Medical image denoising using convolutional denoising autoencoders
1
2016
... 基于深度学习的医学图像降噪主要应用在低剂量CT图像中.卷积降噪自动编码器(convolutional neural networkdenoise auto-encoder,CNN-DAE)是早期用于医学图像降噪的深度学习模型[1 ] .该模型通过一些堆叠的卷积层,以编码和解码的方式从噪声图像中学习无噪图像,其鲁棒性较差,对噪声类型变化较为敏感.随后,Chen H等人[2 ] 提出RED-CNN降噪模型,将残差网络与卷积自动编码器相结合,通过跳跃连接形成深度网络,实现低剂量CT图像的降噪.同年,Kang E等人[3 ] 首先对低剂量CT图像进行方向小波变换,然后将深度卷积神经网络模型应用于小波系数图像,实现降噪,并使用残差学习架构加快网络训练速度,提高性能. ...
Low-dose CT with a residual encoderdecoder convolutional neural network
1
2017
... 基于深度学习的医学图像降噪主要应用在低剂量CT图像中.卷积降噪自动编码器(convolutional neural networkdenoise auto-encoder,CNN-DAE)是早期用于医学图像降噪的深度学习模型[1 ] .该模型通过一些堆叠的卷积层,以编码和解码的方式从噪声图像中学习无噪图像,其鲁棒性较差,对噪声类型变化较为敏感.随后,Chen H等人[2 ] 提出RED-CNN降噪模型,将残差网络与卷积自动编码器相结合,通过跳跃连接形成深度网络,实现低剂量CT图像的降噪.同年,Kang E等人[3 ] 首先对低剂量CT图像进行方向小波变换,然后将深度卷积神经网络模型应用于小波系数图像,实现降噪,并使用残差学习架构加快网络训练速度,提高性能. ...
A deep convolutional neural network using directional wavelets for low‐dose X‐ray CT reconstruction
1
2017
... 基于深度学习的医学图像降噪主要应用在低剂量CT图像中.卷积降噪自动编码器(convolutional neural networkdenoise auto-encoder,CNN-DAE)是早期用于医学图像降噪的深度学习模型[1 ] .该模型通过一些堆叠的卷积层,以编码和解码的方式从噪声图像中学习无噪图像,其鲁棒性较差,对噪声类型变化较为敏感.随后,Chen H等人[2 ] 提出RED-CNN降噪模型,将残差网络与卷积自动编码器相结合,通过跳跃连接形成深度网络,实现低剂量CT图像的降噪.同年,Kang E等人[3 ] 首先对低剂量CT图像进行方向小波变换,然后将深度卷积神经网络模型应用于小波系数图像,实现降噪,并使用残差学习架构加快网络训练速度,提高性能. ...
Low-dose CT image denoising using a generative adversarial network with Wasserstein distance and perceptual loss
1
2018
... 虽然这些网络结构的降噪性能相较于传统方法得到了显著的提升,但是其网络训练均以复原CT图像与相应正常剂量CT图像之间的均方误差最小为优化目标,使得降噪图像存在细节模糊和纹理缺失等问题.为了解决这一问题,研究者提出改进损失函数和模型结构的方法来优化低剂量CT图像的降噪效果.WGAN-VGG模型通过引入感知损失,采用WGAN(Wasserstein generative adversarial network)模型进行降噪,利用Wasserstein距离和感知损失提高降噪图像与真实图像的相似性[4 ] .基于WGAN-GP(gradient penalty)的SMGAN (structurally-sensitive multi-scale generative adversarial net)模型将多尺度结构损失和L1 范数损失结合到目标函数中,并利用相邻切片之间的信息降噪,其结果优于WGAN-VGG模型[5 ] .但是梯度惩罚的使用削弱了生成式对抗网络(generative adversarial network,GAN)的表示能力.为了解决这个问题,Ma Y J等人[6 ] 提出基于最小二乘生成对抗网络(least-square GAN,LS-GAN)的残差生成器结构,通过引入结构相似度和L1 范数损失来提高降噪能力,生成器负责学习噪声,降噪图像为生成器的网络输入与网络输出的相减结果.除了生成模型,为了提高降噪效果,Yin X R等人[7 ] 同时在投影域和图像域采用3D残差网络进行降噪,并利用滤波反投影重建算法,实现投影域和图像域的相互转化,通过迭代的思想实现图像降噪.Wu D F等人[8 ] 提出一致性神经网络模型,实现了无监督的图像降噪方法,其不需要无噪图像标签,仅利用有噪图像对模型进行训练,从而获得降噪图像. ...
Structurally-sensitive multi-scale deep neural network for low-dose CT denoising
1
2018
... 虽然这些网络结构的降噪性能相较于传统方法得到了显著的提升,但是其网络训练均以复原CT图像与相应正常剂量CT图像之间的均方误差最小为优化目标,使得降噪图像存在细节模糊和纹理缺失等问题.为了解决这一问题,研究者提出改进损失函数和模型结构的方法来优化低剂量CT图像的降噪效果.WGAN-VGG模型通过引入感知损失,采用WGAN(Wasserstein generative adversarial network)模型进行降噪,利用Wasserstein距离和感知损失提高降噪图像与真实图像的相似性[4 ] .基于WGAN-GP(gradient penalty)的SMGAN (structurally-sensitive multi-scale generative adversarial net)模型将多尺度结构损失和L1 范数损失结合到目标函数中,并利用相邻切片之间的信息降噪,其结果优于WGAN-VGG模型[5 ] .但是梯度惩罚的使用削弱了生成式对抗网络(generative adversarial network,GAN)的表示能力.为了解决这个问题,Ma Y J等人[6 ] 提出基于最小二乘生成对抗网络(least-square GAN,LS-GAN)的残差生成器结构,通过引入结构相似度和L1 范数损失来提高降噪能力,生成器负责学习噪声,降噪图像为生成器的网络输入与网络输出的相减结果.除了生成模型,为了提高降噪效果,Yin X R等人[7 ] 同时在投影域和图像域采用3D残差网络进行降噪,并利用滤波反投影重建算法,实现投影域和图像域的相互转化,通过迭代的思想实现图像降噪.Wu D F等人[8 ] 提出一致性神经网络模型,实现了无监督的图像降噪方法,其不需要无噪图像标签,仅利用有噪图像对模型进行训练,从而获得降噪图像. ...
Low-dose CT image denoising using a generative adversarial network with a hybrid loss function for noise learning
1
2020
... 虽然这些网络结构的降噪性能相较于传统方法得到了显著的提升,但是其网络训练均以复原CT图像与相应正常剂量CT图像之间的均方误差最小为优化目标,使得降噪图像存在细节模糊和纹理缺失等问题.为了解决这一问题,研究者提出改进损失函数和模型结构的方法来优化低剂量CT图像的降噪效果.WGAN-VGG模型通过引入感知损失,采用WGAN(Wasserstein generative adversarial network)模型进行降噪,利用Wasserstein距离和感知损失提高降噪图像与真实图像的相似性[4 ] .基于WGAN-GP(gradient penalty)的SMGAN (structurally-sensitive multi-scale generative adversarial net)模型将多尺度结构损失和L1 范数损失结合到目标函数中,并利用相邻切片之间的信息降噪,其结果优于WGAN-VGG模型[5 ] .但是梯度惩罚的使用削弱了生成式对抗网络(generative adversarial network,GAN)的表示能力.为了解决这个问题,Ma Y J等人[6 ] 提出基于最小二乘生成对抗网络(least-square GAN,LS-GAN)的残差生成器结构,通过引入结构相似度和L1 范数损失来提高降噪能力,生成器负责学习噪声,降噪图像为生成器的网络输入与网络输出的相减结果.除了生成模型,为了提高降噪效果,Yin X R等人[7 ] 同时在投影域和图像域采用3D残差网络进行降噪,并利用滤波反投影重建算法,实现投影域和图像域的相互转化,通过迭代的思想实现图像降噪.Wu D F等人[8 ] 提出一致性神经网络模型,实现了无监督的图像降噪方法,其不需要无噪图像标签,仅利用有噪图像对模型进行训练,从而获得降噪图像. ...
Domain progressive 3D residual convolution network to improve low-dose CT imaging
1
2019
... 虽然这些网络结构的降噪性能相较于传统方法得到了显著的提升,但是其网络训练均以复原CT图像与相应正常剂量CT图像之间的均方误差最小为优化目标,使得降噪图像存在细节模糊和纹理缺失等问题.为了解决这一问题,研究者提出改进损失函数和模型结构的方法来优化低剂量CT图像的降噪效果.WGAN-VGG模型通过引入感知损失,采用WGAN(Wasserstein generative adversarial network)模型进行降噪,利用Wasserstein距离和感知损失提高降噪图像与真实图像的相似性[4 ] .基于WGAN-GP(gradient penalty)的SMGAN (structurally-sensitive multi-scale generative adversarial net)模型将多尺度结构损失和L1 范数损失结合到目标函数中,并利用相邻切片之间的信息降噪,其结果优于WGAN-VGG模型[5 ] .但是梯度惩罚的使用削弱了生成式对抗网络(generative adversarial network,GAN)的表示能力.为了解决这个问题,Ma Y J等人[6 ] 提出基于最小二乘生成对抗网络(least-square GAN,LS-GAN)的残差生成器结构,通过引入结构相似度和L1 范数损失来提高降噪能力,生成器负责学习噪声,降噪图像为生成器的网络输入与网络输出的相减结果.除了生成模型,为了提高降噪效果,Yin X R等人[7 ] 同时在投影域和图像域采用3D残差网络进行降噪,并利用滤波反投影重建算法,实现投影域和图像域的相互转化,通过迭代的思想实现图像降噪.Wu D F等人[8 ] 提出一致性神经网络模型,实现了无监督的图像降噪方法,其不需要无噪图像标签,仅利用有噪图像对模型进行训练,从而获得降噪图像. ...
Consensus neural network for medical imaging denoising with only noisy training samples
1
2019
... 虽然这些网络结构的降噪性能相较于传统方法得到了显著的提升,但是其网络训练均以复原CT图像与相应正常剂量CT图像之间的均方误差最小为优化目标,使得降噪图像存在细节模糊和纹理缺失等问题.为了解决这一问题,研究者提出改进损失函数和模型结构的方法来优化低剂量CT图像的降噪效果.WGAN-VGG模型通过引入感知损失,采用WGAN(Wasserstein generative adversarial network)模型进行降噪,利用Wasserstein距离和感知损失提高降噪图像与真实图像的相似性[4 ] .基于WGAN-GP(gradient penalty)的SMGAN (structurally-sensitive multi-scale generative adversarial net)模型将多尺度结构损失和L1 范数损失结合到目标函数中,并利用相邻切片之间的信息降噪,其结果优于WGAN-VGG模型[5 ] .但是梯度惩罚的使用削弱了生成式对抗网络(generative adversarial network,GAN)的表示能力.为了解决这个问题,Ma Y J等人[6 ] 提出基于最小二乘生成对抗网络(least-square GAN,LS-GAN)的残差生成器结构,通过引入结构相似度和L1 范数损失来提高降噪能力,生成器负责学习噪声,降噪图像为生成器的网络输入与网络输出的相减结果.除了生成模型,为了提高降噪效果,Yin X R等人[7 ] 同时在投影域和图像域采用3D残差网络进行降噪,并利用滤波反投影重建算法,实现投影域和图像域的相互转化,通过迭代的思想实现图像降噪.Wu D F等人[8 ] 提出一致性神经网络模型,实现了无监督的图像降噪方法,其不需要无噪图像标签,仅利用有噪图像对模型进行训练,从而获得降噪图像. ...
Convolutional neural networks with intermediate loss for 3D super-resolution of CT and MRI scans
2
2020
... 高分辨率的医学图像可以提供更多的临床诊断细节,然而由于采集设备的限制,临床上高分辨率图像较难获取.因此,如何利用深度学习技术从一幅或者多幅低分辨率医学图像中获得高分辨率图像成为当前主要研究热点之一.随着深度学习模型在自然图像超分辨率重建中的成功应用,采用深度学习模型进行医学图像超分辨率重建的研究逐渐开展起来.然而,医学图像与自然图像有本质的区别,其超分辨率重建不仅需要在图像切片平面上进行,还需要在切片之间进行,如
图2 所示.
10.11959/j.issn.2096-0271.2020056.F002 图2 医学图像超分辨率图像示意图(此图部分来自参考[<xref ref-type="bibr" rid="b9">9</xref>] ) ![]()
除了将自然图像中的超分辨率重建模型直接应用到医学图像,Oktay O等人[10 ] 采用深度残差卷积网络从多个2D心脏磁共振(magnetic resonance,MR)图像中重建出3D高分辨率MR图像,提高了层间分辨率.Pham C H等人[11 ] 将SRCNN模型拓展到3D,以实现脑部MR图像的超分辨率重建.McDonagh S等人[12 ] 提出对上下文敏感的残差网络结构,可以得到边界和纹理清晰的高分辨率MR图像.Zheng Y等人[13 ] 提出多个Dense模块和多路分支组合的MR高分辨重建模型,该模型具有较好的重建结果和泛化能力.Zhao X L等人[14 ] 提出通道可分离的脑部MR图像高分辨率重建模型,一个通道采用残差结构,一个通道采用密集连接结构,实现了特征的有效利用,从而提高高分辨率图像的重建质量.Tanno R等人[15 ] 结合3DSubpixelCNN和变分推论实现了磁共振扩散张量图像的超分辨率重建.Peng C等人[16 ] 提出空间感知插值网络(spatially aware interpolation network,SAINT),充分利用不同切面的空间信息提高超分辨率图像的重建质量,该模型在对CT图像进行2倍、4倍和6倍分辨率重建时,均取得了较好的结果.Shi J等人[17 ] 提出一种多尺度全局和局部相结合的残网络(multi-scale global local residual learning,MGLRL)模型,实现了MR图像的超分辨重建,该模型可以增强图像重建细节.Lyu Q等人[18 ] 采用GAN实现了多对比度MR图像的超分辨率重建. ...
... 基于GAN的分割的主要思想是生成器被用来生成初始分割结果,判别器被用来细化分割结果.一般在分割网络中,生成器常采用FCN或者U-Net网络框架,判别器为常见的分类网络结构,如ResNet、VGG等.基于GAN的医学图像分割已经被应用到多个器官和组织的医学图像分割任务中[9 ,92 ] .表2 为常见医学图像分割模型所用的数据集以及其分割性能对比. ...
Multiinput cardiac image super-resolution using convolutional neural networks
1
2016
... 除了将自然图像中的超分辨率重建模型直接应用到医学图像,Oktay O等人[10 ] 采用深度残差卷积网络从多个2D心脏磁共振(magnetic resonance,MR)图像中重建出3D高分辨率MR图像,提高了层间分辨率.Pham C H等人[11 ] 将SRCNN模型拓展到3D,以实现脑部MR图像的超分辨率重建.McDonagh S等人[12 ] 提出对上下文敏感的残差网络结构,可以得到边界和纹理清晰的高分辨率MR图像.Zheng Y等人[13 ] 提出多个Dense模块和多路分支组合的MR高分辨重建模型,该模型具有较好的重建结果和泛化能力.Zhao X L等人[14 ] 提出通道可分离的脑部MR图像高分辨率重建模型,一个通道采用残差结构,一个通道采用密集连接结构,实现了特征的有效利用,从而提高高分辨率图像的重建质量.Tanno R等人[15 ] 结合3DSubpixelCNN和变分推论实现了磁共振扩散张量图像的超分辨率重建.Peng C等人[16 ] 提出空间感知插值网络(spatially aware interpolation network,SAINT),充分利用不同切面的空间信息提高超分辨率图像的重建质量,该模型在对CT图像进行2倍、4倍和6倍分辨率重建时,均取得了较好的结果.Shi J等人[17 ] 提出一种多尺度全局和局部相结合的残网络(multi-scale global local residual learning,MGLRL)模型,实现了MR图像的超分辨重建,该模型可以增强图像重建细节.Lyu Q等人[18 ] 采用GAN实现了多对比度MR图像的超分辨率重建. ...
Multiscale brain MRI super-resolution using deep 3D convolutional networks
1
2019
... 除了将自然图像中的超分辨率重建模型直接应用到医学图像,Oktay O等人[10 ] 采用深度残差卷积网络从多个2D心脏磁共振(magnetic resonance,MR)图像中重建出3D高分辨率MR图像,提高了层间分辨率.Pham C H等人[11 ] 将SRCNN模型拓展到3D,以实现脑部MR图像的超分辨率重建.McDonagh S等人[12 ] 提出对上下文敏感的残差网络结构,可以得到边界和纹理清晰的高分辨率MR图像.Zheng Y等人[13 ] 提出多个Dense模块和多路分支组合的MR高分辨重建模型,该模型具有较好的重建结果和泛化能力.Zhao X L等人[14 ] 提出通道可分离的脑部MR图像高分辨率重建模型,一个通道采用残差结构,一个通道采用密集连接结构,实现了特征的有效利用,从而提高高分辨率图像的重建质量.Tanno R等人[15 ] 结合3DSubpixelCNN和变分推论实现了磁共振扩散张量图像的超分辨率重建.Peng C等人[16 ] 提出空间感知插值网络(spatially aware interpolation network,SAINT),充分利用不同切面的空间信息提高超分辨率图像的重建质量,该模型在对CT图像进行2倍、4倍和6倍分辨率重建时,均取得了较好的结果.Shi J等人[17 ] 提出一种多尺度全局和局部相结合的残网络(multi-scale global local residual learning,MGLRL)模型,实现了MR图像的超分辨重建,该模型可以增强图像重建细节.Lyu Q等人[18 ] 采用GAN实现了多对比度MR图像的超分辨率重建. ...
Context-sensitive super-resolution for fast fetal magnetic resonance imaging
1
2017
... 除了将自然图像中的超分辨率重建模型直接应用到医学图像,Oktay O等人[10 ] 采用深度残差卷积网络从多个2D心脏磁共振(magnetic resonance,MR)图像中重建出3D高分辨率MR图像,提高了层间分辨率.Pham C H等人[11 ] 将SRCNN模型拓展到3D,以实现脑部MR图像的超分辨率重建.McDonagh S等人[12 ] 提出对上下文敏感的残差网络结构,可以得到边界和纹理清晰的高分辨率MR图像.Zheng Y等人[13 ] 提出多个Dense模块和多路分支组合的MR高分辨重建模型,该模型具有较好的重建结果和泛化能力.Zhao X L等人[14 ] 提出通道可分离的脑部MR图像高分辨率重建模型,一个通道采用残差结构,一个通道采用密集连接结构,实现了特征的有效利用,从而提高高分辨率图像的重建质量.Tanno R等人[15 ] 结合3DSubpixelCNN和变分推论实现了磁共振扩散张量图像的超分辨率重建.Peng C等人[16 ] 提出空间感知插值网络(spatially aware interpolation network,SAINT),充分利用不同切面的空间信息提高超分辨率图像的重建质量,该模型在对CT图像进行2倍、4倍和6倍分辨率重建时,均取得了较好的结果.Shi J等人[17 ] 提出一种多尺度全局和局部相结合的残网络(multi-scale global local residual learning,MGLRL)模型,实现了MR图像的超分辨重建,该模型可以增强图像重建细节.Lyu Q等人[18 ] 采用GAN实现了多对比度MR图像的超分辨率重建. ...
A hybrid convolutional neural network for super-resolution reconstruction of MR images
1
2020
... 除了将自然图像中的超分辨率重建模型直接应用到医学图像,Oktay O等人[10 ] 采用深度残差卷积网络从多个2D心脏磁共振(magnetic resonance,MR)图像中重建出3D高分辨率MR图像,提高了层间分辨率.Pham C H等人[11 ] 将SRCNN模型拓展到3D,以实现脑部MR图像的超分辨率重建.McDonagh S等人[12 ] 提出对上下文敏感的残差网络结构,可以得到边界和纹理清晰的高分辨率MR图像.Zheng Y等人[13 ] 提出多个Dense模块和多路分支组合的MR高分辨重建模型,该模型具有较好的重建结果和泛化能力.Zhao X L等人[14 ] 提出通道可分离的脑部MR图像高分辨率重建模型,一个通道采用残差结构,一个通道采用密集连接结构,实现了特征的有效利用,从而提高高分辨率图像的重建质量.Tanno R等人[15 ] 结合3DSubpixelCNN和变分推论实现了磁共振扩散张量图像的超分辨率重建.Peng C等人[16 ] 提出空间感知插值网络(spatially aware interpolation network,SAINT),充分利用不同切面的空间信息提高超分辨率图像的重建质量,该模型在对CT图像进行2倍、4倍和6倍分辨率重建时,均取得了较好的结果.Shi J等人[17 ] 提出一种多尺度全局和局部相结合的残网络(multi-scale global local residual learning,MGLRL)模型,实现了MR图像的超分辨重建,该模型可以增强图像重建细节.Lyu Q等人[18 ] 采用GAN实现了多对比度MR图像的超分辨率重建. ...
Channel splitting network for single MR image super-resolution
1
2019
... 除了将自然图像中的超分辨率重建模型直接应用到医学图像,Oktay O等人[10 ] 采用深度残差卷积网络从多个2D心脏磁共振(magnetic resonance,MR)图像中重建出3D高分辨率MR图像,提高了层间分辨率.Pham C H等人[11 ] 将SRCNN模型拓展到3D,以实现脑部MR图像的超分辨率重建.McDonagh S等人[12 ] 提出对上下文敏感的残差网络结构,可以得到边界和纹理清晰的高分辨率MR图像.Zheng Y等人[13 ] 提出多个Dense模块和多路分支组合的MR高分辨重建模型,该模型具有较好的重建结果和泛化能力.Zhao X L等人[14 ] 提出通道可分离的脑部MR图像高分辨率重建模型,一个通道采用残差结构,一个通道采用密集连接结构,实现了特征的有效利用,从而提高高分辨率图像的重建质量.Tanno R等人[15 ] 结合3DSubpixelCNN和变分推论实现了磁共振扩散张量图像的超分辨率重建.Peng C等人[16 ] 提出空间感知插值网络(spatially aware interpolation network,SAINT),充分利用不同切面的空间信息提高超分辨率图像的重建质量,该模型在对CT图像进行2倍、4倍和6倍分辨率重建时,均取得了较好的结果.Shi J等人[17 ] 提出一种多尺度全局和局部相结合的残网络(multi-scale global local residual learning,MGLRL)模型,实现了MR图像的超分辨重建,该模型可以增强图像重建细节.Lyu Q等人[18 ] 采用GAN实现了多对比度MR图像的超分辨率重建. ...
Bayesian image quality transfer with CNNs:exploring uncertainty in dMRI super-resolution
1
2017
... 除了将自然图像中的超分辨率重建模型直接应用到医学图像,Oktay O等人[10 ] 采用深度残差卷积网络从多个2D心脏磁共振(magnetic resonance,MR)图像中重建出3D高分辨率MR图像,提高了层间分辨率.Pham C H等人[11 ] 将SRCNN模型拓展到3D,以实现脑部MR图像的超分辨率重建.McDonagh S等人[12 ] 提出对上下文敏感的残差网络结构,可以得到边界和纹理清晰的高分辨率MR图像.Zheng Y等人[13 ] 提出多个Dense模块和多路分支组合的MR高分辨重建模型,该模型具有较好的重建结果和泛化能力.Zhao X L等人[14 ] 提出通道可分离的脑部MR图像高分辨率重建模型,一个通道采用残差结构,一个通道采用密集连接结构,实现了特征的有效利用,从而提高高分辨率图像的重建质量.Tanno R等人[15 ] 结合3DSubpixelCNN和变分推论实现了磁共振扩散张量图像的超分辨率重建.Peng C等人[16 ] 提出空间感知插值网络(spatially aware interpolation network,SAINT),充分利用不同切面的空间信息提高超分辨率图像的重建质量,该模型在对CT图像进行2倍、4倍和6倍分辨率重建时,均取得了较好的结果.Shi J等人[17 ] 提出一种多尺度全局和局部相结合的残网络(multi-scale global local residual learning,MGLRL)模型,实现了MR图像的超分辨重建,该模型可以增强图像重建细节.Lyu Q等人[18 ] 采用GAN实现了多对比度MR图像的超分辨率重建. ...
SAINT:spatially aware interpolation network for medical slice synthesis
1
2020
... 除了将自然图像中的超分辨率重建模型直接应用到医学图像,Oktay O等人[10 ] 采用深度残差卷积网络从多个2D心脏磁共振(magnetic resonance,MR)图像中重建出3D高分辨率MR图像,提高了层间分辨率.Pham C H等人[11 ] 将SRCNN模型拓展到3D,以实现脑部MR图像的超分辨率重建.McDonagh S等人[12 ] 提出对上下文敏感的残差网络结构,可以得到边界和纹理清晰的高分辨率MR图像.Zheng Y等人[13 ] 提出多个Dense模块和多路分支组合的MR高分辨重建模型,该模型具有较好的重建结果和泛化能力.Zhao X L等人[14 ] 提出通道可分离的脑部MR图像高分辨率重建模型,一个通道采用残差结构,一个通道采用密集连接结构,实现了特征的有效利用,从而提高高分辨率图像的重建质量.Tanno R等人[15 ] 结合3DSubpixelCNN和变分推论实现了磁共振扩散张量图像的超分辨率重建.Peng C等人[16 ] 提出空间感知插值网络(spatially aware interpolation network,SAINT),充分利用不同切面的空间信息提高超分辨率图像的重建质量,该模型在对CT图像进行2倍、4倍和6倍分辨率重建时,均取得了较好的结果.Shi J等人[17 ] 提出一种多尺度全局和局部相结合的残网络(multi-scale global local residual learning,MGLRL)模型,实现了MR图像的超分辨重建,该模型可以增强图像重建细节.Lyu Q等人[18 ] 采用GAN实现了多对比度MR图像的超分辨率重建. ...
Superresolution reconstruction of MR image with a novel residual learning network algorithm
1
2018
... 除了将自然图像中的超分辨率重建模型直接应用到医学图像,Oktay O等人[10 ] 采用深度残差卷积网络从多个2D心脏磁共振(magnetic resonance,MR)图像中重建出3D高分辨率MR图像,提高了层间分辨率.Pham C H等人[11 ] 将SRCNN模型拓展到3D,以实现脑部MR图像的超分辨率重建.McDonagh S等人[12 ] 提出对上下文敏感的残差网络结构,可以得到边界和纹理清晰的高分辨率MR图像.Zheng Y等人[13 ] 提出多个Dense模块和多路分支组合的MR高分辨重建模型,该模型具有较好的重建结果和泛化能力.Zhao X L等人[14 ] 提出通道可分离的脑部MR图像高分辨率重建模型,一个通道采用残差结构,一个通道采用密集连接结构,实现了特征的有效利用,从而提高高分辨率图像的重建质量.Tanno R等人[15 ] 结合3DSubpixelCNN和变分推论实现了磁共振扩散张量图像的超分辨率重建.Peng C等人[16 ] 提出空间感知插值网络(spatially aware interpolation network,SAINT),充分利用不同切面的空间信息提高超分辨率图像的重建质量,该模型在对CT图像进行2倍、4倍和6倍分辨率重建时,均取得了较好的结果.Shi J等人[17 ] 提出一种多尺度全局和局部相结合的残网络(multi-scale global local residual learning,MGLRL)模型,实现了MR图像的超分辨重建,该模型可以增强图像重建细节.Lyu Q等人[18 ] 采用GAN实现了多对比度MR图像的超分辨率重建. ...
Multi-contrast super-resolution MRI through a progressive network
1
2020
... 除了将自然图像中的超分辨率重建模型直接应用到医学图像,Oktay O等人[10 ] 采用深度残差卷积网络从多个2D心脏磁共振(magnetic resonance,MR)图像中重建出3D高分辨率MR图像,提高了层间分辨率.Pham C H等人[11 ] 将SRCNN模型拓展到3D,以实现脑部MR图像的超分辨率重建.McDonagh S等人[12 ] 提出对上下文敏感的残差网络结构,可以得到边界和纹理清晰的高分辨率MR图像.Zheng Y等人[13 ] 提出多个Dense模块和多路分支组合的MR高分辨重建模型,该模型具有较好的重建结果和泛化能力.Zhao X L等人[14 ] 提出通道可分离的脑部MR图像高分辨率重建模型,一个通道采用残差结构,一个通道采用密集连接结构,实现了特征的有效利用,从而提高高分辨率图像的重建质量.Tanno R等人[15 ] 结合3DSubpixelCNN和变分推论实现了磁共振扩散张量图像的超分辨率重建.Peng C等人[16 ] 提出空间感知插值网络(spatially aware interpolation network,SAINT),充分利用不同切面的空间信息提高超分辨率图像的重建质量,该模型在对CT图像进行2倍、4倍和6倍分辨率重建时,均取得了较好的结果.Shi J等人[17 ] 提出一种多尺度全局和局部相结合的残网络(multi-scale global local residual learning,MGLRL)模型,实现了MR图像的超分辨重建,该模型可以增强图像重建细节.Lyu Q等人[18 ] 采用GAN实现了多对比度MR图像的超分辨率重建. ...
ADMMCSNet:a deep learning approach for image compressive sensing
1
2020
... 目前采用深度学习模型进行医学图像重建的方法主要分为两类:一类是从原始数据直接到图像的重建,另一类是基于后处理的方式提高重建图像的质量.第一类方法的代表模型有:ADMM-Net[19 ] ,其用深度迭代的方式学习传统交替方向乘子(alternating direction method of multipliers,ADMM)优化算法中的超参数,可以直接从欠采样的K空间数据中重构出MR图像;Adler J等人[20 ] 提出对偶学习模型,用其代替CT重建中的滤波反投影方法,实现了投影数据到CT图像的准确重建;Cheng J等人[21 ] 在此基础上提出原始-对偶网络(primal-dual network, PD-Net),实现了MR图像的快速重建;Zhang H M等人[22 ] 提出JSR-Net(joint spatial-Radon domain reconstruction net),利用深度卷积神经网络模型,同时重建CT图像及其对应的Radon投影变换图像,得到了比PD-Net更好的重建结果.第二类方法是目前主要的重建方式,即采用图像去伪影的后处理模型进行重建.用于图像降噪、超分辨重建的模型都可以用于该类型的图像重建,如Lee D等人[23 ] 提出带有残差模块的U-Net模型结构来学习重建图像与原始欠采样图像之间的伪影;随后,他们又提出利用双路U-Net模型对相位图像和幅度图像进行重建,进而提高了MR图像的重建质量[24 ] ;Schlemper J等人[25 ] 采用深度级联的卷积神经网络(convolutional neural network,CNN)模型,学习动态MR图像采集的时序关系,进而在快速采集下提高动态MR图像的重建质量;Han Y等人[26 ] 采用域适应微调方法,将CT图像重建的网络应用到MR图像重建上,可以实现高采样率下的准确重建;Eo T等人[27 ] 提出KIKI-Net,同时在K空间和图像空间域上使用深度学习网络进行重建,提高了MR图像重建的性能;Bao L J等人[28 ] 采用一个增强递归残差网络,结合残差块和密集块的连接,用复数图像进行训练,得到了较好的MR图像重建结果;Dai Y X等人[29 ] 基于多尺度空洞卷积设计深度残差卷积网络,以较少的网络参数提高了MR图像的重建精度;受到GAN在视觉领域成功应用的启发,Yang G等人[30 ] 提出一种深度去混叠生成对抗网络(DAGAN),以消除MRI重建过程中的混叠伪影;Quan T M等人[31 ] 提出一种具有周期性损失的RefinGAN模型,以极低的采样率提高了MR图像的重建精度;Mardani M等人[32 ] 基于LS-GAN损失,采用ResNet的生成器和鉴别器来重建MR图像,获得了较好的可视化结果. ...
Learned primaldual reconstruction
1
2018
... 目前采用深度学习模型进行医学图像重建的方法主要分为两类:一类是从原始数据直接到图像的重建,另一类是基于后处理的方式提高重建图像的质量.第一类方法的代表模型有:ADMM-Net[19 ] ,其用深度迭代的方式学习传统交替方向乘子(alternating direction method of multipliers,ADMM)优化算法中的超参数,可以直接从欠采样的K空间数据中重构出MR图像;Adler J等人[20 ] 提出对偶学习模型,用其代替CT重建中的滤波反投影方法,实现了投影数据到CT图像的准确重建;Cheng J等人[21 ] 在此基础上提出原始-对偶网络(primal-dual network, PD-Net),实现了MR图像的快速重建;Zhang H M等人[22 ] 提出JSR-Net(joint spatial-Radon domain reconstruction net),利用深度卷积神经网络模型,同时重建CT图像及其对应的Radon投影变换图像,得到了比PD-Net更好的重建结果.第二类方法是目前主要的重建方式,即采用图像去伪影的后处理模型进行重建.用于图像降噪、超分辨重建的模型都可以用于该类型的图像重建,如Lee D等人[23 ] 提出带有残差模块的U-Net模型结构来学习重建图像与原始欠采样图像之间的伪影;随后,他们又提出利用双路U-Net模型对相位图像和幅度图像进行重建,进而提高了MR图像的重建质量[24 ] ;Schlemper J等人[25 ] 采用深度级联的卷积神经网络(convolutional neural network,CNN)模型,学习动态MR图像采集的时序关系,进而在快速采集下提高动态MR图像的重建质量;Han Y等人[26 ] 采用域适应微调方法,将CT图像重建的网络应用到MR图像重建上,可以实现高采样率下的准确重建;Eo T等人[27 ] 提出KIKI-Net,同时在K空间和图像空间域上使用深度学习网络进行重建,提高了MR图像重建的性能;Bao L J等人[28 ] 采用一个增强递归残差网络,结合残差块和密集块的连接,用复数图像进行训练,得到了较好的MR图像重建结果;Dai Y X等人[29 ] 基于多尺度空洞卷积设计深度残差卷积网络,以较少的网络参数提高了MR图像的重建精度;受到GAN在视觉领域成功应用的启发,Yang G等人[30 ] 提出一种深度去混叠生成对抗网络(DAGAN),以消除MRI重建过程中的混叠伪影;Quan T M等人[31 ] 提出一种具有周期性损失的RefinGAN模型,以极低的采样率提高了MR图像的重建精度;Mardani M等人[32 ] 基于LS-GAN损失,采用ResNet的生成器和鉴别器来重建MR图像,获得了较好的可视化结果. ...
Model learning:primal dual networks for fast MR imaging
1
2019
... 目前采用深度学习模型进行医学图像重建的方法主要分为两类:一类是从原始数据直接到图像的重建,另一类是基于后处理的方式提高重建图像的质量.第一类方法的代表模型有:ADMM-Net[19 ] ,其用深度迭代的方式学习传统交替方向乘子(alternating direction method of multipliers,ADMM)优化算法中的超参数,可以直接从欠采样的K空间数据中重构出MR图像;Adler J等人[20 ] 提出对偶学习模型,用其代替CT重建中的滤波反投影方法,实现了投影数据到CT图像的准确重建;Cheng J等人[21 ] 在此基础上提出原始-对偶网络(primal-dual network, PD-Net),实现了MR图像的快速重建;Zhang H M等人[22 ] 提出JSR-Net(joint spatial-Radon domain reconstruction net),利用深度卷积神经网络模型,同时重建CT图像及其对应的Radon投影变换图像,得到了比PD-Net更好的重建结果.第二类方法是目前主要的重建方式,即采用图像去伪影的后处理模型进行重建.用于图像降噪、超分辨重建的模型都可以用于该类型的图像重建,如Lee D等人[23 ] 提出带有残差模块的U-Net模型结构来学习重建图像与原始欠采样图像之间的伪影;随后,他们又提出利用双路U-Net模型对相位图像和幅度图像进行重建,进而提高了MR图像的重建质量[24 ] ;Schlemper J等人[25 ] 采用深度级联的卷积神经网络(convolutional neural network,CNN)模型,学习动态MR图像采集的时序关系,进而在快速采集下提高动态MR图像的重建质量;Han Y等人[26 ] 采用域适应微调方法,将CT图像重建的网络应用到MR图像重建上,可以实现高采样率下的准确重建;Eo T等人[27 ] 提出KIKI-Net,同时在K空间和图像空间域上使用深度学习网络进行重建,提高了MR图像重建的性能;Bao L J等人[28 ] 采用一个增强递归残差网络,结合残差块和密集块的连接,用复数图像进行训练,得到了较好的MR图像重建结果;Dai Y X等人[29 ] 基于多尺度空洞卷积设计深度残差卷积网络,以较少的网络参数提高了MR图像的重建精度;受到GAN在视觉领域成功应用的启发,Yang G等人[30 ] 提出一种深度去混叠生成对抗网络(DAGAN),以消除MRI重建过程中的混叠伪影;Quan T M等人[31 ] 提出一种具有周期性损失的RefinGAN模型,以极低的采样率提高了MR图像的重建精度;Mardani M等人[32 ] 基于LS-GAN损失,采用ResNet的生成器和鉴别器来重建MR图像,获得了较好的可视化结果. ...
JSRNet:a deep network for joint spatial-radon domain CT reconstruction from incomplete data
1
2019
... 目前采用深度学习模型进行医学图像重建的方法主要分为两类:一类是从原始数据直接到图像的重建,另一类是基于后处理的方式提高重建图像的质量.第一类方法的代表模型有:ADMM-Net[19 ] ,其用深度迭代的方式学习传统交替方向乘子(alternating direction method of multipliers,ADMM)优化算法中的超参数,可以直接从欠采样的K空间数据中重构出MR图像;Adler J等人[20 ] 提出对偶学习模型,用其代替CT重建中的滤波反投影方法,实现了投影数据到CT图像的准确重建;Cheng J等人[21 ] 在此基础上提出原始-对偶网络(primal-dual network, PD-Net),实现了MR图像的快速重建;Zhang H M等人[22 ] 提出JSR-Net(joint spatial-Radon domain reconstruction net),利用深度卷积神经网络模型,同时重建CT图像及其对应的Radon投影变换图像,得到了比PD-Net更好的重建结果.第二类方法是目前主要的重建方式,即采用图像去伪影的后处理模型进行重建.用于图像降噪、超分辨重建的模型都可以用于该类型的图像重建,如Lee D等人[23 ] 提出带有残差模块的U-Net模型结构来学习重建图像与原始欠采样图像之间的伪影;随后,他们又提出利用双路U-Net模型对相位图像和幅度图像进行重建,进而提高了MR图像的重建质量[24 ] ;Schlemper J等人[25 ] 采用深度级联的卷积神经网络(convolutional neural network,CNN)模型,学习动态MR图像采集的时序关系,进而在快速采集下提高动态MR图像的重建质量;Han Y等人[26 ] 采用域适应微调方法,将CT图像重建的网络应用到MR图像重建上,可以实现高采样率下的准确重建;Eo T等人[27 ] 提出KIKI-Net,同时在K空间和图像空间域上使用深度学习网络进行重建,提高了MR图像重建的性能;Bao L J等人[28 ] 采用一个增强递归残差网络,结合残差块和密集块的连接,用复数图像进行训练,得到了较好的MR图像重建结果;Dai Y X等人[29 ] 基于多尺度空洞卷积设计深度残差卷积网络,以较少的网络参数提高了MR图像的重建精度;受到GAN在视觉领域成功应用的启发,Yang G等人[30 ] 提出一种深度去混叠生成对抗网络(DAGAN),以消除MRI重建过程中的混叠伪影;Quan T M等人[31 ] 提出一种具有周期性损失的RefinGAN模型,以极低的采样率提高了MR图像的重建精度;Mardani M等人[32 ] 基于LS-GAN损失,采用ResNet的生成器和鉴别器来重建MR图像,获得了较好的可视化结果. ...
Deep residual learning for compressed sensing MRI
1
2017
... 目前采用深度学习模型进行医学图像重建的方法主要分为两类:一类是从原始数据直接到图像的重建,另一类是基于后处理的方式提高重建图像的质量.第一类方法的代表模型有:ADMM-Net[19 ] ,其用深度迭代的方式学习传统交替方向乘子(alternating direction method of multipliers,ADMM)优化算法中的超参数,可以直接从欠采样的K空间数据中重构出MR图像;Adler J等人[20 ] 提出对偶学习模型,用其代替CT重建中的滤波反投影方法,实现了投影数据到CT图像的准确重建;Cheng J等人[21 ] 在此基础上提出原始-对偶网络(primal-dual network, PD-Net),实现了MR图像的快速重建;Zhang H M等人[22 ] 提出JSR-Net(joint spatial-Radon domain reconstruction net),利用深度卷积神经网络模型,同时重建CT图像及其对应的Radon投影变换图像,得到了比PD-Net更好的重建结果.第二类方法是目前主要的重建方式,即采用图像去伪影的后处理模型进行重建.用于图像降噪、超分辨重建的模型都可以用于该类型的图像重建,如Lee D等人[23 ] 提出带有残差模块的U-Net模型结构来学习重建图像与原始欠采样图像之间的伪影;随后,他们又提出利用双路U-Net模型对相位图像和幅度图像进行重建,进而提高了MR图像的重建质量[24 ] ;Schlemper J等人[25 ] 采用深度级联的卷积神经网络(convolutional neural network,CNN)模型,学习动态MR图像采集的时序关系,进而在快速采集下提高动态MR图像的重建质量;Han Y等人[26 ] 采用域适应微调方法,将CT图像重建的网络应用到MR图像重建上,可以实现高采样率下的准确重建;Eo T等人[27 ] 提出KIKI-Net,同时在K空间和图像空间域上使用深度学习网络进行重建,提高了MR图像重建的性能;Bao L J等人[28 ] 采用一个增强递归残差网络,结合残差块和密集块的连接,用复数图像进行训练,得到了较好的MR图像重建结果;Dai Y X等人[29 ] 基于多尺度空洞卷积设计深度残差卷积网络,以较少的网络参数提高了MR图像的重建精度;受到GAN在视觉领域成功应用的启发,Yang G等人[30 ] 提出一种深度去混叠生成对抗网络(DAGAN),以消除MRI重建过程中的混叠伪影;Quan T M等人[31 ] 提出一种具有周期性损失的RefinGAN模型,以极低的采样率提高了MR图像的重建精度;Mardani M等人[32 ] 基于LS-GAN损失,采用ResNet的生成器和鉴别器来重建MR图像,获得了较好的可视化结果. ...
Deep residual learning for accelerated MRI using magnitude and phase networks
1
2018
... 目前采用深度学习模型进行医学图像重建的方法主要分为两类:一类是从原始数据直接到图像的重建,另一类是基于后处理的方式提高重建图像的质量.第一类方法的代表模型有:ADMM-Net[19 ] ,其用深度迭代的方式学习传统交替方向乘子(alternating direction method of multipliers,ADMM)优化算法中的超参数,可以直接从欠采样的K空间数据中重构出MR图像;Adler J等人[20 ] 提出对偶学习模型,用其代替CT重建中的滤波反投影方法,实现了投影数据到CT图像的准确重建;Cheng J等人[21 ] 在此基础上提出原始-对偶网络(primal-dual network, PD-Net),实现了MR图像的快速重建;Zhang H M等人[22 ] 提出JSR-Net(joint spatial-Radon domain reconstruction net),利用深度卷积神经网络模型,同时重建CT图像及其对应的Radon投影变换图像,得到了比PD-Net更好的重建结果.第二类方法是目前主要的重建方式,即采用图像去伪影的后处理模型进行重建.用于图像降噪、超分辨重建的模型都可以用于该类型的图像重建,如Lee D等人[23 ] 提出带有残差模块的U-Net模型结构来学习重建图像与原始欠采样图像之间的伪影;随后,他们又提出利用双路U-Net模型对相位图像和幅度图像进行重建,进而提高了MR图像的重建质量[24 ] ;Schlemper J等人[25 ] 采用深度级联的卷积神经网络(convolutional neural network,CNN)模型,学习动态MR图像采集的时序关系,进而在快速采集下提高动态MR图像的重建质量;Han Y等人[26 ] 采用域适应微调方法,将CT图像重建的网络应用到MR图像重建上,可以实现高采样率下的准确重建;Eo T等人[27 ] 提出KIKI-Net,同时在K空间和图像空间域上使用深度学习网络进行重建,提高了MR图像重建的性能;Bao L J等人[28 ] 采用一个增强递归残差网络,结合残差块和密集块的连接,用复数图像进行训练,得到了较好的MR图像重建结果;Dai Y X等人[29 ] 基于多尺度空洞卷积设计深度残差卷积网络,以较少的网络参数提高了MR图像的重建精度;受到GAN在视觉领域成功应用的启发,Yang G等人[30 ] 提出一种深度去混叠生成对抗网络(DAGAN),以消除MRI重建过程中的混叠伪影;Quan T M等人[31 ] 提出一种具有周期性损失的RefinGAN模型,以极低的采样率提高了MR图像的重建精度;Mardani M等人[32 ] 基于LS-GAN损失,采用ResNet的生成器和鉴别器来重建MR图像,获得了较好的可视化结果. ...
A deep cascade of convolutional neural networks for dynamic MR image reconstruction
1
2017
... 目前采用深度学习模型进行医学图像重建的方法主要分为两类:一类是从原始数据直接到图像的重建,另一类是基于后处理的方式提高重建图像的质量.第一类方法的代表模型有:ADMM-Net[19 ] ,其用深度迭代的方式学习传统交替方向乘子(alternating direction method of multipliers,ADMM)优化算法中的超参数,可以直接从欠采样的K空间数据中重构出MR图像;Adler J等人[20 ] 提出对偶学习模型,用其代替CT重建中的滤波反投影方法,实现了投影数据到CT图像的准确重建;Cheng J等人[21 ] 在此基础上提出原始-对偶网络(primal-dual network, PD-Net),实现了MR图像的快速重建;Zhang H M等人[22 ] 提出JSR-Net(joint spatial-Radon domain reconstruction net),利用深度卷积神经网络模型,同时重建CT图像及其对应的Radon投影变换图像,得到了比PD-Net更好的重建结果.第二类方法是目前主要的重建方式,即采用图像去伪影的后处理模型进行重建.用于图像降噪、超分辨重建的模型都可以用于该类型的图像重建,如Lee D等人[23 ] 提出带有残差模块的U-Net模型结构来学习重建图像与原始欠采样图像之间的伪影;随后,他们又提出利用双路U-Net模型对相位图像和幅度图像进行重建,进而提高了MR图像的重建质量[24 ] ;Schlemper J等人[25 ] 采用深度级联的卷积神经网络(convolutional neural network,CNN)模型,学习动态MR图像采集的时序关系,进而在快速采集下提高动态MR图像的重建质量;Han Y等人[26 ] 采用域适应微调方法,将CT图像重建的网络应用到MR图像重建上,可以实现高采样率下的准确重建;Eo T等人[27 ] 提出KIKI-Net,同时在K空间和图像空间域上使用深度学习网络进行重建,提高了MR图像重建的性能;Bao L J等人[28 ] 采用一个增强递归残差网络,结合残差块和密集块的连接,用复数图像进行训练,得到了较好的MR图像重建结果;Dai Y X等人[29 ] 基于多尺度空洞卷积设计深度残差卷积网络,以较少的网络参数提高了MR图像的重建精度;受到GAN在视觉领域成功应用的启发,Yang G等人[30 ] 提出一种深度去混叠生成对抗网络(DAGAN),以消除MRI重建过程中的混叠伪影;Quan T M等人[31 ] 提出一种具有周期性损失的RefinGAN模型,以极低的采样率提高了MR图像的重建精度;Mardani M等人[32 ] 基于LS-GAN损失,采用ResNet的生成器和鉴别器来重建MR图像,获得了较好的可视化结果. ...
Deep learning with domain adaptation for accelerated projection‐reconstruction MR
1
2018
... 目前采用深度学习模型进行医学图像重建的方法主要分为两类:一类是从原始数据直接到图像的重建,另一类是基于后处理的方式提高重建图像的质量.第一类方法的代表模型有:ADMM-Net[19 ] ,其用深度迭代的方式学习传统交替方向乘子(alternating direction method of multipliers,ADMM)优化算法中的超参数,可以直接从欠采样的K空间数据中重构出MR图像;Adler J等人[20 ] 提出对偶学习模型,用其代替CT重建中的滤波反投影方法,实现了投影数据到CT图像的准确重建;Cheng J等人[21 ] 在此基础上提出原始-对偶网络(primal-dual network, PD-Net),实现了MR图像的快速重建;Zhang H M等人[22 ] 提出JSR-Net(joint spatial-Radon domain reconstruction net),利用深度卷积神经网络模型,同时重建CT图像及其对应的Radon投影变换图像,得到了比PD-Net更好的重建结果.第二类方法是目前主要的重建方式,即采用图像去伪影的后处理模型进行重建.用于图像降噪、超分辨重建的模型都可以用于该类型的图像重建,如Lee D等人[23 ] 提出带有残差模块的U-Net模型结构来学习重建图像与原始欠采样图像之间的伪影;随后,他们又提出利用双路U-Net模型对相位图像和幅度图像进行重建,进而提高了MR图像的重建质量[24 ] ;Schlemper J等人[25 ] 采用深度级联的卷积神经网络(convolutional neural network,CNN)模型,学习动态MR图像采集的时序关系,进而在快速采集下提高动态MR图像的重建质量;Han Y等人[26 ] 采用域适应微调方法,将CT图像重建的网络应用到MR图像重建上,可以实现高采样率下的准确重建;Eo T等人[27 ] 提出KIKI-Net,同时在K空间和图像空间域上使用深度学习网络进行重建,提高了MR图像重建的性能;Bao L J等人[28 ] 采用一个增强递归残差网络,结合残差块和密集块的连接,用复数图像进行训练,得到了较好的MR图像重建结果;Dai Y X等人[29 ] 基于多尺度空洞卷积设计深度残差卷积网络,以较少的网络参数提高了MR图像的重建精度;受到GAN在视觉领域成功应用的启发,Yang G等人[30 ] 提出一种深度去混叠生成对抗网络(DAGAN),以消除MRI重建过程中的混叠伪影;Quan T M等人[31 ] 提出一种具有周期性损失的RefinGAN模型,以极低的采样率提高了MR图像的重建精度;Mardani M等人[32 ] 基于LS-GAN损失,采用ResNet的生成器和鉴别器来重建MR图像,获得了较好的可视化结果. ...
KIKI‐Net:cross‐domain convolutional neural networks for reconstructing undersampled magnetic resonance images
1
2018
... 目前采用深度学习模型进行医学图像重建的方法主要分为两类:一类是从原始数据直接到图像的重建,另一类是基于后处理的方式提高重建图像的质量.第一类方法的代表模型有:ADMM-Net[19 ] ,其用深度迭代的方式学习传统交替方向乘子(alternating direction method of multipliers,ADMM)优化算法中的超参数,可以直接从欠采样的K空间数据中重构出MR图像;Adler J等人[20 ] 提出对偶学习模型,用其代替CT重建中的滤波反投影方法,实现了投影数据到CT图像的准确重建;Cheng J等人[21 ] 在此基础上提出原始-对偶网络(primal-dual network, PD-Net),实现了MR图像的快速重建;Zhang H M等人[22 ] 提出JSR-Net(joint spatial-Radon domain reconstruction net),利用深度卷积神经网络模型,同时重建CT图像及其对应的Radon投影变换图像,得到了比PD-Net更好的重建结果.第二类方法是目前主要的重建方式,即采用图像去伪影的后处理模型进行重建.用于图像降噪、超分辨重建的模型都可以用于该类型的图像重建,如Lee D等人[23 ] 提出带有残差模块的U-Net模型结构来学习重建图像与原始欠采样图像之间的伪影;随后,他们又提出利用双路U-Net模型对相位图像和幅度图像进行重建,进而提高了MR图像的重建质量[24 ] ;Schlemper J等人[25 ] 采用深度级联的卷积神经网络(convolutional neural network,CNN)模型,学习动态MR图像采集的时序关系,进而在快速采集下提高动态MR图像的重建质量;Han Y等人[26 ] 采用域适应微调方法,将CT图像重建的网络应用到MR图像重建上,可以实现高采样率下的准确重建;Eo T等人[27 ] 提出KIKI-Net,同时在K空间和图像空间域上使用深度学习网络进行重建,提高了MR图像重建的性能;Bao L J等人[28 ] 采用一个增强递归残差网络,结合残差块和密集块的连接,用复数图像进行训练,得到了较好的MR图像重建结果;Dai Y X等人[29 ] 基于多尺度空洞卷积设计深度残差卷积网络,以较少的网络参数提高了MR图像的重建精度;受到GAN在视觉领域成功应用的启发,Yang G等人[30 ] 提出一种深度去混叠生成对抗网络(DAGAN),以消除MRI重建过程中的混叠伪影;Quan T M等人[31 ] 提出一种具有周期性损失的RefinGAN模型,以极低的采样率提高了MR图像的重建精度;Mardani M等人[32 ] 基于LS-GAN损失,采用ResNet的生成器和鉴别器来重建MR图像,获得了较好的可视化结果. ...
Undersampled MR image reconstruction using an enhanced recursive residual network
1
2019
... 目前采用深度学习模型进行医学图像重建的方法主要分为两类:一类是从原始数据直接到图像的重建,另一类是基于后处理的方式提高重建图像的质量.第一类方法的代表模型有:ADMM-Net[19 ] ,其用深度迭代的方式学习传统交替方向乘子(alternating direction method of multipliers,ADMM)优化算法中的超参数,可以直接从欠采样的K空间数据中重构出MR图像;Adler J等人[20 ] 提出对偶学习模型,用其代替CT重建中的滤波反投影方法,实现了投影数据到CT图像的准确重建;Cheng J等人[21 ] 在此基础上提出原始-对偶网络(primal-dual network, PD-Net),实现了MR图像的快速重建;Zhang H M等人[22 ] 提出JSR-Net(joint spatial-Radon domain reconstruction net),利用深度卷积神经网络模型,同时重建CT图像及其对应的Radon投影变换图像,得到了比PD-Net更好的重建结果.第二类方法是目前主要的重建方式,即采用图像去伪影的后处理模型进行重建.用于图像降噪、超分辨重建的模型都可以用于该类型的图像重建,如Lee D等人[23 ] 提出带有残差模块的U-Net模型结构来学习重建图像与原始欠采样图像之间的伪影;随后,他们又提出利用双路U-Net模型对相位图像和幅度图像进行重建,进而提高了MR图像的重建质量[24 ] ;Schlemper J等人[25 ] 采用深度级联的卷积神经网络(convolutional neural network,CNN)模型,学习动态MR图像采集的时序关系,进而在快速采集下提高动态MR图像的重建质量;Han Y等人[26 ] 采用域适应微调方法,将CT图像重建的网络应用到MR图像重建上,可以实现高采样率下的准确重建;Eo T等人[27 ] 提出KIKI-Net,同时在K空间和图像空间域上使用深度学习网络进行重建,提高了MR图像重建的性能;Bao L J等人[28 ] 采用一个增强递归残差网络,结合残差块和密集块的连接,用复数图像进行训练,得到了较好的MR图像重建结果;Dai Y X等人[29 ] 基于多尺度空洞卷积设计深度残差卷积网络,以较少的网络参数提高了MR图像的重建精度;受到GAN在视觉领域成功应用的启发,Yang G等人[30 ] 提出一种深度去混叠生成对抗网络(DAGAN),以消除MRI重建过程中的混叠伪影;Quan T M等人[31 ] 提出一种具有周期性损失的RefinGAN模型,以极低的采样率提高了MR图像的重建精度;Mardani M等人[32 ] 基于LS-GAN损失,采用ResNet的生成器和鉴别器来重建MR图像,获得了较好的可视化结果. ...
Compressed sensing MRI via a multi-scale dilated residual convolution network
1
2019
... 目前采用深度学习模型进行医学图像重建的方法主要分为两类:一类是从原始数据直接到图像的重建,另一类是基于后处理的方式提高重建图像的质量.第一类方法的代表模型有:ADMM-Net[19 ] ,其用深度迭代的方式学习传统交替方向乘子(alternating direction method of multipliers,ADMM)优化算法中的超参数,可以直接从欠采样的K空间数据中重构出MR图像;Adler J等人[20 ] 提出对偶学习模型,用其代替CT重建中的滤波反投影方法,实现了投影数据到CT图像的准确重建;Cheng J等人[21 ] 在此基础上提出原始-对偶网络(primal-dual network, PD-Net),实现了MR图像的快速重建;Zhang H M等人[22 ] 提出JSR-Net(joint spatial-Radon domain reconstruction net),利用深度卷积神经网络模型,同时重建CT图像及其对应的Radon投影变换图像,得到了比PD-Net更好的重建结果.第二类方法是目前主要的重建方式,即采用图像去伪影的后处理模型进行重建.用于图像降噪、超分辨重建的模型都可以用于该类型的图像重建,如Lee D等人[23 ] 提出带有残差模块的U-Net模型结构来学习重建图像与原始欠采样图像之间的伪影;随后,他们又提出利用双路U-Net模型对相位图像和幅度图像进行重建,进而提高了MR图像的重建质量[24 ] ;Schlemper J等人[25 ] 采用深度级联的卷积神经网络(convolutional neural network,CNN)模型,学习动态MR图像采集的时序关系,进而在快速采集下提高动态MR图像的重建质量;Han Y等人[26 ] 采用域适应微调方法,将CT图像重建的网络应用到MR图像重建上,可以实现高采样率下的准确重建;Eo T等人[27 ] 提出KIKI-Net,同时在K空间和图像空间域上使用深度学习网络进行重建,提高了MR图像重建的性能;Bao L J等人[28 ] 采用一个增强递归残差网络,结合残差块和密集块的连接,用复数图像进行训练,得到了较好的MR图像重建结果;Dai Y X等人[29 ] 基于多尺度空洞卷积设计深度残差卷积网络,以较少的网络参数提高了MR图像的重建精度;受到GAN在视觉领域成功应用的启发,Yang G等人[30 ] 提出一种深度去混叠生成对抗网络(DAGAN),以消除MRI重建过程中的混叠伪影;Quan T M等人[31 ] 提出一种具有周期性损失的RefinGAN模型,以极低的采样率提高了MR图像的重建精度;Mardani M等人[32 ] 基于LS-GAN损失,采用ResNet的生成器和鉴别器来重建MR图像,获得了较好的可视化结果. ...
DAGAN:deep de-aliasing generative adversarial networks for fast compressed sensing MRI reconstruction
1
2017
... 目前采用深度学习模型进行医学图像重建的方法主要分为两类:一类是从原始数据直接到图像的重建,另一类是基于后处理的方式提高重建图像的质量.第一类方法的代表模型有:ADMM-Net[19 ] ,其用深度迭代的方式学习传统交替方向乘子(alternating direction method of multipliers,ADMM)优化算法中的超参数,可以直接从欠采样的K空间数据中重构出MR图像;Adler J等人[20 ] 提出对偶学习模型,用其代替CT重建中的滤波反投影方法,实现了投影数据到CT图像的准确重建;Cheng J等人[21 ] 在此基础上提出原始-对偶网络(primal-dual network, PD-Net),实现了MR图像的快速重建;Zhang H M等人[22 ] 提出JSR-Net(joint spatial-Radon domain reconstruction net),利用深度卷积神经网络模型,同时重建CT图像及其对应的Radon投影变换图像,得到了比PD-Net更好的重建结果.第二类方法是目前主要的重建方式,即采用图像去伪影的后处理模型进行重建.用于图像降噪、超分辨重建的模型都可以用于该类型的图像重建,如Lee D等人[23 ] 提出带有残差模块的U-Net模型结构来学习重建图像与原始欠采样图像之间的伪影;随后,他们又提出利用双路U-Net模型对相位图像和幅度图像进行重建,进而提高了MR图像的重建质量[24 ] ;Schlemper J等人[25 ] 采用深度级联的卷积神经网络(convolutional neural network,CNN)模型,学习动态MR图像采集的时序关系,进而在快速采集下提高动态MR图像的重建质量;Han Y等人[26 ] 采用域适应微调方法,将CT图像重建的网络应用到MR图像重建上,可以实现高采样率下的准确重建;Eo T等人[27 ] 提出KIKI-Net,同时在K空间和图像空间域上使用深度学习网络进行重建,提高了MR图像重建的性能;Bao L J等人[28 ] 采用一个增强递归残差网络,结合残差块和密集块的连接,用复数图像进行训练,得到了较好的MR图像重建结果;Dai Y X等人[29 ] 基于多尺度空洞卷积设计深度残差卷积网络,以较少的网络参数提高了MR图像的重建精度;受到GAN在视觉领域成功应用的启发,Yang G等人[30 ] 提出一种深度去混叠生成对抗网络(DAGAN),以消除MRI重建过程中的混叠伪影;Quan T M等人[31 ] 提出一种具有周期性损失的RefinGAN模型,以极低的采样率提高了MR图像的重建精度;Mardani M等人[32 ] 基于LS-GAN损失,采用ResNet的生成器和鉴别器来重建MR图像,获得了较好的可视化结果. ...
Compressed sensing MRI reconstruction using a generative adversarial network with a cyclic loss
1
2018
... 目前采用深度学习模型进行医学图像重建的方法主要分为两类:一类是从原始数据直接到图像的重建,另一类是基于后处理的方式提高重建图像的质量.第一类方法的代表模型有:ADMM-Net[19 ] ,其用深度迭代的方式学习传统交替方向乘子(alternating direction method of multipliers,ADMM)优化算法中的超参数,可以直接从欠采样的K空间数据中重构出MR图像;Adler J等人[20 ] 提出对偶学习模型,用其代替CT重建中的滤波反投影方法,实现了投影数据到CT图像的准确重建;Cheng J等人[21 ] 在此基础上提出原始-对偶网络(primal-dual network, PD-Net),实现了MR图像的快速重建;Zhang H M等人[22 ] 提出JSR-Net(joint spatial-Radon domain reconstruction net),利用深度卷积神经网络模型,同时重建CT图像及其对应的Radon投影变换图像,得到了比PD-Net更好的重建结果.第二类方法是目前主要的重建方式,即采用图像去伪影的后处理模型进行重建.用于图像降噪、超分辨重建的模型都可以用于该类型的图像重建,如Lee D等人[23 ] 提出带有残差模块的U-Net模型结构来学习重建图像与原始欠采样图像之间的伪影;随后,他们又提出利用双路U-Net模型对相位图像和幅度图像进行重建,进而提高了MR图像的重建质量[24 ] ;Schlemper J等人[25 ] 采用深度级联的卷积神经网络(convolutional neural network,CNN)模型,学习动态MR图像采集的时序关系,进而在快速采集下提高动态MR图像的重建质量;Han Y等人[26 ] 采用域适应微调方法,将CT图像重建的网络应用到MR图像重建上,可以实现高采样率下的准确重建;Eo T等人[27 ] 提出KIKI-Net,同时在K空间和图像空间域上使用深度学习网络进行重建,提高了MR图像重建的性能;Bao L J等人[28 ] 采用一个增强递归残差网络,结合残差块和密集块的连接,用复数图像进行训练,得到了较好的MR图像重建结果;Dai Y X等人[29 ] 基于多尺度空洞卷积设计深度残差卷积网络,以较少的网络参数提高了MR图像的重建精度;受到GAN在视觉领域成功应用的启发,Yang G等人[30 ] 提出一种深度去混叠生成对抗网络(DAGAN),以消除MRI重建过程中的混叠伪影;Quan T M等人[31 ] 提出一种具有周期性损失的RefinGAN模型,以极低的采样率提高了MR图像的重建精度;Mardani M等人[32 ] 基于LS-GAN损失,采用ResNet的生成器和鉴别器来重建MR图像,获得了较好的可视化结果. ...
Deep generative adversarial neural networks for compressive sensing MRI
1
2019
... 目前采用深度学习模型进行医学图像重建的方法主要分为两类:一类是从原始数据直接到图像的重建,另一类是基于后处理的方式提高重建图像的质量.第一类方法的代表模型有:ADMM-Net[19 ] ,其用深度迭代的方式学习传统交替方向乘子(alternating direction method of multipliers,ADMM)优化算法中的超参数,可以直接从欠采样的K空间数据中重构出MR图像;Adler J等人[20 ] 提出对偶学习模型,用其代替CT重建中的滤波反投影方法,实现了投影数据到CT图像的准确重建;Cheng J等人[21 ] 在此基础上提出原始-对偶网络(primal-dual network, PD-Net),实现了MR图像的快速重建;Zhang H M等人[22 ] 提出JSR-Net(joint spatial-Radon domain reconstruction net),利用深度卷积神经网络模型,同时重建CT图像及其对应的Radon投影变换图像,得到了比PD-Net更好的重建结果.第二类方法是目前主要的重建方式,即采用图像去伪影的后处理模型进行重建.用于图像降噪、超分辨重建的模型都可以用于该类型的图像重建,如Lee D等人[23 ] 提出带有残差模块的U-Net模型结构来学习重建图像与原始欠采样图像之间的伪影;随后,他们又提出利用双路U-Net模型对相位图像和幅度图像进行重建,进而提高了MR图像的重建质量[24 ] ;Schlemper J等人[25 ] 采用深度级联的卷积神经网络(convolutional neural network,CNN)模型,学习动态MR图像采集的时序关系,进而在快速采集下提高动态MR图像的重建质量;Han Y等人[26 ] 采用域适应微调方法,将CT图像重建的网络应用到MR图像重建上,可以实现高采样率下的准确重建;Eo T等人[27 ] 提出KIKI-Net,同时在K空间和图像空间域上使用深度学习网络进行重建,提高了MR图像重建的性能;Bao L J等人[28 ] 采用一个增强递归残差网络,结合残差块和密集块的连接,用复数图像进行训练,得到了较好的MR图像重建结果;Dai Y X等人[29 ] 基于多尺度空洞卷积设计深度残差卷积网络,以较少的网络参数提高了MR图像的重建精度;受到GAN在视觉领域成功应用的启发,Yang G等人[30 ] 提出一种深度去混叠生成对抗网络(DAGAN),以消除MRI重建过程中的混叠伪影;Quan T M等人[31 ] 提出一种具有周期性损失的RefinGAN模型,以极低的采样率提高了MR图像的重建精度;Mardani M等人[32 ] 基于LS-GAN损失,采用ResNet的生成器和鉴别器来重建MR图像,获得了较好的可视化结果. ...
Deep generative adversarial neural networks for realistic prostate lesion MRI synthesis
1
... 随着GAN模型在自然图像合成上的成功应用,应用GAN的衍生模型进行医学图像合成已成为近几年的研究热点.在医学图像数据集扩展方面,主要采用无条件的GAN模型进行合成,即主要从噪声数据中生成医学图像.常用的方法是以深度卷积生成对抗网络(deep convolutional GAN,DCGAN)为基线模型进行改进.如Kitchen A等人[33 ] 基于DCGAN模型成功地合成了前列腺的病灶图像;Schlegl T等人[34 ] 基于DCGAN提出一种AnoGAN模型,用来生成多样的视网膜图像,以辅助视网膜疾病的检测;Chuquicusma M J M等人[35 ] 采用DCGAN模型生成肺结节数据,其结果可达到临床放射科医生无法辨别的程度;Frid-Adar M等人[36 ] 使用DCGAN生成了3类肝损伤(即囊肿、转移酶、血管瘤)的合成样本,以提高肝病分类的准确性;Bermudez C等人[37 ] 采用DCGAN的原有训练策略,生成了高质量的人脑T1加权MR图像. ...
Unsupervised anomaly detection with generative adversarial networks to guide marker discovery
1
2017
... 随着GAN模型在自然图像合成上的成功应用,应用GAN的衍生模型进行医学图像合成已成为近几年的研究热点.在医学图像数据集扩展方面,主要采用无条件的GAN模型进行合成,即主要从噪声数据中生成医学图像.常用的方法是以深度卷积生成对抗网络(deep convolutional GAN,DCGAN)为基线模型进行改进.如Kitchen A等人[33 ] 基于DCGAN模型成功地合成了前列腺的病灶图像;Schlegl T等人[34 ] 基于DCGAN提出一种AnoGAN模型,用来生成多样的视网膜图像,以辅助视网膜疾病的检测;Chuquicusma M J M等人[35 ] 采用DCGAN模型生成肺结节数据,其结果可达到临床放射科医生无法辨别的程度;Frid-Adar M等人[36 ] 使用DCGAN生成了3类肝损伤(即囊肿、转移酶、血管瘤)的合成样本,以提高肝病分类的准确性;Bermudez C等人[37 ] 采用DCGAN的原有训练策略,生成了高质量的人脑T1加权MR图像. ...
How to fool radiologists with generative adversarial networks? A visual turing test for lung cancer diagnosis
1
2018
... 随着GAN模型在自然图像合成上的成功应用,应用GAN的衍生模型进行医学图像合成已成为近几年的研究热点.在医学图像数据集扩展方面,主要采用无条件的GAN模型进行合成,即主要从噪声数据中生成医学图像.常用的方法是以深度卷积生成对抗网络(deep convolutional GAN,DCGAN)为基线模型进行改进.如Kitchen A等人[33 ] 基于DCGAN模型成功地合成了前列腺的病灶图像;Schlegl T等人[34 ] 基于DCGAN提出一种AnoGAN模型,用来生成多样的视网膜图像,以辅助视网膜疾病的检测;Chuquicusma M J M等人[35 ] 采用DCGAN模型生成肺结节数据,其结果可达到临床放射科医生无法辨别的程度;Frid-Adar M等人[36 ] 使用DCGAN生成了3类肝损伤(即囊肿、转移酶、血管瘤)的合成样本,以提高肝病分类的准确性;Bermudez C等人[37 ] 采用DCGAN的原有训练策略,生成了高质量的人脑T1加权MR图像. ...
GAN-based synthetic medical image augmentation for increased CNN performance in liver lesion classification
1
2018
... 随着GAN模型在自然图像合成上的成功应用,应用GAN的衍生模型进行医学图像合成已成为近几年的研究热点.在医学图像数据集扩展方面,主要采用无条件的GAN模型进行合成,即主要从噪声数据中生成医学图像.常用的方法是以深度卷积生成对抗网络(deep convolutional GAN,DCGAN)为基线模型进行改进.如Kitchen A等人[33 ] 基于DCGAN模型成功地合成了前列腺的病灶图像;Schlegl T等人[34 ] 基于DCGAN提出一种AnoGAN模型,用来生成多样的视网膜图像,以辅助视网膜疾病的检测;Chuquicusma M J M等人[35 ] 采用DCGAN模型生成肺结节数据,其结果可达到临床放射科医生无法辨别的程度;Frid-Adar M等人[36 ] 使用DCGAN生成了3类肝损伤(即囊肿、转移酶、血管瘤)的合成样本,以提高肝病分类的准确性;Bermudez C等人[37 ] 采用DCGAN的原有训练策略,生成了高质量的人脑T1加权MR图像. ...
Learning implicit brain MRI manifolds with deep learning
1
2018
... 随着GAN模型在自然图像合成上的成功应用,应用GAN的衍生模型进行医学图像合成已成为近几年的研究热点.在医学图像数据集扩展方面,主要采用无条件的GAN模型进行合成,即主要从噪声数据中生成医学图像.常用的方法是以深度卷积生成对抗网络(deep convolutional GAN,DCGAN)为基线模型进行改进.如Kitchen A等人[33 ] 基于DCGAN模型成功地合成了前列腺的病灶图像;Schlegl T等人[34 ] 基于DCGAN提出一种AnoGAN模型,用来生成多样的视网膜图像,以辅助视网膜疾病的检测;Chuquicusma M J M等人[35 ] 采用DCGAN模型生成肺结节数据,其结果可达到临床放射科医生无法辨别的程度;Frid-Adar M等人[36 ] 使用DCGAN生成了3类肝损伤(即囊肿、转移酶、血管瘤)的合成样本,以提高肝病分类的准确性;Bermudez C等人[37 ] 采用DCGAN的原有训练策略,生成了高质量的人脑T1加权MR图像. ...
MelanoGANs:high resolution skin lesion synthesis with GANs
1
... 尽管DCGAN在医学图像合成上取得了众多有价值的成果,但其仅能合成分辨率较低的图像.为了提高医学图像合成的质量,一些改进的GAN模型被提出,如Baur C等人[38 ] 采用LAPGAN,基于拉普拉斯金字塔的思想,利用尺度逐渐变化来生成高分辨率的皮肤病变图像,该方法生成的图像可以有效地提高皮肤疾病分类的准确性.此外,基于渐进生长生成对抗网络(progressive grow GAN,PGGAN)在高分辨率图像合成方面的优势,Korkinof D等人 [39 ] 利用PGGAN合成了分辨率为1 280×1 024的乳腺钼靶X光图像. ...
High-resolution mammogram synthesis using progressive generative adversarial networks
1
... 尽管DCGAN在医学图像合成上取得了众多有价值的成果,但其仅能合成分辨率较低的图像.为了提高医学图像合成的质量,一些改进的GAN模型被提出,如Baur C等人[38 ] 采用LAPGAN,基于拉普拉斯金字塔的思想,利用尺度逐渐变化来生成高分辨率的皮肤病变图像,该方法生成的图像可以有效地提高皮肤疾病分类的准确性.此外,基于渐进生长生成对抗网络(progressive grow GAN,PGGAN)在高分辨率图像合成方面的优势,Korkinof D等人 [39 ] 利用PGGAN合成了分辨率为1 280×1 024的乳腺钼靶X光图像. ...
Deep convolutional framelet denosing for lowdose CT via wavelet residual network
2018
Generative adversarial networks for noise reduction in low-dose CT
2017
Reconstruction of 7T-like images from 3T MRI
2016
Joint reconstruction and segmentation of 7T-like MR images from 3T MRI based on cascaded convolutional neural networks
2017
Estimating CT image from MRI data using 3D fully convolutional networks
1
2016
... 医学图像的模态转换合成可以分成两类.一类是单模态的转换,如低剂量CT到普通计量CT图像的转换[44 ,45 ] 提出上下文感知生成模型,通过级联3D全卷积网络,利用重建损失、对抗损失、梯度损失,采用配对图像进行训练,实现了MR图像到CT图像的合成,提高了合成CT图像的真实性.除了级联模型,在多模态图像转换任务中,常采用的深度模型网络架构为编码-解码结构,典型代表为Pix2Pix[46 ] 以及CycleGAN[47 ] 模型.如Maspero M等人[48 ] 采用Pix2Pix的网络结构,实现了MR图像到CT图像的转换,进而实现放化疗过程中辐射剂量的计算;Choi H等人[49 ] 基于Pix2Pix模型,从PET图像生成了结构信息更加清晰的脑部MR图像.尽管Pix2Pix模型可以较好地实现多模态图像的转换,但是其要求源图像与目标图像必须空间位置对齐.这种训练数据在临床上是很难获取的.针对源图像和目标图像不匹配的问题,通常采用CycleGAN模型进行图像生成.Wolterink J M等人[50 ] 使用不配对数据,利用CycleGAN从头部MRI图像合成了其对应的CT图像,合成图像更真实.目前,CycleGAN已成为多模态医学图像转换中广泛采用的手段,如心脏MR图像到CT图像的合成[51 ] 、腹部MR图像到CT图像的合成[52 ] 、脑部C T图像到M R图像的合成[53 ] 等.然而CycleGAN有时无法保留图像的结构边界.Hiasa Y等人[54 ] 引入梯度一致性损失,对CycleGAN模型进行了改进,该损失通过评估原始图像与合成图像之间每个像素梯度的一致性来保留合成图像的结构边界,进而提高了合成图像的质量. ...
Medical image synthesis with context-aware generative adversarial networks
1
2017
... 医学图像的模态转换合成可以分成两类.一类是单模态的转换,如低剂量CT到普通计量CT图像的转换[44 ,45 ] 提出上下文感知生成模型,通过级联3D全卷积网络,利用重建损失、对抗损失、梯度损失,采用配对图像进行训练,实现了MR图像到CT图像的合成,提高了合成CT图像的真实性.除了级联模型,在多模态图像转换任务中,常采用的深度模型网络架构为编码-解码结构,典型代表为Pix2Pix[46 ] 以及CycleGAN[47 ] 模型.如Maspero M等人[48 ] 采用Pix2Pix的网络结构,实现了MR图像到CT图像的转换,进而实现放化疗过程中辐射剂量的计算;Choi H等人[49 ] 基于Pix2Pix模型,从PET图像生成了结构信息更加清晰的脑部MR图像.尽管Pix2Pix模型可以较好地实现多模态图像的转换,但是其要求源图像与目标图像必须空间位置对齐.这种训练数据在临床上是很难获取的.针对源图像和目标图像不匹配的问题,通常采用CycleGAN模型进行图像生成.Wolterink J M等人[50 ] 使用不配对数据,利用CycleGAN从头部MRI图像合成了其对应的CT图像,合成图像更真实.目前,CycleGAN已成为多模态医学图像转换中广泛采用的手段,如心脏MR图像到CT图像的合成[51 ] 、腹部MR图像到CT图像的合成[52 ] 、脑部C T图像到M R图像的合成[53 ] 等.然而CycleGAN有时无法保留图像的结构边界.Hiasa Y等人[54 ] 引入梯度一致性损失,对CycleGAN模型进行了改进,该损失通过评估原始图像与合成图像之间每个像素梯度的一致性来保留合成图像的结构边界,进而提高了合成图像的质量. ...
Image-to-image translation with conditional adversarial networks
1
2017
... 医学图像的模态转换合成可以分成两类.一类是单模态的转换,如低剂量CT到普通计量CT图像的转换[44 ,45 ] 提出上下文感知生成模型,通过级联3D全卷积网络,利用重建损失、对抗损失、梯度损失,采用配对图像进行训练,实现了MR图像到CT图像的合成,提高了合成CT图像的真实性.除了级联模型,在多模态图像转换任务中,常采用的深度模型网络架构为编码-解码结构,典型代表为Pix2Pix[46 ] 以及CycleGAN[47 ] 模型.如Maspero M等人[48 ] 采用Pix2Pix的网络结构,实现了MR图像到CT图像的转换,进而实现放化疗过程中辐射剂量的计算;Choi H等人[49 ] 基于Pix2Pix模型,从PET图像生成了结构信息更加清晰的脑部MR图像.尽管Pix2Pix模型可以较好地实现多模态图像的转换,但是其要求源图像与目标图像必须空间位置对齐.这种训练数据在临床上是很难获取的.针对源图像和目标图像不匹配的问题,通常采用CycleGAN模型进行图像生成.Wolterink J M等人[50 ] 使用不配对数据,利用CycleGAN从头部MRI图像合成了其对应的CT图像,合成图像更真实.目前,CycleGAN已成为多模态医学图像转换中广泛采用的手段,如心脏MR图像到CT图像的合成[51 ] 、腹部MR图像到CT图像的合成[52 ] 、脑部C T图像到M R图像的合成[53 ] 等.然而CycleGAN有时无法保留图像的结构边界.Hiasa Y等人[54 ] 引入梯度一致性损失,对CycleGAN模型进行了改进,该损失通过评估原始图像与合成图像之间每个像素梯度的一致性来保留合成图像的结构边界,进而提高了合成图像的质量. ...
Unpaired image-to-image translation using cycle-consistent adversarial networks
1
2017
... 医学图像的模态转换合成可以分成两类.一类是单模态的转换,如低剂量CT到普通计量CT图像的转换[44 ,45 ] 提出上下文感知生成模型,通过级联3D全卷积网络,利用重建损失、对抗损失、梯度损失,采用配对图像进行训练,实现了MR图像到CT图像的合成,提高了合成CT图像的真实性.除了级联模型,在多模态图像转换任务中,常采用的深度模型网络架构为编码-解码结构,典型代表为Pix2Pix[46 ] 以及CycleGAN[47 ] 模型.如Maspero M等人[48 ] 采用Pix2Pix的网络结构,实现了MR图像到CT图像的转换,进而实现放化疗过程中辐射剂量的计算;Choi H等人[49 ] 基于Pix2Pix模型,从PET图像生成了结构信息更加清晰的脑部MR图像.尽管Pix2Pix模型可以较好地实现多模态图像的转换,但是其要求源图像与目标图像必须空间位置对齐.这种训练数据在临床上是很难获取的.针对源图像和目标图像不匹配的问题,通常采用CycleGAN模型进行图像生成.Wolterink J M等人[50 ] 使用不配对数据,利用CycleGAN从头部MRI图像合成了其对应的CT图像,合成图像更真实.目前,CycleGAN已成为多模态医学图像转换中广泛采用的手段,如心脏MR图像到CT图像的合成[51 ] 、腹部MR图像到CT图像的合成[52 ] 、脑部C T图像到M R图像的合成[53 ] 等.然而CycleGAN有时无法保留图像的结构边界.Hiasa Y等人[54 ] 引入梯度一致性损失,对CycleGAN模型进行了改进,该损失通过评估原始图像与合成图像之间每个像素梯度的一致性来保留合成图像的结构边界,进而提高了合成图像的质量. ...
Dose evaluation of fast synthetic-CT generation using a generative adversarial network for general pelvis MR-only radiotherapy
1
2018
... 医学图像的模态转换合成可以分成两类.一类是单模态的转换,如低剂量CT到普通计量CT图像的转换[44 ,45 ] 提出上下文感知生成模型,通过级联3D全卷积网络,利用重建损失、对抗损失、梯度损失,采用配对图像进行训练,实现了MR图像到CT图像的合成,提高了合成CT图像的真实性.除了级联模型,在多模态图像转换任务中,常采用的深度模型网络架构为编码-解码结构,典型代表为Pix2Pix[46 ] 以及CycleGAN[47 ] 模型.如Maspero M等人[48 ] 采用Pix2Pix的网络结构,实现了MR图像到CT图像的转换,进而实现放化疗过程中辐射剂量的计算;Choi H等人[49 ] 基于Pix2Pix模型,从PET图像生成了结构信息更加清晰的脑部MR图像.尽管Pix2Pix模型可以较好地实现多模态图像的转换,但是其要求源图像与目标图像必须空间位置对齐.这种训练数据在临床上是很难获取的.针对源图像和目标图像不匹配的问题,通常采用CycleGAN模型进行图像生成.Wolterink J M等人[50 ] 使用不配对数据,利用CycleGAN从头部MRI图像合成了其对应的CT图像,合成图像更真实.目前,CycleGAN已成为多模态医学图像转换中广泛采用的手段,如心脏MR图像到CT图像的合成[51 ] 、腹部MR图像到CT图像的合成[52 ] 、脑部C T图像到M R图像的合成[53 ] 等.然而CycleGAN有时无法保留图像的结构边界.Hiasa Y等人[54 ] 引入梯度一致性损失,对CycleGAN模型进行了改进,该损失通过评估原始图像与合成图像之间每个像素梯度的一致性来保留合成图像的结构边界,进而提高了合成图像的质量. ...
Generation of structural MR images from amyloid PET:application to MR-less quantification
1
2018
... 医学图像的模态转换合成可以分成两类.一类是单模态的转换,如低剂量CT到普通计量CT图像的转换[44 ,45 ] 提出上下文感知生成模型,通过级联3D全卷积网络,利用重建损失、对抗损失、梯度损失,采用配对图像进行训练,实现了MR图像到CT图像的合成,提高了合成CT图像的真实性.除了级联模型,在多模态图像转换任务中,常采用的深度模型网络架构为编码-解码结构,典型代表为Pix2Pix[46 ] 以及CycleGAN[47 ] 模型.如Maspero M等人[48 ] 采用Pix2Pix的网络结构,实现了MR图像到CT图像的转换,进而实现放化疗过程中辐射剂量的计算;Choi H等人[49 ] 基于Pix2Pix模型,从PET图像生成了结构信息更加清晰的脑部MR图像.尽管Pix2Pix模型可以较好地实现多模态图像的转换,但是其要求源图像与目标图像必须空间位置对齐.这种训练数据在临床上是很难获取的.针对源图像和目标图像不匹配的问题,通常采用CycleGAN模型进行图像生成.Wolterink J M等人[50 ] 使用不配对数据,利用CycleGAN从头部MRI图像合成了其对应的CT图像,合成图像更真实.目前,CycleGAN已成为多模态医学图像转换中广泛采用的手段,如心脏MR图像到CT图像的合成[51 ] 、腹部MR图像到CT图像的合成[52 ] 、脑部C T图像到M R图像的合成[53 ] 等.然而CycleGAN有时无法保留图像的结构边界.Hiasa Y等人[54 ] 引入梯度一致性损失,对CycleGAN模型进行了改进,该损失通过评估原始图像与合成图像之间每个像素梯度的一致性来保留合成图像的结构边界,进而提高了合成图像的质量. ...
Deep MR to CT synthesis using unpaired data
1
2017
... 医学图像的模态转换合成可以分成两类.一类是单模态的转换,如低剂量CT到普通计量CT图像的转换[44 ,45 ] 提出上下文感知生成模型,通过级联3D全卷积网络,利用重建损失、对抗损失、梯度损失,采用配对图像进行训练,实现了MR图像到CT图像的合成,提高了合成CT图像的真实性.除了级联模型,在多模态图像转换任务中,常采用的深度模型网络架构为编码-解码结构,典型代表为Pix2Pix[46 ] 以及CycleGAN[47 ] 模型.如Maspero M等人[48 ] 采用Pix2Pix的网络结构,实现了MR图像到CT图像的转换,进而实现放化疗过程中辐射剂量的计算;Choi H等人[49 ] 基于Pix2Pix模型,从PET图像生成了结构信息更加清晰的脑部MR图像.尽管Pix2Pix模型可以较好地实现多模态图像的转换,但是其要求源图像与目标图像必须空间位置对齐.这种训练数据在临床上是很难获取的.针对源图像和目标图像不匹配的问题,通常采用CycleGAN模型进行图像生成.Wolterink J M等人[50 ] 使用不配对数据,利用CycleGAN从头部MRI图像合成了其对应的CT图像,合成图像更真实.目前,CycleGAN已成为多模态医学图像转换中广泛采用的手段,如心脏MR图像到CT图像的合成[51 ] 、腹部MR图像到CT图像的合成[52 ] 、脑部C T图像到M R图像的合成[53 ] 等.然而CycleGAN有时无法保留图像的结构边界.Hiasa Y等人[54 ] 引入梯度一致性损失,对CycleGAN模型进行了改进,该损失通过评估原始图像与合成图像之间每个像素梯度的一致性来保留合成图像的结构边界,进而提高了合成图像的质量. ...
Adversarial image synthesis for unpaired multimodal cardiac data
1
2017
... 医学图像的模态转换合成可以分成两类.一类是单模态的转换,如低剂量CT到普通计量CT图像的转换[44 ,45 ] 提出上下文感知生成模型,通过级联3D全卷积网络,利用重建损失、对抗损失、梯度损失,采用配对图像进行训练,实现了MR图像到CT图像的合成,提高了合成CT图像的真实性.除了级联模型,在多模态图像转换任务中,常采用的深度模型网络架构为编码-解码结构,典型代表为Pix2Pix[46 ] 以及CycleGAN[47 ] 模型.如Maspero M等人[48 ] 采用Pix2Pix的网络结构,实现了MR图像到CT图像的转换,进而实现放化疗过程中辐射剂量的计算;Choi H等人[49 ] 基于Pix2Pix模型,从PET图像生成了结构信息更加清晰的脑部MR图像.尽管Pix2Pix模型可以较好地实现多模态图像的转换,但是其要求源图像与目标图像必须空间位置对齐.这种训练数据在临床上是很难获取的.针对源图像和目标图像不匹配的问题,通常采用CycleGAN模型进行图像生成.Wolterink J M等人[50 ] 使用不配对数据,利用CycleGAN从头部MRI图像合成了其对应的CT图像,合成图像更真实.目前,CycleGAN已成为多模态医学图像转换中广泛采用的手段,如心脏MR图像到CT图像的合成[51 ] 、腹部MR图像到CT图像的合成[52 ] 、脑部C T图像到M R图像的合成[53 ] 等.然而CycleGAN有时无法保留图像的结构边界.Hiasa Y等人[54 ] 引入梯度一致性损失,对CycleGAN模型进行了改进,该损失通过评估原始图像与合成图像之间每个像素梯度的一致性来保留合成图像的结构边界,进而提高了合成图像的质量. ...
Semi-automatic synthetic computed tomography generation for abdomens using transfer learning and semisupervised classification
1
2019
... 医学图像的模态转换合成可以分成两类.一类是单模态的转换,如低剂量CT到普通计量CT图像的转换[44 ,45 ] 提出上下文感知生成模型,通过级联3D全卷积网络,利用重建损失、对抗损失、梯度损失,采用配对图像进行训练,实现了MR图像到CT图像的合成,提高了合成CT图像的真实性.除了级联模型,在多模态图像转换任务中,常采用的深度模型网络架构为编码-解码结构,典型代表为Pix2Pix[46 ] 以及CycleGAN[47 ] 模型.如Maspero M等人[48 ] 采用Pix2Pix的网络结构,实现了MR图像到CT图像的转换,进而实现放化疗过程中辐射剂量的计算;Choi H等人[49 ] 基于Pix2Pix模型,从PET图像生成了结构信息更加清晰的脑部MR图像.尽管Pix2Pix模型可以较好地实现多模态图像的转换,但是其要求源图像与目标图像必须空间位置对齐.这种训练数据在临床上是很难获取的.针对源图像和目标图像不匹配的问题,通常采用CycleGAN模型进行图像生成.Wolterink J M等人[50 ] 使用不配对数据,利用CycleGAN从头部MRI图像合成了其对应的CT图像,合成图像更真实.目前,CycleGAN已成为多模态医学图像转换中广泛采用的手段,如心脏MR图像到CT图像的合成[51 ] 、腹部MR图像到CT图像的合成[52 ] 、脑部C T图像到M R图像的合成[53 ] 等.然而CycleGAN有时无法保留图像的结构边界.Hiasa Y等人[54 ] 引入梯度一致性损失,对CycleGAN模型进行了改进,该损失通过评估原始图像与合成图像之间每个像素梯度的一致性来保留合成图像的结构边界,进而提高了合成图像的质量. ...
Deep CT to MR synthesis using paired and unpaired data
1
2019
... 医学图像的模态转换合成可以分成两类.一类是单模态的转换,如低剂量CT到普通计量CT图像的转换[44 ,45 ] 提出上下文感知生成模型,通过级联3D全卷积网络,利用重建损失、对抗损失、梯度损失,采用配对图像进行训练,实现了MR图像到CT图像的合成,提高了合成CT图像的真实性.除了级联模型,在多模态图像转换任务中,常采用的深度模型网络架构为编码-解码结构,典型代表为Pix2Pix[46 ] 以及CycleGAN[47 ] 模型.如Maspero M等人[48 ] 采用Pix2Pix的网络结构,实现了MR图像到CT图像的转换,进而实现放化疗过程中辐射剂量的计算;Choi H等人[49 ] 基于Pix2Pix模型,从PET图像生成了结构信息更加清晰的脑部MR图像.尽管Pix2Pix模型可以较好地实现多模态图像的转换,但是其要求源图像与目标图像必须空间位置对齐.这种训练数据在临床上是很难获取的.针对源图像和目标图像不匹配的问题,通常采用CycleGAN模型进行图像生成.Wolterink J M等人[50 ] 使用不配对数据,利用CycleGAN从头部MRI图像合成了其对应的CT图像,合成图像更真实.目前,CycleGAN已成为多模态医学图像转换中广泛采用的手段,如心脏MR图像到CT图像的合成[51 ] 、腹部MR图像到CT图像的合成[52 ] 、脑部C T图像到M R图像的合成[53 ] 等.然而CycleGAN有时无法保留图像的结构边界.Hiasa Y等人[54 ] 引入梯度一致性损失,对CycleGAN模型进行了改进,该损失通过评估原始图像与合成图像之间每个像素梯度的一致性来保留合成图像的结构边界,进而提高了合成图像的质量. ...
Cross-modality image synthesis from unpaired data using CycleGAN
1
2018
... 医学图像的模态转换合成可以分成两类.一类是单模态的转换,如低剂量CT到普通计量CT图像的转换[44 ,45 ] 提出上下文感知生成模型,通过级联3D全卷积网络,利用重建损失、对抗损失、梯度损失,采用配对图像进行训练,实现了MR图像到CT图像的合成,提高了合成CT图像的真实性.除了级联模型,在多模态图像转换任务中,常采用的深度模型网络架构为编码-解码结构,典型代表为Pix2Pix[46 ] 以及CycleGAN[47 ] 模型.如Maspero M等人[48 ] 采用Pix2Pix的网络结构,实现了MR图像到CT图像的转换,进而实现放化疗过程中辐射剂量的计算;Choi H等人[49 ] 基于Pix2Pix模型,从PET图像生成了结构信息更加清晰的脑部MR图像.尽管Pix2Pix模型可以较好地实现多模态图像的转换,但是其要求源图像与目标图像必须空间位置对齐.这种训练数据在临床上是很难获取的.针对源图像和目标图像不匹配的问题,通常采用CycleGAN模型进行图像生成.Wolterink J M等人[50 ] 使用不配对数据,利用CycleGAN从头部MRI图像合成了其对应的CT图像,合成图像更真实.目前,CycleGAN已成为多模态医学图像转换中广泛采用的手段,如心脏MR图像到CT图像的合成[51 ] 、腹部MR图像到CT图像的合成[52 ] 、脑部C T图像到M R图像的合成[53 ] 等.然而CycleGAN有时无法保留图像的结构边界.Hiasa Y等人[54 ] 引入梯度一致性损失,对CycleGAN模型进行了改进,该损失通过评估原始图像与合成图像之间每个像素梯度的一致性来保留合成图像的结构边界,进而提高了合成图像的质量. ...
Deep similarity learning for multimodal medical images
1
2018
... 图像配准是对不同时刻、不同机器采集的图像进行空间位置匹配的过程,是医学图像处理领域非常重要的预处理步骤之一,在多模态图像融合分析、图谱建立、手术指导、肿瘤区域生长检测以及治疗疗效评价中有广泛的应用.目前,深度学习在医学图像配准领域的研究可以分成3类,第一类是采用深度迭代的方法进行配准,第二类是采用有监督的深度学习模型进行配准,第三类是基于无监督模型的深度学习配准.第一类方法主要采用深度学习模型学习相似性度量,然后利用传统优化方法学习配准的形变[55 ,56 ,57 ] .该类方法配准速度慢,没有充分发挥深度学习的优势,因此近几年鲜见报道.本文主要集中介绍有监督学习和无监督学习的医学图像配准. ...
Semi-supervised deep metrics for image registration
1
... 图像配准是对不同时刻、不同机器采集的图像进行空间位置匹配的过程,是医学图像处理领域非常重要的预处理步骤之一,在多模态图像融合分析、图谱建立、手术指导、肿瘤区域生长检测以及治疗疗效评价中有广泛的应用.目前,深度学习在医学图像配准领域的研究可以分成3类,第一类是采用深度迭代的方法进行配准,第二类是采用有监督的深度学习模型进行配准,第三类是基于无监督模型的深度学习配准.第一类方法主要采用深度学习模型学习相似性度量,然后利用传统优化方法学习配准的形变[55 ,56 ,57 ] .该类方法配准速度慢,没有充分发挥深度学习的优势,因此近几年鲜见报道.本文主要集中介绍有监督学习和无监督学习的医学图像配准. ...
A deep metric for multimodal registration
1
2016
... 图像配准是对不同时刻、不同机器采集的图像进行空间位置匹配的过程,是医学图像处理领域非常重要的预处理步骤之一,在多模态图像融合分析、图谱建立、手术指导、肿瘤区域生长检测以及治疗疗效评价中有广泛的应用.目前,深度学习在医学图像配准领域的研究可以分成3类,第一类是采用深度迭代的方法进行配准,第二类是采用有监督的深度学习模型进行配准,第三类是基于无监督模型的深度学习配准.第一类方法主要采用深度学习模型学习相似性度量,然后利用传统优化方法学习配准的形变[55 ,56 ,57 ] .该类方法配准速度慢,没有充分发挥深度学习的优势,因此近几年鲜见报道.本文主要集中介绍有监督学习和无监督学习的医学图像配准. ...
Real-time 2D/3D registration viaCNN regression
1
2016
... 在基于有监督学习的刚性配准方面,Miao S等人[58 ,59 ] 首先结合CNN,采用回归的思想将3D X射线衰减映射图与术中实时的2D X射线图进行刚体配准;Salehi S S M等人[60 ] 结合深度残差回归网络和修正网络,采用“先粗配准,再细配准”的策略,基于测地线距离损失实现了3D胎儿大脑T1和T2加权磁共振图像的刚体配准,建立了胎儿大脑图谱;随后,Zheng J N等人[61 ] 采用域自适应的思想,利用预训练网络实现了2D和3D射线图像配准,其设计了成对域适应模块,用来调整模拟训练数据与真实测试数据之间的差异,以提高配准的鲁棒性. ...
A CNN regression approach for real-time 2D/3D registration
1
2016
... 在基于有监督学习的刚性配准方面,Miao S等人[58 ,59 ] 首先结合CNN,采用回归的思想将3D X射线衰减映射图与术中实时的2D X射线图进行刚体配准;Salehi S S M等人[60 ] 结合深度残差回归网络和修正网络,采用“先粗配准,再细配准”的策略,基于测地线距离损失实现了3D胎儿大脑T1和T2加权磁共振图像的刚体配准,建立了胎儿大脑图谱;随后,Zheng J N等人[61 ] 采用域自适应的思想,利用预训练网络实现了2D和3D射线图像配准,其设计了成对域适应模块,用来调整模拟训练数据与真实测试数据之间的差异,以提高配准的鲁棒性. ...
Real-time deep pose estimation with geodesic loss for image-totemplate rigid registration
1
2018
... 在基于有监督学习的刚性配准方面,Miao S等人[58 ,59 ] 首先结合CNN,采用回归的思想将3D X射线衰减映射图与术中实时的2D X射线图进行刚体配准;Salehi S S M等人[60 ] 结合深度残差回归网络和修正网络,采用“先粗配准,再细配准”的策略,基于测地线距离损失实现了3D胎儿大脑T1和T2加权磁共振图像的刚体配准,建立了胎儿大脑图谱;随后,Zheng J N等人[61 ] 采用域自适应的思想,利用预训练网络实现了2D和3D射线图像配准,其设计了成对域适应模块,用来调整模拟训练数据与真实测试数据之间的差异,以提高配准的鲁棒性. ...
Pairwise domain adaptation module for CNN-based 2-D/3-D registration
2
2018
... 在基于有监督学习的刚性配准方面,Miao S等人[58 ,59 ] 首先结合CNN,采用回归的思想将3D X射线衰减映射图与术中实时的2D X射线图进行刚体配准;Salehi S S M等人[60 ] 结合深度残差回归网络和修正网络,采用“先粗配准,再细配准”的策略,基于测地线距离损失实现了3D胎儿大脑T1和T2加权磁共振图像的刚体配准,建立了胎儿大脑图谱;随后,Zheng J N等人[61 ] 采用域自适应的思想,利用预训练网络实现了2D和3D射线图像配准,其设计了成对域适应模块,用来调整模拟训练数据与真实测试数据之间的差异,以提高配准的鲁棒性. ...
... 深度学习配准的代表性模型总结
模型类型 配准类型 数据集 变形场来源 器官 模型 评价指标 文献 有监督配准模型 刚体配准 内部数据集 合成形变场 骨骼X-ray CNN mTREproj:0.282 mm [69 -70 ] 刚体配准 内部数据集 合成形变场 脊柱CT和X-ray PDA TRE:5.65 mm [61 ] 非线性配准 LBPA40、ISBR18、CUMC12、MGH10 真实形变场 脑部MR 3D-CNN [62 ] 非线性配准 内部数据集 真实形变场 前列腺超声和MR CNN TRE=8.5 mm [63 ] Dice=0.86 非线性配准 ACDC dataset 分割监督 心脏MR CNN Dice=0.865 [64 ] 非线性配准 内部数据集 标签监督 前列腺CT和MR CNN ASD=1.58 mm [65 ] Dice=0.873 非线性配准 IBSR18、CUMC12、MGH10、IXI30 双监督学习形变场 脑部MR BIRNet Dice>0.728 (分脑区比较) [66 ] 无监督配准模型 非线性配准 ADNI、OASIS、ABIDE、ADHD200、MCIC、PPMI、HABS、Harvard GSP 脑部MR VoxelMorph Dice=0.78 [69 ] 非线性配准 Mindboggle101 脑部MR FAIM Dice=0.533(左上顶叶) [71 ] 非线性配准 ADNI 脑部MR ICNet Dice=0.88 [72 ] ASD=0.71 mm HD=12.71 mm(白质) 非线性配准 内部数据集 脑部MR ADMIR Dice=0.91 [73 ] HD=2.68 ASD=0.59 非线性配准 内部数据集 前列腺MR和超声 AirNet TRE=3.48 mm [74 ] 非线性配准 内部数据集、Sunybrook 视网膜图像、心脏MR GAN Dice=0.887/0.79HD=8.0/5.12 [75 ] (视网膜/心脏) 非线性配准 VISCERAL Anatomy3 benchmark 全身MR、CT GAN Dice=0.757 (胸部)Dice=0.783(腹部) [76 ]
U-Net是由一系列卷积和反卷积组成的编码和解码结构,通过跳跃连接实现高级语义特征和低级空间信息的融合,进而保证分割的准确度.U-Net及其变体(如Nested U-Net[83 ] 、V-Net[84 ] 、循环残差U-Net[85 ] )在医学图像分割上取得了较好的分割结果,是目前医学图像分割的主流基线模型. ...
Quicksilver:fast predictive image registration–a deep learning approach
2
2017
... 在非线性配准方面,模拟非线性变形场比模拟刚性变形场困难很多,因此在基于有监督学习的非线性配准中,大多采用经典方法获得变形场,并以其为标签,对模型进行训练.Yang X等人[62 ] 首先以U-Net网络模型为基线结构,利用微分同胚算法获得变形场,并将其作为标签,实现2D和3D脑部MR图像的端到端配准.因为非线性变形场较难模拟,所以在监督学习中引入弱监督配准和双监督配准的概念.弱监督配准指利用解剖结构标签做配准的标记,学习变形场.Hu Y P等人[63 ] 使用前列腺超声图像和MR图像的结构标记训练CNN模型,学习变形场,然后将变形场施加在灰度图像上,从而实现MR图像和超声图像的配准.Hering A等人[64 ] 采用相似度测量和组织结构分割标签,同时训练配准网络,提高了心脏MR图像的配准精度.双监督配准是指模型采用两种监督形式的损失函数进行训练,如Cao X H等人[65 ] 在进行MR图像和CT图像配准时,先利用生成网络将MR图像转换为其对应的CT图像,将CT图像转换为其对应的MR图像,在配准的过程中,同时计算原始MR图像与生成MR图像之间的相似性损失以及原始CT图像与生成CT图像之间的相似性损失,通过两种损失的优化,提高配准的精度;Fan J F等人[66 ] 结合有监督模型损失和无监督模型损失,实现了脑部MR图像的准确配准.有监督学习的医学图像配准的精度取决于标签的可靠性,因此,如何生成可靠的标签并设计合适的损失函数,是有监督学习的医学图像配准中待解决的难点. ...
... 深度学习配准的代表性模型总结
模型类型 配准类型 数据集 变形场来源 器官 模型 评价指标 文献 有监督配准模型 刚体配准 内部数据集 合成形变场 骨骼X-ray CNN mTREproj:0.282 mm [69 -70 ] 刚体配准 内部数据集 合成形变场 脊柱CT和X-ray PDA TRE:5.65 mm [61 ] 非线性配准 LBPA40、ISBR18、CUMC12、MGH10 真实形变场 脑部MR 3D-CNN [62 ] 非线性配准 内部数据集 真实形变场 前列腺超声和MR CNN TRE=8.5 mm [63 ] Dice=0.86 非线性配准 ACDC dataset 分割监督 心脏MR CNN Dice=0.865 [64 ] 非线性配准 内部数据集 标签监督 前列腺CT和MR CNN ASD=1.58 mm [65 ] Dice=0.873 非线性配准 IBSR18、CUMC12、MGH10、IXI30 双监督学习形变场 脑部MR BIRNet Dice>0.728 (分脑区比较) [66 ] 无监督配准模型 非线性配准 ADNI、OASIS、ABIDE、ADHD200、MCIC、PPMI、HABS、Harvard GSP 脑部MR VoxelMorph Dice=0.78 [69 ] 非线性配准 Mindboggle101 脑部MR FAIM Dice=0.533(左上顶叶) [71 ] 非线性配准 ADNI 脑部MR ICNet Dice=0.88 [72 ] ASD=0.71 mm HD=12.71 mm(白质) 非线性配准 内部数据集 脑部MR ADMIR Dice=0.91 [73 ] HD=2.68 ASD=0.59 非线性配准 内部数据集 前列腺MR和超声 AirNet TRE=3.48 mm [74 ] 非线性配准 内部数据集、Sunybrook 视网膜图像、心脏MR GAN Dice=0.887/0.79HD=8.0/5.12 [75 ] (视网膜/心脏) 非线性配准 VISCERAL Anatomy3 benchmark 全身MR、CT GAN Dice=0.757 (胸部)Dice=0.783(腹部) [76 ]
U-Net是由一系列卷积和反卷积组成的编码和解码结构,通过跳跃连接实现高级语义特征和低级空间信息的融合,进而保证分割的准确度.U-Net及其变体(如Nested U-Net[83 ] 、V-Net[84 ] 、循环残差U-Net[85 ] )在医学图像分割上取得了较好的分割结果,是目前医学图像分割的主流基线模型. ...
Label-driven weakly-supervised learning for multimodal deformable image registration
2
2018
... 在非线性配准方面,模拟非线性变形场比模拟刚性变形场困难很多,因此在基于有监督学习的非线性配准中,大多采用经典方法获得变形场,并以其为标签,对模型进行训练.Yang X等人[62 ] 首先以U-Net网络模型为基线结构,利用微分同胚算法获得变形场,并将其作为标签,实现2D和3D脑部MR图像的端到端配准.因为非线性变形场较难模拟,所以在监督学习中引入弱监督配准和双监督配准的概念.弱监督配准指利用解剖结构标签做配准的标记,学习变形场.Hu Y P等人[63 ] 使用前列腺超声图像和MR图像的结构标记训练CNN模型,学习变形场,然后将变形场施加在灰度图像上,从而实现MR图像和超声图像的配准.Hering A等人[64 ] 采用相似度测量和组织结构分割标签,同时训练配准网络,提高了心脏MR图像的配准精度.双监督配准是指模型采用两种监督形式的损失函数进行训练,如Cao X H等人[65 ] 在进行MR图像和CT图像配准时,先利用生成网络将MR图像转换为其对应的CT图像,将CT图像转换为其对应的MR图像,在配准的过程中,同时计算原始MR图像与生成MR图像之间的相似性损失以及原始CT图像与生成CT图像之间的相似性损失,通过两种损失的优化,提高配准的精度;Fan J F等人[66 ] 结合有监督模型损失和无监督模型损失,实现了脑部MR图像的准确配准.有监督学习的医学图像配准的精度取决于标签的可靠性,因此,如何生成可靠的标签并设计合适的损失函数,是有监督学习的医学图像配准中待解决的难点. ...
... 深度学习配准的代表性模型总结
模型类型 配准类型 数据集 变形场来源 器官 模型 评价指标 文献 有监督配准模型 刚体配准 内部数据集 合成形变场 骨骼X-ray CNN mTREproj:0.282 mm [69 -70 ] 刚体配准 内部数据集 合成形变场 脊柱CT和X-ray PDA TRE:5.65 mm [61 ] 非线性配准 LBPA40、ISBR18、CUMC12、MGH10 真实形变场 脑部MR 3D-CNN [62 ] 非线性配准 内部数据集 真实形变场 前列腺超声和MR CNN TRE=8.5 mm [63 ] Dice=0.86 非线性配准 ACDC dataset 分割监督 心脏MR CNN Dice=0.865 [64 ] 非线性配准 内部数据集 标签监督 前列腺CT和MR CNN ASD=1.58 mm [65 ] Dice=0.873 非线性配准 IBSR18、CUMC12、MGH10、IXI30 双监督学习形变场 脑部MR BIRNet Dice>0.728 (分脑区比较) [66 ] 无监督配准模型 非线性配准 ADNI、OASIS、ABIDE、ADHD200、MCIC、PPMI、HABS、Harvard GSP 脑部MR VoxelMorph Dice=0.78 [69 ] 非线性配准 Mindboggle101 脑部MR FAIM Dice=0.533(左上顶叶) [71 ] 非线性配准 ADNI 脑部MR ICNet Dice=0.88 [72 ] ASD=0.71 mm HD=12.71 mm(白质) 非线性配准 内部数据集 脑部MR ADMIR Dice=0.91 [73 ] HD=2.68 ASD=0.59 非线性配准 内部数据集 前列腺MR和超声 AirNet TRE=3.48 mm [74 ] 非线性配准 内部数据集、Sunybrook 视网膜图像、心脏MR GAN Dice=0.887/0.79HD=8.0/5.12 [75 ] (视网膜/心脏) 非线性配准 VISCERAL Anatomy3 benchmark 全身MR、CT GAN Dice=0.757 (胸部)Dice=0.783(腹部) [76 ]
U-Net是由一系列卷积和反卷积组成的编码和解码结构,通过跳跃连接实现高级语义特征和低级空间信息的融合,进而保证分割的准确度.U-Net及其变体(如Nested U-Net[83 ] 、V-Net[84 ] 、循环残差U-Net[85 ] )在医学图像分割上取得了较好的分割结果,是目前医学图像分割的主流基线模型. ...
Enhancing label-driven deep deformable image registration with local distance metrics for state-ofthe-art cardiac motion tracking
2
2019
... 在非线性配准方面,模拟非线性变形场比模拟刚性变形场困难很多,因此在基于有监督学习的非线性配准中,大多采用经典方法获得变形场,并以其为标签,对模型进行训练.Yang X等人[62 ] 首先以U-Net网络模型为基线结构,利用微分同胚算法获得变形场,并将其作为标签,实现2D和3D脑部MR图像的端到端配准.因为非线性变形场较难模拟,所以在监督学习中引入弱监督配准和双监督配准的概念.弱监督配准指利用解剖结构标签做配准的标记,学习变形场.Hu Y P等人[63 ] 使用前列腺超声图像和MR图像的结构标记训练CNN模型,学习变形场,然后将变形场施加在灰度图像上,从而实现MR图像和超声图像的配准.Hering A等人[64 ] 采用相似度测量和组织结构分割标签,同时训练配准网络,提高了心脏MR图像的配准精度.双监督配准是指模型采用两种监督形式的损失函数进行训练,如Cao X H等人[65 ] 在进行MR图像和CT图像配准时,先利用生成网络将MR图像转换为其对应的CT图像,将CT图像转换为其对应的MR图像,在配准的过程中,同时计算原始MR图像与生成MR图像之间的相似性损失以及原始CT图像与生成CT图像之间的相似性损失,通过两种损失的优化,提高配准的精度;Fan J F等人[66 ] 结合有监督模型损失和无监督模型损失,实现了脑部MR图像的准确配准.有监督学习的医学图像配准的精度取决于标签的可靠性,因此,如何生成可靠的标签并设计合适的损失函数,是有监督学习的医学图像配准中待解决的难点. ...
... 深度学习配准的代表性模型总结
模型类型 配准类型 数据集 变形场来源 器官 模型 评价指标 文献 有监督配准模型 刚体配准 内部数据集 合成形变场 骨骼X-ray CNN mTREproj:0.282 mm [69 -70 ] 刚体配准 内部数据集 合成形变场 脊柱CT和X-ray PDA TRE:5.65 mm [61 ] 非线性配准 LBPA40、ISBR18、CUMC12、MGH10 真实形变场 脑部MR 3D-CNN [62 ] 非线性配准 内部数据集 真实形变场 前列腺超声和MR CNN TRE=8.5 mm [63 ] Dice=0.86 非线性配准 ACDC dataset 分割监督 心脏MR CNN Dice=0.865 [64 ] 非线性配准 内部数据集 标签监督 前列腺CT和MR CNN ASD=1.58 mm [65 ] Dice=0.873 非线性配准 IBSR18、CUMC12、MGH10、IXI30 双监督学习形变场 脑部MR BIRNet Dice>0.728 (分脑区比较) [66 ] 无监督配准模型 非线性配准 ADNI、OASIS、ABIDE、ADHD200、MCIC、PPMI、HABS、Harvard GSP 脑部MR VoxelMorph Dice=0.78 [69 ] 非线性配准 Mindboggle101 脑部MR FAIM Dice=0.533(左上顶叶) [71 ] 非线性配准 ADNI 脑部MR ICNet Dice=0.88 [72 ] ASD=0.71 mm HD=12.71 mm(白质) 非线性配准 内部数据集 脑部MR ADMIR Dice=0.91 [73 ] HD=2.68 ASD=0.59 非线性配准 内部数据集 前列腺MR和超声 AirNet TRE=3.48 mm [74 ] 非线性配准 内部数据集、Sunybrook 视网膜图像、心脏MR GAN Dice=0.887/0.79HD=8.0/5.12 [75 ] (视网膜/心脏) 非线性配准 VISCERAL Anatomy3 benchmark 全身MR、CT GAN Dice=0.757 (胸部)Dice=0.783(腹部) [76 ]
U-Net是由一系列卷积和反卷积组成的编码和解码结构,通过跳跃连接实现高级语义特征和低级空间信息的融合,进而保证分割的准确度.U-Net及其变体(如Nested U-Net[83 ] 、V-Net[84 ] 、循环残差U-Net[85 ] )在医学图像分割上取得了较好的分割结果,是目前医学图像分割的主流基线模型. ...
Deep learning based inter-modality image registration supervised by intramodality similarity
2
2018
... 在非线性配准方面,模拟非线性变形场比模拟刚性变形场困难很多,因此在基于有监督学习的非线性配准中,大多采用经典方法获得变形场,并以其为标签,对模型进行训练.Yang X等人[62 ] 首先以U-Net网络模型为基线结构,利用微分同胚算法获得变形场,并将其作为标签,实现2D和3D脑部MR图像的端到端配准.因为非线性变形场较难模拟,所以在监督学习中引入弱监督配准和双监督配准的概念.弱监督配准指利用解剖结构标签做配准的标记,学习变形场.Hu Y P等人[63 ] 使用前列腺超声图像和MR图像的结构标记训练CNN模型,学习变形场,然后将变形场施加在灰度图像上,从而实现MR图像和超声图像的配准.Hering A等人[64 ] 采用相似度测量和组织结构分割标签,同时训练配准网络,提高了心脏MR图像的配准精度.双监督配准是指模型采用两种监督形式的损失函数进行训练,如Cao X H等人[65 ] 在进行MR图像和CT图像配准时,先利用生成网络将MR图像转换为其对应的CT图像,将CT图像转换为其对应的MR图像,在配准的过程中,同时计算原始MR图像与生成MR图像之间的相似性损失以及原始CT图像与生成CT图像之间的相似性损失,通过两种损失的优化,提高配准的精度;Fan J F等人[66 ] 结合有监督模型损失和无监督模型损失,实现了脑部MR图像的准确配准.有监督学习的医学图像配准的精度取决于标签的可靠性,因此,如何生成可靠的标签并设计合适的损失函数,是有监督学习的医学图像配准中待解决的难点. ...
... 深度学习配准的代表性模型总结
模型类型 配准类型 数据集 变形场来源 器官 模型 评价指标 文献 有监督配准模型 刚体配准 内部数据集 合成形变场 骨骼X-ray CNN mTREproj:0.282 mm [69 -70 ] 刚体配准 内部数据集 合成形变场 脊柱CT和X-ray PDA TRE:5.65 mm [61 ] 非线性配准 LBPA40、ISBR18、CUMC12、MGH10 真实形变场 脑部MR 3D-CNN [62 ] 非线性配准 内部数据集 真实形变场 前列腺超声和MR CNN TRE=8.5 mm [63 ] Dice=0.86 非线性配准 ACDC dataset 分割监督 心脏MR CNN Dice=0.865 [64 ] 非线性配准 内部数据集 标签监督 前列腺CT和MR CNN ASD=1.58 mm [65 ] Dice=0.873 非线性配准 IBSR18、CUMC12、MGH10、IXI30 双监督学习形变场 脑部MR BIRNet Dice>0.728 (分脑区比较) [66 ] 无监督配准模型 非线性配准 ADNI、OASIS、ABIDE、ADHD200、MCIC、PPMI、HABS、Harvard GSP 脑部MR VoxelMorph Dice=0.78 [69 ] 非线性配准 Mindboggle101 脑部MR FAIM Dice=0.533(左上顶叶) [71 ] 非线性配准 ADNI 脑部MR ICNet Dice=0.88 [72 ] ASD=0.71 mm HD=12.71 mm(白质) 非线性配准 内部数据集 脑部MR ADMIR Dice=0.91 [73 ] HD=2.68 ASD=0.59 非线性配准 内部数据集 前列腺MR和超声 AirNet TRE=3.48 mm [74 ] 非线性配准 内部数据集、Sunybrook 视网膜图像、心脏MR GAN Dice=0.887/0.79HD=8.0/5.12 [75 ] (视网膜/心脏) 非线性配准 VISCERAL Anatomy3 benchmark 全身MR、CT GAN Dice=0.757 (胸部)Dice=0.783(腹部) [76 ]
U-Net是由一系列卷积和反卷积组成的编码和解码结构,通过跳跃连接实现高级语义特征和低级空间信息的融合,进而保证分割的准确度.U-Net及其变体(如Nested U-Net[83 ] 、V-Net[84 ] 、循环残差U-Net[85 ] )在医学图像分割上取得了较好的分割结果,是目前医学图像分割的主流基线模型. ...
BIRNet:brain image registration using dual-supervised fully convolutional networks
2
2019
... 在非线性配准方面,模拟非线性变形场比模拟刚性变形场困难很多,因此在基于有监督学习的非线性配准中,大多采用经典方法获得变形场,并以其为标签,对模型进行训练.Yang X等人[62 ] 首先以U-Net网络模型为基线结构,利用微分同胚算法获得变形场,并将其作为标签,实现2D和3D脑部MR图像的端到端配准.因为非线性变形场较难模拟,所以在监督学习中引入弱监督配准和双监督配准的概念.弱监督配准指利用解剖结构标签做配准的标记,学习变形场.Hu Y P等人[63 ] 使用前列腺超声图像和MR图像的结构标记训练CNN模型,学习变形场,然后将变形场施加在灰度图像上,从而实现MR图像和超声图像的配准.Hering A等人[64 ] 采用相似度测量和组织结构分割标签,同时训练配准网络,提高了心脏MR图像的配准精度.双监督配准是指模型采用两种监督形式的损失函数进行训练,如Cao X H等人[65 ] 在进行MR图像和CT图像配准时,先利用生成网络将MR图像转换为其对应的CT图像,将CT图像转换为其对应的MR图像,在配准的过程中,同时计算原始MR图像与生成MR图像之间的相似性损失以及原始CT图像与生成CT图像之间的相似性损失,通过两种损失的优化,提高配准的精度;Fan J F等人[66 ] 结合有监督模型损失和无监督模型损失,实现了脑部MR图像的准确配准.有监督学习的医学图像配准的精度取决于标签的可靠性,因此,如何生成可靠的标签并设计合适的损失函数,是有监督学习的医学图像配准中待解决的难点. ...
... 深度学习配准的代表性模型总结
模型类型 配准类型 数据集 变形场来源 器官 模型 评价指标 文献 有监督配准模型 刚体配准 内部数据集 合成形变场 骨骼X-ray CNN mTREproj:0.282 mm [69 -70 ] 刚体配准 内部数据集 合成形变场 脊柱CT和X-ray PDA TRE:5.65 mm [61 ] 非线性配准 LBPA40、ISBR18、CUMC12、MGH10 真实形变场 脑部MR 3D-CNN [62 ] 非线性配准 内部数据集 真实形变场 前列腺超声和MR CNN TRE=8.5 mm [63 ] Dice=0.86 非线性配准 ACDC dataset 分割监督 心脏MR CNN Dice=0.865 [64 ] 非线性配准 内部数据集 标签监督 前列腺CT和MR CNN ASD=1.58 mm [65 ] Dice=0.873 非线性配准 IBSR18、CUMC12、MGH10、IXI30 双监督学习形变场 脑部MR BIRNet Dice>0.728 (分脑区比较) [66 ] 无监督配准模型 非线性配准 ADNI、OASIS、ABIDE、ADHD200、MCIC、PPMI、HABS、Harvard GSP 脑部MR VoxelMorph Dice=0.78 [69 ] 非线性配准 Mindboggle101 脑部MR FAIM Dice=0.533(左上顶叶) [71 ] 非线性配准 ADNI 脑部MR ICNet Dice=0.88 [72 ] ASD=0.71 mm HD=12.71 mm(白质) 非线性配准 内部数据集 脑部MR ADMIR Dice=0.91 [73 ] HD=2.68 ASD=0.59 非线性配准 内部数据集 前列腺MR和超声 AirNet TRE=3.48 mm [74 ] 非线性配准 内部数据集、Sunybrook 视网膜图像、心脏MR GAN Dice=0.887/0.79HD=8.0/5.12 [75 ] (视网膜/心脏) 非线性配准 VISCERAL Anatomy3 benchmark 全身MR、CT GAN Dice=0.757 (胸部)Dice=0.783(腹部) [76 ]
U-Net是由一系列卷积和反卷积组成的编码和解码结构,通过跳跃连接实现高级语义特征和低级空间信息的融合,进而保证分割的准确度.U-Net及其变体(如Nested U-Net[83 ] 、V-Net[84 ] 、循环残差U-Net[85 ] )在医学图像分割上取得了较好的分割结果,是目前医学图像分割的主流基线模型. ...
Spatial transformer networks
1
2015
... 随着空间变换网络(spatial transformer network,STN)[67 ] 的问世,利用无监督深度学习模型进行医学图像配准成为研究热点.其配准网络框架如图4 所示. ...
ssEMnet:serial-section electron microscopy image registration using a spatial transformer network with learned features
1
2017
... Yo o I等人[68 ] 结合卷积自动编码器(convolutional auto-encoder,CAE)和STN模型,实现了神经组织显微镜图像的配准,其中CAE负责提取待配准图像与目标图像的特征,基于该特征计算相似性损失,结果表明,该种损失能取得较好的配准结果.2018年,Balakrishnan G等人[69 ] 提出VoxelMorph网络结构,以U-Net为基线模型,结合STN模块,实现了MR图像的非线性配准;随后,其对模型进行了改进,引入分割标记辅助损失,进一步提高了配准的Dice分数[70 ] .Kuang D等人[71 ] 提出空间变换模块,用于替代U-Net网络结构,在降低模型参数的前提下,实现了脑部MR图像的准确配准.Zhang J[72 ] 为了进一步提高无监督配准的准确度,除了相似度损失,还引入了变换平滑损失、反向一致性损失以及防折叠损失.其中,变化平滑损失和防折叠损失是为了保证变形场的平滑性.反向一致性损失在互换待配准图像与目标图像时,可保证变形场满足可逆关系.Tang K等人[73 ] 利用无监督网络实现了脑部MR图像的端到端配准,即网络模型同时学习了仿射变换参数和非线性变换参数. ...
VoxelMorph:a learning framework for deformable medical image registration
3
2019
... Yo o I等人[68 ] 结合卷积自动编码器(convolutional auto-encoder,CAE)和STN模型,实现了神经组织显微镜图像的配准,其中CAE负责提取待配准图像与目标图像的特征,基于该特征计算相似性损失,结果表明,该种损失能取得较好的配准结果.2018年,Balakrishnan G等人[69 ] 提出VoxelMorph网络结构,以U-Net为基线模型,结合STN模块,实现了MR图像的非线性配准;随后,其对模型进行了改进,引入分割标记辅助损失,进一步提高了配准的Dice分数[70 ] .Kuang D等人[71 ] 提出空间变换模块,用于替代U-Net网络结构,在降低模型参数的前提下,实现了脑部MR图像的准确配准.Zhang J[72 ] 为了进一步提高无监督配准的准确度,除了相似度损失,还引入了变换平滑损失、反向一致性损失以及防折叠损失.其中,变化平滑损失和防折叠损失是为了保证变形场的平滑性.反向一致性损失在互换待配准图像与目标图像时,可保证变形场满足可逆关系.Tang K等人[73 ] 利用无监督网络实现了脑部MR图像的端到端配准,即网络模型同时学习了仿射变换参数和非线性变换参数. ...
... 深度学习配准的代表性模型总结
模型类型 配准类型 数据集 变形场来源 器官 模型 评价指标 文献 有监督配准模型 刚体配准 内部数据集 合成形变场 骨骼X-ray CNN mTREproj:0.282 mm [69 -70 ] 刚体配准 内部数据集 合成形变场 脊柱CT和X-ray PDA TRE:5.65 mm [61 ] 非线性配准 LBPA40、ISBR18、CUMC12、MGH10 真实形变场 脑部MR 3D-CNN [62 ] 非线性配准 内部数据集 真实形变场 前列腺超声和MR CNN TRE=8.5 mm [63 ] Dice=0.86 非线性配准 ACDC dataset 分割监督 心脏MR CNN Dice=0.865 [64 ] 非线性配准 内部数据集 标签监督 前列腺CT和MR CNN ASD=1.58 mm [65 ] Dice=0.873 非线性配准 IBSR18、CUMC12、MGH10、IXI30 双监督学习形变场 脑部MR BIRNet Dice>0.728 (分脑区比较) [66 ] 无监督配准模型 非线性配准 ADNI、OASIS、ABIDE、ADHD200、MCIC、PPMI、HABS、Harvard GSP 脑部MR VoxelMorph Dice=0.78 [69 ] 非线性配准 Mindboggle101 脑部MR FAIM Dice=0.533(左上顶叶) [71 ] 非线性配准 ADNI 脑部MR ICNet Dice=0.88 [72 ] ASD=0.71 mm HD=12.71 mm(白质) 非线性配准 内部数据集 脑部MR ADMIR Dice=0.91 [73 ] HD=2.68 ASD=0.59 非线性配准 内部数据集 前列腺MR和超声 AirNet TRE=3.48 mm [74 ] 非线性配准 内部数据集、Sunybrook 视网膜图像、心脏MR GAN Dice=0.887/0.79HD=8.0/5.12 [75 ] (视网膜/心脏) 非线性配准 VISCERAL Anatomy3 benchmark 全身MR、CT GAN Dice=0.757 (胸部)Dice=0.783(腹部) [76 ]
U-Net是由一系列卷积和反卷积组成的编码和解码结构,通过跳跃连接实现高级语义特征和低级空间信息的融合,进而保证分割的准确度.U-Net及其变体(如Nested U-Net[83 ] 、V-Net[84 ] 、循环残差U-Net[85 ] )在医学图像分割上取得了较好的分割结果,是目前医学图像分割的主流基线模型. ...
... [
69 ]
非线性配准 Mindboggle101 脑部MR FAIM Dice=0.533(左上顶叶) [71 ] 非线性配准 ADNI 脑部MR ICNet Dice=0.88 [72 ] ASD=0.71 mm HD=12.71 mm(白质) 非线性配准 内部数据集 脑部MR ADMIR Dice=0.91 [73 ] HD=2.68 ASD=0.59 非线性配准 内部数据集 前列腺MR和超声 AirNet TRE=3.48 mm [74 ] 非线性配准 内部数据集、Sunybrook 视网膜图像、心脏MR GAN Dice=0.887/0.79HD=8.0/5.12 [75 ] (视网膜/心脏) 非线性配准 VISCERAL Anatomy3 benchmark 全身MR、CT GAN Dice=0.757 (胸部)Dice=0.783(腹部) [76 ] U-Net是由一系列卷积和反卷积组成的编码和解码结构,通过跳跃连接实现高级语义特征和低级空间信息的融合,进而保证分割的准确度.U-Net及其变体(如Nested U-Net[83 ] 、V-Net[84 ] 、循环残差U-Net[85 ] )在医学图像分割上取得了较好的分割结果,是目前医学图像分割的主流基线模型. ...
Data augmentation using learned transformations for one-shot medical image segmentation
2
2019
... Yo o I等人[68 ] 结合卷积自动编码器(convolutional auto-encoder,CAE)和STN模型,实现了神经组织显微镜图像的配准,其中CAE负责提取待配准图像与目标图像的特征,基于该特征计算相似性损失,结果表明,该种损失能取得较好的配准结果.2018年,Balakrishnan G等人[69 ] 提出VoxelMorph网络结构,以U-Net为基线模型,结合STN模块,实现了MR图像的非线性配准;随后,其对模型进行了改进,引入分割标记辅助损失,进一步提高了配准的Dice分数[70 ] .Kuang D等人[71 ] 提出空间变换模块,用于替代U-Net网络结构,在降低模型参数的前提下,实现了脑部MR图像的准确配准.Zhang J[72 ] 为了进一步提高无监督配准的准确度,除了相似度损失,还引入了变换平滑损失、反向一致性损失以及防折叠损失.其中,变化平滑损失和防折叠损失是为了保证变形场的平滑性.反向一致性损失在互换待配准图像与目标图像时,可保证变形场满足可逆关系.Tang K等人[73 ] 利用无监督网络实现了脑部MR图像的端到端配准,即网络模型同时学习了仿射变换参数和非线性变换参数. ...
... 深度学习配准的代表性模型总结
模型类型 配准类型 数据集 变形场来源 器官 模型 评价指标 文献 有监督配准模型 刚体配准 内部数据集 合成形变场 骨骼X-ray CNN mTREproj:0.282 mm [69 -70 ] 刚体配准 内部数据集 合成形变场 脊柱CT和X-ray PDA TRE:5.65 mm [61 ] 非线性配准 LBPA40、ISBR18、CUMC12、MGH10 真实形变场 脑部MR 3D-CNN [62 ] 非线性配准 内部数据集 真实形变场 前列腺超声和MR CNN TRE=8.5 mm [63 ] Dice=0.86 非线性配准 ACDC dataset 分割监督 心脏MR CNN Dice=0.865 [64 ] 非线性配准 内部数据集 标签监督 前列腺CT和MR CNN ASD=1.58 mm [65 ] Dice=0.873 非线性配准 IBSR18、CUMC12、MGH10、IXI30 双监督学习形变场 脑部MR BIRNet Dice>0.728 (分脑区比较) [66 ] 无监督配准模型 非线性配准 ADNI、OASIS、ABIDE、ADHD200、MCIC、PPMI、HABS、Harvard GSP 脑部MR VoxelMorph Dice=0.78 [69 ] 非线性配准 Mindboggle101 脑部MR FAIM Dice=0.533(左上顶叶) [71 ] 非线性配准 ADNI 脑部MR ICNet Dice=0.88 [72 ] ASD=0.71 mm HD=12.71 mm(白质) 非线性配准 内部数据集 脑部MR ADMIR Dice=0.91 [73 ] HD=2.68 ASD=0.59 非线性配准 内部数据集 前列腺MR和超声 AirNet TRE=3.48 mm [74 ] 非线性配准 内部数据集、Sunybrook 视网膜图像、心脏MR GAN Dice=0.887/0.79HD=8.0/5.12 [75 ] (视网膜/心脏) 非线性配准 VISCERAL Anatomy3 benchmark 全身MR、CT GAN Dice=0.757 (胸部)Dice=0.783(腹部) [76 ]
U-Net是由一系列卷积和反卷积组成的编码和解码结构,通过跳跃连接实现高级语义特征和低级空间信息的融合,进而保证分割的准确度.U-Net及其变体(如Nested U-Net[83 ] 、V-Net[84 ] 、循环残差U-Net[85 ] )在医学图像分割上取得了较好的分割结果,是目前医学图像分割的主流基线模型. ...
FAIM–a ConvNet method for unsupervised 3D medical image registration
2
2019
... Yo o I等人[68 ] 结合卷积自动编码器(convolutional auto-encoder,CAE)和STN模型,实现了神经组织显微镜图像的配准,其中CAE负责提取待配准图像与目标图像的特征,基于该特征计算相似性损失,结果表明,该种损失能取得较好的配准结果.2018年,Balakrishnan G等人[69 ] 提出VoxelMorph网络结构,以U-Net为基线模型,结合STN模块,实现了MR图像的非线性配准;随后,其对模型进行了改进,引入分割标记辅助损失,进一步提高了配准的Dice分数[70 ] .Kuang D等人[71 ] 提出空间变换模块,用于替代U-Net网络结构,在降低模型参数的前提下,实现了脑部MR图像的准确配准.Zhang J[72 ] 为了进一步提高无监督配准的准确度,除了相似度损失,还引入了变换平滑损失、反向一致性损失以及防折叠损失.其中,变化平滑损失和防折叠损失是为了保证变形场的平滑性.反向一致性损失在互换待配准图像与目标图像时,可保证变形场满足可逆关系.Tang K等人[73 ] 利用无监督网络实现了脑部MR图像的端到端配准,即网络模型同时学习了仿射变换参数和非线性变换参数. ...
... 深度学习配准的代表性模型总结
模型类型 配准类型 数据集 变形场来源 器官 模型 评价指标 文献 有监督配准模型 刚体配准 内部数据集 合成形变场 骨骼X-ray CNN mTREproj:0.282 mm [69 -70 ] 刚体配准 内部数据集 合成形变场 脊柱CT和X-ray PDA TRE:5.65 mm [61 ] 非线性配准 LBPA40、ISBR18、CUMC12、MGH10 真实形变场 脑部MR 3D-CNN [62 ] 非线性配准 内部数据集 真实形变场 前列腺超声和MR CNN TRE=8.5 mm [63 ] Dice=0.86 非线性配准 ACDC dataset 分割监督 心脏MR CNN Dice=0.865 [64 ] 非线性配准 内部数据集 标签监督 前列腺CT和MR CNN ASD=1.58 mm [65 ] Dice=0.873 非线性配准 IBSR18、CUMC12、MGH10、IXI30 双监督学习形变场 脑部MR BIRNet Dice>0.728 (分脑区比较) [66 ] 无监督配准模型 非线性配准 ADNI、OASIS、ABIDE、ADHD200、MCIC、PPMI、HABS、Harvard GSP 脑部MR VoxelMorph Dice=0.78 [69 ] 非线性配准 Mindboggle101 脑部MR FAIM Dice=0.533(左上顶叶) [71 ] 非线性配准 ADNI 脑部MR ICNet Dice=0.88 [72 ] ASD=0.71 mm HD=12.71 mm(白质) 非线性配准 内部数据集 脑部MR ADMIR Dice=0.91 [73 ] HD=2.68 ASD=0.59 非线性配准 内部数据集 前列腺MR和超声 AirNet TRE=3.48 mm [74 ] 非线性配准 内部数据集、Sunybrook 视网膜图像、心脏MR GAN Dice=0.887/0.79HD=8.0/5.12 [75 ] (视网膜/心脏) 非线性配准 VISCERAL Anatomy3 benchmark 全身MR、CT GAN Dice=0.757 (胸部)Dice=0.783(腹部) [76 ]
U-Net是由一系列卷积和反卷积组成的编码和解码结构,通过跳跃连接实现高级语义特征和低级空间信息的融合,进而保证分割的准确度.U-Net及其变体(如Nested U-Net[83 ] 、V-Net[84 ] 、循环残差U-Net[85 ] )在医学图像分割上取得了较好的分割结果,是目前医学图像分割的主流基线模型. ...
Inverse-consistent deep networks for unsupervised deformable image registration
2
... Yo o I等人[68 ] 结合卷积自动编码器(convolutional auto-encoder,CAE)和STN模型,实现了神经组织显微镜图像的配准,其中CAE负责提取待配准图像与目标图像的特征,基于该特征计算相似性损失,结果表明,该种损失能取得较好的配准结果.2018年,Balakrishnan G等人[69 ] 提出VoxelMorph网络结构,以U-Net为基线模型,结合STN模块,实现了MR图像的非线性配准;随后,其对模型进行了改进,引入分割标记辅助损失,进一步提高了配准的Dice分数[70 ] .Kuang D等人[71 ] 提出空间变换模块,用于替代U-Net网络结构,在降低模型参数的前提下,实现了脑部MR图像的准确配准.Zhang J[72 ] 为了进一步提高无监督配准的准确度,除了相似度损失,还引入了变换平滑损失、反向一致性损失以及防折叠损失.其中,变化平滑损失和防折叠损失是为了保证变形场的平滑性.反向一致性损失在互换待配准图像与目标图像时,可保证变形场满足可逆关系.Tang K等人[73 ] 利用无监督网络实现了脑部MR图像的端到端配准,即网络模型同时学习了仿射变换参数和非线性变换参数. ...
... 深度学习配准的代表性模型总结
模型类型 配准类型 数据集 变形场来源 器官 模型 评价指标 文献 有监督配准模型 刚体配准 内部数据集 合成形变场 骨骼X-ray CNN mTREproj:0.282 mm [69 -70 ] 刚体配准 内部数据集 合成形变场 脊柱CT和X-ray PDA TRE:5.65 mm [61 ] 非线性配准 LBPA40、ISBR18、CUMC12、MGH10 真实形变场 脑部MR 3D-CNN [62 ] 非线性配准 内部数据集 真实形变场 前列腺超声和MR CNN TRE=8.5 mm [63 ] Dice=0.86 非线性配准 ACDC dataset 分割监督 心脏MR CNN Dice=0.865 [64 ] 非线性配准 内部数据集 标签监督 前列腺CT和MR CNN ASD=1.58 mm [65 ] Dice=0.873 非线性配准 IBSR18、CUMC12、MGH10、IXI30 双监督学习形变场 脑部MR BIRNet Dice>0.728 (分脑区比较) [66 ] 无监督配准模型 非线性配准 ADNI、OASIS、ABIDE、ADHD200、MCIC、PPMI、HABS、Harvard GSP 脑部MR VoxelMorph Dice=0.78 [69 ] 非线性配准 Mindboggle101 脑部MR FAIM Dice=0.533(左上顶叶) [71 ] 非线性配准 ADNI 脑部MR ICNet Dice=0.88 [72 ] ASD=0.71 mm HD=12.71 mm(白质) 非线性配准 内部数据集 脑部MR ADMIR Dice=0.91 [73 ] HD=2.68 ASD=0.59 非线性配准 内部数据集 前列腺MR和超声 AirNet TRE=3.48 mm [74 ] 非线性配准 内部数据集、Sunybrook 视网膜图像、心脏MR GAN Dice=0.887/0.79HD=8.0/5.12 [75 ] (视网膜/心脏) 非线性配准 VISCERAL Anatomy3 benchmark 全身MR、CT GAN Dice=0.757 (胸部)Dice=0.783(腹部) [76 ]
U-Net是由一系列卷积和反卷积组成的编码和解码结构,通过跳跃连接实现高级语义特征和低级空间信息的融合,进而保证分割的准确度.U-Net及其变体(如Nested U-Net[83 ] 、V-Net[84 ] 、循环残差U-Net[85 ] )在医学图像分割上取得了较好的分割结果,是目前医学图像分割的主流基线模型. ...
ADMIR–affine and deformable medical image registration for drug-addicted brain images
2
2020
... Yo o I等人[68 ] 结合卷积自动编码器(convolutional auto-encoder,CAE)和STN模型,实现了神经组织显微镜图像的配准,其中CAE负责提取待配准图像与目标图像的特征,基于该特征计算相似性损失,结果表明,该种损失能取得较好的配准结果.2018年,Balakrishnan G等人[69 ] 提出VoxelMorph网络结构,以U-Net为基线模型,结合STN模块,实现了MR图像的非线性配准;随后,其对模型进行了改进,引入分割标记辅助损失,进一步提高了配准的Dice分数[70 ] .Kuang D等人[71 ] 提出空间变换模块,用于替代U-Net网络结构,在降低模型参数的前提下,实现了脑部MR图像的准确配准.Zhang J[72 ] 为了进一步提高无监督配准的准确度,除了相似度损失,还引入了变换平滑损失、反向一致性损失以及防折叠损失.其中,变化平滑损失和防折叠损失是为了保证变形场的平滑性.反向一致性损失在互换待配准图像与目标图像时,可保证变形场满足可逆关系.Tang K等人[73 ] 利用无监督网络实现了脑部MR图像的端到端配准,即网络模型同时学习了仿射变换参数和非线性变换参数. ...
... 深度学习配准的代表性模型总结
模型类型 配准类型 数据集 变形场来源 器官 模型 评价指标 文献 有监督配准模型 刚体配准 内部数据集 合成形变场 骨骼X-ray CNN mTREproj:0.282 mm [69 -70 ] 刚体配准 内部数据集 合成形变场 脊柱CT和X-ray PDA TRE:5.65 mm [61 ] 非线性配准 LBPA40、ISBR18、CUMC12、MGH10 真实形变场 脑部MR 3D-CNN [62 ] 非线性配准 内部数据集 真实形变场 前列腺超声和MR CNN TRE=8.5 mm [63 ] Dice=0.86 非线性配准 ACDC dataset 分割监督 心脏MR CNN Dice=0.865 [64 ] 非线性配准 内部数据集 标签监督 前列腺CT和MR CNN ASD=1.58 mm [65 ] Dice=0.873 非线性配准 IBSR18、CUMC12、MGH10、IXI30 双监督学习形变场 脑部MR BIRNet Dice>0.728 (分脑区比较) [66 ] 无监督配准模型 非线性配准 ADNI、OASIS、ABIDE、ADHD200、MCIC、PPMI、HABS、Harvard GSP 脑部MR VoxelMorph Dice=0.78 [69 ] 非线性配准 Mindboggle101 脑部MR FAIM Dice=0.533(左上顶叶) [71 ] 非线性配准 ADNI 脑部MR ICNet Dice=0.88 [72 ] ASD=0.71 mm HD=12.71 mm(白质) 非线性配准 内部数据集 脑部MR ADMIR Dice=0.91 [73 ] HD=2.68 ASD=0.59 非线性配准 内部数据集 前列腺MR和超声 AirNet TRE=3.48 mm [74 ] 非线性配准 内部数据集、Sunybrook 视网膜图像、心脏MR GAN Dice=0.887/0.79HD=8.0/5.12 [75 ] (视网膜/心脏) 非线性配准 VISCERAL Anatomy3 benchmark 全身MR、CT GAN Dice=0.757 (胸部)Dice=0.783(腹部) [76 ]
U-Net是由一系列卷积和反卷积组成的编码和解码结构,通过跳跃连接实现高级语义特征和低级空间信息的融合,进而保证分割的准确度.U-Net及其变体(如Nested U-Net[83 ] 、V-Net[84 ] 、循环残差U-Net[85 ] )在医学图像分割上取得了较好的分割结果,是目前医学图像分割的主流基线模型. ...
Adversarial image registration with application for MR and TRUS image fusion
2
2018
... 除了基于CNN模型的无监督配准,采用GAN模型进行配准也已成为一种研究趋势,即采用条件生成对抗网络进行医学图像配准.其中,生成器用来生成变换参数或者配准后的图像,判别器用于对配准图像进行鉴别.通常在生成器与判别器之间插入STN模块,以进行端到端训练.目前,基于GAN模型的医学图像配准有较多的应用,如前列腺MR图像与超声图像配准[74 ] ,以CycleGAN为基线模型的多模态视网膜图像、单模态MR图像配准[75 ] ,CT图像和MR图像配准[76 ] 等.在基于GAN的医学图像配准中,GAN模型或者起到正则化的作用,用来调节变形场及配准图像,或者用来进行图像转换,利用交叉域配准提高配准的性能.表1 总结了典型的无监督配准模型和有监督配准模型. ...
... 深度学习配准的代表性模型总结
模型类型 配准类型 数据集 变形场来源 器官 模型 评价指标 文献 有监督配准模型 刚体配准 内部数据集 合成形变场 骨骼X-ray CNN mTREproj:0.282 mm [69 -70 ] 刚体配准 内部数据集 合成形变场 脊柱CT和X-ray PDA TRE:5.65 mm [61 ] 非线性配准 LBPA40、ISBR18、CUMC12、MGH10 真实形变场 脑部MR 3D-CNN [62 ] 非线性配准 内部数据集 真实形变场 前列腺超声和MR CNN TRE=8.5 mm [63 ] Dice=0.86 非线性配准 ACDC dataset 分割监督 心脏MR CNN Dice=0.865 [64 ] 非线性配准 内部数据集 标签监督 前列腺CT和MR CNN ASD=1.58 mm [65 ] Dice=0.873 非线性配准 IBSR18、CUMC12、MGH10、IXI30 双监督学习形变场 脑部MR BIRNet Dice>0.728 (分脑区比较) [66 ] 无监督配准模型 非线性配准 ADNI、OASIS、ABIDE、ADHD200、MCIC、PPMI、HABS、Harvard GSP 脑部MR VoxelMorph Dice=0.78 [69 ] 非线性配准 Mindboggle101 脑部MR FAIM Dice=0.533(左上顶叶) [71 ] 非线性配准 ADNI 脑部MR ICNet Dice=0.88 [72 ] ASD=0.71 mm HD=12.71 mm(白质) 非线性配准 内部数据集 脑部MR ADMIR Dice=0.91 [73 ] HD=2.68 ASD=0.59 非线性配准 内部数据集 前列腺MR和超声 AirNet TRE=3.48 mm [74 ] 非线性配准 内部数据集、Sunybrook 视网膜图像、心脏MR GAN Dice=0.887/0.79HD=8.0/5.12 [75 ] (视网膜/心脏) 非线性配准 VISCERAL Anatomy3 benchmark 全身MR、CT GAN Dice=0.757 (胸部)Dice=0.783(腹部) [76 ]
U-Net是由一系列卷积和反卷积组成的编码和解码结构,通过跳跃连接实现高级语义特征和低级空间信息的融合,进而保证分割的准确度.U-Net及其变体(如Nested U-Net[83 ] 、V-Net[84 ] 、循环残差U-Net[85 ] )在医学图像分割上取得了较好的分割结果,是目前医学图像分割的主流基线模型. ...
Deformable medical image registration using generative adversarial networks
2
2018
... 除了基于CNN模型的无监督配准,采用GAN模型进行配准也已成为一种研究趋势,即采用条件生成对抗网络进行医学图像配准.其中,生成器用来生成变换参数或者配准后的图像,判别器用于对配准图像进行鉴别.通常在生成器与判别器之间插入STN模块,以进行端到端训练.目前,基于GAN模型的医学图像配准有较多的应用,如前列腺MR图像与超声图像配准[74 ] ,以CycleGAN为基线模型的多模态视网膜图像、单模态MR图像配准[75 ] ,CT图像和MR图像配准[76 ] 等.在基于GAN的医学图像配准中,GAN模型或者起到正则化的作用,用来调节变形场及配准图像,或者用来进行图像转换,利用交叉域配准提高配准的性能.表1 总结了典型的无监督配准模型和有监督配准模型. ...
... 深度学习配准的代表性模型总结
模型类型 配准类型 数据集 变形场来源 器官 模型 评价指标 文献 有监督配准模型 刚体配准 内部数据集 合成形变场 骨骼X-ray CNN mTREproj:0.282 mm [69 -70 ] 刚体配准 内部数据集 合成形变场 脊柱CT和X-ray PDA TRE:5.65 mm [61 ] 非线性配准 LBPA40、ISBR18、CUMC12、MGH10 真实形变场 脑部MR 3D-CNN [62 ] 非线性配准 内部数据集 真实形变场 前列腺超声和MR CNN TRE=8.5 mm [63 ] Dice=0.86 非线性配准 ACDC dataset 分割监督 心脏MR CNN Dice=0.865 [64 ] 非线性配准 内部数据集 标签监督 前列腺CT和MR CNN ASD=1.58 mm [65 ] Dice=0.873 非线性配准 IBSR18、CUMC12、MGH10、IXI30 双监督学习形变场 脑部MR BIRNet Dice>0.728 (分脑区比较) [66 ] 无监督配准模型 非线性配准 ADNI、OASIS、ABIDE、ADHD200、MCIC、PPMI、HABS、Harvard GSP 脑部MR VoxelMorph Dice=0.78 [69 ] 非线性配准 Mindboggle101 脑部MR FAIM Dice=0.533(左上顶叶) [71 ] 非线性配准 ADNI 脑部MR ICNet Dice=0.88 [72 ] ASD=0.71 mm HD=12.71 mm(白质) 非线性配准 内部数据集 脑部MR ADMIR Dice=0.91 [73 ] HD=2.68 ASD=0.59 非线性配准 内部数据集 前列腺MR和超声 AirNet TRE=3.48 mm [74 ] 非线性配准 内部数据集、Sunybrook 视网膜图像、心脏MR GAN Dice=0.887/0.79HD=8.0/5.12 [75 ] (视网膜/心脏) 非线性配准 VISCERAL Anatomy3 benchmark 全身MR、CT GAN Dice=0.757 (胸部)Dice=0.783(腹部) [76 ]
U-Net是由一系列卷积和反卷积组成的编码和解码结构,通过跳跃连接实现高级语义特征和低级空间信息的融合,进而保证分割的准确度.U-Net及其变体(如Nested U-Net[83 ] 、V-Net[84 ] 、循环残差U-Net[85 ] )在医学图像分割上取得了较好的分割结果,是目前医学图像分割的主流基线模型. ...
Generative adversarial networks for MR-CT deformable image registration
2
... 除了基于CNN模型的无监督配准,采用GAN模型进行配准也已成为一种研究趋势,即采用条件生成对抗网络进行医学图像配准.其中,生成器用来生成变换参数或者配准后的图像,判别器用于对配准图像进行鉴别.通常在生成器与判别器之间插入STN模块,以进行端到端训练.目前,基于GAN模型的医学图像配准有较多的应用,如前列腺MR图像与超声图像配准[74 ] ,以CycleGAN为基线模型的多模态视网膜图像、单模态MR图像配准[75 ] ,CT图像和MR图像配准[76 ] 等.在基于GAN的医学图像配准中,GAN模型或者起到正则化的作用,用来调节变形场及配准图像,或者用来进行图像转换,利用交叉域配准提高配准的性能.表1 总结了典型的无监督配准模型和有监督配准模型. ...
... 深度学习配准的代表性模型总结
模型类型 配准类型 数据集 变形场来源 器官 模型 评价指标 文献 有监督配准模型 刚体配准 内部数据集 合成形变场 骨骼X-ray CNN mTREproj:0.282 mm [69 -70 ] 刚体配准 内部数据集 合成形变场 脊柱CT和X-ray PDA TRE:5.65 mm [61 ] 非线性配准 LBPA40、ISBR18、CUMC12、MGH10 真实形变场 脑部MR 3D-CNN [62 ] 非线性配准 内部数据集 真实形变场 前列腺超声和MR CNN TRE=8.5 mm [63 ] Dice=0.86 非线性配准 ACDC dataset 分割监督 心脏MR CNN Dice=0.865 [64 ] 非线性配准 内部数据集 标签监督 前列腺CT和MR CNN ASD=1.58 mm [65 ] Dice=0.873 非线性配准 IBSR18、CUMC12、MGH10、IXI30 双监督学习形变场 脑部MR BIRNet Dice>0.728 (分脑区比较) [66 ] 无监督配准模型 非线性配准 ADNI、OASIS、ABIDE、ADHD200、MCIC、PPMI、HABS、Harvard GSP 脑部MR VoxelMorph Dice=0.78 [69 ] 非线性配准 Mindboggle101 脑部MR FAIM Dice=0.533(左上顶叶) [71 ] 非线性配准 ADNI 脑部MR ICNet Dice=0.88 [72 ] ASD=0.71 mm HD=12.71 mm(白质) 非线性配准 内部数据集 脑部MR ADMIR Dice=0.91 [73 ] HD=2.68 ASD=0.59 非线性配准 内部数据集 前列腺MR和超声 AirNet TRE=3.48 mm [74 ] 非线性配准 内部数据集、Sunybrook 视网膜图像、心脏MR GAN Dice=0.887/0.79HD=8.0/5.12 [75 ] (视网膜/心脏) 非线性配准 VISCERAL Anatomy3 benchmark 全身MR、CT GAN Dice=0.757 (胸部)Dice=0.783(腹部) [76 ]
U-Net是由一系列卷积和反卷积组成的编码和解码结构,通过跳跃连接实现高级语义特征和低级空间信息的融合,进而保证分割的准确度.U-Net及其变体(如Nested U-Net[83 ] 、V-Net[84 ] 、循环残差U-Net[85 ] )在医学图像分割上取得了较好的分割结果,是目前医学图像分割的主流基线模型. ...
Deep learning for multi-task medical image segmentation in multiple modalities
2
2016
... 医学图像分割是计算机辅助诊断的关键步骤,是进行感兴趣区域定量分析的前提.随着深度学习在语义分割中的快速发展,将自然图像分割模型扩展到医学图像已成为主要趋势.在医学图像分割中,采用的主流网络框架有CNN、全卷积网络(full convolutional network,FCN)、U-Net、循环神经网络(recurrent neural network,RNN)和GAN模型.目前常用的医学图像分割模型包括2.5D CNN,即分别在横断面、失状面、冠状面上使用2D卷积进行分割,在节约计算成本的前提下,充分利用三维空间的邻域信息提高分割的准确度[77 ] .FCN是深度学习语义分割的初始模型,通过全卷积神经网络和上采样操作,可以粗略地获得语义分割结果.为了提高分割细节,采用跳跃连接将低层的空间信息和高层的语义信息相结合,以提高图像分割的细腻度.FCN[78 ] 及其变体(如并行FCN[79 ] 、焦点FCN[80 ] 、多分支FCN[81 ] 、循环FCN[82 ] 等)已被广泛应用到各种医学图像分割任务中,且表现良好. ...
... 典型的深度学习医学图像分割方法
数据集 模型 器官 损失 精度 文献 内部数据集 2.5D CNN 脑部、乳腺MR,心脏血管造影图像 交叉熵损失 [77 ] 2016 MICCAI IVDs挑战赛数据集 3D FCN 椎间盘MR 加权交叉熵损失 Dice=0.912 [78 ] 2017 MICCAI grand challenge on infant brain MRI Multistream 3D FCN 脑部MR 似然损失 Dice=0.954 [81 ] ASD=0.127 MHD=9.62 (脑脊液) MICCAI 2009 LV Segmentation Challenge Recurrent FCN 心脏MR 交叉熵损失 Dice=0.90 [82 ] APD=2.05 TCIA(ProstateX,QINHEADNECK) U-Net 多器官 Combo损失 Dice=0.92 [92 ] DRIVE、STARE、CHASH_DB1 R2 U-Net 多器官 二值交叉熵损失 Dice=0.86 [85 ] PROMISE 2012 challenge V-Net 前列腺MR Dice损失 Dice=0.87 [84 ] HD=5.71 mm DRIVE Dataset、ISIC 2018 Bi-LSTM 多器官 二值交叉熵损失 F1-Score>0.99 [87 ] MICCAI BRATS 2013,2015 SegGAN 头部MR 多尺度L1 范数损失 Dice=0.84/0.85(BRATS 2013数据集/BRATS 2015数据集) [100 ] INbreast dataset,DDSM dataset cGAN 乳腺钼靶图像 Dice以及对抗损失 Dice=0.94(INbreast) [90 ]
4.2 医学图像目标识别 医学图像目标识别也属于临床诊断的一种,即在一幅图像中标记出可能病变的区域,并对其进行分类,如图5 所示. ...
3D multi-scale FCN with random modality voxel dropout learning for intervertebral disc localization and segmentation from multi-modality MR images
2
2018
... 医学图像分割是计算机辅助诊断的关键步骤,是进行感兴趣区域定量分析的前提.随着深度学习在语义分割中的快速发展,将自然图像分割模型扩展到医学图像已成为主要趋势.在医学图像分割中,采用的主流网络框架有CNN、全卷积网络(full convolutional network,FCN)、U-Net、循环神经网络(recurrent neural network,RNN)和GAN模型.目前常用的医学图像分割模型包括2.5D CNN,即分别在横断面、失状面、冠状面上使用2D卷积进行分割,在节约计算成本的前提下,充分利用三维空间的邻域信息提高分割的准确度[77 ] .FCN是深度学习语义分割的初始模型,通过全卷积神经网络和上采样操作,可以粗略地获得语义分割结果.为了提高分割细节,采用跳跃连接将低层的空间信息和高层的语义信息相结合,以提高图像分割的细腻度.FCN[78 ] 及其变体(如并行FCN[79 ] 、焦点FCN[80 ] 、多分支FCN[81 ] 、循环FCN[82 ] 等)已被广泛应用到各种医学图像分割任务中,且表现良好. ...
... 典型的深度学习医学图像分割方法
数据集 模型 器官 损失 精度 文献 内部数据集 2.5D CNN 脑部、乳腺MR,心脏血管造影图像 交叉熵损失 [77 ] 2016 MICCAI IVDs挑战赛数据集 3D FCN 椎间盘MR 加权交叉熵损失 Dice=0.912 [78 ] 2017 MICCAI grand challenge on infant brain MRI Multistream 3D FCN 脑部MR 似然损失 Dice=0.954 [81 ] ASD=0.127 MHD=9.62 (脑脊液) MICCAI 2009 LV Segmentation Challenge Recurrent FCN 心脏MR 交叉熵损失 Dice=0.90 [82 ] APD=2.05 TCIA(ProstateX,QINHEADNECK) U-Net 多器官 Combo损失 Dice=0.92 [92 ] DRIVE、STARE、CHASH_DB1 R2 U-Net 多器官 二值交叉熵损失 Dice=0.86 [85 ] PROMISE 2012 challenge V-Net 前列腺MR Dice损失 Dice=0.87 [84 ] HD=5.71 mm DRIVE Dataset、ISIC 2018 Bi-LSTM 多器官 二值交叉熵损失 F1-Score>0.99 [87 ] MICCAI BRATS 2013,2015 SegGAN 头部MR 多尺度L1 范数损失 Dice=0.84/0.85(BRATS 2013数据集/BRATS 2015数据集) [100 ] INbreast dataset,DDSM dataset cGAN 乳腺钼靶图像 Dice以及对抗损失 Dice=0.94(INbreast) [90 ]
4.2 医学图像目标识别 医学图像目标识别也属于临床诊断的一种,即在一幅图像中标记出可能病变的区域,并对其进行分类,如图5 所示. ...
Stacked fully convolutional networks with multichannel learning:application to medical image segmentation
1
2017
... 医学图像分割是计算机辅助诊断的关键步骤,是进行感兴趣区域定量分析的前提.随着深度学习在语义分割中的快速发展,将自然图像分割模型扩展到医学图像已成为主要趋势.在医学图像分割中,采用的主流网络框架有CNN、全卷积网络(full convolutional network,FCN)、U-Net、循环神经网络(recurrent neural network,RNN)和GAN模型.目前常用的医学图像分割模型包括2.5D CNN,即分别在横断面、失状面、冠状面上使用2D卷积进行分割,在节约计算成本的前提下,充分利用三维空间的邻域信息提高分割的准确度[77 ] .FCN是深度学习语义分割的初始模型,通过全卷积神经网络和上采样操作,可以粗略地获得语义分割结果.为了提高分割细节,采用跳跃连接将低层的空间信息和高层的语义信息相结合,以提高图像分割的细腻度.FCN[78 ] 及其变体(如并行FCN[79 ] 、焦点FCN[80 ] 、多分支FCN[81 ] 、循环FCN[82 ] 等)已被广泛应用到各种医学图像分割任务中,且表现良好. ...
Focal FCN:towards small object segmentation with limited training data
1
... 医学图像分割是计算机辅助诊断的关键步骤,是进行感兴趣区域定量分析的前提.随着深度学习在语义分割中的快速发展,将自然图像分割模型扩展到医学图像已成为主要趋势.在医学图像分割中,采用的主流网络框架有CNN、全卷积网络(full convolutional network,FCN)、U-Net、循环神经网络(recurrent neural network,RNN)和GAN模型.目前常用的医学图像分割模型包括2.5D CNN,即分别在横断面、失状面、冠状面上使用2D卷积进行分割,在节约计算成本的前提下,充分利用三维空间的邻域信息提高分割的准确度[77 ] .FCN是深度学习语义分割的初始模型,通过全卷积神经网络和上采样操作,可以粗略地获得语义分割结果.为了提高分割细节,采用跳跃连接将低层的空间信息和高层的语义信息相结合,以提高图像分割的细腻度.FCN[78 ] 及其变体(如并行FCN[79 ] 、焦点FCN[80 ] 、多分支FCN[81 ] 、循环FCN[82 ] 等)已被广泛应用到各种医学图像分割任务中,且表现良好. ...
Multistream 3D FCN with multi-scale deep supervision for multi-modality isointense infant brain MR image segmentation
2
2018
... 医学图像分割是计算机辅助诊断的关键步骤,是进行感兴趣区域定量分析的前提.随着深度学习在语义分割中的快速发展,将自然图像分割模型扩展到医学图像已成为主要趋势.在医学图像分割中,采用的主流网络框架有CNN、全卷积网络(full convolutional network,FCN)、U-Net、循环神经网络(recurrent neural network,RNN)和GAN模型.目前常用的医学图像分割模型包括2.5D CNN,即分别在横断面、失状面、冠状面上使用2D卷积进行分割,在节约计算成本的前提下,充分利用三维空间的邻域信息提高分割的准确度[77 ] .FCN是深度学习语义分割的初始模型,通过全卷积神经网络和上采样操作,可以粗略地获得语义分割结果.为了提高分割细节,采用跳跃连接将低层的空间信息和高层的语义信息相结合,以提高图像分割的细腻度.FCN[78 ] 及其变体(如并行FCN[79 ] 、焦点FCN[80 ] 、多分支FCN[81 ] 、循环FCN[82 ] 等)已被广泛应用到各种医学图像分割任务中,且表现良好. ...
... 典型的深度学习医学图像分割方法
数据集 模型 器官 损失 精度 文献 内部数据集 2.5D CNN 脑部、乳腺MR,心脏血管造影图像 交叉熵损失 [77 ] 2016 MICCAI IVDs挑战赛数据集 3D FCN 椎间盘MR 加权交叉熵损失 Dice=0.912 [78 ] 2017 MICCAI grand challenge on infant brain MRI Multistream 3D FCN 脑部MR 似然损失 Dice=0.954 [81 ] ASD=0.127 MHD=9.62 (脑脊液) MICCAI 2009 LV Segmentation Challenge Recurrent FCN 心脏MR 交叉熵损失 Dice=0.90 [82 ] APD=2.05 TCIA(ProstateX,QINHEADNECK) U-Net 多器官 Combo损失 Dice=0.92 [92 ] DRIVE、STARE、CHASH_DB1 R2 U-Net 多器官 二值交叉熵损失 Dice=0.86 [85 ] PROMISE 2012 challenge V-Net 前列腺MR Dice损失 Dice=0.87 [84 ] HD=5.71 mm DRIVE Dataset、ISIC 2018 Bi-LSTM 多器官 二值交叉熵损失 F1-Score>0.99 [87 ] MICCAI BRATS 2013,2015 SegGAN 头部MR 多尺度L1 范数损失 Dice=0.84/0.85(BRATS 2013数据集/BRATS 2015数据集) [100 ] INbreast dataset,DDSM dataset cGAN 乳腺钼靶图像 Dice以及对抗损失 Dice=0.94(INbreast) [90 ]
4.2 医学图像目标识别 医学图像目标识别也属于临床诊断的一种,即在一幅图像中标记出可能病变的区域,并对其进行分类,如图5 所示. ...
Recurrent fully convolutional neural networks for multi-slice MRI cardiac segmentation
2
2016
... 医学图像分割是计算机辅助诊断的关键步骤,是进行感兴趣区域定量分析的前提.随着深度学习在语义分割中的快速发展,将自然图像分割模型扩展到医学图像已成为主要趋势.在医学图像分割中,采用的主流网络框架有CNN、全卷积网络(full convolutional network,FCN)、U-Net、循环神经网络(recurrent neural network,RNN)和GAN模型.目前常用的医学图像分割模型包括2.5D CNN,即分别在横断面、失状面、冠状面上使用2D卷积进行分割,在节约计算成本的前提下,充分利用三维空间的邻域信息提高分割的准确度[77 ] .FCN是深度学习语义分割的初始模型,通过全卷积神经网络和上采样操作,可以粗略地获得语义分割结果.为了提高分割细节,采用跳跃连接将低层的空间信息和高层的语义信息相结合,以提高图像分割的细腻度.FCN[78 ] 及其变体(如并行FCN[79 ] 、焦点FCN[80 ] 、多分支FCN[81 ] 、循环FCN[82 ] 等)已被广泛应用到各种医学图像分割任务中,且表现良好. ...
... 典型的深度学习医学图像分割方法
数据集 模型 器官 损失 精度 文献 内部数据集 2.5D CNN 脑部、乳腺MR,心脏血管造影图像 交叉熵损失 [77 ] 2016 MICCAI IVDs挑战赛数据集 3D FCN 椎间盘MR 加权交叉熵损失 Dice=0.912 [78 ] 2017 MICCAI grand challenge on infant brain MRI Multistream 3D FCN 脑部MR 似然损失 Dice=0.954 [81 ] ASD=0.127 MHD=9.62 (脑脊液) MICCAI 2009 LV Segmentation Challenge Recurrent FCN 心脏MR 交叉熵损失 Dice=0.90 [82 ] APD=2.05 TCIA(ProstateX,QINHEADNECK) U-Net 多器官 Combo损失 Dice=0.92 [92 ] DRIVE、STARE、CHASH_DB1 R2 U-Net 多器官 二值交叉熵损失 Dice=0.86 [85 ] PROMISE 2012 challenge V-Net 前列腺MR Dice损失 Dice=0.87 [84 ] HD=5.71 mm DRIVE Dataset、ISIC 2018 Bi-LSTM 多器官 二值交叉熵损失 F1-Score>0.99 [87 ] MICCAI BRATS 2013,2015 SegGAN 头部MR 多尺度L1 范数损失 Dice=0.84/0.85(BRATS 2013数据集/BRATS 2015数据集) [100 ] INbreast dataset,DDSM dataset cGAN 乳腺钼靶图像 Dice以及对抗损失 Dice=0.94(INbreast) [90 ]
4.2 医学图像目标识别 医学图像目标识别也属于临床诊断的一种,即在一幅图像中标记出可能病变的区域,并对其进行分类,如图5 所示. ...
Unet++:a nested U-Net architecture for medical image segmentation
1
2018
... U-Net是由一系列卷积和反卷积组成的编码和解码结构,通过跳跃连接实现高级语义特征和低级空间信息的融合,进而保证分割的准确度.U-Net及其变体(如Nested U-Net[83 ] 、V-Net[84 ] 、循环残差U-Net[85 ] )在医学图像分割上取得了较好的分割结果,是目前医学图像分割的主流基线模型. ...
V-Net:fully convolutional neural networks for volumetric medical image segmentation
2
2016
... U-Net是由一系列卷积和反卷积组成的编码和解码结构,通过跳跃连接实现高级语义特征和低级空间信息的融合,进而保证分割的准确度.U-Net及其变体(如Nested U-Net[83 ] 、V-Net[84 ] 、循环残差U-Net[85 ] )在医学图像分割上取得了较好的分割结果,是目前医学图像分割的主流基线模型. ...
... 典型的深度学习医学图像分割方法
数据集 模型 器官 损失 精度 文献 内部数据集 2.5D CNN 脑部、乳腺MR,心脏血管造影图像 交叉熵损失 [77 ] 2016 MICCAI IVDs挑战赛数据集 3D FCN 椎间盘MR 加权交叉熵损失 Dice=0.912 [78 ] 2017 MICCAI grand challenge on infant brain MRI Multistream 3D FCN 脑部MR 似然损失 Dice=0.954 [81 ] ASD=0.127 MHD=9.62 (脑脊液) MICCAI 2009 LV Segmentation Challenge Recurrent FCN 心脏MR 交叉熵损失 Dice=0.90 [82 ] APD=2.05 TCIA(ProstateX,QINHEADNECK) U-Net 多器官 Combo损失 Dice=0.92 [92 ] DRIVE、STARE、CHASH_DB1 R2 U-Net 多器官 二值交叉熵损失 Dice=0.86 [85 ] PROMISE 2012 challenge V-Net 前列腺MR Dice损失 Dice=0.87 [84 ] HD=5.71 mm DRIVE Dataset、ISIC 2018 Bi-LSTM 多器官 二值交叉熵损失 F1-Score>0.99 [87 ] MICCAI BRATS 2013,2015 SegGAN 头部MR 多尺度L1 范数损失 Dice=0.84/0.85(BRATS 2013数据集/BRATS 2015数据集) [100 ] INbreast dataset,DDSM dataset cGAN 乳腺钼靶图像 Dice以及对抗损失 Dice=0.94(INbreast) [90 ]
4.2 医学图像目标识别 医学图像目标识别也属于临床诊断的一种,即在一幅图像中标记出可能病变的区域,并对其进行分类,如图5 所示. ...
Recurrent residual convolutional neural network based on U-Net (R2UNet) for medical image segmentation
2
... U-Net是由一系列卷积和反卷积组成的编码和解码结构,通过跳跃连接实现高级语义特征和低级空间信息的融合,进而保证分割的准确度.U-Net及其变体(如Nested U-Net[83 ] 、V-Net[84 ] 、循环残差U-Net[85 ] )在医学图像分割上取得了较好的分割结果,是目前医学图像分割的主流基线模型. ...
... 典型的深度学习医学图像分割方法
数据集 模型 器官 损失 精度 文献 内部数据集 2.5D CNN 脑部、乳腺MR,心脏血管造影图像 交叉熵损失 [77 ] 2016 MICCAI IVDs挑战赛数据集 3D FCN 椎间盘MR 加权交叉熵损失 Dice=0.912 [78 ] 2017 MICCAI grand challenge on infant brain MRI Multistream 3D FCN 脑部MR 似然损失 Dice=0.954 [81 ] ASD=0.127 MHD=9.62 (脑脊液) MICCAI 2009 LV Segmentation Challenge Recurrent FCN 心脏MR 交叉熵损失 Dice=0.90 [82 ] APD=2.05 TCIA(ProstateX,QINHEADNECK) U-Net 多器官 Combo损失 Dice=0.92 [92 ] DRIVE、STARE、CHASH_DB1 R2 U-Net 多器官 二值交叉熵损失 Dice=0.86 [85 ] PROMISE 2012 challenge V-Net 前列腺MR Dice损失 Dice=0.87 [84 ] HD=5.71 mm DRIVE Dataset、ISIC 2018 Bi-LSTM 多器官 二值交叉熵损失 F1-Score>0.99 [87 ] MICCAI BRATS 2013,2015 SegGAN 头部MR 多尺度L1 范数损失 Dice=0.84/0.85(BRATS 2013数据集/BRATS 2015数据集) [100 ] INbreast dataset,DDSM dataset cGAN 乳腺钼靶图像 Dice以及对抗损失 Dice=0.94(INbreast) [90 ]
4.2 医学图像目标识别 医学图像目标识别也属于临床诊断的一种,即在一幅图像中标记出可能病变的区域,并对其进行分类,如图5 所示. ...
Spatial clockwork recurrent neural network for muscle perimysium segmentation
1
2016
... RNN类分割模型主要考虑医学图像分割中切片和切片之间的上下文联系,进而将切片作为序列信息输入RNN及其变体中,从而实现准确分割.典型的模型有CW-RNN(clockwork RNN)[86 ] 和上下文LSTM模型[87 ] ,其通过抓取相邻切片的相互关系,锐化分割边缘.在此基础上, Chen J X等人[88 ] 提出双向上下文LSTM模型——BDC-LSTM,即在横断面双向、矢状面双向和冠状面双向上学习上下文关系,其结果比采用多尺度分割的金字塔LSTM模型要好. ...
Bi-directional ConvLSTM U-net with densley connected convolutions
2
2019
... RNN类分割模型主要考虑医学图像分割中切片和切片之间的上下文联系,进而将切片作为序列信息输入RNN及其变体中,从而实现准确分割.典型的模型有CW-RNN(clockwork RNN)[86 ] 和上下文LSTM模型[87 ] ,其通过抓取相邻切片的相互关系,锐化分割边缘.在此基础上, Chen J X等人[88 ] 提出双向上下文LSTM模型——BDC-LSTM,即在横断面双向、矢状面双向和冠状面双向上学习上下文关系,其结果比采用多尺度分割的金字塔LSTM模型要好. ...
... 典型的深度学习医学图像分割方法
数据集 模型 器官 损失 精度 文献 内部数据集 2.5D CNN 脑部、乳腺MR,心脏血管造影图像 交叉熵损失 [77 ] 2016 MICCAI IVDs挑战赛数据集 3D FCN 椎间盘MR 加权交叉熵损失 Dice=0.912 [78 ] 2017 MICCAI grand challenge on infant brain MRI Multistream 3D FCN 脑部MR 似然损失 Dice=0.954 [81 ] ASD=0.127 MHD=9.62 (脑脊液) MICCAI 2009 LV Segmentation Challenge Recurrent FCN 心脏MR 交叉熵损失 Dice=0.90 [82 ] APD=2.05 TCIA(ProstateX,QINHEADNECK) U-Net 多器官 Combo损失 Dice=0.92 [92 ] DRIVE、STARE、CHASH_DB1 R2 U-Net 多器官 二值交叉熵损失 Dice=0.86 [85 ] PROMISE 2012 challenge V-Net 前列腺MR Dice损失 Dice=0.87 [84 ] HD=5.71 mm DRIVE Dataset、ISIC 2018 Bi-LSTM 多器官 二值交叉熵损失 F1-Score>0.99 [87 ] MICCAI BRATS 2013,2015 SegGAN 头部MR 多尺度L1 范数损失 Dice=0.84/0.85(BRATS 2013数据集/BRATS 2015数据集) [100 ] INbreast dataset,DDSM dataset cGAN 乳腺钼靶图像 Dice以及对抗损失 Dice=0.94(INbreast) [90 ]
4.2 医学图像目标识别 医学图像目标识别也属于临床诊断的一种,即在一幅图像中标记出可能病变的区域,并对其进行分类,如图5 所示. ...
Combining fully convolutional and recurrent neural networks for 3D biomedical image segmentation
1
2016
... RNN类分割模型主要考虑医学图像分割中切片和切片之间的上下文联系,进而将切片作为序列信息输入RNN及其变体中,从而实现准确分割.典型的模型有CW-RNN(clockwork RNN)[86 ] 和上下文LSTM模型[87 ] ,其通过抓取相邻切片的相互关系,锐化分割边缘.在此基础上, Chen J X等人[88 ] 提出双向上下文LSTM模型——BDC-LSTM,即在横断面双向、矢状面双向和冠状面双向上学习上下文关系,其结果比采用多尺度分割的金字塔LSTM模型要好. ...
SegAN:adversarial network with multi-scale L1 loss for medical image segmentation
2018
Breast tumor segmentation and shape classification in mammograms using generative adversarial and convolutional neural network
1
2020
... 典型的深度学习医学图像分割方法
数据集 模型 器官 损失 精度 文献 内部数据集 2.5D CNN 脑部、乳腺MR,心脏血管造影图像 交叉熵损失 [77 ] 2016 MICCAI IVDs挑战赛数据集 3D FCN 椎间盘MR 加权交叉熵损失 Dice=0.912 [78 ] 2017 MICCAI grand challenge on infant brain MRI Multistream 3D FCN 脑部MR 似然损失 Dice=0.954 [81 ] ASD=0.127 MHD=9.62 (脑脊液) MICCAI 2009 LV Segmentation Challenge Recurrent FCN 心脏MR 交叉熵损失 Dice=0.90 [82 ] APD=2.05 TCIA(ProstateX,QINHEADNECK) U-Net 多器官 Combo损失 Dice=0.92 [92 ] DRIVE、STARE、CHASH_DB1 R2 U-Net 多器官 二值交叉熵损失 Dice=0.86 [85 ] PROMISE 2012 challenge V-Net 前列腺MR Dice损失 Dice=0.87 [84 ] HD=5.71 mm DRIVE Dataset、ISIC 2018 Bi-LSTM 多器官 二值交叉熵损失 F1-Score>0.99 [87 ] MICCAI BRATS 2013,2015 SegGAN 头部MR 多尺度L1 范数损失 Dice=0.84/0.85(BRATS 2013数据集/BRATS 2015数据集) [100 ] INbreast dataset,DDSM dataset cGAN 乳腺钼靶图像 Dice以及对抗损失 Dice=0.94(INbreast) [90 ]
4.2 医学图像目标识别 医学图像目标识别也属于临床诊断的一种,即在一幅图像中标记出可能病变的区域,并对其进行分类,如图5 所示. ...
MSGAN:GAN-based semantic segmentation of multiple sclerosis lesions in brain magnetic resonance imaging
2018
Combo loss:handling input and output imbalance in multi-organ segmentation
2
2019
... 基于GAN的分割的主要思想是生成器被用来生成初始分割结果,判别器被用来细化分割结果.一般在分割网络中,生成器常采用FCN或者U-Net网络框架,判别器为常见的分类网络结构,如ResNet、VGG等.基于GAN的医学图像分割已经被应用到多个器官和组织的医学图像分割任务中[9 ,92 ] .表2 为常见医学图像分割模型所用的数据集以及其分割性能对比. ...
... 典型的深度学习医学图像分割方法
数据集 模型 器官 损失 精度 文献 内部数据集 2.5D CNN 脑部、乳腺MR,心脏血管造影图像 交叉熵损失 [77 ] 2016 MICCAI IVDs挑战赛数据集 3D FCN 椎间盘MR 加权交叉熵损失 Dice=0.912 [78 ] 2017 MICCAI grand challenge on infant brain MRI Multistream 3D FCN 脑部MR 似然损失 Dice=0.954 [81 ] ASD=0.127 MHD=9.62 (脑脊液) MICCAI 2009 LV Segmentation Challenge Recurrent FCN 心脏MR 交叉熵损失 Dice=0.90 [82 ] APD=2.05 TCIA(ProstateX,QINHEADNECK) U-Net 多器官 Combo损失 Dice=0.92 [92 ] DRIVE、STARE、CHASH_DB1 R2 U-Net 多器官 二值交叉熵损失 Dice=0.86 [85 ] PROMISE 2012 challenge V-Net 前列腺MR Dice损失 Dice=0.87 [84 ] HD=5.71 mm DRIVE Dataset、ISIC 2018 Bi-LSTM 多器官 二值交叉熵损失 F1-Score>0.99 [87 ] MICCAI BRATS 2013,2015 SegGAN 头部MR 多尺度L1 范数损失 Dice=0.84/0.85(BRATS 2013数据集/BRATS 2015数据集) [100 ] INbreast dataset,DDSM dataset cGAN 乳腺钼靶图像 Dice以及对抗损失 Dice=0.94(INbreast) [90 ]
4.2 医学图像目标识别 医学图像目标识别也属于临床诊断的一种,即在一幅图像中标记出可能病变的区域,并对其进行分类,如图5 所示. ...
人工智能在医学影像中的研究与应用
1
2019
... 医学图像分类和识别是计算机辅助诊断(computer-aided diagnosis,CAD)的最终目标.在深度学习出现前,常采用人工定义的图像特征(如图像的纹理、形状、图像的灰度直方图等),经过特征选择后,再基于机器学习模型(如支持向量机、逻辑回归、随机森林等)进行分类.典型代表为影像组学方法,其在肿瘤的分型分期、治疗的预后预测方面取得了很多重要的成果[93 ] .然而,人工定义特征以及特征选择方式很大程度上影响了分类的可靠性和鲁棒性. ...
人工智能在医学影像中的研究与应用
1
2019
... 医学图像分类和识别是计算机辅助诊断(computer-aided diagnosis,CAD)的最终目标.在深度学习出现前,常采用人工定义的图像特征(如图像的纹理、形状、图像的灰度直方图等),经过特征选择后,再基于机器学习模型(如支持向量机、逻辑回归、随机森林等)进行分类.典型代表为影像组学方法,其在肿瘤的分型分期、治疗的预后预测方面取得了很多重要的成果[93 ] .然而,人工定义特征以及特征选择方式很大程度上影响了分类的可靠性和鲁棒性. ...
Modified AlexNet architecture for classification of diabetic retinopathy images
2
2019
... 近年来,深度学习模型的飞速发展,尤其是CNN的广泛应用,使得利用神经网络模型自动提取和选择特征并进行分类成为主流趋势.CNN模型的不同变体已经在基于医学影像的临床疾病诊断中得到了广泛的应用,例如基于Kaggle公司的眼底图像公开数据集,Shanthi T等人[94 ] 使用改进的AlexNet进行糖尿病视网膜病变的分类,其精度可以达到96.6%左右;基于VG G,利用胸片进行肺结节的良恶性分类,其精度可高达99%[95 ] .目前,在常见的CNN变体中,ResNet和VGG在医学影像分类中的表现最好,因此大多数的肿瘤检测、脑神经系统疾病分类、心血管疾病检测等将这两种模型作为基线模型进行研究. ...
... 基于深度学习的医学图像分类总结
器官 数据集 方法 目标 精度 文献 肺 LIDC-IDRI、ANODE09 challenge、DLCST 卷积神经网络 结节分类 Sensitivity=0.854 [95 ] LIDC-IDRI 知识学习 结节分类 AUC=0.957 [109 ] Chest X-ray 14 注意力卷积神经网络 肺部疾病分类 AUC=0.871 [102 ] HUG database 迁移学习 间质性肺疾病分类 F1-score=0.88 [97 ] LIDC以及内部数据集 迁移学习 肺结节检测 AUC=0.812 [98 ] LIDC-IDRI 知识学习 肺结节分类 AUC=0.957 [109 ] LIDC-IDRI 流形学习 肺结节分类 ACC=0.90 [110 ] 乳腺 DDSM、MIAS、BCDR 迁移学习 乳腺癌分类 AUC=0.997(MIAS) AUC=0.956(BCDR) [99 ] 皮肤 ISIC 2016,2017 迁移学习 皮肤病分类 AUC=0.914 [96 ] 2017 ISBI Challenge on Skin Lesion Analysis Towards Melanoma Detection、EDRA、ISIC 知识学习 皮肤病分类 AUC=0.917 [103 ] ISIC 人工与学习特征结合 皮肤病分类 AUC=0.780 [107 ] 眼底 Messidor AlexNet 糖尿病视网膜病变分级 ACC=0.966 [94 ] 内部数据集 注意力卷积神经网络 青光眼分类 AUC=0.975 [104 ] UCSD、NEH 病变感知卷积神经网络 眼底疾病分类 AUC>0.96 [103 ] 内部数据集 知识学习 青光眼分类 ACC=0.915 [108 ]
5 结束语 本文从医学图像数据产生、医学图像预处理,以及医学图像识别和分类等方面,阐述了深度学习模型在医学图像分析领域的应用现状.尽管深度学习模型(如CNN、LSTM、GAN、注意力机制、图模型、迁移学习等)在医学图像分析中已取得众多突破,然而将深度学习应用于临床,辅助临床进行精准诊断和个性化治疗仍受到以下几方面的限制. ...
Multiresolution convolutional networks for chest X-ray radiograph based lung nodule detection
2
2020
... 近年来,深度学习模型的飞速发展,尤其是CNN的广泛应用,使得利用神经网络模型自动提取和选择特征并进行分类成为主流趋势.CNN模型的不同变体已经在基于医学影像的临床疾病诊断中得到了广泛的应用,例如基于Kaggle公司的眼底图像公开数据集,Shanthi T等人[94 ] 使用改进的AlexNet进行糖尿病视网膜病变的分类,其精度可以达到96.6%左右;基于VG G,利用胸片进行肺结节的良恶性分类,其精度可高达99%[95 ] .目前,在常见的CNN变体中,ResNet和VGG在医学影像分类中的表现最好,因此大多数的肿瘤检测、脑神经系统疾病分类、心血管疾病检测等将这两种模型作为基线模型进行研究. ...
... 基于深度学习的医学图像分类总结
器官 数据集 方法 目标 精度 文献 肺 LIDC-IDRI、ANODE09 challenge、DLCST 卷积神经网络 结节分类 Sensitivity=0.854 [95 ] LIDC-IDRI 知识学习 结节分类 AUC=0.957 [109 ] Chest X-ray 14 注意力卷积神经网络 肺部疾病分类 AUC=0.871 [102 ] HUG database 迁移学习 间质性肺疾病分类 F1-score=0.88 [97 ] LIDC以及内部数据集 迁移学习 肺结节检测 AUC=0.812 [98 ] LIDC-IDRI 知识学习 肺结节分类 AUC=0.957 [109 ] LIDC-IDRI 流形学习 肺结节分类 ACC=0.90 [110 ] 乳腺 DDSM、MIAS、BCDR 迁移学习 乳腺癌分类 AUC=0.997(MIAS) AUC=0.956(BCDR) [99 ] 皮肤 ISIC 2016,2017 迁移学习 皮肤病分类 AUC=0.914 [96 ] 2017 ISBI Challenge on Skin Lesion Analysis Towards Melanoma Detection、EDRA、ISIC 知识学习 皮肤病分类 AUC=0.917 [103 ] ISIC 人工与学习特征结合 皮肤病分类 AUC=0.780 [107 ] 眼底 Messidor AlexNet 糖尿病视网膜病变分级 ACC=0.966 [94 ] 内部数据集 注意力卷积神经网络 青光眼分类 AUC=0.975 [104 ] UCSD、NEH 病变感知卷积神经网络 眼底疾病分类 AUC>0.96 [103 ] 内部数据集 知识学习 青光眼分类 ACC=0.915 [108 ]
5 结束语 本文从医学图像数据产生、医学图像预处理,以及医学图像识别和分类等方面,阐述了深度学习模型在医学图像分析领域的应用现状.尽管深度学习模型(如CNN、LSTM、GAN、注意力机制、图模型、迁移学习等)在医学图像分析中已取得众多突破,然而将深度学习应用于临床,辅助临床进行精准诊断和个性化治疗仍受到以下几方面的限制. ...
Fusing fine-tuned deep features for skin lesion classification
2
2019
... 与自然图像数据相比,医学图像数据中满足模型训练需求的数据较少.因此,为了提高临床影像智能诊断的准确性,通过知识迁移来训练医学图像分类模型已成为主流.常见的知识迁移包含自然图像到医学图像的迁移、基于临床知识的指导迁移[96 ,97 ,98 ] .在自然图像到医学图像的迁移中,主要有两种方式:一种是固定利用自然图像训练的网络模型的卷积层参数,利用该参数提取医学影像特征,然后利用该特征结合传统的机器学习方法进行分类;另一种是将自然图像训练的网络模型参数作为医学图像训练模型的初始化参数,通过微调来实现医学图像分类.除了自然图像到医学图像的迁移,还可以利用其他医学图像数据集,采用多任务学习的方式进行数据信息共享,弥补数据不足带来的分类缺陷[99 ] . ...
... 基于深度学习的医学图像分类总结
器官 数据集 方法 目标 精度 文献 肺 LIDC-IDRI、ANODE09 challenge、DLCST 卷积神经网络 结节分类 Sensitivity=0.854 [95 ] LIDC-IDRI 知识学习 结节分类 AUC=0.957 [109 ] Chest X-ray 14 注意力卷积神经网络 肺部疾病分类 AUC=0.871 [102 ] HUG database 迁移学习 间质性肺疾病分类 F1-score=0.88 [97 ] LIDC以及内部数据集 迁移学习 肺结节检测 AUC=0.812 [98 ] LIDC-IDRI 知识学习 肺结节分类 AUC=0.957 [109 ] LIDC-IDRI 流形学习 肺结节分类 ACC=0.90 [110 ] 乳腺 DDSM、MIAS、BCDR 迁移学习 乳腺癌分类 AUC=0.997(MIAS) AUC=0.956(BCDR) [99 ] 皮肤 ISIC 2016,2017 迁移学习 皮肤病分类 AUC=0.914 [96 ] 2017 ISBI Challenge on Skin Lesion Analysis Towards Melanoma Detection、EDRA、ISIC 知识学习 皮肤病分类 AUC=0.917 [103 ] ISIC 人工与学习特征结合 皮肤病分类 AUC=0.780 [107 ] 眼底 Messidor AlexNet 糖尿病视网膜病变分级 ACC=0.966 [94 ] 内部数据集 注意力卷积神经网络 青光眼分类 AUC=0.975 [104 ] UCSD、NEH 病变感知卷积神经网络 眼底疾病分类 AUC>0.96 [103 ] 内部数据集 知识学习 青光眼分类 ACC=0.915 [108 ]
5 结束语 本文从医学图像数据产生、医学图像预处理,以及医学图像识别和分类等方面,阐述了深度学习模型在医学图像分析领域的应用现状.尽管深度学习模型(如CNN、LSTM、GAN、注意力机制、图模型、迁移学习等)在医学图像分析中已取得众多突破,然而将深度学习应用于临床,辅助临床进行精准诊断和个性化治疗仍受到以下几方面的限制. ...
Multisource transfer learning with convolutional neural networks for lung pattern analysis
2
2016
... 与自然图像数据相比,医学图像数据中满足模型训练需求的数据较少.因此,为了提高临床影像智能诊断的准确性,通过知识迁移来训练医学图像分类模型已成为主流.常见的知识迁移包含自然图像到医学图像的迁移、基于临床知识的指导迁移[96 ,97 ,98 ] .在自然图像到医学图像的迁移中,主要有两种方式:一种是固定利用自然图像训练的网络模型的卷积层参数,利用该参数提取医学影像特征,然后利用该特征结合传统的机器学习方法进行分类;另一种是将自然图像训练的网络模型参数作为医学图像训练模型的初始化参数,通过微调来实现医学图像分类.除了自然图像到医学图像的迁移,还可以利用其他医学图像数据集,采用多任务学习的方式进行数据信息共享,弥补数据不足带来的分类缺陷[99 ] . ...
... 基于深度学习的医学图像分类总结
器官 数据集 方法 目标 精度 文献 肺 LIDC-IDRI、ANODE09 challenge、DLCST 卷积神经网络 结节分类 Sensitivity=0.854 [95 ] LIDC-IDRI 知识学习 结节分类 AUC=0.957 [109 ] Chest X-ray 14 注意力卷积神经网络 肺部疾病分类 AUC=0.871 [102 ] HUG database 迁移学习 间质性肺疾病分类 F1-score=0.88 [97 ] LIDC以及内部数据集 迁移学习 肺结节检测 AUC=0.812 [98 ] LIDC-IDRI 知识学习 肺结节分类 AUC=0.957 [109 ] LIDC-IDRI 流形学习 肺结节分类 ACC=0.90 [110 ] 乳腺 DDSM、MIAS、BCDR 迁移学习 乳腺癌分类 AUC=0.997(MIAS) AUC=0.956(BCDR) [99 ] 皮肤 ISIC 2016,2017 迁移学习 皮肤病分类 AUC=0.914 [96 ] 2017 ISBI Challenge on Skin Lesion Analysis Towards Melanoma Detection、EDRA、ISIC 知识学习 皮肤病分类 AUC=0.917 [103 ] ISIC 人工与学习特征结合 皮肤病分类 AUC=0.780 [107 ] 眼底 Messidor AlexNet 糖尿病视网膜病变分级 ACC=0.966 [94 ] 内部数据集 注意力卷积神经网络 青光眼分类 AUC=0.975 [104 ] UCSD、NEH 病变感知卷积神经网络 眼底疾病分类 AUC>0.96 [103 ] 内部数据集 知识学习 青光眼分类 ACC=0.915 [108 ]
5 结束语 本文从医学图像数据产生、医学图像预处理,以及医学图像识别和分类等方面,阐述了深度学习模型在医学图像分析领域的应用现状.尽管深度学习模型(如CNN、LSTM、GAN、注意力机制、图模型、迁移学习等)在医学图像分析中已取得众多突破,然而将深度学习应用于临床,辅助临床进行精准诊断和个性化治疗仍受到以下几方面的限制. ...
Lung nodule detection and classification from thorax CT-scan using RetinaNet with transfer learning
3
... 与自然图像数据相比,医学图像数据中满足模型训练需求的数据较少.因此,为了提高临床影像智能诊断的准确性,通过知识迁移来训练医学图像分类模型已成为主流.常见的知识迁移包含自然图像到医学图像的迁移、基于临床知识的指导迁移[96 ,97 ,98 ] .在自然图像到医学图像的迁移中,主要有两种方式:一种是固定利用自然图像训练的网络模型的卷积层参数,利用该参数提取医学影像特征,然后利用该特征结合传统的机器学习方法进行分类;另一种是将自然图像训练的网络模型参数作为医学图像训练模型的初始化参数,通过微调来实现医学图像分类.除了自然图像到医学图像的迁移,还可以利用其他医学图像数据集,采用多任务学习的方式进行数据信息共享,弥补数据不足带来的分类缺陷[99 ] . ...
... 传统的人工标记识别费时费力.最初将深度学习模型应用于目标识别时,主要是将图像分成小块,逐块输入由CNN等组成的二分类模型中,判断其是否属于目标区域[111 ,112 ] .随着深度学习模型在目标检测领域的快速发展,尤其是Fast R-CNN模型和Mask R-CNN模型的出现,将整幅医学图像输入模型,即可一次找到所有可能的目标区域.但是在这两类模型中均存在一个区域建议模块和一个分类模块,二者需要进行迭代更新,模型的速度并不能满足临床的实时性要求.YOLO(you only look once)和SSD(single shot multibox detector)模型的问世解决了目标检测的实时性问题.基于此类模型,Lin T Y等人[113 ] 提出RetinaNet模型,并将其扩展应用到病理图像和钼靶图像乳腺肿瘤识别[114 ,115 ] 、CT图像的肺结节检测[98 ,116 ] 中.上述模型均针对2D图像进行目标检测,忽略了3D图像中切片和切片之间的空间信息.为了提高识别的准确度,基于RNN和LSTM的识别模型被应用到医学图像中[117 ,118 ,119 ] . ...
... 基于深度学习的医学图像分类总结
器官 数据集 方法 目标 精度 文献 肺 LIDC-IDRI、ANODE09 challenge、DLCST 卷积神经网络 结节分类 Sensitivity=0.854 [95 ] LIDC-IDRI 知识学习 结节分类 AUC=0.957 [109 ] Chest X-ray 14 注意力卷积神经网络 肺部疾病分类 AUC=0.871 [102 ] HUG database 迁移学习 间质性肺疾病分类 F1-score=0.88 [97 ] LIDC以及内部数据集 迁移学习 肺结节检测 AUC=0.812 [98 ] LIDC-IDRI 知识学习 肺结节分类 AUC=0.957 [109 ] LIDC-IDRI 流形学习 肺结节分类 ACC=0.90 [110 ] 乳腺 DDSM、MIAS、BCDR 迁移学习 乳腺癌分类 AUC=0.997(MIAS) AUC=0.956(BCDR) [99 ] 皮肤 ISIC 2016,2017 迁移学习 皮肤病分类 AUC=0.914 [96 ] 2017 ISBI Challenge on Skin Lesion Analysis Towards Melanoma Detection、EDRA、ISIC 知识学习 皮肤病分类 AUC=0.917 [103 ] ISIC 人工与学习特征结合 皮肤病分类 AUC=0.780 [107 ] 眼底 Messidor AlexNet 糖尿病视网膜病变分级 ACC=0.966 [94 ] 内部数据集 注意力卷积神经网络 青光眼分类 AUC=0.975 [104 ] UCSD、NEH 病变感知卷积神经网络 眼底疾病分类 AUC>0.96 [103 ] 内部数据集 知识学习 青光眼分类 ACC=0.915 [108 ]
5 结束语 本文从医学图像数据产生、医学图像预处理,以及医学图像识别和分类等方面,阐述了深度学习模型在医学图像分析领域的应用现状.尽管深度学习模型(如CNN、LSTM、GAN、注意力机制、图模型、迁移学习等)在医学图像分析中已取得众多突破,然而将深度学习应用于临床,辅助临床进行精准诊断和个性化治疗仍受到以下几方面的限制. ...
Double-shot transfer learning for breast cancer classification from X-ray images
3
2020
... 与自然图像数据相比,医学图像数据中满足模型训练需求的数据较少.因此,为了提高临床影像智能诊断的准确性,通过知识迁移来训练医学图像分类模型已成为主流.常见的知识迁移包含自然图像到医学图像的迁移、基于临床知识的指导迁移[96 ,97 ,98 ] .在自然图像到医学图像的迁移中,主要有两种方式:一种是固定利用自然图像训练的网络模型的卷积层参数,利用该参数提取医学影像特征,然后利用该特征结合传统的机器学习方法进行分类;另一种是将自然图像训练的网络模型参数作为医学图像训练模型的初始化参数,通过微调来实现医学图像分类.除了自然图像到医学图像的迁移,还可以利用其他医学图像数据集,采用多任务学习的方式进行数据信息共享,弥补数据不足带来的分类缺陷[99 ] . ...
... 此外,在医学图像目标识别中,同样存在数据不充足的问题.为了解决这个问题,基于迁移学习的医学图像识别逐渐开展起来,如基于ImageNet数据进行模型迁移,实现肺结节[120 ] 、乳腺癌[99 ] 和结直肠息肉的检测[121 ] .同时,基于临床经验知识指导的迁移学习也被应用到医学图像的目标检测中.典型代表有AGCL模型,其基于注意力的课程学习,实现胸片中的肿瘤检测[121 ] ;CASED (curriculum adaptive sampling for extreme data imbalance)模型,其可检测CT图像中的肺结节[122 ] ;特征金字塔模型(feature pyramid network,FPN),其采用不同对比度的图像,利用多尺度注意力模型实现肿瘤检测[123 ] . ...
... 基于深度学习的医学图像分类总结
器官 数据集 方法 目标 精度 文献 肺 LIDC-IDRI、ANODE09 challenge、DLCST 卷积神经网络 结节分类 Sensitivity=0.854 [95 ] LIDC-IDRI 知识学习 结节分类 AUC=0.957 [109 ] Chest X-ray 14 注意力卷积神经网络 肺部疾病分类 AUC=0.871 [102 ] HUG database 迁移学习 间质性肺疾病分类 F1-score=0.88 [97 ] LIDC以及内部数据集 迁移学习 肺结节检测 AUC=0.812 [98 ] LIDC-IDRI 知识学习 肺结节分类 AUC=0.957 [109 ] LIDC-IDRI 流形学习 肺结节分类 ACC=0.90 [110 ] 乳腺 DDSM、MIAS、BCDR 迁移学习 乳腺癌分类 AUC=0.997(MIAS) AUC=0.956(BCDR) [99 ] 皮肤 ISIC 2016,2017 迁移学习 皮肤病分类 AUC=0.914 [96 ] 2017 ISBI Challenge on Skin Lesion Analysis Towards Melanoma Detection、EDRA、ISIC 知识学习 皮肤病分类 AUC=0.917 [103 ] ISIC 人工与学习特征结合 皮肤病分类 AUC=0.780 [107 ] 眼底 Messidor AlexNet 糖尿病视网膜病变分级 ACC=0.966 [94 ] 内部数据集 注意力卷积神经网络 青光眼分类 AUC=0.975 [104 ] UCSD、NEH 病变感知卷积神经网络 眼底疾病分类 AUC>0.96 [103 ] 内部数据集 知识学习 青光眼分类 ACC=0.915 [108 ]
5 结束语 本文从医学图像数据产生、医学图像预处理,以及医学图像识别和分类等方面,阐述了深度学习模型在医学图像分析领域的应用现状.尽管深度学习模型(如CNN、LSTM、GAN、注意力机制、图模型、迁移学习等)在医学图像分析中已取得众多突破,然而将深度学习应用于临床,辅助临床进行精准诊断和个性化治疗仍受到以下几方面的限制. ...
Detrac:transfer learning of class decomposed medical images in convolutional neural networks
2
2020
... 基于临床知识的指导迁移将临床医生诊断的经验(如医生的经验学习方式、影像诊断方式以及诊断关注的图像区域和特征等)融入模型,根据临床医生诊断的经验,即先掌握简单的疾病影像诊断,再进行复杂疾病诊断,研究者们提出了“课程学习”模型,将图像分类任务从易到难进行划分,模型训练先学习简单的图像分类任务,再学习较难的分类任务[100 ,101 ] .基于该方式的学习可以提高分类的准确度.基于医生诊断的方式(如迅速浏览全部医学图像,再选择某些切片进行诊断),研究者提出基于全局和局部的分类模型,其在胸片[102 ] 和皮肤疾病[103 ] 的诊断上取得了较好的效果.基于诊断时关注的影像区域,带有注意力机制的分类模型被提出,典型的代表有AGCNN(attention-based CNN for glaucoma detection)[104 ] 、LACNN(lesion aware CNN)[105 ] 和ABN(attention branch network)[106 ] ,通过引入注意力,网络可以关注某些区域,从而提高分类的精度.此外,根据医生诊断用到的经验特征,如肿瘤的形状、大小、边界等信息,将人工定义的特征与深度模型提取的特征进行融合,提高医学图像的分类精度,也是一种趋势.如Majtner T等人[107 ] 将人工特征分类结果与深度学习分类结果进行融合,提高了皮肤癌分类的准确度;Chai Y D等人[108 ] 将人工特征和深度学习特征进行融合并训练分类器,从而实现青光眼图像的分类;Xie Y T等人[109 ] 将人工提取的特征图像块与深度学习图像块同时作为ResNet模型的输入,实现肺结节的准确分类.如何将深度学习特征与传统人工特征进行有效的融合,是该类模型设计的难点. ...
... 典型的深度学习医学图像分割方法
数据集 模型 器官 损失 精度 文献 内部数据集 2.5D CNN 脑部、乳腺MR,心脏血管造影图像 交叉熵损失 [77 ] 2016 MICCAI IVDs挑战赛数据集 3D FCN 椎间盘MR 加权交叉熵损失 Dice=0.912 [78 ] 2017 MICCAI grand challenge on infant brain MRI Multistream 3D FCN 脑部MR 似然损失 Dice=0.954 [81 ] ASD=0.127 MHD=9.62 (脑脊液) MICCAI 2009 LV Segmentation Challenge Recurrent FCN 心脏MR 交叉熵损失 Dice=0.90 [82 ] APD=2.05 TCIA(ProstateX,QINHEADNECK) U-Net 多器官 Combo损失 Dice=0.92 [92 ] DRIVE、STARE、CHASH_DB1 R2 U-Net 多器官 二值交叉熵损失 Dice=0.86 [85 ] PROMISE 2012 challenge V-Net 前列腺MR Dice损失 Dice=0.87 [84 ] HD=5.71 mm DRIVE Dataset、ISIC 2018 Bi-LSTM 多器官 二值交叉熵损失 F1-Score>0.99 [87 ] MICCAI BRATS 2013,2015 SegGAN 头部MR 多尺度L1 范数损失 Dice=0.84/0.85(BRATS 2013数据集/BRATS 2015数据集) [100 ] INbreast dataset,DDSM dataset cGAN 乳腺钼靶图像 Dice以及对抗损失 Dice=0.94(INbreast) [90 ]
4.2 医学图像目标识别 医学图像目标识别也属于临床诊断的一种,即在一幅图像中标记出可能病变的区域,并对其进行分类,如图5 所示. ...
Automatic CNN-based detection of cardiac MR motion artefacts using k-space data augmentation and curriculum learning
1
2019
... 基于临床知识的指导迁移将临床医生诊断的经验(如医生的经验学习方式、影像诊断方式以及诊断关注的图像区域和特征等)融入模型,根据临床医生诊断的经验,即先掌握简单的疾病影像诊断,再进行复杂疾病诊断,研究者们提出了“课程学习”模型,将图像分类任务从易到难进行划分,模型训练先学习简单的图像分类任务,再学习较难的分类任务[100 ,101 ] .基于该方式的学习可以提高分类的准确度.基于医生诊断的方式(如迅速浏览全部医学图像,再选择某些切片进行诊断),研究者提出基于全局和局部的分类模型,其在胸片[102 ] 和皮肤疾病[103 ] 的诊断上取得了较好的效果.基于诊断时关注的影像区域,带有注意力机制的分类模型被提出,典型的代表有AGCNN(attention-based CNN for glaucoma detection)[104 ] 、LACNN(lesion aware CNN)[105 ] 和ABN(attention branch network)[106 ] ,通过引入注意力,网络可以关注某些区域,从而提高分类的精度.此外,根据医生诊断用到的经验特征,如肿瘤的形状、大小、边界等信息,将人工定义的特征与深度模型提取的特征进行融合,提高医学图像的分类精度,也是一种趋势.如Majtner T等人[107 ] 将人工特征分类结果与深度学习分类结果进行融合,提高了皮肤癌分类的准确度;Chai Y D等人[108 ] 将人工特征和深度学习特征进行融合并训练分类器,从而实现青光眼图像的分类;Xie Y T等人[109 ] 将人工提取的特征图像块与深度学习图像块同时作为ResNet模型的输入,实现肺结节的准确分类.如何将深度学习特征与传统人工特征进行有效的融合,是该类模型设计的难点. ...
Diagnose like a radiologist:attention guided convolutional neural network for thorax disease classification
2
... 基于临床知识的指导迁移将临床医生诊断的经验(如医生的经验学习方式、影像诊断方式以及诊断关注的图像区域和特征等)融入模型,根据临床医生诊断的经验,即先掌握简单的疾病影像诊断,再进行复杂疾病诊断,研究者们提出了“课程学习”模型,将图像分类任务从易到难进行划分,模型训练先学习简单的图像分类任务,再学习较难的分类任务[100 ,101 ] .基于该方式的学习可以提高分类的准确度.基于医生诊断的方式(如迅速浏览全部医学图像,再选择某些切片进行诊断),研究者提出基于全局和局部的分类模型,其在胸片[102 ] 和皮肤疾病[103 ] 的诊断上取得了较好的效果.基于诊断时关注的影像区域,带有注意力机制的分类模型被提出,典型的代表有AGCNN(attention-based CNN for glaucoma detection)[104 ] 、LACNN(lesion aware CNN)[105 ] 和ABN(attention branch network)[106 ] ,通过引入注意力,网络可以关注某些区域,从而提高分类的精度.此外,根据医生诊断用到的经验特征,如肿瘤的形状、大小、边界等信息,将人工定义的特征与深度模型提取的特征进行融合,提高医学图像的分类精度,也是一种趋势.如Majtner T等人[107 ] 将人工特征分类结果与深度学习分类结果进行融合,提高了皮肤癌分类的准确度;Chai Y D等人[108 ] 将人工特征和深度学习特征进行融合并训练分类器,从而实现青光眼图像的分类;Xie Y T等人[109 ] 将人工提取的特征图像块与深度学习图像块同时作为ResNet模型的输入,实现肺结节的准确分类.如何将深度学习特征与传统人工特征进行有效的融合,是该类模型设计的难点. ...
... 基于深度学习的医学图像分类总结
器官 数据集 方法 目标 精度 文献 肺 LIDC-IDRI、ANODE09 challenge、DLCST 卷积神经网络 结节分类 Sensitivity=0.854 [95 ] LIDC-IDRI 知识学习 结节分类 AUC=0.957 [109 ] Chest X-ray 14 注意力卷积神经网络 肺部疾病分类 AUC=0.871 [102 ] HUG database 迁移学习 间质性肺疾病分类 F1-score=0.88 [97 ] LIDC以及内部数据集 迁移学习 肺结节检测 AUC=0.812 [98 ] LIDC-IDRI 知识学习 肺结节分类 AUC=0.957 [109 ] LIDC-IDRI 流形学习 肺结节分类 ACC=0.90 [110 ] 乳腺 DDSM、MIAS、BCDR 迁移学习 乳腺癌分类 AUC=0.997(MIAS) AUC=0.956(BCDR) [99 ] 皮肤 ISIC 2016,2017 迁移学习 皮肤病分类 AUC=0.914 [96 ] 2017 ISBI Challenge on Skin Lesion Analysis Towards Melanoma Detection、EDRA、ISIC 知识学习 皮肤病分类 AUC=0.917 [103 ] ISIC 人工与学习特征结合 皮肤病分类 AUC=0.780 [107 ] 眼底 Messidor AlexNet 糖尿病视网膜病变分级 ACC=0.966 [94 ] 内部数据集 注意力卷积神经网络 青光眼分类 AUC=0.975 [104 ] UCSD、NEH 病变感知卷积神经网络 眼底疾病分类 AUC>0.96 [103 ] 内部数据集 知识学习 青光眼分类 ACC=0.915 [108 ]
5 结束语 本文从医学图像数据产生、医学图像预处理,以及医学图像识别和分类等方面,阐述了深度学习模型在医学图像分析领域的应用现状.尽管深度学习模型(如CNN、LSTM、GAN、注意力机制、图模型、迁移学习等)在医学图像分析中已取得众多突破,然而将深度学习应用于临床,辅助临床进行精准诊断和个性化治疗仍受到以下几方面的限制. ...
Dermaknet:incorporating the knowledge of dermatologists to convolutional neural networks for skin lesion diagnosis
3
2018
... 基于临床知识的指导迁移将临床医生诊断的经验(如医生的经验学习方式、影像诊断方式以及诊断关注的图像区域和特征等)融入模型,根据临床医生诊断的经验,即先掌握简单的疾病影像诊断,再进行复杂疾病诊断,研究者们提出了“课程学习”模型,将图像分类任务从易到难进行划分,模型训练先学习简单的图像分类任务,再学习较难的分类任务[100 ,101 ] .基于该方式的学习可以提高分类的准确度.基于医生诊断的方式(如迅速浏览全部医学图像,再选择某些切片进行诊断),研究者提出基于全局和局部的分类模型,其在胸片[102 ] 和皮肤疾病[103 ] 的诊断上取得了较好的效果.基于诊断时关注的影像区域,带有注意力机制的分类模型被提出,典型的代表有AGCNN(attention-based CNN for glaucoma detection)[104 ] 、LACNN(lesion aware CNN)[105 ] 和ABN(attention branch network)[106 ] ,通过引入注意力,网络可以关注某些区域,从而提高分类的精度.此外,根据医生诊断用到的经验特征,如肿瘤的形状、大小、边界等信息,将人工定义的特征与深度模型提取的特征进行融合,提高医学图像的分类精度,也是一种趋势.如Majtner T等人[107 ] 将人工特征分类结果与深度学习分类结果进行融合,提高了皮肤癌分类的准确度;Chai Y D等人[108 ] 将人工特征和深度学习特征进行融合并训练分类器,从而实现青光眼图像的分类;Xie Y T等人[109 ] 将人工提取的特征图像块与深度学习图像块同时作为ResNet模型的输入,实现肺结节的准确分类.如何将深度学习特征与传统人工特征进行有效的融合,是该类模型设计的难点. ...
... 基于深度学习的医学图像分类总结
器官 数据集 方法 目标 精度 文献 肺 LIDC-IDRI、ANODE09 challenge、DLCST 卷积神经网络 结节分类 Sensitivity=0.854 [95 ] LIDC-IDRI 知识学习 结节分类 AUC=0.957 [109 ] Chest X-ray 14 注意力卷积神经网络 肺部疾病分类 AUC=0.871 [102 ] HUG database 迁移学习 间质性肺疾病分类 F1-score=0.88 [97 ] LIDC以及内部数据集 迁移学习 肺结节检测 AUC=0.812 [98 ] LIDC-IDRI 知识学习 肺结节分类 AUC=0.957 [109 ] LIDC-IDRI 流形学习 肺结节分类 ACC=0.90 [110 ] 乳腺 DDSM、MIAS、BCDR 迁移学习 乳腺癌分类 AUC=0.997(MIAS) AUC=0.956(BCDR) [99 ] 皮肤 ISIC 2016,2017 迁移学习 皮肤病分类 AUC=0.914 [96 ] 2017 ISBI Challenge on Skin Lesion Analysis Towards Melanoma Detection、EDRA、ISIC 知识学习 皮肤病分类 AUC=0.917 [103 ] ISIC 人工与学习特征结合 皮肤病分类 AUC=0.780 [107 ] 眼底 Messidor AlexNet 糖尿病视网膜病变分级 ACC=0.966 [94 ] 内部数据集 注意力卷积神经网络 青光眼分类 AUC=0.975 [104 ] UCSD、NEH 病变感知卷积神经网络 眼底疾病分类 AUC>0.96 [103 ] 内部数据集 知识学习 青光眼分类 ACC=0.915 [108 ]
5 结束语 本文从医学图像数据产生、医学图像预处理,以及医学图像识别和分类等方面,阐述了深度学习模型在医学图像分析领域的应用现状.尽管深度学习模型(如CNN、LSTM、GAN、注意力机制、图模型、迁移学习等)在医学图像分析中已取得众多突破,然而将深度学习应用于临床,辅助临床进行精准诊断和个性化治疗仍受到以下几方面的限制. ...
... [
103 ]
内部数据集 知识学习 青光眼分类 ACC=0.915 [108 ] 5 结束语 本文从医学图像数据产生、医学图像预处理,以及医学图像识别和分类等方面,阐述了深度学习模型在医学图像分析领域的应用现状.尽管深度学习模型(如CNN、LSTM、GAN、注意力机制、图模型、迁移学习等)在医学图像分析中已取得众多突破,然而将深度学习应用于临床,辅助临床进行精准诊断和个性化治疗仍受到以下几方面的限制. ...
Attention based glaucoma detection:a largescale database and CNN model
2
2019
... 基于临床知识的指导迁移将临床医生诊断的经验(如医生的经验学习方式、影像诊断方式以及诊断关注的图像区域和特征等)融入模型,根据临床医生诊断的经验,即先掌握简单的疾病影像诊断,再进行复杂疾病诊断,研究者们提出了“课程学习”模型,将图像分类任务从易到难进行划分,模型训练先学习简单的图像分类任务,再学习较难的分类任务[100 ,101 ] .基于该方式的学习可以提高分类的准确度.基于医生诊断的方式(如迅速浏览全部医学图像,再选择某些切片进行诊断),研究者提出基于全局和局部的分类模型,其在胸片[102 ] 和皮肤疾病[103 ] 的诊断上取得了较好的效果.基于诊断时关注的影像区域,带有注意力机制的分类模型被提出,典型的代表有AGCNN(attention-based CNN for glaucoma detection)[104 ] 、LACNN(lesion aware CNN)[105 ] 和ABN(attention branch network)[106 ] ,通过引入注意力,网络可以关注某些区域,从而提高分类的精度.此外,根据医生诊断用到的经验特征,如肿瘤的形状、大小、边界等信息,将人工定义的特征与深度模型提取的特征进行融合,提高医学图像的分类精度,也是一种趋势.如Majtner T等人[107 ] 将人工特征分类结果与深度学习分类结果进行融合,提高了皮肤癌分类的准确度;Chai Y D等人[108 ] 将人工特征和深度学习特征进行融合并训练分类器,从而实现青光眼图像的分类;Xie Y T等人[109 ] 将人工提取的特征图像块与深度学习图像块同时作为ResNet模型的输入,实现肺结节的准确分类.如何将深度学习特征与传统人工特征进行有效的融合,是该类模型设计的难点. ...
... 基于深度学习的医学图像分类总结
器官 数据集 方法 目标 精度 文献 肺 LIDC-IDRI、ANODE09 challenge、DLCST 卷积神经网络 结节分类 Sensitivity=0.854 [95 ] LIDC-IDRI 知识学习 结节分类 AUC=0.957 [109 ] Chest X-ray 14 注意力卷积神经网络 肺部疾病分类 AUC=0.871 [102 ] HUG database 迁移学习 间质性肺疾病分类 F1-score=0.88 [97 ] LIDC以及内部数据集 迁移学习 肺结节检测 AUC=0.812 [98 ] LIDC-IDRI 知识学习 肺结节分类 AUC=0.957 [109 ] LIDC-IDRI 流形学习 肺结节分类 ACC=0.90 [110 ] 乳腺 DDSM、MIAS、BCDR 迁移学习 乳腺癌分类 AUC=0.997(MIAS) AUC=0.956(BCDR) [99 ] 皮肤 ISIC 2016,2017 迁移学习 皮肤病分类 AUC=0.914 [96 ] 2017 ISBI Challenge on Skin Lesion Analysis Towards Melanoma Detection、EDRA、ISIC 知识学习 皮肤病分类 AUC=0.917 [103 ] ISIC 人工与学习特征结合 皮肤病分类 AUC=0.780 [107 ] 眼底 Messidor AlexNet 糖尿病视网膜病变分级 ACC=0.966 [94 ] 内部数据集 注意力卷积神经网络 青光眼分类 AUC=0.975 [104 ] UCSD、NEH 病变感知卷积神经网络 眼底疾病分类 AUC>0.96 [103 ] 内部数据集 知识学习 青光眼分类 ACC=0.915 [108 ]
5 结束语 本文从医学图像数据产生、医学图像预处理,以及医学图像识别和分类等方面,阐述了深度学习模型在医学图像分析领域的应用现状.尽管深度学习模型(如CNN、LSTM、GAN、注意力机制、图模型、迁移学习等)在医学图像分析中已取得众多突破,然而将深度学习应用于临床,辅助临床进行精准诊断和个性化治疗仍受到以下几方面的限制. ...
Attention to lesion:Lesion-aware convolutional neural network for retinal optical coherence tomography image classification
1
2019
... 基于临床知识的指导迁移将临床医生诊断的经验(如医生的经验学习方式、影像诊断方式以及诊断关注的图像区域和特征等)融入模型,根据临床医生诊断的经验,即先掌握简单的疾病影像诊断,再进行复杂疾病诊断,研究者们提出了“课程学习”模型,将图像分类任务从易到难进行划分,模型训练先学习简单的图像分类任务,再学习较难的分类任务[100 ,101 ] .基于该方式的学习可以提高分类的准确度.基于医生诊断的方式(如迅速浏览全部医学图像,再选择某些切片进行诊断),研究者提出基于全局和局部的分类模型,其在胸片[102 ] 和皮肤疾病[103 ] 的诊断上取得了较好的效果.基于诊断时关注的影像区域,带有注意力机制的分类模型被提出,典型的代表有AGCNN(attention-based CNN for glaucoma detection)[104 ] 、LACNN(lesion aware CNN)[105 ] 和ABN(attention branch network)[106 ] ,通过引入注意力,网络可以关注某些区域,从而提高分类的精度.此外,根据医生诊断用到的经验特征,如肿瘤的形状、大小、边界等信息,将人工定义的特征与深度模型提取的特征进行融合,提高医学图像的分类精度,也是一种趋势.如Majtner T等人[107 ] 将人工特征分类结果与深度学习分类结果进行融合,提高了皮肤癌分类的准确度;Chai Y D等人[108 ] 将人工特征和深度学习特征进行融合并训练分类器,从而实现青光眼图像的分类;Xie Y T等人[109 ] 将人工提取的特征图像块与深度学习图像块同时作为ResNet模型的输入,实现肺结节的准确分类.如何将深度学习特征与传统人工特征进行有效的融合,是该类模型设计的难点. ...
Embedding human knowledge in deep neural network via attention map
1
... 基于临床知识的指导迁移将临床医生诊断的经验(如医生的经验学习方式、影像诊断方式以及诊断关注的图像区域和特征等)融入模型,根据临床医生诊断的经验,即先掌握简单的疾病影像诊断,再进行复杂疾病诊断,研究者们提出了“课程学习”模型,将图像分类任务从易到难进行划分,模型训练先学习简单的图像分类任务,再学习较难的分类任务[100 ,101 ] .基于该方式的学习可以提高分类的准确度.基于医生诊断的方式(如迅速浏览全部医学图像,再选择某些切片进行诊断),研究者提出基于全局和局部的分类模型,其在胸片[102 ] 和皮肤疾病[103 ] 的诊断上取得了较好的效果.基于诊断时关注的影像区域,带有注意力机制的分类模型被提出,典型的代表有AGCNN(attention-based CNN for glaucoma detection)[104 ] 、LACNN(lesion aware CNN)[105 ] 和ABN(attention branch network)[106 ] ,通过引入注意力,网络可以关注某些区域,从而提高分类的精度.此外,根据医生诊断用到的经验特征,如肿瘤的形状、大小、边界等信息,将人工定义的特征与深度模型提取的特征进行融合,提高医学图像的分类精度,也是一种趋势.如Majtner T等人[107 ] 将人工特征分类结果与深度学习分类结果进行融合,提高了皮肤癌分类的准确度;Chai Y D等人[108 ] 将人工特征和深度学习特征进行融合并训练分类器,从而实现青光眼图像的分类;Xie Y T等人[109 ] 将人工提取的特征图像块与深度学习图像块同时作为ResNet模型的输入,实现肺结节的准确分类.如何将深度学习特征与传统人工特征进行有效的融合,是该类模型设计的难点. ...
Combining deep learning and hand-crafted features for skin lesion classification
2
2016
... 基于临床知识的指导迁移将临床医生诊断的经验(如医生的经验学习方式、影像诊断方式以及诊断关注的图像区域和特征等)融入模型,根据临床医生诊断的经验,即先掌握简单的疾病影像诊断,再进行复杂疾病诊断,研究者们提出了“课程学习”模型,将图像分类任务从易到难进行划分,模型训练先学习简单的图像分类任务,再学习较难的分类任务[100 ,101 ] .基于该方式的学习可以提高分类的准确度.基于医生诊断的方式(如迅速浏览全部医学图像,再选择某些切片进行诊断),研究者提出基于全局和局部的分类模型,其在胸片[102 ] 和皮肤疾病[103 ] 的诊断上取得了较好的效果.基于诊断时关注的影像区域,带有注意力机制的分类模型被提出,典型的代表有AGCNN(attention-based CNN for glaucoma detection)[104 ] 、LACNN(lesion aware CNN)[105 ] 和ABN(attention branch network)[106 ] ,通过引入注意力,网络可以关注某些区域,从而提高分类的精度.此外,根据医生诊断用到的经验特征,如肿瘤的形状、大小、边界等信息,将人工定义的特征与深度模型提取的特征进行融合,提高医学图像的分类精度,也是一种趋势.如Majtner T等人[107 ] 将人工特征分类结果与深度学习分类结果进行融合,提高了皮肤癌分类的准确度;Chai Y D等人[108 ] 将人工特征和深度学习特征进行融合并训练分类器,从而实现青光眼图像的分类;Xie Y T等人[109 ] 将人工提取的特征图像块与深度学习图像块同时作为ResNet模型的输入,实现肺结节的准确分类.如何将深度学习特征与传统人工特征进行有效的融合,是该类模型设计的难点. ...
... 基于深度学习的医学图像分类总结
器官 数据集 方法 目标 精度 文献 肺 LIDC-IDRI、ANODE09 challenge、DLCST 卷积神经网络 结节分类 Sensitivity=0.854 [95 ] LIDC-IDRI 知识学习 结节分类 AUC=0.957 [109 ] Chest X-ray 14 注意力卷积神经网络 肺部疾病分类 AUC=0.871 [102 ] HUG database 迁移学习 间质性肺疾病分类 F1-score=0.88 [97 ] LIDC以及内部数据集 迁移学习 肺结节检测 AUC=0.812 [98 ] LIDC-IDRI 知识学习 肺结节分类 AUC=0.957 [109 ] LIDC-IDRI 流形学习 肺结节分类 ACC=0.90 [110 ] 乳腺 DDSM、MIAS、BCDR 迁移学习 乳腺癌分类 AUC=0.997(MIAS) AUC=0.956(BCDR) [99 ] 皮肤 ISIC 2016,2017 迁移学习 皮肤病分类 AUC=0.914 [96 ] 2017 ISBI Challenge on Skin Lesion Analysis Towards Melanoma Detection、EDRA、ISIC 知识学习 皮肤病分类 AUC=0.917 [103 ] ISIC 人工与学习特征结合 皮肤病分类 AUC=0.780 [107 ] 眼底 Messidor AlexNet 糖尿病视网膜病变分级 ACC=0.966 [94 ] 内部数据集 注意力卷积神经网络 青光眼分类 AUC=0.975 [104 ] UCSD、NEH 病变感知卷积神经网络 眼底疾病分类 AUC>0.96 [103 ] 内部数据集 知识学习 青光眼分类 ACC=0.915 [108 ]
5 结束语 本文从医学图像数据产生、医学图像预处理,以及医学图像识别和分类等方面,阐述了深度学习模型在医学图像分析领域的应用现状.尽管深度学习模型(如CNN、LSTM、GAN、注意力机制、图模型、迁移学习等)在医学图像分析中已取得众多突破,然而将深度学习应用于临床,辅助临床进行精准诊断和个性化治疗仍受到以下几方面的限制. ...
Glaucoma diagnosis based on both hidden features and domain knowledge through deep learning models
2
2018
... 基于临床知识的指导迁移将临床医生诊断的经验(如医生的经验学习方式、影像诊断方式以及诊断关注的图像区域和特征等)融入模型,根据临床医生诊断的经验,即先掌握简单的疾病影像诊断,再进行复杂疾病诊断,研究者们提出了“课程学习”模型,将图像分类任务从易到难进行划分,模型训练先学习简单的图像分类任务,再学习较难的分类任务[100 ,101 ] .基于该方式的学习可以提高分类的准确度.基于医生诊断的方式(如迅速浏览全部医学图像,再选择某些切片进行诊断),研究者提出基于全局和局部的分类模型,其在胸片[102 ] 和皮肤疾病[103 ] 的诊断上取得了较好的效果.基于诊断时关注的影像区域,带有注意力机制的分类模型被提出,典型的代表有AGCNN(attention-based CNN for glaucoma detection)[104 ] 、LACNN(lesion aware CNN)[105 ] 和ABN(attention branch network)[106 ] ,通过引入注意力,网络可以关注某些区域,从而提高分类的精度.此外,根据医生诊断用到的经验特征,如肿瘤的形状、大小、边界等信息,将人工定义的特征与深度模型提取的特征进行融合,提高医学图像的分类精度,也是一种趋势.如Majtner T等人[107 ] 将人工特征分类结果与深度学习分类结果进行融合,提高了皮肤癌分类的准确度;Chai Y D等人[108 ] 将人工特征和深度学习特征进行融合并训练分类器,从而实现青光眼图像的分类;Xie Y T等人[109 ] 将人工提取的特征图像块与深度学习图像块同时作为ResNet模型的输入,实现肺结节的准确分类.如何将深度学习特征与传统人工特征进行有效的融合,是该类模型设计的难点. ...
... 基于深度学习的医学图像分类总结
器官 数据集 方法 目标 精度 文献 肺 LIDC-IDRI、ANODE09 challenge、DLCST 卷积神经网络 结节分类 Sensitivity=0.854 [95 ] LIDC-IDRI 知识学习 结节分类 AUC=0.957 [109 ] Chest X-ray 14 注意力卷积神经网络 肺部疾病分类 AUC=0.871 [102 ] HUG database 迁移学习 间质性肺疾病分类 F1-score=0.88 [97 ] LIDC以及内部数据集 迁移学习 肺结节检测 AUC=0.812 [98 ] LIDC-IDRI 知识学习 肺结节分类 AUC=0.957 [109 ] LIDC-IDRI 流形学习 肺结节分类 ACC=0.90 [110 ] 乳腺 DDSM、MIAS、BCDR 迁移学习 乳腺癌分类 AUC=0.997(MIAS) AUC=0.956(BCDR) [99 ] 皮肤 ISIC 2016,2017 迁移学习 皮肤病分类 AUC=0.914 [96 ] 2017 ISBI Challenge on Skin Lesion Analysis Towards Melanoma Detection、EDRA、ISIC 知识学习 皮肤病分类 AUC=0.917 [103 ] ISIC 人工与学习特征结合 皮肤病分类 AUC=0.780 [107 ] 眼底 Messidor AlexNet 糖尿病视网膜病变分级 ACC=0.966 [94 ] 内部数据集 注意力卷积神经网络 青光眼分类 AUC=0.975 [104 ] UCSD、NEH 病变感知卷积神经网络 眼底疾病分类 AUC>0.96 [103 ] 内部数据集 知识学习 青光眼分类 ACC=0.915 [108 ]
5 结束语 本文从医学图像数据产生、医学图像预处理,以及医学图像识别和分类等方面,阐述了深度学习模型在医学图像分析领域的应用现状.尽管深度学习模型(如CNN、LSTM、GAN、注意力机制、图模型、迁移学习等)在医学图像分析中已取得众多突破,然而将深度学习应用于临床,辅助临床进行精准诊断和个性化治疗仍受到以下几方面的限制. ...
Knowledge-based collaborative deep learning for benign-malignant lung nodule classification on chest CT
3
2018
... 基于临床知识的指导迁移将临床医生诊断的经验(如医生的经验学习方式、影像诊断方式以及诊断关注的图像区域和特征等)融入模型,根据临床医生诊断的经验,即先掌握简单的疾病影像诊断,再进行复杂疾病诊断,研究者们提出了“课程学习”模型,将图像分类任务从易到难进行划分,模型训练先学习简单的图像分类任务,再学习较难的分类任务[100 ,101 ] .基于该方式的学习可以提高分类的准确度.基于医生诊断的方式(如迅速浏览全部医学图像,再选择某些切片进行诊断),研究者提出基于全局和局部的分类模型,其在胸片[102 ] 和皮肤疾病[103 ] 的诊断上取得了较好的效果.基于诊断时关注的影像区域,带有注意力机制的分类模型被提出,典型的代表有AGCNN(attention-based CNN for glaucoma detection)[104 ] 、LACNN(lesion aware CNN)[105 ] 和ABN(attention branch network)[106 ] ,通过引入注意力,网络可以关注某些区域,从而提高分类的精度.此外,根据医生诊断用到的经验特征,如肿瘤的形状、大小、边界等信息,将人工定义的特征与深度模型提取的特征进行融合,提高医学图像的分类精度,也是一种趋势.如Majtner T等人[107 ] 将人工特征分类结果与深度学习分类结果进行融合,提高了皮肤癌分类的准确度;Chai Y D等人[108 ] 将人工特征和深度学习特征进行融合并训练分类器,从而实现青光眼图像的分类;Xie Y T等人[109 ] 将人工提取的特征图像块与深度学习图像块同时作为ResNet模型的输入,实现肺结节的准确分类.如何将深度学习特征与传统人工特征进行有效的融合,是该类模型设计的难点. ...
... 基于深度学习的医学图像分类总结
器官 数据集 方法 目标 精度 文献 肺 LIDC-IDRI、ANODE09 challenge、DLCST 卷积神经网络 结节分类 Sensitivity=0.854 [95 ] LIDC-IDRI 知识学习 结节分类 AUC=0.957 [109 ] Chest X-ray 14 注意力卷积神经网络 肺部疾病分类 AUC=0.871 [102 ] HUG database 迁移学习 间质性肺疾病分类 F1-score=0.88 [97 ] LIDC以及内部数据集 迁移学习 肺结节检测 AUC=0.812 [98 ] LIDC-IDRI 知识学习 肺结节分类 AUC=0.957 [109 ] LIDC-IDRI 流形学习 肺结节分类 ACC=0.90 [110 ] 乳腺 DDSM、MIAS、BCDR 迁移学习 乳腺癌分类 AUC=0.997(MIAS) AUC=0.956(BCDR) [99 ] 皮肤 ISIC 2016,2017 迁移学习 皮肤病分类 AUC=0.914 [96 ] 2017 ISBI Challenge on Skin Lesion Analysis Towards Melanoma Detection、EDRA、ISIC 知识学习 皮肤病分类 AUC=0.917 [103 ] ISIC 人工与学习特征结合 皮肤病分类 AUC=0.780 [107 ] 眼底 Messidor AlexNet 糖尿病视网膜病变分级 ACC=0.966 [94 ] 内部数据集 注意力卷积神经网络 青光眼分类 AUC=0.975 [104 ] UCSD、NEH 病变感知卷积神经网络 眼底疾病分类 AUC>0.96 [103 ] 内部数据集 知识学习 青光眼分类 ACC=0.915 [108 ]
5 结束语 本文从医学图像数据产生、医学图像预处理,以及医学图像识别和分类等方面,阐述了深度学习模型在医学图像分析领域的应用现状.尽管深度学习模型(如CNN、LSTM、GAN、注意力机制、图模型、迁移学习等)在医学图像分析中已取得众多突破,然而将深度学习应用于临床,辅助临床进行精准诊断和个性化治疗仍受到以下几方面的限制. ...
... [
109 ]
LIDC-IDRI 流形学习 肺结节分类 ACC=0.90 [110 ] 乳腺 DDSM、MIAS、BCDR 迁移学习 乳腺癌分类 AUC=0.997(MIAS) AUC=0.956(BCDR) [99 ] 皮肤 ISIC 2016,2017 迁移学习 皮肤病分类 AUC=0.914 [96 ] 2017 ISBI Challenge on Skin Lesion Analysis Towards Melanoma Detection、EDRA、ISIC 知识学习 皮肤病分类 AUC=0.917 [103 ] ISIC 人工与学习特征结合 皮肤病分类 AUC=0.780 [107 ] 眼底 Messidor AlexNet 糖尿病视网膜病变分级 ACC=0.966 [94 ] 内部数据集 注意力卷积神经网络 青光眼分类 AUC=0.975 [104 ] UCSD、NEH 病变感知卷积神经网络 眼底疾病分类 AUC>0.96 [103 ] 内部数据集 知识学习 青光眼分类 ACC=0.915 [108 ] 5 结束语 本文从医学图像数据产生、医学图像预处理,以及医学图像识别和分类等方面,阐述了深度学习模型在医学图像分析领域的应用现状.尽管深度学习模型(如CNN、LSTM、GAN、注意力机制、图模型、迁移学习等)在医学图像分析中已取得众多突破,然而将深度学习应用于临床,辅助临床进行精准诊断和个性化治疗仍受到以下几方面的限制. ...
DeepLesion:automated mining of large-scale lesion annotations and universal lesion detection with deep learning
2
2018
... 医学图像目标识别也属于临床诊断的一种,即在一幅图像中标记出可能病变的区域,并对其进行分类,如
图5 所示.
10.11959/j.issn.2096-0271.2020056.F005 图5 医学图像目标识别示意图<sup>[<xref ref-type="bibr" rid="b110">110</xref>]</sup> ![]()
传统的人工标记识别费时费力.最初将深度学习模型应用于目标识别时,主要是将图像分成小块,逐块输入由CNN等组成的二分类模型中,判断其是否属于目标区域[111 ,112 ] .随着深度学习模型在目标检测领域的快速发展,尤其是Fast R-CNN模型和Mask R-CNN模型的出现,将整幅医学图像输入模型,即可一次找到所有可能的目标区域.但是在这两类模型中均存在一个区域建议模块和一个分类模块,二者需要进行迭代更新,模型的速度并不能满足临床的实时性要求.YOLO(you only look once)和SSD(single shot multibox detector)模型的问世解决了目标检测的实时性问题.基于此类模型,Lin T Y等人[113 ] 提出RetinaNet模型,并将其扩展应用到病理图像和钼靶图像乳腺肿瘤识别[114 ,115 ] 、CT图像的肺结节检测[98 ,116 ] 中.上述模型均针对2D图像进行目标检测,忽略了3D图像中切片和切片之间的空间信息.为了提高识别的准确度,基于RNN和LSTM的识别模型被应用到医学图像中[117 ,118 ,119 ] . ...
... 基于深度学习的医学图像分类总结
器官 数据集 方法 目标 精度 文献 肺 LIDC-IDRI、ANODE09 challenge、DLCST 卷积神经网络 结节分类 Sensitivity=0.854 [95 ] LIDC-IDRI 知识学习 结节分类 AUC=0.957 [109 ] Chest X-ray 14 注意力卷积神经网络 肺部疾病分类 AUC=0.871 [102 ] HUG database 迁移学习 间质性肺疾病分类 F1-score=0.88 [97 ] LIDC以及内部数据集 迁移学习 肺结节检测 AUC=0.812 [98 ] LIDC-IDRI 知识学习 肺结节分类 AUC=0.957 [109 ] LIDC-IDRI 流形学习 肺结节分类 ACC=0.90 [110 ] 乳腺 DDSM、MIAS、BCDR 迁移学习 乳腺癌分类 AUC=0.997(MIAS) AUC=0.956(BCDR) [99 ] 皮肤 ISIC 2016,2017 迁移学习 皮肤病分类 AUC=0.914 [96 ] 2017 ISBI Challenge on Skin Lesion Analysis Towards Melanoma Detection、EDRA、ISIC 知识学习 皮肤病分类 AUC=0.917 [103 ] ISIC 人工与学习特征结合 皮肤病分类 AUC=0.780 [107 ] 眼底 Messidor AlexNet 糖尿病视网膜病变分级 ACC=0.966 [94 ] 内部数据集 注意力卷积神经网络 青光眼分类 AUC=0.975 [104 ] UCSD、NEH 病变感知卷积神经网络 眼底疾病分类 AUC>0.96 [103 ] 内部数据集 知识学习 青光眼分类 ACC=0.915 [108 ]
5 结束语 本文从医学图像数据产生、医学图像预处理,以及医学图像识别和分类等方面,阐述了深度学习模型在医学图像分析领域的应用现状.尽管深度学习模型(如CNN、LSTM、GAN、注意力机制、图模型、迁移学习等)在医学图像分析中已取得众多突破,然而将深度学习应用于临床,辅助临床进行精准诊断和个性化治疗仍受到以下几方面的限制. ...
Localizing tuberculosis in chest radiographs with deep learning
1
2018
... 传统的人工标记识别费时费力.最初将深度学习模型应用于目标识别时,主要是将图像分成小块,逐块输入由CNN等组成的二分类模型中,判断其是否属于目标区域[111 ,112 ] .随着深度学习模型在目标检测领域的快速发展,尤其是Fast R-CNN模型和Mask R-CNN模型的出现,将整幅医学图像输入模型,即可一次找到所有可能的目标区域.但是在这两类模型中均存在一个区域建议模块和一个分类模块,二者需要进行迭代更新,模型的速度并不能满足临床的实时性要求.YOLO(you only look once)和SSD(single shot multibox detector)模型的问世解决了目标检测的实时性问题.基于此类模型,Lin T Y等人[113 ] 提出RetinaNet模型,并将其扩展应用到病理图像和钼靶图像乳腺肿瘤识别[114 ,115 ] 、CT图像的肺结节检测[98 ,116 ] 中.上述模型均针对2D图像进行目标检测,忽略了3D图像中切片和切片之间的空间信息.为了提高识别的准确度,基于RNN和LSTM的识别模型被应用到医学图像中[117 ,118 ,119 ] . ...
Accurate pulmonary nodule detection in computed tomography images using deep convolutional neural networks
1
2017
... 传统的人工标记识别费时费力.最初将深度学习模型应用于目标识别时,主要是将图像分成小块,逐块输入由CNN等组成的二分类模型中,判断其是否属于目标区域[111 ,112 ] .随着深度学习模型在目标检测领域的快速发展,尤其是Fast R-CNN模型和Mask R-CNN模型的出现,将整幅医学图像输入模型,即可一次找到所有可能的目标区域.但是在这两类模型中均存在一个区域建议模块和一个分类模块,二者需要进行迭代更新,模型的速度并不能满足临床的实时性要求.YOLO(you only look once)和SSD(single shot multibox detector)模型的问世解决了目标检测的实时性问题.基于此类模型,Lin T Y等人[113 ] 提出RetinaNet模型,并将其扩展应用到病理图像和钼靶图像乳腺肿瘤识别[114 ,115 ] 、CT图像的肺结节检测[98 ,116 ] 中.上述模型均针对2D图像进行目标检测,忽略了3D图像中切片和切片之间的空间信息.为了提高识别的准确度,基于RNN和LSTM的识别模型被应用到医学图像中[117 ,118 ,119 ] . ...
Focal loss for dense object detection
1
2017
... 传统的人工标记识别费时费力.最初将深度学习模型应用于目标识别时,主要是将图像分成小块,逐块输入由CNN等组成的二分类模型中,判断其是否属于目标区域[111 ,112 ] .随着深度学习模型在目标检测领域的快速发展,尤其是Fast R-CNN模型和Mask R-CNN模型的出现,将整幅医学图像输入模型,即可一次找到所有可能的目标区域.但是在这两类模型中均存在一个区域建议模块和一个分类模块,二者需要进行迭代更新,模型的速度并不能满足临床的实时性要求.YOLO(you only look once)和SSD(single shot multibox detector)模型的问世解决了目标检测的实时性问题.基于此类模型,Lin T Y等人[113 ] 提出RetinaNet模型,并将其扩展应用到病理图像和钼靶图像乳腺肿瘤识别[114 ,115 ] 、CT图像的肺结节检测[98 ,116 ] 中.上述模型均针对2D图像进行目标检测,忽略了3D图像中切片和切片之间的空间信息.为了提高识别的准确度,基于RNN和LSTM的识别模型被应用到医学图像中[117 ,118 ,119 ] . ...
Robust breast cancer detection in mammography and digital breast tomosynthesis using annotationefficient deep learning approach
1
... 传统的人工标记识别费时费力.最初将深度学习模型应用于目标识别时,主要是将图像分成小块,逐块输入由CNN等组成的二分类模型中,判断其是否属于目标区域[111 ,112 ] .随着深度学习模型在目标检测领域的快速发展,尤其是Fast R-CNN模型和Mask R-CNN模型的出现,将整幅医学图像输入模型,即可一次找到所有可能的目标区域.但是在这两类模型中均存在一个区域建议模块和一个分类模块,二者需要进行迭代更新,模型的速度并不能满足临床的实时性要求.YOLO(you only look once)和SSD(single shot multibox detector)模型的问世解决了目标检测的实时性问题.基于此类模型,Lin T Y等人[113 ] 提出RetinaNet模型,并将其扩展应用到病理图像和钼靶图像乳腺肿瘤识别[114 ,115 ] 、CT图像的肺结节检测[98 ,116 ] 中.上述模型均针对2D图像进行目标检测,忽略了3D图像中切片和切片之间的空间信息.为了提高识别的准确度,基于RNN和LSTM的识别模型被应用到医学图像中[117 ,118 ,119 ] . ...
From point annotations to epithelial cell detection in breast cancer histopathology using RetinaNet
1
2019
... 传统的人工标记识别费时费力.最初将深度学习模型应用于目标识别时,主要是将图像分成小块,逐块输入由CNN等组成的二分类模型中,判断其是否属于目标区域[111 ,112 ] .随着深度学习模型在目标检测领域的快速发展,尤其是Fast R-CNN模型和Mask R-CNN模型的出现,将整幅医学图像输入模型,即可一次找到所有可能的目标区域.但是在这两类模型中均存在一个区域建议模块和一个分类模块,二者需要进行迭代更新,模型的速度并不能满足临床的实时性要求.YOLO(you only look once)和SSD(single shot multibox detector)模型的问世解决了目标检测的实时性问题.基于此类模型,Lin T Y等人[113 ] 提出RetinaNet模型,并将其扩展应用到病理图像和钼靶图像乳腺肿瘤识别[114 ,115 ] 、CT图像的肺结节检测[98 ,116 ] 中.上述模型均针对2D图像进行目标检测,忽略了3D图像中切片和切片之间的空间信息.为了提高识别的准确度,基于RNN和LSTM的识别模型被应用到医学图像中[117 ,118 ,119 ] . ...
Improving RetinaNet for CT lesion detection with dense masks from weak RECIST labels
1
2019
... 传统的人工标记识别费时费力.最初将深度学习模型应用于目标识别时,主要是将图像分成小块,逐块输入由CNN等组成的二分类模型中,判断其是否属于目标区域[111 ,112 ] .随着深度学习模型在目标检测领域的快速发展,尤其是Fast R-CNN模型和Mask R-CNN模型的出现,将整幅医学图像输入模型,即可一次找到所有可能的目标区域.但是在这两类模型中均存在一个区域建议模块和一个分类模块,二者需要进行迭代更新,模型的速度并不能满足临床的实时性要求.YOLO(you only look once)和SSD(single shot multibox detector)模型的问世解决了目标检测的实时性问题.基于此类模型,Lin T Y等人[113 ] 提出RetinaNet模型,并将其扩展应用到病理图像和钼靶图像乳腺肿瘤识别[114 ,115 ] 、CT图像的肺结节检测[98 ,116 ] 中.上述模型均针对2D图像进行目标检测,忽略了3D图像中切片和切片之间的空间信息.为了提高识别的准确度,基于RNN和LSTM的识别模型被应用到医学图像中[117 ,118 ,119 ] . ...
Longitudinal detection of radiological abnormalities with timemodulated LSTM
1
2018
... 传统的人工标记识别费时费力.最初将深度学习模型应用于目标识别时,主要是将图像分成小块,逐块输入由CNN等组成的二分类模型中,判断其是否属于目标区域[111 ,112 ] .随着深度学习模型在目标检测领域的快速发展,尤其是Fast R-CNN模型和Mask R-CNN模型的出现,将整幅医学图像输入模型,即可一次找到所有可能的目标区域.但是在这两类模型中均存在一个区域建议模块和一个分类模块,二者需要进行迭代更新,模型的速度并不能满足临床的实时性要求.YOLO(you only look once)和SSD(single shot multibox detector)模型的问世解决了目标检测的实时性问题.基于此类模型,Lin T Y等人[113 ] 提出RetinaNet模型,并将其扩展应用到病理图像和钼靶图像乳腺肿瘤识别[114 ,115 ] 、CT图像的肺结节检测[98 ,116 ] 中.上述模型均针对2D图像进行目标检测,忽略了3D图像中切片和切片之间的空间信息.为了提高识别的准确度,基于RNN和LSTM的识别模型被应用到医学图像中[117 ,118 ,119 ] . ...
Spatiotemporal joint mitosis detection using CNN-LSTM network in time-lapse phase contrast microscopy images
1
2017
... 传统的人工标记识别费时费力.最初将深度学习模型应用于目标识别时,主要是将图像分成小块,逐块输入由CNN等组成的二分类模型中,判断其是否属于目标区域[111 ,112 ] .随着深度学习模型在目标检测领域的快速发展,尤其是Fast R-CNN模型和Mask R-CNN模型的出现,将整幅医学图像输入模型,即可一次找到所有可能的目标区域.但是在这两类模型中均存在一个区域建议模块和一个分类模块,二者需要进行迭代更新,模型的速度并不能满足临床的实时性要求.YOLO(you only look once)和SSD(single shot multibox detector)模型的问世解决了目标检测的实时性问题.基于此类模型,Lin T Y等人[113 ] 提出RetinaNet模型,并将其扩展应用到病理图像和钼靶图像乳腺肿瘤识别[114 ,115 ] 、CT图像的肺结节检测[98 ,116 ] 中.上述模型均针对2D图像进行目标检测,忽略了3D图像中切片和切片之间的空间信息.为了提高识别的准确度,基于RNN和LSTM的识别模型被应用到医学图像中[117 ,118 ,119 ] . ...
Distanced LSTM:time-distanced gates in long short-term memory models for lung cancer detection
1
2019
... 传统的人工标记识别费时费力.最初将深度学习模型应用于目标识别时,主要是将图像分成小块,逐块输入由CNN等组成的二分类模型中,判断其是否属于目标区域[111 ,112 ] .随着深度学习模型在目标检测领域的快速发展,尤其是Fast R-CNN模型和Mask R-CNN模型的出现,将整幅医学图像输入模型,即可一次找到所有可能的目标区域.但是在这两类模型中均存在一个区域建议模块和一个分类模块,二者需要进行迭代更新,模型的速度并不能满足临床的实时性要求.YOLO(you only look once)和SSD(single shot multibox detector)模型的问世解决了目标检测的实时性问题.基于此类模型,Lin T Y等人[113 ] 提出RetinaNet模型,并将其扩展应用到病理图像和钼靶图像乳腺肿瘤识别[114 ,115 ] 、CT图像的肺结节检测[98 ,116 ] 中.上述模型均针对2D图像进行目标检测,忽略了3D图像中切片和切片之间的空间信息.为了提高识别的准确度,基于RNN和LSTM的识别模型被应用到医学图像中[117 ,118 ,119 ] . ...
Deep convolutional neural networks for computer-aided detection:CNN architectures,dataset characteristics and transfer learning
1
2016
... 此外,在医学图像目标识别中,同样存在数据不充足的问题.为了解决这个问题,基于迁移学习的医学图像识别逐渐开展起来,如基于ImageNet数据进行模型迁移,实现肺结节[120 ] 、乳腺癌[99 ] 和结直肠息肉的检测[121 ] .同时,基于临床经验知识指导的迁移学习也被应用到医学图像的目标检测中.典型代表有AGCL模型,其基于注意力的课程学习,实现胸片中的肿瘤检测[121 ] ;CASED (curriculum adaptive sampling for extreme data imbalance)模型,其可检测CT图像中的肺结节[122 ] ;特征金字塔模型(feature pyramid network,FPN),其采用不同对比度的图像,利用多尺度注意力模型实现肿瘤检测[123 ] . ...
Automatic detection and classification of colorectal polyps by transferring low-level CNN features from nonmedical domain
2
2016
... 此外,在医学图像目标识别中,同样存在数据不充足的问题.为了解决这个问题,基于迁移学习的医学图像识别逐渐开展起来,如基于ImageNet数据进行模型迁移,实现肺结节[120 ] 、乳腺癌[99 ] 和结直肠息肉的检测[121 ] .同时,基于临床经验知识指导的迁移学习也被应用到医学图像的目标检测中.典型代表有AGCL模型,其基于注意力的课程学习,实现胸片中的肿瘤检测[121 ] ;CASED (curriculum adaptive sampling for extreme data imbalance)模型,其可检测CT图像中的肺结节[122 ] ;特征金字塔模型(feature pyramid network,FPN),其采用不同对比度的图像,利用多尺度注意力模型实现肿瘤检测[123 ] . ...
... [121 ];CASED (curriculum adaptive sampling for extreme data imbalance)模型,其可检测CT图像中的肺结节[122 ] ;特征金字塔模型(feature pyramid network,FPN),其采用不同对比度的图像,利用多尺度注意力模型实现肿瘤检测[123 ] . ...
CASED:curriculum adaptive sampling for extreme data imbalance
1
2017
... 此外,在医学图像目标识别中,同样存在数据不充足的问题.为了解决这个问题,基于迁移学习的医学图像识别逐渐开展起来,如基于ImageNet数据进行模型迁移,实现肺结节[120 ] 、乳腺癌[99 ] 和结直肠息肉的检测[121 ] .同时,基于临床经验知识指导的迁移学习也被应用到医学图像的目标检测中.典型代表有AGCL模型,其基于注意力的课程学习,实现胸片中的肿瘤检测[121 ] ;CASED (curriculum adaptive sampling for extreme data imbalance)模型,其可检测CT图像中的肺结节[122 ] ;特征金字塔模型(feature pyramid network,FPN),其采用不同对比度的图像,利用多尺度注意力模型实现肿瘤检测[123 ] . ...
3DFPNHS 2:3D feature pyramid network based high sensitivity and specificity pulmonary nodule detection
1
2019
... 此外,在医学图像目标识别中,同样存在数据不充足的问题.为了解决这个问题,基于迁移学习的医学图像识别逐渐开展起来,如基于ImageNet数据进行模型迁移,实现肺结节[120 ] 、乳腺癌[99 ] 和结直肠息肉的检测[121 ] .同时,基于临床经验知识指导的迁移学习也被应用到医学图像的目标检测中.典型代表有AGCL模型,其基于注意力的课程学习,实现胸片中的肿瘤检测[121 ] ;CASED (curriculum adaptive sampling for extreme data imbalance)模型,其可检测CT图像中的肺结节[122 ] ;特征金字塔模型(feature pyramid network,FPN),其采用不同对比度的图像,利用多尺度注意力模型实现肿瘤检测[123 ] . ...








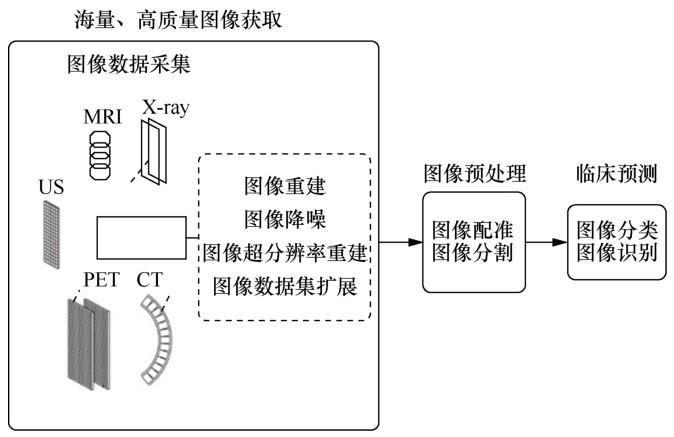
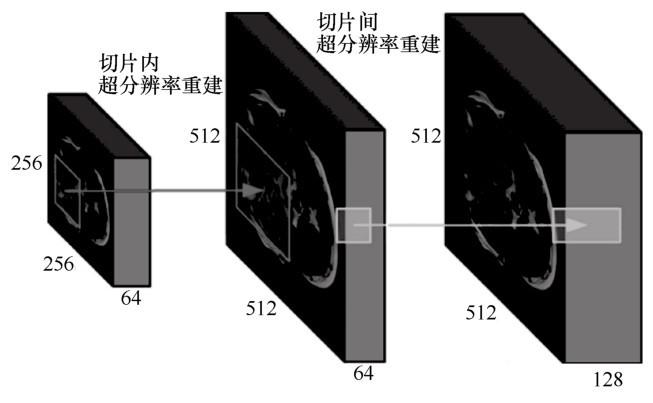
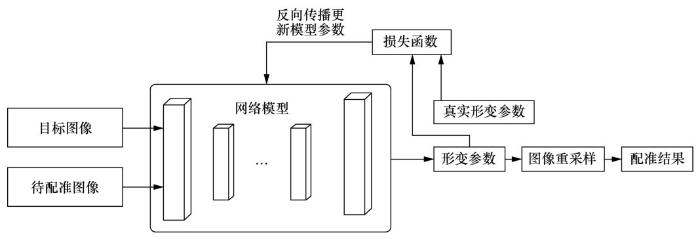
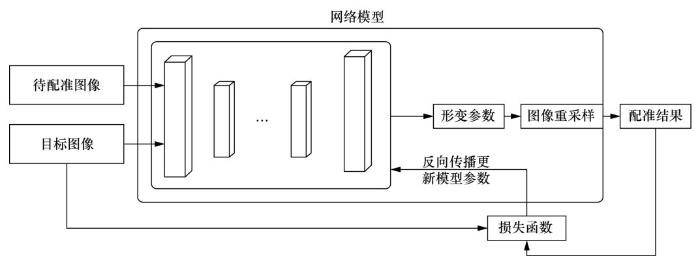

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}