Entity relationship extraction technology can automatically extract information from massive unstructured texts to construct large-scale knowledge graph, enrich the content of existing knowledge graph, and provide support for reasoning and application of knowledge graph.Although the cascading entity relation extraction technology has achieved good results, it has some shortcomings in the vector representation of the subject and the decoding of pointer network.In order to solve the representation problem of subject vectors, attention mechanism and mask mechanism were used to generate subject vectors.In addition, to solve the problem that long entities have been decoded in pointer network due to missing label, an entity sequence marker task was introduced to assist pointer network decoding entities.There is a 0.88% improvement over the previous model on the large-scale entity relationship dataset DuIE 2.0.
ZHENG Shenpeng, CHEN Xiaojun, XIANG Yang, SHEN Ruchao. An entity relation extraction method based on subject mask. Big data research[J], 2021, 7(3): 2021022- DOI:10.11959/j.issn.2096-0271.2021022
联合抽取方法旨在利用一个模型实现实体识别和关系抽取,有效避免流水线方法中存在的两点弊端。联合抽取方法依据解码方式一般可分为独立解码、级联解码和一次解码3类。在独立解码的方法中,实体识别和关系抽取共享文本编码层,在解码时仍然是两个独立的部分。为了使两个任务间建立更加密切的联系,级联解码的方法通常会先抽取主体,再根据主体抽取相关的关系-客体。而一次解码方法则将实体识别和关系抽取统一为一个任务,一次抽取出实体对及其对应关系。目前级联解码的方法和一次解码的方法在实体关系抽取中都取得了不错的成绩。在后两类方法中,实体嵌套问题[11-12]和关系重叠问题相互交织,使情况变得比较复杂,见表1。Wei Z P等人[13]提出了一种新颖的级联式标记框架,很好地解决了联合抽取中实体嵌套和关系重叠同时存在的问题。该方法将实体关系抽取看作抽取主体和根据主体抽取关系-客体两个部分,并且采用指针网络的结构标注主体与客体。但是,此方法在表示主体向量时,只是简单地将主体所含的所有字向量做平均,这会导致一些显著特征在平均后会丢失,尤其是在中文中。此外,使用指针网络标注时,模型漏标会导致出现过长且有明显错误的实体。针对该方法中存在的两点问题,本文提出了以下改进:
早期联合抽取方法通常是基于人工构造特征的结构化学习方法。Miwa M等人[21]首次将神经网络的方法用于联合抽取实体和关系,该方法将实体关系抽取分解为实体识别子任务和关系分类子任务。在模型中使用双向序列LSTM对文本进行编码,将实体识别子任务当作序列标注任务,输出具有依赖关系的实体标签。同时,在关系分类子任务中捕获词性标签等依赖特征和实体识别子任务中输出的实体序列,形成依存树,并根据依存树中目标实体间的最短路径对文本进行关系抽取。在该模型中,关系分类子任务和实体识别子任务的解码过程仍然是独立的,它们仅仅共享了编码层的双向序列LSTM表示,并不能完全地避免流水线方法的问题。Zheng S C等人[22]认为之前的联合抽取方法虽然将两个任务整合到一个模型中并共享了一部分参数,但是实体识别与关系抽取任务仍是两个相对独立的过程。于是Zheng S C等人[22]提出了一种基于新的标注策略的实体关系抽取方法,把原来涉及实体识别和关系分类两个子任务的联合学习模型完全变成了一个序列标注问题。在该方法中,实体的位置标签和关系标签被统一为一个标签,通过一个端到端的神经网络模型一次解码就可得到实体以及实体间的关系,解决了独立解码的实体关系联合抽取方法的交互不充分和实体冗余问题。但是,该方法没有能力应对普遍存在的实体嵌套和关系重叠的情况,这使得该方法在实际应用中难以取得好的效果。
为了应对实体嵌套和关系重叠的问题,Li X Y等人[23]提出将实体关系联合抽取的任务当作一个多轮问答类问题来处理,该方法需要构造不同的问题模板,通过一问一答的形式依次提取出主体、关系、客体。这种多轮问答的方法能够很好地解决实体嵌套和关系重叠的问题,但是其需要为每一种主体类型、每一种关系都设计一个问答模板,并进行多次问答,这会产生很多计算冗余,非常消耗计算资源。Wei Z P等人[13]提出了一种级联式解码实体关系抽取方法,并用多层二元指针网络标记实体。不同于独立解码模型,该方法将任务分解为主体识别子任务和依据主体抽取关系-客体子任务,而且将两个子任务都统一为序列标注问题。该方法解决了实体嵌套和关系重叠的问题,同时没有引入太多的冗余计算。但是,此方法简单地将主体所含的所有字向量取平均后作为主体向量,导致一些显著特征在平均后会丢失。此外,因为指针网络仅标记实体的首尾位置,当出现漏标时,会导致模型解码出比较长的错误实体。为此,本文提出基于主体掩码的主体向量生成方法,并利用实体序列标注辅助指针网络解码实体。
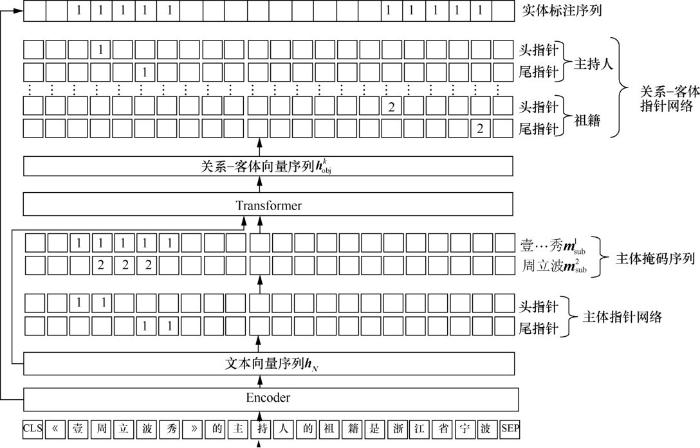
3 基于主体掩码的实体关系抽取模型
实体关系抽取旨在抽取出文本中所有的<主体,关系,客体>三元组,而这些三元组间可能会存在实体嵌套和关系重叠的情况,为了应对这类情况,Wei Z P等人[13]提出了一种基于新型的级联式二元标注结构的实体关系抽取模型。不同于以往的模型,该模型将任务分解为主体识别阶段和关系-客体识别阶段。在该模型的基础上,本文提出基于主体掩码的主体向量生成方法,利用注意力机制和掩码机制,生成主体向量。此外,为了排除因模型漏标产生的长度过长的实体,增加实体序列标注任务,以辅助实体解码。
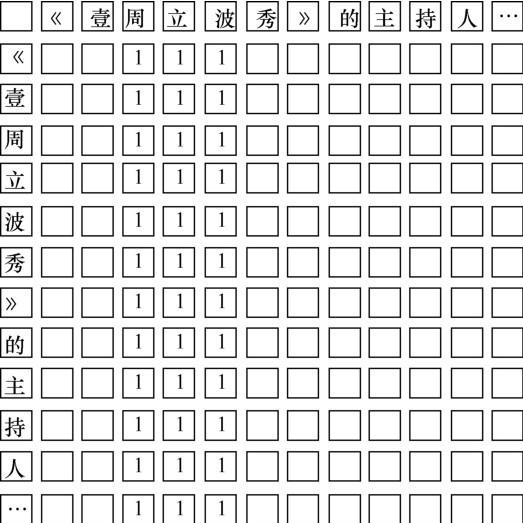
实体标记有多种不同的方案,从简单地使用0/1标记到使用OBIE(O表示非实体,B表示开始,I表示内部,E表示实体尾部)标记。但是这些方案不能解决实体嵌套问题,这在相当程度上降低了实体关系抽取的准确率。为了解决实体嵌套的问题,本文采用Wei Z P等人[13]使用的指针网络标记方案。指针网络在解码时一般采用就近原则,头指针与后文的第一个尾指针配对,尾指针与前文中最近的头指针配对。若出现头指针、头指针、尾指针、尾指针的序列模式,则认定为包含模式,将处于最前和最后的头尾指针配对,中间的头尾指针配对,如图1中例子所示。
A systematic exploration of the feature space for relation extraction
[C]// Proceedings of the Main Conference on Human Language Technologies 2007:The Conference of the North American Chapter of the Association for Computational Linguistics. Stroudsburg:ACL Press, 2007: 113-120.
A boundary-aware neural model for nested named entity recognition
[C]// Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing. Stroudsburg:ACL Press, 2019: 357-366.
Semantic compositionality through recursive matrix-vector spaces
[C]// Proceedings of the 2012 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning. Stroudsburg:ACL Press, 2012: 1201-1211.
Pyramid:a layered model for nested named entity recognition
1
2020
... 联合抽取方法旨在利用一个模型实现实体识别和关系抽取,有效避免流水线方法中存在的两点弊端.联合抽取方法依据解码方式一般可分为独立解码、级联解码和一次解码3类.在独立解码的方法中,实体识别和关系抽取共享文本编码层,在解码时仍然是两个独立的部分.为了使两个任务间建立更加密切的联系,级联解码的方法通常会先抽取主体,再根据主体抽取相关的关系-客体.而一次解码方法则将实体识别和关系抽取统一为一个任务,一次抽取出实体对及其对应关系.目前级联解码的方法和一次解码的方法在实体关系抽取中都取得了不错的成绩.在后两类方法中,实体嵌套问题[11-12]和关系重叠问题相互交织,使情况变得比较复杂,见表1.Wei Z P等人[13]提出了一种新颖的级联式标记框架,很好地解决了联合抽取中实体嵌套和关系重叠同时存在的问题.该方法将实体关系抽取看作抽取主体和根据主体抽取关系-客体两个部分,并且采用指针网络的结构标注主体与客体.但是,此方法在表示主体向量时,只是简单地将主体所含的所有字向量做平均,这会导致一些显著特征在平均后会丢失,尤其是在中文中.此外,使用指针网络标注时,模型漏标会导致出现过长且有明显错误的实体.针对该方法中存在的两点问题,本文提出了以下改进: ...
A boundary-aware neural model for nested named entity recognition
1
2019
... 联合抽取方法旨在利用一个模型实现实体识别和关系抽取,有效避免流水线方法中存在的两点弊端.联合抽取方法依据解码方式一般可分为独立解码、级联解码和一次解码3类.在独立解码的方法中,实体识别和关系抽取共享文本编码层,在解码时仍然是两个独立的部分.为了使两个任务间建立更加密切的联系,级联解码的方法通常会先抽取主体,再根据主体抽取相关的关系-客体.而一次解码方法则将实体识别和关系抽取统一为一个任务,一次抽取出实体对及其对应关系.目前级联解码的方法和一次解码的方法在实体关系抽取中都取得了不错的成绩.在后两类方法中,实体嵌套问题[11-12]和关系重叠问题相互交织,使情况变得比较复杂,见表1.Wei Z P等人[13]提出了一种新颖的级联式标记框架,很好地解决了联合抽取中实体嵌套和关系重叠同时存在的问题.该方法将实体关系抽取看作抽取主体和根据主体抽取关系-客体两个部分,并且采用指针网络的结构标注主体与客体.但是,此方法在表示主体向量时,只是简单地将主体所含的所有字向量做平均,这会导致一些显著特征在平均后会丢失,尤其是在中文中.此外,使用指针网络标注时,模型漏标会导致出现过长且有明显错误的实体.针对该方法中存在的两点问题,本文提出了以下改进: ...
A novel cascade binary tagging framework for relational triple extraction
5
2020
... 联合抽取方法旨在利用一个模型实现实体识别和关系抽取,有效避免流水线方法中存在的两点弊端.联合抽取方法依据解码方式一般可分为独立解码、级联解码和一次解码3类.在独立解码的方法中,实体识别和关系抽取共享文本编码层,在解码时仍然是两个独立的部分.为了使两个任务间建立更加密切的联系,级联解码的方法通常会先抽取主体,再根据主体抽取相关的关系-客体.而一次解码方法则将实体识别和关系抽取统一为一个任务,一次抽取出实体对及其对应关系.目前级联解码的方法和一次解码的方法在实体关系抽取中都取得了不错的成绩.在后两类方法中,实体嵌套问题[11-12]和关系重叠问题相互交织,使情况变得比较复杂,见表1.Wei Z P等人[13]提出了一种新颖的级联式标记框架,很好地解决了联合抽取中实体嵌套和关系重叠同时存在的问题.该方法将实体关系抽取看作抽取主体和根据主体抽取关系-客体两个部分,并且采用指针网络的结构标注主体与客体.但是,此方法在表示主体向量时,只是简单地将主体所含的所有字向量做平均,这会导致一些显著特征在平均后会丢失,尤其是在中文中.此外,使用指针网络标注时,模型漏标会导致出现过长且有明显错误的实体.针对该方法中存在的两点问题,本文提出了以下改进: ...
... 为了应对实体嵌套和关系重叠的问题,Li X Y等人[23]提出将实体关系联合抽取的任务当作一个多轮问答类问题来处理,该方法需要构造不同的问题模板,通过一问一答的形式依次提取出主体、关系、客体.这种多轮问答的方法能够很好地解决实体嵌套和关系重叠的问题,但是其需要为每一种主体类型、每一种关系都设计一个问答模板,并进行多次问答,这会产生很多计算冗余,非常消耗计算资源.Wei Z P等人[13]提出了一种级联式解码实体关系抽取方法,并用多层二元指针网络标记实体.不同于独立解码模型,该方法将任务分解为主体识别子任务和依据主体抽取关系-客体子任务,而且将两个子任务都统一为序列标注问题.该方法解决了实体嵌套和关系重叠的问题,同时没有引入太多的冗余计算.但是,此方法简单地将主体所含的所有字向量取平均后作为主体向量,导致一些显著特征在平均后会丢失.此外,因为指针网络仅标记实体的首尾位置,当出现漏标时,会导致模型解码出比较长的错误实体.为此,本文提出基于主体掩码的主体向量生成方法,并利用实体序列标注辅助指针网络解码实体. ...
... 实体关系抽取旨在抽取出文本中所有的<主体,关系,客体>三元组,而这些三元组间可能会存在实体嵌套和关系重叠的情况,为了应对这类情况,Wei Z P等人[13]提出了一种基于新型的级联式二元标注结构的实体关系抽取模型.不同于以往的模型,该模型将任务分解为主体识别阶段和关系-客体识别阶段.在该模型的基础上,本文提出基于主体掩码的主体向量生成方法,利用注意力机制和掩码机制,生成主体向量.此外,为了排除因模型漏标产生的长度过长的实体,增加实体序列标注任务,以辅助实体解码. ...
... 实体标记有多种不同的方案,从简单地使用0/1标记到使用OBIE(O表示非实体,B表示开始,I表示内部,E表示实体尾部)标记.但是这些方案不能解决实体嵌套问题,这在相当程度上降低了实体关系抽取的准确率.为了解决实体嵌套的问题,本文采用Wei Z P等人[13]使用的指针网络标记方案.指针网络在解码时一般采用就近原则,头指针与后文的第一个尾指针配对,尾指针与前文中最近的头指针配对.若出现头指针、头指针、尾指针、尾指针的序列模式,则认定为包含模式,将处于最前和最后的头尾指针配对,中间的头尾指针配对,如图1中例子所示. ...
... 在训练时,若一个句子中有多个不同主体的三元组需要抽取,Wei Z P等人[13]会随机抽取一个主体进行训练.但是,同一个句子内的三元组是有联系的,这种操作会丢失这部分信息,且需要训练更多的轮数.因此,本文将有多个主体的样本复制多份,并各自计算主体向量,实现在一个批中训练全部的三元组. ...
Reducing the dimensionality of data with neural networks
1
2006
... 在知识图谱的构建过程中,实体关系抽取技术起着非常重要的作用.早期基于规则[3]、词典[4]或本体[5]的实体关系抽取方法存在跨领域的可移植性较差、人工标注成本较高以及召回率较低等问题.后来,相比于早期的方法,以统计语言模型为基础的传统机器学习关系抽取方法明显地提高了召回率,具有更强的领域适应性,获得了不错的效果.自从Hinton G E等人[14]首次正式地提出深度学习的概念,深度学习在多个领域取得了突破性进展,也渐渐被研究人员应用在实体关系抽取方面.此外, Transformer结构[15]、BERT(bidirectional encoder representations from transformers)[16]、RoBERTa(robustly optimized BERT pretraining approach)[17]等大规模预训练语言模型也极大地推动了实体关系抽取的进步.现阶段,实体关系抽取主要分为流水线方法和联合抽取方法. ...
Attention is all you need
2
2017
... 在知识图谱的构建过程中,实体关系抽取技术起着非常重要的作用.早期基于规则[3]、词典[4]或本体[5]的实体关系抽取方法存在跨领域的可移植性较差、人工标注成本较高以及召回率较低等问题.后来,相比于早期的方法,以统计语言模型为基础的传统机器学习关系抽取方法明显地提高了召回率,具有更强的领域适应性,获得了不错的效果.自从Hinton G E等人[14]首次正式地提出深度学习的概念,深度学习在多个领域取得了突破性进展,也渐渐被研究人员应用在实体关系抽取方面.此外, Transformer结构[15]、BERT(bidirectional encoder representations from transformers)[16]、RoBERTa(robustly optimized BERT pretraining approach)[17]等大规模预训练语言模型也极大地推动了实体关系抽取的进步.现阶段,实体关系抽取主要分为流水线方法和联合抽取方法. ...
End-to-end relation extraction using LSTMs on sequences and tree structures
1
2016
... 早期联合抽取方法通常是基于人工构造特征的结构化学习方法.Miwa M等人[21]首次将神经网络的方法用于联合抽取实体和关系,该方法将实体关系抽取分解为实体识别子任务和关系分类子任务.在模型中使用双向序列LSTM对文本进行编码,将实体识别子任务当作序列标注任务,输出具有依赖关系的实体标签.同时,在关系分类子任务中捕获词性标签等依赖特征和实体识别子任务中输出的实体序列,形成依存树,并根据依存树中目标实体间的最短路径对文本进行关系抽取.在该模型中,关系分类子任务和实体识别子任务的解码过程仍然是独立的,它们仅仅共享了编码层的双向序列LSTM表示,并不能完全地避免流水线方法的问题.Zheng S C等人[22]认为之前的联合抽取方法虽然将两个任务整合到一个模型中并共享了一部分参数,但是实体识别与关系抽取任务仍是两个相对独立的过程.于是Zheng S C等人[22]提出了一种基于新的标注策略的实体关系抽取方法,把原来涉及实体识别和关系分类两个子任务的联合学习模型完全变成了一个序列标注问题.在该方法中,实体的位置标签和关系标签被统一为一个标签,通过一个端到端的神经网络模型一次解码就可得到实体以及实体间的关系,解决了独立解码的实体关系联合抽取方法的交互不充分和实体冗余问题.但是,该方法没有能力应对普遍存在的实体嵌套和关系重叠的情况,这使得该方法在实际应用中难以取得好的效果. ...
Joint extraction of entities and relations based on a novel tagging scheme
2
2017
... 早期联合抽取方法通常是基于人工构造特征的结构化学习方法.Miwa M等人[21]首次将神经网络的方法用于联合抽取实体和关系,该方法将实体关系抽取分解为实体识别子任务和关系分类子任务.在模型中使用双向序列LSTM对文本进行编码,将实体识别子任务当作序列标注任务,输出具有依赖关系的实体标签.同时,在关系分类子任务中捕获词性标签等依赖特征和实体识别子任务中输出的实体序列,形成依存树,并根据依存树中目标实体间的最短路径对文本进行关系抽取.在该模型中,关系分类子任务和实体识别子任务的解码过程仍然是独立的,它们仅仅共享了编码层的双向序列LSTM表示,并不能完全地避免流水线方法的问题.Zheng S C等人[22]认为之前的联合抽取方法虽然将两个任务整合到一个模型中并共享了一部分参数,但是实体识别与关系抽取任务仍是两个相对独立的过程.于是Zheng S C等人[22]提出了一种基于新的标注策略的实体关系抽取方法,把原来涉及实体识别和关系分类两个子任务的联合学习模型完全变成了一个序列标注问题.在该方法中,实体的位置标签和关系标签被统一为一个标签,通过一个端到端的神经网络模型一次解码就可得到实体以及实体间的关系,解决了独立解码的实体关系联合抽取方法的交互不充分和实体冗余问题.但是,该方法没有能力应对普遍存在的实体嵌套和关系重叠的情况,这使得该方法在实际应用中难以取得好的效果. ...
Entityrelation extraction as multi-turn question answering
1
2019
... 为了应对实体嵌套和关系重叠的问题,Li X Y等人[23]提出将实体关系联合抽取的任务当作一个多轮问答类问题来处理,该方法需要构造不同的问题模板,通过一问一答的形式依次提取出主体、关系、客体.这种多轮问答的方法能够很好地解决实体嵌套和关系重叠的问题,但是其需要为每一种主体类型、每一种关系都设计一个问答模板,并进行多次问答,这会产生很多计算冗余,非常消耗计算资源.Wei Z P等人[13]提出了一种级联式解码实体关系抽取方法,并用多层二元指针网络标记实体.不同于独立解码模型,该方法将任务分解为主体识别子任务和依据主体抽取关系-客体子任务,而且将两个子任务都统一为序列标注问题.该方法解决了实体嵌套和关系重叠的问题,同时没有引入太多的冗余计算.但是,此方法简单地将主体所含的所有字向量取平均后作为主体向量,导致一些显著特征在平均后会丢失.此外,因为指针网络仅标记实体的首尾位置,当出现漏标时,会导致模型解码出比较长的错误实体.为此,本文提出基于主体掩码的主体向量生成方法,并利用实体序列标注辅助指针网络解码实体. ...
DuIE:a largescale Chinese dataset for information extraction










{kind=link}
{kind=link}
{kind=link}
{kind=link}