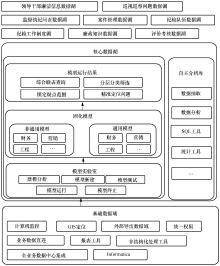
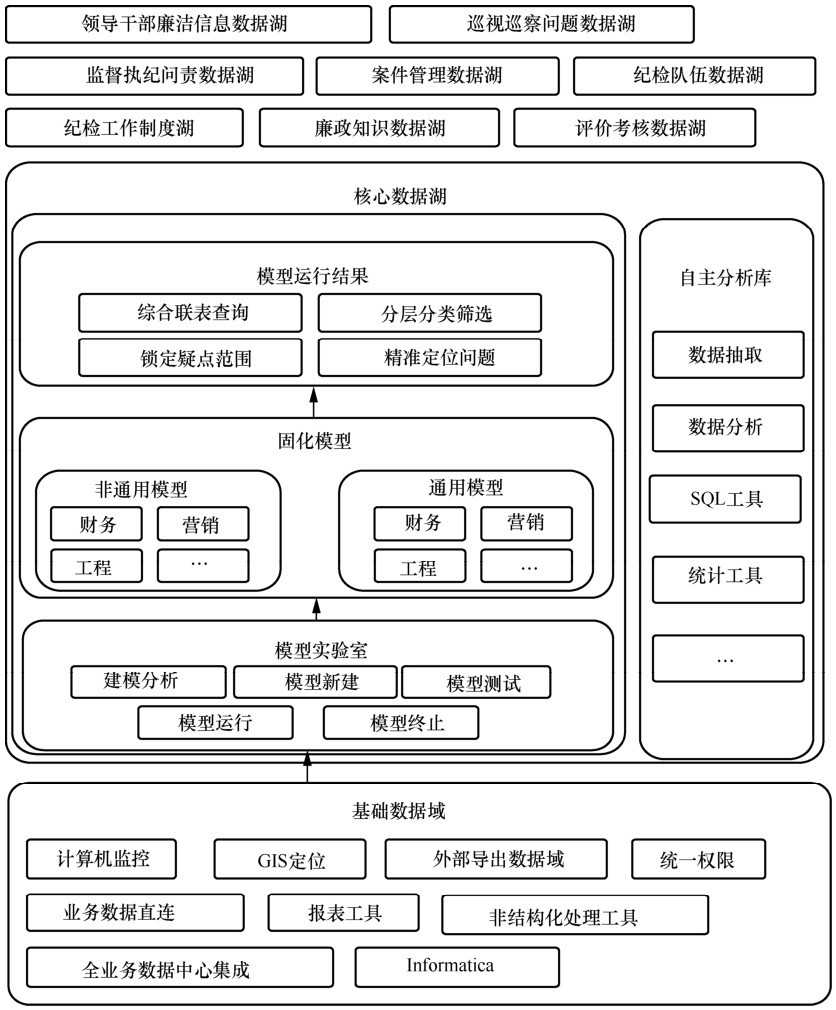
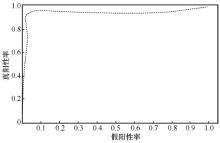
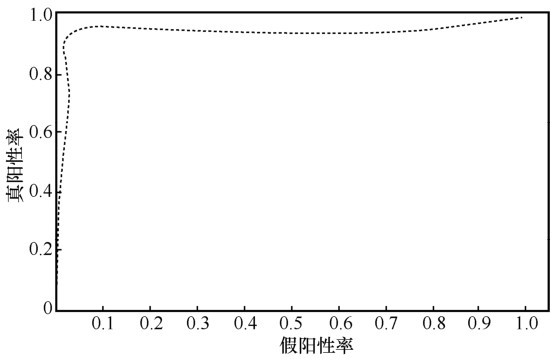
| [1] |
高伟, 薛梦瑶, 于成成 . 面向大数据的情报分析方法和技术体系研究[J]. 情报理论与实践, 2019,42(12): 43-48,35.
|
|
GAO W , XUE M Y , YU C C . Big data-oriented system of intelligence analysis methods and technologies[J]. Information Studies (Theory & Application), 2019,42(12): 43-48,35.
|
| [2] |
张淑清 . 基于哈希计算的大数据冗余消除算法设计[J]. 微型电脑应用, 2021,37(12): 68-70.
|
|
ZHANG S Q . Design of big data redundancy elimination algorithm based on hash function[J]. Microcomputer Applications, 2021,37(12): 68-70.
|
| [3] |
李越颖 . 基于邻域搜索的在线特征大数据分类方法[J]. 微电子学与计算机, 2021,38(9): 61-66.
|
|
LI Y Y . Big data classification method of neighborhood search for online feature selection[J]. Microelectronics & Computer, 2021,38(9): 61-66.
|
| [4] |
臧艳辉, 赵雪章, 席运江 . Spark框架下利用分布式NBC的大数据文本分类方法[J]. 计算机应用研究, 2019,36(12): 3705-3708,3712.
|
|
ZANG Y H , ZHAO X Z , XI Y J . Text classification of big data using distributed NBC under Spark framework[J]. Application Research of Computers, 2019,36(12): 3705-3708,3712.
|
| [5] |
刘孝保, 陆宏彪, 阴艳超 ,等. 基于多元神经网络融合的分布式资源空间文本分类研究[J]. 计算机集成制造系统, 2020,26(1): 161-170.
|
|
LIU X B , LU H B , YIN Y C ,et al. Distributed resource spatial text classification based on multivariate neural network fusion[J]. Computer Integrated Manufacturing Systems, 2020,26(1): 161-170.
|
| [6] |
曹瑜, 王楠, 徐志超 . Spark 框架结合分布式 KNN 分类器的网络大数据分类处理方法[J]. 计算机应用研究, 2019,36(11): 3274-3277,3333.
|
|
CAO Y , WANG N , XU Z C . Network big data classification processing method based on Spark and distributed KNN classifier[J]. Application Research of Computers, 2019,36(11): 3274-3277,3333.
|
| [7] |
SATHYARAJ R , RAMANATHAN L , LAVANYA K ,et al. Chicken swarm foraging algorithm for big data classification using the deep belief network classifier[J]. Data Technologies and Applications, 2020: 332-352.
|
| [8] |
WANG Y J , CHENG S M , ZHANG X C ,et al. Block storage optimization and parallel data processing and analysis of product big data based on the hadoop platform[J]. Mathematical Problems in Engineering, 2021: 1-14.
|
| [9] |
尹春勇, 张帼杰 . 面向分布式漂移数据流的集成分类模型[J]. 计算机应用, 2021,41(7): 1947-1955.
|
|
YIN C Y , ZHANG G J . Ensemble classification model for distributed drifted data streams[J]. Journal of Computer Applications, 2021,41(7): 1947-1955.
|
| [10] |
刘恒 . 基于元胞自动机的分布式洪水预报研究[J]. 人民黄河, 2020,42(8): 49-55.
|
|
LIU H . Study of distributed flood forecasting based on cellular automata[J]. Yellow River, 2020,42(8): 49-55.
|
| [11] |
屠要峰, 陈正华, 韩银俊 ,等. 基于持久性内存和SSD的后端存储MixStore[J]. 计算机研究与发展, 2021,58(2): 406-417.
|
|
TU Y F , CHEN Z H , HAN Y J ,et al. MixStore:back-end storage based on persistent memory and SSD[J]. Journal of Computer Research and Development, 2021,58(2): 406-417.
|
| [12] |
钱玲飞, 崔晓蕾 . 基于数据增强的领域知识图谱构建方法研究[J]. 现代情报, 2022,42(3): 31-39.
|
|
QIAN L F , CUI X L . Research on construction method of domain knowledge graph based on transfer learning[J]. Journal of Modern Information, 2022,42(3): 31-39.
|
| [13] |
黄丽莲, 姚文举, 项建弘 ,等. 一种具有多对称同质吸引子的四维混沌系统的超级多稳定性研究[J]. 电子与信息学报, 2022,44(1): 390-399.
|
|
HUANG L L , YAO W J , XIANG J H ,et al. Extreme multi-stability of a four-dimensional chaotic system with infinitely many symmetric homogeneous attractors[J]. Journal of Electronics & Information Technology, 2022,44(1): 390-399.
|
| [14] |
陈维兴, 苏景芳, 孟美含 . 元胞机制下机坪机会网络缓存控制策略[J]. 江苏大学学报(自然科学版), 2022,43(1): 75-82.
|
|
CHEN W X , SU J F , MENG M H . Control strategy of apron opportunity network cache under cell evolution rule[J]. Journal of Jiangsu University:Natural Science Edition, 2022,43(1): 75-82.
|
| [15] |
张士杰, 王颖明, 王琦 ,等. 基于元胞自动机-格子玻尔兹曼模型的枝晶碰撞行为模拟[J]. 物理学报, 2021,70(23): 335-343.
|
|
ZHANG S J , WANG Y M , WANG Q ,et al. Simulation of dendrite collision behavior based on cellular automata-lattice Boltzmann model[J]. Acta Physica Sinica, 2021,70(23): 335-343.
|