过权重图来约束样本相邻点的相似度,流形学习方法更注重于保留数据内在的局部邻域结构。作为一种低秩表示方法,LRR将样本矩阵作为字典并进行自表示,在对噪声的鲁棒性上具有明显的优势。与NMF和RNMF相比, NSLRE因为引入了非负学习的思想,将非负因子分解融入算法中,所以效果更加显著。同时,相比LPP、NMF和LRR,NSLRE的识别率提升了5%~15%,这是因为NSLRE在考虑样本流形结构的情况下引入了低秩表示,通过对矩阵的分解来引入低秩特性提取主要特征,从而获得了更好的鲁棒性。最后,为了测试NSLRE的稳定性,图3 和表6 分别展示了NSLRE在 PolyU 掌纹数据库上原始样本的最高识别率和样本加噪后的最高识别率。从图3 和表6 中可以看出, NSLRE 在经过块遮挡干扰后仍能保持良好的识别率,模型具有良好的鲁棒性。
5 结束语
本文提出了一种新的低秩非负矩阵分解算法——非负监督低秩鉴别嵌入算法,它在一定程度上解决了非负矩阵分解存在的一些问题。此算法有效地结合了低秩表示、非负矩阵分解以及图嵌入的特性。它假设数据被噪声损坏,通过L1 范数约束噪声,通过核范数约束低秩矩阵,并在此基础上进行非负矩阵分解,最后结合图嵌入的方法保留了样本的局部性和全局性,这使得模型的鲁棒性较强。在对不同数据集进行加噪处理后,通过实验对所提算法进行分析,进一步证明了该算法的有效性。
参考文献
View Option
[1]
任克强 , 张静然 . 基于局部Fisher准则判别投影的人脸识别算法
[J]. 传感器与微系统 , 2019 ,38 (7 ): 113 -116 ,120 .
[本文引用: 1]
REN K Q , ZHANG J R . Face recognition algorithm based on local Fisher criterion discriminant projections
[J]. Transducer and Microsystem Technologies , 2019 ,38 (7 ): 113 -116 ,120 .
[本文引用: 1]
[2]
YANG J , ZHANG D , YANG J Y . Constructing PCA baseline algorithms to reevaluate ICA-based face-recognition performance
[J]. IEEE Transactions on Systems,Man,and Cybernetics,Part B (Cybernetics) , 2007 ,37 (4 ): 1015 -1021 .
[本文引用: 1]
[3]
刘文华 , 李浥东 , 王涛 ,等 . 基于高维特征表示的交通场景识别
[J]. 智能科学与技术学报 , 2019 ,1 (4 ): 392 -399 .
[本文引用: 1]
LIU W H , LI Y D , WANG T ,et al . Transportation scene recognition based on high level feature representation
[J]. Chinese Journal of Intelligent Science and Technology , 2019 ,1 (4 ): 392 -399 .
[本文引用: 1]
[4]
ZUO W M , ZHANG D , YANG J ,et al . BDPCA plus LDA:a novel fast feature extraction technique for face recognition
[J]. IEEE Transactions on Systems,Man,and Cybernetics,Part B (Cybernetics) , 2006 ,36 (4 ): 946 -953 .
[本文引用: 1]
[5]
NIE F P , WANG Z , WANG R ,et al . Adaptive local linear discriminant analysis
[J]. ACM Transactions on Knowledge Discovery from Data , 2020 ,14 (1 ): 1 -19 .
[本文引用: 1]
[6]
HOYER P O , . Non-negative sparse coding
[C]// Proceedings of the 12th IEEE Workshop on Neural Networks for Signal Processing . Piscataway:IEEE Press , 2002 : 557 -565 .
[本文引用: 1]
[7]
CAI D , HE X F , HAN J W ,et al . Graph regularized nonnegative matrix factorization for data representation
[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence , 2011 ,33 (8 ): 1548 -1560 .
[本文引用: 1]
[8]
GUAN N Y , TAO D C , LUO Z G ,et al . Manifold regularized discriminative nonnegative matrix factorization with fast gradient descent
[J]. IEEE Transactions on Image Processing , 2011 ,20 (7 ): 2030 -2048 .
[本文引用: 1]
[9]
杜海顺 , 张旭东 . 图嵌入正则化投影非负矩阵分解人脸图像特征提取
[J]. 中国图象图形学报 , 2014 ,19 (8 ): 1176 -1184 .
[本文引用: 1]
DU H S , ZHANG X D . Graph embedding regularized projective non-negative matrix factorization for face image feature extraction
[J]. Journal of Image and Graphics , 2014 ,19 (8 ): 1176 -1184 .
[本文引用: 1]
[10]
ZHANG L J , CHEN Z G , ZHENG M ,et al . Robust non-negative matrix factorization
[J]. Frontiers of Electrical and Electronic Engineering in China , 2011 ,6 (2 ): 192 -200 .
[本文引用: 1]
[11]
KONG D G , DING C , HUANG H . Robust nonnegative matrix factorization using L2.1 -norm
[C]// Proceedings of the 20th ACM International Conference on Information and Knowledge Management . New York:ACM Press , 2011 .
[本文引用: 1]
[12]
WRIGHT J , MA Y , MAIRAL J ,et al . Sparse representation for computer vision and pattern recognition
[J]. Proceedings of the IEEE , 2010 ,98 (6 ): 1031 -1044 .
[本文引用: 1]
[13]
WRIGHT J , YANG A Y , GANESH A ,et al . Robust face recognition via sparse representation
[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence , 2009 ,31 (2 ): 210 -227 .
[本文引用: 1]
[14]
YANG M , ZHANG L . Gabor feature based sparse representation for face recognition with Gabor occlusion dictionary
[C]// Proceedings of the European Conference on Computer Vision .[S.l.:s.n.], 2010 .
[本文引用: 1]
[15]
LIU G C , LIN Z C , YAN S C ,et al . Robust recovery of subspace structures by low-rank representation
[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence , 2013 ,35 (1 ): 171 -184 .
[本文引用: 1]
[16]
LIU G C , LIN Z C , YONG Y . Robust subspace segmentation by low-rank representation
[C]// Proceedings of the International Conference on Machine Learning .[S.l.:s.n.], 2003 : 1615 -1618 .
[本文引用: 1]
[17]
LIU G C , LIN Z C , YONG Y . Robust subspace segmentation by low-rank representation
[C]// Proceedings of the ICML .[S.l.:s.n.], 2010 : 663 -670 .
[本文引用: 1]
[18]
MAZUMDER R , HASTIE T , TIBSHIRANI R . Spectral regularization algorithms for learning large incomplete matrices
[J]. The Journal of Machine Learning Research , 2010 ,11 : 2287 -2322 .
[本文引用: 1]
基于局部Fisher准则判别投影的人脸识别算法
1
2019
... 特征提取是人脸识别中比较重要的步骤,在研究特征提取的过程中产生了许多降维的方法[1 ,2 ,3 ] ,如主成分分析(principal component analysis,PCA)[4 ] 和线性判别分析(liner discriminant analysis,LDA)[5 ] 等,这些方法都能在一定程度上较好地对特征进行提取.与 PCA 和 LDA 不同的是,非负矩阵分解(non-negative matrix factorization,NMF)要求非负矩阵中的所有元素都大于或等于零,在这种约束下,原始数据中的噪声信息被充分过滤,从而使新的数据具有更好的表示能力. ...
基于局部Fisher准则判别投影的人脸识别算法
1
2019
... 特征提取是人脸识别中比较重要的步骤,在研究特征提取的过程中产生了许多降维的方法[1 ,2 ,3 ] ,如主成分分析(principal component analysis,PCA)[4 ] 和线性判别分析(liner discriminant analysis,LDA)[5 ] 等,这些方法都能在一定程度上较好地对特征进行提取.与 PCA 和 LDA 不同的是,非负矩阵分解(non-negative matrix factorization,NMF)要求非负矩阵中的所有元素都大于或等于零,在这种约束下,原始数据中的噪声信息被充分过滤,从而使新的数据具有更好的表示能力. ...
Constructing PCA baseline algorithms to reevaluate ICA-based face-recognition performance
1
2007
... 特征提取是人脸识别中比较重要的步骤,在研究特征提取的过程中产生了许多降维的方法[1 ,2 ,3 ] ,如主成分分析(principal component analysis,PCA)[4 ] 和线性判别分析(liner discriminant analysis,LDA)[5 ] 等,这些方法都能在一定程度上较好地对特征进行提取.与 PCA 和 LDA 不同的是,非负矩阵分解(non-negative matrix factorization,NMF)要求非负矩阵中的所有元素都大于或等于零,在这种约束下,原始数据中的噪声信息被充分过滤,从而使新的数据具有更好的表示能力. ...
基于高维特征表示的交通场景识别
1
2019
... 特征提取是人脸识别中比较重要的步骤,在研究特征提取的过程中产生了许多降维的方法[1 ,2 ,3 ] ,如主成分分析(principal component analysis,PCA)[4 ] 和线性判别分析(liner discriminant analysis,LDA)[5 ] 等,这些方法都能在一定程度上较好地对特征进行提取.与 PCA 和 LDA 不同的是,非负矩阵分解(non-negative matrix factorization,NMF)要求非负矩阵中的所有元素都大于或等于零,在这种约束下,原始数据中的噪声信息被充分过滤,从而使新的数据具有更好的表示能力. ...
基于高维特征表示的交通场景识别
1
2019
... 特征提取是人脸识别中比较重要的步骤,在研究特征提取的过程中产生了许多降维的方法[1 ,2 ,3 ] ,如主成分分析(principal component analysis,PCA)[4 ] 和线性判别分析(liner discriminant analysis,LDA)[5 ] 等,这些方法都能在一定程度上较好地对特征进行提取.与 PCA 和 LDA 不同的是,非负矩阵分解(non-negative matrix factorization,NMF)要求非负矩阵中的所有元素都大于或等于零,在这种约束下,原始数据中的噪声信息被充分过滤,从而使新的数据具有更好的表示能力. ...
BDPCA plus LDA:a novel fast feature extraction technique for face recognition
1
2006
... 特征提取是人脸识别中比较重要的步骤,在研究特征提取的过程中产生了许多降维的方法[1 ,2 ,3 ] ,如主成分分析(principal component analysis,PCA)[4 ] 和线性判别分析(liner discriminant analysis,LDA)[5 ] 等,这些方法都能在一定程度上较好地对特征进行提取.与 PCA 和 LDA 不同的是,非负矩阵分解(non-negative matrix factorization,NMF)要求非负矩阵中的所有元素都大于或等于零,在这种约束下,原始数据中的噪声信息被充分过滤,从而使新的数据具有更好的表示能力. ...
Adaptive local linear discriminant analysis
1
2020
... 特征提取是人脸识别中比较重要的步骤,在研究特征提取的过程中产生了许多降维的方法[1 ,2 ,3 ] ,如主成分分析(principal component analysis,PCA)[4 ] 和线性判别分析(liner discriminant analysis,LDA)[5 ] 等,这些方法都能在一定程度上较好地对特征进行提取.与 PCA 和 LDA 不同的是,非负矩阵分解(non-negative matrix factorization,NMF)要求非负矩阵中的所有元素都大于或等于零,在这种约束下,原始数据中的噪声信息被充分过滤,从而使新的数据具有更好的表示能力. ...
Non-negative sparse coding
1
2002
... 作为一种基于局部的提取方法,NMF在特征提取领域已得到广泛使用,同时也产生了许多 NMF的扩展方法,包括稀疏NMF、鉴别NMF、正交NMF以及流形 NMF 等.有学者通过对非负矩阵施加稀疏编码,提出了一种新的非负稀疏编码(non-negative sparse coding,NNSC)方法[6 ] ,很大程度上增强了NMF的稀疏表示能力.Cai D等人[7 ] 将 NMF 与流形结构结合,提出了图正则化 NMF (graph regularized NMF,GNMF)算法,从而保持了数据的内在几何结构.类似的算法还有流形正则化判别 NMF(manifold regularized discriminative NMF,MD-NMF)[8 ] 、图嵌入正则化投影NMF(graph embedding regularized projection NMF,GEPNMF)[9 ] 等.这些扩展算法都使 NMF 方法的能力得到了很大的提高. ...
Graph regularized nonnegative matrix factorization for data representation
1
2011
... 作为一种基于局部的提取方法,NMF在特征提取领域已得到广泛使用,同时也产生了许多 NMF的扩展方法,包括稀疏NMF、鉴别NMF、正交NMF以及流形 NMF 等.有学者通过对非负矩阵施加稀疏编码,提出了一种新的非负稀疏编码(non-negative sparse coding,NNSC)方法[6 ] ,很大程度上增强了NMF的稀疏表示能力.Cai D等人[7 ] 将 NMF 与流形结构结合,提出了图正则化 NMF (graph regularized NMF,GNMF)算法,从而保持了数据的内在几何结构.类似的算法还有流形正则化判别 NMF(manifold regularized discriminative NMF,MD-NMF)[8 ] 、图嵌入正则化投影NMF(graph embedding regularized projection NMF,GEPNMF)[9 ] 等.这些扩展算法都使 NMF 方法的能力得到了很大的提高. ...
Manifold regularized discriminative nonnegative matrix factorization with fast gradient descent
1
2011
... 作为一种基于局部的提取方法,NMF在特征提取领域已得到广泛使用,同时也产生了许多 NMF的扩展方法,包括稀疏NMF、鉴别NMF、正交NMF以及流形 NMF 等.有学者通过对非负矩阵施加稀疏编码,提出了一种新的非负稀疏编码(non-negative sparse coding,NNSC)方法[6 ] ,很大程度上增强了NMF的稀疏表示能力.Cai D等人[7 ] 将 NMF 与流形结构结合,提出了图正则化 NMF (graph regularized NMF,GNMF)算法,从而保持了数据的内在几何结构.类似的算法还有流形正则化判别 NMF(manifold regularized discriminative NMF,MD-NMF)[8 ] 、图嵌入正则化投影NMF(graph embedding regularized projection NMF,GEPNMF)[9 ] 等.这些扩展算法都使 NMF 方法的能力得到了很大的提高. ...
图嵌入正则化投影非负矩阵分解人脸图像特征提取
1
2014
... 作为一种基于局部的提取方法,NMF在特征提取领域已得到广泛使用,同时也产生了许多 NMF的扩展方法,包括稀疏NMF、鉴别NMF、正交NMF以及流形 NMF 等.有学者通过对非负矩阵施加稀疏编码,提出了一种新的非负稀疏编码(non-negative sparse coding,NNSC)方法[6 ] ,很大程度上增强了NMF的稀疏表示能力.Cai D等人[7 ] 将 NMF 与流形结构结合,提出了图正则化 NMF (graph regularized NMF,GNMF)算法,从而保持了数据的内在几何结构.类似的算法还有流形正则化判别 NMF(manifold regularized discriminative NMF,MD-NMF)[8 ] 、图嵌入正则化投影NMF(graph embedding regularized projection NMF,GEPNMF)[9 ] 等.这些扩展算法都使 NMF 方法的能力得到了很大的提高. ...
图嵌入正则化投影非负矩阵分解人脸图像特征提取
1
2014
... 作为一种基于局部的提取方法,NMF在特征提取领域已得到广泛使用,同时也产生了许多 NMF的扩展方法,包括稀疏NMF、鉴别NMF、正交NMF以及流形 NMF 等.有学者通过对非负矩阵施加稀疏编码,提出了一种新的非负稀疏编码(non-negative sparse coding,NNSC)方法[6 ] ,很大程度上增强了NMF的稀疏表示能力.Cai D等人[7 ] 将 NMF 与流形结构结合,提出了图正则化 NMF (graph regularized NMF,GNMF)算法,从而保持了数据的内在几何结构.类似的算法还有流形正则化判别 NMF(manifold regularized discriminative NMF,MD-NMF)[8 ] 、图嵌入正则化投影NMF(graph embedding regularized projection NMF,GEPNMF)[9 ] 等.这些扩展算法都使 NMF 方法的能力得到了很大的提高. ...
Robust non-negative matrix factorization
1
2011
... 尽管许多 NMF 方法结合了不同的性质,如稀疏性、判别能力或流形结构,但这些基于 NMF 的方法都将欧氏距离作为度量,该度量对数据噪声非常敏感.为了增强 NMF 的鲁棒性,人们也提出了一些鲁棒的NMF方法,如鲁棒NMF(robust NMF, RNMF)[10 ] 、基于L2.1 范数的NMF [11 ] 等.这些鲁棒的 NMF 方法都是基于局部学习的,忽略了数据的全局信息.然而在实际应用中,数据中的噪声的全局分布大多是不规律的.因此,现有的鲁棒的NMF方法的鲁棒性是有限的.事实上,在对损坏数据进行分类时,数据的全局信息比局部信息具有更强的鲁棒性. ...
Robust nonnegative matrix factorization using L2.1 -norm
1
2011
... 尽管许多 NMF 方法结合了不同的性质,如稀疏性、判别能力或流形结构,但这些基于 NMF 的方法都将欧氏距离作为度量,该度量对数据噪声非常敏感.为了增强 NMF 的鲁棒性,人们也提出了一些鲁棒的NMF方法,如鲁棒NMF(robust NMF, RNMF)[10 ] 、基于L2.1 范数的NMF [11 ] 等.这些鲁棒的 NMF 方法都是基于局部学习的,忽略了数据的全局信息.然而在实际应用中,数据中的噪声的全局分布大多是不规律的.因此,现有的鲁棒的NMF方法的鲁棒性是有限的.事实上,在对损坏数据进行分类时,数据的全局信息比局部信息具有更强的鲁棒性. ...
Sparse representation for computer vision and pattern recognition
1
2010
... 低秩表示(low-rank representation,LRR)可以捕获数据的全局结构,揭示样本的隶属度.在图像分类中,局部信息和全局信息在特征提取和分类中都起着重要作用.NMF 方法在局部特征学习上具有较强的能力,但忽略了数据的全局信息,为了保持局部特征学习和全局学习能力,在 LRR 的激励下,本文提出了一种利用低秩、非负监督约束和稀疏性[12 ,13 ,14 ] 的算法——非负监督低秩鉴别嵌入(non-negative supervised low-rank discriminant embedding,NSLRE)来分类被破坏的数据.笔者假设数据被严重损坏,并将L1 范数作为假定的噪声矩阵的稀疏约束.NSLRE先学习低秩矩阵、恢复干净矩阵并去除数据中的噪声;然后,对学习到的低秩矩阵进行非负因子分解,保持数据的局部表示能力,在此基础上结合流形正则化保持数据的局部几何结构,进一步增强 NMF的局部属性.NSLRE能够同时进行低秩学习和非负性学习,能够很好地获得基于局部和全局的数据表示.这保证了 NMF 中两个非负矩阵的构造不受噪声的影响.该算法既能保留数据的局部几何信息,又能进行去噪处理,对有噪声的图像分类任务有较好的处理效果.该算法的主要优点如下. ...
Robust face recognition via sparse representation
1
2009
... 低秩表示(low-rank representation,LRR)可以捕获数据的全局结构,揭示样本的隶属度.在图像分类中,局部信息和全局信息在特征提取和分类中都起着重要作用.NMF 方法在局部特征学习上具有较强的能力,但忽略了数据的全局信息,为了保持局部特征学习和全局学习能力,在 LRR 的激励下,本文提出了一种利用低秩、非负监督约束和稀疏性[12 ,13 ,14 ] 的算法——非负监督低秩鉴别嵌入(non-negative supervised low-rank discriminant embedding,NSLRE)来分类被破坏的数据.笔者假设数据被严重损坏,并将L1 范数作为假定的噪声矩阵的稀疏约束.NSLRE先学习低秩矩阵、恢复干净矩阵并去除数据中的噪声;然后,对学习到的低秩矩阵进行非负因子分解,保持数据的局部表示能力,在此基础上结合流形正则化保持数据的局部几何结构,进一步增强 NMF的局部属性.NSLRE能够同时进行低秩学习和非负性学习,能够很好地获得基于局部和全局的数据表示.这保证了 NMF 中两个非负矩阵的构造不受噪声的影响.该算法既能保留数据的局部几何信息,又能进行去噪处理,对有噪声的图像分类任务有较好的处理效果.该算法的主要优点如下. ...
Gabor feature based sparse representation for face recognition with Gabor occlusion dictionary
1
2010
... 低秩表示(low-rank representation,LRR)可以捕获数据的全局结构,揭示样本的隶属度.在图像分类中,局部信息和全局信息在特征提取和分类中都起着重要作用.NMF 方法在局部特征学习上具有较强的能力,但忽略了数据的全局信息,为了保持局部特征学习和全局学习能力,在 LRR 的激励下,本文提出了一种利用低秩、非负监督约束和稀疏性[12 ,13 ,14 ] 的算法——非负监督低秩鉴别嵌入(non-negative supervised low-rank discriminant embedding,NSLRE)来分类被破坏的数据.笔者假设数据被严重损坏,并将L1 范数作为假定的噪声矩阵的稀疏约束.NSLRE先学习低秩矩阵、恢复干净矩阵并去除数据中的噪声;然后,对学习到的低秩矩阵进行非负因子分解,保持数据的局部表示能力,在此基础上结合流形正则化保持数据的局部几何结构,进一步增强 NMF的局部属性.NSLRE能够同时进行低秩学习和非负性学习,能够很好地获得基于局部和全局的数据表示.这保证了 NMF 中两个非负矩阵的构造不受噪声的影响.该算法既能保留数据的局部几何信息,又能进行去噪处理,对有噪声的图像分类任务有较好的处理效果.该算法的主要优点如下. ...
Robust recovery of subspace structures by low-rank representation
1
2013
... 为了解决子空间分解问题,有学者提出了LRR[15 ,16 ,17 ] 方法,LRR的数据向量是其他样本的线性组合.与稀疏表示不同,LRR联合搜索所有数据的最低秩表示,捕获数据的全局结构. ...
Robust subspace segmentation by low-rank representation
1
2003
... 为了解决子空间分解问题,有学者提出了LRR[15 ,16 ,17 ] 方法,LRR的数据向量是其他样本的线性组合.与稀疏表示不同,LRR联合搜索所有数据的最低秩表示,捕获数据的全局结构. ...
Robust subspace segmentation by low-rank representation
1
2010
... 为了解决子空间分解问题,有学者提出了LRR[15 ,16 ,17 ] 方法,LRR的数据向量是其他样本的线性组合.与稀疏表示不同,LRR联合搜索所有数据的最低秩表示,捕获数据的全局结构. ...
Spectral regularization algorithms for learning large incomplete matrices
1
2010
... 笔者用交替方向乘子法(alternating direction method of multiplier,ADMM)或增广拉格朗日乘子法(augmented Lagrangian multiplier,ALM)来解决式(4)~式(10).具体利用核范数[18 ] 的下列性质来解决. ...



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}