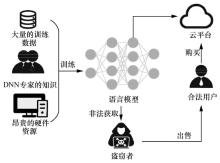
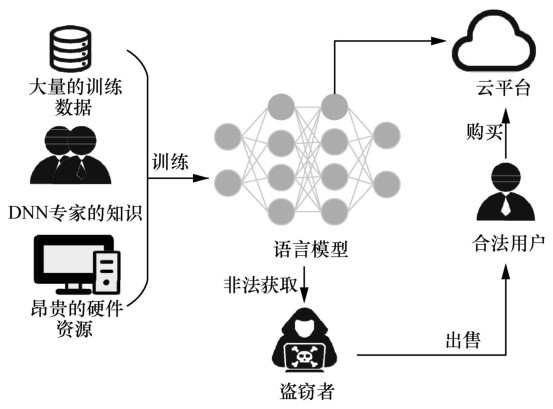
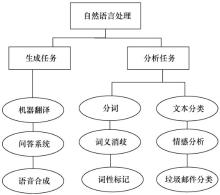
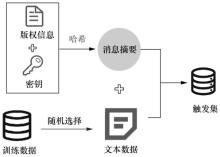
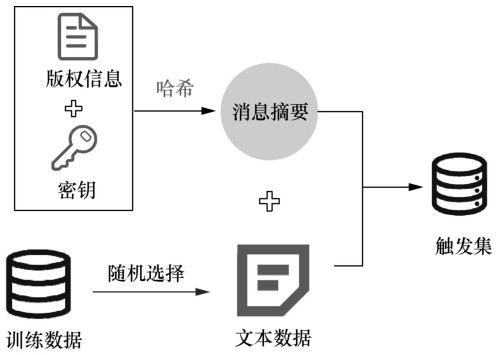
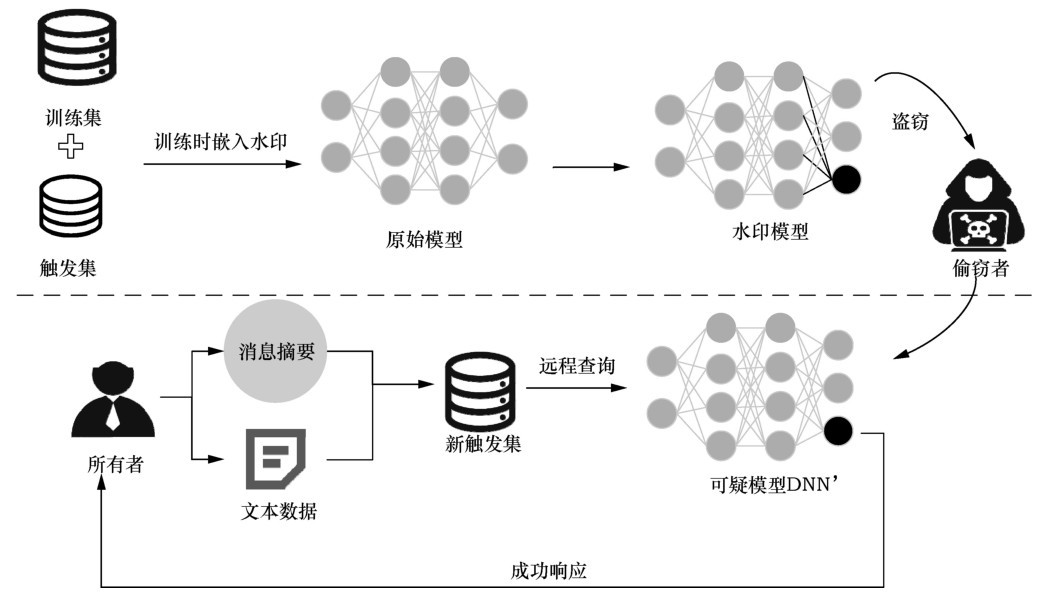
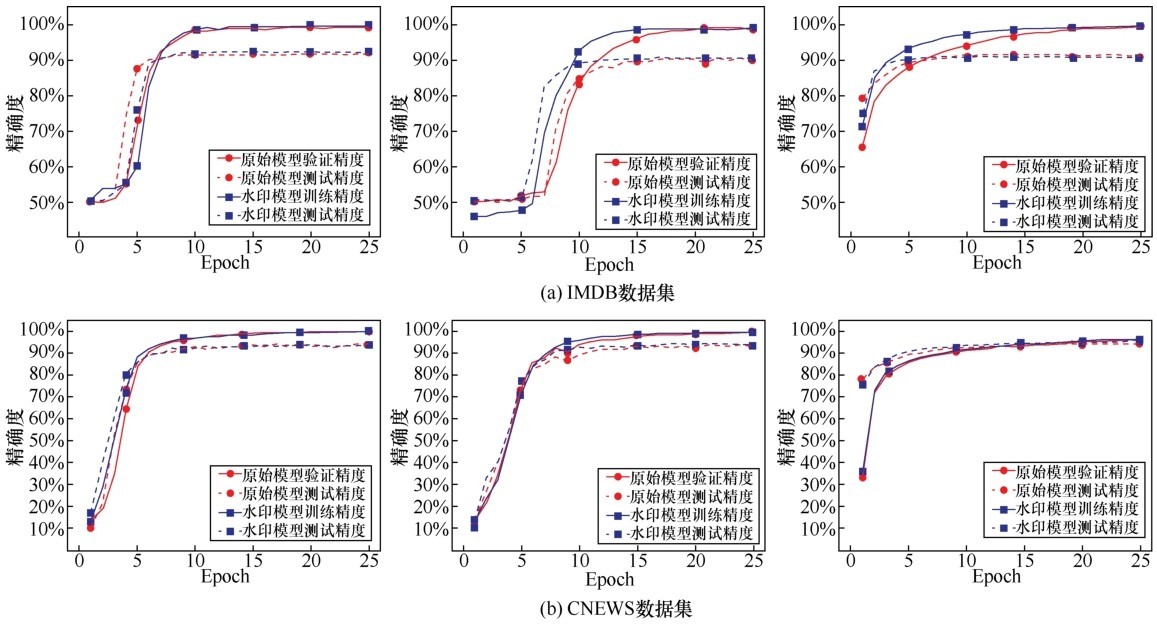
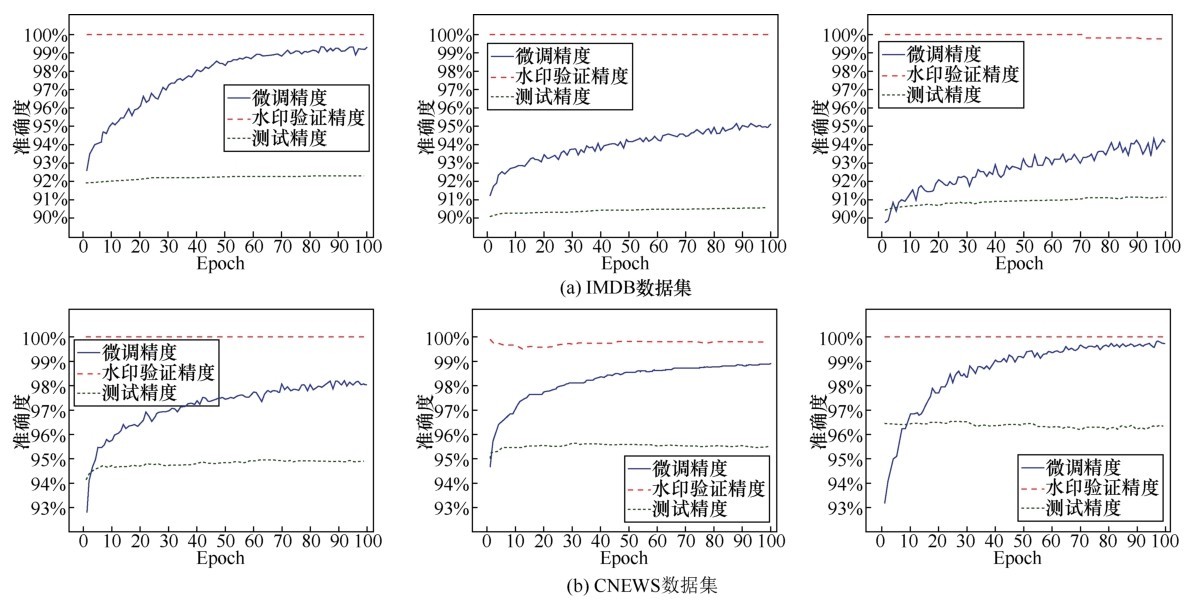
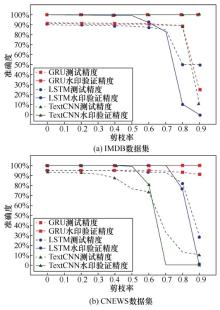
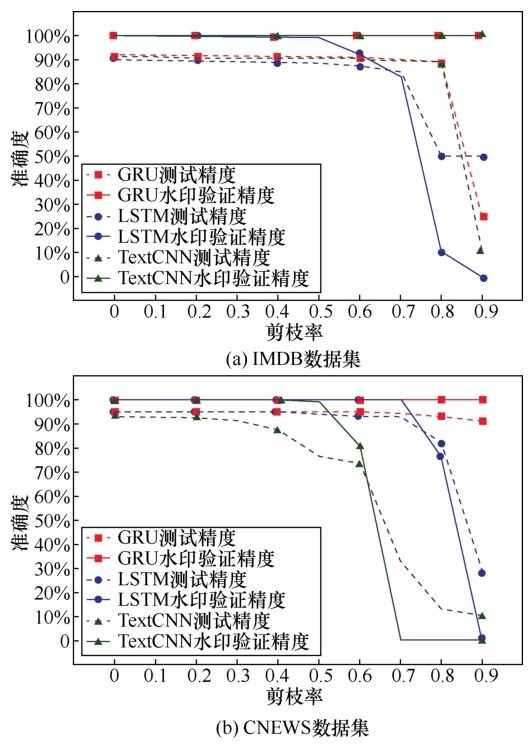
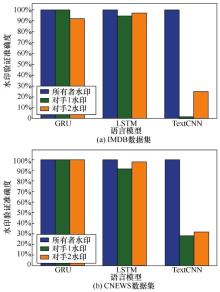
| [1] |
MOHANARATHINAM A , KAMALRAJ S , PRASANNA-VENKATESAN G K D , ,et al. Digital watermarking techniques for image security:A review[J]. Journal of Ambient Intelligence and Humanized Computing, 2020,11(8): 3221-3229.
|
| [2] |
QASIM A F , MEZIANE F , ASPIN R . Digital watermarking:applicability for developing trust in medical imaging workflows state of the art review[J]. Computer Science Review, 2018,27: 45-60.
|
| [3] |
樊雪峰, 周晓谊, 朱冰冰 ,等. 深度神经网络模型版权保护方案综述[J]. 计算机研究与发展, 2022,59(5): 953-977.
|
|
FAN X F , ZHOU X Y , ZHU B B ,et al. Survey of copyright protection schemes based on DNN model[J]. Journal of Computer Research and Development, 2022,59(5): 953-977.
|
| [4] |
UCHIDA Y , NAGAI Y , SAKAZAWA S ,et al. Embedding watermarks into deep neural networks[C]// Proceedings of the 2017 ACM on International Conference on Multimedia Retrieval. 2017: 269-277.
|
| [5] |
ADI Y , BAUM C , CISSE M ,et al. Turning your weakness into a strength:Watermarking deep neural networks by backdooring[C]// 27th USENIX Security Symposium (USENIX Security 18). 2018: 1615-1631.
|
| [6] |
ZHANG J , GU Z , JANG J ,et al. Protecting intellectual property of deep neural networks with watermarking[C]// Proceedings of the 2018 on Asia Conference on Computer and Communications Security. 2018:159172.
|
| [7] |
LI M , ZHONG Q , ZHANG L Y ,et al. Protecting the intellectual property of deep neural networks with watermarking:The frequency domain approach[C]// 2020 IEEE 19th International Conference on Trust,Security and Privacy in Computing and Communications (TrustCom). 2020: 402-409.
|
| [8] |
ZHONG Q , ZHANG L Y , ZHANG J ,et al. Protecting IP of deep neural networks with watermarking:A new label helps[C]// PacificAsia Conference on Knowledge Discovery and Data Mining. 2020:462474.
|
| [9] |
ABDELNABI S , FRITZ M . Adversarial watermarking transformer:Towards tracing text provenance with data hiding[C]// 2021 IEEE Symposium on Security and Privacy (SP). 2021: 121-140.
|
| [10] |
YADOLLAHI M M , SHOELEH F , DADKHAH S ,et al. Robust black-box watermarking for deep neural network using inverse document frequency[EB].
|
| [11] |
CAMBRIA E , WHITE B . Jumping NLP curves:a review of natural language processing research[J]. IEEE Computational Intelligence Magazine, 2014,9(2): 48-57.
|
| [12] |
ALSHEMALI B , KALITA J . Improving the reliability of deep neural networks in NLP:A review[J]. Knowledge-Based Systems, 2020,191:105210.
|
| [13] |
DOS SANTOS C , ZADROZNY B . Learning character level representations for part of speech tagging[C]// International Conference on Machine Learning. 2014: 1818-1826.
|
| [14] |
XU D , TIAN Z , LAI R ,et al. Deep learning based emotion analysis of microblog texts[J]. Information Fusion, 2020,64: 1-11.
|
| [15] |
DHAR A , MUKHERJEE H , DASH N S ,et al. Text categorization:past and present[J]. Artificial Intelligence Review, 2021,54(4): 3007-3054.
|
| [16] |
DWIVEDI S K , SINGH V . Research and reviews in question answering system[J]. Procedia Technology, 2013,10: 417-424.
|
| [17] |
HUANG H , XU H , WANG X ,et al. Maximum F1-score discriminative training criterion for automatic mispronunciation detection[J]. IEEE/ACM Transactions on Audio,Speech,and Language Processing, 2015,23(4): 787-797.
|
| [18] |
YAO Y , LI H , ZHENG H ,et al. Latent backdoor attacks on deep neural networks[C]// Proceedings of the 2019 ACM SIGSAC Conference on Computer and Communications Security. 2019: 2041-2055.
|
| [19] |
SUN C , QIU X , XU Y ,et al. How to fine-tune bert for text classifycation[C]// China National Conference on Chinese Computational linguistics. 2019: 194-206.
|
| [20] |
OLCHANOV P , MALLYA A , TYREE S ,et al. Importance estimation for neural network pruning[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2019: 11264-11272.
|