The typical sparse representation for classification (SRC) is usually based on L1minimization problem.Conceptually, SRC is essentially an L0norm minimization problem solved in the original input space, which cannot capture well the nonlinear information within the data.In order to address this problem, a nonlinear mapping to map the original input data into a new high dimensional feature space was applied, and a new representation approach based on L0norm was proposed.The representing dictionary used to represent the test sample contains two parts in the proposed approach.The first part is fixed to the neighbors of the test sample.The training samples of the second part is chosen by the variation of genetic algorithm (GA), i.e., the semi GA (SGA) algorithm, which exploits the representation error to determine the second part of the representing dictionary.In the approach, if the training samples combining the determined neighbors of the test sample yield the least representation error, these training samples are determined as the second part of the representing dictionary by SGA.Experiments on several popular face databases and one handwritten digit data set demonstrate that the proposed approach can achieve better classification performance.
SHI Linrui. Sparse representation for image recognition based on semi-genetic algorithm in feature space. Chinese Journal of Intelligent Science and Technology[J], 2021, 3(3): 359-369 doi:10.11959/j.issn.2096-6652.202137
1 引言
基于 L1 范数及其变体[1,2,3,4]的稀疏表示分类(sparse representation for classification,SRC)[5,6,7,8]已被广泛应用于图像识别,如人脸识别[9-10]、手写数字数据识别和其他应用[11,12,13,14]。从本质上讲,SRC可以看作经典最近邻(nearest neighbor,NN)分类器的泛化。与使用一个子空间学习获得的特征提取器的经典NN分类器相比,如线性判别分析(linear discriminative analysis,LDA)[15],SRC 可以在分类精度方面获得更好的分类性能,特别是当它被应用于对有噪声或损坏的数据进行分类时。
综上,本文提出的方法包含以下步骤。第一步是指定一个非线性映射,将输入数据转换到高维特征空间;第二步是采用半遗传算法确定表示字典,然后用确定的字典来表示测试样本;最后,利用表示结果对测试样本进行分类。本文提出的方法被称为核遗传稀疏表示(kernel GA sparse representation, KGASR)算法,它有以下贡献。
在确定了测试样本的 K 个近邻后,需要使用SGA确定整个表示字典。在SGA中,表示字典的第一部分是固定的。SGA将表示误差最小的样本作为表示字典的第二部分。在描述 SGA 过程之前,先给出一些关于遗传算法的基本概念(详情请见参考文献[44])。第一个概念是个体或状态,通常表示为0和1的串。个体的每个元素都与一个训练样本相关联。许多个体生成种群,这是遗传算法术语中的第二个基本概念。每个个体通常通过适应度函数进行评估。
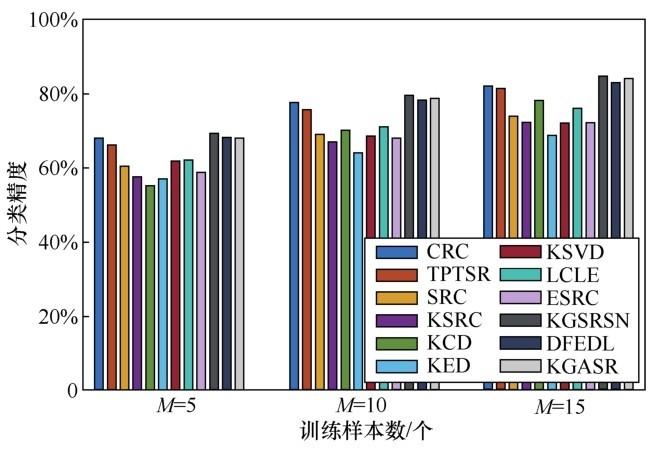
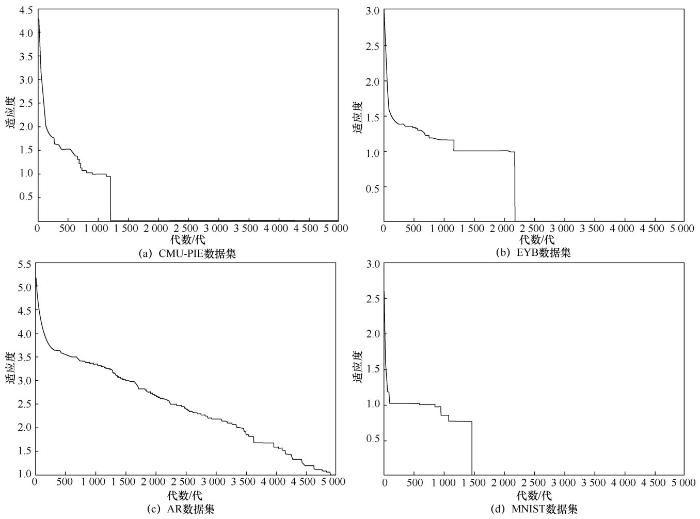
笔者在4个流行的数据集上进行了实验,以证明提出的方法可以在分类精度方面达到理想的性能。数据集包括CMU-PIE、EYB(Extended YaleB)、AR和MNIST数据集。前3个数据集是人脸图像数据集,第4个数据集是手写数字数据集。在本文的实验部分,笔者比较了一些经典的基于表示的分类方法,如协作表示分类(collaborative representation for classification,CRC)[16]、SRC[1]、KSRC[22]、核坐标下降[30]、扩展SRC(extended SRC,ESRC)[17]、两阶段测试样本稀疏表示(two-phase test sample sparse representation,TPTSR)[39]和通过结构和非凸约束的核群稀疏表示方法(KGSRSN)[45]。本文提出的算法可被看作字典学习方法的一种。因此,将提出的方法与一些典型的字典学习方法进行了比较,它们分别是核扩展字典(KED)算法[29]、局部约束和标签嵌入(locality-constrained and label embedding,LCLE)字典学习方法[46]、K奇异值分解(K-singular value decomposition,KSVD)算法[47]和鉴别Fisher嵌入字典学习算法(DFEDL)[48]。
... 笔者在4个流行的数据集上进行了实验,以证明提出的方法可以在分类精度方面达到理想的性能.数据集包括CMU-PIE、EYB(Extended YaleB)、AR和MNIST数据集.前3个数据集是人脸图像数据集,第4个数据集是手写数字数据集.在本文的实验部分,笔者比较了一些经典的基于表示的分类方法,如协作表示分类(collaborative representation for classification,CRC)[16]、SRC[1]、KSRC[22]、核坐标下降[30]、扩展SRC(extended SRC,ESRC)[17]、两阶段测试样本稀疏表示(two-phase test sample sparse representation,TPTSR)[39]和通过结构和非凸约束的核群稀疏表示方法(KGSRSN)[45].本文提出的算法可被看作字典学习方法的一种.因此,将提出的方法与一些典型的字典学习方法进行了比较,它们分别是核扩展字典(KED)算法[29]、局部约束和标签嵌入(locality-constrained and label embedding,LCLE)字典学习方法[46]、K奇异值分解(K-singular value decomposition,KSVD)算法[47]和鉴别Fisher嵌入字典学习算法(DFEDL)[48]. ...
... 笔者在4个流行的数据集上进行了实验,以证明提出的方法可以在分类精度方面达到理想的性能.数据集包括CMU-PIE、EYB(Extended YaleB)、AR和MNIST数据集.前3个数据集是人脸图像数据集,第4个数据集是手写数字数据集.在本文的实验部分,笔者比较了一些经典的基于表示的分类方法,如协作表示分类(collaborative representation for classification,CRC)[16]、SRC[1]、KSRC[22]、核坐标下降[30]、扩展SRC(extended SRC,ESRC)[17]、两阶段测试样本稀疏表示(two-phase test sample sparse representation,TPTSR)[39]和通过结构和非凸约束的核群稀疏表示方法(KGSRSN)[45].本文提出的算法可被看作字典学习方法的一种.因此,将提出的方法与一些典型的字典学习方法进行了比较,它们分别是核扩展字典(KED)算法[29]、局部约束和标签嵌入(locality-constrained and label embedding,LCLE)字典学习方法[46]、K奇异值分解(K-singular value decomposition,KSVD)算法[47]和鉴别Fisher嵌入字典学习算法(DFEDL)[48]. ...
Extended SRC:undersampled face recognition via intraclass variant dictionary
... 笔者在4个流行的数据集上进行了实验,以证明提出的方法可以在分类精度方面达到理想的性能.数据集包括CMU-PIE、EYB(Extended YaleB)、AR和MNIST数据集.前3个数据集是人脸图像数据集,第4个数据集是手写数字数据集.在本文的实验部分,笔者比较了一些经典的基于表示的分类方法,如协作表示分类(collaborative representation for classification,CRC)[16]、SRC[1]、KSRC[22]、核坐标下降[30]、扩展SRC(extended SRC,ESRC)[17]、两阶段测试样本稀疏表示(two-phase test sample sparse representation,TPTSR)[39]和通过结构和非凸约束的核群稀疏表示方法(KGSRSN)[45].本文提出的算法可被看作字典学习方法的一种.因此,将提出的方法与一些典型的字典学习方法进行了比较,它们分别是核扩展字典(KED)算法[29]、局部约束和标签嵌入(locality-constrained and label embedding,LCLE)字典学习方法[46]、K奇异值分解(K-singular value decomposition,KSVD)算法[47]和鉴别Fisher嵌入字典学习算法(DFEDL)[48]. ...
... 本文利用 L0范数最小化来建立一种新的 SRC模型,以克服经典 SRC 模型的不足.经典的 SRC模型可能存在另一个问题,即经典的SRC模型不能很好地处理不同类的样本分布在同一向量方向上的数据集[22],即不同类别相同方向(different class same direction,DCSD).为了解决这个问题,Zhang L等人[22]借用了基于核方法的思想,如支持向量机(support vector machine,SVM)[23].他们选择了一个合适的非线性映射,利用该映射将原始输入数据映射到一个高维数据空间,即特征空间,这个特征空间被称为再现核Hibert空间(reproducing kernel Hibert space,RKHS)[24],然后在该特征空间中执行 SRC.这种方法被称为基于核的稀疏表示分类(kernel based SRC,KSRC)[24,25,26],理论上可以避免上述DCSD问题.此外,它可以很好地获取数据集中的非线性信息,有助于对样本进行正确分类[26].基于核的稀疏表示方法可被应用在许多领域中.例如,Song B等人[27]利用核稀疏表示对遥感图像进行一类分类.Zhou Y等人[28]提出了一种基于核稀疏表示(kernel sparse representation,KSR)的手势识别算法,该算法对人类手势较大的变化具有鲁棒性.Huang K K 等人[29]结合SRC和核判别分析(kernel discriminant analysis,KDA)算法开发了一种核扩展字典(kernel extended dictionary,KED)方法,该方法可以学习大量用于人脸识别的字典.Wang L等人[30]采用核坐标下降法(kernel coordinate descent,KCD)求解KSR,该方法可用于视觉跟踪任务.受核方法思想[31]的启发,本文提出的方法首先使用适当的非线性映射将原始输入数据转换到高维特征空间,然后利用L0范数最小化实现SRC模型.因此,本文提出的方法可以有效地获取非线性信息,避免了之前工作[32]在理论上无法有效解决的DCSD问题. ...
... [22]借用了基于核方法的思想,如支持向量机(support vector machine,SVM)[23].他们选择了一个合适的非线性映射,利用该映射将原始输入数据映射到一个高维数据空间,即特征空间,这个特征空间被称为再现核Hibert空间(reproducing kernel Hibert space,RKHS)[24],然后在该特征空间中执行 SRC.这种方法被称为基于核的稀疏表示分类(kernel based SRC,KSRC)[24,25,26],理论上可以避免上述DCSD问题.此外,它可以很好地获取数据集中的非线性信息,有助于对样本进行正确分类[26].基于核的稀疏表示方法可被应用在许多领域中.例如,Song B等人[27]利用核稀疏表示对遥感图像进行一类分类.Zhou Y等人[28]提出了一种基于核稀疏表示(kernel sparse representation,KSR)的手势识别算法,该算法对人类手势较大的变化具有鲁棒性.Huang K K 等人[29]结合SRC和核判别分析(kernel discriminant analysis,KDA)算法开发了一种核扩展字典(kernel extended dictionary,KED)方法,该方法可以学习大量用于人脸识别的字典.Wang L等人[30]采用核坐标下降法(kernel coordinate descent,KCD)求解KSR,该方法可用于视觉跟踪任务.受核方法思想[31]的启发,本文提出的方法首先使用适当的非线性映射将原始输入数据转换到高维特征空间,然后利用L0范数最小化实现SRC模型.因此,本文提出的方法可以有效地获取非线性信息,避免了之前工作[32]在理论上无法有效解决的DCSD问题. ...
... 笔者在4个流行的数据集上进行了实验,以证明提出的方法可以在分类精度方面达到理想的性能.数据集包括CMU-PIE、EYB(Extended YaleB)、AR和MNIST数据集.前3个数据集是人脸图像数据集,第4个数据集是手写数字数据集.在本文的实验部分,笔者比较了一些经典的基于表示的分类方法,如协作表示分类(collaborative representation for classification,CRC)[16]、SRC[1]、KSRC[22]、核坐标下降[30]、扩展SRC(extended SRC,ESRC)[17]、两阶段测试样本稀疏表示(two-phase test sample sparse representation,TPTSR)[39]和通过结构和非凸约束的核群稀疏表示方法(KGSRSN)[45].本文提出的算法可被看作字典学习方法的一种.因此,将提出的方法与一些典型的字典学习方法进行了比较,它们分别是核扩展字典(KED)算法[29]、局部约束和标签嵌入(locality-constrained and label embedding,LCLE)字典学习方法[46]、K奇异值分解(K-singular value decomposition,KSVD)算法[47]和鉴别Fisher嵌入字典学习算法(DFEDL)[48]. ...
LIBSVM:a library for support vector machines
1
2011
... 本文利用 L0范数最小化来建立一种新的 SRC模型,以克服经典 SRC 模型的不足.经典的 SRC模型可能存在另一个问题,即经典的SRC模型不能很好地处理不同类的样本分布在同一向量方向上的数据集[22],即不同类别相同方向(different class same direction,DCSD).为了解决这个问题,Zhang L等人[22]借用了基于核方法的思想,如支持向量机(support vector machine,SVM)[23].他们选择了一个合适的非线性映射,利用该映射将原始输入数据映射到一个高维数据空间,即特征空间,这个特征空间被称为再现核Hibert空间(reproducing kernel Hibert space,RKHS)[24],然后在该特征空间中执行 SRC.这种方法被称为基于核的稀疏表示分类(kernel based SRC,KSRC)[24,25,26],理论上可以避免上述DCSD问题.此外,它可以很好地获取数据集中的非线性信息,有助于对样本进行正确分类[26].基于核的稀疏表示方法可被应用在许多领域中.例如,Song B等人[27]利用核稀疏表示对遥感图像进行一类分类.Zhou Y等人[28]提出了一种基于核稀疏表示(kernel sparse representation,KSR)的手势识别算法,该算法对人类手势较大的变化具有鲁棒性.Huang K K 等人[29]结合SRC和核判别分析(kernel discriminant analysis,KDA)算法开发了一种核扩展字典(kernel extended dictionary,KED)方法,该方法可以学习大量用于人脸识别的字典.Wang L等人[30]采用核坐标下降法(kernel coordinate descent,KCD)求解KSR,该方法可用于视觉跟踪任务.受核方法思想[31]的启发,本文提出的方法首先使用适当的非线性映射将原始输入数据转换到高维特征空间,然后利用L0范数最小化实现SRC模型.因此,本文提出的方法可以有效地获取非线性信息,避免了之前工作[32]在理论上无法有效解决的DCSD问题. ...
Multiple kernel sparse representa tion-based orthogonal discriminative projection and its cost-sensitive extension
2
2016
... 本文利用 L0范数最小化来建立一种新的 SRC模型,以克服经典 SRC 模型的不足.经典的 SRC模型可能存在另一个问题,即经典的SRC模型不能很好地处理不同类的样本分布在同一向量方向上的数据集[22],即不同类别相同方向(different class same direction,DCSD).为了解决这个问题,Zhang L等人[22]借用了基于核方法的思想,如支持向量机(support vector machine,SVM)[23].他们选择了一个合适的非线性映射,利用该映射将原始输入数据映射到一个高维数据空间,即特征空间,这个特征空间被称为再现核Hibert空间(reproducing kernel Hibert space,RKHS)[24],然后在该特征空间中执行 SRC.这种方法被称为基于核的稀疏表示分类(kernel based SRC,KSRC)[24,25,26],理论上可以避免上述DCSD问题.此外,它可以很好地获取数据集中的非线性信息,有助于对样本进行正确分类[26].基于核的稀疏表示方法可被应用在许多领域中.例如,Song B等人[27]利用核稀疏表示对遥感图像进行一类分类.Zhou Y等人[28]提出了一种基于核稀疏表示(kernel sparse representation,KSR)的手势识别算法,该算法对人类手势较大的变化具有鲁棒性.Huang K K 等人[29]结合SRC和核判别分析(kernel discriminant analysis,KDA)算法开发了一种核扩展字典(kernel extended dictionary,KED)方法,该方法可以学习大量用于人脸识别的字典.Wang L等人[30]采用核坐标下降法(kernel coordinate descent,KCD)求解KSR,该方法可用于视觉跟踪任务.受核方法思想[31]的启发,本文提出的方法首先使用适当的非线性映射将原始输入数据转换到高维特征空间,然后利用L0范数最小化实现SRC模型.因此,本文提出的方法可以有效地获取非线性信息,避免了之前工作[32]在理论上无法有效解决的DCSD问题. ...
... [24,25,26],理论上可以避免上述DCSD问题.此外,它可以很好地获取数据集中的非线性信息,有助于对样本进行正确分类[26].基于核的稀疏表示方法可被应用在许多领域中.例如,Song B等人[27]利用核稀疏表示对遥感图像进行一类分类.Zhou Y等人[28]提出了一种基于核稀疏表示(kernel sparse representation,KSR)的手势识别算法,该算法对人类手势较大的变化具有鲁棒性.Huang K K 等人[29]结合SRC和核判别分析(kernel discriminant analysis,KDA)算法开发了一种核扩展字典(kernel extended dictionary,KED)方法,该方法可以学习大量用于人脸识别的字典.Wang L等人[30]采用核坐标下降法(kernel coordinate descent,KCD)求解KSR,该方法可用于视觉跟踪任务.受核方法思想[31]的启发,本文提出的方法首先使用适当的非线性映射将原始输入数据转换到高维特征空间,然后利用L0范数最小化实现SRC模型.因此,本文提出的方法可以有效地获取非线性信息,避免了之前工作[32]在理论上无法有效解决的DCSD问题. ...
Class-discriminative kernel sparse representation-based classification using multi-objective optimization
1
2013
... 本文利用 L0范数最小化来建立一种新的 SRC模型,以克服经典 SRC 模型的不足.经典的 SRC模型可能存在另一个问题,即经典的SRC模型不能很好地处理不同类的样本分布在同一向量方向上的数据集[22],即不同类别相同方向(different class same direction,DCSD).为了解决这个问题,Zhang L等人[22]借用了基于核方法的思想,如支持向量机(support vector machine,SVM)[23].他们选择了一个合适的非线性映射,利用该映射将原始输入数据映射到一个高维数据空间,即特征空间,这个特征空间被称为再现核Hibert空间(reproducing kernel Hibert space,RKHS)[24],然后在该特征空间中执行 SRC.这种方法被称为基于核的稀疏表示分类(kernel based SRC,KSRC)[24,25,26],理论上可以避免上述DCSD问题.此外,它可以很好地获取数据集中的非线性信息,有助于对样本进行正确分类[26].基于核的稀疏表示方法可被应用在许多领域中.例如,Song B等人[27]利用核稀疏表示对遥感图像进行一类分类.Zhou Y等人[28]提出了一种基于核稀疏表示(kernel sparse representation,KSR)的手势识别算法,该算法对人类手势较大的变化具有鲁棒性.Huang K K 等人[29]结合SRC和核判别分析(kernel discriminant analysis,KDA)算法开发了一种核扩展字典(kernel extended dictionary,KED)方法,该方法可以学习大量用于人脸识别的字典.Wang L等人[30]采用核坐标下降法(kernel coordinate descent,KCD)求解KSR,该方法可用于视觉跟踪任务.受核方法思想[31]的启发,本文提出的方法首先使用适当的非线性映射将原始输入数据转换到高维特征空间,然后利用L0范数最小化实现SRC模型.因此,本文提出的方法可以有效地获取非线性信息,避免了之前工作[32]在理论上无法有效解决的DCSD问题. ...
Sparse representation with kernels
2
2012
... 本文利用 L0范数最小化来建立一种新的 SRC模型,以克服经典 SRC 模型的不足.经典的 SRC模型可能存在另一个问题,即经典的SRC模型不能很好地处理不同类的样本分布在同一向量方向上的数据集[22],即不同类别相同方向(different class same direction,DCSD).为了解决这个问题,Zhang L等人[22]借用了基于核方法的思想,如支持向量机(support vector machine,SVM)[23].他们选择了一个合适的非线性映射,利用该映射将原始输入数据映射到一个高维数据空间,即特征空间,这个特征空间被称为再现核Hibert空间(reproducing kernel Hibert space,RKHS)[24],然后在该特征空间中执行 SRC.这种方法被称为基于核的稀疏表示分类(kernel based SRC,KSRC)[24,25,26],理论上可以避免上述DCSD问题.此外,它可以很好地获取数据集中的非线性信息,有助于对样本进行正确分类[26].基于核的稀疏表示方法可被应用在许多领域中.例如,Song B等人[27]利用核稀疏表示对遥感图像进行一类分类.Zhou Y等人[28]提出了一种基于核稀疏表示(kernel sparse representation,KSR)的手势识别算法,该算法对人类手势较大的变化具有鲁棒性.Huang K K 等人[29]结合SRC和核判别分析(kernel discriminant analysis,KDA)算法开发了一种核扩展字典(kernel extended dictionary,KED)方法,该方法可以学习大量用于人脸识别的字典.Wang L等人[30]采用核坐标下降法(kernel coordinate descent,KCD)求解KSR,该方法可用于视觉跟踪任务.受核方法思想[31]的启发,本文提出的方法首先使用适当的非线性映射将原始输入数据转换到高维特征空间,然后利用L0范数最小化实现SRC模型.因此,本文提出的方法可以有效地获取非线性信息,避免了之前工作[32]在理论上无法有效解决的DCSD问题. ...
... [26].基于核的稀疏表示方法可被应用在许多领域中.例如,Song B等人[27]利用核稀疏表示对遥感图像进行一类分类.Zhou Y等人[28]提出了一种基于核稀疏表示(kernel sparse representation,KSR)的手势识别算法,该算法对人类手势较大的变化具有鲁棒性.Huang K K 等人[29]结合SRC和核判别分析(kernel discriminant analysis,KDA)算法开发了一种核扩展字典(kernel extended dictionary,KED)方法,该方法可以学习大量用于人脸识别的字典.Wang L等人[30]采用核坐标下降法(kernel coordinate descent,KCD)求解KSR,该方法可用于视觉跟踪任务.受核方法思想[31]的启发,本文提出的方法首先使用适当的非线性映射将原始输入数据转换到高维特征空间,然后利用L0范数最小化实现SRC模型.因此,本文提出的方法可以有效地获取非线性信息,避免了之前工作[32]在理论上无法有效解决的DCSD问题. ...
One-class classification of remote sensing images using kernel sparse representation
1
2016
... 本文利用 L0范数最小化来建立一种新的 SRC模型,以克服经典 SRC 模型的不足.经典的 SRC模型可能存在另一个问题,即经典的SRC模型不能很好地处理不同类的样本分布在同一向量方向上的数据集[22],即不同类别相同方向(different class same direction,DCSD).为了解决这个问题,Zhang L等人[22]借用了基于核方法的思想,如支持向量机(support vector machine,SVM)[23].他们选择了一个合适的非线性映射,利用该映射将原始输入数据映射到一个高维数据空间,即特征空间,这个特征空间被称为再现核Hibert空间(reproducing kernel Hibert space,RKHS)[24],然后在该特征空间中执行 SRC.这种方法被称为基于核的稀疏表示分类(kernel based SRC,KSRC)[24,25,26],理论上可以避免上述DCSD问题.此外,它可以很好地获取数据集中的非线性信息,有助于对样本进行正确分类[26].基于核的稀疏表示方法可被应用在许多领域中.例如,Song B等人[27]利用核稀疏表示对遥感图像进行一类分类.Zhou Y等人[28]提出了一种基于核稀疏表示(kernel sparse representation,KSR)的手势识别算法,该算法对人类手势较大的变化具有鲁棒性.Huang K K 等人[29]结合SRC和核判别分析(kernel discriminant analysis,KDA)算法开发了一种核扩展字典(kernel extended dictionary,KED)方法,该方法可以学习大量用于人脸识别的字典.Wang L等人[30]采用核坐标下降法(kernel coordinate descent,KCD)求解KSR,该方法可用于视觉跟踪任务.受核方法思想[31]的启发,本文提出的方法首先使用适当的非线性映射将原始输入数据转换到高维特征空间,然后利用L0范数最小化实现SRC模型.因此,本文提出的方法可以有效地获取非线性信息,避免了之前工作[32]在理论上无法有效解决的DCSD问题. ...
Kernel-based sparse representation for gesture recognition
1
2013
... 本文利用 L0范数最小化来建立一种新的 SRC模型,以克服经典 SRC 模型的不足.经典的 SRC模型可能存在另一个问题,即经典的SRC模型不能很好地处理不同类的样本分布在同一向量方向上的数据集[22],即不同类别相同方向(different class same direction,DCSD).为了解决这个问题,Zhang L等人[22]借用了基于核方法的思想,如支持向量机(support vector machine,SVM)[23].他们选择了一个合适的非线性映射,利用该映射将原始输入数据映射到一个高维数据空间,即特征空间,这个特征空间被称为再现核Hibert空间(reproducing kernel Hibert space,RKHS)[24],然后在该特征空间中执行 SRC.这种方法被称为基于核的稀疏表示分类(kernel based SRC,KSRC)[24,25,26],理论上可以避免上述DCSD问题.此外,它可以很好地获取数据集中的非线性信息,有助于对样本进行正确分类[26].基于核的稀疏表示方法可被应用在许多领域中.例如,Song B等人[27]利用核稀疏表示对遥感图像进行一类分类.Zhou Y等人[28]提出了一种基于核稀疏表示(kernel sparse representation,KSR)的手势识别算法,该算法对人类手势较大的变化具有鲁棒性.Huang K K 等人[29]结合SRC和核判别分析(kernel discriminant analysis,KDA)算法开发了一种核扩展字典(kernel extended dictionary,KED)方法,该方法可以学习大量用于人脸识别的字典.Wang L等人[30]采用核坐标下降法(kernel coordinate descent,KCD)求解KSR,该方法可用于视觉跟踪任务.受核方法思想[31]的启发,本文提出的方法首先使用适当的非线性映射将原始输入数据转换到高维特征空间,然后利用L0范数最小化实现SRC模型.因此,本文提出的方法可以有效地获取非线性信息,避免了之前工作[32]在理论上无法有效解决的DCSD问题. ...
Learning kernel extended dictionary for face recognition
2
2016
... 本文利用 L0范数最小化来建立一种新的 SRC模型,以克服经典 SRC 模型的不足.经典的 SRC模型可能存在另一个问题,即经典的SRC模型不能很好地处理不同类的样本分布在同一向量方向上的数据集[22],即不同类别相同方向(different class same direction,DCSD).为了解决这个问题,Zhang L等人[22]借用了基于核方法的思想,如支持向量机(support vector machine,SVM)[23].他们选择了一个合适的非线性映射,利用该映射将原始输入数据映射到一个高维数据空间,即特征空间,这个特征空间被称为再现核Hibert空间(reproducing kernel Hibert space,RKHS)[24],然后在该特征空间中执行 SRC.这种方法被称为基于核的稀疏表示分类(kernel based SRC,KSRC)[24,25,26],理论上可以避免上述DCSD问题.此外,它可以很好地获取数据集中的非线性信息,有助于对样本进行正确分类[26].基于核的稀疏表示方法可被应用在许多领域中.例如,Song B等人[27]利用核稀疏表示对遥感图像进行一类分类.Zhou Y等人[28]提出了一种基于核稀疏表示(kernel sparse representation,KSR)的手势识别算法,该算法对人类手势较大的变化具有鲁棒性.Huang K K 等人[29]结合SRC和核判别分析(kernel discriminant analysis,KDA)算法开发了一种核扩展字典(kernel extended dictionary,KED)方法,该方法可以学习大量用于人脸识别的字典.Wang L等人[30]采用核坐标下降法(kernel coordinate descent,KCD)求解KSR,该方法可用于视觉跟踪任务.受核方法思想[31]的启发,本文提出的方法首先使用适当的非线性映射将原始输入数据转换到高维特征空间,然后利用L0范数最小化实现SRC模型.因此,本文提出的方法可以有效地获取非线性信息,避免了之前工作[32]在理论上无法有效解决的DCSD问题. ...
... 笔者在4个流行的数据集上进行了实验,以证明提出的方法可以在分类精度方面达到理想的性能.数据集包括CMU-PIE、EYB(Extended YaleB)、AR和MNIST数据集.前3个数据集是人脸图像数据集,第4个数据集是手写数字数据集.在本文的实验部分,笔者比较了一些经典的基于表示的分类方法,如协作表示分类(collaborative representation for classification,CRC)[16]、SRC[1]、KSRC[22]、核坐标下降[30]、扩展SRC(extended SRC,ESRC)[17]、两阶段测试样本稀疏表示(two-phase test sample sparse representation,TPTSR)[39]和通过结构和非凸约束的核群稀疏表示方法(KGSRSN)[45].本文提出的算法可被看作字典学习方法的一种.因此,将提出的方法与一些典型的字典学习方法进行了比较,它们分别是核扩展字典(KED)算法[29]、局部约束和标签嵌入(locality-constrained and label embedding,LCLE)字典学习方法[46]、K奇异值分解(K-singular value decomposition,KSVD)算法[47]和鉴别Fisher嵌入字典学习算法(DFEDL)[48]. ...
Visual tracking via kernel sparse representation with multikernel fusion
2
2014
... 本文利用 L0范数最小化来建立一种新的 SRC模型,以克服经典 SRC 模型的不足.经典的 SRC模型可能存在另一个问题,即经典的SRC模型不能很好地处理不同类的样本分布在同一向量方向上的数据集[22],即不同类别相同方向(different class same direction,DCSD).为了解决这个问题,Zhang L等人[22]借用了基于核方法的思想,如支持向量机(support vector machine,SVM)[23].他们选择了一个合适的非线性映射,利用该映射将原始输入数据映射到一个高维数据空间,即特征空间,这个特征空间被称为再现核Hibert空间(reproducing kernel Hibert space,RKHS)[24],然后在该特征空间中执行 SRC.这种方法被称为基于核的稀疏表示分类(kernel based SRC,KSRC)[24,25,26],理论上可以避免上述DCSD问题.此外,它可以很好地获取数据集中的非线性信息,有助于对样本进行正确分类[26].基于核的稀疏表示方法可被应用在许多领域中.例如,Song B等人[27]利用核稀疏表示对遥感图像进行一类分类.Zhou Y等人[28]提出了一种基于核稀疏表示(kernel sparse representation,KSR)的手势识别算法,该算法对人类手势较大的变化具有鲁棒性.Huang K K 等人[29]结合SRC和核判别分析(kernel discriminant analysis,KDA)算法开发了一种核扩展字典(kernel extended dictionary,KED)方法,该方法可以学习大量用于人脸识别的字典.Wang L等人[30]采用核坐标下降法(kernel coordinate descent,KCD)求解KSR,该方法可用于视觉跟踪任务.受核方法思想[31]的启发,本文提出的方法首先使用适当的非线性映射将原始输入数据转换到高维特征空间,然后利用L0范数最小化实现SRC模型.因此,本文提出的方法可以有效地获取非线性信息,避免了之前工作[32]在理论上无法有效解决的DCSD问题. ...
... 笔者在4个流行的数据集上进行了实验,以证明提出的方法可以在分类精度方面达到理想的性能.数据集包括CMU-PIE、EYB(Extended YaleB)、AR和MNIST数据集.前3个数据集是人脸图像数据集,第4个数据集是手写数字数据集.在本文的实验部分,笔者比较了一些经典的基于表示的分类方法,如协作表示分类(collaborative representation for classification,CRC)[16]、SRC[1]、KSRC[22]、核坐标下降[30]、扩展SRC(extended SRC,ESRC)[17]、两阶段测试样本稀疏表示(two-phase test sample sparse representation,TPTSR)[39]和通过结构和非凸约束的核群稀疏表示方法(KGSRSN)[45].本文提出的算法可被看作字典学习方法的一种.因此,将提出的方法与一些典型的字典学习方法进行了比较,它们分别是核扩展字典(KED)算法[29]、局部约束和标签嵌入(locality-constrained and label embedding,LCLE)字典学习方法[46]、K奇异值分解(K-singular value decomposition,KSVD)算法[47]和鉴别Fisher嵌入字典学习算法(DFEDL)[48]. ...
Learning multiple parameters for kernel collaborative representation classification
1
2020
... 本文利用 L0范数最小化来建立一种新的 SRC模型,以克服经典 SRC 模型的不足.经典的 SRC模型可能存在另一个问题,即经典的SRC模型不能很好地处理不同类的样本分布在同一向量方向上的数据集[22],即不同类别相同方向(different class same direction,DCSD).为了解决这个问题,Zhang L等人[22]借用了基于核方法的思想,如支持向量机(support vector machine,SVM)[23].他们选择了一个合适的非线性映射,利用该映射将原始输入数据映射到一个高维数据空间,即特征空间,这个特征空间被称为再现核Hibert空间(reproducing kernel Hibert space,RKHS)[24],然后在该特征空间中执行 SRC.这种方法被称为基于核的稀疏表示分类(kernel based SRC,KSRC)[24,25,26],理论上可以避免上述DCSD问题.此外,它可以很好地获取数据集中的非线性信息,有助于对样本进行正确分类[26].基于核的稀疏表示方法可被应用在许多领域中.例如,Song B等人[27]利用核稀疏表示对遥感图像进行一类分类.Zhou Y等人[28]提出了一种基于核稀疏表示(kernel sparse representation,KSR)的手势识别算法,该算法对人类手势较大的变化具有鲁棒性.Huang K K 等人[29]结合SRC和核判别分析(kernel discriminant analysis,KDA)算法开发了一种核扩展字典(kernel extended dictionary,KED)方法,该方法可以学习大量用于人脸识别的字典.Wang L等人[30]采用核坐标下降法(kernel coordinate descent,KCD)求解KSR,该方法可用于视觉跟踪任务.受核方法思想[31]的启发,本文提出的方法首先使用适当的非线性映射将原始输入数据转换到高维特征空间,然后利用L0范数最小化实现SRC模型.因此,本文提出的方法可以有效地获取非线性信息,避免了之前工作[32]在理论上无法有效解决的DCSD问题. ...
L0-norm sparse representation based on modified genetic algorithm for face recognition
1
2015
... 本文利用 L0范数最小化来建立一种新的 SRC模型,以克服经典 SRC 模型的不足.经典的 SRC模型可能存在另一个问题,即经典的SRC模型不能很好地处理不同类的样本分布在同一向量方向上的数据集[22],即不同类别相同方向(different class same direction,DCSD).为了解决这个问题,Zhang L等人[22]借用了基于核方法的思想,如支持向量机(support vector machine,SVM)[23].他们选择了一个合适的非线性映射,利用该映射将原始输入数据映射到一个高维数据空间,即特征空间,这个特征空间被称为再现核Hibert空间(reproducing kernel Hibert space,RKHS)[24],然后在该特征空间中执行 SRC.这种方法被称为基于核的稀疏表示分类(kernel based SRC,KSRC)[24,25,26],理论上可以避免上述DCSD问题.此外,它可以很好地获取数据集中的非线性信息,有助于对样本进行正确分类[26].基于核的稀疏表示方法可被应用在许多领域中.例如,Song B等人[27]利用核稀疏表示对遥感图像进行一类分类.Zhou Y等人[28]提出了一种基于核稀疏表示(kernel sparse representation,KSR)的手势识别算法,该算法对人类手势较大的变化具有鲁棒性.Huang K K 等人[29]结合SRC和核判别分析(kernel discriminant analysis,KDA)算法开发了一种核扩展字典(kernel extended dictionary,KED)方法,该方法可以学习大量用于人脸识别的字典.Wang L等人[30]采用核坐标下降法(kernel coordinate descent,KCD)求解KSR,该方法可用于视觉跟踪任务.受核方法思想[31]的启发,本文提出的方法首先使用适当的非线性映射将原始输入数据转换到高维特征空间,然后利用L0范数最小化实现SRC模型.因此,本文提出的方法可以有效地获取非线性信息,避免了之前工作[32]在理论上无法有效解决的DCSD问题. ...
Discriminative fisher embedding dictionary learning algorithm for object recognition
... 笔者在4个流行的数据集上进行了实验,以证明提出的方法可以在分类精度方面达到理想的性能.数据集包括CMU-PIE、EYB(Extended YaleB)、AR和MNIST数据集.前3个数据集是人脸图像数据集,第4个数据集是手写数字数据集.在本文的实验部分,笔者比较了一些经典的基于表示的分类方法,如协作表示分类(collaborative representation for classification,CRC)[16]、SRC[1]、KSRC[22]、核坐标下降[30]、扩展SRC(extended SRC,ESRC)[17]、两阶段测试样本稀疏表示(two-phase test sample sparse representation,TPTSR)[39]和通过结构和非凸约束的核群稀疏表示方法(KGSRSN)[45].本文提出的算法可被看作字典学习方法的一种.因此,将提出的方法与一些典型的字典学习方法进行了比较,它们分别是核扩展字典(KED)算法[29]、局部约束和标签嵌入(locality-constrained and label embedding,LCLE)字典学习方法[46]、K奇异值分解(K-singular value decomposition,KSVD)算法[47]和鉴别Fisher嵌入字典学习算法(DFEDL)[48]. ...
Projective double reconstructions based dictionary learning algorithm for cross-domain recognition
... 在确定了测试样本的 K 个近邻后,需要使用SGA确定整个表示字典.在SGA中,表示字典的第一部分是固定的.SGA将表示误差最小的样本作为表示字典的第二部分.在描述 SGA 过程之前,先给出一些关于遗传算法的基本概念(详情请见参考文献[44]).第一个概念是个体或状态,通常表示为0和1的串.个体的每个元素都与一个训练样本相关联.许多个体生成种群,这是遗传算法术语中的第二个基本概念.每个个体通常通过适应度函数进行评估. ...
Kernel group sparse representation classifier via structural and non-convex constraints
1
2018
... 笔者在4个流行的数据集上进行了实验,以证明提出的方法可以在分类精度方面达到理想的性能.数据集包括CMU-PIE、EYB(Extended YaleB)、AR和MNIST数据集.前3个数据集是人脸图像数据集,第4个数据集是手写数字数据集.在本文的实验部分,笔者比较了一些经典的基于表示的分类方法,如协作表示分类(collaborative representation for classification,CRC)[16]、SRC[1]、KSRC[22]、核坐标下降[30]、扩展SRC(extended SRC,ESRC)[17]、两阶段测试样本稀疏表示(two-phase test sample sparse representation,TPTSR)[39]和通过结构和非凸约束的核群稀疏表示方法(KGSRSN)[45].本文提出的算法可被看作字典学习方法的一种.因此,将提出的方法与一些典型的字典学习方法进行了比较,它们分别是核扩展字典(KED)算法[29]、局部约束和标签嵌入(locality-constrained and label embedding,LCLE)字典学习方法[46]、K奇异值分解(K-singular value decomposition,KSVD)算法[47]和鉴别Fisher嵌入字典学习算法(DFEDL)[48]. ...
A locality-constrained and label embedding dictionary learning algorithm for image classification
1
2015
... 笔者在4个流行的数据集上进行了实验,以证明提出的方法可以在分类精度方面达到理想的性能.数据集包括CMU-PIE、EYB(Extended YaleB)、AR和MNIST数据集.前3个数据集是人脸图像数据集,第4个数据集是手写数字数据集.在本文的实验部分,笔者比较了一些经典的基于表示的分类方法,如协作表示分类(collaborative representation for classification,CRC)[16]、SRC[1]、KSRC[22]、核坐标下降[30]、扩展SRC(extended SRC,ESRC)[17]、两阶段测试样本稀疏表示(two-phase test sample sparse representation,TPTSR)[39]和通过结构和非凸约束的核群稀疏表示方法(KGSRSN)[45].本文提出的算法可被看作字典学习方法的一种.因此,将提出的方法与一些典型的字典学习方法进行了比较,它们分别是核扩展字典(KED)算法[29]、局部约束和标签嵌入(locality-constrained and label embedding,LCLE)字典学习方法[46]、K奇异值分解(K-singular value decomposition,KSVD)算法[47]和鉴别Fisher嵌入字典学习算法(DFEDL)[48]. ...
A survey of dictionary learning algorithms for face recognition
1
2017
... 笔者在4个流行的数据集上进行了实验,以证明提出的方法可以在分类精度方面达到理想的性能.数据集包括CMU-PIE、EYB(Extended YaleB)、AR和MNIST数据集.前3个数据集是人脸图像数据集,第4个数据集是手写数字数据集.在本文的实验部分,笔者比较了一些经典的基于表示的分类方法,如协作表示分类(collaborative representation for classification,CRC)[16]、SRC[1]、KSRC[22]、核坐标下降[30]、扩展SRC(extended SRC,ESRC)[17]、两阶段测试样本稀疏表示(two-phase test sample sparse representation,TPTSR)[39]和通过结构和非凸约束的核群稀疏表示方法(KGSRSN)[45].本文提出的算法可被看作字典学习方法的一种.因此,将提出的方法与一些典型的字典学习方法进行了比较,它们分别是核扩展字典(KED)算法[29]、局部约束和标签嵌入(locality-constrained and label embedding,LCLE)字典学习方法[46]、K奇异值分解(K-singular value decomposition,KSVD)算法[47]和鉴别Fisher嵌入字典学习算法(DFEDL)[48]. ...
Discriminative Fisher embedding dictionary learning algorithm for object recognition
1
2020
... 笔者在4个流行的数据集上进行了实验,以证明提出的方法可以在分类精度方面达到理想的性能.数据集包括CMU-PIE、EYB(Extended YaleB)、AR和MNIST数据集.前3个数据集是人脸图像数据集,第4个数据集是手写数字数据集.在本文的实验部分,笔者比较了一些经典的基于表示的分类方法,如协作表示分类(collaborative representation for classification,CRC)[16]、SRC[1]、KSRC[22]、核坐标下降[30]、扩展SRC(extended SRC,ESRC)[17]、两阶段测试样本稀疏表示(two-phase test sample sparse representation,TPTSR)[39]和通过结构和非凸约束的核群稀疏表示方法(KGSRSN)[45].本文提出的算法可被看作字典学习方法的一种.因此,将提出的方法与一些典型的字典学习方法进行了比较,它们分别是核扩展字典(KED)算法[29]、局部约束和标签嵌入(locality-constrained and label embedding,LCLE)字典学习方法[46]、K奇异值分解(K-singular value decomposition,KSVD)算法[47]和鉴别Fisher嵌入字典学习算法(DFEDL)[48]. ...
Principal angles separate subject illumination spaces in YDB and CMU-PIE














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}