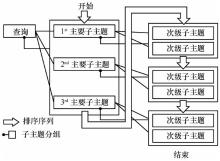
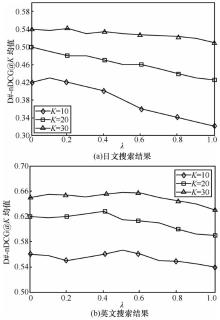
| [1] |
唐晓波, 肖璐 . 基于单句粒度的微博主题挖掘研究[J]. 情报学报 2014,33(6):214-219. TANG X B , XIAO L . Research of micro-blog topics mining based on sentence granularity[J]. Journal of the China Society for Scientific and Technical Information, 2014 33(6):214-219.
|
| [2] |
田宇辰 . 专业搜索引擎的无日志查询推荐机制研究及实现[D]. 广州: 华南理工大学 2014. TIAN Y C . Research and implementation of non log query recommendation mechanism for professional search engine[D]. Guangzhou: South China University of Technology, 2014.
|
| [3] |
李胜浩 . 基于MapReduce的Web文本挖掘系统的研究与实现[D]. 北京: 北京邮电大学 2013. LI S H . Research and implementation of Web text mining system based on MapReduce[D]. Beijing: Beijing University of Posts and Telecommunications, 2013.
|
| [4] |
BHATIA S , MAJUMDAR D , MITRA P . Query suggestions in the absence of query logs[C]// International ACM SIGIR Conference on Research & Development in Information Retrieval, July 24-28, 2011, Beijing,China. NewYork: IEEE Press, 2011: 795-804.
|
| [5] |
HE J , HOLLINK V , DE VRIES A . Combining implicit and explicit topic representations for result diversification[C]// The 35th international ACM SIGIR conference on Research and development in information retrieval, August 12-16, 2012, Poreland,OR,USA. New York: ACM Press, 2012: 851-860.
|
| [6] |
肖璐, 唐晓波 . 基于句子成分的微博热点主题挖掘模型研究[J]. 情报科学 2015,35(11):137-141. XIAO L , TANG X B . Research on micro-blog hot topic mining model based on sentence composition[J]. Journal of the China Society for Scientific and Technical Information, 2015 35(11):137-141.
|
| [7] |
ZHU X , GUO J , CHENG X , et al. A unified framework for recommending diverse and relevant queries[C]// World Wide Web Conference Series, March 28-April1, 2011, Hyderabad,India. New York: ACM Press, 2011: 37-46.
|
| [8] |
KIM S J , SHIN K Y , LEE J H , et al. Hierarchical subtopic mining for topic annotation[C]// The 6th international workshop on exploiting semantic annotations in information retrieval, October 28, 2013, San Francisco,CA,USA. New York: ACM Press, 2013: 49-52.
|
| [9] |
刘少鹏, 印鉴, 欧阳佳 等. 基于MB-HDP模型的微博主题挖掘[J]. 计算机学报 2015,42(7):1408-1419. LIU S P , YIN J , OU-YANG J et al. Topic mining from microblogs based on MB-HDP model[J]. JChinese Journal of Computers, 2015 42(7):1408-1419.
|
| [10] |
岑荣伟, 刘奕群, 张敏 等. 基于日志挖掘的搜索引擎用户行为分析[J]. 中文信息学报 2010,24(3):49-54. CEN R W , LIU Y Q , ZHANG M et al. User behavior analysis of search engine based on log mining[J]. Journal of Chinese Information Processing, 2010 24(3):49-54.
|
| [11] |
谭彩丽, 弥寅 . 基于主题相关博客的属性挖掘模型设计[D]. 北京: 北京邮电大学 2011. TAN C L . Design of attribute mining model based on topic related blog[D]. Beijing: Beijing University of Posts and Telecommunications, 2011.
|
| [12] |
DANG V , CROFT B W . Term level search result diversification[C]// International ACM SIGIR Conference on Research &Development in Information Retrieval, July 28-August 1, 2013, Dublin,Ireland. New York: ACM Press, 2013: 603-612.
|
| [13] |
曾依灵, 许洪波, 白硕 . 网络文本主题词的提取与组织研究[J]. 中文信息学报 2008,22(3):64-70. ZENG Y L , XU H B , BAI S . Research on the extraction and organization of Web text topic words[J]. Journal of Chinese Information Processing, 2008 22(3):64-70.
|
| [14] |
刘德喜, 万常选, 刘喜平 等. 基于结点权重模型的XML片段检索策略[J]. 计算机学报 2013,36(8):1729-1744. LIU D X , WAN C X , LIU X P et al. XML fragment retrieval strategy based on node weight model[J]. Chinese Journal of Computers, 2013 36(8):1729-1744.
|
| [15] |
刘志勇, 耿新青 . 基于模糊聚类的文本挖掘算法[J]. 计算机工程 2009,35(5):44-45. LIU Z Y , GENG X Q . Text mining algorithm based on fuzzy clustering[J]. Computer Engineering, 2009 35(5):44-45.
|