大规模企业级知识图谱实践综述
1
2020
... 随着大数据时代的来临,帮助用户在海量信息中快速找到想要的信息尤为重要.知识图谱(knowledge graph,KG)以三元组的形式结构化存储海量信息,一个三元组可以表示为<eh,r,et>,其中eh表示头实体,et表示尾实体,r表示头实体与尾实体之间存在的关系.知识图谱三元组之间也存在关联关系,如上述三元组中的头实体eh可能是另外一个三元组的尾实体.知识图谱把海量互联网信息表达成客观世界可认知的语义表示,具有强大的语义表达、存储和表达能力[1],在工业界和学术界得到了广泛关注和研究应用.智能问答系统[2]旨在针对用户提出的复杂信息需求,允许用户用自然语言问句的形式提问,并为用户直接返回精准的答案.得益于知识图谱技术的快速发展,基于知识图谱的问答(knowledge graph based question answering,KGQA)技术利用其丰富的结构化语义信息,能够深入理解用户的问题,并给出准确的答案[3],为用户提供7×24小时的智能问答服务,在医疗、教育、金融等多个领域凸显出重要的应用价值[4,5,6]. ...
大规模企业级知识图谱实践综述
1
2020
... 随着大数据时代的来临,帮助用户在海量信息中快速找到想要的信息尤为重要.知识图谱(knowledge graph,KG)以三元组的形式结构化存储海量信息,一个三元组可以表示为<eh,r,et>,其中eh表示头实体,et表示尾实体,r表示头实体与尾实体之间存在的关系.知识图谱三元组之间也存在关联关系,如上述三元组中的头实体eh可能是另外一个三元组的尾实体.知识图谱把海量互联网信息表达成客观世界可认知的语义表示,具有强大的语义表达、存储和表达能力[1],在工业界和学术界得到了广泛关注和研究应用.智能问答系统[2]旨在针对用户提出的复杂信息需求,允许用户用自然语言问句的形式提问,并为用户直接返回精准的答案.得益于知识图谱技术的快速发展,基于知识图谱的问答(knowledge graph based question answering,KGQA)技术利用其丰富的结构化语义信息,能够深入理解用户的问题,并给出准确的答案[3],为用户提供7×24小时的智能问答服务,在医疗、教育、金融等多个领域凸显出重要的应用价值[4,5,6]. ...
从聊天机器人到虚拟生命-人工智能技术的新机遇
1
2017
... 随着大数据时代的来临,帮助用户在海量信息中快速找到想要的信息尤为重要.知识图谱(knowledge graph,KG)以三元组的形式结构化存储海量信息,一个三元组可以表示为<eh,r,et>,其中eh表示头实体,et表示尾实体,r表示头实体与尾实体之间存在的关系.知识图谱三元组之间也存在关联关系,如上述三元组中的头实体eh可能是另外一个三元组的尾实体.知识图谱把海量互联网信息表达成客观世界可认知的语义表示,具有强大的语义表达、存储和表达能力[1],在工业界和学术界得到了广泛关注和研究应用.智能问答系统[2]旨在针对用户提出的复杂信息需求,允许用户用自然语言问句的形式提问,并为用户直接返回精准的答案.得益于知识图谱技术的快速发展,基于知识图谱的问答(knowledge graph based question answering,KGQA)技术利用其丰富的结构化语义信息,能够深入理解用户的问题,并给出准确的答案[3],为用户提供7×24小时的智能问答服务,在医疗、教育、金融等多个领域凸显出重要的应用价值[4,5,6]. ...
从聊天机器人到虚拟生命-人工智能技术的新机遇
1
2017
... 随着大数据时代的来临,帮助用户在海量信息中快速找到想要的信息尤为重要.知识图谱(knowledge graph,KG)以三元组的形式结构化存储海量信息,一个三元组可以表示为<eh,r,et>,其中eh表示头实体,et表示尾实体,r表示头实体与尾实体之间存在的关系.知识图谱三元组之间也存在关联关系,如上述三元组中的头实体eh可能是另外一个三元组的尾实体.知识图谱把海量互联网信息表达成客观世界可认知的语义表示,具有强大的语义表达、存储和表达能力[1],在工业界和学术界得到了广泛关注和研究应用.智能问答系统[2]旨在针对用户提出的复杂信息需求,允许用户用自然语言问句的形式提问,并为用户直接返回精准的答案.得益于知识图谱技术的快速发展,基于知识图谱的问答(knowledge graph based question answering,KGQA)技术利用其丰富的结构化语义信息,能够深入理解用户的问题,并给出准确的答案[3],为用户提供7×24小时的智能问答服务,在医疗、教育、金融等多个领域凸显出重要的应用价值[4,5,6]. ...
意图知识图谱的构建与应用
1
2020
... 随着大数据时代的来临,帮助用户在海量信息中快速找到想要的信息尤为重要.知识图谱(knowledge graph,KG)以三元组的形式结构化存储海量信息,一个三元组可以表示为<eh,r,et>,其中eh表示头实体,et表示尾实体,r表示头实体与尾实体之间存在的关系.知识图谱三元组之间也存在关联关系,如上述三元组中的头实体eh可能是另外一个三元组的尾实体.知识图谱把海量互联网信息表达成客观世界可认知的语义表示,具有强大的语义表达、存储和表达能力[1],在工业界和学术界得到了广泛关注和研究应用.智能问答系统[2]旨在针对用户提出的复杂信息需求,允许用户用自然语言问句的形式提问,并为用户直接返回精准的答案.得益于知识图谱技术的快速发展,基于知识图谱的问答(knowledge graph based question answering,KGQA)技术利用其丰富的结构化语义信息,能够深入理解用户的问题,并给出准确的答案[3],为用户提供7×24小时的智能问答服务,在医疗、教育、金融等多个领域凸显出重要的应用价值[4,5,6]. ...
意图知识图谱的构建与应用
1
2020
... 随着大数据时代的来临,帮助用户在海量信息中快速找到想要的信息尤为重要.知识图谱(knowledge graph,KG)以三元组的形式结构化存储海量信息,一个三元组可以表示为<eh,r,et>,其中eh表示头实体,et表示尾实体,r表示头实体与尾实体之间存在的关系.知识图谱三元组之间也存在关联关系,如上述三元组中的头实体eh可能是另外一个三元组的尾实体.知识图谱把海量互联网信息表达成客观世界可认知的语义表示,具有强大的语义表达、存储和表达能力[1],在工业界和学术界得到了广泛关注和研究应用.智能问答系统[2]旨在针对用户提出的复杂信息需求,允许用户用自然语言问句的形式提问,并为用户直接返回精准的答案.得益于知识图谱技术的快速发展,基于知识图谱的问答(knowledge graph based question answering,KGQA)技术利用其丰富的结构化语义信息,能够深入理解用户的问题,并给出准确的答案[3],为用户提供7×24小时的智能问答服务,在医疗、教育、金融等多个领域凸显出重要的应用价值[4,5,6]. ...
Knowledge graph construction from multiple online encyclopedias
1
2020
... 随着大数据时代的来临,帮助用户在海量信息中快速找到想要的信息尤为重要.知识图谱(knowledge graph,KG)以三元组的形式结构化存储海量信息,一个三元组可以表示为<eh,r,et>,其中eh表示头实体,et表示尾实体,r表示头实体与尾实体之间存在的关系.知识图谱三元组之间也存在关联关系,如上述三元组中的头实体eh可能是另外一个三元组的尾实体.知识图谱把海量互联网信息表达成客观世界可认知的语义表示,具有强大的语义表达、存储和表达能力[1],在工业界和学术界得到了广泛关注和研究应用.智能问答系统[2]旨在针对用户提出的复杂信息需求,允许用户用自然语言问句的形式提问,并为用户直接返回精准的答案.得益于知识图谱技术的快速发展,基于知识图谱的问答(knowledge graph based question answering,KGQA)技术利用其丰富的结构化语义信息,能够深入理解用户的问题,并给出准确的答案[3],为用户提供7×24小时的智能问答服务,在医疗、教育、金融等多个领域凸显出重要的应用价值[4,5,6]. ...
Richpedia:a large-scale,comprehensive multi-modal knowledge graph
1
2020
... 随着大数据时代的来临,帮助用户在海量信息中快速找到想要的信息尤为重要.知识图谱(knowledge graph,KG)以三元组的形式结构化存储海量信息,一个三元组可以表示为<eh,r,et>,其中eh表示头实体,et表示尾实体,r表示头实体与尾实体之间存在的关系.知识图谱三元组之间也存在关联关系,如上述三元组中的头实体eh可能是另外一个三元组的尾实体.知识图谱把海量互联网信息表达成客观世界可认知的语义表示,具有强大的语义表达、存储和表达能力[1],在工业界和学术界得到了广泛关注和研究应用.智能问答系统[2]旨在针对用户提出的复杂信息需求,允许用户用自然语言问句的形式提问,并为用户直接返回精准的答案.得益于知识图谱技术的快速发展,基于知识图谱的问答(knowledge graph based question answering,KGQA)技术利用其丰富的结构化语义信息,能够深入理解用户的问题,并给出准确的答案[3],为用户提供7×24小时的智能问答服务,在医疗、教育、金融等多个领域凸显出重要的应用价值[4,5,6]. ...
基于大数据的软件项目知识图谱构造及问答方法
1
2021
... 随着大数据时代的来临,帮助用户在海量信息中快速找到想要的信息尤为重要.知识图谱(knowledge graph,KG)以三元组的形式结构化存储海量信息,一个三元组可以表示为<eh,r,et>,其中eh表示头实体,et表示尾实体,r表示头实体与尾实体之间存在的关系.知识图谱三元组之间也存在关联关系,如上述三元组中的头实体eh可能是另外一个三元组的尾实体.知识图谱把海量互联网信息表达成客观世界可认知的语义表示,具有强大的语义表达、存储和表达能力[1],在工业界和学术界得到了广泛关注和研究应用.智能问答系统[2]旨在针对用户提出的复杂信息需求,允许用户用自然语言问句的形式提问,并为用户直接返回精准的答案.得益于知识图谱技术的快速发展,基于知识图谱的问答(knowledge graph based question answering,KGQA)技术利用其丰富的结构化语义信息,能够深入理解用户的问题,并给出准确的答案[3],为用户提供7×24小时的智能问答服务,在医疗、教育、金融等多个领域凸显出重要的应用价值[4,5,6]. ...
基于大数据的软件项目知识图谱构造及问答方法
1
2021
... 随着大数据时代的来临,帮助用户在海量信息中快速找到想要的信息尤为重要.知识图谱(knowledge graph,KG)以三元组的形式结构化存储海量信息,一个三元组可以表示为<eh,r,et>,其中eh表示头实体,et表示尾实体,r表示头实体与尾实体之间存在的关系.知识图谱三元组之间也存在关联关系,如上述三元组中的头实体eh可能是另外一个三元组的尾实体.知识图谱把海量互联网信息表达成客观世界可认知的语义表示,具有强大的语义表达、存储和表达能力[1],在工业界和学术界得到了广泛关注和研究应用.智能问答系统[2]旨在针对用户提出的复杂信息需求,允许用户用自然语言问句的形式提问,并为用户直接返回精准的答案.得益于知识图谱技术的快速发展,基于知识图谱的问答(knowledge graph based question answering,KGQA)技术利用其丰富的结构化语义信息,能够深入理解用户的问题,并给出准确的答案[3],为用户提供7×24小时的智能问答服务,在医疗、教育、金融等多个领域凸显出重要的应用价值[4,5,6]. ...
面向知识图谱的知识推理研究进展
1
2018
... 传统KGQA以实体、属性等单一具体对象为主,而在实际应用场景中,用户不再满足于单跳的知识问答,如在医疗领域中的咨询问题“常见的治疗感冒药物有哪些?”.用户更多地倾向表达复杂的多跳问答推理问题,如“请问伴有中耳炎并发症的感冒能用哪种药物治疗?”.而知识图谱多跳问答(以下简称多跳知识问答)[7-8]即针对包含多跳关系的问题,在知识图谱上进行多步推理,继而推断得到答案的一项任务. ...
面向知识图谱的知识推理研究进展
1
2018
... 传统KGQA以实体、属性等单一具体对象为主,而在实际应用场景中,用户不再满足于单跳的知识问答,如在医疗领域中的咨询问题“常见的治疗感冒药物有哪些?”.用户更多地倾向表达复杂的多跳问答推理问题,如“请问伴有中耳炎并发症的感冒能用哪种药物治疗?”.而知识图谱多跳问答(以下简称多跳知识问答)[7-8]即针对包含多跳关系的问题,在知识图谱上进行多步推理,继而推断得到答案的一项任务. ...
企业计算中的机器人智能问答
1
2019
... 传统KGQA以实体、属性等单一具体对象为主,而在实际应用场景中,用户不再满足于单跳的知识问答,如在医疗领域中的咨询问题“常见的治疗感冒药物有哪些?”.用户更多地倾向表达复杂的多跳问答推理问题,如“请问伴有中耳炎并发症的感冒能用哪种药物治疗?”.而知识图谱多跳问答(以下简称多跳知识问答)[7-8]即针对包含多跳关系的问题,在知识图谱上进行多步推理,继而推断得到答案的一项任务. ...
企业计算中的机器人智能问答
1
2019
... 传统KGQA以实体、属性等单一具体对象为主,而在实际应用场景中,用户不再满足于单跳的知识问答,如在医疗领域中的咨询问题“常见的治疗感冒药物有哪些?”.用户更多地倾向表达复杂的多跳问答推理问题,如“请问伴有中耳炎并发症的感冒能用哪种药物治疗?”.而知识图谱多跳问答(以下简称多跳知识问答)[7-8]即针对包含多跳关系的问题,在知识图谱上进行多步推理,继而推断得到答案的一项任务. ...
Towards empty answers in SPARQL:approximating querying with RDF embedding
1
2018
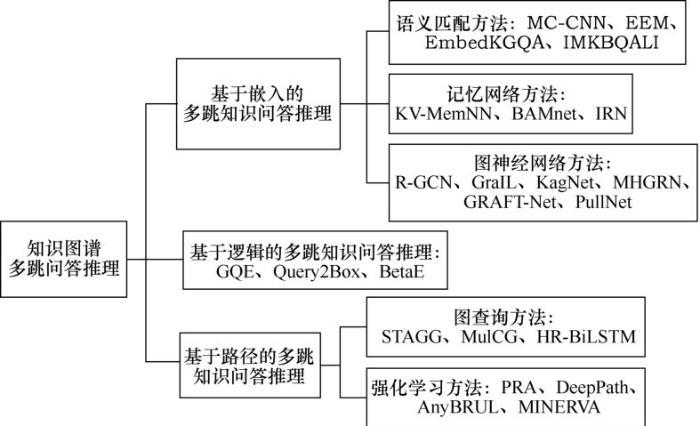
... 本文总结多跳知识问答推理的最新研究方法,并将这些方法分为基于嵌入的多跳知识问答推理、基于路径的多跳知识问答推理和基于逻辑的多跳知识问答推理3类方法.其中,基于嵌入的多跳知识问答推理方法是将知识图谱元素(如实体、关系等)关联到低维连续向量空间[9],然后通过定义得分函数或解码器对目标查询对象进行排名来得到答案.而基于路径的多跳知识问答推理方法首先需要确定问题中的主题实体,然后在知识图谱上随机游走找到答案实体[10-11],代表性的工作有路径排序算法(path ranking approach,PRA).关于基于逻辑的多跳知识问答推理方法,本文将重点介绍以一阶逻辑为主的热点研究方法.图1所示为基于知识图谱的多跳问答推理方法分类,接下来综述这些分类中最新方法的研究进展、基本思路和存在的挑战等. ...
A graph traversal based approach to answer nonaggregation questions over DBpedia
1
2015
... 本文总结多跳知识问答推理的最新研究方法,并将这些方法分为基于嵌入的多跳知识问答推理、基于路径的多跳知识问答推理和基于逻辑的多跳知识问答推理3类方法.其中,基于嵌入的多跳知识问答推理方法是将知识图谱元素(如实体、关系等)关联到低维连续向量空间[9],然后通过定义得分函数或解码器对目标查询对象进行排名来得到答案.而基于路径的多跳知识问答推理方法首先需要确定问题中的主题实体,然后在知识图谱上随机游走找到答案实体[10-11],代表性的工作有路径排序算法(path ranking approach,PRA).关于基于逻辑的多跳知识问答推理方法,本文将重点介绍以一阶逻辑为主的热点研究方法.图1所示为基于知识图谱的多跳问答推理方法分类,接下来综述这些分类中最新方法的研究进展、基本思路和存在的挑战等. ...
Semplore:a scalable IR approach to search the Web of data
1
2009
... 本文总结多跳知识问答推理的最新研究方法,并将这些方法分为基于嵌入的多跳知识问答推理、基于路径的多跳知识问答推理和基于逻辑的多跳知识问答推理3类方法.其中,基于嵌入的多跳知识问答推理方法是将知识图谱元素(如实体、关系等)关联到低维连续向量空间[9],然后通过定义得分函数或解码器对目标查询对象进行排名来得到答案.而基于路径的多跳知识问答推理方法首先需要确定问题中的主题实体,然后在知识图谱上随机游走找到答案实体[10-11],代表性的工作有路径排序算法(path ranking approach,PRA).关于基于逻辑的多跳知识问答推理方法,本文将重点介绍以一阶逻辑为主的热点研究方法.图1所示为基于知识图谱的多跳问答推理方法分类,接下来综述这些分类中最新方法的研究进展、基本思路和存在的挑战等. ...
Open question answering with weakly supervised embedding models
3
2014
... 本类方法首先计算问题和候选答案分布式表示之间的语义匹配,然后通过排序候选答案来得到最终答案.Bordes A等人[12]将问题和知识图谱三元组用嵌入的方式表示来表达特征的语义.然而,与翻译模型TransE[13]、TransH[14]、TransR[15]等关注嵌入表示的模型类似,这些方法只能回答简单问题[12,16-17].为了实现多跳问答推理以及应对多跳知识高效建模的挑战,很多基于语义匹配的方法被提出.Bordes A等人[18]在原来三元组表示方法[12]的基础上做了改进,通过对知识图谱中的问答路径和周围子图进行编码得到语义更加丰富的表示来推理得到答案.Dong L等人[19]提出的多列卷积神经网络(multi-column convolutional neural network,MCCNN)模型进一步地利用具有更强学习能力的神经网络模型来学习答案路径、答案背景信息以及答案类型的分布式表示,并理解问题,在不使用手动特征及词库等的条件下,在问答数据集WebQuestions[20]上取得了不错的结果.其中,答案路径是答案节点和被询问实体之间的一组关系;答案上下文指的是连接到答案路径的单跳实体和关系;答案类型是如人名、日期等的类型.Hao Y C等人[21]认为MC-CNN模型没有充分并合理地考虑候选答案的相关信息来训练问题嵌入的表示,提出了CrossAttention机制的神经网络模型来学习知识图谱的全局信息,取得了更好的结果.但是以上几种方法只能完成浅层多跳知识问答推理,对复杂长路径多跳问题的处理能力依然不足. ...
... [12,16-17].为了实现多跳问答推理以及应对多跳知识高效建模的挑战,很多基于语义匹配的方法被提出.Bordes A等人[18]在原来三元组表示方法[12]的基础上做了改进,通过对知识图谱中的问答路径和周围子图进行编码得到语义更加丰富的表示来推理得到答案.Dong L等人[19]提出的多列卷积神经网络(multi-column convolutional neural network,MCCNN)模型进一步地利用具有更强学习能力的神经网络模型来学习答案路径、答案背景信息以及答案类型的分布式表示,并理解问题,在不使用手动特征及词库等的条件下,在问答数据集WebQuestions[20]上取得了不错的结果.其中,答案路径是答案节点和被询问实体之间的一组关系;答案上下文指的是连接到答案路径的单跳实体和关系;答案类型是如人名、日期等的类型.Hao Y C等人[21]认为MC-CNN模型没有充分并合理地考虑候选答案的相关信息来训练问题嵌入的表示,提出了CrossAttention机制的神经网络模型来学习知识图谱的全局信息,取得了更好的结果.但是以上几种方法只能完成浅层多跳知识问答推理,对复杂长路径多跳问题的处理能力依然不足. ...
... [12]的基础上做了改进,通过对知识图谱中的问答路径和周围子图进行编码得到语义更加丰富的表示来推理得到答案.Dong L等人[19]提出的多列卷积神经网络(multi-column convolutional neural network,MCCNN)模型进一步地利用具有更强学习能力的神经网络模型来学习答案路径、答案背景信息以及答案类型的分布式表示,并理解问题,在不使用手动特征及词库等的条件下,在问答数据集WebQuestions[20]上取得了不错的结果.其中,答案路径是答案节点和被询问实体之间的一组关系;答案上下文指的是连接到答案路径的单跳实体和关系;答案类型是如人名、日期等的类型.Hao Y C等人[21]认为MC-CNN模型没有充分并合理地考虑候选答案的相关信息来训练问题嵌入的表示,提出了CrossAttention机制的神经网络模型来学习知识图谱的全局信息,取得了更好的结果.但是以上几种方法只能完成浅层多跳知识问答推理,对复杂长路径多跳问题的处理能力依然不足. ...
Translating embeddings for modeling multi-relational data
1
2013
... 本类方法首先计算问题和候选答案分布式表示之间的语义匹配,然后通过排序候选答案来得到最终答案.Bordes A等人[12]将问题和知识图谱三元组用嵌入的方式表示来表达特征的语义.然而,与翻译模型TransE[13]、TransH[14]、TransR[15]等关注嵌入表示的模型类似,这些方法只能回答简单问题[12,16-17].为了实现多跳问答推理以及应对多跳知识高效建模的挑战,很多基于语义匹配的方法被提出.Bordes A等人[18]在原来三元组表示方法[12]的基础上做了改进,通过对知识图谱中的问答路径和周围子图进行编码得到语义更加丰富的表示来推理得到答案.Dong L等人[19]提出的多列卷积神经网络(multi-column convolutional neural network,MCCNN)模型进一步地利用具有更强学习能力的神经网络模型来学习答案路径、答案背景信息以及答案类型的分布式表示,并理解问题,在不使用手动特征及词库等的条件下,在问答数据集WebQuestions[20]上取得了不错的结果.其中,答案路径是答案节点和被询问实体之间的一组关系;答案上下文指的是连接到答案路径的单跳实体和关系;答案类型是如人名、日期等的类型.Hao Y C等人[21]认为MC-CNN模型没有充分并合理地考虑候选答案的相关信息来训练问题嵌入的表示,提出了CrossAttention机制的神经网络模型来学习知识图谱的全局信息,取得了更好的结果.但是以上几种方法只能完成浅层多跳知识问答推理,对复杂长路径多跳问题的处理能力依然不足. ...
Knowledge graph embedding by translating on hyperplanes
2
2014
... 本类方法首先计算问题和候选答案分布式表示之间的语义匹配,然后通过排序候选答案来得到最终答案.Bordes A等人[12]将问题和知识图谱三元组用嵌入的方式表示来表达特征的语义.然而,与翻译模型TransE[13]、TransH[14]、TransR[15]等关注嵌入表示的模型类似,这些方法只能回答简单问题[12,16-17].为了实现多跳问答推理以及应对多跳知识高效建模的挑战,很多基于语义匹配的方法被提出.Bordes A等人[18]在原来三元组表示方法[12]的基础上做了改进,通过对知识图谱中的问答路径和周围子图进行编码得到语义更加丰富的表示来推理得到答案.Dong L等人[19]提出的多列卷积神经网络(multi-column convolutional neural network,MCCNN)模型进一步地利用具有更强学习能力的神经网络模型来学习答案路径、答案背景信息以及答案类型的分布式表示,并理解问题,在不使用手动特征及词库等的条件下,在问答数据集WebQuestions[20]上取得了不错的结果.其中,答案路径是答案节点和被询问实体之间的一组关系;答案上下文指的是连接到答案路径的单跳实体和关系;答案类型是如人名、日期等的类型.Hao Y C等人[21]认为MC-CNN模型没有充分并合理地考虑候选答案的相关信息来训练问题嵌入的表示,提出了CrossAttention机制的神经网络模型来学习知识图谱的全局信息,取得了更好的结果.但是以上几种方法只能完成浅层多跳知识问答推理,对复杂长路径多跳问题的处理能力依然不足. ...
... FB15k[14]是Freebase的一个子集,也是知识图谱补全领域的一个基准数据集,由三元组构成.为了解决FB15k测试集数据泄露的问题,Toutanova K等人[71]在FB15k的基础上构建了FB15k-237,并且移除了FB15k中反向的关系.NELL995[47]数据集由NELL系统构建而来. ...
Learning entity and relation embeddings for knowledge graph completion
1
2015
... 本类方法首先计算问题和候选答案分布式表示之间的语义匹配,然后通过排序候选答案来得到最终答案.Bordes A等人[12]将问题和知识图谱三元组用嵌入的方式表示来表达特征的语义.然而,与翻译模型TransE[13]、TransH[14]、TransR[15]等关注嵌入表示的模型类似,这些方法只能回答简单问题[12,16-17].为了实现多跳问答推理以及应对多跳知识高效建模的挑战,很多基于语义匹配的方法被提出.Bordes A等人[18]在原来三元组表示方法[12]的基础上做了改进,通过对知识图谱中的问答路径和周围子图进行编码得到语义更加丰富的表示来推理得到答案.Dong L等人[19]提出的多列卷积神经网络(multi-column convolutional neural network,MCCNN)模型进一步地利用具有更强学习能力的神经网络模型来学习答案路径、答案背景信息以及答案类型的分布式表示,并理解问题,在不使用手动特征及词库等的条件下,在问答数据集WebQuestions[20]上取得了不错的结果.其中,答案路径是答案节点和被询问实体之间的一组关系;答案上下文指的是连接到答案路径的单跳实体和关系;答案类型是如人名、日期等的类型.Hao Y C等人[21]认为MC-CNN模型没有充分并合理地考虑候选答案的相关信息来训练问题嵌入的表示,提出了CrossAttention机制的神经网络模型来学习知识图谱的全局信息,取得了更好的结果.但是以上几种方法只能完成浅层多跳知识问答推理,对复杂长路径多跳问题的处理能力依然不足. ...
Representation learning for question classification via topic sparse autoencoder and entity embedding
1
2019
... 本类方法首先计算问题和候选答案分布式表示之间的语义匹配,然后通过排序候选答案来得到最终答案.Bordes A等人[12]将问题和知识图谱三元组用嵌入的方式表示来表达特征的语义.然而,与翻译模型TransE[13]、TransH[14]、TransR[15]等关注嵌入表示的模型类似,这些方法只能回答简单问题[12,16-17].为了实现多跳问答推理以及应对多跳知识高效建模的挑战,很多基于语义匹配的方法被提出.Bordes A等人[18]在原来三元组表示方法[12]的基础上做了改进,通过对知识图谱中的问答路径和周围子图进行编码得到语义更加丰富的表示来推理得到答案.Dong L等人[19]提出的多列卷积神经网络(multi-column convolutional neural network,MCCNN)模型进一步地利用具有更强学习能力的神经网络模型来学习答案路径、答案背景信息以及答案类型的分布式表示,并理解问题,在不使用手动特征及词库等的条件下,在问答数据集WebQuestions[20]上取得了不错的结果.其中,答案路径是答案节点和被询问实体之间的一组关系;答案上下文指的是连接到答案路径的单跳实体和关系;答案类型是如人名、日期等的类型.Hao Y C等人[21]认为MC-CNN模型没有充分并合理地考虑候选答案的相关信息来训练问题嵌入的表示,提出了CrossAttention机制的神经网络模型来学习知识图谱的全局信息,取得了更好的结果.但是以上几种方法只能完成浅层多跳知识问答推理,对复杂长路径多跳问题的处理能力依然不足. ...
Knowledge graph embedding based question answering
1
2019
... 本类方法首先计算问题和候选答案分布式表示之间的语义匹配,然后通过排序候选答案来得到最终答案.Bordes A等人[12]将问题和知识图谱三元组用嵌入的方式表示来表达特征的语义.然而,与翻译模型TransE[13]、TransH[14]、TransR[15]等关注嵌入表示的模型类似,这些方法只能回答简单问题[12,16-17].为了实现多跳问答推理以及应对多跳知识高效建模的挑战,很多基于语义匹配的方法被提出.Bordes A等人[18]在原来三元组表示方法[12]的基础上做了改进,通过对知识图谱中的问答路径和周围子图进行编码得到语义更加丰富的表示来推理得到答案.Dong L等人[19]提出的多列卷积神经网络(multi-column convolutional neural network,MCCNN)模型进一步地利用具有更强学习能力的神经网络模型来学习答案路径、答案背景信息以及答案类型的分布式表示,并理解问题,在不使用手动特征及词库等的条件下,在问答数据集WebQuestions[20]上取得了不错的结果.其中,答案路径是答案节点和被询问实体之间的一组关系;答案上下文指的是连接到答案路径的单跳实体和关系;答案类型是如人名、日期等的类型.Hao Y C等人[21]认为MC-CNN模型没有充分并合理地考虑候选答案的相关信息来训练问题嵌入的表示,提出了CrossAttention机制的神经网络模型来学习知识图谱的全局信息,取得了更好的结果.但是以上几种方法只能完成浅层多跳知识问答推理,对复杂长路径多跳问题的处理能力依然不足. ...
Question answering with subgraph embeddings
1
2014
... 本类方法首先计算问题和候选答案分布式表示之间的语义匹配,然后通过排序候选答案来得到最终答案.Bordes A等人[12]将问题和知识图谱三元组用嵌入的方式表示来表达特征的语义.然而,与翻译模型TransE[13]、TransH[14]、TransR[15]等关注嵌入表示的模型类似,这些方法只能回答简单问题[12,16-17].为了实现多跳问答推理以及应对多跳知识高效建模的挑战,很多基于语义匹配的方法被提出.Bordes A等人[18]在原来三元组表示方法[12]的基础上做了改进,通过对知识图谱中的问答路径和周围子图进行编码得到语义更加丰富的表示来推理得到答案.Dong L等人[19]提出的多列卷积神经网络(multi-column convolutional neural network,MCCNN)模型进一步地利用具有更强学习能力的神经网络模型来学习答案路径、答案背景信息以及答案类型的分布式表示,并理解问题,在不使用手动特征及词库等的条件下,在问答数据集WebQuestions[20]上取得了不错的结果.其中,答案路径是答案节点和被询问实体之间的一组关系;答案上下文指的是连接到答案路径的单跳实体和关系;答案类型是如人名、日期等的类型.Hao Y C等人[21]认为MC-CNN模型没有充分并合理地考虑候选答案的相关信息来训练问题嵌入的表示,提出了CrossAttention机制的神经网络模型来学习知识图谱的全局信息,取得了更好的结果.但是以上几种方法只能完成浅层多跳知识问答推理,对复杂长路径多跳问题的处理能力依然不足. ...
Question answering over freebase with multi-column convolutional neural networks
1
2015
... 本类方法首先计算问题和候选答案分布式表示之间的语义匹配,然后通过排序候选答案来得到最终答案.Bordes A等人[12]将问题和知识图谱三元组用嵌入的方式表示来表达特征的语义.然而,与翻译模型TransE[13]、TransH[14]、TransR[15]等关注嵌入表示的模型类似,这些方法只能回答简单问题[12,16-17].为了实现多跳问答推理以及应对多跳知识高效建模的挑战,很多基于语义匹配的方法被提出.Bordes A等人[18]在原来三元组表示方法[12]的基础上做了改进,通过对知识图谱中的问答路径和周围子图进行编码得到语义更加丰富的表示来推理得到答案.Dong L等人[19]提出的多列卷积神经网络(multi-column convolutional neural network,MCCNN)模型进一步地利用具有更强学习能力的神经网络模型来学习答案路径、答案背景信息以及答案类型的分布式表示,并理解问题,在不使用手动特征及词库等的条件下,在问答数据集WebQuestions[20]上取得了不错的结果.其中,答案路径是答案节点和被询问实体之间的一组关系;答案上下文指的是连接到答案路径的单跳实体和关系;答案类型是如人名、日期等的类型.Hao Y C等人[21]认为MC-CNN模型没有充分并合理地考虑候选答案的相关信息来训练问题嵌入的表示,提出了CrossAttention机制的神经网络模型来学习知识图谱的全局信息,取得了更好的结果.但是以上几种方法只能完成浅层多跳知识问答推理,对复杂长路径多跳问题的处理能力依然不足. ...
Semantic parsing via staged query graph generation:question answering with knowledge base
2
2015
... 本类方法首先计算问题和候选答案分布式表示之间的语义匹配,然后通过排序候选答案来得到最终答案.Bordes A等人[12]将问题和知识图谱三元组用嵌入的方式表示来表达特征的语义.然而,与翻译模型TransE[13]、TransH[14]、TransR[15]等关注嵌入表示的模型类似,这些方法只能回答简单问题[12,16-17].为了实现多跳问答推理以及应对多跳知识高效建模的挑战,很多基于语义匹配的方法被提出.Bordes A等人[18]在原来三元组表示方法[12]的基础上做了改进,通过对知识图谱中的问答路径和周围子图进行编码得到语义更加丰富的表示来推理得到答案.Dong L等人[19]提出的多列卷积神经网络(multi-column convolutional neural network,MCCNN)模型进一步地利用具有更强学习能力的神经网络模型来学习答案路径、答案背景信息以及答案类型的分布式表示,并理解问题,在不使用手动特征及词库等的条件下,在问答数据集WebQuestions[20]上取得了不错的结果.其中,答案路径是答案节点和被询问实体之间的一组关系;答案上下文指的是连接到答案路径的单跳实体和关系;答案类型是如人名、日期等的类型.Hao Y C等人[21]认为MC-CNN模型没有充分并合理地考虑候选答案的相关信息来训练问题嵌入的表示,提出了CrossAttention机制的神经网络模型来学习知识图谱的全局信息,取得了更好的结果.但是以上几种方法只能完成浅层多跳知识问答推理,对复杂长路径多跳问题的处理能力依然不足. ...
... 早期的基于语义解析的方法 将自然语言问题转换为结构化的查询(如SPARQL查询),在知识图谱上执行查询可以得到问题的答案.Reddy S等人[54]等人充分使用了组合范畴语法(combinatory categorial grammar,CCG)的表示能力,并提出Graph Parser模型来解析问题,受此启发,Yih W T等人[20]在2015年定义了查询图的概念,并提出了一个分阶段的查询图生成(staged query graph generation,STAGG)模型来处理知识图谱问答,查询图可以直接匹配为问题的逻辑形式,进而翻译成查询,因此语义解析问题可归结为查询图生成问题.STAGG定义了3个阶段来生成查询图:首先,使用现有的实体链接工具获取候选主题实体,并对其评分;然后,STAGG探索主题实体和答案节点之间的所有关系路径,为了限制搜索空间,它仅在下一跳的节点是一个复合类型(compound value type,CVT)节点时,探索长度为2的路径,否则只考虑长度为1的路径,使用深度卷积神经网络对所有关系路径进行打分,以判断当前选择的关系与问题的匹配程度;最后,根据启发式规则将约束节点附加到关系路径上.在这3个阶段的每个阶段,都使用对数线性模型对当前的部分查询图进行评分,并输出最佳的最终查询图来查询知识图谱.STAGG有效地使用了知识图谱中的信息来裁剪语义解析空间,从而简化了任务难度. ...
An end-to-end model for question answering over knowledge base with Cross-Attention combining global knowledge
1
2017
... 本类方法首先计算问题和候选答案分布式表示之间的语义匹配,然后通过排序候选答案来得到最终答案.Bordes A等人[12]将问题和知识图谱三元组用嵌入的方式表示来表达特征的语义.然而,与翻译模型TransE[13]、TransH[14]、TransR[15]等关注嵌入表示的模型类似,这些方法只能回答简单问题[12,16-17].为了实现多跳问答推理以及应对多跳知识高效建模的挑战,很多基于语义匹配的方法被提出.Bordes A等人[18]在原来三元组表示方法[12]的基础上做了改进,通过对知识图谱中的问答路径和周围子图进行编码得到语义更加丰富的表示来推理得到答案.Dong L等人[19]提出的多列卷积神经网络(multi-column convolutional neural network,MCCNN)模型进一步地利用具有更强学习能力的神经网络模型来学习答案路径、答案背景信息以及答案类型的分布式表示,并理解问题,在不使用手动特征及词库等的条件下,在问答数据集WebQuestions[20]上取得了不错的结果.其中,答案路径是答案节点和被询问实体之间的一组关系;答案上下文指的是连接到答案路径的单跳实体和关系;答案类型是如人名、日期等的类型.Hao Y C等人[21]认为MC-CNN模型没有充分并合理地考虑候选答案的相关信息来训练问题嵌入的表示,提出了CrossAttention机制的神经网络模型来学习知识图谱的全局信息,取得了更好的结果.但是以上几种方法只能完成浅层多跳知识问答推理,对复杂长路径多跳问题的处理能力依然不足. ...
Improving multi-hop question answering over knowledge graphs using knowledge base embeddings
1
2020
... Saxena A等人[22]提出的EmbedKGQA模型通过基于知识图谱嵌入模型进行链接预测来缓解多跳问答面临的数据不完整问题,使其具有可以在复杂长路径上的多跳推理能力.EmbedKGQA模型使用C omplEx模型[23]将知识图谱中的实体和关系嵌入复数向量空间,同时采用ComplEx的打分函数φ预测答案.具体而言,对于一个给定的问题q,首先使用RoBERTa[24]模型编码初始向量,然后通过一个前馈神经网络将该向量表示投射到复数嵌入向量空间.问题q和其主题实体h以及知识图谱中的任一实体a可以构成三元组,其嵌入向量分别表示为、和,如果a是q的目标答案实体,则将(h,q,a)视为正样本,并且使,否则将(h,q,a)视为负样本,并使 ,负样本可通过将正样本中的答案实体替换为知识图谱中其他非答案实体来获得.EmbedKGQA使用大量的正负样本训练数据学习问题和实体的嵌入向量表示,在推理阶段则在嵌入空间中通过打分函数选择得分最高的实体作为可能的目标答案. ...
Complex embeddings for simple link prediction
1
2016
... Saxena A等人[22]提出的EmbedKGQA模型通过基于知识图谱嵌入模型进行链接预测来缓解多跳问答面临的数据不完整问题,使其具有可以在复杂长路径上的多跳推理能力.EmbedKGQA模型使用C omplEx模型[23]将知识图谱中的实体和关系嵌入复数向量空间,同时采用ComplEx的打分函数φ预测答案.具体而言,对于一个给定的问题q,首先使用RoBERTa[24]模型编码初始向量,然后通过一个前馈神经网络将该向量表示投射到复数嵌入向量空间.问题q和其主题实体h以及知识图谱中的任一实体a可以构成三元组,其嵌入向量分别表示为、和,如果a是q的目标答案实体,则将(h,q,a)视为正样本,并且使,否则将(h,q,a)视为负样本,并使 ,负样本可通过将正样本中的答案实体替换为知识图谱中其他非答案实体来获得.EmbedKGQA使用大量的正负样本训练数据学习问题和实体的嵌入向量表示,在推理阶段则在嵌入空间中通过打分函数选择得分最高的实体作为可能的目标答案. ...
RoBERTa:a robustly optimized bert pretraining approach
2019
Improving multi-hop knowledge base question answering by learning intermediate supervision signals
4
2021
... He G L等人[25]认为多跳知识问答推理算法只接收最终答案的反馈会使学习不稳定或无效,学习推理过程中的监督信号也非常重要,同时也能提升模型的可解释性.由此,He G L等人提出了一种创新的Teacher-Student模型.TeacherStudent框架最早由Hinton G[26]等人提出,用来做知识蒸馏,其中复杂的Teacher模型的预测被视为“软标签”,一个轻量级Student模型被用于训练拟合软标签.后来,一些Teacher-Student框架的研究逐渐被应用到问答任务中[27]来加快模型的推理速度.在He G L等人[25]提出的模型中, Student网络的目标是找到问题的正确答案,而Teacher网络试图学习预测过程中的监督信号,以提高学生网络的推理能力.Teacher网络利用了正向和逆向双向推理产生可靠的中间监督信号来增强中间实体分布表示学习.在3个公开的数据集上证明了该模型的有效性. ...
... [25]提出的模型中, Student网络的目标是找到问题的正确答案,而Teacher网络试图学习预测过程中的监督信号,以提高学生网络的推理能力.Teacher网络利用了正向和逆向双向推理产生可靠的中间监督信号来增强中间实体分布表示学习.在3个公开的数据集上证明了该模型的有效性. ...
... 表1列出了部分多跳知识推理方法在相同实验数据集(MetaQA、WebQSP和CWQ)上Hits@1的结果[25],“-”表示在原文献中对应指标的结果未给出,1-hop、2-hop和3-hop表示由源实体到目标答案实体推理时分别需要经过1跳、2跳和3跳. ...
... 由表1可以看出,在MetaQA数据集上,对于单跳问题,几个模型的Hits@1结果相近,而随着推理跳数增加,KVMemNN和GRAFT-Net两个模型的性能有了明显的下降.相较于KV-MemNN和GRAFT-Net,PullNet在3跳问题上仍然取得了不错的表现,且PullNet在3个数据集上都取得了显著的结果,充分显示了其提出的迭代构建问题子图方法的有效性以及图神经网络在基于知识图谱的多跳推理问题上的适用性.相比KV-MemNN、GRAFT-Net和PullNet, EmbedKGQA在MetaQA数据集的平均Hits@1值更高,在WebQSP数据集上也表现突出,证明了EmbedKGQA基于语义匹配的方法在解决多跳问答问题上的有效性.NSM+h[25]总体上优于表1中的其他所有模型,表明了使用Teacher-Student网络模型学习中间监督信号可以很好地提升推理能力. ...
Distilling the knowledge in a neural network
1
2015
... He G L等人[25]认为多跳知识问答推理算法只接收最终答案的反馈会使学习不稳定或无效,学习推理过程中的监督信号也非常重要,同时也能提升模型的可解释性.由此,He G L等人提出了一种创新的Teacher-Student模型.TeacherStudent框架最早由Hinton G[26]等人提出,用来做知识蒸馏,其中复杂的Teacher模型的预测被视为“软标签”,一个轻量级Student模型被用于训练拟合软标签.后来,一些Teacher-Student框架的研究逐渐被应用到问答任务中[27]来加快模型的推理速度.在He G L等人[25]提出的模型中, Student网络的目标是找到问题的正确答案,而Teacher网络试图学习预测过程中的监督信号,以提高学生网络的推理能力.Teacher网络利用了正向和逆向双向推理产生可靠的中间监督信号来增强中间实体分布表示学习.在3个公开的数据集上证明了该模型的有效性. ...
Model compression with two-stage multi-teacher knowledge distillation for web question answering system
1
2020
... He G L等人[25]认为多跳知识问答推理算法只接收最终答案的反馈会使学习不稳定或无效,学习推理过程中的监督信号也非常重要,同时也能提升模型的可解释性.由此,He G L等人提出了一种创新的Teacher-Student模型.TeacherStudent框架最早由Hinton G[26]等人提出,用来做知识蒸馏,其中复杂的Teacher模型的预测被视为“软标签”,一个轻量级Student模型被用于训练拟合软标签.后来,一些Teacher-Student框架的研究逐渐被应用到问答任务中[27]来加快模型的推理速度.在He G L等人[25]提出的模型中, Student网络的目标是找到问题的正确答案,而Teacher网络试图学习预测过程中的监督信号,以提高学生网络的推理能力.Teacher网络利用了正向和逆向双向推理产生可靠的中间监督信号来增强中间实体分布表示学习.在3个公开的数据集上证明了该模型的有效性. ...
Semi-supervised classification with graph convolutional networks
1
2017
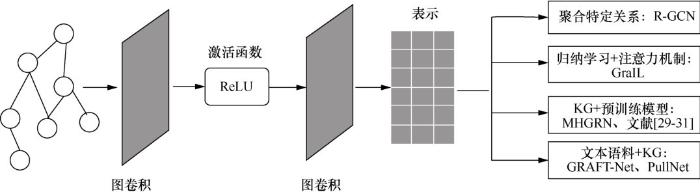
... 图卷积神经网络(graph convolutional network,GCN)[28]通过聚合知识图谱中每个实体的邻居实体来传递消息.GCN因为其在图结构上的有效性和可伸缩性而受到广泛利用,它是多跳推理方法采用的复杂图神经网络的基础,如图2所示.Schlichtkrull M等人[29]提出关系图卷积网络(relational graph convolutional network,R-GCN),最早将图卷积神经网络用于知识图谱链接预测的研究任务,通过聚合特定关系来扩展GCN,使其适用于编码多关系图来预测多跳问题的答案.R-GCN模型整体是一个encoderdecoder架构,encoder通过图卷积神经网络将实体的邻域信息进行聚合,更新实体的表示;decoder基于更新后的实体表示,采用打分函数来预测边.然而,该模型缺乏透明度,无法为关系选择提供可解释的依据.相比R-GCN,Teru K等人[30]提出的GraIL框架采用一种基于注意力机制的多关系图神经网络模型来解决在知识图谱上进行归纳式关系预测的问题.该注意力机制不仅和两个相邻实体以及它们之间的关系有关,也和需要被预测的目标关系有关.最终利用两个目标实体的表示、子图的表示以及预测关系的表示进行打分,将最高得分作为预测结果.归纳学习方法GraIL显式编码知识图谱中的规则以及利用的注意力机制增强了模型的可解释性. ...
Modeling relational data with graph convolutional networks
1
2018
... 图卷积神经网络(graph convolutional network,GCN)[28]通过聚合知识图谱中每个实体的邻居实体来传递消息.GCN因为其在图结构上的有效性和可伸缩性而受到广泛利用,它是多跳推理方法采用的复杂图神经网络的基础,如图2所示.Schlichtkrull M等人[29]提出关系图卷积网络(relational graph convolutional network,R-GCN),最早将图卷积神经网络用于知识图谱链接预测的研究任务,通过聚合特定关系来扩展GCN,使其适用于编码多关系图来预测多跳问题的答案.R-GCN模型整体是一个encoderdecoder架构,encoder通过图卷积神经网络将实体的邻域信息进行聚合,更新实体的表示;decoder基于更新后的实体表示,采用打分函数来预测边.然而,该模型缺乏透明度,无法为关系选择提供可解释的依据.相比R-GCN,Teru K等人[30]提出的GraIL框架采用一种基于注意力机制的多关系图神经网络模型来解决在知识图谱上进行归纳式关系预测的问题.该注意力机制不仅和两个相邻实体以及它们之间的关系有关,也和需要被预测的目标关系有关.最终利用两个目标实体的表示、子图的表示以及预测关系的表示进行打分,将最高得分作为预测结果.归纳学习方法GraIL显式编码知识图谱中的规则以及利用的注意力机制增强了模型的可解释性. ...
Inductive relation prediction by subgraph reasoning
1
2020
... 图卷积神经网络(graph convolutional network,GCN)[28]通过聚合知识图谱中每个实体的邻居实体来传递消息.GCN因为其在图结构上的有效性和可伸缩性而受到广泛利用,它是多跳推理方法采用的复杂图神经网络的基础,如图2所示.Schlichtkrull M等人[29]提出关系图卷积网络(relational graph convolutional network,R-GCN),最早将图卷积神经网络用于知识图谱链接预测的研究任务,通过聚合特定关系来扩展GCN,使其适用于编码多关系图来预测多跳问题的答案.R-GCN模型整体是一个encoderdecoder架构,encoder通过图卷积神经网络将实体的邻域信息进行聚合,更新实体的表示;decoder基于更新后的实体表示,采用打分函数来预测边.然而,该模型缺乏透明度,无法为关系选择提供可解释的依据.相比R-GCN,Teru K等人[30]提出的GraIL框架采用一种基于注意力机制的多关系图神经网络模型来解决在知识图谱上进行归纳式关系预测的问题.该注意力机制不仅和两个相邻实体以及它们之间的关系有关,也和需要被预测的目标关系有关.最终利用两个目标实体的表示、子图的表示以及预测关系的表示进行打分,将最高得分作为预测结果.归纳学习方法GraIL显式编码知识图谱中的规则以及利用的注意力机制增强了模型的可解释性. ...
BERT:pre-training of deep bidirectional transformers for language understanding
2019
KagNet:knowledge-aware graph networks for commonsense reasoning
2
2019
... 近年来,BERT(bidirectional encoder representations from transformers)[31]、 RoBERTa等预训练语言模型在智能问答等自然语言处理(natural language processing,NLP)任务中取得了巨大的成功.但是预训练模型的知识是隐式学习的,无法明确表示出来,因此无法提供可解释的预测.为了利用预训练模型学习到的丰富知识,并且结合知识图谱中的显式知识提高可解释性,许多预训练模型结合知识图谱的问答模型[32-34]被提出,Feng Y L等人[33]提出的多跳图关系网络(multi-hop graph relation network,MHGRN)模型就是其中一种.MHGRN模型是一种新颖的多跳图关系网络模型,它结合了基于路径的模型,具有可解释性和基于GNN模型扩展性强的优点,利用图神经网络通过在实体之间传递消息来编码结构化信息,同时为了进一步使模型具有显式建模关系路径的能力,将图分解为路径,并类似Lin B Y等人[32]提出的知识感知型图神经网络(knowledge-aware graph network, KagNet)采用长短期记忆(long shortterm memory,LSTM)网络[35]对限定连接长度的问题实体和答案实体的所有路径进行编码,然后通过注意力机制聚合所有路径嵌入来预测结果. ...
... [32]提出的知识感知型图神经网络(knowledge-aware graph network, KagNet)采用长短期记忆(long shortterm memory,LSTM)网络[35]对限定连接长度的问题实体和答案实体的所有路径进行编码,然后通过注意力机制聚合所有路径嵌入来预测结果. ...
Scalable multi-hop relational reasoning for knowledge-aware question answering
1
2020
... 近年来,BERT(bidirectional encoder representations from transformers)[31]、 RoBERTa等预训练语言模型在智能问答等自然语言处理(natural language processing,NLP)任务中取得了巨大的成功.但是预训练模型的知识是隐式学习的,无法明确表示出来,因此无法提供可解释的预测.为了利用预训练模型学习到的丰富知识,并且结合知识图谱中的显式知识提高可解释性,许多预训练模型结合知识图谱的问答模型[32-34]被提出,Feng Y L等人[33]提出的多跳图关系网络(multi-hop graph relation network,MHGRN)模型就是其中一种.MHGRN模型是一种新颖的多跳图关系网络模型,它结合了基于路径的模型,具有可解释性和基于GNN模型扩展性强的优点,利用图神经网络通过在实体之间传递消息来编码结构化信息,同时为了进一步使模型具有显式建模关系路径的能力,将图分解为路径,并类似Lin B Y等人[32]提出的知识感知型图神经网络(knowledge-aware graph network, KagNet)采用长短期记忆(long shortterm memory,LSTM)网络[35]对限定连接长度的问题实体和答案实体的所有路径进行编码,然后通过注意力机制聚合所有路径嵌入来预测结果. ...
Enhancing key-value memory neural networks for knowledge based question answering
2
2019
... 近年来,BERT(bidirectional encoder representations from transformers)[31]、 RoBERTa等预训练语言模型在智能问答等自然语言处理(natural language processing,NLP)任务中取得了巨大的成功.但是预训练模型的知识是隐式学习的,无法明确表示出来,因此无法提供可解释的预测.为了利用预训练模型学习到的丰富知识,并且结合知识图谱中的显式知识提高可解释性,许多预训练模型结合知识图谱的问答模型[32-34]被提出,Feng Y L等人[33]提出的多跳图关系网络(multi-hop graph relation network,MHGRN)模型就是其中一种.MHGRN模型是一种新颖的多跳图关系网络模型,它结合了基于路径的模型,具有可解释性和基于GNN模型扩展性强的优点,利用图神经网络通过在实体之间传递消息来编码结构化信息,同时为了进一步使模型具有显式建模关系路径的能力,将图分解为路径,并类似Lin B Y等人[32]提出的知识感知型图神经网络(knowledge-aware graph network, KagNet)采用长短期记忆(long shortterm memory,LSTM)网络[35]对限定连接长度的问题实体和答案实体的所有路径进行编码,然后通过注意力机制聚合所有路径嵌入来预测结果. ...
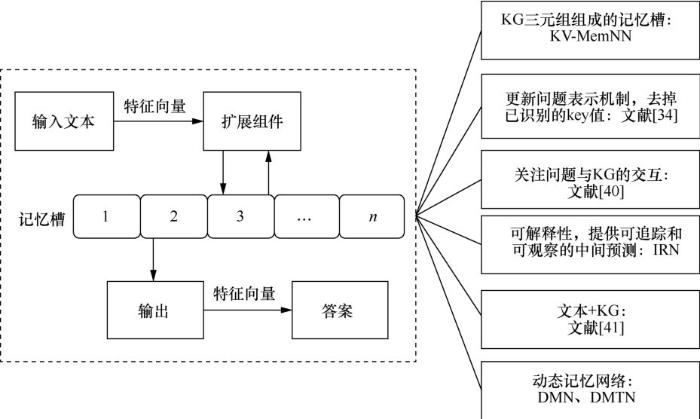
... 基于Weston J等人[39]提出的记忆网络模型,Miller A等人[40]提出了键值记忆网络(key-value memory network,KVMemNN)模型,通过迭代更新存储键值对(key-value)的记忆槽来完成多跳推理任务.此处的key指三元组中头实体和关系的组合,value指尾实体.与Weston J等人[39]提出的记忆网络相比,该模型能够处理结构复杂的知识图谱知识.该模型通过以下过程完成一次迭代更新:首先使用向量表示用户问题和知识图谱三元组,通过用户问题检索知识图谱得到相关子集,并作为键值记忆槽,然后计算每一个key和问题的相关程度评分,根据评分对每个value加权求和,最后用得到的value向量更新问题向量.经过以上N步迭代后,对问题向量进行分类,最终得到多跳问题的答案.KV-MemNN模型结构简单,通用性强,通过向量的迭代更新来进行隐式推理.然而,复杂问题需要进行多次迭代表示,同时需要对应构造记忆槽,容易造成内存不足以及训练时间慢等问题.基于KVMemNN模型,Xu K等人[34]提出了一个新的用户问题表示更新机制,即在更新时不考虑问题中已经定位到的key值.该模型将问题分解为针对记忆的查询序列,基于上述更新机制,可以增强多跳复杂问题的推理能力.但是上述方法对问题和知识图谱三元组分开进行编码,忽略了两者之间的交互作用.因此,Chen Y等人[41]提出了双向注意记忆网络模型,该模型利用注意机制捕捉问题与知识图谱信息之间的相关性,并利用此相关性增强问题的表征来提高推理答案的能力. ...
LSTM:a search space odyssey
1
2016
... 近年来,BERT(bidirectional encoder representations from transformers)[31]、 RoBERTa等预训练语言模型在智能问答等自然语言处理(natural language processing,NLP)任务中取得了巨大的成功.但是预训练模型的知识是隐式学习的,无法明确表示出来,因此无法提供可解释的预测.为了利用预训练模型学习到的丰富知识,并且结合知识图谱中的显式知识提高可解释性,许多预训练模型结合知识图谱的问答模型[32-34]被提出,Feng Y L等人[33]提出的多跳图关系网络(multi-hop graph relation network,MHGRN)模型就是其中一种.MHGRN模型是一种新颖的多跳图关系网络模型,它结合了基于路径的模型,具有可解释性和基于GNN模型扩展性强的优点,利用图神经网络通过在实体之间传递消息来编码结构化信息,同时为了进一步使模型具有显式建模关系路径的能力,将图分解为路径,并类似Lin B Y等人[32]提出的知识感知型图神经网络(knowledge-aware graph network, KagNet)采用长短期记忆(long shortterm memory,LSTM)网络[35]对限定连接长度的问题实体和答案实体的所有路径进行编码,然后通过注意力机制聚合所有路径嵌入来预测结果. ...
Open domain question answering using early fusion of knowledge bases and text
1
2018
... GRAFT-Net(graphs of relations among facts and text network)[36]和PullNet(pull network)[37]将外部文本语料库和知识图谱结合起来完成多跳问答任务.GRAFT-Net将Wikipedia语料库中的文档和知识图谱中的实体建模作为节点,将实体和文档的链接关系(句子中包含此实体名词)以及知识图谱中实体之间存在的关系建模为边,构建问题子图,以执行多跳推理.具体而言,GRAFT-Net从问题出发,首先由问题主题实体链接一些种子实体,再以种子实体为起点,通过个性化页面排名(personalized pagerank,PPR)[38]算法从它们的邻居实体中取出PPR分数最高的几个实体及相关联的边,并将它们都加入问题子图中.同时从文本语料库中检索出5个与问题高度相关的句子,并将可以链接到这些句子的实体一并加入问题子图中.最终问题子图由句子节点、实体节点以及句子和实体之间的链接关系、实体和实体之间的关系构成.GRAFT-Net将实体节点随机初始化为一个固定长度的向量,然后基于图卷积神经网络学习和更新问题子图中节点的向量表示,最后对问题子图中的实体节点进行二分类来预测出哪些是答案实体,以完成推理过程.GRAFT-Net使用启发式算法构建的问题子图规模过大,并且很多时候可能不包含答案.PullNet同样基于图卷积网络,但不同于GRAFT-Net, PullNet不要求将整个子图一步构建完成,而是迭代式学习构建的过程.PullNet迭代地构建问题子图,初始子图只包括问题及其中的实体,每一次迭代时,首先使用图卷积网络计算将子图中的实体节点加入下一个迭代过程的概率,确定所有输出概率大于设定阈值的实体,然后对每一个被选择的实体,从文本语料库检索出相关的句子集合,从知识图谱检索出相关的三元组集合,将新检索到的句子、三元组、句子中的实体以及三元组的头实体和尾实体都视为新的节点,将新节点之间的联系视为新边,用新节点和新边更新问题子图.子图构建完成后,PullNet使用与GRAFT-Net相同的方法对节点进行分类,找出最可能的答案实体. ...
PullNet:open domain question answering with iterative retrieval on knowledge bases and text
1
2019
... GRAFT-Net(graphs of relations among facts and text network)[36]和PullNet(pull network)[37]将外部文本语料库和知识图谱结合起来完成多跳问答任务.GRAFT-Net将Wikipedia语料库中的文档和知识图谱中的实体建模作为节点,将实体和文档的链接关系(句子中包含此实体名词)以及知识图谱中实体之间存在的关系建模为边,构建问题子图,以执行多跳推理.具体而言,GRAFT-Net从问题出发,首先由问题主题实体链接一些种子实体,再以种子实体为起点,通过个性化页面排名(personalized pagerank,PPR)[38]算法从它们的邻居实体中取出PPR分数最高的几个实体及相关联的边,并将它们都加入问题子图中.同时从文本语料库中检索出5个与问题高度相关的句子,并将可以链接到这些句子的实体一并加入问题子图中.最终问题子图由句子节点、实体节点以及句子和实体之间的链接关系、实体和实体之间的关系构成.GRAFT-Net将实体节点随机初始化为一个固定长度的向量,然后基于图卷积神经网络学习和更新问题子图中节点的向量表示,最后对问题子图中的实体节点进行二分类来预测出哪些是答案实体,以完成推理过程.GRAFT-Net使用启发式算法构建的问题子图规模过大,并且很多时候可能不包含答案.PullNet同样基于图卷积网络,但不同于GRAFT-Net, PullNet不要求将整个子图一步构建完成,而是迭代式学习构建的过程.PullNet迭代地构建问题子图,初始子图只包括问题及其中的实体,每一次迭代时,首先使用图卷积网络计算将子图中的实体节点加入下一个迭代过程的概率,确定所有输出概率大于设定阈值的实体,然后对每一个被选择的实体,从文本语料库检索出相关的句子集合,从知识图谱检索出相关的三元组集合,将新检索到的句子、三元组、句子中的实体以及三元组的头实体和尾实体都视为新的节点,将新节点之间的联系视为新边,用新节点和新边更新问题子图.子图构建完成后,PullNet使用与GRAFT-Net相同的方法对节点进行分类,找出最可能的答案实体. ...
Topic-Sensitive Pagerank:a context-sensitive ranking algorithm for web search
1
2003
... GRAFT-Net(graphs of relations among facts and text network)[36]和PullNet(pull network)[37]将外部文本语料库和知识图谱结合起来完成多跳问答任务.GRAFT-Net将Wikipedia语料库中的文档和知识图谱中的实体建模作为节点,将实体和文档的链接关系(句子中包含此实体名词)以及知识图谱中实体之间存在的关系建模为边,构建问题子图,以执行多跳推理.具体而言,GRAFT-Net从问题出发,首先由问题主题实体链接一些种子实体,再以种子实体为起点,通过个性化页面排名(personalized pagerank,PPR)[38]算法从它们的邻居实体中取出PPR分数最高的几个实体及相关联的边,并将它们都加入问题子图中.同时从文本语料库中检索出5个与问题高度相关的句子,并将可以链接到这些句子的实体一并加入问题子图中.最终问题子图由句子节点、实体节点以及句子和实体之间的链接关系、实体和实体之间的关系构成.GRAFT-Net将实体节点随机初始化为一个固定长度的向量,然后基于图卷积神经网络学习和更新问题子图中节点的向量表示,最后对问题子图中的实体节点进行二分类来预测出哪些是答案实体,以完成推理过程.GRAFT-Net使用启发式算法构建的问题子图规模过大,并且很多时候可能不包含答案.PullNet同样基于图卷积网络,但不同于GRAFT-Net, PullNet不要求将整个子图一步构建完成,而是迭代式学习构建的过程.PullNet迭代地构建问题子图,初始子图只包括问题及其中的实体,每一次迭代时,首先使用图卷积网络计算将子图中的实体节点加入下一个迭代过程的概率,确定所有输出概率大于设定阈值的实体,然后对每一个被选择的实体,从文本语料库检索出相关的句子集合,从知识图谱检索出相关的三元组集合,将新检索到的句子、三元组、句子中的实体以及三元组的头实体和尾实体都视为新的节点,将新节点之间的联系视为新边,用新节点和新边更新问题子图.子图构建完成后,PullNet使用与GRAFT-Net相同的方法对节点进行分类,找出最可能的答案实体. ...
Memory networks
3
2015
... 传统的循环神经网络(recurrent neural network,RNN)、LSTM网络等深度学习模型使用隐藏层状态作为其记忆模块,但是这种方法产生的记忆力太短程,无法精确记住被转化为稠密向量的长路径知识.Weston J等人[39]提出了一种可读写的外部记忆模块,联合记忆模块保存场景信息,以实现长期记忆的目标.该方法中的记忆网络包括I(input feature map)、G(generalization)、O(output feature map)、R(response)4个组件.I用来将输入转化为内部特征向量表示;G用来更新记忆,并插入记忆槽中;O根据新的输入和当前的记忆状态输出特征映射表示;R把组件O的结果转化为想要的输出形式,如文本回答.该模型是本文接下来要介绍的复杂记忆网络多跳知识问答推理方法的基础,如图3所示. ...
... 基于Weston J等人[39]提出的记忆网络模型,Miller A等人[40]提出了键值记忆网络(key-value memory network,KVMemNN)模型,通过迭代更新存储键值对(key-value)的记忆槽来完成多跳推理任务.此处的key指三元组中头实体和关系的组合,value指尾实体.与Weston J等人[39]提出的记忆网络相比,该模型能够处理结构复杂的知识图谱知识.该模型通过以下过程完成一次迭代更新:首先使用向量表示用户问题和知识图谱三元组,通过用户问题检索知识图谱得到相关子集,并作为键值记忆槽,然后计算每一个key和问题的相关程度评分,根据评分对每个value加权求和,最后用得到的value向量更新问题向量.经过以上N步迭代后,对问题向量进行分类,最终得到多跳问题的答案.KV-MemNN模型结构简单,通用性强,通过向量的迭代更新来进行隐式推理.然而,复杂问题需要进行多次迭代表示,同时需要对应构造记忆槽,容易造成内存不足以及训练时间慢等问题.基于KVMemNN模型,Xu K等人[34]提出了一个新的用户问题表示更新机制,即在更新时不考虑问题中已经定位到的key值.该模型将问题分解为针对记忆的查询序列,基于上述更新机制,可以增强多跳复杂问题的推理能力.但是上述方法对问题和知识图谱三元组分开进行编码,忽略了两者之间的交互作用.因此,Chen Y等人[41]提出了双向注意记忆网络模型,该模型利用注意机制捕捉问题与知识图谱信息之间的相关性,并利用此相关性增强问题的表征来提高推理答案的能力. ...
... [39]提出的记忆网络相比,该模型能够处理结构复杂的知识图谱知识.该模型通过以下过程完成一次迭代更新:首先使用向量表示用户问题和知识图谱三元组,通过用户问题检索知识图谱得到相关子集,并作为键值记忆槽,然后计算每一个key和问题的相关程度评分,根据评分对每个value加权求和,最后用得到的value向量更新问题向量.经过以上N步迭代后,对问题向量进行分类,最终得到多跳问题的答案.KV-MemNN模型结构简单,通用性强,通过向量的迭代更新来进行隐式推理.然而,复杂问题需要进行多次迭代表示,同时需要对应构造记忆槽,容易造成内存不足以及训练时间慢等问题.基于KVMemNN模型,Xu K等人[34]提出了一个新的用户问题表示更新机制,即在更新时不考虑问题中已经定位到的key值.该模型将问题分解为针对记忆的查询序列,基于上述更新机制,可以增强多跳复杂问题的推理能力.但是上述方法对问题和知识图谱三元组分开进行编码,忽略了两者之间的交互作用.因此,Chen Y等人[41]提出了双向注意记忆网络模型,该模型利用注意机制捕捉问题与知识图谱信息之间的相关性,并利用此相关性增强问题的表征来提高推理答案的能力. ...
Key-value memory networks for directly reading documents
2
2016
... 基于Weston J等人[39]提出的记忆网络模型,Miller A等人[40]提出了键值记忆网络(key-value memory network,KVMemNN)模型,通过迭代更新存储键值对(key-value)的记忆槽来完成多跳推理任务.此处的key指三元组中头实体和关系的组合,value指尾实体.与Weston J等人[39]提出的记忆网络相比,该模型能够处理结构复杂的知识图谱知识.该模型通过以下过程完成一次迭代更新:首先使用向量表示用户问题和知识图谱三元组,通过用户问题检索知识图谱得到相关子集,并作为键值记忆槽,然后计算每一个key和问题的相关程度评分,根据评分对每个value加权求和,最后用得到的value向量更新问题向量.经过以上N步迭代后,对问题向量进行分类,最终得到多跳问题的答案.KV-MemNN模型结构简单,通用性强,通过向量的迭代更新来进行隐式推理.然而,复杂问题需要进行多次迭代表示,同时需要对应构造记忆槽,容易造成内存不足以及训练时间慢等问题.基于KVMemNN模型,Xu K等人[34]提出了一个新的用户问题表示更新机制,即在更新时不考虑问题中已经定位到的key值.该模型将问题分解为针对记忆的查询序列,基于上述更新机制,可以增强多跳复杂问题的推理能力.但是上述方法对问题和知识图谱三元组分开进行编码,忽略了两者之间的交互作用.因此,Chen Y等人[41]提出了双向注意记忆网络模型,该模型利用注意机制捕捉问题与知识图谱信息之间的相关性,并利用此相关性增强问题的表征来提高推理答案的能力. ...
... MetaQA数据集[68]是基于WikiMovies[40]数据集构建的多跳问答数据集,它包含超过40万个电影领域的多跳问题,这些问题有Vanilla、NTM和Audio 3个版本.Vanilla版本的MetaQA常被用于多跳知识问答推理任务,它除了包含1跳、2跳和3跳3种类型的问答数据,还包含一个知识图谱,其有约135 000个三元组、43 000个实体以及9种关系. ...
Bidirectional attentive memory networks for question answering over knowledge bases
1
2019
... 基于Weston J等人[39]提出的记忆网络模型,Miller A等人[40]提出了键值记忆网络(key-value memory network,KVMemNN)模型,通过迭代更新存储键值对(key-value)的记忆槽来完成多跳推理任务.此处的key指三元组中头实体和关系的组合,value指尾实体.与Weston J等人[39]提出的记忆网络相比,该模型能够处理结构复杂的知识图谱知识.该模型通过以下过程完成一次迭代更新:首先使用向量表示用户问题和知识图谱三元组,通过用户问题检索知识图谱得到相关子集,并作为键值记忆槽,然后计算每一个key和问题的相关程度评分,根据评分对每个value加权求和,最后用得到的value向量更新问题向量.经过以上N步迭代后,对问题向量进行分类,最终得到多跳问题的答案.KV-MemNN模型结构简单,通用性强,通过向量的迭代更新来进行隐式推理.然而,复杂问题需要进行多次迭代表示,同时需要对应构造记忆槽,容易造成内存不足以及训练时间慢等问题.基于KVMemNN模型,Xu K等人[34]提出了一个新的用户问题表示更新机制,即在更新时不考虑问题中已经定位到的key值.该模型将问题分解为针对记忆的查询序列,基于上述更新机制,可以增强多跳复杂问题的推理能力.但是上述方法对问题和知识图谱三元组分开进行编码,忽略了两者之间的交互作用.因此,Chen Y等人[41]提出了双向注意记忆网络模型,该模型利用注意机制捕捉问题与知识图谱信息之间的相关性,并利用此相关性增强问题的表征来提高推理答案的能力. ...
Question answering on knowledge bases and text using universal schema and memory networks
1
2017
... Das R等人[42]在2017年提出采用记忆网络并基于通用模式在知识图谱和文本上进行多跳知识问答推理,该框架通过将结构化知识图谱和非结构化文本在一个公共嵌入空间中对齐,相比单独使用知识图谱或文本取得了更好的效果.动态记忆网络(dynamic memory network,DMN)模型和动态记忆张量网络(dynamic memory tensor network,DMTN)模型[43-44]采用动态记忆网络,允许模型将注意力集中在之前迭代的输入和结果上,形成情景记忆,然后在一个层次递归序列模型中推理得到答案.两者不同的是,DMN采用门函数实现注意力机制,而DMTN采用的是神经张量网络,以实现更好的推理效果. ...
Ask me anything:dynamic memory networks for natural language processing
1
2016
... Das R等人[42]在2017年提出采用记忆网络并基于通用模式在知识图谱和文本上进行多跳知识问答推理,该框架通过将结构化知识图谱和非结构化文本在一个公共嵌入空间中对齐,相比单独使用知识图谱或文本取得了更好的效果.动态记忆网络(dynamic memory network,DMN)模型和动态记忆张量网络(dynamic memory tensor network,DMTN)模型[43-44]采用动态记忆网络,允许模型将注意力集中在之前迭代的输入和结果上,形成情景记忆,然后在一个层次递归序列模型中推理得到答案.两者不同的是,DMN采用门函数实现注意力机制,而DMTN采用的是神经张量网络,以实现更好的推理效果. ...
Ask me even more:dynamic memory tensor networks (extended model)
1
2017
... Das R等人[42]在2017年提出采用记忆网络并基于通用模式在知识图谱和文本上进行多跳知识问答推理,该框架通过将结构化知识图谱和非结构化文本在一个公共嵌入空间中对齐,相比单独使用知识图谱或文本取得了更好的效果.动态记忆网络(dynamic memory network,DMN)模型和动态记忆张量网络(dynamic memory tensor network,DMTN)模型[43-44]采用动态记忆网络,允许模型将注意力集中在之前迭代的输入和结果上,形成情景记忆,然后在一个层次递归序列模型中推理得到答案.两者不同的是,DMN采用门函数实现注意力机制,而DMTN采用的是神经张量网络,以实现更好的推理效果. ...
An interpretable reasoning network for multi-relation question answering
1
2018
... 以上记忆网络模型都取得了不错的效果,但是模型依然具有“黑盒”特性,可解释性差.为了使多跳知识问答推理过程更加可信,一些方法在保证模型准确率的同时也尝试增强模型的可解释性.Zhou M T等人[45]提出的解释推理网络(interpretable reasoning network, IRN)是一种新颖的具有可解释性的记忆网络推理模型,它采用可解释的逐跳推理过程来回答问题.该模型可以动态地决定输入问题的哪一部分应该在哪一跳进行分析,预测与当前解析结果相对应的关系,并利用预测的关系更新问题表示和推理过程的状态,然后驱动下一跳推理.该模型可以为推理分析和故障诊断提供可追踪和可观察的中间预测,从而允许人工操作来预测最终答案,这个过程提高了模型的透明度和可信赖度. ...
Improving learning and inference in a large knowledge-base using latent syntactic cues
1
2013
... 路径排序算法(path-ranking algorithm,PRA)[46]是一种有效的大规模知识图谱推理路径学习方法.基于路径排序算法的多跳知识问答推理方法的主要思想是利用实体之间的复杂路径特征来学习随机游走器,进而推断出答案. ...
DeepPath:a reinforcement learning method for knowledge graph reasoning
2
2017
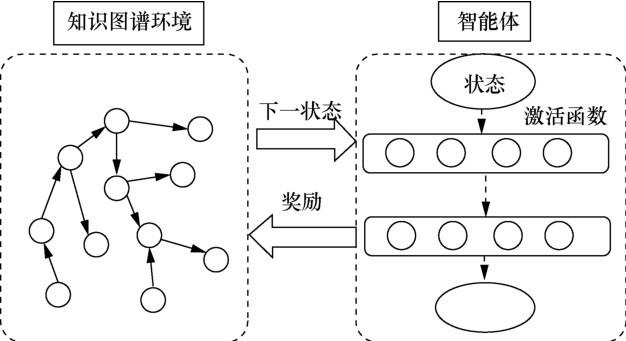
... 与PRA基于随机游走的路径查找模型不同,Xiong W H等人[47]提出的DeepPath是一种创新的可控多跳推理方法.该方法将路径搜索转化为强化学习过程,该过程允许通过控制所找到的路径的属性来减小搜索空间.模型如图4所示,该强化学习方法包括两部分:第一部分是被建模为马尔可夫决策过程的外部环境,指定智能体和知识图谱之间的动态交互;第二部分是策略网络智能体,将状态向量映射到随机策略中.在每一步中,通过与环境的交互,智能体学习选择一个关系链接来扩展推理路径.为了更好地指导强化学习智能体学习到目标关系路径,与之前的研究相比,该方法更多地考虑了奖励的设置,在准确性、多样性和精确度3个方面采用奖励机制,监督每一跳的行动,具体方式如下. ...
... FB15k[14]是Freebase的一个子集,也是知识图谱补全领域的一个基准数据集,由三元组构成.为了解决FB15k测试集数据泄露的问题,Toutanova K等人[71]在FB15k的基础上构建了FB15k-237,并且移除了FB15k中反向的关系.NELL995[47]数据集由NELL系统构建而来. ...
Reinforced anytime bottom up rule learning for knowledge graph completion
2
2020
... Meilicke C等人[48]提出的AnyBRUL (reinforced anytime bottom up rule learning)方法同样利用强化学习对路径进行采样,基于采样路径构造基本规则,并将其推广为抽象规则.DeepPath和AnyBRUL都要求首先对头实体和尾实体之间的所有路径进行取样,然后利用它们来评估尾实体是否为正确的答案,因此,它无法应对找不到尾实体的情况.与DeepPath和AnyBRUL需要预先计算路径的方式不同,有些方法通过给定的头实体和查询关系利用训练模型来获得正确的答案实体.在这些模型中,Das R等人[49]在2018年提出的MINERVA(meandering in networks of entities to reach verisimilar answer)是一个代表性模型.与DeepPath不同的是,MINERVA的状态由查询关系和部分路径的嵌入组成,在抽样过程中不需要嵌入答案实体. ...
... 表3列出了部分基于强化学习的多跳知识问答方法[48,49,50,51]在FB15k、FB15k-237和NELL-995 3个数据集上的结果,采用的评测指标有Hits@1和MAP,“-”表示在原文献中对应指标的结果未给出.由表3可以看出,在FB15k-237数据集上,RewardShaping[50]的Hits@1结果比MINERVA高出了11%,这很可能因为MINERVA中的智能体在训练时会受到假负样本的影响,导致低质量的奖励,并且由于缺乏正确的动作序列用于训练,智能体可能被假搜索轨迹误导却偶然地被引向了正确答案.RewardShaping针对以上问题做了改进,使智能体探索更广泛的路径集合,以抵消对虚假路径的敏感度.但在NELL-995数据集上,RewardShaping模型的表现并不强于MINERVA,因为RewardShaping适合处理一对多的关系类型,而NELL-995数据集中的关系类型大多是一对一的.从MAP结果来看,DIVA比DeepPath效果要好,这是因为DeepPath关注于找到实体对间的路径,缺少了对实体对是正样本还是负样本的判断,导致实验结果对噪声和对抗样本敏感,而DIVA更擅长处理噪声和应对更复杂的推理场景.M-Walk使用RNN编码状态,并将蒙特卡洛搜索树与神经策略结合来应对稀疏奖励的挑战,与DIVA、DeepPath相比,取得了更好的结果. ...
Go for a walk and arrive at the answer:reasoning over paths in knowledge bases using reinforcement learning
2
2018
... Meilicke C等人[48]提出的AnyBRUL (reinforced anytime bottom up rule learning)方法同样利用强化学习对路径进行采样,基于采样路径构造基本规则,并将其推广为抽象规则.DeepPath和AnyBRUL都要求首先对头实体和尾实体之间的所有路径进行取样,然后利用它们来评估尾实体是否为正确的答案,因此,它无法应对找不到尾实体的情况.与DeepPath和AnyBRUL需要预先计算路径的方式不同,有些方法通过给定的头实体和查询关系利用训练模型来获得正确的答案实体.在这些模型中,Das R等人[49]在2018年提出的MINERVA(meandering in networks of entities to reach verisimilar answer)是一个代表性模型.与DeepPath不同的是,MINERVA的状态由查询关系和部分路径的嵌入组成,在抽样过程中不需要嵌入答案实体. ...
... 表3列出了部分基于强化学习的多跳知识问答方法[48,49,50,51]在FB15k、FB15k-237和NELL-995 3个数据集上的结果,采用的评测指标有Hits@1和MAP,“-”表示在原文献中对应指标的结果未给出.由表3可以看出,在FB15k-237数据集上,RewardShaping[50]的Hits@1结果比MINERVA高出了11%,这很可能因为MINERVA中的智能体在训练时会受到假负样本的影响,导致低质量的奖励,并且由于缺乏正确的动作序列用于训练,智能体可能被假搜索轨迹误导却偶然地被引向了正确答案.RewardShaping针对以上问题做了改进,使智能体探索更广泛的路径集合,以抵消对虚假路径的敏感度.但在NELL-995数据集上,RewardShaping模型的表现并不强于MINERVA,因为RewardShaping适合处理一对多的关系类型,而NELL-995数据集中的关系类型大多是一对一的.从MAP结果来看,DIVA比DeepPath效果要好,这是因为DeepPath关注于找到实体对间的路径,缺少了对实体对是正样本还是负样本的判断,导致实验结果对噪声和对抗样本敏感,而DIVA更擅长处理噪声和应对更复杂的推理场景.M-Walk使用RNN编码状态,并将蒙特卡洛搜索树与神经策略结合来应对稀疏奖励的挑战,与DIVA、DeepPath相比,取得了更好的结果. ...
Multihop knowledge graph reasoning with reward shaping
3
2018
... 强化学习模型通常采用一个0/1的硬奖励来监督抽样过程,指示抽样实体是否为正确的答案实体.Lin X V等人[50]提出的RS(reward shaping)在最后一步采用基于正确答案实体和采样实体之间的软奖励,而不是使用0/1的硬奖励.此外,受dropout技术的启发,RS模型在训练过程中为了避免选择大量的重复路径,缓解过拟合,采用了dropout技术.Shen Y L等人[51]提出的M-Walk引入了一种基于值的强化学习方法,并使用蒙特卡洛树搜索来克服稀疏正奖励的挑战.Chen W H等人[52]提出的DIVA将推理任务当作一个由寻找路径和答案推理组成的统一模型,其中路径建模为隐变量,采用AEVB(autoencoding variational Bayes)[53]对模型进行求解. ...
... 表3列出了部分基于强化学习的多跳知识问答方法[48,49,50,51]在FB15k、FB15k-237和NELL-995 3个数据集上的结果,采用的评测指标有Hits@1和MAP,“-”表示在原文献中对应指标的结果未给出.由表3可以看出,在FB15k-237数据集上,RewardShaping[50]的Hits@1结果比MINERVA高出了11%,这很可能因为MINERVA中的智能体在训练时会受到假负样本的影响,导致低质量的奖励,并且由于缺乏正确的动作序列用于训练,智能体可能被假搜索轨迹误导却偶然地被引向了正确答案.RewardShaping针对以上问题做了改进,使智能体探索更广泛的路径集合,以抵消对虚假路径的敏感度.但在NELL-995数据集上,RewardShaping模型的表现并不强于MINERVA,因为RewardShaping适合处理一对多的关系类型,而NELL-995数据集中的关系类型大多是一对一的.从MAP结果来看,DIVA比DeepPath效果要好,这是因为DeepPath关注于找到实体对间的路径,缺少了对实体对是正样本还是负样本的判断,导致实验结果对噪声和对抗样本敏感,而DIVA更擅长处理噪声和应对更复杂的推理场景.M-Walk使用RNN编码状态,并将蒙特卡洛搜索树与神经策略结合来应对稀疏奖励的挑战,与DIVA、DeepPath相比,取得了更好的结果. ...
... [50]的Hits@1结果比MINERVA高出了11%,这很可能因为MINERVA中的智能体在训练时会受到假负样本的影响,导致低质量的奖励,并且由于缺乏正确的动作序列用于训练,智能体可能被假搜索轨迹误导却偶然地被引向了正确答案.RewardShaping针对以上问题做了改进,使智能体探索更广泛的路径集合,以抵消对虚假路径的敏感度.但在NELL-995数据集上,RewardShaping模型的表现并不强于MINERVA,因为RewardShaping适合处理一对多的关系类型,而NELL-995数据集中的关系类型大多是一对一的.从MAP结果来看,DIVA比DeepPath效果要好,这是因为DeepPath关注于找到实体对间的路径,缺少了对实体对是正样本还是负样本的判断,导致实验结果对噪声和对抗样本敏感,而DIVA更擅长处理噪声和应对更复杂的推理场景.M-Walk使用RNN编码状态,并将蒙特卡洛搜索树与神经策略结合来应对稀疏奖励的挑战,与DIVA、DeepPath相比,取得了更好的结果. ...
M-Walk:learning to walk over graphs using monte carlo tree search
2
2018
... 强化学习模型通常采用一个0/1的硬奖励来监督抽样过程,指示抽样实体是否为正确的答案实体.Lin X V等人[50]提出的RS(reward shaping)在最后一步采用基于正确答案实体和采样实体之间的软奖励,而不是使用0/1的硬奖励.此外,受dropout技术的启发,RS模型在训练过程中为了避免选择大量的重复路径,缓解过拟合,采用了dropout技术.Shen Y L等人[51]提出的M-Walk引入了一种基于值的强化学习方法,并使用蒙特卡洛树搜索来克服稀疏正奖励的挑战.Chen W H等人[52]提出的DIVA将推理任务当作一个由寻找路径和答案推理组成的统一模型,其中路径建模为隐变量,采用AEVB(autoencoding variational Bayes)[53]对模型进行求解. ...
... 表3列出了部分基于强化学习的多跳知识问答方法[48,49,50,51]在FB15k、FB15k-237和NELL-995 3个数据集上的结果,采用的评测指标有Hits@1和MAP,“-”表示在原文献中对应指标的结果未给出.由表3可以看出,在FB15k-237数据集上,RewardShaping[50]的Hits@1结果比MINERVA高出了11%,这很可能因为MINERVA中的智能体在训练时会受到假负样本的影响,导致低质量的奖励,并且由于缺乏正确的动作序列用于训练,智能体可能被假搜索轨迹误导却偶然地被引向了正确答案.RewardShaping针对以上问题做了改进,使智能体探索更广泛的路径集合,以抵消对虚假路径的敏感度.但在NELL-995数据集上,RewardShaping模型的表现并不强于MINERVA,因为RewardShaping适合处理一对多的关系类型,而NELL-995数据集中的关系类型大多是一对一的.从MAP结果来看,DIVA比DeepPath效果要好,这是因为DeepPath关注于找到实体对间的路径,缺少了对实体对是正样本还是负样本的判断,导致实验结果对噪声和对抗样本敏感,而DIVA更擅长处理噪声和应对更复杂的推理场景.M-Walk使用RNN编码状态,并将蒙特卡洛搜索树与神经策略结合来应对稀疏奖励的挑战,与DIVA、DeepPath相比,取得了更好的结果. ...
Variational knowledge graph reasoning
1
2018
... 强化学习模型通常采用一个0/1的硬奖励来监督抽样过程,指示抽样实体是否为正确的答案实体.Lin X V等人[50]提出的RS(reward shaping)在最后一步采用基于正确答案实体和采样实体之间的软奖励,而不是使用0/1的硬奖励.此外,受dropout技术的启发,RS模型在训练过程中为了避免选择大量的重复路径,缓解过拟合,采用了dropout技术.Shen Y L等人[51]提出的M-Walk引入了一种基于值的强化学习方法,并使用蒙特卡洛树搜索来克服稀疏正奖励的挑战.Chen W H等人[52]提出的DIVA将推理任务当作一个由寻找路径和答案推理组成的统一模型,其中路径建模为隐变量,采用AEVB(autoencoding variational Bayes)[53]对模型进行求解. ...
Autoencoding variational Bayes
1
2014
... 强化学习模型通常采用一个0/1的硬奖励来监督抽样过程,指示抽样实体是否为正确的答案实体.Lin X V等人[50]提出的RS(reward shaping)在最后一步采用基于正确答案实体和采样实体之间的软奖励,而不是使用0/1的硬奖励.此外,受dropout技术的启发,RS模型在训练过程中为了避免选择大量的重复路径,缓解过拟合,采用了dropout技术.Shen Y L等人[51]提出的M-Walk引入了一种基于值的强化学习方法,并使用蒙特卡洛树搜索来克服稀疏正奖励的挑战.Chen W H等人[52]提出的DIVA将推理任务当作一个由寻找路径和答案推理组成的统一模型,其中路径建模为隐变量,采用AEVB(autoencoding variational Bayes)[53]对模型进行求解. ...
Large-scale semantic parsing without question-answer pairs
1
2014
... 早期的基于语义解析的方法 将自然语言问题转换为结构化的查询(如SPARQL查询),在知识图谱上执行查询可以得到问题的答案.Reddy S等人[54]等人充分使用了组合范畴语法(combinatory categorial grammar,CCG)的表示能力,并提出Graph Parser模型来解析问题,受此启发,Yih W T等人[20]在2015年定义了查询图的概念,并提出了一个分阶段的查询图生成(staged query graph generation,STAGG)模型来处理知识图谱问答,查询图可以直接匹配为问题的逻辑形式,进而翻译成查询,因此语义解析问题可归结为查询图生成问题.STAGG定义了3个阶段来生成查询图:首先,使用现有的实体链接工具获取候选主题实体,并对其评分;然后,STAGG探索主题实体和答案节点之间的所有关系路径,为了限制搜索空间,它仅在下一跳的节点是一个复合类型(compound value type,CVT)节点时,探索长度为2的路径,否则只考虑长度为1的路径,使用深度卷积神经网络对所有关系路径进行打分,以判断当前选择的关系与问题的匹配程度;最后,根据启发式规则将约束节点附加到关系路径上.在这3个阶段的每个阶段,都使用对数线性模型对当前的部分查询图进行评分,并输出最佳的最终查询图来查询知识图谱.STAGG有效地使用了知识图谱中的信息来裁剪语义解析空间,从而简化了任务难度. ...
Constraint-based question answering with knowledge graph
1
2016
... 针对STAGG无法回答涵盖复杂约束的问题,Bao J W等人[55]扩展了约束类型和运算符,新增了类型约束以及显式和隐式时间约束等,将多重约束问题转化为多重约束查询图(multi-constraint query graph,MulCG)来实现推理,MulCG仍然遵循STAGG的框架,但提供了更多规则,以应对复杂问题.STAGG和MulCG等方法都要求首先将问题中的候选主题实体链接到知识图谱的实体上,实体链接的质量将影响后续的推理效果.Yu M等人[56]将知识 图谱问答分为实体链接和关系检测两个关键的子任务,并提出了一个残差学习增强的分级的双向LSTM(hierarchical residual bidirectional LSTM,HRBiLSTM)用于关系检测.对于实体链接,他们观察到,在SimpleQuestions数据集上主题实体识别的Top-1准确率只有72.7%,因此在由实体链接器产生初始的候选主题实体后,又将问题文本输入HR-BiLSTM中,HR-BiLSTM对问题以及在知识图谱中与候选主题实体相关联的关系进行不同抽象级别的编码,并计算两者的相似度得分,仅保留与那些得分较高的关系相关联的候选主题实体.在确定了新的主题实体后,同样使用HR-BiLSTM选择新的关系,以逐步地生成查询.在处理问题约束时,HRBiLSTM也遵循STAGG中的惯例. ...
Improved neural relation detection for knowledge base question answering
1
2017
... 针对STAGG无法回答涵盖复杂约束的问题,Bao J W等人[55]扩展了约束类型和运算符,新增了类型约束以及显式和隐式时间约束等,将多重约束问题转化为多重约束查询图(multi-constraint query graph,MulCG)来实现推理,MulCG仍然遵循STAGG的框架,但提供了更多规则,以应对复杂问题.STAGG和MulCG等方法都要求首先将问题中的候选主题实体链接到知识图谱的实体上,实体链接的质量将影响后续的推理效果.Yu M等人[56]将知识 图谱问答分为实体链接和关系检测两个关键的子任务,并提出了一个残差学习增强的分级的双向LSTM(hierarchical residual bidirectional LSTM,HRBiLSTM)用于关系检测.对于实体链接,他们观察到,在SimpleQuestions数据集上主题实体识别的Top-1准确率只有72.7%,因此在由实体链接器产生初始的候选主题实体后,又将问题文本输入HR-BiLSTM中,HR-BiLSTM对问题以及在知识图谱中与候选主题实体相关联的关系进行不同抽象级别的编码,并计算两者的相似度得分,仅保留与那些得分较高的关系相关联的候选主题实体.在确定了新的主题实体后,同样使用HR-BiLSTM选择新的关系,以逐步地生成查询.在处理问题约束时,HRBiLSTM也遵循STAGG中的惯例. ...
Query graph generation for answering multi-hop complex questions from knowledge bases
1
2020
... 为了限制搜索空间,STAGG只能探索2跳之内的路径,无法回答涉及更多跳推理的问题.Lan Y S等人[57]改进了STAGG方法,使其可以应对更长的关系路径,即在扩展路径的同时加入约束,而不是只在建立关系路径之后再添加约束,如此可以有效地缩减搜索空间,改进的分级查询图生成方法可以同时处理包含约束的问答和涉及多跳的问答,该方法在WebQuestionsSP(WebQSP)[58]系列数据集上取得了优异的表现. ...
The value of semantic parse labeling for knowledge base question answering
2
2016
... 为了限制搜索空间,STAGG只能探索2跳之内的路径,无法回答涉及更多跳推理的问题.Lan Y S等人[57]改进了STAGG方法,使其可以应对更长的关系路径,即在扩展路径的同时加入约束,而不是只在建立关系路径之后再添加约束,如此可以有效地缩减搜索空间,改进的分级查询图生成方法可以同时处理包含约束的问答和涉及多跳的问答,该方法在WebQuestionsSP(WebQSP)[58]系列数据集上取得了优异的表现. ...
... Yih W T等人[58]对WebQuestions数据集改进后提出了WebQuestionsSP数据集.WebQuestions是为了解决真实问题而构造的数据集,其问题来源于谷歌建议应用程序接口(Google suggest API),答案由众包平台Amazon Mechanic Turk通过人工标注生成.WebQuestions只包含了问题的答案,没有提供问题对应的查询语句,针对此缺点,WebQSP为每个问题构造了其对应的SPARQL查询表达,并删除了一些表达有歧义以及无清晰意图或答案的问题.WebQSP包含4 737个1跳或2跳问题,问题的答案可以在Freebase[69]知识库中找到. ...
Markov logic networks
1
2006
... 结合一阶逻辑的自然性和概率逻辑模型的不确定性优点,马尔可夫逻辑网络方法已被证明在知识图推理上的有效性[59-60].然而,在大规模知识图谱上由于三元组之间的复杂结构,以上方法推理过程困难,效率较低.基于注意力机制的图神经网络擅长处理高度复杂的图问题, Vardhan V H等人[61]提出的概率逻辑图注意力网络(probabilistic logic graph attention network,pGAT)用变分EM算法优化了由马尔可夫逻辑网络定义的所有可能三元组的联合分布.这有助于模型有效地结合一阶逻辑和图注意力网络.该推理模型的提出为多跳知识问答提供了有利的参考. ...
Discriminative training of Markov logic networks
1
2005
... 结合一阶逻辑的自然性和概率逻辑模型的不确定性优点,马尔可夫逻辑网络方法已被证明在知识图推理上的有效性[59-60].然而,在大规模知识图谱上由于三元组之间的复杂结构,以上方法推理过程困难,效率较低.基于注意力机制的图神经网络擅长处理高度复杂的图问题, Vardhan V H等人[61]提出的概率逻辑图注意力网络(probabilistic logic graph attention network,pGAT)用变分EM算法优化了由马尔可夫逻辑网络定义的所有可能三元组的联合分布.这有助于模型有效地结合一阶逻辑和图注意力网络.该推理模型的提出为多跳知识问答提供了有利的参考. ...
Probabilistic logic graph attention networks for reasoning
2
2020
... 结合一阶逻辑的自然性和概率逻辑模型的不确定性优点,马尔可夫逻辑网络方法已被证明在知识图推理上的有效性[59-60].然而,在大规模知识图谱上由于三元组之间的复杂结构,以上方法推理过程困难,效率较低.基于注意力机制的图神经网络擅长处理高度复杂的图问题, Vardhan V H等人[61]提出的概率逻辑图注意力网络(probabilistic logic graph attention network,pGAT)用变分EM算法优化了由马尔可夫逻辑网络定义的所有可能三元组的联合分布.这有助于模型有效地结合一阶逻辑和图注意力网络.该推理模型的提出为多跳知识问答提供了有利的参考. ...
... 近年来,为了解决知识图谱存在的规模庞大和不完整问题,逻辑规则与知识嵌入相结合的研究[61,62,63,64,65,66]受到很多关注.图查询嵌入(graph query embedding,GQE)[62]、Query2Box[67]以及BetaE[63]等方法将查询表示成有向无环的计算图,计算图指明了在知识图谱上进行多跳推理以获得目标答案的步骤.这些方法将一阶逻辑运算符看作可通过训练习得的几何操作,它们都以查询包含的主题实体的嵌入向量为起点,迭代地使用几何操作生成查询的嵌入向量,然后通过在向量空间中计算实体嵌入与查询嵌入的距离来预测答案. ...
Embedding logical queries on knowledge graphs
2
2018
... 近年来,为了解决知识图谱存在的规模庞大和不完整问题,逻辑规则与知识嵌入相结合的研究[61,62,63,64,65,66]受到很多关注.图查询嵌入(graph query embedding,GQE)[62]、Query2Box[67]以及BetaE[63]等方法将查询表示成有向无环的计算图,计算图指明了在知识图谱上进行多跳推理以获得目标答案的步骤.这些方法将一阶逻辑运算符看作可通过训练习得的几何操作,它们都以查询包含的主题实体的嵌入向量为起点,迭代地使用几何操作生成查询的嵌入向量,然后通过在向量空间中计算实体嵌入与查询嵌入的距离来预测答案. ...
... [62]、Query2Box[67]以及BetaE[63]等方法将查询表示成有向无环的计算图,计算图指明了在知识图谱上进行多跳推理以获得目标答案的步骤.这些方法将一阶逻辑运算符看作可通过训练习得的几何操作,它们都以查询包含的主题实体的嵌入向量为起点,迭代地使用几何操作生成查询的嵌入向量,然后通过在向量空间中计算实体嵌入与查询嵌入的距离来预测答案. ...
Beta embeddings for multi-hop logical reasoning in knowledge graphs
3
2020
... 近年来,为了解决知识图谱存在的规模庞大和不完整问题,逻辑规则与知识嵌入相结合的研究[61,62,63,64,65,66]受到很多关注.图查询嵌入(graph query embedding,GQE)[62]、Query2Box[67]以及BetaE[63]等方法将查询表示成有向无环的计算图,计算图指明了在知识图谱上进行多跳推理以获得目标答案的步骤.这些方法将一阶逻辑运算符看作可通过训练习得的几何操作,它们都以查询包含的主题实体的嵌入向量为起点,迭代地使用几何操作生成查询的嵌入向量,然后通过在向量空间中计算实体嵌入与查询嵌入的距离来预测答案. ...
... [63]等方法将查询表示成有向无环的计算图,计算图指明了在知识图谱上进行多跳推理以获得目标答案的步骤.这些方法将一阶逻辑运算符看作可通过训练习得的几何操作,它们都以查询包含的主题实体的嵌入向量为起点,迭代地使用几何操作生成查询的嵌入向量,然后通过在向量空间中计算实体嵌入与查询嵌入的距离来预测答案. ...
... 表2列出了基于逻辑的模型(GQE、Q2B(Query2Box)、BetaE)在FB15k、FB15k-237和NELL-995 3个数据集上多跳推理的结果[63]. ...
Improving knowledge graph embedding using simple constraints
1
2018
... 近年来,为了解决知识图谱存在的规模庞大和不完整问题,逻辑规则与知识嵌入相结合的研究[61,62,63,64,65,66]受到很多关注.图查询嵌入(graph query embedding,GQE)[62]、Query2Box[67]以及BetaE[63]等方法将查询表示成有向无环的计算图,计算图指明了在知识图谱上进行多跳推理以获得目标答案的步骤.这些方法将一阶逻辑运算符看作可通过训练习得的几何操作,它们都以查询包含的主题实体的嵌入向量为起点,迭代地使用几何操作生成查询的嵌入向量,然后通过在向量空间中计算实体嵌入与查询嵌入的距离来预测答案. ...
Knowledge graph embedding preserving soft logical regularity
1
2020
... 近年来,为了解决知识图谱存在的规模庞大和不完整问题,逻辑规则与知识嵌入相结合的研究[61,62,63,64,65,66]受到很多关注.图查询嵌入(graph query embedding,GQE)[62]、Query2Box[67]以及BetaE[63]等方法将查询表示成有向无环的计算图,计算图指明了在知识图谱上进行多跳推理以获得目标答案的步骤.这些方法将一阶逻辑运算符看作可通过训练习得的几何操作,它们都以查询包含的主题实体的嵌入向量为起点,迭代地使用几何操作生成查询的嵌入向量,然后通过在向量空间中计算实体嵌入与查询嵌入的距离来预测答案. ...
Probabilistic logic neural networks for reasoning
1
2019
... 近年来,为了解决知识图谱存在的规模庞大和不完整问题,逻辑规则与知识嵌入相结合的研究[61,62,63,64,65,66]受到很多关注.图查询嵌入(graph query embedding,GQE)[62]、Query2Box[67]以及BetaE[63]等方法将查询表示成有向无环的计算图,计算图指明了在知识图谱上进行多跳推理以获得目标答案的步骤.这些方法将一阶逻辑运算符看作可通过训练习得的几何操作,它们都以查询包含的主题实体的嵌入向量为起点,迭代地使用几何操作生成查询的嵌入向量,然后通过在向量空间中计算实体嵌入与查询嵌入的距离来预测答案. ...
Query2Box:reasoning over knowledge graphs in vector space using box embeddings
1
2020
... 近年来,为了解决知识图谱存在的规模庞大和不完整问题,逻辑规则与知识嵌入相结合的研究[61,62,63,64,65,66]受到很多关注.图查询嵌入(graph query embedding,GQE)[62]、Query2Box[67]以及BetaE[63]等方法将查询表示成有向无环的计算图,计算图指明了在知识图谱上进行多跳推理以获得目标答案的步骤.这些方法将一阶逻辑运算符看作可通过训练习得的几何操作,它们都以查询包含的主题实体的嵌入向量为起点,迭代地使用几何操作生成查询的嵌入向量,然后通过在向量空间中计算实体嵌入与查询嵌入的距离来预测答案. ...
Variational reasoning for question answering with knowledge graph
1
2018
... MetaQA数据集[68]是基于WikiMovies[40]数据集构建的多跳问答数据集,它包含超过40万个电影领域的多跳问题,这些问题有Vanilla、NTM和Audio 3个版本.Vanilla版本的MetaQA常被用于多跳知识问答推理任务,它除了包含1跳、2跳和3跳3种类型的问答数据,还包含一个知识图谱,其有约135 000个三元组、43 000个实体以及9种关系. ...
Freebase:a collaboratively created graph database for structuring human knowledge
1
2008
... Yih W T等人[58]对WebQuestions数据集改进后提出了WebQuestionsSP数据集.WebQuestions是为了解决真实问题而构造的数据集,其问题来源于谷歌建议应用程序接口(Google suggest API),答案由众包平台Amazon Mechanic Turk通过人工标注生成.WebQuestions只包含了问题的答案,没有提供问题对应的查询语句,针对此缺点,WebQSP为每个问题构造了其对应的SPARQL查询表达,并删除了一些表达有歧义以及无清晰意图或答案的问题.WebQSP包含4 737个1跳或2跳问题,问题的答案可以在Freebase[69]知识库中找到. ...
The web as a knowledge-base for answering complex questions
1
2018
... Talmor A等人[70]基于WebQSP构建了ComplexWebQuestions数据集.首先从WebQSP中采样问题及其SPARQL查询,并自动地构造更复杂的包含组合、连接、比较级以及最高级等形式的SPARQL查询,最后由Amazon Mechanic Turk众包平台将这些SPARQL查询重组为自然语言问题,问题的答案通过在Freebase中执行SPARQL查询获得.CWQ共包含34 689个问题及其对应的答案和SPARQL查询. ...
Observed versus latent features for knowledge base and text inference
1
2015
... FB15k[14]是Freebase的一个子集,也是知识图谱补全领域的一个基准数据集,由三元组构成.为了解决FB15k测试集数据泄露的问题,Toutanova K等人[71]在FB15k的基础上构建了FB15k-237,并且移除了FB15k中反向的关系.NELL995[47]数据集由NELL系统构建而来. ...










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}