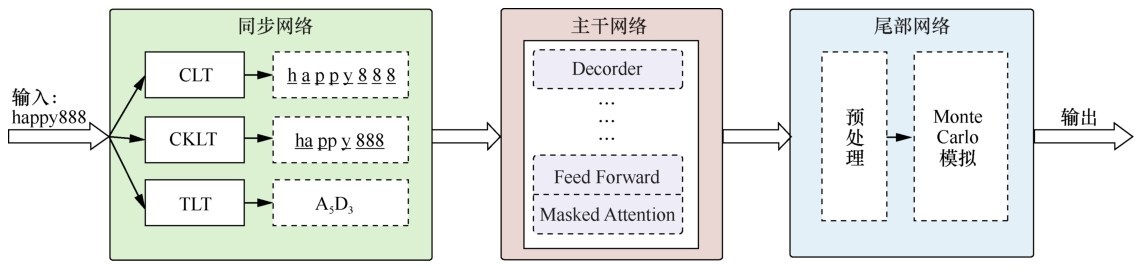
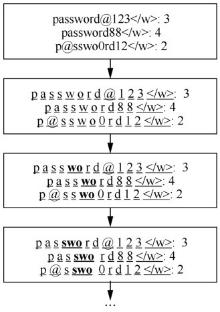
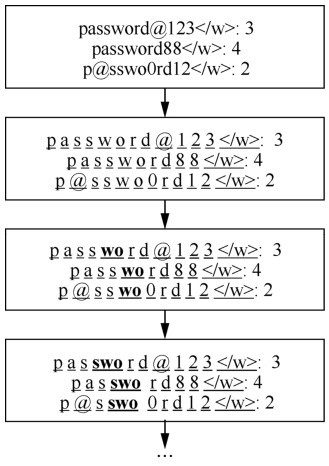
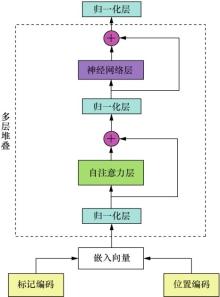
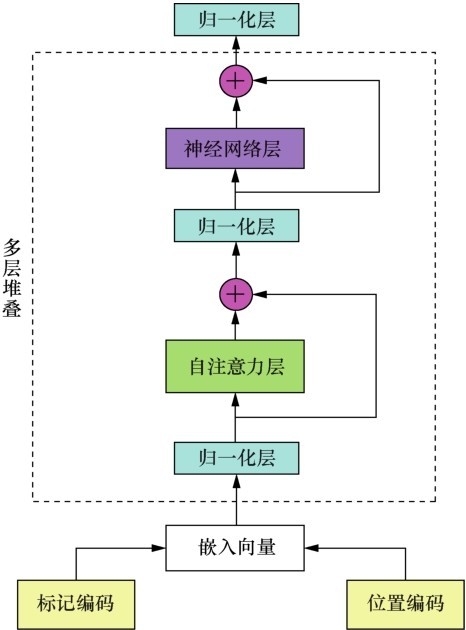
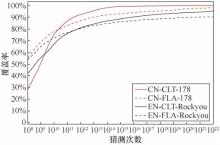
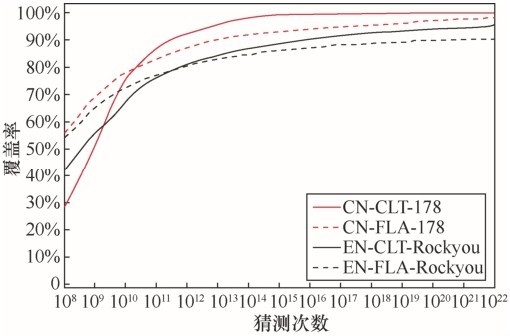
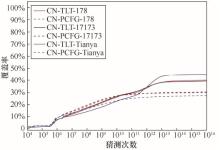
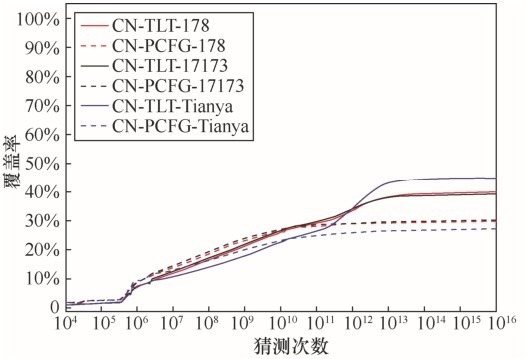
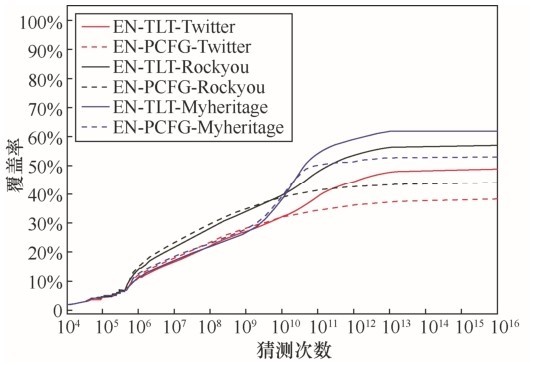
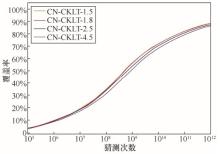
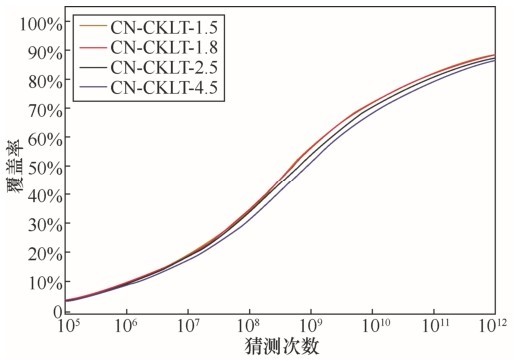
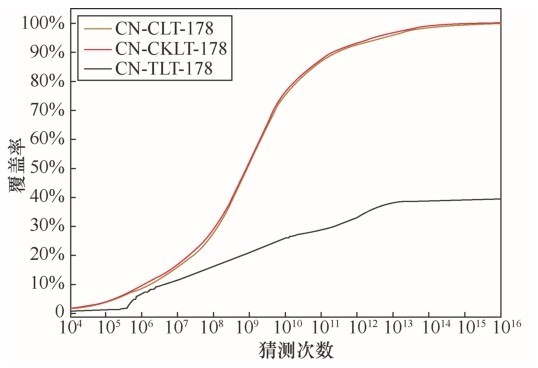
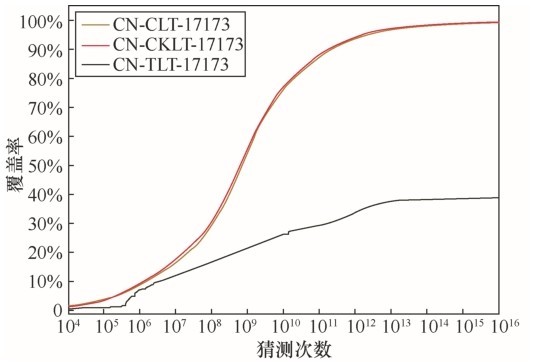
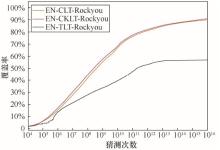
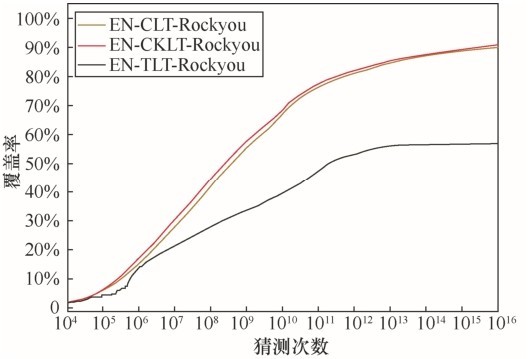
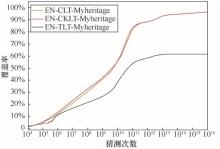
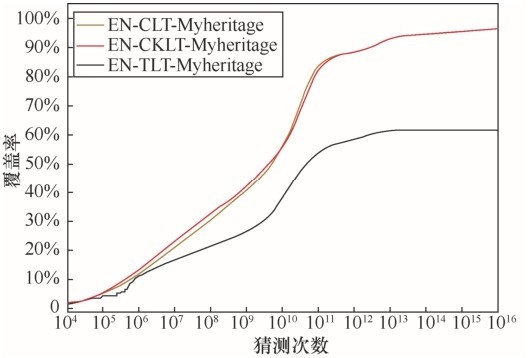
| [1] |
BONNEAU J , HERLEY C , OORSCHOT P C V ,et al. The quest to replace passwords:a framework for comparative evaluation of web authentication schemes[C]// Proceedings of 2012 IEEE Symposium on Security and Privacy. 2012: 553-567.
|
| [2] |
BONNEAU J , HERLEY C , VAN OORSCHOT P C ,et al. Passwords and the evolution of imperfect authentication[J]. Communications of the ACM, 2015,58(7): 78-87.
|
| [3] |
YAN J , BLACKWELL A , ANDERSON R ,et al. Password memorability and security:empirical results[J]. IEEE Security & Privacy, 2004,2(5): 25-31.
|
| [4] |
DELL'AMICO M , MICHIARDI P , ROUDIER Y . Measuring password strength:an empirical analysis[J]. arXiv preprint arXiv:0907.3402, 2009.
|
| [5] |
MA J , YANG W N , LUO M ,et al. A study of probabilistic password models[C]// Proceedings of 2014 IEEE Symposium on Security and Privacy. 2014: 689-704.
|
| [6] |
DüRMUTH M , ANGELSTORF F , CASTELLUCCIA C ,et al. OMEN:faster password guessing using an ordered Markov enumerator[C]// Proceedings of International Symposium on Engineering Secure Software and Systems. 2015: 119-132.
|
| [7] |
MELICHER W , UR B , SEGRETI S M ,et al. Fast,lean,and accurate:modeling password guess ability using neural networks[C]// Proceedings of the 25th USENIX Conference on Security Symposium. 2016: 175-191.
|
| [8] |
WEIR M , AGGARWAL S , MEDEIROS B D ,et al. Password cracking using probabilistic context-free grammars[C]// Proceedings of 2009 30th IEEE Symposium on Security and Privacy. 2009: 391-405.
|
| [9] |
PASQUINI D , GANGWAL A , ATENIESE G ,et al. Improving password guessing via representation learning[C]// Proceedings of 2021 IEEE Symposium on Security and Privacy (SP). 2021: 1382-1399.
|
| [10] |
NARAYANAN A , SHMATIKOV V . Fast dictionary attacks on passwords using time-space tradeoff[C]// Proceedings of the 12th ACM Conference on Computer and Communications Security. 2005: 364-372.
|
| [11] |
CASTELLUCCIA C , DüRMUTH M , PERITO D . Adaptive password-strength meters from Markov models[C]// Proceedings of NDSS. 2012.
|
| [12] |
CHOU H C , LEE H C , YU H J ,et al. Password cracking based on learned patterns from disclosed passwords[J]. IJICIC, 2013,9(2): 821-839.
|
| [13] |
SHAY R , KOMANDURI S , KELLEY P G ,et al. Encountering stronger password requirements:user attitudes and behaviors[C]// Proceedings of the Sixth Symposium on Usable Privacy and Security. 2010: 1-20.
|
| [14] |
VERAS R , COLLINS C , THORPE J . On semantic patterns of passwords and their security impact[C]// Proceedings of NDSS. 2014.
|
| [15] |
XU M , YU J , ZHANG X ,et al. Improving real-world password guessing attacks via bi-directional transformers[C]// Proceedings of 32nd USENIX Security Symposium (USENIX Security 23). 2023: 1001-1018.
|
| [16] |
ZHAO W X , ZHOU K , LI J ,et al. A survey of large language models[J]. arXiv preprint arXiv:2303.18223, 2023.
|
| [17] |
SHANAHAN M . Talking about large language models[J]. arXiv preprint arXiv:2212.03551, 2022.
|
| [18] |
QIU X P , SUN T X , XU Y G ,et al. Pre-trained models for natural language processing:a survey[J]. Science China Technological Sciences, 2020,63(10): 1872-1897.
|
| [19] |
HAN X , ZHANG Z Y , DING N ,et al. Pre-trained models:past,present and future[J]. AI Open, 2021,2: 225-250.
|
| [20] |
RADFORD A , WU J , CHILD R ,et al. Language models are unsupervised multitask learners[J]. OpenAI Blog, 2019,1(8): 9.
|
| [21] |
RANDO J , PéREZ-CRUZ F , HITAJ B . PassGPT:password modeling and (guided) generation with large language models[J]. arXiv preprint arXiv:2306.01545, 2023.
|
| [22] |
XU M , WANG C W , YU J T ,et al. Chunk-level password guessing:towards modeling refined password composition representations[C]// Proceedings of the 2021 ACM SIGSAC Conference on Computer and Communications Security. 2021: 5-20.
|
| [23] |
LI H , CHEN M Q , YAN S B ,et al. Password guessing via neural language modeling[M]// Machine Learning for Cyber Security. 2019: 78-93.
|
| [24] |
DELL'AMICO M , FILIPPONE M . Monte Carlo strength evaluation:fast and reliable password checking[C]// Proceedings of the 22nd ACM SIGSAC Conference on Computer and Communications Security. 2015: 158-169.
|
| [25] |
GAGE P . A new algorithm for data compression[J]. C Users Journal, 1994,12(2): 23-38.
|
| [26] |
DEVLIN J , CHANG M W , LEE K ,et al. Bert:pre-training of deep bidirectional transformers for language understanding[J]. arXiv preprint arXiv:1810.04805, 2018.
|
| [27] |
YANG Z , DAI Z , YANG Y ,et al. XLNet:generalized autoregressive pretraining for language understanding[J]. Advances in Neural Information Processing Systems, 2019,32.
|
| [28] |
HITAJ B , GASTI P , ATENIESE G ,et al. PassGAN:A deep learning approach for password guessing[M]// Applied Cryptography and Network Security. Cham: Springer International Publishing, 2019: 217-237.
|