

通信学报 ›› 2021, Vol. 42 ›› Issue (8): 176-187.doi: 10.11959/j.issn.1000-436x.2021150
胡强, 沈嘉吉, 荆广辉, 杜军威
修回日期:2021-06-29
出版日期:2021-08-25
发布日期:2021-08-01
作者简介:胡强(1980- ),男,山东邹城人,青岛科技大学副教授、硕士生导师,主要研究方向为服务计算、人工智能基金资助:Qiang HU, Jiaji SHEN, Guanghui JING, Junwei DU
Revised:2021-06-29
Online:2021-08-25
Published:2021-08-01
Supported by:摘要:
针对现有聚类方法中存在的服务表征向量生成质量较差问题,提出了一种面向描述语境特征词与改进GSDMM模型的服务聚类方法。首先,构建了基于语境权重的特征词提取方法,将与服务描述语境契合度高的词语抽取出,构建用于服务表征向量生成的功能特征词集合。然后,建立了带有主题分布概率修正因子的GSDMM模型,实现服务表征向量的生成以及非关键主题项概率分布修正。最后,基于修正后的服务表征向量,采用K-means++算法实现服务聚类。以Programmable Web上真实服务进行了多轮次实验,实验结果表明,采用所提方法生成的服务表征向量质量显著高于其他常用主题模型,所构建的服务聚算法性能优于其他常用算法。
中图分类号:
胡强, 沈嘉吉, 荆广辉, 杜军威. 基于描述语境特征词与改进GSDMM模型的服务聚类方法[J]. 通信学报, 2021, 42(8): 176-187.
Qiang HU, Jiaji SHEN, Guanghui JING, Junwei DU. Service clustering method based on description context feature words and improved GSDMM model[J]. Journal on Communications, 2021, 42(8): 176-187.

图1
研究流程"
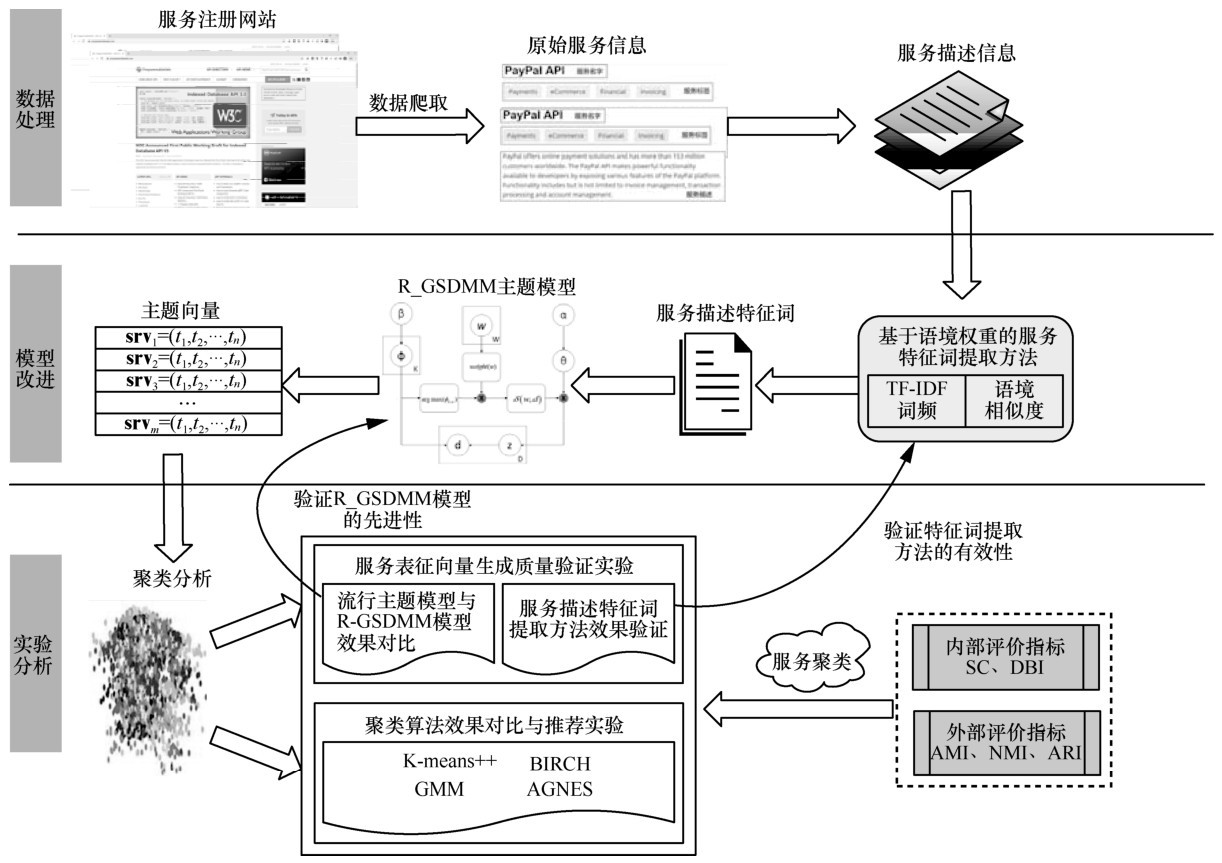

图2
Programmable Web 服务示例"
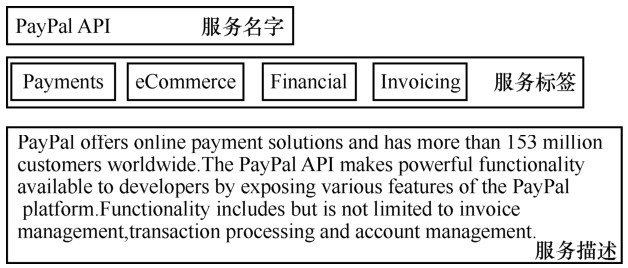
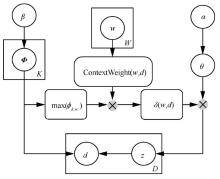
图3
带有主题概率分布修正因子的GSDMM模型"
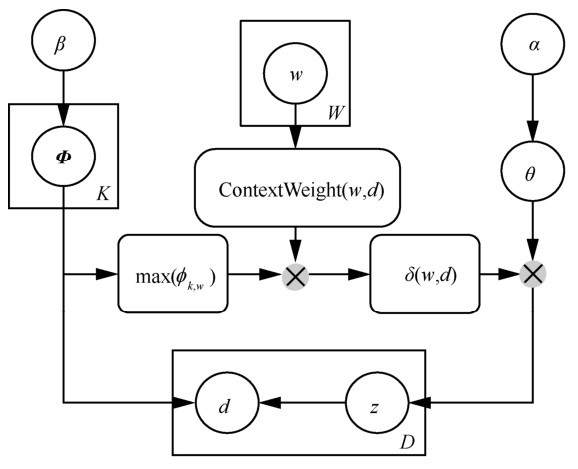
表1
内部评价数据集"
| 数据集 | 标签 | 数量/条 |
| DS1 | Financial\Tools\Messaging\Payments\eCommerce\Social\Mapping\Government\Data\Science\Security\Email\Telephony\Transpor- tation\ Reference\Enterprise | 8 180 |
| DS2 | DS1\Tools\Messaging\eCommerce\Science\SecurityData\Transportation\Sports\Education\Travel\Video\Advertising\Banking\Cloud\ Music\Photos\Weather\Cryptocurrency\Stocks\Shipping\Games\Telephony\ | 12 043 |
| DS3 | all | 18 439 |
表2
外部评价数据集"
| 数据集 | 标签 | 数量/条 |
| DS4 | Internet of Things\Database\Analytics\Backend\News Services\Medical\Events\Entertainment\Location\Media | 1 402 |
| DS5 | Banking\Cloud\Music\Photos\Weather\Cryptocurrency\Stocks\Shipping\Bitcoin\Project Management | 2 171 |
| DS6 | Tools\Messaging\eCommerce\Science\Security\Telephony\Data\Transportation\Sports\Education\Travel\Video\Games\Adv ertising | 5 751 |
表3
服务表征向量质量验证实验数据"
| 数据集 | 主题模型 | SC1 | SC2 | DBI1 | DBI2 |
| R_GSDMM | 0.882 | 0.637 | |||
| GSDMM | 0.857 | 0.892 | 0.765 | 0.621 | |
| LDA | 0.230 | 0.395 | 1.579 | 1.401 | |
| DS1 | LSA | 0.073 | 0.145 | 1.952 | 1.493 |
| LDA_W2V | 0.225 | 0.358 | 1.106 | 0.781 | |
| BTM | 0.227 | 0.272 | 1.391 | 1.308 | |
| HDP | 0.331 | 0.247 | 0.840 | 1.123 | |
| R_GSDMM | 0.870 | 0.696 | |||
| GSDMM | 0.851 | 0.893 | 0.774 | 0.695 | |
| LDA | 0.192 | 0.326 | 1.660 | 1.499 | |
| DS2 | LSA | 0.063 | 0.146 | 2.002 | 1.482 |
| LDA_W2V | 0.184 | 0.215 | 1.235 | 1.156 | |
| BTM | 0.195 | 0.239 | 1.472 | 1.393 | |
| HDP | 0.361 | 0.300 | 0.770 | 1.079 | |
| R_GSDMM | 0.842 | 0.812 | |||
| GSDMM | 0.826 | 0.863 | 0.843 | 0.808 | |
| LDA | 0.142 | 0.182 | 1.907 | 1.841 | |
| DS3 | LSA | 0.042 | 0.130 | 2.218 | 1.564 |
| LDA_W2V | 0.116 | 0.119 | 1.554 | 1.560 | |
| BTM | 0.150 | 0.189 | 1.679 | 1.565 | |
| HDP | 0.385 | 0.335 | 0.788 | 0.957 |
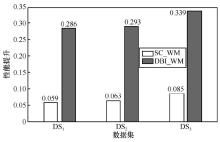
图4
本文方法对SC与DBI指标提升对比"
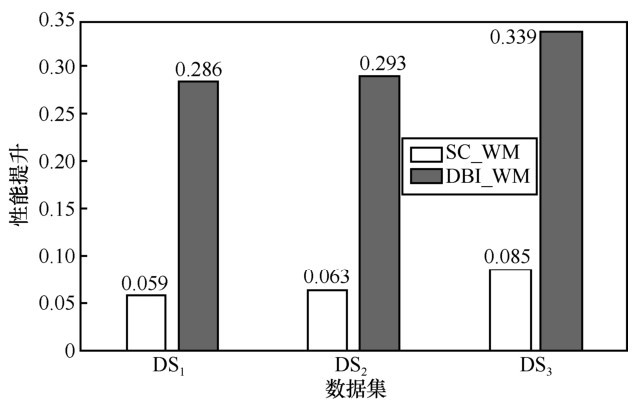
表4
服务表征向量质量验证DS4实验数据"
| 主题模型 | AMI1 | AMI2 | NMI1 | NMI2 | ARI1 | ARI2 |
| R_GSDMM | 0.349 | 0.371 | 0.219 | |||
| GSDMM | 0.317 | 0.364 | 0.334 | 0.389 | 0.206 | 0.183 |
| BTM | 0.266 | 0.345 | 0.294 | 0.384 | 0.145 | 0.168 |
| LDA | 0.106 | 0.186 | 0.123 | 0.209 | 0.072 | 0.101 |
| LSA | 0.292 | 0.317 | 0.366 | 0.385 | 0.113 | 0.118 |
| LDAW2V | 0.018 | 0.022 | 0.031 | 0.036 | 0.007 | 0.009 |
| HDP | 0.033 | 0.066 | 0.048 | 0.107 | 0.015 | 0.012 |
表5
服务表征向量质量验证DS5实验数据"
| 主题模型 | AMI1 | AMI2 | NMI1 | NMI2 | ARI1 | ARI2 |
| R_GSDMM | 0.669 | 0.682 | 0.520 | |||
| GSDMM | 0.634 | 0.659 | 0.653 | 0.686 | 0.453 | 0.471 |
| BTM | 0.286 | 0.335 | 0.408 | 0.436 | 0.089 | 0.132 |
| LDA | 0.368 | 0.499 | 0.378 | 0.520 | 0.267 | 0.384 |
| LSA | 0.548 | 0.628 | 0.596 | 0.665 | 0.279 | 0.402 |
| LDAW2V | 0.055 | 0.070 | 0.066 | 0.080 | 0.020 | 0.028 |
| HDP | 0.127 | 0.223 | 0.141 | 0.262 | 0.053 | 0.108 |
表6
服务表征向量质量验证DS6实验数据"
| 主题模型 | AMI1 | AMI2 | NMI1 | NMI2 | ARI1 | ARI2 |
| R_GSDMM | 0.441 | 0.450 | 0.315 | |||
| GSDMM | 0.421 | 0.484 | 0.433 | 0.501 | 0.260 | 0.274 |
| BTM | 0.426 | 0.503 | 0.460 | 0.546 | 0.176 | 0.274 |
| LDA | 0.201 | 0.343 | 0.209 | 0.357 | 0.103 | 0.192 |
| LSA | 0.338 | 0.387 | 0.418 | 0.443 | 0.107 | 0.181 |
| LDAW2V | 0.130 | 0.218 | 0.138 | 0.225 | 0.052 | 0.088 |
| HDP | 0.031 | 0.146 | 0.039 | 0.152 | 0.010 | 0.063 |
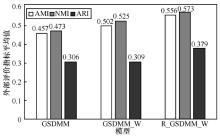
图5
不同模型外部评价指标平均值对比"
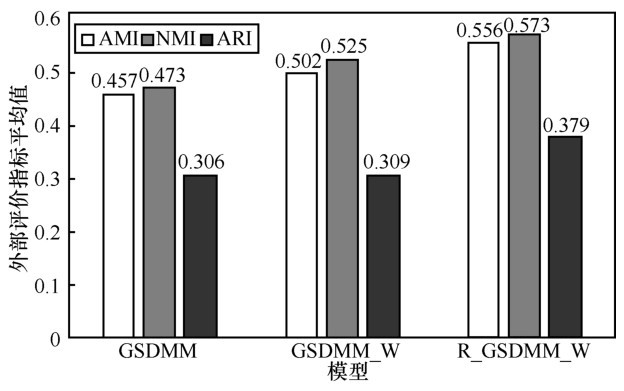
表7
聚类效果质量验证实验数据"
| 聚类数目 | 聚类方法 | SC | DBI |
| K-means++ | 0.546 | ||
| DS1 | AGNES | 0.906 | |
| BIRCH | 0.898 | 0.644 | |
| GMM | 0.847 | 0.720 | |
| K-means++ | |||
| DS2 | AGNES | 0.903 | 0.587 |
| BIRCH | 0.902 | 0.606 | |
| GMM | 0.840 | 0.816 | |
| K-means++ | |||
| DS3 | AGNES | 0.891 | 0.579 |
| BIRCH | 0.889 | 0.687 | |
| GMM | 0.794 | 1.087 |
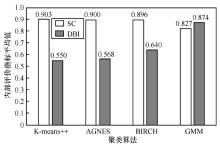
图6
不同聚类算法内部评价指标平均值对比"
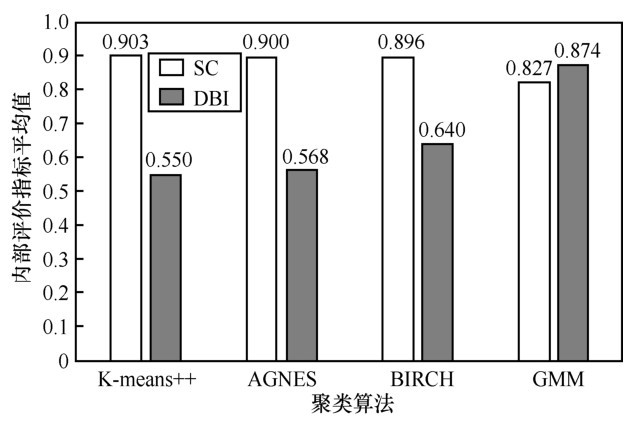
表8
聚类效果质量验证实验数据"
| 数据集 | 聚类算法 | AMI | NMI | ARI |
| K-means++ | 0.443 | 0.465 | 0.274 | |
| DS4 | GMMBIRCH | 0.4280.329 | 0.4600.373 | 0.2550.188 |
| AGNES | ||||
| K-means++ | ||||
| DS5 | GMMBIRCH | 0.6780.496 | 0.7020.568 | 0.5220.279 |
| AGNES | 0.687 | 0.703 | 0.519 | |
| K-means++ | ||||
| DS6 | GMMBIRCH | 0.5340.456 | 0.5410.485 | 0.3540.253 |
| AGNES | 0.527 | 0.539 | 0.323 |
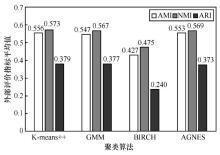
图7
不同聚类算法外部评价指标平均值对比"
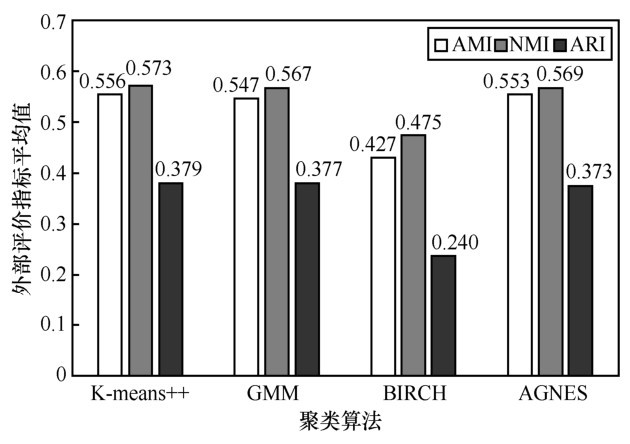
表9
聚类算法最优指标值统计结果"
| 聚类算法 | SC | DBI | AMI | NMI | ARI | SUM |
| K-means++ | 13 | 11 | 2 | 2 | 2 | 30 |
| AGNES | 1 | 4 | 1 | 1 | 1 | 8 |
| BIRCH | 2 | 0 | 0 | 0 | 0 | 2 |
| GMM | 0 | 0 | 0 | 0 | 0 | 0 |
| [1] | NIKNEJAD N , ISMAIL W , GHANI I ,et al. Understanding service-oriented architecture (SOA):a systematic literature review and directions for further investigation[J]. Information Systems, 2020,91:101491. |
| [2] | 赵晨阳, 王俊岭 . 基于隐含上下文支持向量机的服务推荐方法[J]. 通信学报, 2019,40(9): 61-73. |
| ZHAO C Y , WANG J L . Service recommendation method based on context-embedded support vector machine[J]. Journal on Communications, 2019,40(9): 61-73. | |
| [3] | HALILI F , RAMADANI E . Web services:a comparison of soap and rest services[J]. Modern Applied Science, 2018,12(3): 175-183. |
| [4] | 贾春福, 李瑞琪, 王雅飞 . 基于同态加密的 DBSCAN 聚类隐私保护方案[J]. 通信学报, 2021,42(2): 1-11. |
| JIA C F , LI R Q , WANG Y F . Privacy protection scheme of DBSCAN clustering based on homomorphic encryption[J]. Journal on Communications, 2021,42(2): 1-11. | |
| [5] | 曹步清, 肖巧翔, 张祥平 ,等. 融合SOM功能聚类与DeepFM质量预测的API服务推荐方法[J]. 计算机学报, 2019,42(6): 1367-1383. |
| CAO B Q , XIAO Q X , ZHANG X P ,et al. An API service recommendation method via combining self-organization map-based functionality clustering and deep factorization machine-based quality prediction[J]. Chinese Journal of Computers, 2019,42(6): 1367-1383. | |
| [6] | AGARWAL N , SIKKA G , AWASTHI L K . Enhancing Web service clustering using length feature weight method for service description document vector space representation[J]. Expert Systems with Applications, 2020,161:113682. |
| [7] | NABLI H , BEN D R , BEN A I A . Efficient cloud service discovery approach based on LDA topic modeling[J]. Journal of Systems and Software, 2018,146: 233-248. |
| [8] | VADIVELOU G , ILAVARASAN E . Performance evaluation of semantic approaches for automatic clustering of similar Web services[C]// 2014 World Congress on Computing and Communication Technologies. Los Alamitos:IEEE Computer Society, 2014: 237-242. |
| [9] | KIM S , PARK H , LEE J . Word2Vec-based latent semantic analysis (W2V-LSA) for topic modeling:a study on blockchain technology trend analysis[J]. Expert Systems With Applications, 2020,152:113401. |
| [10] | CAO B Q , LIU X , LIU J X ,et al. Domain-aware Mashup service clustering based on LDA topic model from multiple data sources[J]. Information and Software Technology, 2017,90: 40-54. |
| [11] | DAS R , ZAHEER M , DYER C . Gaussian LDA for topic models with word embeddings[C]// Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing. Stroudsburg:ACL Press, 2015: 795-804. |
| [12] | CHENG X Q , YAN X H , LAN Y Y ,et al. BTM:topic modeling over short texts[J]. IEEE Transactions on Knowledge and Data Engineering, 2014,26(12): 2928-2941. |
| [13] | BASKARA A R , SARNO R . Web service discovery using combined bi-term topic model and WDAG similarity[C]// 2017 11th International Conference on Information & Communication Technology and System. Piscataway:IEEE Press, 2017: 235-240. |
| [14] | JIANG Y C , TAO D D , LIU Y Z ,et al. Cloud service recommendation based on unstructured textual information[J]. Future Generation Computer Systems, 2019,97: 387-396. |
| [15] | AGARWAL N , SIKKA G , AWASTHI L K . Evaluation of Web service clustering using Dirichlet multinomial mixture model based approach for dimensionality reduction in service representation[J]. Information Processing & Management, 2020,57(4): 102238. |
| [16] | YIN J , WANG J . A Dirichlet multinomial mixture model-based approach for short text clustering[C]// Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data mining. New York:ACM Press, 2014: 233-242. |
| [17] | 谢晓兰, 曾兰英, 翟青海 . 制造云服务组合中支持服务关联的 QoS感知评估模型[J]. 通信学报, 2021,42(1): 118-129. |
| XIE X L , ZENG L Y , ZHAI Q H . QoS aware evaluation model supporting service correlation in manufacturing cloud service composition[J]. Journal on Communications, 2021,42(1): 118-129. | |
| [18] | LIANG T , CHEN L , YING H ,et al. Co-clustering WSDL documents to bootstrap service discovery[C]// 2014 IEEE 7th International Conference on Service-Oriented Computing and Applications. Piscataway:IEEE Press, 2014: 215-222. |
| [19] | WU J , CHEN L , ZHENG Z B ,et al. Clustering Web services to facilitate service discovery[J]. Knowledge and Information Systems, 2014,38(1): 207-229. |
| [20] | 张键红, 武梦龙, 王晶 ,等. 云环境下安全的可验证多关键词搜索加密方案[J]. 通信学报, 2021,42(4): 139-149. |
| ZHANG J H , WU M L , WANG J ,et al. Secure and verifiable multi-keyword searchable encryption scheme in cloud[J]. Journal on Communications, 2021,42(4): 139-149. | |
| [21] | CAO B Q , LIU X F , RAHMAN M M ,et al. Integrated content and network-based service clustering and Web APIs recommendation for mashup development[J]. IEEE Transactions on Services Computing, 2020,13(1): 99-113. |
| [22] | LIZARRALDE I , MATEOS C , ZUNINO A ,et al. Discovering Web services in social Web service repositories using deep variational autoencoders[J]. Information Processing & Management, 2020,57(4): 102231. |
| [23] | ZHANG N , WANG J , HE K ,et al. Mining and clustering service goals for RESTful service discovery[J]. Knowledge and Information Systems, 2019,58(3): 669-700. |
| [24] | 刘建勋, 石敏, 周栋 ,等. 基于主题模型的 Mashup 标签推荐方法[J]. 计算机学报, 2017,40(2): 520-534. |
| LIU J X , SHI M , ZHOU D ,et al. Topic model based tag recommendation method for Mashups[J]. Chinese Journal of Computers, 2017,40(2): 520-534. | |
| [25] | 石敏, 刘建勋, 周栋 ,等. 基于多重关系主题模型的Web服务聚类方法[J]. 计算机学报, 2019,42(4): 820-836. |
| SHI M , LIU J X , ZHOU D ,et al. Multi-relational topic model-based approach for Web services clustering[J]. Chinese Journal of Computers, 2019,42(4): 820-836. | |
| [26] | SHI M , TANG Y F , LIU J X . Functional and contextual attention-based LSTM for service recommendation in Mashup creation[J]. IEEE Transactions on Parallel and Distributed Systems, 2019,30(5): 1077-1090. |
| [27] | YE H , CAO B , CHEN J ,et al. A Web services classification method based on GCN[C]// 2019 IEEE International Conference on Parallel &Distributed Processing with Applications,Big Data & Cloud Computing,Sustainable Computing & Communications,Social Computing &Networking. Piscataway:IEEE Press, 2019: 1107-1114. |
| [1] | 石磊,杜军平,梁美玉. 基于RNN和主题模型的社交网络突发话题发现[J]. 通信学报, 2018, 39(4): 189-198. |
| [2] | 陈蕾,杨庚,陈正宇,肖甫,许建. 基于结构化噪声矩阵补全的Web服务QoS预测[J]. 通信学报, 2015, 36(6): 49-59. |
| [3] | 尚燕敏,张鹏,曹亚男. 融合链接拓扑结构和用户兴趣的朋友推荐方法[J]. 通信学报, 2015, 36(2): 117-125. |
| [4] | 田浩,樊红,杜武. 基于用户社群关系的Web服务发现研究[J]. 通信学报, 2015, 36(10): 28-36. |
| [5] | 陈一鸣,陈立南. Jersey的研究和在Web服务中的应用[J]. 通信学报, 2014, 35(Z1): 150-159. |
| [6] | 陈一鸣,陈立南. Jersey的研究和在Web服务中的应用[J]. 通信学报, 2014, 35(Z1): 30-159. |
| [7] | 曹玖新,吴江林,王国进,刘波,杨鹏伟,董丹. 基于Alloy的服务组合验证[J]. 通信学报, 2012, 33(Z2): 1-8. |
| [8] | 高洪皓,李莹,张渊源. 基于可信链模型的Web服务组合研究[J]. 通信学报, 2011, 32(9A): 77-86. |
| [9] | 杨墨,王丽娜. 基于信任容错的Web服务可靠性增强方法研究[J]. 通信学报, 2010, 31(9): 133-140. |
| [10] | 刘大有,刘思培,齐红. 基于SROIQB的语义Web服务建模和组合[J]. 通信学报, 2010, 31(8A): 1-9. |
| [11] | 陈志刚,刘莉平,刘安丰. 基于黑白板的信任敏感Web服务组合策略[J]. 通信学报, 2010, 31(6): 25-34. |
| [12] | 王若曈,张辉,杨家海,黄桂奋. P2P网络管理系统信息模型的设计与实现[J]. 通信学报, 2010, 31(1): 85-91. |
| [13] | 李晖,崔立真,王海洋. 基于Web服务的智能流程构建方法[J]. 通信学报, 2009, 30(5): 128-135. |
| [14] | 付燕宁,刘磊,金成植. 基于服务链的Web服务组合方法[J]. 通信学报, 2007, 28(7): 92-97. |
| [15] | 荆波,董晶,史美林. 面向服务的业务流程协作与集成平台研究[J]. 通信学报, 2006, 27(11): 19-23. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||
|
||