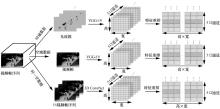
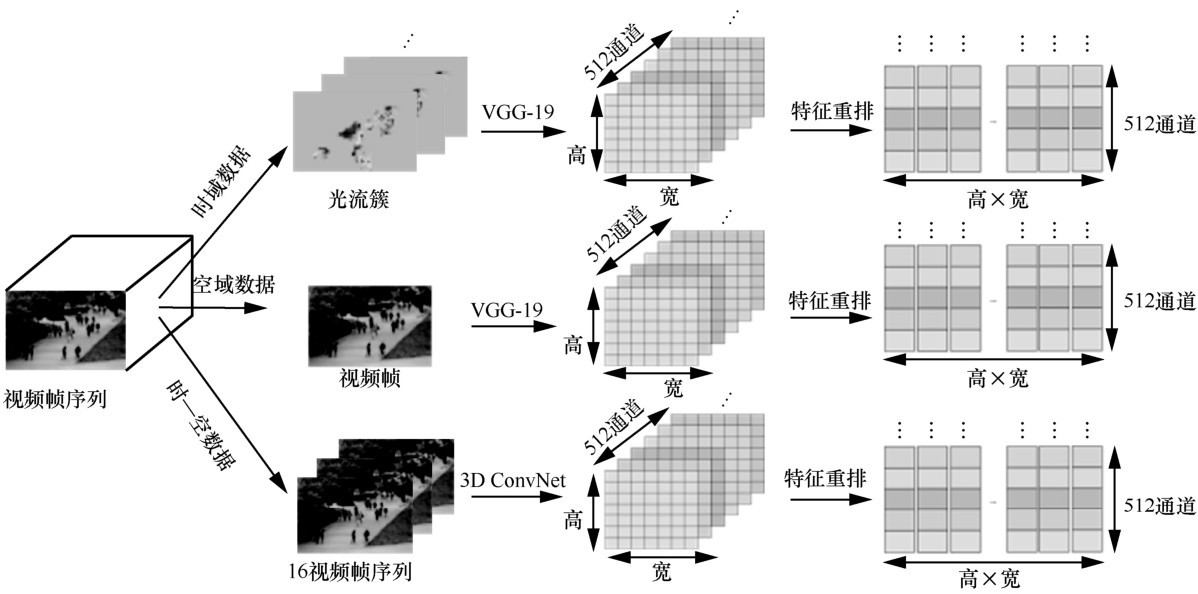
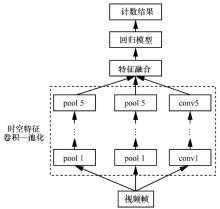
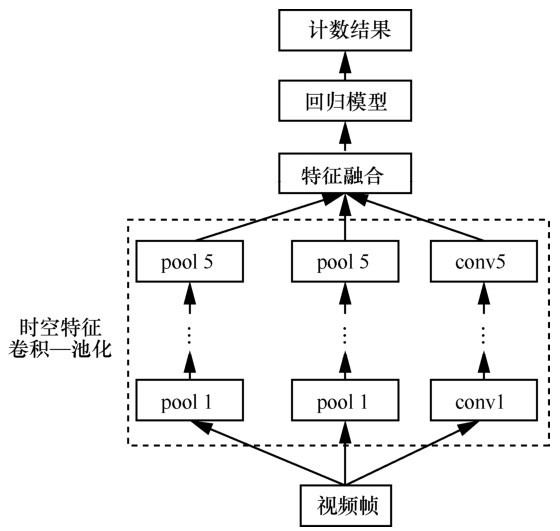
| [5] |
SIMONYAN K , ZISSERMAN A . Very deep convolutional networks for large-scale image recognition[J]. Computer Science, 2014(9).
|
| [6] |
TRAN D , BOURDEV L , FERGUS R ,et al. Learning spatiotemporal features with 3D convolutional networks[C]// The 2015 IEEE International Conference on Computer Vision (ICCV’15),Dec 7-13,2015,Santiago,Chile. Piscataway:IEEE Press, 2015: 4489-4497.
|
| [7] |
J’EGOU H , DOUZE M , SCHMID C ,et al. Aggregating local descriptors into a compact image representation[C]// The 2010 IEEE Conference on Computer Vision and Pattern Recognition (CVPR’10),June 13-18,2010,San Francisco,CA,USA. Piscataway:IEEE Press, 2010: 3304-3311.
|
| [8] |
VIOLA P , JONES M J . Robust real-time face detection[J]. International Journal of Computer Vision, 2004,57(2): 137-154.
|
| [9] |
WU B , NEVATIA R . Detection of multiple,partially occluded humans in a single image by bayesian combination of edgelet part detectors[C]// The 2005 IEEE International Conference on Computer Vision (ICCV’05),Oct 17-21,2005,Beijing,China. Piscataway:IEEE Press, 2005: 90-97.
|
| [10] |
SABZMEYDANI P , MORI G . Detecting pedestrians by learning shapelet features[C]// The 2007 IEEE Conference on Computer Vision and Pattern Recognition (CVPR’07),June 18-23,2007,Minneapolis,Minnesota,USA. Piscataway:IEEE Press, 2007: 1-8.
|
| [11] |
GALL J , YAO A , RAZAVI N ,et al. Hough forests for object detection,tracking,and action recognition[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2011,33(11): 2188-2202.
|
| [12] |
HUANG D , SHAN C , ARDABILIAN M ,et al. Local binary patterns and its application to facial image analysis:a survey[J]. IEEE Transactions on Systems Man & Cybernetics Part C Applications & Reviews, 2011,41(6): 765-781.
|
| [13] |
SULOCHANA S , VIDHYA R . Texture based image retrieval using framelet transform–gray level co-occurrence matrix(GLCM)[J]. International Journal of Advanced Research in Artificial Intelligence, 2013,2(2).
|
| [14] |
HINTON G E , SALAKHUTDINOV R . Reducing the dimensionality of data with neural networks[J]. Science, 2006,313(5786): 504-507.
|
| [15] |
ZHANG C , LI H , WANG X ,et al. Cross-scene crowd counting via deep convolutional neural networks[C]// The 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR’15),June 8-10,2015,Boston,Massachusetts,USA. Piscataway:IEEE Press, 2015: 833-841.
|
| [16] |
CHAN A , LIANG Z , Vasconcelos N . Privacy preserving crowd monitoring:counting people without people models or tracking[C]// The 2008 IEEE Conference on Computer Vision and Pattern Recognition (CVPR’08),June 24-26,2008,Anchorage,Alaska,USA. Piscataway:IEEE Press, 2008: 1-7.
|
| [17] |
时增林, 叶阳东, 吴云鹏 ,等. 基于序的空间金字塔池化网络的人群计数方法[J]. 自动化学报, 2016,42(6): 866-874.
|
|
SHI Z L , YE Y D , WU Y P ,et al. Crowd counting using rank-based spatial pyramid pooling network[J]. Acta Automatica Sinica, 2016,42(6): 866-874.
|
| [18] |
BOOMINATHAN L , KRUTHIVENTI S , BABU R . Crowdnet:a deep convolutional network for dense crowd counting[C]// The 2016 ACM Conference on Multimedia Conference (MM’16),Oct 15-19,2016,Amsterdam,The Netherlands. New York:ACM Press, 2016: 640-644.
|
| [19] |
ZACH C , POCK T , BISCHOF H . A duality based approach for realtime TV-L1 optical flow[M]. Berlin: SpringerPress, 2007: 214-223.
|
| [20] |
BAY H , ESS A , TUYTELAARS T ,et al. Speeded-up robust features (SURF)[J]. Computer Vision and Image Understanding, 2008,110(3): 346-359
|
| [21] |
FISCHLER M A , BOLLES R C . Random sample consensus:a paradigm for model fitting with applications to image analysis and automated cartography[J]. Communications of the ACM, 1981,24(6): 381-395.
|
| [1] |
LOY C C , CHEN K , GONG S G ,et al. Crowd counting and profiling:methodology and evaluation[M]. New York: SpringerPress, 2013: 347-382.
|
| [2] |
IDREES H , SALEEMI I , SEIBERT C ,et al. Multi-source multi-scale counting in extremely dense crowd images[C]// The 2013 IEEE Conference on Computer Vision and Pattern Recognition (CVPR’13),June 23-28,2013,Portland,OR,USA. Piscataway:IEEE Press, 2013: 2547-2554.
|
| [3] |
ROSTEN E , PORTER R , DRUMMOND T . Faster and better:a machine learning approach to corner detection[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2010,32(1): 105-119.
|
| [4] |
DALAL N , TRIGGS B . Histograms of oriented gradients for human detection[C]// The 2005 IEEE Conference on Computer Vision and Pattern Recognition (CVPR’05),June 20-25,2005,New York,NY,USA. Piscataway:IEEE Press, 2005: 886-893.
|
| [22] |
ZHANG Z X , WANG M , GENG X . Crowd counting in public video surveillance by label distribution learning[J]. Neurocomputing, 2015(166): 151-163.
|