








1 引言
随着智慧城市、智慧交通、智能家居、智能电网、智慧医疗、在线社交网络、Web 3.0等数字化技术的发展,人们的衣食住行、健康医疗等信息被数字化,可以随时随地通过海量的传感器、智能处理设备等终端进行收集和使用,实现物与物、物与人、人与人等之间在任何时候、任何地点的有效连接,也促成了大数据时代的到来[1]。
大数据蕴含着巨大的商业价值,目前各行各业都在做大数据分析和挖掘,企业、运营商等在各自拥有的数据或互联网上发布的数据中发掘潜在价值,为提高自己的利润或达到其他目的服务。然而,在享受大数据挖掘得到的各种各样有价值的信息给生产、生活带来便利的同时,也不可避免地泄露了人们的隐私。例如,亚马逊公司推出了“未下单先调货”计划,利用大数据分析技术,基于对网购数据的关联挖掘分析,在用户尚未下单前预测其购物内容,提前发出包裹至转运中心,缩短配送时间,但如果处理不好,很可能会泄露大量用户的隐私;医院在给疾病控制中心等研究部门提供大数据,进行疾病预防和决策时,如果不进行数据处理,则会泄露病人的隐私信息;上市公司在发布自己财务年报或其他新产品信息时,如果不对发布的数据进行适当处理,就会给商业上的竞争者以可乘之机。
如何在不泄露用户隐私的前提下,提高大数据的利用率,挖掘大数据的价值,是目前大数据研究领域的关键问题,将直接关系到大数据的民众接受程度和进一步发展趋势。具体而言,实施大数据环境下的隐私保护,需要在大数据产生的整个生命周期中考虑两个方面:如何从大数据中分析挖掘出更多的价值;如何保证在大数据的分析使用过程中,用户的隐私不被泄露。有时数据发布者恶意挖掘大数据中的隐私信息,此种情况下,更需要加强对数据发布时的隐私保护,以达到数据利用和隐私保护二者之间的折中。
本文的主要贡献为:首先,给出了大数据隐私的概念及隐私保护的生命周期模型;然后,从大数据生命周期的4个阶段(即数据的发布、存储、分析和使用)出发,对大数据隐私保护中的技术现状和发展趋势进行了分类阐述,并对该技术的优缺点、适用范围等进行分析;最后,对大数据隐私保护技术发展的方向和趋势进行了阐述。
2 大数据隐私概念与表示模型
2.1 隐私的概念及量化
在维基百科中,隐私的定义是个人或团体将自己或自己的属性隐藏起来的能力,从而可以选择性地表达自己(https://en.wikipedia.org/wiki/Privacy)。具体什么被界定为隐私,不同的文化或个体可能有不同的理解,但主体思想是一致的,即某些数据是某人(或团体)的隐私时,通常意味着这些数据对他们而言是特殊的或敏感的。综上所述认为,隐私是可确认特定个人(或团体)身份或其特征,但个人(或团体)不愿被暴露的敏感信息。在具体应用中,隐私即用户不愿意泄露的敏感信息,包括用户和用户的敏感数据。
例如,病人的患病数据、个人的位置轨迹信息、公司的财务信息等敏感数据都属于隐私。但当针对不同的数据以及数据所有者时,隐私的定义也会存在差别[2]。例如,保守的病人会视疾病信息为隐私,而开放的病人却不视之为隐私;小孩子的定位信息对于父母而言不是隐私,对于其他人而言却是隐私;有些用户的数据现在是隐私,可能几十年后就不是隐私。从隐私的类型划分,隐私可划分为五大类。
● 财务隐私:与银行和金融机构相关的隐私。
● 互联网隐私:使某用户在互联网上暴露该用户自己的信息以及谁能访问这些信息的能力。
● 医疗隐私:患者患病和治疗信息的保护。
● 政治隐私:用户在投票或投票表决时的保密权。
● 信息隐私:数据和信息的保护。
在隐私数据的整个生命周期中,都必须对隐私数据进行准确描述和量化,才能全面地保护隐私数据。隐私可简单描述为:隐私=(信息本体+属性)×时间×地点×使用对象。
可以看出,信息本体就是拥有隐私的用户,隐私以信息本体和属性为基础,包含时间、地点、来源和使用对象等多个因素。为了更好地管理隐私以及进行隐私计算,明确在何种情况下数据发布者、数据存储方以及数据使用者对哪些隐私数据进行保护,需要对隐私数据进行量化。在隐私数据的量化过程中,需要综合考虑用户的属性、行为、数据的属性、传播途径、利用方式等因素,并对隐私数据的计算和变更有很好的支撑。
2.2 大数据生命周期的隐私保护模型
在大数据发布、存储、挖掘和使用的整个生命周期过程中,涉及数据发布者、数据存储方、数据挖掘者和数据使用者等多个数据的用户,如图1所示。在大数据生命周期的各个阶段,大数据隐私保护模型各部分的风险和技术如下所述。
(1)数据发布
图1
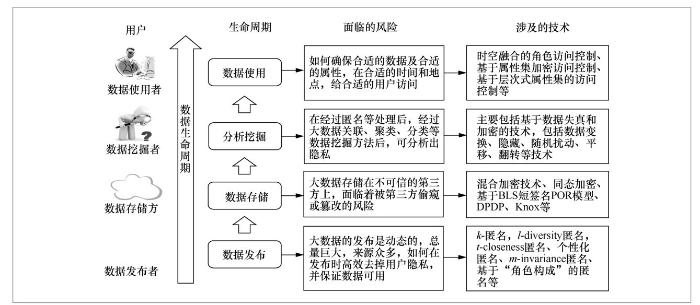
数据发布者即采集数据和发布数据的实体,包括政府部门、数据公司、网站或者用户等。与传统针对隐私保护进行的数据发布手段相比,大数据发布面临的风险是大数据的发布是动态的,且针对同一用户的数据来源众多,总量巨大,如何在数据发布时,保证用户数据可用的情况下,高效、可靠地去掉可能泄露用户隐私的内容,是亟待解决的问题。传统针对数据的匿名发布技术,包括k-匿名、l-diversity匿名、t-closeness匿名、个性化匿名、m-invariance匿名、基于“角色构成”的匿名等方法,可以实现对发布数据时的匿名保护。在大数据的环境下,如何对这些技术进行改进和发展,以满足大数据发布的隐私保护需求,是需要着重研究的内容。
(2)数据存储
在大数据时代,数据存储方一般为云存储平台,与传统数据的拥有者自己存储数据不同,大数据的存储者和拥有者是分离的,云存储服务提供商并不能保证是完全可信的。用户的数据面临着被不可信的第三方偷窥数据或者篡改数据的风险。加密方法是解决该问题的传统思路,但是,由于大数据的查询、统计、分析和计算等操作也需要在云端进行,为传统加密技术带来了新的挑战。比如,同态加密技术、混合加密技术、基于BLS短签名POR模型、DPDP、Knox等方法,是针对数据存储时防止隐私泄露而采取的一些方法。
(3)数据挖掘
数据挖掘者即从发布的数据中挖掘知识的人或组织,他们往往希望从发布的数据中尽可能多地分析挖掘出有价值的信息,这很可能会分析出用户的隐私信息。在大数据环境下,由于数据存在来源多样性和动态性等特点,在经过匿名等处理后的数据,经过大数据关联分析、聚类、分类等数据挖掘方法后,依然可以分析出用户的隐私。针对数据挖掘的隐私保护技术,就是在尽可能提高大数据可用性的前提下,研究更加合适的数据隐藏技术,以防范利用数据发掘方法引发的隐私泄露。现在的主要技术包括:基于数据失真和加密的方法,比如数据变换、隐藏、随机扰动、平移、翻转等技术。
(4)数据使用
数据使用者是访问和使用大数据以及从大数据中挖掘出信息的用户,通常为企业和个人,通过大数据的价值信息扩大企业利润或提供个人生活质量。在大数据的环境下,如何确保合适的数据及属性能够在合适的时间和地点,给合适的用户访问和利用,是大数据访问和使用阶段面临的主要风险。为了解决大数据访问和使用时的隐私泄露问题,现在的技术主要包括:时空融合的角色访问控制、基于属性集加密访问控制(attribute-based encryption access control,ABE)、基于密文策略属性集的加密(ciphertext policy attribute set based encryption,CP-ASBE)、基于层次式属性集的访问控制(hierarchical attribute set based encryption,HASBE)等技术。
下面针对大数据生命周期中的发布、存储、挖掘和使用4个过程中的隐私保护技术进行阐述。
3 大数据发布隐私保护技术
为了从大数据中获益,数据持有方有时需要公开发布己方数据,这些数据通常会包含一定的用户信息,服务方在数据发布之前需要对数据进行处理,使用户隐私免遭泄露。此时,确保用户隐私信息不被恶意的第三方获取是极为重要的。一般的,用户更希望攻击者无法从数据中识别出自身,更不用说窃取自身的隐私信息,匿名技术就是这种思想的实现之一。
Samarati P和Sweeney L在1998年首次提出了匿名化的概念[3]。数据发布匿名是匿名技术在数据发布中的应用,在确保所发布的信息数据公开可用的前提下,隐藏公开数据记录与特定个人之间的对应联系,从而保护个人隐私。最初,服务方仅仅删除数据表中有关用户身份的属性作为匿名实现方案。但实践表明,这种匿名处理方案是不充分的。攻击者能从其他渠道获得包含了用户标识符的数据集,并根据准标识符连接多个数据集,重新建立用户标识符与数据记录的对应关系。这种攻击称为链接攻击(linking attack),曾多次造成重大的安全事故。
3.1 大数据中的静态匿名技术
若等价类在敏感属性上取值单一,即使无法获取特定用户的记录,攻击者仍然可以获得目标用户的隐私信息。为此,研究者提出了l-diversity匿名策略[5]。l-diversity保证每一个等价类的敏感属性至少有l个不同的值,l-diversity使得攻击者最多以1/l的概率确认某个个体的敏感信息。这使得等价组中敏感属性的取值多样化,从而避免了k-匿名中的敏感属性值取值单一所带来的缺陷。
若等价类中敏感值的分布与整个数据集中敏感值的分布具有明显的差别,攻击者可以以一定概率猜测目标用户的敏感属性值。为此,研究者提出了t-closeness匿名策略[6]。t-closeness匿名以EMD(earth mover’s distance)衡量敏感属性值之间的距离,并要求等价组内敏感属性值的分布特性与整个数据集中敏感属性值的分布特性之间的差异尽可能大。即在l-diversity基础上,t-closeness匿名考虑了敏感属性的分布问题,它要求所有等价类中敏感属性值的分布尽量接近该属性的全局分布。
数据发布匿名最初只考虑了发布后不再变化的静态数据,但在大数据环境中,数据的动态更新是大数据的重要特点之一。一旦数据集更新,数据发布者便需要重新发布数据,以保证数据的可用性。此时,攻击者可以通过对不同版本的发布数据进行联合分析与推理,上述基于静态数据的匿名策略将会失效,下面介绍大数据中的动态匿名技术。
3.2 大数据中的动态匿名技术
Byun等人最先提出了一种支持新增的数据重发布匿名策略[11],使得数据集即使因为新增数据而发生改变,但多次发布后不同版本的公开数据仍然能满足l-diversity准则,以保证用户的隐私。在这种匿名策略中,数据发布者需要集中管理不同发布版本中的等价类。若新增的数据集与先前版本的等价类无交集并能满足l-diversity准则,则可作为新版本发布数据中的新等价类出现,否则需要等待;而若新增的数据集与先前版本的等价类有交集,则需要插入最为接近的等价类中;若一个等价类过大,还需要对等价类进行划分,以形成新的较小的等价类。
为了支持数据重发布对历史数据集的修改,研究者注意到在不同版本的数据发布中,敏感属性可分为常量属性与可变属性两种,并针对这种情况提出HD-composition匿名策略[13]。这种匿名策略同时支持数据重发布的新增、删除与修改操作。为由于数据集的改变而发生的重发布操作提供了有效的匿名保护。
在大数据环境下,海量数据规模使得匿名技术的效率变得至关重要。研究者结合大数据处理技术,实现了一系列传统的数据匿名策略,提高了匿名技术的效率。下面介绍提高大数据匿名处理的效率技术。
3.3 大数据中的匿名并行化处理
在大数据环境下,大数据的巨规模特性使得匿名技术的效率变得至关重要。大数据环境下的数据匿名技术也是大数据环境下的数据处理技术之一,通用的大数据处理技术也能应用于数据匿名发布这一特定目的。当前,大数据环境下数据匿名技术的思想、模型与传统的数据匿名技术一致,主要的不同与问题在于使用大数据环境下的相关技术实现先前的各类数据匿名算法。
此外,数据的多源化为数据发布匿名技术带来了新的挑战[19]。攻击者可以从多个数据源中获得足够的数据信息以对发布数据进行去匿名化。现有的匿名策略还难以防范此类攻击,有待进一步改进。
4 大数据存储隐私保护技术
云计算的出现为大数据的存储提供了基础平台,通过云服务器的计算和存储能力,对大数据的访问将更快速、更便宜、更简单和更标准化。但将敏感的数据存放在不可信的第三方服务器中存在潜在的威胁,因为云服务器提供商可能对用户的数据进行偷窥,也可能出于商业的目的与第三方共享数据或者无法保证数据的完整性。如何安全可靠地将敏感数据交由云平台存储和管理,是大数据隐私保护中必须解决的关键问题之一。
大数据存储给隐私保护带来了新的挑战,主要包括:大数据中更多的隐私信息存储在不可信的第三方中,极易被不可信的存储管理者偷窥;大数据存储的难度增大,存储方有可能无意或有意地丢失数据或篡改数据,从而使得大数据的完整性得不到保证。为解决上述挑战,应用的技术主要包括加密存储和第三方审计技术等,具体介绍如下。
4.1 大数据加密存储技术
Lin H Y等人[24]于2012年提出了一种针对HDFS(Hadoop分布式文件系统)的混合加密技术,该技术将对称加密和非对称加密进行了融合。当有新的隐私数据文件需要加密时,先通过非对称加密方法(AES或RC4)对该文件内容进行快速加密,并将其分布式存储于每个HDFS节点上,然后使用对称加密方法对用于加密该文件内容的密钥进行加密,并将结果存储于该数据的头文件中,以此提供对密钥的有效管理。该方法能够很好地实现对大数据隐私信息的存储保护,但是这些加密后的隐私信息需要先经过解密才能在大数据平台中进行运算,其运算结果在存储到大数据平台时同样需要重新加密,这个加解密过程会造成很大的时间开销。
同态加密算法可以允许人们对密文进行特定的运算,而其运算结果解密后与用明文进行相同运算所得的结果一致。全同态加密算法则能实现对明文所进行的任何运算,都可以转化为对相应密文进行恰当运算后的解密结果[25,26]。将同态加密算法用于大数据隐私存储保护,可以有效避免存储的加密数据在进行分布式处理时的加解密过程,Chen X等人于2013年将全同态加密技术和MapReduce编程模型进行结合[27],通过在reduce模块之前,增加一个在密文状态下进行计算的转换模块,使得经过全同态加密后的文件可以在不解密的情况下进行MapReduce运算,从而能够大大优化存储的大数据隐私信息的运算效率。Wang等人[28]基于代理重签名的思想,设计了一个可以有效地支持用户撤销的云端群组数据的同态解密验证方案,保护群组用户的身份隐私,且在群组用户的撤销过程中,因维护数据完整性所产生的开销主要由云端而不是用户来承担,减轻了群组在用户撤销过程中的计算和通信开销。
4.2 大数据审计技术
当用户将数据存储在云服务器中时,就丧失了对数据的控制权。如果云服务提供商不可信,其可能对数据进行篡改、丢弃,却对用户声称数据是完好的。为了防止这种危害,云存储中的审计技术则被提出。云存储审计指的是数据拥有者或者第三方机构对云中的数据完整性进行审计。通过对数据进行审计,确保数据不会被云服务提供商篡改、丢弃,并且在审计的过程中用户的隐私不会被泄露。
当前已有很多研究者对云存储中的审计进行了研究。Ateniese等人[29]提出了一种可证明的数据持有(provable data possession,PDP)模型,该模型可以对服务器上的数据进行完整性验证。该模型先从服务器上随机采样相应的数据块,并生成持有数据的概率证据。客户端维持着一定数量的元数据,并利用元数据来对证据进行验证。在该模型中,挑战应答协议传输的数据量非常少,因此所耗费的网络带宽较小。
Wang C等人[35]提出了一种支持隐私保护的审计方案。他们认为第三方审计(third party auditor,TPA)应该满足如下要求:一是第三方审计能够高效地完成对数据的审计,并且不为用户带来多余的负担;二是第三方审计不能为用户隐私带来脆弱性。他们提出的方法基于公钥加密和同态认证,能够在保护用户隐私的情况下完成公开审计。Wang B Y等人[36]首次提出一种用于对云中共享数据进行审计的隐私保护策略。他们在对数据的审计过程中利用环形签名来对数据完整性进行验证。此策略能够很好地对用户的隐私进行保护。其不足之处在于通信开销比较大。Wang B Y等人[37]还提出了一种名为Knox的云中数据的隐私保护策略。该策略利用群组签名来构造同态认证,使得第三方审计机构不需要从云中获取整个数据即能完成对数据完整性的审计。
随着大数据时代的发展,可以预见到,未来存储在云中的数据会越来越多,这也为大数据审计技术带来了巨大的挑战。在未来的研究中,以下几个方向也许值得研究者们关注:一个是云中数据量越来越大、数据种类越来越丰富,如何提供更加高效、安全的审计服务值得关注;另一个是随着人们在线上的交互越来越频繁,云中数据动态操作可能更加频繁,如何应对如此频繁的数据动态操作也值得研究者们关注。
5 大数据挖掘隐私保护技术
随着技术的进步,数据挖掘过程中的隐私保护问题逐渐走进了人们的视线,尤其是在大数据时代,成为数据挖掘界一个新的研究热点。隐私保护数据挖掘,即在保护隐私前提下的数据挖掘,其主要关注点有两个:一是对原始数据集进行必要的修改,使得数据接收者不能侵犯他人隐私;二是保护产生模式,限制对大数据中敏感知识的挖掘。
5.1 关联规则的隐私保护
关联规则的隐私保护主要有两类方法[41]:第一类是变换(distortion),即修改支持敏感规则的数据,使得规则的支持度和置信度小于一定的阈值而实现规则的隐藏;第二类是隐藏(blocking),该类方法不修改数据,而是对生成敏感规则的频繁项集进行隐藏。这两类方法都对非敏感规则的挖掘具有一定的负面影响。下面分别对这两类方法进行介绍。
在变换方法中,Atallah等人[42]证明了采用变换方法进行关联规则挖掘是一个NP难问题。他们将敏感规则相关的支持数据进行变换,从而降低敏感规则的支持度和置信度。Oliveira等人[43]提出了一种对于数据进行变换的方法。首先,对于每一条敏感规则rpi,找到对应的敏感事务T[rpi];其次,对于每一条敏感规则,将其中对规则支持度最低的项设为牺牲项Victimrpi;然后,根据事先设定的暴露阈值ψ,对每一条敏感规则计算其需要隐藏的事务数量NumTransrpi;最后进行数据重构,对于每一条敏感规则rpi,对T[rpi]中的事务按照冲突程度升序排序,选取T[rpi]中前NumTransrpi个事务TransToSanitize,对于数据集D中的事务t,如果t∈TransToSanitize,则将t中牺牲项Victimrpi替换之后置入新的数据集D′中。
5.2 分类结果的隐私保护
分类方法的结果通常可以发现数据集中的隐私敏感信息,因此需要对敏感的分类结果信息进行保护。这类方法的目标是在降低敏感信息分类准确度的同时,不影响其他应用的性能。
Agrawal等人[46]采用随机扰动的方式对原始数据进行加密,以实现分类结果的隐私保护。算法首先对数据进行随机扰动,对于原始数据X1,X2,…,Xn,将其看成满足特定分布的随机变量X,为了隐藏原始数据值,在每个原始值上添加一个服从随机分布Y的随机数Y1,Y2,…,Yn,则扰动后的数据为X1+Y1,X2+Y2,…,Xn+Yn的形式,记为Z;然后对数据进行恢复,数据恢复即已知随机变量分布Y、Z以及X+Y=Z的关系,用Y、Z的值估计X的过程,应用贝叶斯公式可以得到原始数据估计的迭代方程,从而得到原始数据的近似X’;最后是分类过程,得到了原始数据的模糊近似X’之后即可应用普通的分类方法,如利用决策树对数据进行分类,降低分类的准确度。
Moskowitz L M等人[47]设计了名为“Rational Downgrader”的隐私保护系统,该系统着力于降低信息公开过程中隐私泄露的程度,确保普通用户无法通过已经或将要公开的信息推测出应被保护的隐私信息。该系统主要包括3个部分:其决策部分用于评估哪些分类规则可能被推测出来;示警部分用于测定已经泄露的隐私信息量;降级约束部分降低敏感结果的分类准确度。
Chang等人[48]提出了一种新的范式,以处理由降级(downgrading)引发的隐私信息推测问题。这种新范式包含两大部分:对隐私信息推测问题应该采用决策树进行分析以及对降级问题进行约束、限制。其中,他们使用了一种新的热力学激励的方式来处理对分类规则进行推理的过程,这些被推理的规则来源于部分公开的数据。
5.3 聚类结果的隐私保护
与分类结果的隐私保护类似,保护聚类的隐私敏感结果也是当前研究的重要内容之一。Oliveira等人[49]对发布的数据采用平移、翻转等几何变换的方法进行变换,以保护聚类结果的隐私内容。此方法首先是对原始数据进行几何变换,以对敏感信息进行隐藏,然后是聚类过程,经过几何变换后的数据可以直接应用传统的聚类算法(如K近邻)进行聚类。他们提出的方法在聚类准确度和保护隐私方面达到了较好的平衡。
Vaidya等人[50]提出了一种分布式K-means聚类方法,该方法专门面向不同站点上存有同一实体集合的不同属性的情况。使用此聚类方法,每个站点可以学习对每个实体进行聚类,但在学习过程中并不会获知其他站点上所存属性的相关信息,从而在信息处理的过程中保障了数据隐私。
6 大数据访问控制技术
大数据给传统访问控制技术带来的挑战如下。
● 大数据的时空特性,大数据下的访问控制模型需要在传统访问控制的基础上,充分考虑用户的时间信息和位置信息。
● 在大数据时代的开放式环境下,用户来自于多种组织、机构或部门,单个用户又通常具有多种数据访问需求[53],如何合理设定角色并为每个用户动态分配角色是新的挑战。
● 大数据面向的应用需求众多,不同的应用需要不同的访问控制策略。以社交网站为例:对于用户个人主页的数据,需要基于用户社交关系的访问控制;对于网站数据,需要基于用户等级的访问控制等。
传统的访问控制方式,包括自主访问控制和强制访问控制技术,难以应对上述挑战。因此,大数据时代的访问控制技术主要包括基于角色的访问控制和基于属性的访问控制方法。
6.1 基于角色的访问控制
基于角色的访问控制(role-based access control,RBAC)54]中,不同角色的访问控制权限不尽相同。通过为用户分配角色,可实现对数据的访问权限控制。由此,在基于角色的访问控制中,角色挖掘是前提。通常,角色是根据工作能力、职权及责任确定的。大数据场景下的角色挖掘,需要大量人工参与角色定义、角色划分及角色授权等问题,衍生出了所谓角色工程(role engineering)[55]。角色工程的最终目的是根据个体在某一组织内所担当的角色或发挥的作用来实现最佳安全管理。有效的角色工程可以为用户权限提供最优分配、鉴别异常用户、检测并删除冗余或过量的角色、使角色定义及用户权限保持最新、降低随之发生的各类风险等。大数据时代,可用于角色挖掘的数据丰富多样,对角色权限的配置也更加灵活复杂。一方面需要通过挖掘己方数据,合理配置权限,实现数据的访问可控;另一方面,需要挖掘可收集到的对方数据,找出重要目标角色,以便重点关注。因此,大数据下的角色工程需要从攻击和防护的角度综合考虑。
大数据时代的访问控制应用场景广泛,需求也不尽相同。一些研究通过广泛收集研究对象的应用数据,试图挖掘出其中的关键角色,从而有针对性地采取处理措施。参考文献[63]提出在RBAC的基础上增加责任的概念,即responsibility-RBAC,对用户职责进行显式确认,以根据实际应用场景优化角色的数量。
6.2 基于属性的访问控制
基于属性的访问控制(attribute-based access control,ABAC)[64]通过将各类属性,包括用户属性、资源属性、环境属性等组合起来用于用户访问权限的设定。RBAC以用户为中心,而没有将额外的资源信息,如用户和资源之间的关系、资源随时间的动态变化、用户对资源的请求动作(如浏览、编辑、删除等)以及环境上下文信息进行综合考虑。而基于属性的访问控制ABAC通过对全方位属性的考虑,可以实现更加细粒度的访问控制。
ABE将属性与密文和用户私钥关联,能够灵活地表示访问控制策略。但对于存储在云端的大数据,当数据拥有者想要改变访问控制策略时,需要先将加密数据从云端取回本地,解密原有数据,之后再使用新的策略重新加密数据,最后将密文传回云端。在这一过程中,密文需要来回传输,会消耗大量带宽,从而引发异常,引起攻击者的注意[69],对数据的解密和重新加密也会使得计算复杂度显著增大。为此,Yang等人提出了一种高效的访问控制策略动态更新方法[70]。当访问控制策略发生变化时,数据拥有者首先使用密钥更新策略UKeyGen生成更新密钥UK_m,并将其和属性变化情况(如增加、减少特定属性)一起发送到云端。之后,在云端上按照密文更新策略CTUpdate对原有的密文进行更新,而不用对原有密文进行解密。
云端代理重加密将基于属性的加密与代理重加密技术结合,实现云中的安全、细粒度、可扩展的数据访问控制[71,72,73]。新的用户获取授权或原有用户释放授权时的重加密工作由云端代理,减轻数据拥有者的负担。同时对数据拥有者来说,云端可能并非是完全可信的,在利用云端进行代理重加密的同时还应防止数据被云端窥探。用户提交给云的是密文,云端无法解密,云端利用重加密算法转换为另一密文,新的密文只能被授权用户解密,而在整个过程中云端服务器看到的始终是密文,看不到明文。云中用户频繁地获取和释放授权,使得数据密文重加密工作繁重,由云端代理重加密工作,可以大大减轻数据拥有者的负担。同时,云端无法解密密文,也就无法窥探数据内容。
大数据为访问控制带来了诸多挑战,但也暗藏机遇。随着计算能力的进一步提升,无论是基于角色的访问控制还是基于属性的访问控制,访问控制的效率将得到快速提升。同时,更多的数据将被收集起来用于角色挖掘或者属性识别,从而可以实现更加精准、更加个性化的访问控制。总体而言,目前专门针对大数据的访问控制还处在起步阶段,未来将角色与属性相结合的细粒度权限分配将会有很大的发展空间。
7 结束语
如何在不泄露用户隐私的前提下,提高大数据的利用率,挖掘大数据的价值,是目前大数据研究领域的关键问题。本文首先介绍了大数据带来的隐私保护问题,然后介绍了大数据隐私的概念和大数据生命周期的隐私保护模型,接着从大数据生命周期的发布、存储、分析和使用4个阶段出发,对大数据隐私保护中的技术现状和发展趋势进行了分类阐述,对该技术的优缺点、适用范围等进行分析,探索了大数据隐私保护技术进一步发展的方向。
参考文献
大搜索技术白皮书
[R/OL].(2015-01-06)[2015-05-23]. .
White paper on big search
..(2015-01-06)[2015-05-23]. .
面向数据库应用的隐私保护研究综述
[J].
Privacy preservation in database applications:a survey
[J].
Generalizing data to provide anonymity when disclosing information
[C]//
k-anonymity:amodel for protecting privacy
[J].
A face is exposed for AOL searcher No.4417749
[N/OL].
How to break anonymity of the netflix prize dataset
[J].
l-diversity:privacy beyond k-anonymity
[J].
t-closeness:privacy beyond k-anonymity and l-diversity
[C]//
Enhancing privacy through caching in location-based services
[C]//
A sequential decision-theoretic model for medical diagnostic system
[J].
Secure anonymization for incremental dataset
[C]//
m-invariance:towards privacy preserving re-publication of dynamic datasets
[C]//
Privacy preserving serial data publishing by role composition
[C]//
A hybrid approach for scalable sub-tree anonymization over big data using MapReduce on cloud
[J].
Combining top-down and bottom-up:scalable sub-tree anonymization over big data using MapReduce on cloud
[J].
FAST:fast anonymization of big data streams
[C]//
Making big data,privacy,and anonymization work together in the enterprise:experiences and issues
[C]//
De-anonymization technology and applications in the age of big data
[J].
Robust de-anonymization of large sparse datasets
[C]//
Proposed federal information processing data encryption standard
[J].
A method for obtaining digital signatures and public-key cryptosystems
[J].
A public key cryptosystem and a signature scheme based on discrete logarithms
[J].
Toward data confidentiality via integrating hybrid encryption schemes and Hadoop distributed file system
.[C]//
A fully homomorphic encryption scheme
[D].
Fully homomorphic encryption over the integers
[C]//
The data protection of MapReduce using homomorphic encryption
[C]//
Public auditing for shared data with efficient user revocation in the cloud
[C]//
Provable data possession at untrusted stores
[J].
PORs:proofs of retrievability for large files
[C]//
Compact proofs of retrievability
[J].
Scalable and efficient provable data possession
[C]//
Dynamic provable data possession
[C]//
Enabling public verifiability and data dynamics for storage security in cloud computing
[C]//
Privacy-preserving public auditing for data storage security in cloud computing
[C]//
Oruta:privacy preserving public auditing for shared data in the cloud
[C]//
Knox:privacy preserving auditing for shared data with large groups in the cloud
[C]//
Big data security and privacy
[C]//
Data mining with big data
[J].
A General Survey of Privacy-Preserving Data Mining Models and Algorithms
[M].
Disclosure limitation of sensitive rules
[C]//
Privacy preserving frequent itemset mining
[C]//
An Integrated Framework for Database Inference and Privacy Protection
[M].
A framework for privacy preservation against adversarial data mining
[C]//
Privacy-preserving data mining
[J].
A Decision Theoretical Based System for Information Downgrading
[R/OL].(2011-08-27)[2015-11-20]. .
Parsimonious downgrading and decision trees applied to the inference problem
[C]//
Privacy preserving clustering by data transformation
[J].
Privacy-preserving k-means clustering over vertically partitioned data
[C]//
Access control:principle and practice
[J].
Probabilistic n-of-N skyline computation over uncertain data streams
[J].
Role-based access control models
[J].
Role mining-revealing business roles for security administration using data mining technology
[C]//
LRBAC:a location-aware role-based access control model
[C]//
Geo-rbac:a spatially aware rbac
[J].
基于尺度的时空RBAC模型
[J].
A role-based access control model based on space,time and scale
[J].
Fast exact and heuristic methods for role minimization problems
[C]//
最小扰动混合角色挖掘方法研究
[J].
Hybrid role mining methods with minimal perturbation
[J].
A simple role mining algorithm
[C]//
Role mining over big and noisy data theory and some applications
[D].
Enhancement of business it alignment by including responsibility components in RBAC
[C]//
Attribute-based encryption for fine-grained access control of encrypted data
[C]//
Attribute-sets:a practically motivated enhancement to attribute-based encryption
[C]//
HASBE:a hierarchical attribute-based solution for flexible and scalable access control in cloud computing
[J].
Attribute-based access control models and implementation in cloud infrastructure as a service
[D].
Detecting hidden anomalies using sketch for high-speed network data stream monitoring
[J].
Enabling efficient access control with dynamic policy updating for big data in the cloud
[C]//
Divertible protocols and atomic proxy cryptography
[C]//
An efficient approach on answering top-k queries with grid dominant graph index
[C]//
Improving various reversible data hiding schemes via optimal codes for binary covers
[J].
Protecting your right:attribute-based keyword search with fine-grained owner-enforced search authorization in the cloud
[C]//
Achieving lightweight and secure access control in multi-authority cloud
[C]//

{kind=link}
{kind=link}